Chinese address http://www.apache-druid.cn/
1. Introduction
At present, there are many mainstream big data real-time analysis databases on the market. Why do we choose Apache Druid? Let's make a comparison first:
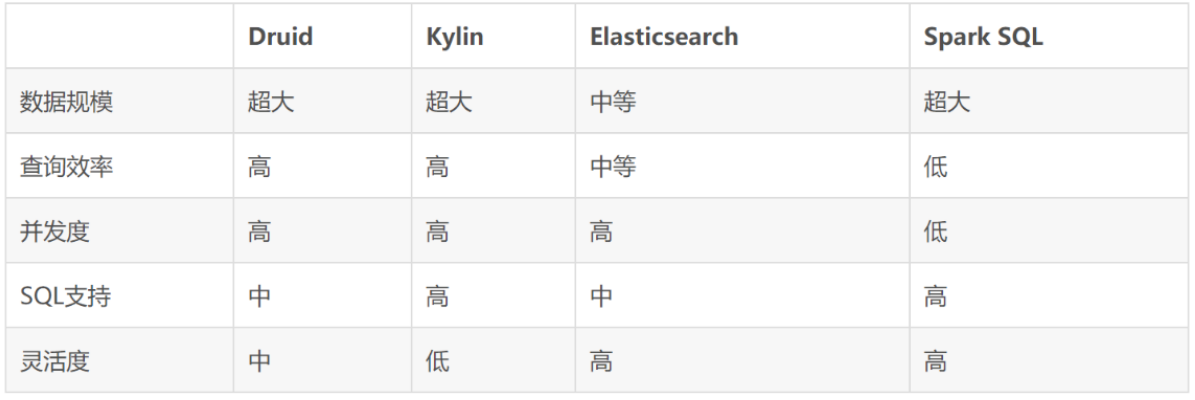
Apache Druid is a real-time analytical database designed for rapid query analysis ("OLAP" queries) on large data sets. Druid is most often used as a database to support application scenarios of real-time ingestion, high-performance query and high stable operation. At the same time, Druid is also usually used to help the graphical interface of analytical applications, or as a high concurrency back-end API that needs rapid aggregation. Druid is most suitable for event oriented data.
Druid is usually applied to the following scenarios:
1:Click stream analysis( Web End and mobile end) 2:Network monitoring analysis (network performance monitoring) 3:Service indicator storage 4:Supply chain analysis (manufacturing indicators) 5:Application performance index analysis 6:Digital advertising analysis 7:Business intelligence / OLAP
Druid main features:
1:Column storage, Druid Using column storage means that in a specific data query, it only needs to query specific columns, which greatly improves the performance of some column query scenarios. In addition, each column of data is optimized for specific data types to support rapid scanning and aggregation. 2:Scalable distributed systems, Druid It is usually deployed in a cluster of dozens to hundreds of servers, and can provide the receiving rate of millions of records per second, the reserved storage of trillions of records, and the query latency of sub second to several seconds. 3:Massively parallel processing, Druid Queries can be processed in parallel throughout the cluster. 4:Real time or batch ingestion, Druid The data can be ingested in real time (the data that has been ingested can be used for query immediately) or in batch. 5:It is self-healing, self balancing and easy to operate. As a cluster operation and maintenance operator, if you want to scale the cluster, you only need to add or delete services, and the cluster will automatically rebalance itself in the background without causing any downtime. If any one Druid If the server fails, the system will automatically bypass the damage. Druid The design is 7*24 24 / 7 operation without planned downtime for any reason, including configuration changes and software updates. 6:Cloud native fault-tolerant architecture that will not lose data once Druid Once the data is ingested, the replica is securely stored on a deep storage medium (usually cloud storage), HDFS Or shared file system). Even if one Druid If the service fails, you can also recover your data from deep storage. For only a few Druid Limited failure of services, replicas ensure that queries can still be made when the system is restored. 7:Index for fast filtering, Druid use CONCISE or Roaring Compressed bitmap index to create an index to support fast filtering and cross column search. 8:Time based partitioning, Druid First, the data is partitioned according to time. In addition, it can be partitioned according to other fields. This means that time-based queries will only access partitions that match the query time range, which will greatly improve the performance of time-based data(__time). 9:Approximation algorithm, Druid Approximation is applied count-distinct,Approximate sorting and approximate histogram and quantile calculation algorithm. These algorithms take up limited memory usage and are usually much faster than accurate calculations. For scenes where accuracy is more important than speed, Druid It also provides accurate count-distinct And precise sorting. 10:Automatic aggregation upon ingestion, Druid Support optional data aggregation in the data ingestion phase. This aggregation will partially aggregate your data in advance, which can save a lot of cost and improve performance.
In what scenario should Druid be used
1:The data insertion frequency is high, but the data is rarely updated 2:Most query scenarios are aggregate query and group query( GroupBy),At the same time, there must be retrieval and scanning query 3:Locate the data query delay target between 100 milliseconds and a few seconds 4:Data has a time attribute( Druid (optimized and designed for time) 5:In the multi table scenario, each query hits only one large distributed table, and the query may hit multiple smaller distributed tables lookup surface 6:The scene contains high base dimension data columns (for example URL,user ID And need to count and sort them quickly 7:Need from Kafka,HDFS,Object storage (e.g Amazon S3)Load data in
Apache Druid architecture
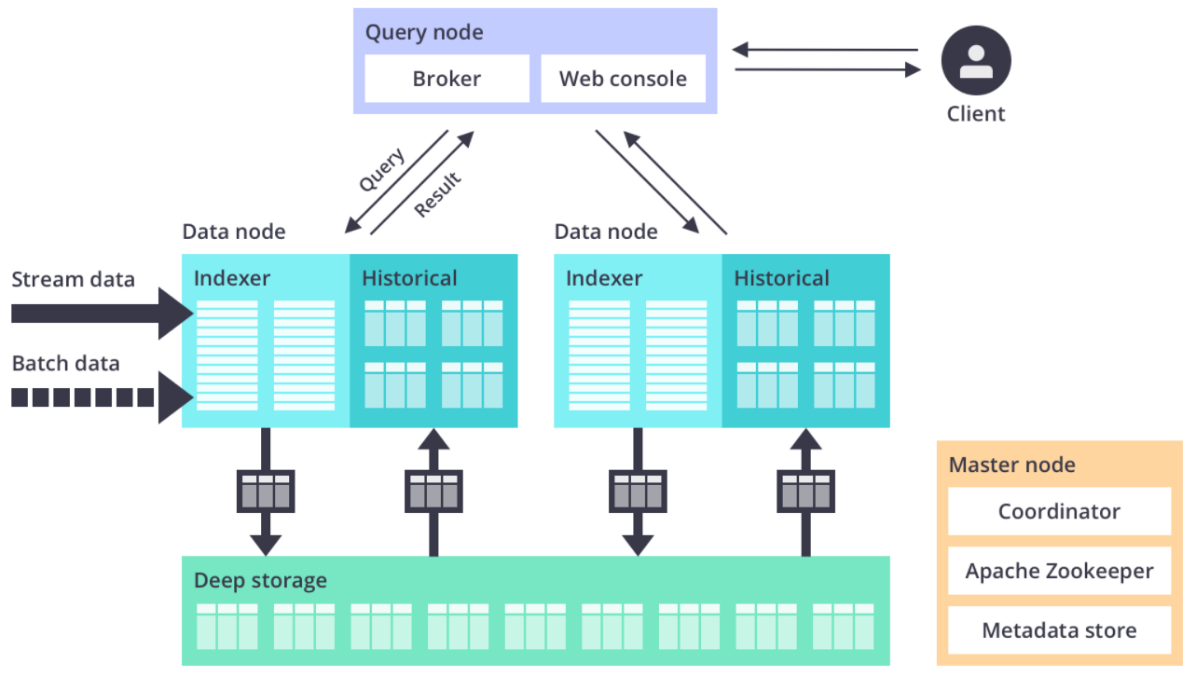
As shown in the figure above, this is the architecture diagram of the official website Apache Druid:
1.Historicale: Load the generated data file for data query. 2.Broker: Provide external data query services. 3.Coordinator: be responsible for Historical Node Data load balancing, and Rule Manage the data lifecycle. 4.Metabase( Metastore): storage druid Metadata information of the cluster, such as Segment For general use MySQL or PostgreSQL 5.Distributed coordination service( Coordination): by Druid Clusters provide consistency services, usually zookeeper 6.Data file storage( DeepStorage): Store generated Segment Documents for Historical Node Download, generally for use HDFS
2. Installation
Installation package download address: http://druid.apache.org/downloads.html
Upload the installation package to the server and unzip it. Then enter the directory for related operations.
For the convenience of operation, we can start the stand-alone version, but the stand-alone version will automatically load Zookeeper. The cluster version can freely configure the external nodes of Zookeeper, but the stand-alone version cannot. Because I also use Zookeeper in Kafka, in order to avoid conflict between the two zookeepers, I need to replace the Zookeeper port of Apache Druid to be installed, and replace 2181 with 3181 in apache-druid-0.20 Execute the following 2 lines of commands in the 0 Directory:
sed -i "s/2181/3181/g" `grep 2181 -rl ./` sed -i "s/druid.zk.service.host=localhost/druid.zk.service.host=localhost:3181/g" `grep druid.zk.service.host=localhost -rl ./`
Description: sed -i "s / original string / new string / g" grep directory of original string - rl
Druid's time zone is inconsistent with the domestic time zone, which will be 8 hours less than ours. We need to modify the configuration file and add time + 8 in batch. The code is as follows:
sed -i "s/Duser.timezone=UTC/Duser.timezone=UTC+8/g" `grep Duser.timezone=UTC -rl ./`
Next, go to / usr / local / apache-druid-0.20 Start Apache Druid in 0 / bin directory:
./start-micro-quickstart
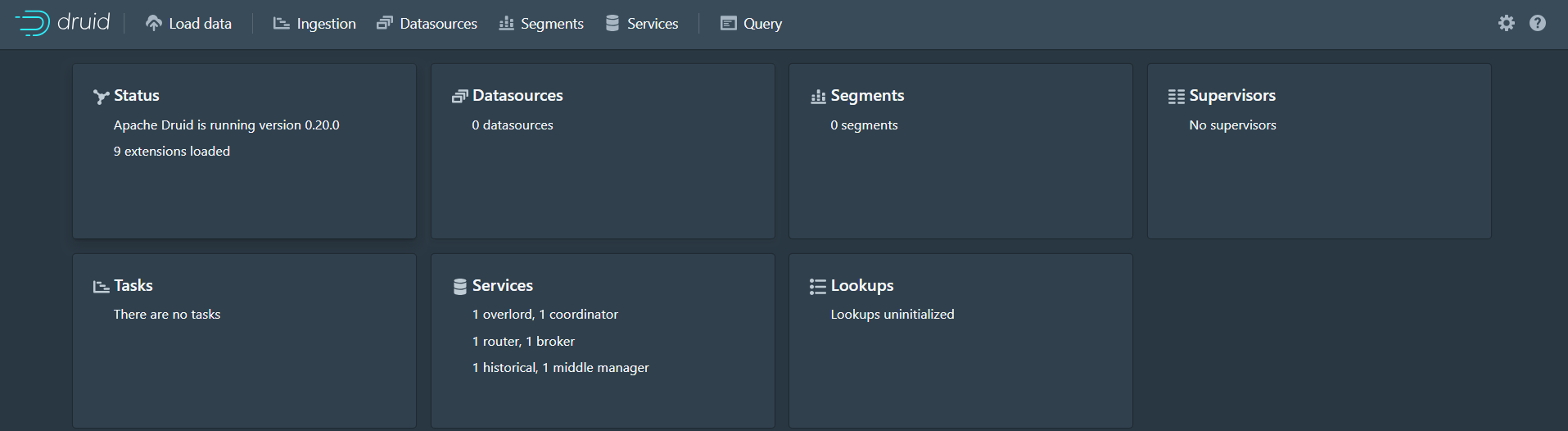
After startup, wait 20 seconds and we can access the Apache Druid console http://192.168.100.130:8888/ The effects are as follows:
be careful:
-
If you need to run in the background, you can execute it directly/ start-micro-quickstart &
-
The server firewall needs to open the corresponding port
Coordinator 8081 Historical 8083 Broker 8082 Realtime 8084 Overlord 8090 MiddleManager 8091 Router 8888