Introduction to this article
The Dragon Boat Festival is coming. How about traveling? Go home? Visit relatives and friends? You have to bring zongzi. Then:
- What brand of zongzi do you choose?
- What flavor of zongzi do you choose?
- What price range to choose?

This year, Huang climbed the "zongzi data" on jd.com in Python to analyze it and see what he found! In this paper, data crawling, data cleaning and data visualization are three convenient methods, but you can simply complete a small data analysis project, so that you can have a comprehensive application of knowledge.
The whole idea is as follows:
- Crawl web pages: https://www.jd.com/
- Crawling Description: Based on Jingdong website, we search the data of "zongzi" on the website, which is about 100 pages. The fields we crawl include both the relevant information of the primary page and some information of the secondary page;
- Crawling idea: first analyze the primary page of a page of data, then analyze the secondary page, and finally turn the page;
- Crawling fields: name (title), price, brand (store) and category (taste) of zongzi;
- Tools used: requests + lxml + pandas + time + re + pyechards
- Website parsing method: xpath
The final effect is as follows: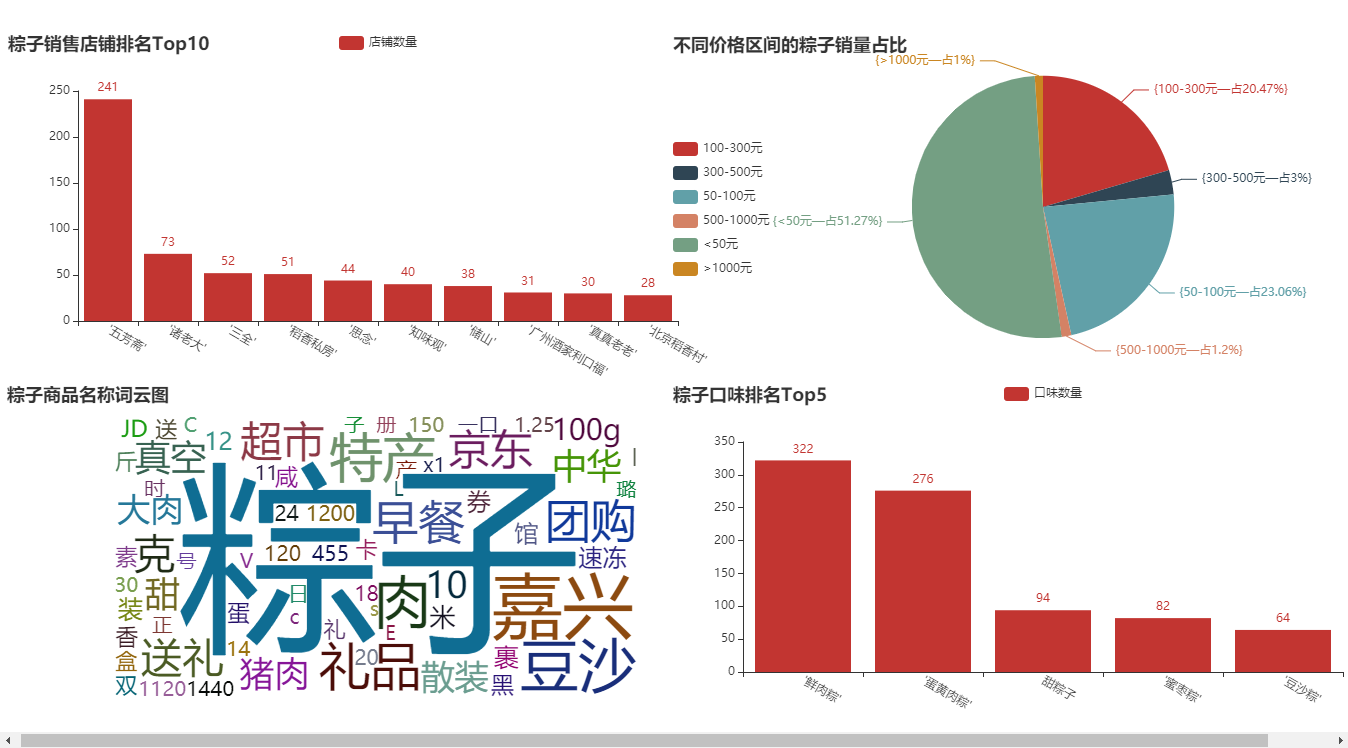
Data crawling
Jd.com website is generally dynamically loaded, that is, in a general way, it can only crawl to the first 30 data of a page (a page has a total of 60 data).
Based on this article, I only used the most basic method to crawl the first 30 data of each page (if you are interested, you can go down and crawl all the data by yourself).
So, what fields are crawled in this paper? I'll give you a presentation. If you are interested, you can crawl more fields and do more detailed analysis.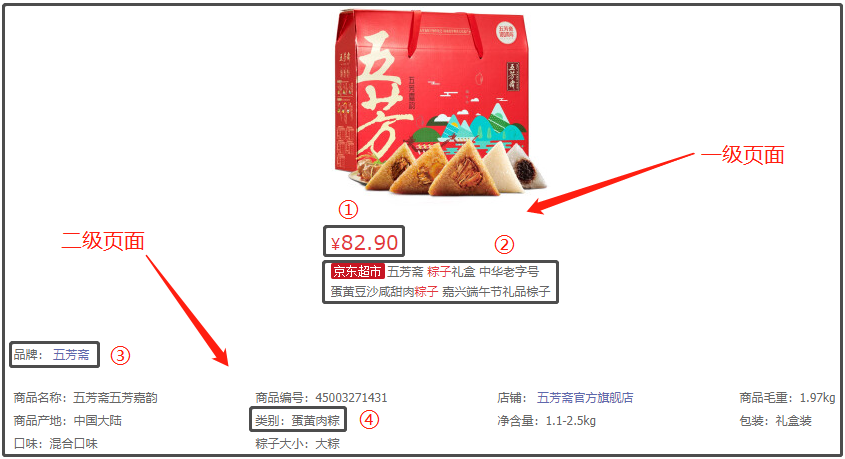
Let's show you the crawler Code:
import pandas as pd
import requests
from lxml import etree
import chardet
import time
import re
def get_CI(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; X64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}
rqg = requests.get(url,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# Price
p_price = html.xpath('//div/div[@class="p-price"]/strong/i/text()')
# name
p_name = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/em')
p_name = [str(p_name[i].xpath('string(.)')) for i in range(len(p_name))]
# Deep url
deep_ur1 = html.xpath('//div/div[@class="p-name p-name-type-2"]/a/@href')
deep_url = ["http:" + i for i in deep_ur1]
# From here, we get the information of "secondary page"
brands_list = []
kinds_list = []
for i in deep_url:
rqg = requests.get(i,headers=headers)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# brand
brands = html.xpath('//div/div[@class="ETab"]//ul[@id="parameter-brand"]/li/@title')
brands_list.append(brands)
# category
kinds = re.findall('>Category:(.*?)</li>',rqg.text)
kinds_list.append(kinds)
data = pd.DataFrame({'name':p_name,'Price':p_price,'brand':brands_list,'category':kinds_list})
return(data)
x = "https://search.jd.com/Search?keyword=%E7%B2%BD%E5%AD%90&qrst=1&wq=%E7%B2%BD%E5%AD%90&stock=1&page="
url_list = [x + str(i) for i in range(1,200,2)]
res = pd.DataFrame(columns=['name','Price','brand','category'])
# The "page turning" operation is performed here
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# Save data
res.to_csv('aliang.csv',encoding='utf_8_sig')
The data finally crawled, like this.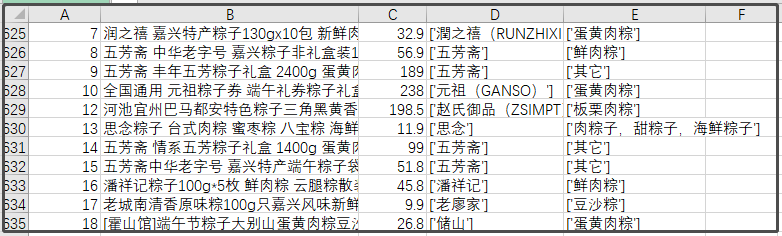
Data cleaning
As can be seen from the above figure, the whole data is very neat, not particularly messy. We can only do some simple operations.
First use the pandas library to read the data.
import pandas as pd
df = pd.read_excel("traditional Chinese rice-pudding.xlsx",index_col=False)
df.head()
The results are as follows:
We remove the brackets for the "brand" and "category" fields respectively.
df["brand"] = df["brand"].apply(lambda x: x[1:-1]) df["category"] = df["category"].apply(lambda x: x[1:-1]) df.head()
The results are as follows: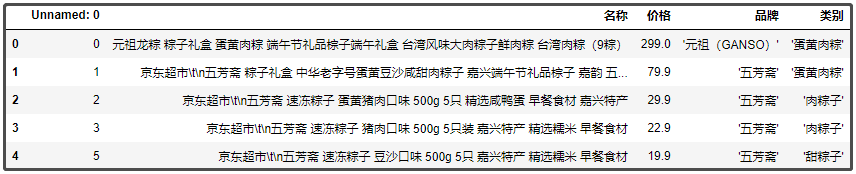
① Top 10 stores of zongzi brand
df["brand"].value_counts()[:10]
② The top 5 flavors of zongzi
def func1(x):
if x.find("sweet") > 0:
return "Sweet zongzi"
else:
return x
df["category"] = df["category"].apply(func1)
df["category"].value_counts()[1:6]
The results are as follows: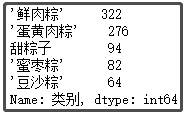
③ Division of selling price range of zongzi
def price_range(x): #Divide the price range according to Taobao's recommendation
if x <= 50:
return '<50 element'
elif x <= 100:
return '50-100 element'
elif x <= 300:
return '100-300 element'
elif x <= 500:
return '300-500 element'
elif x <= 1000:
return '500-1000 element'
else:
return '>1000 element'
df["Price range"] = df["Price"].apply(price_range)
df["Price range"].value_counts()
The results are as follows: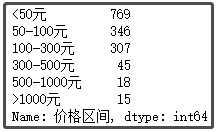
Since there are not many data and there are not many fields, there is not a lot of random data. Therefore, there are no operations such as data De duplication and missing value filling. Therefore, you can go down to get more fields and more data for data analysis.
Data visualization
As the saying goes: words are not as good as tables, and tables are not as good as pictures. Through visual analysis, we can show the "hidden" information behind the data.
Expansion: of course, it's just "throwing bricks to attract jade". I didn't get too much data or too many fields. Here is an assignment for friends who study. Go down and do more thorough analysis with more data and more fields.
Here, we will make a visual display based on the following questions:
- ① Top 10 column chart of zongzi sales store;
- ② Top 5 column chart of zongzi taste ranking;
- ③ Zongzi sales price range division pie chart;
- ④ Rice dumpling commodity name word cloud map;
In view of the layout of the whole article, the code of the visualization part of this article can be obtained at the end of this article.
① Top 10 column chart of zongzi sales store
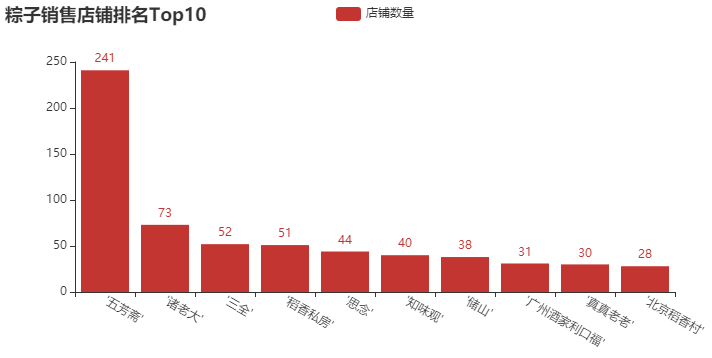
Conclusion analysis: last year, we analyzed the data of some moon cakes. The brands of "wufangzhai" and "Beijing daoxiangcun" are still fresh in our memory. It can be said that they are old shops for making moon cakes and zongzi. Like "Sanquan" and "missing", I always think they only make dumplings and dumplings. Is zongzi worth a try? Of course, there are some new brands here, such as "boss Zhu", "Daoxiang private house" and so on. You can go down and search. Shopping is to choose carefully, and the brand is also important.
② Top 5 column chart of zongzi taste ranking
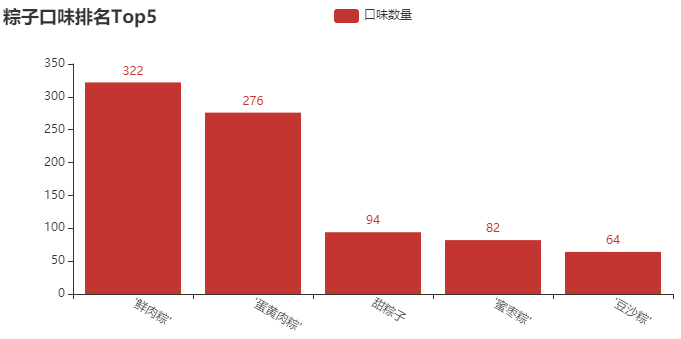
Conclusion analysis: in my impression, what I ate most when I was a child was "sweet zongzi". I didn't know until I went to junior high school that zongzi can still have meat? Of course, it can be seen from the picture that most shops sell "fresh meat dumplings". After all, this gift still looks high-end. There are also some flavors here, such as "jujube Zong" and "bean paste Zong", which I haven't eaten. If you gave it to someone, what flavor would you give it to?
③ Pie chart for dividing the selling price range of zongzi
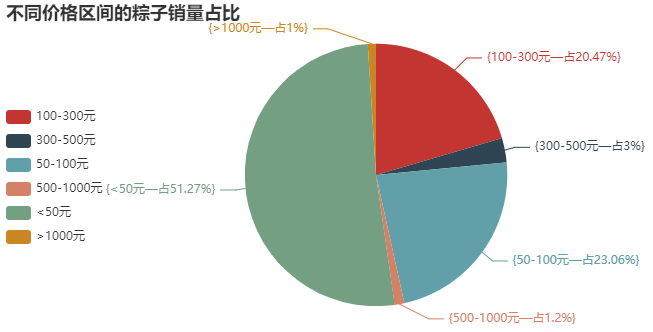
Conclusion analysis: here, I deliberately subdivide the price range. This pie chart is also very realistic. After all, the Dragon Boat Festival is held once a year. It is still dominated by small profits and quick sales. Nearly 80% of zongzi are sold for less than 100 yuan. Of course, there are some mid-range zongzi, the price is 100-300 yuan. More than 300 yuan, I don't think it's necessary to eat. Anyway, I won't spend so much money on zongzi.
④ Cloud picture of zongzi commodity name

Conclusion analysis: from the figure, we can roughly see the selling points of the merchants. After all, it is a festival. "Giving gifts" and "gifts" reflect the festival atmosphere. "Pork" and "bean paste" reflect the taste of zongzi. Of course, is it a good choice for "breakfast"? If you buy, you also support "group purchase".
⑤ The graphics are combined into a large screen
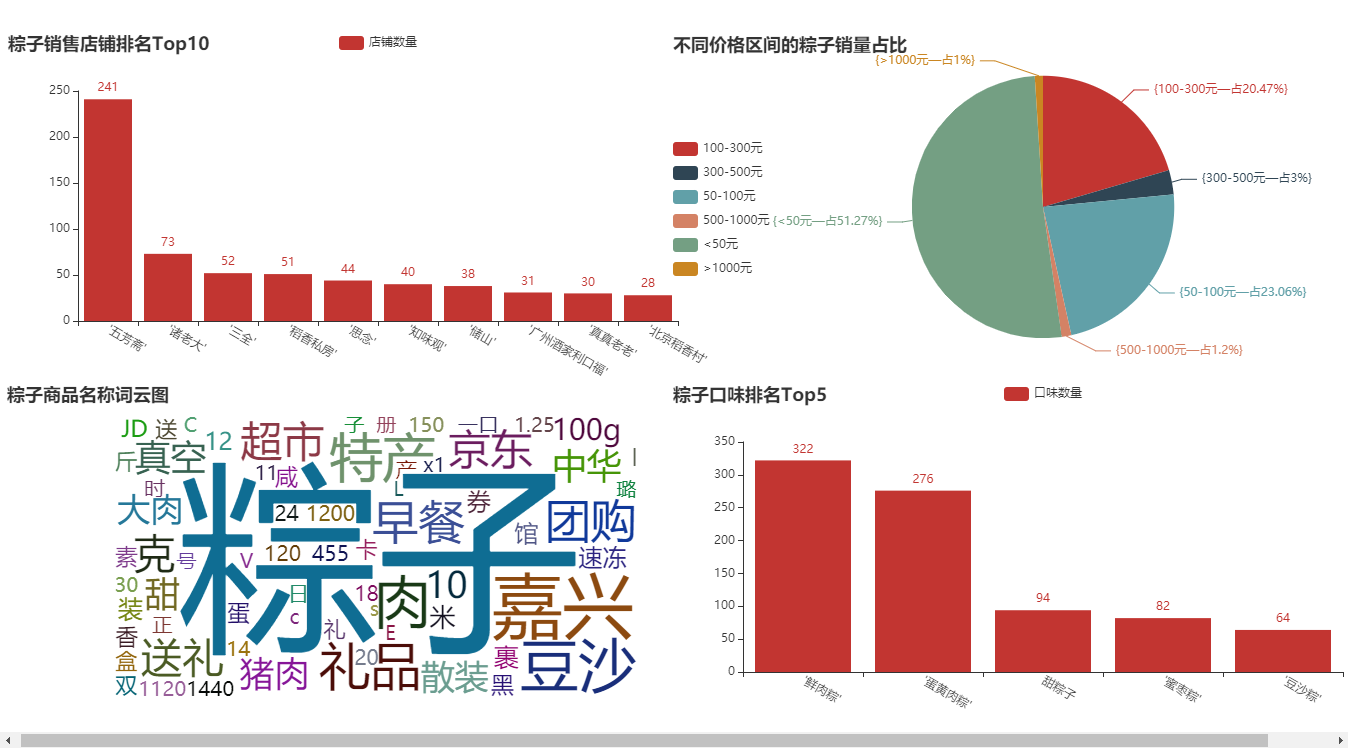
The visualization of this paper uses the pyecharts library to draw. We first make each picture separately, and then integrate the graphics to make a beautiful large visual screen. About how to make, you can get the code by private letter!
How to get the source code:
① More than 3000 Python e-books
② Python development environment installation tutorial
③ Python 400 set self-study video
④ Common vocabulary of software development
⑤ Python learning Roadmap
⑥ Project source code case sharing
If you can use it, you can take it directly. In my QQ technical exchange group, group number: 739021630 (pure technical exchange and resource sharing, advertising is not allowed) take it by yourself
Click here to receive