1, Foreword
DRQN comes from a paper in 2015. It is an early algorithm, and the content is easy to understand. It is to combine the traditional DQN with LSTM to make the agent have the function of memory, and finally achieved good results. It performs better than DQN in POMDP environment.
Before reading this article, it is assumed that you already know DQN, and you can understand the code of DQN and its operation principle. If you don't know, you can go and have a look https://aistudio.baidu.com/aistudio/projectdetail/2231135 . The code of this article is also modified and implemented directly on its basis.
The following is a link to the original paper. Interested friends can have a look.
- https://readpaper.com/pdf-annotate/note?noteId=614295504096829440
2, Principle
The following mainly discusses the relevant contents according to the paper
1. What is POMDP
First of all, we must know what MDP is. MDP is the abbreviation of Markov decision process. Simply put, the observation observed by the agent is equal to the environment of the environment with which it interacts. The whole environment has no secret to the agent. POMDP corresponds to a partially observable Markov decision-making process. The observation observed by the agent is not equal to the environment. It can only see part of the environment. Generally speaking, MDP is from the perspective of God and POMDP is from the perspective of players.
2. Why consider POMDP
MDP environment is generally simple. For example, in yadali game, DQN infers the complete state of the game by taking the input of four frames as the feature, which makes the environment MDP. However, in real life, the environment conforming to POMDP is the mainstream. The environment faced in real life is usually complex and unpredictable. At this time, it is necessary to consider the performance of agents in POMDP.
3. How to build POMDP through MDP
In this paper, the author transforms the classic table tennis game. By setting a probability parameter, each frame has a certain probability of "being blocked", that is, the picture turns black, so that the agent cannot obtain the required information to build an environment in line with POMDP - flicker table tennis game.
4. How does drqn perform on POMDP
This paper mainly observes the performance of DRQN through flashing table tennis game.
See the effect by visualizing the convolution layer and LSTM layer.
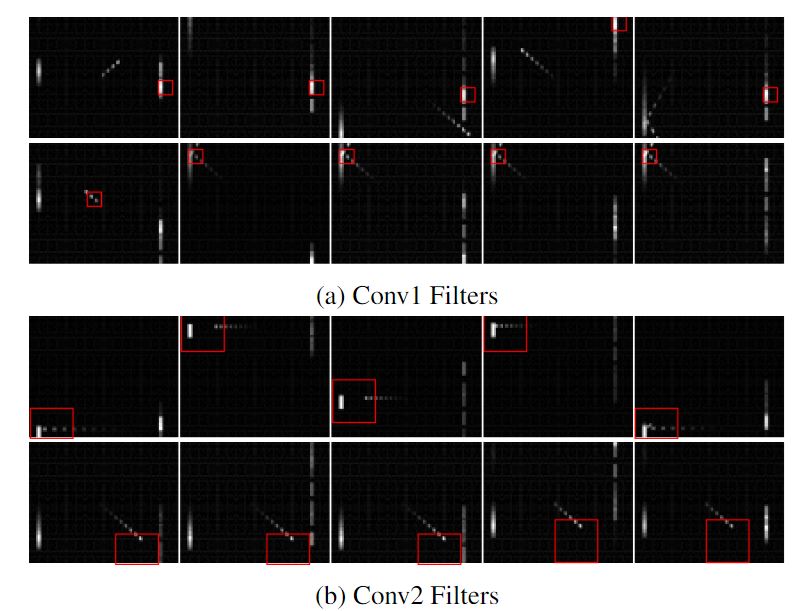

It can be seen that during the game, the model can also detect important events such as ball leakage and reflection. This shows that the performance of DRQN can meet the requirements in POMDP environment.
Even if only one frame is input in each time step, DRQN can complete the task well, which shows that the cyclic neural network can effectively integrate the information between frames and obtain results similar to those of multi frame input convolution layer
5. Conclusion
Whether training in MDP, reasoning in POMDP, or training in POMDP, reasoning in MDP, DRQN can achieve good results.
The network trained with DQRN can get quite good performance even when the input is only 1 frame. However, the disadvantage is that DRQN and DQN are not very different in MDP environment. In POMDP, it is only an alternative to DQN multi frame input.
It does not have systematic advantages.
3, Network structure and update mode
1. Network structure
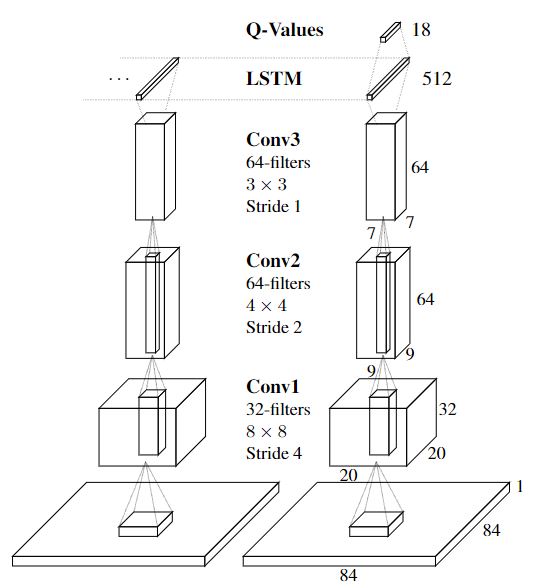
The first is the convolutional neural network for image processing. The image features processed by the convolutional neural network are input into LSTM, and then processed by LSTM and then input into DQN. It can be seen that the network structure of the algorithm is relatively simple. The main thing is to add an LSTM layer in front of DQN. However, there are still some points to pay attention to in the specific code implementation and input and output. At the same time, because we use a third-party library to build the environment, the previous convolutional neural network can be omitted and built directly from the LSTM layer.
2. Update method
There are two main update methods. One is sequential update. Randomly select an episode in the experience pool, and then randomly select a time point in the episode, running from this point to the end of the episode. Sequentially update the status of LSTM at the beginning of each training, inherited from the previous one.
The other is random update. Randomly select an episode in the experience pool, and then randomly select a time point in the episode. These steps are the same as sequential update, and then run the preset step instead of to the end. Out of order update the hidden layer status of LSTM is reset to 0 at the beginning of each training.
For example, after any episode is selected, the third step is selected, and the episode has a total of 10 steps, in order from the third to 10. Assuming five are preset, the disorder is from the third to the eighth
This paper mainly uses out of order update
4, Code implementation
The code is modified directly from DQN. The original DQN code is on the link at the beginning. You can look at that first, and then look down.
Let's talk about the modified part.
#Import the third-party libraries that will be used import parl from parl.utils import logger import paddle import copy import numpy as np import os import gym import random import collections
#Set the super parameters that will be used learn_freq = 3 # The training frequency does not need to learn from every step. Learn after accumulating some new experience to improve efficiency memory_warmup_size = 50 # episode_ replay_ Some experience data needs to be stored in memory before starting training batch_size = 8 # The amount of data that is given to the agent to learn each time is obtained from a batch of random sample s in replay memory lr = 6e-4 # Learning rate gamma = 0.99 # The attenuation factor of reward is generally 0.9 to 0.999 num_step=10 episode_size=500 # The larger the size of replay memory (the size of the dataset), the more memory it takes
An LSTM layer is added at the beginning of the network, and a function for initializing the LSTM layer is set. Because it is an out of order update, it is all 0
The obtained output shape is [batch_size,num_steps,output_size]. In the original code, the output shape is [batch_size,output_size]. For alignment, use padding.reshape to convert the data shape, and the conversion will not change the corresponding relationship
#Build network
class Model(paddle.nn.Layer):
def __init__(self, obs_dim,act_dim):
super(Model,self).__init__()
self.hidden_size=64
self.first=False
self.act_dim=act_dim
# Layer 3 fully connected network
self.fc1 = paddle.nn.Sequential(
paddle.nn.Linear(obs_dim,128),
paddle.nn.ReLU())
self.fc2 = paddle.nn.Sequential(
paddle.nn.Linear(self.hidden_size,128),
paddle.nn.ReLU())
self.fc3 = paddle.nn.Linear(128,act_dim)
self.lstm=paddle.nn.LSTM(128,self.hidden_size,1) #[input_size,hidden_size,num_layers]
def init_lstm_state(self,batch_size):
self.h=paddle.zeros(shape=[1,batch_size,self.hidden_size],dtype='float32')
self.c=paddle.zeros(shape=[1,batch_size,self.hidden_size],dtype='float32')
self.first=True
def forward(self, obs):
# Enter state and output Q corresponding to all action s, [Q(s,a1), Q(s,a2), Q(s,a3)...]
obs = self.fc1(obs)
#Reset before each workout
if (self.first):
x,(h,c) = self.lstm(obs,(self.h,self.c)) #obs:[batch_size,num_steps,input_size]
self.first=False
else:
x,(h,c) = self.lstm(obs) #obs:[batch_size,num_steps,input_size]
x=paddle.reshape(x,shape=[-1,self.hidden_size])
h2 = self.fc2(x)
Q = self.fc3(h2)
return Q
Changed the shape of action, reward and done, others remain unchanged
#DRQN algorithm
class DRQN(parl.Algorithm):
def __init__(self, model, act_dim=None, gamma=None, lr=None):
self.model = model
self.target_model = copy.deepcopy(model) #Copy the predict network to get the target network and realize the fixed-Q-target function
#Is the data type correct
assert isinstance(act_dim, int)
assert isinstance(gamma, float)
assert isinstance(lr, float)
self.act_dim = act_dim
self.gamma = gamma
self.lr = lr
self.optimizer=paddle.optimizer.Adam(learning_rate=self.lr,parameters=self.model.parameters()) # Using Adam optimizer
#Prediction function
def predict(self, obs):
return self.model.forward(obs)
def learn(self, obs, action, reward, next_obs, terminal):
#Flatten data
action=paddle.reshape(action,shape=[-1])
reward=paddle.reshape(reward,shape=[-1])
terminal=paddle.reshape(terminal,shape=[-1])
# From target_ Get the value of max Q 'in model to calculate target_Q
next_predict_Q = self.target_model.forward(next_obs)
best_v = paddle.max(next_predict_Q, axis=-1)#next_ predict_ Each dimension (row) of Q is maximized, because each row corresponds to a St, and the number of rows is the batch size of our input data
best_v.stop_gradient = True #Prevent gradient transfer because model parameters are fixed
terminal = paddle.cast(terminal, dtype='float32') #Convert data type to float32
target = reward + (1.0 - terminal) * self.gamma * best_v #Realistic value of Q
predict_Q = self.model.forward(obs) # Get Q prediction
#The next step is to get the Q(s,a) corresponding to the action
action_onehot = paddle.nn.functional.one_hot(action, self.act_dim) # Convert action to onehot vector, for example: 3 = > [0,0,0,1,0]
action_onehot = paddle.cast(action_onehot, dtype='float32')
predict_action_Q = paddle.sum(
paddle.multiply(action_onehot, predict_Q) #Multiply element by element to get Q(s,a) corresponding to action
, axis=1) #Sum each row,Note the true purpose of summing here # For example: pred_value = [[2.3, 5.7, 1.2, 3.9, 1.4]], action_onehot = [[0,0,0,1,0]]
#Real is a transformation dimension, similar to matrix transpose. And target Same form. # ==> pred_action_value = [[3.9]]
# Calculate Q(s,a) and target_ The mean square deviation of Q is obtained. It is a regression problem to let the output of one group approach the output of another group, so the mean square loss function is used
loss=paddle.nn.functional.square_error_cost(predict_action_Q, target)
cost = paddle.mean(loss)
cost.backward() #Back propagation
self.optimizer.step() #Update parameters
self.optimizer.clear_grad() #Clear gradient
def sync_target(self):
self.target_model = copy.deepcopy(model) #Copy the predict network to get the target network and realize the fixed-Q-target function
class Agent(parl.Agent):
def __init__(self,
algorithm,
act_dim,
e_greed=0.1,
e_greed_decrement=0 ):
#Judge whether the type of input data is int
assert isinstance(act_dim, int)
self.act_dim = act_dim
#Call the object of the Agent parent class and enter the algorithm class algorithm so that we can call the members in the algorithm
super(Agent, self).__init__(algorithm)
self.global_step = 0 #Total operation steps
self.update_target_steps = 200 # Every 200 training steps, copy the parameters of the model to the target_ In model
self.e_greed = e_greed # There is a certain probability to randomly select actions and explore
self.e_greed_decrement = e_greed_decrement # As the training gradually converges, the degree of exploration gradually decreases
#The parameter obs is a single input, which is different from the parameter of the learn function
def sample(self, obs):
sample = np.random.rand() # Generate decimals between 0 and 1
if sample < self.e_greed:
act = np.random.randint(self.act_dim) # Exploration: every action has a probability to be selected
else:
act = self.predict(obs) # Select the best action
self.e_greed = max(
0.01, self.e_greed - self.e_greed_decrement) # As the training gradually converges, the degree of exploration gradually decreases
return act
#The output is obtained through neural network
def predict(self, obs): # Select the best action
obs=paddle.to_tensor(obs,dtype='float32') #Convert target array to tensor
predict_Q=self.alg.predict(obs).numpy() #Convert the resulting tensor to an array
act = np.argmax(predict_Q) # Select the subscript with the largest Q, that is, the corresponding action
return act
#The learn function here mainly includes two functions. 1. Synchronize model parameters 2. Update model. These two functions are finally realized by calling the functions in the algorithm algorithm.
#Note that the parameters entered here are arrays composed of a batch of data
def learn(self, obs, act, reward, next_obs, terminal):
# Synchronize the model and target every 200 training steps_ Parameters of model
if self.global_step % self.update_target_steps == 0:
self.alg.sync_target()
self.global_step += 1 #Every time the learn function is executed, the total number of times is + 1
#Convert to tensor
obs=paddle.to_tensor(obs,dtype='float32')
act=paddle.to_tensor(act,dtype='int32')
reward=paddle.to_tensor(reward,dtype='float32')
next_obs=paddle.to_tensor(next_obs,dtype='float32')
terminal=paddle.to_tensor(terminal,dtype='float32')
#Learning
self.alg.learn(obs, act, reward, next_obs, terminal)
Because the data required by DRQN is sampled from an entire episode, each data in the dataset should be an episode. Therefore, the experience pool class is rewritten. The function of each step collected by the original class remains unchanged. At the same time, each step determines whether it is the last step of an episode, that is, whether done is True. Create a new episodemomery class, input all episodes, and randomly select a time step for processing
class EpisodeMemory(object):
def __init__(self,episode_size,num_step):
self.buffer = collections.deque(maxlen=episode_size)
self.num_step=num_step #time step
def put(self,episode):
self.buffer.append(episode)
def sample(self,batch_size):
mini_batch = random.sample(self.buffer, batch_size) #The return value is a list
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
self.num_step = min(self.num_step, len(experience)) #Prevents the sequence length from being less than the predefined length
for experience in mini_batch:
idx = np.random.randint(0, len(experience)-self.num_step+1) #Randomly select the id of a time step
s, a, r, s_p, done = [],[],[],[],[]
for i in range(idx,idx+self.num_step):
e1,e2,e3,e4,e5=experience[i][0]
s.append(e1[0][0]),a.append(e2),r.append(e3),s_p.append(e4),done.append(e5)
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
#Convert data format
obs_batch=np.array(obs_batch).astype('float32')
action_batch=np.array(action_batch).astype('float32')
reward_batch=np.array(reward_batch).astype('float32')
next_obs_batch=np.array(next_obs_batch).astype('float32')
done_batch=np.array(done_batch).astype('float32')
#Convert list to array and data type
return obs_batch,action_batch,reward_batch,next_obs_batch,done_batch
#Length of output queue
def __len__(self):
return len(self.buffer)
class ReplayMemory(object):
def __init__(self,e_rpm):
#Create a fixed length queue as a buffer area. When the queue is full, the oldest message will be automatically deleted
self.e_rpm=e_rpm
self.buff=[]
# Add an experience to the experience pool
def append(self,exp,done):
self.buff.append([exp])
#Add an entire episode to the experience pool
if(done):
self.e_rpm.put(self.buff)
self.buff=[]
#Length of output queue
def __len__(self):
return len(self.buff)
Set a certain episode interval to train once and jump out of the loop at the same time. Reinitialize the hidden layer parameters of LSTM before each training
# Train an episode
def run_episode(env, agent, rpm, e_rpm, obs_shape): #rpm is the experience pool
for step in range(1,learn_freq+1):
#Reset environment
obs = env.reset()
while True:
obs=obs.reshape(1,1,obs_shape)
action = agent.sample(obs) # Sampling actions, all actions have the probability of being tried
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done),done) #Collect data
obs = next_obs
if done:
break
#After storing enough experience, train at intervals
if (len(e_rpm) > memory_warmup_size):
#Reset LSTM parameters before each workout
model.init_lstm_state(batch_size)
(batch_obs, batch_action, batch_reward, batch_next_obs,batch_done) = e_rpm.sample(batch_size)
agent.learn(batch_obs, batch_action, batch_reward,batch_next_obs,batch_done) # s,a,r,s',done
# Evaluate the agent, run 5 episode s, and average the total reward
def evaluate(env, agent, obs_shape,render=False):
eval_reward = [] #The list stores the reward of all episode s
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
obs=obs.reshape(1,1,obs_shape)
action = agent.predict(obs) # Predict action, select only the best action
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward) #Average
env = gym.make('CartPole-v1')
action_dim = env.action_space.n
obs_shape = env.observation_space.shape
save_path = './dqn_model.ckpt'
e_rpm=EpisodeMemory(episode_size,num_step)
rpm = ReplayMemory(e_rpm) # Instantiate the experience playback pool of DQN
# Constructing agent based on parl framework
model = Model(obs_dim=obs_shape[0],act_dim=action_dim)
algorithm = DRQN(model, act_dim=action_dim, gamma=gamma, lr=lr)
agent = Agent(
algorithm,
act_dim=action_dim,
e_greed=0.1, # There is a certain probability to randomly select actions and explore
e_greed_decrement=8e-7) # As the training gradually converges, the degree of exploration gradually decreases
# First save some data in the experience pool to avoid insufficient sample richness at the beginning of training
while len(e_rpm) < memory_warmup_size:
run_episode(env, agent, rpm,e_rpm,obs_shape[0])
#Define training times
max_train_num = 2000
best_acc=377.0
agent.restore(save_path)
# Start training
train_num = 0
while train_num < max_train_num: # Training max_episode rounds, and the test part will not be counted into the episode quantity
# train part
#The purpose of the for loop is to test every 50 times
for i in range(0, 50):
run_episode(env, agent,rpm, e_rpm,obs_shape[0])
train_num += 1
# test part
eval_reward = evaluate(env, agent,obs_shape[0], render=False) #render=True to view the display effect
if eval_reward>best_acc:
best_acc=eval_reward
agent.save(save_path)
#Write information to log file
logger.info('train_num:{} e_greed:{} test_reward:{}'.format(
train_num, agent.e_greed, eval_reward))
e(env, agent,obs_shape[0], render=False) #render=True to view the display effect
if eval_reward>best_acc:
best_acc=eval_reward
agent.save(save_path)
#Write information to log file
logger.info('train_num:{} e_greed:{} test_reward:{}'.format(
train_num, agent.e_greed, eval_reward))
[32m[10-30 21:27:56 MainThread @machine_info.py:88][0m nvidia-smi -L found gpu count: 1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for fc1.0.weight. fc1.0.weight receives a shape [64, 128], but the expected shape is [4, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for fc2.0.weight. fc2.0.weight receives a shape [128, 128], but the expected shape is [64, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for lstm.weight_ih_l0. lstm.weight_ih_l0 receives a shape [256, 4], but the expected shape is [256, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for lstm.0.cell.weight_ih. lstm.0.cell.weight_ih receives a shape [256, 4], but the expected shape is [256, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[32m[10-30 21:27:59 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:50 e_greed:0.09840000000000951 test_reward:10.0
[32m[10-30 21:28:01 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:100 e_greed:0.09717920000001676 test_reward:9.8
[32m[10-30 21:28:04 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:150 e_greed:0.09591920000002424 test_reward:10.2
[32m[10-30 21:28:07 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:200 e_greed:0.0944768000000328 test_reward:11.0
[32m[10-30 21:28:09 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:250 e_greed:0.09330160000003979 test_reward:9.0
[32m[10-30 21:28:12 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:300 e_greed:0.09211440000004684 test_reward:9.0
[32m[10-30 21:28:14 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:350 e_greed:0.09093200000005386 test_reward:9.6
[32m[10-30 21:28:17 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:400 e_greed:0.08976000000006082 test_reward:9.2
[32m[10-30 21:28:19 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:450 e_greed:0.0885680000000679 test_reward:9.8
[32m[10-30 21:28:22 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:500 e_greed:0.087371200000075 test_reward:9.2
[32m[10-30 21:28:24 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:550 e_greed:0.08620640000008192 test_reward:9.6
[32m[10-30 21:28:27 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:600 e_greed:0.0850312000000889 test_reward:9.4
[32m[10-30 21:28:29 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:650 e_greed:0.08388160000009573 test_reward:9.4
[32m[10-30 21:28:32 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:700 e_greed:0.08273040000010257 test_reward:9.6
[32m[10-30 21:28:34 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:750 e_greed:0.0815128000001098 test_reward:9.8
[32m[10-30 21:28:37 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:800 e_greed:0.08027520000011715 test_reward:9.8
[32m[10-30 21:28:40 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:850 e_greed:0.07881680000012581 test_reward:10.6
[32m[10-30 21:28:44 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:900 e_greed:0.07678400000013788 test_reward:13.0
[32m[10-30 21:28:48 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:950 e_greed:0.07478480000014975 test_reward:9.0
[32m[10-30 21:28:53 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1000 e_greed:0.07232720000016435 test_reward:12.0
[32m[10-30 21:28:57 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1050 e_greed:0.07040160000017578 test_reward:9.4
[32m[10-30 21:29:03 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1100 e_greed:0.06750000000019302 test_reward:105.2
[32m[10-30 21:29:23 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1150 e_greed:0.057448000000208894 test_reward:86.2
[32m[10-30 21:29:38 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1200 e_greed:0.04959200000018741 test_reward:53.2
[32m[10-30 21:30:08 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1250 e_greed:0.03536800000014851 test_reward:376.2
[32m[10-30 21:30:53 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1300 e_greed:0.012563200000160545 test_reward:142.4
[32m[10-30 21:31:24 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1350 e_greed:0.01 test_reward:16.2
[32m[10-30 21:31:53 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1400 e_greed:0.01 test_reward:189.2
[32m[10-30 21:32:20 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1450 e_greed:0.01 test_reward:177.8
[32m[10-30 21:32:58 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1500 e_greed:0.01 test_reward:119.8
[32m[10-30 21:33:36 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1550 e_greed:0.01 test_reward:192.8
[32m[10-30 21:34:37 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1600 e_greed:0.01 test_reward:200.6
[32m[10-30 21:35:13 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1650 e_greed:0.01 test_reward:19.4
[32m[10-30 21:36:00 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1700 e_greed:0.01 test_reward:181.8
[32m[10-30 21:36:47 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1750 e_greed:0.01 test_reward:139.2
[32m[10-30 21:37:43 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1800 e_greed:0.01 test_reward:193.8
[32m[10-30 21:38:50 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1850 e_greed:0.01 test_reward:322.4
[32m[10-30 21:40:11 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1900 e_greed:0.01 test_reward:500.0
[32m[10-30 21:41:29 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1950 e_greed:0.01 test_reward:438.4
[32m[10-30 21:42:43 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:2000 e_greed:0.01 test_reward:500.0
The effect is fairly good, but it can be seen that the current parameters are not the optimal parameters, and there is still room for improvement. You can try to adjust the given super parameters. The model can get better results in less time
There are already trained models in the space. If you don't want to train, you can load them directly.
Personal profile
Author: Wang Zhenhao
2020 undergraduate of computer science and technology in Qinhuangdao branch of Northeast University
Direction of interest: CV, RL
I am here AI Studio Gain silver level on the and light up 2 badges to