| Which course does this assignment belong to | < Fuzhou University 2022 object oriented programming > |
|---|---|
| What are the requirements for this assignment | < 2022 object oriented programming winter vacation assignment 2 > |
| The goal of this assignment | Implement a routing program |
| Job text | as follows |
| Other references | < simple file I/O operation with C + +, OFSTREAM fout, fin >< rookie tutorial - C + + files and streams >< Google open source project style guide - C + + >< windows command line compiling C, C + + program >< vsial studio code compares the difference between two files >< calculation method of CIDR address >< summary of two kinds of recording program running time commonly used in C + + |
preface
After completing the second winter vacation homework, write a summary. It's a strange topic. It's only an algorithm / programming problem in essence, but it's packaged as an engineering project. By the way, some real thoughts. My Github warehouse is here: https://github.com/Gorsonpy/MatchHelper.git
development environment
Language, I choose C++ 11
coding: Visual Studio Community 2022.

check : Visual Studio Code.

Use steps
In this place, I failed to meet the requirements of the topic (command-line operation). Because I can't figure out that the ifstream in C + + needs to specify the file to be opened in the program. How can I open the file again through the command line for input (unless I change the ifstream to the standard input cin)? Perhaps C-style file input and output can achieve this, but my ability is limited, so I can only write an interactive interface first.
- Open the X64\Debug folder.
- Click main Exe (or enter main.exe when entering the same level directory from the command line)
- Enter the file name as prompted
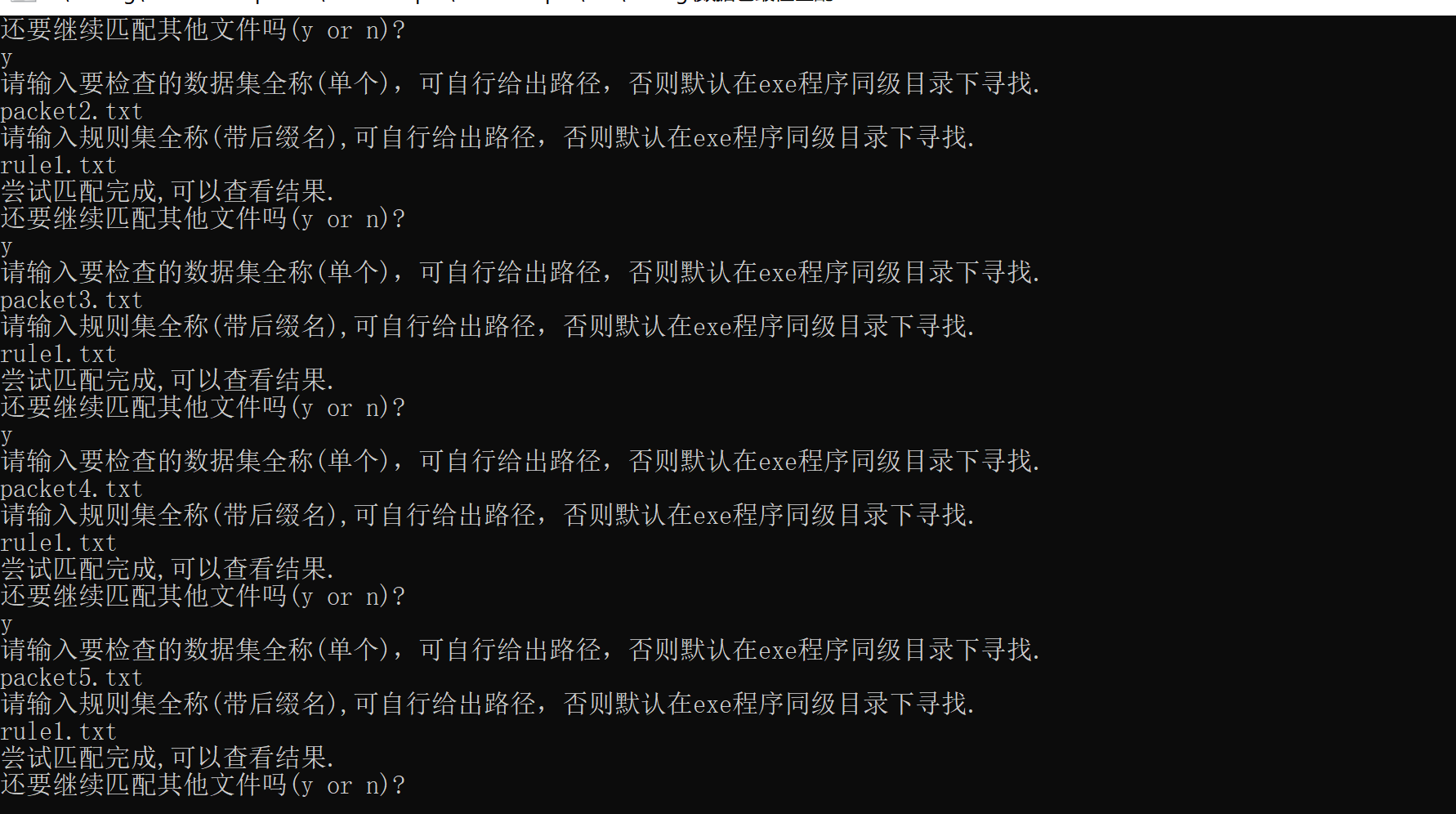
What to learn
File input / output stream
I seldom used it before. I learned a wave first. Here are the tests:
First, test the file output. The code is as follows
#include<iostream>
#Include < fsstream > / / the standard library used to read and write files to the stream
#include<string>
using std::cin;
using std::cout;
using std::string;
using std::ofstream;
using std::ifstream;
using std::endl;
int main()
{
ofstream fout("textOut.dat");
fout << "test: writing sth" << endl;
fout << "second line" << endl;
fout.close();
return 0;
}
Before running the code, an empty text document of textOut is created:

After running, verify the results:
It is worth noting that C + + looks for the range of file names. After consulting the data + my own experiment, I found that:
You can specify the path of the file name or not. If the path is not specified in the test code, you can search under the same level directory of the generated cpp source file (also known as the exe executable file directory, but my test is in the cpp directory). If there is already textOut with the same name, write it. If not, generate a textOut under this path and then write it. If you specify the same path, write it if you find it. If you don't find it, create it first and then write it.
In addition, when the ofstream object opens a file, different write modes can be passed in at the same time (refer to the STL document). If not, the default is to delete the original content after opening the file and write it again.
Retest file input and file output. The logic of file input and file output is similar, so I won't repeat it:

#include<iostream>
#Include < fsstream > / / the standard library used to read and write files to the stream
#include<string>
using std::cin;
using std::cout;
using std::string;
using std::ofstream;
using std::ifstream;
using std::endl;
int main()
{
ifstream fin("textIn.txt");
ofstream fout("textOut.txt");
string data = "test data";
int a, b;
fin >> a >> b;
fout << a + b << endl;
fin.close();
fout.close();
}
Observe text output:

Supplement: after the complete test, it is found that when the IDE "compiles and runs", the default search directory of the file stream is the directory where the cpp file is located, and when the exe file is run separately, the search directory is the directory where the exe file is located.
CIDR address and dotted decimal
One of the worst places to experience. The whole assignment did not mention CIDR, only ip address and dotted decimal. If you search the Internet directly, the conversion rate of ip address will probably overturn, because it is not a set of things. For example, you should find this thing:

However, the address of this job is prefixed with "/ 32", which is the CIDR address.

You have to learn both of them before you can do this homework. Unfortunately, you may not even know the term CIDR without mentioning the homework. Including me, I didn't know it until I asked the senior students:

As a task person, the perspective experience is really poor. Would it be easier to understand if you could provide an example of address conversion in your homework? It won't take much time. If you don't tell me the professional term is CIDR address, it's also easy to query and understand. This thing itself is not difficult, but it takes a lot of time (actually the main time) on it, because if you just search "ip address", you will fall out of the hole, unless it is "ip address with digits" and so on? Just give a conversion example / professional term can save a lot of time. Why not?
Multi file programming
I learned it before and forgot it badly. After reviewing it, the principle of C++Primer is: classes are defined in the header file, functions should be declared in the header file (. h) and source files (. cpp).
Naming conventions
By the way, I learned the following Google naming specifications for C + + projects. I think it is very clever. One thing is that the member variables in C + + classes should be added with '' at the end I found it really wonderful after following it, because it avoids the conflict between the names of formal parameters and class member variables in many functions, and doesn't need to spend a lot of effort on designing names.
Analysis ideas
In fact, there is no idea.
- Each Data is abstracted as a Data class and each Rule is abstracted as a Rule class In fact, it can be implemented with structures here, and it is much simpler, but after all, the course is called "Object-Oriented Programming", and the third round will be based on the second round. In order to enhance reusability, class is selected.
Data.h documents:
#pragma once
#ifndef DATA_H
#include<iostream>
#include<fstream>
#include<string>
#include<vector>
using std::vector;
using std::cout;
using std::endl;
using std::string;
using std::ifstream;
using std::istream;
using std::ostream;
using ll = long long;
class Data
{
ll origin_ip_; //decimal system
ll origin_port_;
ll receiver_ip_; //Decimal storage
ll receiver_port_;
ll tcp_;
public:
friend vector<Data> ReadData(string &file_name);
friend ostream& operator<<(ostream& os, Data& data);
Data() = default;
Data(ll ip1, ll port1, ll ip2, ll port2,
ll tcp) : origin_ip_(ip1), origin_port_(port1), receiver_ip_(ip2),
receiver_port_(port2), tcp_(tcp) {};
ll origin_ip()const { return origin_ip_; }
ll origin_port()const { return origin_port_; }
ll receiver_ip()const { return receiver_ip_; }
ll receiver_port()const { return receiver_port_; }
ll tcp()const { return tcp_; }
};
#endif // DATA_H
ostream& operator<<(ostream& os, Data& data);
vector<Data> ReadData(string &file_name);
Rule.h documents:
#pragma once
#ifndef RULE_H
#include<iostream>
#include<fstream>
#include<string>
#include<vector>
using std::vector;
using std::cout;
using std::endl;
using std::string;
using std::ifstream;
using std::istream;
using std::ostream;
using std::string;
using ll = long long;
class Rule
{
ll origin_ip_beg_;
ll origin_ip_end_;
ll receiver_ip_beg_;
ll receiver_ip_end_;
ll origin_port_beg_;
ll origin_port_end_;
ll receiver_port_beg_;
ll receiver_port_end_;
ll tcp_;
public:
friend vector<Rule> ReadRule(string& file_name);
friend ostream& operator<<(ostream& out, Rule rule);
Rule() = default;
Rule(ll ip1_beg, ll ip1_end, ll ip2_beg, ll ip2_end,
ll port1_beg, ll port1_end,
ll port2_beg, ll port2_end, ll tcp)
: origin_ip_beg_(ip1_beg), origin_ip_end_(ip1_end), receiver_ip_beg_(ip2_beg),
receiver_ip_end_(ip2_end), origin_port_beg_(port1_beg),
origin_port_end_(port1_end), receiver_port_beg_(port2_beg),
receiver_port_end_(port2_end), tcp_(tcp) {}
ll origin_ip_beg()const { return origin_ip_beg_; }
ll origin_ip_end()const { return origin_ip_end_; }
ll receiver_ip_beg()const { return receiver_ip_beg_; }
ll receiver_ip_end()const{ return receiver_ip_end_; }
ll origin_port_beg()const { return origin_port_beg_; }
ll origin_port_end()const { return origin_port_end_; }
ll receiver_port_beg()const { return receiver_port_beg_; }
ll receiver_port_end()const { return receiver_port_end_; }
ll tcp()const { return tcp_; }
};
#endif // !RULE_H
vector<Rule> ReadRule(string& file_name);
Core function header file match_util.h:
#pragma once #ifndef MATCH_UTIL_H #include<vector> #include "Data.h" #include "Rule.h" using std::vector; vector<int32_t> DoMatch(vector<Data> &datalist, vector<Rule> &rulelist); bool check(Data& data, Rule& rule); void Result_In_File(string &file_name, vector<Data> &datalist, vector<Rule> &rulelist, string &packet_name); void EnquireUser(); #endif // !MATCH_UTIL_H
Class functions are redundant. Overloading the "< <" operator has nothing to do with the task. It is simply convenient for you to debug the output information.
-
For file input and output, I use the fstream library, but the experience is very poor. Maybe the C style will be better. I will talk about this in detail below.
-
Implementation of ip address conversion function (ReadRule.cpp).
#include<iostream>
#include<algorithm>
#include<fstream>
#include<string>
#include<algorithm>
#include"Rule.h"
using std::string;
using std::vector;
using std::fstream;
using std::pair;
using ll = long long;
using PII = pair<ll, ll>;
long long qpower(ll a, ll b)
{
ll basic = a, ans = 1;
while (b > 0)
{
if (b & 1)
{
ans *= basic;
}
basic *= basic;
b >>= 1;
}
return ans;
}
PII StrBin_To_Dec(string &str_bin, ll bit) //Convert binary strings to decimal
//Returns a binary of the minimum address ip and the maximum address ip
{
PII min_max;
ll num = 0;
int base = 31; //Benchmark, i.e. the power of 2
for (int i = 0; i < bit; ++i) //The normal before bit is calculated in binary
{
ll curr = 0;
if (str_bin[i] == '1')
{
curr = qpower(2, base);
}
num += curr;
--base;
}
min_max.first = num; //The minimum value is set to 0, without calculation
for (int i = bit; i < str_bin.size(); ++i)
{
//The maximum value is all followed by 1
num += qpower(2, base);
--base;
}
min_max.second = num;
return min_max;
}
string Dec_To_Bin(ll num) //Accepts a number and converts it into a string of eight binary digits
{
string str_bin = "00000000"; //The initial eight bits are set to 0
for (int i = 7; i >= 0; --i)
{
str_bin[i] = num % 2 + 48;
num >>= 1;
}
return str_bin;
}
void TransCidr(string& cidr, int cnt[]) //Divide the cidr address into five decimal parts
// Stored in the incoming array
{
auto iter = cidr.begin();
ll i = 0; //Subscript of array
while (iter != cidr.end()) //Traversal string
{
while (iter != cidr.end() && *iter != '.' && *iter != '/')
{
cnt[i] = 10 * cnt[i] + (*iter) - 48; //Calculate the decimal number size of each part
++iter;
}
//Jumping out of the inner loop means reading '.' Or '/' or end
//If you read to the end, add the last digit
if (*iter == '/')
{
++iter;
while (iter != cidr.end())
{
cnt[4] = 10 * cnt[4] + (*iter) - 48;
++iter;
}
return;
}
else
++iter, ++i;
}
}
vector<Rule> ReadRule(string &file_name)
{
ifstream fin(file_name);
vector<Rule> rulelist;
ll port1_beg = 0, port1_end = 0, port2_beg = 0, port2_end = 0,
tcp = 0;
//The following two ip addresses are separated:
while (!fin.eof() && fin.peek() != EOF)
{
char other = '\0';
fin >> other; //Remove the '@' character at the beginning
if (other == '\0') //Monitor whether it is the last blank line
break;
string cidr1, cidr2; //cidr address
fin >> cidr1 >> cidr2;
int cnt1[5] = { 0, 0, 0, 0, 0 }; //Store the numbers of five parts respectively
int cnt2[5] = { 0, 0, 0, 0, 0};
TransCidr(cidr1, cnt1), TransCidr(cidr2, cnt2); // Separate the five parts of the ip address in cnt1 and cnt2
string str_bin1, str_bin2;
for (int i = 0; i < 4; ++i) //The first four locations are ip information
{
str_bin1 += Dec_To_Bin(cnt1[i]);
}
PII ip1 = StrBin_To_Dec(str_bin1, cnt1[4]);
for (int i = 0; i < 4; ++i)
{
str_bin2 += Dec_To_Bin(cnt2[i]);
}
PII ip2 = StrBin_To_Dec(str_bin2, cnt2[4]);
.... //Port and tcp read in codes are omitted below
}
The general idea is to read in the file -- convert the CIDR address into four eight bit binary strings and separate the bit information -- splice the four strings into a string -- fill 0 (get the minimum address) and 1 (get the maximum address) according to the address bit information -- convert the binary character string into decimal number storage, and then directly compare it with the ip decimal number of the data set
- Matching function, I use a very simple method in this place:
bool check(Data& data, Rule& rule)
{
if (data.origin_ip() < rule.origin_ip_beg() ||
data.origin_ip() > rule.origin_ip_end())
return false;
if (data.receiver_ip() < rule.receiver_ip_beg() ||
data.receiver_ip() > rule.receiver_ip_end())
return false;
if (data.origin_port() < rule.origin_port_beg()
|| data.origin_port() > rule.origin_port_end())
return false;
if (data.receiver_port() < rule.receiver_port_beg()
|| data.receiver_port() > rule.receiver_port_end())
return false;
if (data.tcp() != rule.tcp() && rule.tcp() <= 255)
return false;
return true;
}
vector<int32_t> DoMatch(vector<Data> &datalist, vector<Rule> &rulelist)
{
vector<int32_t> ans;
for (Data& data:datalist)
{
bool tag = true; //Is there a match for the tag
for (size_t i = 0; i < rulelist.size(); ++i)
{
Rule rule = rulelist.at(i);
if (!check(data, rule))
continue;
else
{
int idx = static_cast<int>(i);
ans.push_back(idx);
tag = false;
break;
}
}
if (tag)
ans.push_back(-1);
}
return ans;
}
- The specific codes of other functions can be moved to Github.
Answer check and performance analysis
Time complexity
The main controllable cost should be the matching phase. My approach here is too violent. The inner and outer layers traverse two vector s with a time complexity of $O(n^2)$
Answer check
I use the file content comparison provided in VS Code.
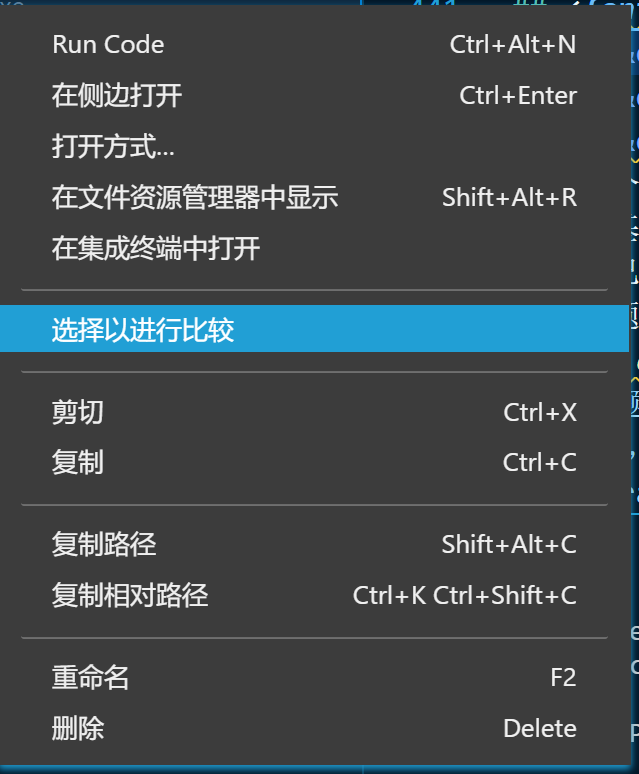
But the output format required by the job is the same as an1 Txt is different!
Operation requirements:

ans1.txt:

This really gives people a bad experience! So we can only follow ANS1 Txt only output the matching position, and then add the output "packet information" after confirming that it is correct
The monitoring interface is as follows, and no error is reported:
Running time statistics
Here I choose time H standard library, checking packet1 The matching time of TXT (the interactive comment should be removed in advance, and the hard coded file name is in the program) code is as follows:
#include<iostream>
#Include < fsstream > / / the standard library used to read and write files to the stream
#include<string>
#include<vector>
#include<time.h>
#include"Data.h"
#include"Rule.h"
#include"match_util.h"
using std::cin;
using std::cout;
using std::string;
using std::endl;
using std::vector;
int main()
{
clock_t beg, end;
beg = clock();
EnquireUser();
beg = clock();
cout << "Total:" << (double)(end - beg) / CLOCKS_PER_SEC << "s" << endl;
system("pause");
return 0;
}
The time results are as follows:

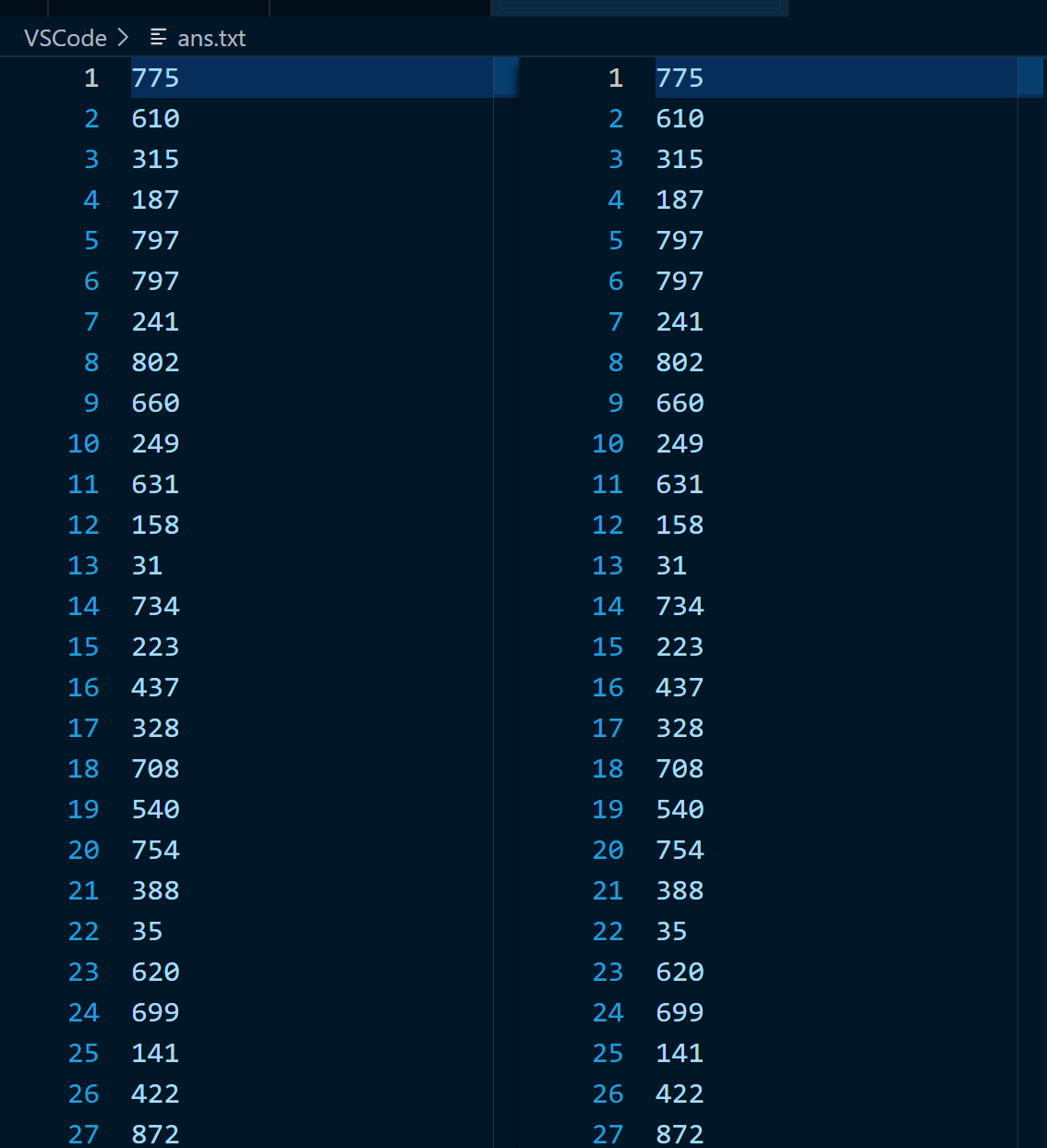
This is the matching time of a data set, so it can be calculated that the time to complete all five data sets is about 4.605s, i.e. 4605ms.
Optimization thinking (not realized)
It can be seen that the matching efficiency is still very low. An optimization method I think of is to use the memory method, and set a space to store the matching answers of the rule set, because observing the sample data set file, we can find that many of them are repeated (exactly the same). If this memory can be successfully realized, those who have calculated the answers before do not need to traverse the rule set, and can O(1) directly give the answers, If the data set size is M, there are R non repetitive rules and the rule set size is N, then the time complexity can be changed from O(MN) to O(RN). Considering the actual situation, there will be many repetitive situations, so the optimization effect should be obvious.
In the end, I failed to implement this optimization scheme, because how to mark to effectively determine whether two pieces of data in the data set are exactly the same is beyond my ability. If you simply add a member variable to the data set to store the answer, and backtrack the calculated rule set to compare whether the ip, port and other information are exactly the same, the inspection process actually makes a traversal, and the time complexity is actually about O(RRN/2) rather than the ideal O(R*N) When the size of non duplicate data set is large and the size of rule set is small, reverse optimization is likely to be made.
Difficulties encountered
-
As mentioned above, the lack of CIDR address concept in the title has made me take a lot of detours.
-
For file input, I have encountered many problems in using fsstream of C++ STL. Sometimes i fstream will read the last blank line more, sometimes it won't, and there is no rule to follow. There are a variety of online search methods, which have no obvious effect. I can only manually mark them to reduce reading errors. I didn't believe that others said C++ STL was disabled before, but now I believe it. It is hard not to doubt whether the implementation of the standard library itself is problematic.
-
Git operation is not very friendly to VS, and it has not been able to add successfully at the beginning Later, I referred to an article to solve it smoothly. < [note] vs2015 "Could not open '***.VC.opendb'" > when using GIT
-
As mentioned above, the final command-line operation settings fail to find out how to implement fsstream. Maybe cin should be used instead of i fstream.
epilogue
My ability is limited and can only be achieved to this extent. I welcome criticism and correction.