Articles have been included in Github.com/niumoo/JavaNotes Welcome to Star and Instructions.
Welcome to my attention Public Number , articles are updated weekly.
The previous article introduced the HashMap source code, which was very popular. Many students expressed their opinions. This time it came again. This time it is ConcurrentHashMap. As a thread-safe HashMap, it is also used frequently.So what is its storage structure and how does it work?
1. ConcurrentHashMap 1.7
1. Storage structure
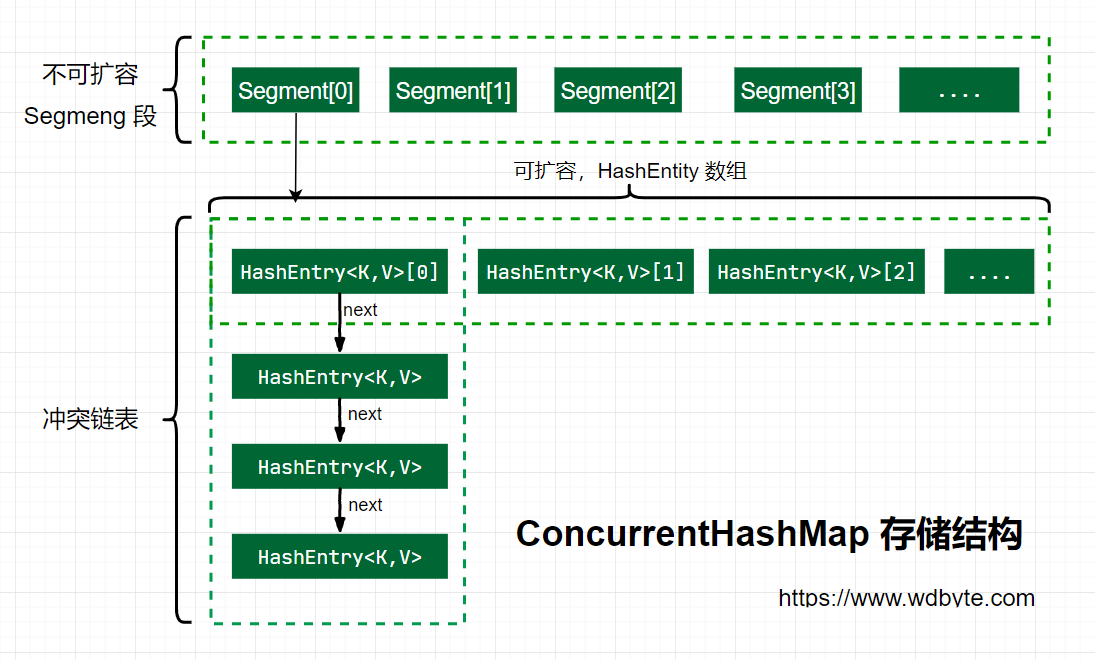
The storage structure of ConcurrentHashMap in Java 7 is illustrated above. ConcurrnetHashMap is composed of several Segments, and each Segment is a HashMap-like structure, so the interior of each HashMap can be expanded.However, once initialized, the number of Segments cannot be changed. The default number of Segments is 16. You can also assume that ConcurrentHashMap supports up to 16 threads of concurrency by default.
2. Initialization
Explore the initialization process of ConcurrentHashMap through its parameterless construction.
/** * Creates a new, empty map with a default initial capacity (16), * load factor (0.75) and concurrencyLevel (16). */ public ConcurrentHashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); }
A parameterized construct is called in a parameterized construct, passing in the default values of three parameters whose values are.
/** * Default Initialization Capacity */ static final int DEFAULT_INITIAL_CAPACITY = 16; /** * Default Load Factor */ static final float DEFAULT_LOAD_FACTOR = 0.75f; /** * Default Concurrency Level */ static final int DEFAULT_CONCURRENCY_LEVEL = 16;
Next, look at the internal implementation logic of this parametric constructor.
@SuppressWarnings("unchecked") public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) { // Parameter Check if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); // Check concurrency level size, greater than 1< < 16, reset to 65536 if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; // Find power-of-two sizes best matching arguments // How much power of 2 int sshift = 0; int ssize = 1; // This loop finds the second most recent value of 2 above concurrencyLevel while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1; } // Record Segment Offset this.segmentShift = 32 - sshift; // Record Segment Mask this.segmentMask = ssize - 1; // Set capacity if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; // c = capacity / ssize, default 16 / 16 = 1, here is the calculation of HashMap-like capacity in each Segment int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; //Capacity similar to HashMap in Segment s is at least a multiple of 2 or 2 while (cap < c) cap <<= 1; // create segments and segments[0] // Create an array of segments, set segments[0] Segment<k,v> s0 = new Segment<k,v>(loadFactor, (int)(cap * loadFactor), (HashEntry<k,v>[])new HashEntry[cap]); Segment<k,v>[] ss = (Segment<k,v>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] this.segments = ss; }
Summarize the initialization logic for ConcurrnetHashMap in Java 7.
- Required parameter checks.
- Check concurrency level concurrencyLevel size and reset to maximum if greater than maximum.The default value for tragic construction is 16.
- Find the power value of the nearest 2 above concurrencyLevel for the initial capacity size, which defaults to 16.
- Record the segmentShift offset, which is the N in Capacity = 2 to the N power and is used to calculate the position later in Put.The default is 32 - sshift = 28.
- Record segmentMask, default is ssize-1 = 16-1 = 15.
- Initialize segments[0], default size is 2, load factor is 0.75, expansion threshold is 2*0.75=1.5, the second value is inserted for expansion.
3. put
Next, the above initialization parameters continue to look at the put method source.
/** * Maps the specified key to the specified value in this table. * Neither the key nor the value can be null. * * <p> The value can be retrieved by calling the <tt>get</tt> method * with a key that is equal to the original key. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with <tt>key</tt>, or * <tt>null</tt> if there was no mapping for <tt>key</tt> * @throws NullPointerException if the specified key or value is null */ public V put(K key, V value) { Segment<k,v> s; if (value == null) throw new NullPointerException(); int hash = hash(key); // hash value is unsigned right-shifted 28 bits (obtained at initialization), then runs and runs with segmentMask=15 // In fact, it's about running and running a high 4-bit segmentMask (1111) int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<k,v>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment // Initialize if the found Segment is empty s = ensureSegment(j); return s.put(key, hash, value, false); } /** * Returns the segment for the given index, creating it and * recording in segment table (via CAS) if not already present. * * @param k the index * @return the segment */ @SuppressWarnings("unchecked") private Segment<k,v> ensureSegment(int k) { final Segment<k,v>[] ss = this.segments; long u = (k << SSHIFT) + SBASE; // raw offset Segment<k,v> seg; // Determine if Segment at u is null if ((seg = (Segment<k,v>)UNSAFE.getObjectVolatile(ss, u)) == null) { Segment<k,v> proto = ss[0]; // use segment 0 as prototype // Get HashEntry<k, v>Initialization Length in segment 0 int cap = proto.table.length; // Gets the expanded load factor from the hash table in segment 0, and all segments have the same loadFactor float lf = proto.loadFactor; // Calculate Expansion Threshold int threshold = (int)(cap * lf); // Create a HashEntry array of cap capacity HashEntry<k,v>[] tab = (HashEntry<k,v>[])new HashEntry[cap]; if ((seg = (Segment<k,v>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck // Check again if the Segment at the u location is null, as there may be other threads working on it Segment<k,v> s = new Segment<k,v>(lf, threshold, tab); // Spin checks if the Segment at the u position is null while ((seg = (Segment<k,v>)UNSAFE.getObjectVolatile(ss, u)) == null) { // Assignment using CAS will only succeed once if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) break; } } } return seg; }
The source code above analyzed the process of ConcurrentHashMap when put ting a data, and the following combs the specific process.
-
Calculate the location of the key to put and get the Segment at the specified location.
-
Initialize the Segment if the Segment at the specified location is empty.
Initialize Segment process:
- Check that the calculated Segment is null.
- To continue initializing for null, create a HashEntry array using the capacity and load factor of Segment[0].
- Check again if the calculated Segment at the specified location is null.
- Initialize this Segment using the created HashEntry array.
- Spin determines if the calculated Segment at the specified location is null, and CAS is used to assign the Segment at that location.
-
Segment.put Insert key,value value.
The above explores the operations for getting and initializing Segments.The put method for the last line of Segments has not been reviewed yet, so continue with the analysis.
final V put(K key, int hash, V value, boolean onlyIfAbsent) { // Acquire ReentrantLock exclusive lock, not scanAndLockForPut. HashEntry<k,v> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<k,v>[] tab = table; // Calculate the data location to put int index = (tab.length - 1) & hash; // CAS Gets the value of the index coordinate HashEntry<k,v> first = entryAt(tab, index); for (HashEntry<k,v> e = first;;) { if (e != null) { // Check to see if the key already exists, if so, traverse the list to find the location, and replace the value after finding it K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { // The first value does not indicate that the index position already has a value, there is a conflict, chain header interpolation. if (node != null) node.setNext(first); else node = new HashEntry<k,v>(hash, key, value, first); int c = count + 1; // Capacity greater than expansion threshold, smaller than maximum capacity, to expand if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else // The index position assigns a node, which may be an element or a chain table header setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; }
Since Segments inherit ReentrantLock, it is easy to obtain locks within Segments, which is used by the put process.
-
tryLock() acquires the lock, but cannot continue to acquire it using the scanAndLockForPut method.
-
Calculate the index location where the put data will be placed and get the HashEntry at that location.
-
Why traverse put new elements?Because the HashEntry obtained here may be an empty element or the chain table already exists, treat it differently.
If HashEntry does not exist at this location:
- If the current capacity is greater than the expansion threshold and less than the maximum capacity, the capacity is expanded.
- Direct head insertion.
If HashEntry exists at this location:
- Determines if the key and hash values of the current elements in the list are consistent with the key and hash values to be put.Consistency Replace Value
- Inconsistent, get the next node in the list until you find the same value to replace, or the list is not identical at all.
- If the current capacity is greater than the expansion threshold and less than the maximum capacity, the capacity is expanded.
- Direct chain header insertion.
-
If the location you want to insert already exists before, return the old value after replacement, otherwise return null.
The scanAndLockForPut operation in the first step above is not described here, and what this method does is continuously spin tryLock() to acquire a lock.lock() is used to block acquisition of locks when the number of spins is greater than the specified number.HashEntry to get the lower hash position in the table while spinning.
private HashEntry<k,v> scanAndLockForPut(K key, int hash, V value) { HashEntry<k,v> first = entryForHash(this, hash); HashEntry<k,v> e = first; HashEntry<k,v> node = null; int retries = -1; // negative while locating node // Spin Acquisition Lock while (!tryLock()) { HashEntry<k,v> f; // to recheck first below if (retries < 0) { if (e == null) { if (node == null) // speculatively create node node = new HashEntry<k,v>(hash, key, value, null); retries = 0; } else if (key.equals(e.key)) retries = 0; else e = e.next; } else if (++retries > MAX_SCAN_RETRIES) { // Once the spin has reached the specified number of times, blocking waits until locks are acquired lock(); break; } else if ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) { e = first = f; // re-traverse if entry changed retries = -1; } } return node; }
4. Expand rehash
ConcurrentHashMap will only grow twice as large.When the data in the old array is moved to the new array, the position either remains the same or changes to index+ oldSize, and the node in the parameter is inserted into the specified position using the chain header interpolation after expansion.
private void rehash(HashEntry<k,v> node) { HashEntry<k,v>[] oldTable = table; // Old capacity int oldCapacity = oldTable.length; // New capacity, double expansion int newCapacity = oldCapacity << 1; // New Expansion Threshold threshold = (int)(newCapacity * loadFactor); // Create a new array HashEntry<k,v>[] newTable = (HashEntry<k,v>[]) new HashEntry[newCapacity]; // New mask, default 2 expands to 4, -1 to 3, and binary to 11. int sizeMask = newCapacity - 1; for (int i = 0; i < oldCapacity ; i++) { // Traversing through old arrays HashEntry<k,v> e = oldTable[i]; if (e != null) { HashEntry<k,v> next = e.next; // Calculate new locations, new locations may only be inconvenient or old locations + old capacity. int idx = e.hash & sizeMask; if (next == null) // Single node on list // If the current position is not a list, but an element, assign the value directly newTable[idx] = e; else { // Reuse consecutive sequence at same slot // If it's a chain list HashEntry<k,v> lastRun = e; int lastIdx = idx; // The new location may only be inconvenient or old + old capacity. // After traversal, the elements behind lastRun are all in the same position for (HashEntry<k,v> last = next; last != null; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } // , the element locations behind lastRun are the same, assigning directly to the new location as a list of chains. newTable[lastIdx] = lastRun; // Clone remaining nodes for (HashEntry<k,v> p = e; p != lastRun; p = p.next) { // Traverses through the remaining elements and interpolates the header to the specified k position. V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry<k,v> n = newTable[k]; newTable[k] = new HashEntry<k,v>(h, p.key, v, n); } } } } // Head Interpolation to Insert New Nodes int nodeIndex = node.hash & sizeMask; // add the new node node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; }
Some students may be confused about the last two for loops. The first for here is to find a node whose new location is the same for all the next nodes behind it.Then assign this to the new location as a list of chains.The second for loop is to insert the remaining elements into the list of specified locations by header insertion.The reason for this may be based on probability statistics, where students with in-depth research can make comments.
5. get
It's easy to get here. The get method only takes two steps.
- Calculate the storage location of the key.
- Traverses the specified location to find the value of the same key.
public V get(Object key) { Segment<k,v> s; // manually integrate access methods to reduce overhead HashEntry<k,v>[] tab; int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; // Calculate where to store the key if ((s = (Segment<k,v>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry<k,v> e = (HashEntry<k,v>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { // If it is a linked list, traverse to find the value of the same key. K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; }
2. ConcurrentHashMap 1.8
1. Storage structure
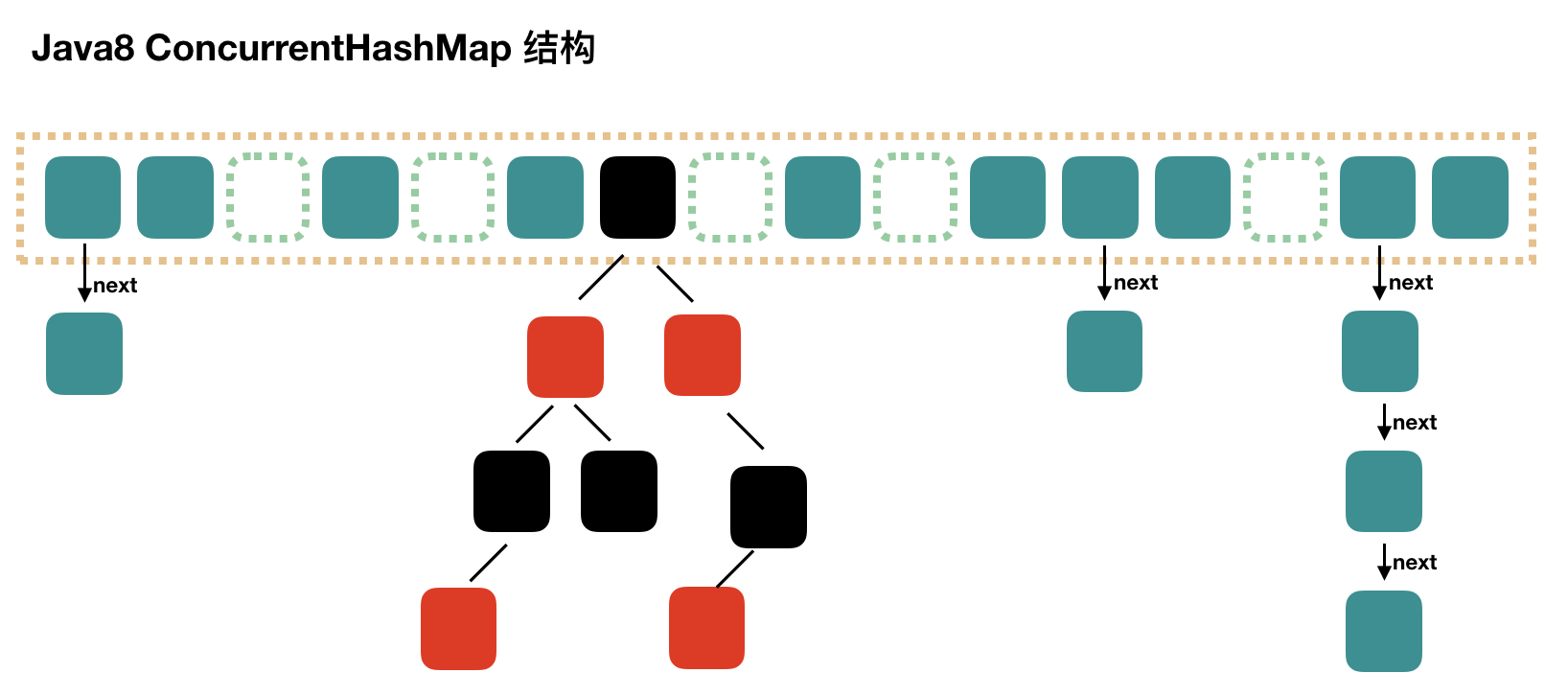
You can see that the ConcurrentHashMap for Java8 has changed a lot compared to Java7, not the previous egment array + HashEntry array + Chain list, but the Node array + chain list / red-black tree.When the conflict chain is expressed to a certain length, the chain list is converted to a red-black tree.
2. Initialize initTable
/** * Initializes table, using the size recorded in sizeCtl. */ private final Node<k,v>[] initTable() { Node<k,v>[] tab; int sc; while ((tab = table) == null || tab.length == 0) { // If sizeCtl < 0 ,Describe additional thread execution CAS Successful, initializing. if ((sc = sizeCtl) < 0) // Transfer CPU Usage Thread.yield(); // lost initialization race; just spin else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { try { if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<k,v>[] nt = (Node<k,v>[])new Node<!--?,?-->[n]; table = tab = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; } break; } } return tab; }
From the source code, you can see that the initialization of ConcurrentHashMap is done by spin and CAS operations.It is important to note that the variable sizeCtl, whose value determines the current initialization state.
- -1 indicates initialization is in progress
- -N indicates that N-1 threads are expanding
- Indicates the table initialization size if the table is not initialized
- Indicates the table capacity if the table has already been initialized.
3. put
Pass through the put source directly.
public V put(K key, V value) { return putVal(key, value, false); } /** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { // key and value cannot be empty if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<k,v>[] tab = table;;) { // f = target location element Node<k,v> f; int n, i, fh;// Element hash value holding target position after fh if (tab == null || (n = tab.length) == 0) // Array bucket is empty, initialize array bucket (spin+CAS) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // Empty barrel, CAS put in, no lock, directly break out when successful if (casTabAt(tab, i, null,new Node<k,v>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null; // Use synchronized locking to join nodes synchronized (f) { if (tabAt(tab, i) == f) { // Description is a list of chains if (fh >= 0) { binCount = 1; // Loop in new or overlay nodes for (Node<k,v> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<k,v> pred = e; if ((e = e.next) == null) { pred.next = new Node<k,v>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { // red-black tree Node<k,v> p; binCount = 2; if ((p = ((TreeBin<k,v>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }
-
hashcode is calculated from key.
-
Determine if initialization is required.
-
That is, Node located by the current key, if NULL indicates that the current location can write data, and CAS attempts to write, failures guarantee spin success.
-
If the hashcode == MOVED == -1 at the current location, an expansion is required.
-
If none is satisfied, the synchronized lock is used to write data.
-
If the quantity is greater than TREEIFY_THRESHOLD is converted to a red-black tree.
4. get
The get process is simple and passes directly through the source code.
public V get(Object key) { Node<k,v>[] tab; Node<k,v> e, p; int n, eh; K ek; // hash location where key is located int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { // Head node hash values are the same if the specified location element exists if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) // The key hash values are equal, the key values are the same, returning the element value directly return e.val; } else if (eh < 0) // Head node hash value less than 0, indicating expansion or red-black tree, find return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) { // Is a linked list, traverse search if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }
To summarize the get process:
- Calculate the location based on the hash value.
- Find the specified location, and if the header node is the one to find, return its value directly.
- If the hash value of the header node is less than 0, it means that the tree is expanding or is red-black, look for it.
- If it is a linked list, iterate through the lookup.
Summary:
Overall, ConcruuentHashMap has changed considerably in Java8 compared to Java7.
3. Summary
ConcruuentHashMap uses a segmented lock in Java7, meaning that only one thread can operate on each Segment at the same time, and each Segment is a structure similar to a HashMap array that can be expanded and its conflicts translated into a list of chains.However, the number of segments cannot be changed once they are initialized.
The Synchronized Lock CAS mechanism used by ConcruuentHashMap in Java8.The structure has also evolved from the Segment array + HashEntry array + chain table in Java7 to the Node array + chain list / red-black tree, which is similar to a HashEntry structure.It converts to a red-black tree when the conflict reaches a certain size and returns to the list when the conflict is less than a certain number.
Some students may have questions about the performance of Synchronized lock. In fact, since the introduction of lock upgrade strategy, the performance of Synchronized lock is no longer a problem. Interested students can learn about the lock upgrade of Synchronized by themselves.
Last words
Articles have been included in Github.com/niumoo/JavaNotes Welcome to Star and Instructions.More front-line factory interviews, Java programmers need to master the core knowledge and other articles, also collated a lot of my text, welcome Star and perfect, hope we can become excellent together.
Articles that are helpful and can be clicked "like" or "share" are all supported and I like them!
Articles are updated continuously every week. To keep an eye on my updated articles and shared dry goods in real time, you can focus on the Unread Code Public Number or My Blog.
