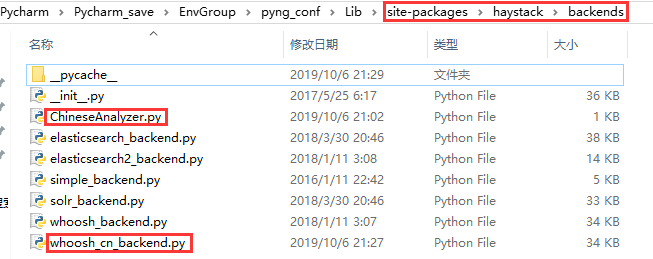
In order to achieve the search function in the project, we use the full-text search framework haystack+ search engine whoosh+ Chinese word packet jieba
install and configure
Installation of required packages
pip install django-haystack
pip install whoosh
pip install jieba
Register haystack application to settings file
INSTALLED_APPS = [ 'haystack', # Registered Full Text Retrieval Framework ]
Configuring Full Text Retrieval Framework in settings File
# Configuration of Full Text Retrieval Framework HAYSTACK_CONNECTIONS = { 'default': { # Use whoosh engine 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine', # Index file path 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), } } # When adding, modifying and deleting data, automatically generate index HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
Generation of Index Files
To generate an index file, you first need to configure which content to index, such as product name, profile and details; in order to configure the database to index the specified content, we need to do the following steps:
Configure the search_indexes.py file
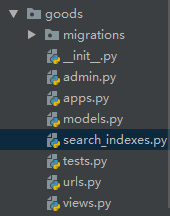
Because the database in django is usually generated by ORM, first of all, we need to create a search_indexes.py file in the application corresponding to the data table. For example, I want to retrieve the corresponding table of the goods now is the Goods SKU table, and the table is under the application of goods, so I create a new search_indexes.py file under the application of goods. The screenshot is as follows:
Add the following to the search_indexes.py file
# Define index classes from haystack import indexes # Import your model class from goods.models import GoodsSKU # Specifies that some data of a class is indexed # Index Class Name Format:Model class name+Index class GoodsSKUIndex(indexes.SearchIndex, indexes.Indexable): # Index field use_template=True Specifies which fields in the table are indexed according to the instructions placed in a file text = indexes.CharField(document=True, use_template=True) def get_model(self): # Return to your model class return GoodsSKU # Indexed data def index_queryset(self, using=None): return self.get_model().objects.all()
Specify the content to be retrieved
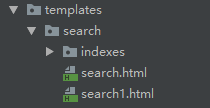
New search folder under templates folder, new indexes folder under search folder, new folder to retrieve application name under indexes folder, such as goods folder, new table name _text.txt under goods folder, table name lowercase, so the current directory structure is templates/search/indexes/goods/goodssku_text.txt, such as screenshots. Next:

In the goodssku_text.txt file, specify which fields in the table you want to index data. Now we need to index according to the name, description and details of the product. The following configuration
# Specify which fields in the table to index data {{ object.name }} # Index by the name of the commodity {{ object.desc }} # Establish an index based on the product profile {{ object.goods.detail }} # Index the details of the goods
Objects can be understood as commodity objects corresponding to data tables.
Generate index file
Use the command line terminal that comes with pycharm to run the following commands to generate index files:
python manage.py rebuild_index
After running successfully, you can see the following index files under the project
Using Full Text Retrieval
With the above configuration, our data index has been established, and now we are going to use full-text retrieval in our project.
Form form modification where retrieval is needed
<form action="/search" method="get"> <input type="text" class="input_text fl" name="q" placeholder="Search merchandise"> <input type="submit" class="input_btn fr" name="" value="search"> </form>
As shown above, it should be noted that:
- The way of sending must use get.
- The search input box name must be q;
Configuration retrieves the corresponding url
Add the following url configuration to the urls.py file under the project
urlpatterns = [ url(r'^search/', include('haystack.urls')), # Full Text Retrieval Framework ]
Parameters generated after successful retrieval
When haystack automatically retrieves successfully, three parameters will be returned to us.
- The query parameter represents the parameters of your query.
- The page parameter, the page object of the current page, is a collection of queried objects, which can obtain a single commodity through the for loop class, and the corresponding fields of the commodity through the commodity. objects. xxxx.
- paginator parameter, paginator object paginated.
The parameters can be tested with the following code
templates/indexes/search.html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> Search keywords:{{ query }}<br/> Current page Page object:{{ page }}<br/> <ul> {% for item in page %} <li>{{ item.object }}</li> {% endfor %} </ul> paging paginator object:{{ paginator }}<br/> </body> </html>
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> Search keywords:{{ query }}<br/> Current page Page object:{{ page }}<br/> <ul> {% for item in page %} <li>{{ item.object }}</li> {% endfor %} </ul> paging paginator object:{{ paginator }}<br/> </body> </html>