1. Product background and iterative thinking
MVP: the smallest available product, the smallest subset of functions that can make the business run
That is, first implement the most core and important functions in the current version, and then iterate the functions step by step
How to find out the MVP function scope of the product:
- Determine the core objectives, core users and core scenarios of the product
- Do product objectives need to be completed or presented online
- What should the minimum MVP product do to achieve business objectives
- Which functions are not on the core path of user process
- What simplifications and assumptions can be made to deliver products in the shortest time and make the business process run
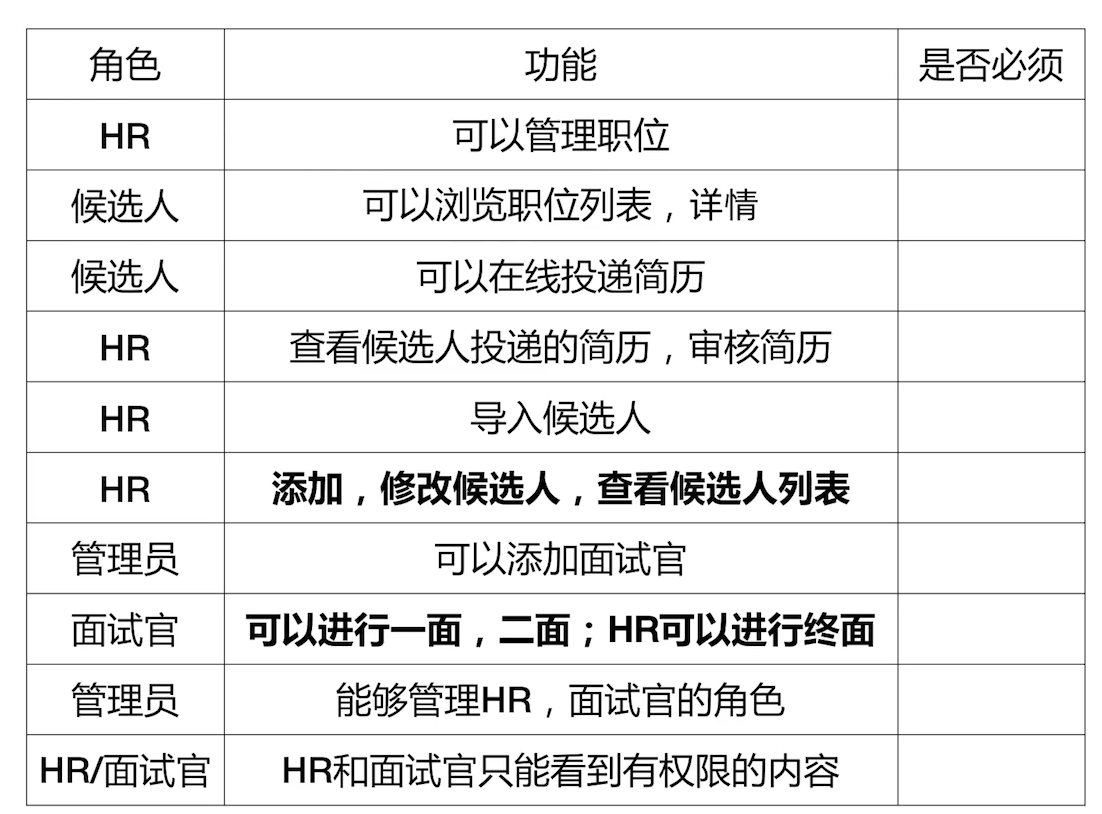
2. Ten principles of enterprise database design
1. Three basic principles
- Clear structure: the table name and field name have no ambiguity and can be understood at a glance
- Sole responsibility: one table for one use, clear domain definition, no irrelevant information is stored, and relevant data is in one table
- Primary key responsibilities: design primary keys without physical meaning, have unique constraints, and ensure idempotence
2. 4 scalability principles (affecting system performance and capacity)
- Separation of length and length: it can be expanded. Long text can be stored independently with appropriate capacity design. Usually, long text is stored in KT system
- Hot and cold separation: separation of current data from historical data
- Complete index: there is an appropriate index to facilitate query
- Disassociated query: do not use all SQLJoin operations, and do not perform associated queries for two or more tables
3. Three completeness principles
- Integrity: ensure the accuracy and integrity of data, and record the main contents
- Traceable: traceable to the creation time, modification time, and can be deleted logically
- Consistency principle: the data shall be consistent, and the same data shall not be stored in different tables as far as possible
3. In model__ unicode__ And__ str__ Use of
#python2 gives priority to using this method to convert objects into strings, if not__ unicode__ () method, use__ str__ () method
def __unicode__(self):
return self.username
#Python 3 direct definition__ str__ () method, which is used by the system to convert the object into a string
def __str__(self):
return self.username #Defines the field name that the view displays
4. Grouping of detail pages in admin
# Grouping, fieldsets is the set list of fields; The first element of the tuple represents the name of the group display; The second element is a map that defines which fields are available
fieldsets = (
(None, {'fields': ("userid", ("username", "city"), ("phone", "email"), ("apply_position", "born_address"), ("gender", "candidate_remark"), ("bachelor_school", "master_school", "doctor_school"), ("major", "degree"), ("test_score_general_ability", "paper_score"),"last_editor",)}),
('First round interview record', {'fields': (("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage", "first_disadvantage", ("first_result", "first_recommend_position"), ("first_interviewer", "first_remark"),)}),
('Second round interview record', {'fields': ("second_score", ("second_learning_ability", "second_professional_competency", "second_pursue_of_excellence"), ("second_communication_ability", "second_pressure_score"), "second_advantage", "second_disadvantage", ("second_result", "second_recommend_position"), ("second_interviewer", "second_remark"),)}),
('HR Retest record', {'fields': ("hr_score", ("hr_responsibility", "hr_communication_ability", "hr_logic_ability", "hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", ("hr_result", "hr_interviewer", "hr_remark"),)})
)
5. Batch import candidate data from Excel file
Create a file named import_candidates
class Command(BaseCommand):
help = 'From one CSV Read the candidate list from the contents of the file and import it into the database' # Help text
#Command line parameters
def add_arguments(self, parser):
parser.add_argument('--path', type=str) # Use the long command line, which is commonly used in Linux commands, -- represents a long command, and the parameter passed in is a string type
# processing logic
def handle(self, *args, **options):
path = options['path'] # Read path
with open(path,'rt',encoding='gbk') as f: # Open file as read-only
reader = csv.reader(f,dialect='excel',delimiter=';') # Read files with csv; dialect: Specifies the format, delimiter: Specifies the delimiter
for row in reader: # Traverse each line
candidate = Candidate.objects.create(
username = row[0],
city = row[1],
phone=row[2],
bachelor_school=row[3],
major=row[4],
degree=row[5],
test_score_general_ability=row[6],
paper_score=row[7]
)
print(candidate)
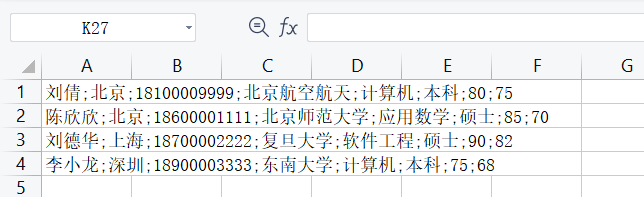
Enter the command on the terminal: Python manage py import_ candidates --path ./ candidates. csv to import csv content
The content format of csv file is:
6. List filtering and query
Operate in admin
# List page search properties
search_fields = ('username', 'phone', 'email', 'bachelor_school')
#Filter criteria (a filter block appears in the display page coordinates)
list_filter = ('city','first_result','hr_result','first_interviewer_user','second_interviewer_user','hr_interviewer_user')
# List page sorting
ordering = ('hr_result', 'second_result', 'first_result')
7. Export data to csv file
Define a function export in admin_ model_ as_ csv
# Realize data export function
exportable_fields = ('username', 'city', 'phone', 'bachelor_school', 'master_school', 'degree', 'first_result', 'first_interviewer',
'second_result', 'second_interviewer', 'hr_result', 'hr_score', 'hr_remark', 'hr_interviewer')
# Request is the request initiated by the user, and queryset is the data set in the result list selected by the user on the interface
def export_model_as_csv(modeladmin,request,queryset): # Request is the request initiated by the user. queryset is the data set in the result list selected by the user in the list
response = HttpResponse(content_type='text/csv')
field_list = exportable_fields # Exported fields
# Specifies the format of the exported file
response['Content-Disposition'] = 'attachment; filename=%s-list-%s.csv' %(
'recruitment-candidates',
datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
)
#Write header
writer = csv.writer(response)
writer.writerow(
# Take the Chinese name displayed on the page corresponding to each field as the header in our export file,
[queryset.model._meta.get_field(f).verbose_name.title() for f in field_list]
)
# Write in every line of data
for obj in queryset:
#A single line record (the value of each field) is written to the csv file
csv_line_values = []
for field in field_list:
field_object = queryset.model._meta.get_field(field)
field_value = field_object.value_from_object(obj)
csv_line_values.append(field_value)
writer.writerow(csv_line_values)
return response
# Define the properties of this function
export_model_as_csv.short_description = u'Export as CSV file'
Register the function in actions, and the actions will be registered in the function that inherits ModelAdmin
actions = [export_model_as_csv,]
8. Record logs to facilitate troubleshooting
Four components
- Loggers: processing class / object of logging. A Logger can have multiple Handlers
- Handler: how to handle each log message, record it to file, console or network
- Filters: defines filters, which are used on the Logger/Handler
- Formatters: defines the format of log text records
Four log levels
- DEBUG: DEBUG
- INFO: common system information
- WARNING: a small WARNING that does not affect the main functions
- ERROR: the system has an ERROR that cannot be ignored
- CRITICAL: a very serious error
# Logging
LOGGING = {
"version": 1, # Version number of the logging format
"disable_existing_loggers":False, # Disable the existing Logger
"handlers": {
"console": {
"class": "logging.StreamHandler",
},
},
"loggers":{
"django_python3_ldap":{
"handlers":["console"], # It will output to the console
"level":"DEBUG", # level
},
},
}
Detailed definition
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'simple': { # exact format is not important, this is the minimum information
'format': '%(asctime)s %(name)-12s %(lineno)d %(levelname)-8s %(message)s',
},
},
'handlers': {
'console': {
'class': 'logging.StreamHandler', # Output to console
'formatter': 'simple',
},
'mail_admins': { # Add Handler for mail_admins for `warning` and above
'level': 'ERROR', # Defines the level of error. The log is sent to the mail and sent to the mail processor
'class': 'django.utils.log.AdminEmailHandler',
},
'file': { # Record to file and record log information to file
#'level': 'INFO',
'class': 'logging.FileHandler',
'formatter': 'simple',
'filename': os.path.join(BASE_DIR, 'recruitment.admin.log'), #BASE_ The previous directory of dir, that is, under the previous directory of the project directory
},
'performance': {
#'level': 'INFO',
'class': 'logging.FileHandler',
'formatter': 'simple',
'filename': os.path.join(BASE_DIR, 'recruitment.performance.log'),
},
},
'root': { #The default Logger at the global level of the system is a special Logger in Logger
'handlers': ['console', 'file'], # Console and file output at the same time
'level': 'INFO',
},
"interview.performance": {
"handlers": ["console", "performance"],
"level": "INFO",
"propagate": False,
},
}
Custom log
Define Logger class
loggng=logging.getLogger(__name__)
Write in the function that needs to be written to the log. Take the function of exporting csv file as an example:
logging.info('%s exported %s candidate records' % (request.user, len(queryset)))
9. Separation of production environment and development environment configuration
Question:
- The configuration of the production environment is separated from that of the development environment, which allows Debugging
- Sensitive information is not submitted to the code base, such as database connection, secret key, LDAP connection information, etc
- The configurations used in production and development environments may be different. For example, MySQL/Sqlite databases are used respectively
This information can be put into the configuration of the development environment, and the configuration of the development environment can be changed from Go inside gitignore and specify it
You can create a settings package in the project directory and set settings Put the configuration of Py in the settings package and rename the file base Py, you also need to create one in the settings package__ init__.py file
The original reference configuration was in manage Py, manage Py has a setdefault, which sets DJANGO_SETTINGS_MODULE refers to the configuration of settings under the recruitment package, so it should be changed to base under the settings package py
When we start the django environment and do not specify the django configuration by default, we use settings base
In settings Base contains the basic configuration and creates local Py and production Py configuration file, you can set local Py condition reached In gitignore
Specify configuration:
python manage.py runserver 0.0.0.0:8000 --settings=settings.local
The specified configuration will overwrite the configuration in the base
10. Perfect page
Title, defined in urls:
from django.utils.translation import gettext as _
admin.site.site_header = _('Jiangguo technology recruitment management system')
Use help in the model field_ Text to set the prompt content
HR decides who the interviewer is. The interviewer cannot change HR's decisionChange interviewer to option:
second_interviewer_user = models.ForeignKey(User, related_name='second_interviewer_user', blank=True, #It refers to a foreign key, so it becomes choice
null=True, on_delete=models.CASCADE,
verbose_name=u'interviewer')
For the interviewer, the interviewer field can only be read:
#The first approach
#Set the read-only field and the detailed page. This is a method facing all users
readonly_fields = ('first_interviewer_user','second_interviewer_user')
# The second method
# Set the read-only field, detailed page, the second method
def get_group_names(self,user):
group_names = []
for g in user.groups.all():
group_names.append(g.name)
return group_names
def get_readonly_fields(self, request, obj=None):
group_names = self.get_group_names(request.user) # Get the user's group
if 'interviewer' in group_names:
logging.info("interviewer is in user's group for %s" % request.user.username)
return ('first_interviewer_user','second_interviewer_user')
return ()
Enables HR to make batch modifications on the list page
# The first way is for all users
#superuser modifiable options for data form pages
list_editable = ('first_interviewer_user','second_interviewer_user')
# The second way
def get_list_editable(self, request):
group_names = self.get_group_names(request.user)
if request.user.is_superuser or 'hr' in group_names:
return ('first_interviewer_user','second_interviewer_user',)
return ()
# Use get_list_editable returns a list. django does not recognize it because django does not recognize the list_editable has no corresponding function to support the setting of this property, so it overrides a get defined in ModelAdmin_ changelist_ Instance, overriding the parent class list_ Properties of editable
def get_changelist_instance(self, request): #Override list of parent class_ Editable property
self.list_editable = self.get_list_editable(request)
return super(CandidateAdmin, self).get_changelist_instance(request)