Article Directory
https://www.cnblogs.com/wish123/p/5573098.html
Preface
-
Docker, one of the most secure container technologies, provides strong security default configurations in many ways, including Capability capability restrictions for container root users, Seccomp system call filtering, MAC access control for Apparmor, ulimit restrictions, pid-limits support, mirror signature mechanisms, and so on.
-
Docker uses Namespace to achieve six isolations, which appear to be complete, but still do not completely isolate Linux resources, such as directories such as / proc, /sys, /dev/sd*, and all information other than SELinux, time, and syslog is not completely isolated.In fact, Docker has done a lot of work on security, including the following aspects:
-
1. Capability limitations of the Linux kernel
Docker supports setting Capabilities for containers and specifying permissions to open to containers.This way, the root user in the container has many fewer privileges than the actual root.After version 0.6, Docker supports opening containers with super privileges so that containers have host root privileges. -
2. Mirror Signature Mechanism
Since version 1.8, Docker has provided a mirror signature mechanism to verify the source and integrity of the image. This feature needs to be turned on manually so that the image creator can sign the image before the push image. Docker will not pull validation fails or unsigned image labels when the mirror pulls. -
3. MAC Access Control for Apparmor
Apparmor can associate process privileges with process Capabilities capabilities to achieve mandatory access control (MAC) for a process.In Docker, we can use Apparmor to limit the ability of users to execute certain commands, limit container networks, read and write permissions to files, and so on. -
4. Seccomp System Call Filtering
Using Seccomp, you can limit the range of system calls that a process can invoke. The default Seccomp configuration file provided by Docker has disabled about 44 more than 300+ system calls to satisfy the system call requirements of most containers. -
5. User Namespace Isolation
Namespace provides isolation for running processes and restricts their access to system resources without the process being aware of these restrictions. The best way to prevent privilege escalation attacks within a container is to configure the container's application to run as an unprivileged user and the process must run as the root user in the containerContainer that can remap this user to a user with lower privileges on the Docker host.The mapped user is assigned a series of UIDs that run as normal UIDs from 0 to 65536 in the namespace but do not have privileges on the host. -
6,SELinux
SELinux provides mandatory access control (MAC), which is no longer based solely on the rwx privileges of the process owner and file resources.It can add a barrier to an attacker's container breakthrough attack.Docker provides support for SELinux. -
7. Support for pid-limits
Before you talk about pid-limits, you need to talk about what a fork bomb is. A fork bomb creates a large number of processes at a very fast speed, which consumes the available space allocated by the system to the process, saturates the process table, and prevents the system from running new programs.When it comes to process limit, you probably know that ulimit's nproc configuration has pits. Unlike other ulimit options, nproc is a user-managed setup option that adjusts the maximum number of processes that belong to a user's UID.This section will be introduced in the next section.Docker since 1.10 supports specifying - pids-limit for containers to limit the number of processes in a container, which can be used to limit the number of processes in a container. -
8. Other Kernel Security Features Tool Support
Around the container ecology, there are many tools that can support container security, such as the Docker bench audit tool. https://github.com/docker/docker-bench-security) Check your Docker runtime using Sysdig Falco (Tool Address: https://sysdig.com/opensource/falco/) To detect abnormal activity inside the container, GRSEC and PAX can be used to strengthen the system core, and so on.
Linux Kernel Capability Capability Capability Limitations
1.Capabilities simply means the permissions that are open to processes, such as allowing them to access the network, read files, and so on.The Docker container is essentially a process, and by default, Docker deletes all Capabilities except those that are required, and you can see a complete list of available Capabilities in the Linux manual page.Docker version 0.6 later supports adding the - privileged option to the startup parameters to open super permissions for containers.
2.Docker support for Capabilities is important for container security because we often run as root users in containers, and with Capability restrictions, the root in the container has much fewer privileges than the real root user.This means that even if an intruder manages to gain root privileges in a container, it will be difficult to severely destroy or gain host root privileges.
When we specify the - privileded option in docker run, Docker actually does two things:
1. Obtain all capabilities of the system root user and assign them to the container;
2. Scan all device files of the host machine and mount them in containers.
Understanding docker security
- The security of Docker containers depends largely on the Linux system itself. When evaluating the security of Docker, the following main considerations are considered:
1. Container isolation security provided by the namespace mechanism of the Linux kernel
2. The Linux control group mechanism is safe to control container resources.
3. Operational privilege security brought about by the capability mechanism of the Linux kernel
4. The resistance of the Docker program itself, especially the server.
5. The impact of other security enhancements on container security.
Namespace Isolated Security
- When docker run starts a container, Docker creates a separate namespace for the container in the background.Namespaces provide the most basic and direct isolation.
- Isolation through Linux namespace is less thorough than the virtual machine approach.
- Containers are only a special process running on the host machine, so multiple containers use the same host's operating system kernel.
- There are many resources and objects in the Linux kernel that cannot be Namespace d, such as time.
Security of Control Group Resource Control
- When docker run starts a container, Docker creates a separate set of control group policies for the container in the background.
- Linux Cgroups provide a number of useful features to ensure that containers fairly share the host's memory, CPU, disk IO, and other resources.
- Ensure that resource pressures occurring within containers do not affect the local host system and other containers and are essential to prevent denial of service attacks (DDoS).
Kernel Capability Mechanisms
- Capability is a powerful feature of the Linux kernel that provides fine-grained access control.
- In most cases, containers do not require "real" root privileges; they only require a few capabilities.
- By default, Docker uses a whitelist mechanism to disable permissions other than Required Features.
Docker Server Protection
- The core of using the Docker container is the Docker server, which ensures that only trusted users can access the Docker service.
- Mapping the root user of a container to a non-root user on the local host alleviates security issues caused by elevated permissions between the container and the host.
- Allows the Docker server to run under non-root privileges, using secure and reliable subprocesses to proxy operations that require privileged privileges.These sub-processes only allow operations within a specific range.
Other security features
- Enabling GRSEC and PAX in the kernel adds more security checks at compile and run time, and avoids malicious detection through address randomization.Enabling this feature does not require any configuration by Docker.
- Use some container templates with enhanced security features.
- Users can customize security policies by customizing stricter access control mechanisms.
- When a file system is mounted inside a container, you can configure a read-only mode to prevent applications inside the container from damaging the external environment through the file system, especially directories related to the operating state of some systems.
Container Resource Control
- The full name of Linux Cgroups is the Linux Control Group.Is the upper limit of resources that a group of processes can use, including CPU, memory, disk, network bandwidth, and so on.Prioritize, audit, and suspend and resume processes.
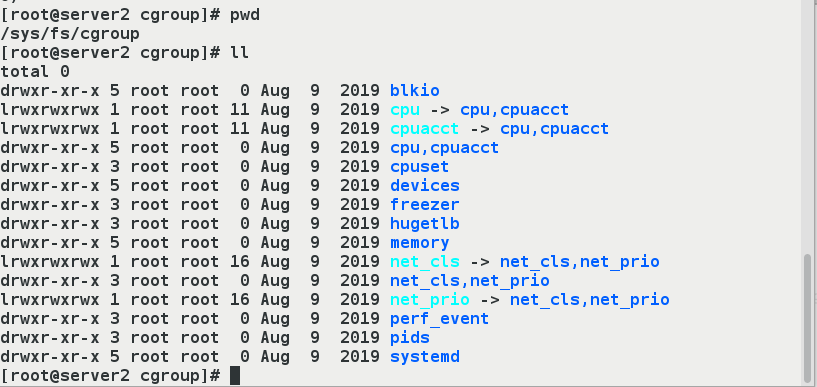
- The operating interface exposed to users by Linux Cgroups is the file system.It is organized in files and directories under the / sys/fs/cgroup path of the operating system.Execute this command to see: mount -t cgroup.
- Under /sys/fs/cgroup, there are many subdirectories, called subsystems, such as cpuset, cpu, memory.Under each subsystem, create a control group (that is, create a new directory) for each container.What values are filled in in the resource file below the control group is specified by the parameters that the user performs the docker run.
CPU bound
- Open the docker and monitor if the cgroup is turned on.(all on means on)
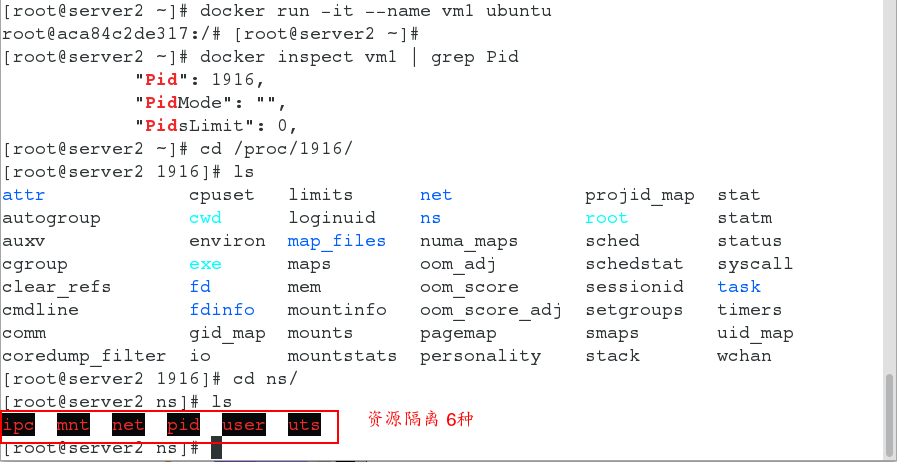
[root@server2 ns]# systemctl start docker [root@server2 ns]# mount -t cgroup cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)

- View hierarchical paths to the cgroup subsystem
- Establish a CPU control population
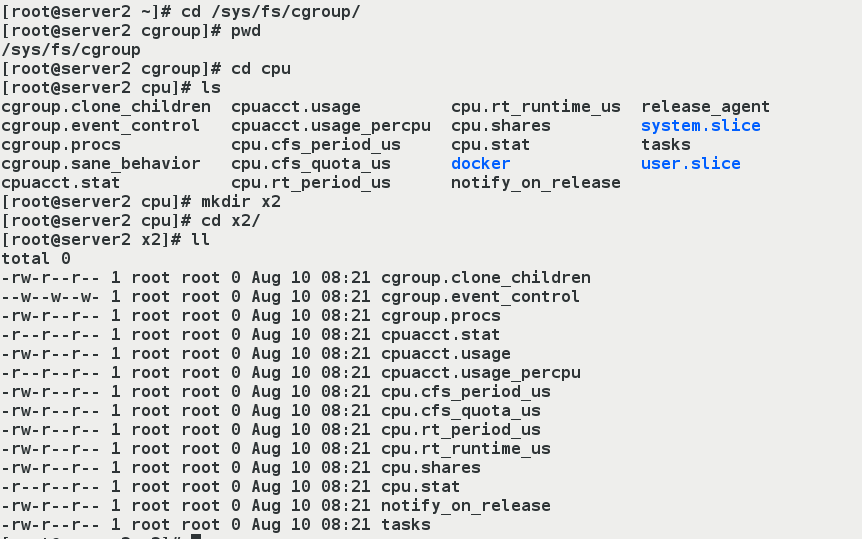
First enter the corresponding hierarchical path of the CPU subsystem: cd/sys/fs/cgroup/cpu
Create a cpu control group by creating a new folder: mkdir x2, that is, create a new cpu control group: x2
After creating the new x2, you can see that the related files are automatically created in the directory, which are pseudo files
[root@server2 ~]# cd /sys/fs/cgroup/ [root@server2 cgroup]# pwd /sys/fs/cgroup [root@server2 cgroup]# cd cpu [root@server2 cpu]# ls cgroup.clone_children cpuacct.usage cpu.rt_runtime_us release_agent cgroup.event_control cpuacct.usage_percpu cpu.shares system.slice cgroup.procs cpu.cfs_period_us cpu.stat tasks cgroup.sane_behavior cpu.cfs_quota_us docker user.slice cpuacct.stat cpu.rt_period_us notify_on_release [root@server2 cpu]# mkdir x2 ##New x2 Directory [root@server2 cpu]# cd x2/ [root@server2 x2]# ll #Automatically generate related files in directory
- (4) Test restrictions on cpu usage
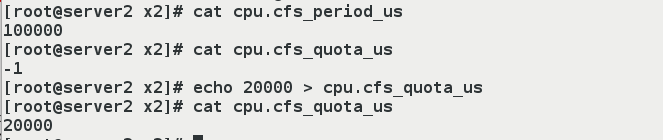
Our test example is mainly used in two files, cpu.cfs_period_us and cpu.cfs_quota_us.
cpu.cfs_period_us: The period (microseconds) allocated by the cpu, defaulting to 100000.
cpu.cfs_quota_us: Indicates that the control group limits the time consumed (in microseconds) by default to -1, indicating no limit.
If set to 2000, it represents 20,000/100,000 = 20% CPU.
[root@server2 x2]# cat cpu.cfs_period_us 100000 [root@server2 x2]# cat cpu.cfs_quota_us ##Default is -1, meaning unlimited -1 [root@server2 x2]# echo 20000 > cpu.cfs_quota_us ##Modification occupancy is 20% [root@server2 x2]# cat cpu.cfs_quota_us 20000
- (5) Testing
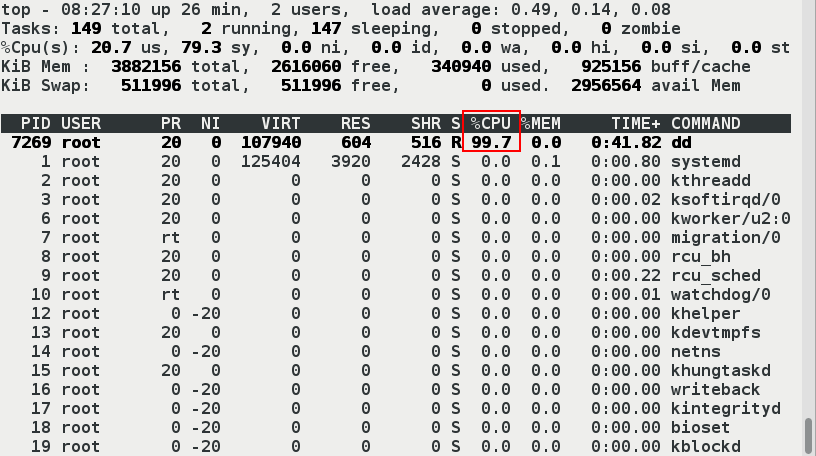
[root@server2 x2]# dd if=/dev/zero of=/dev/null & ##Open the task.Get in the background and use the [top] command to view 100% of the view [1] 7269
- (6) Create a container and limit the use of cpu
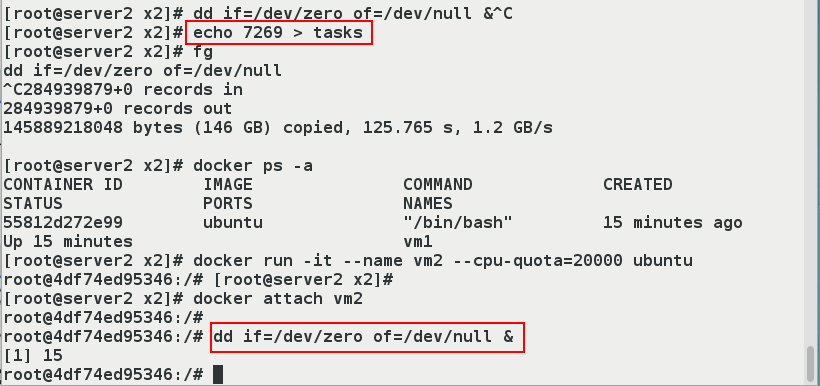
[root@server2 x2]# echo 7269 > tasks #dd's process number [root@server2 x2]# fg dd if=/dev/zero of=/dev/null ^C284939879+0 records in 284939879+0 records out 145889218048 bytes (146 GB) copied, 125.765 s, 1.2 GB/s [root@server2 x2]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 55812d272e99 ubuntu "/bin/bash" 15 minutes ago Up 15 minutes vm1 [root@server2 x2]# docker run -it --name vm2 --cpu-quota=20000 ubuntu root@4df74ed95346:/# [root@server2 x2]# [root@server2 x2]# docker attach vm2 root@4df74ed95346:/# dd if=/dev/zero of=/dev/null & [1] 15
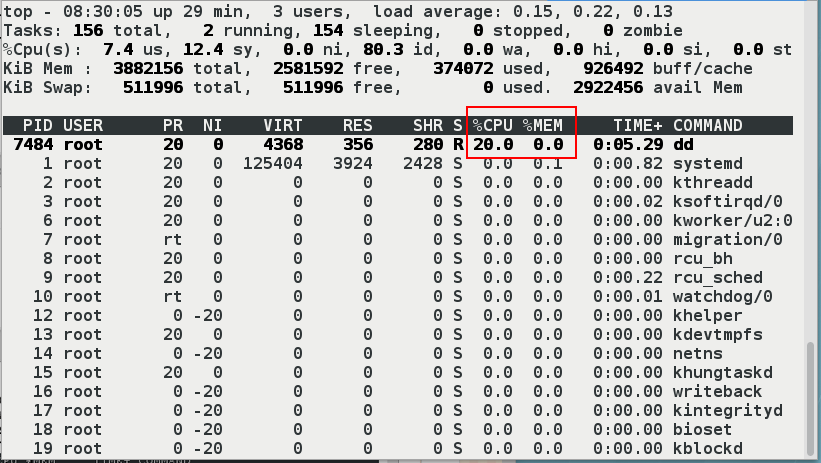
- Open another shell to see top > CPU usage 20%
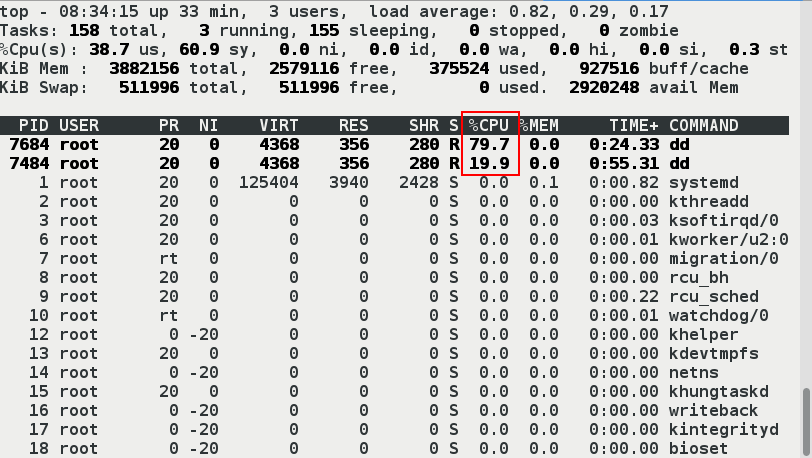
If you create containers without restrictions, the occupancy will be 100%
[root@server2 x2]# docker run -it --name vm3 ubuntu root@33da6039575f:/# dd if=/dev/zero of=/dev/null
Memory Limit
Example:
Container available memory consists of two parts: physical memory and swap swap partition.
docker run -it --memory 200M --memory-swap=200M ubuntu
- memory sets the memory usage limit
- memory-swap sets swap exchange partition limit
- The specific process is as follows:
(1) Install cgroup, which provides cgexec commands.
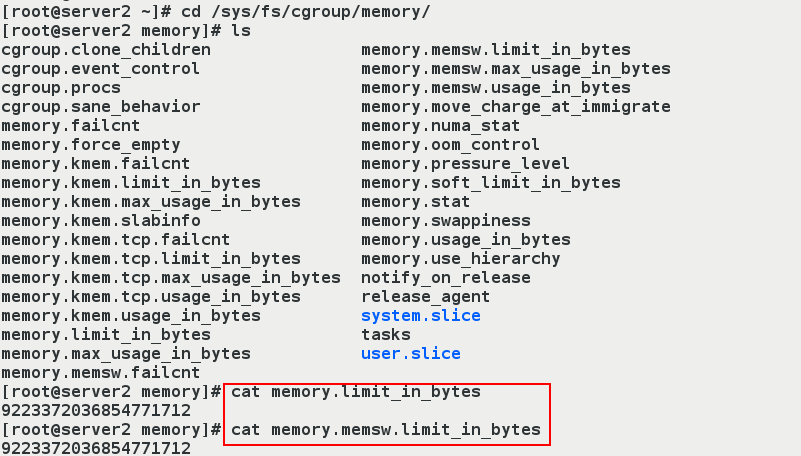
[root@server2 ~]# yum install libcgroup-tools -y [root@server2 ~]# cd /sys/fs/cgroup/memory/ [root@erver2 memory]# ls [root@server2 memory]# cat memory.limit_in_bytes 9223372036854771712 #The number is too large to be equal to unlimited. [root@server2 memory]# cat memory.memsw.limit_in_bytes 9223372036854771712
- (2) Set resource limit parameters: Memory + Swap Partition <=300M
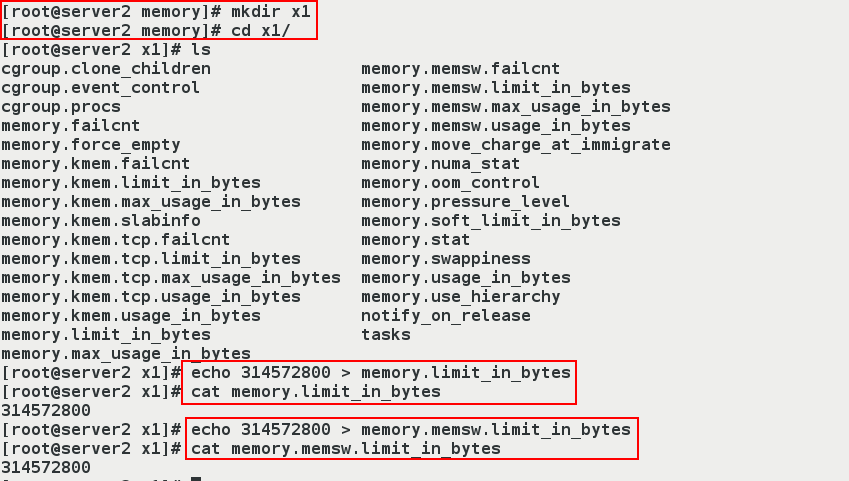
[root@server1 ~]# cd /sys/fs/cgroup/memory/ [root@server1 memory]# mkdir ##snow Create directory snow,The name of the directory is given at will. ##stay/sys/fs/cgroup/memory Directory Created,automatic succession/sys/fs/cgroup/memory Contents in the directory.The purpose of creating this directory is to(1)To demonstrate how a container works.Because once the container is run,Will be in this directory,Generate a docker Catalog, docker Containers are generated in the directory ID Corresponding directory,In directory memory Content under directory inherits from/sys/fs/cgroup/memeory Contents under the directory. ##(2) Direct modification of the contents of files in/sys/fs/cgroup/memory will result in errors. [root@server1 memory]# echo 209715200 > memory.limit_in_bytes -bash: echo: write error: Invalid argument [root@server1 memory]# cd snow/ [root@server1 snow]# echo 209715200 > memory.limit_in_bytes #Set the maximum memory usage to 200M(209715200=200*1024*1024).209715200 is in BB) [root@server1 snow]# echo 209715200 > memory.memsw.limit_in_bytes #Because the maximum amount of memory consumed is the same as the maximum amount of memory consumed by the swap partition.Indicates that the maximum available memory is 200M and the available swap is 0M.That is, limited memory + swap partition <=200M [root@server1 snow]# cat memory.limit_in_bytes 209715200 [root@server1 snow]# cat memory.memsw.limit_in_bytes 209715200 //Value note: Files in the / sys/fs/cgroup/memory directory cannot be edited with vim, edited with vim, and cannot be saved out (even with "wq!", exit cannot be saved.)
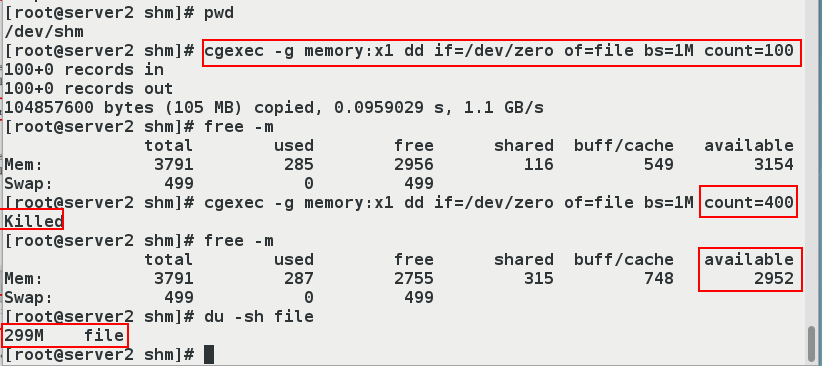
- Now available memory is 300M, test:
[root@server2 shm]# pwd
/dev/shm
[root@server2 shm]# cgexec -g memory:x1 dd if=/dev/zero of=file bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 0.0959029 s, 1.1 GB/s
[root@server2 shm]# free -m
total used free shared buff/cache available
Mem: 3791 285 2956 116 549 3154 #We found that there is less than 100M of available memory
Swap: 499 0 499
[root@server2 shm]# cgexec -g memory:x1 dd if=/dev/zero of=file bs=1M count=400 #Because the specified file size exceeds the limit of 400M, Killed is displayed, which is the limit we previously set for directories, which can only take up to 300M
Killed
[root@server2 shm]# free -m
total used free shared buff/cache available
Mem: 3791 287 2755 315 748 2952
Swap: 499 0 499
[root@server2 shm]# du -sh file
299M file

- Note: If memory and swap partitions are not restricted, the contents in the / sys/fs/cgroup/memory/memory.limit_in_bytes and/sys/fs/cgroup/memory/memory.memsw.limit_in_bytes files will not be modified.The dd command will always succeed regardless of the size of the bigfile to be generated.
- If you restrict memory only (limited to 200M) without restricting the swap f partition, you modify only the contents in the / sys/fs/cgroup/memory/memory.limit_in_bytes file, not the contents in the / sys/fs/cgroup/memory/memory.memsw.limit_in_bytes file.The dd command will succeed if the size of the bigfile to be generated is greater than 200M, but only 200M is from memory and the rest is from the swap partition.
- (1) Specify the size of memory and swap partitions, run containers
[root@server2 ~]# docker run -it --name vm1 --memory 104857600 --memory-swap 104857600 ubuntu root@55812d272e99:/# [root@server2 ~]# ##Run container vm1 using ubuntu mirror, specifying memory + swap partition <100M.And exit with Ctrl+p+q, that is, don't let the container stop.

- Check to see if the settings are valid.
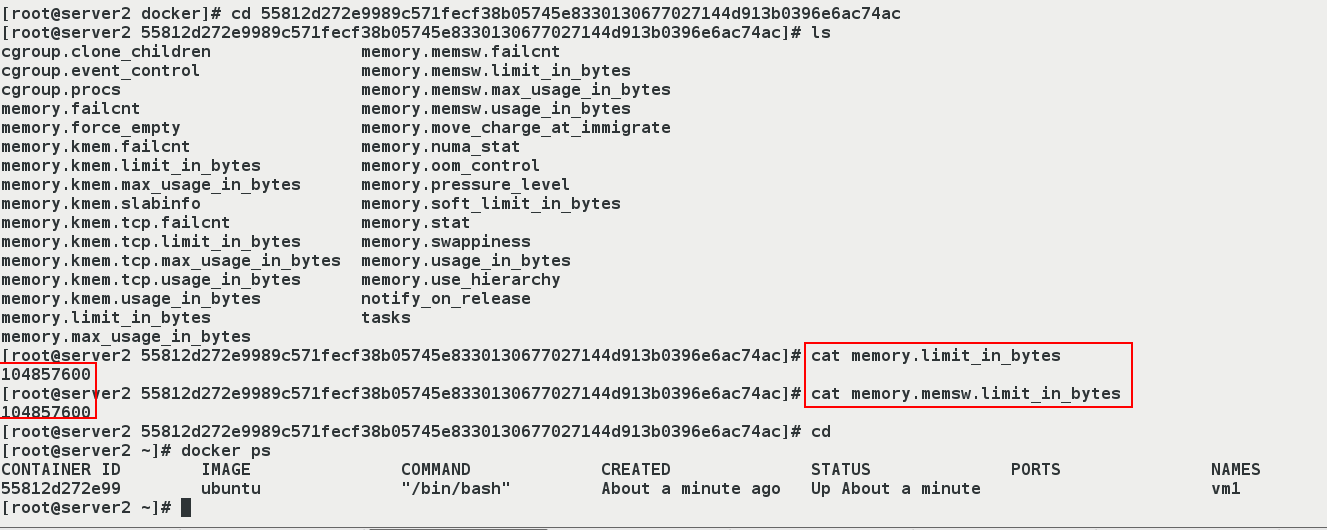
[root@server2 ~]# cd /sys/fs/cgroup/memory/docker/ [root@server2 docker]# ls [root@server2 docker]# cd 55812d272e9989c571fecf38b05745e8330130677027144d913b0396e6ac74ac [root@server2 55812d272e9989c571fecf38b05745e8330130677027144d913b0396e6ac74ac]# ls
- The above string is the size of the memory and swap partition we see matches the size we set. Let's confirm the container ID to make sure we look at the container we're running
- Note for value: Container isolation is not good
So what you see inside a container using the command "free-m" is the same as what you see on the host using the command "free-m"
So if you want to see if the restriction is successful, you need to go into the directory corresponding to the container to see it
[root@server2 55812d272e9989c571fecf38b05745e8330130677027144d913b0396e6ac74ac]# cat memory.limit_in_bytes 104857600 [root@server2 55812d272e9989c571fecf38b05745e8330130677027144d913b0396e6ac74ac]# cat memory.memsw.limit_in_bytes 104857600 [root@server2 55812d272e9989c571fecf38b05745e8330130677027144d913b0396e6ac74ac]# cd [root@server2 ~]# docker ps
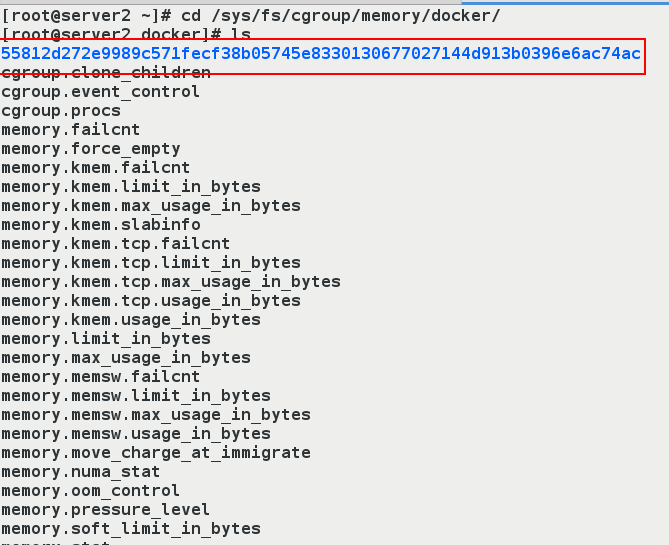
- The above string is the size of the memory and swap partition we see matches the size we set. Let's confirm the container ID to make sure we look at the container we're running
Block IO Restrictions
docker run -it --device-write-bps /dev/sda:30MB ubuntu - device-write-bps Restricts the BPS of write devices Current block IO restrictions are only valid for direct IO (file system caching cannot be used)
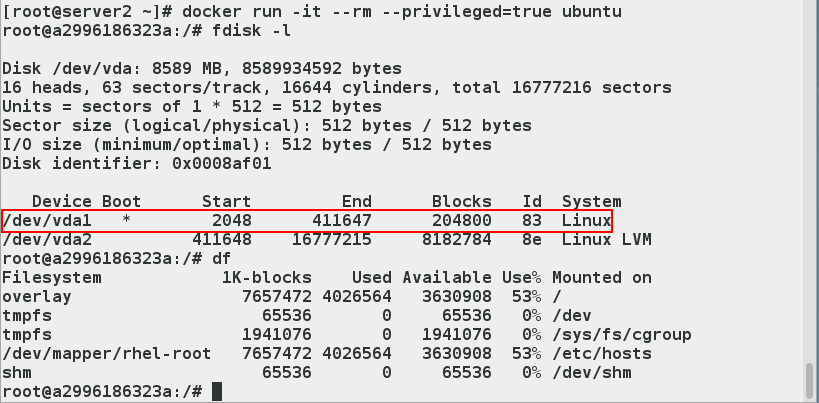
- (1) First you can look at the partition to determine where to write
[root@server2 ~]# docker run -it --rm --privileged=true ubuntu root@a2996186323a:/# fdisk -l Disk /dev/vda: 8589 MB, 8589934592 bytes 16 heads, 63 sectors/track, 16644 cylinders, total 16777216 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x0008af01 Device Boot Start End Blocks Id System /dev/vda1 * 2048 411647 204800 83 Linux /dev/vda2 411648 16777215 8182784 8e Linux LVM
- (2) Create new containers for testing
[root@server2 ~]# docker run -it --rm --device-write-bps /dev/vda:30M ubuntu root@860272c843f0:/# dd if=/dev/zero of=file bs=1M count=300 oflag=direct 300+0 records in 300+0 records out 314572800 bytes (315 MB) copied, 10.355 s, 30.4 MB/s #It takes about 10s root@860272c843f0:/# dd if=/dev/zero of=file bs=1M count=300 300+0 records in 300+0 records out 314572800 bytes (315 MB) copied, 0.337771 s, 931 MB/s #Less than 1s usage
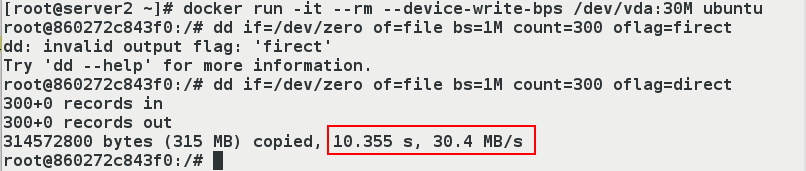
- As can be seen from the figure above, our limitation on container IO works, as to why the second write was so fast during the demonstration operation
This depends on the parameter [oflag=direct], which means: read and write data using direct IO