Dubbo extension point loading mechanism
preface
This paper first introduces the overview of the existing Dubbo loading mechanism, including the improvements made by Dubbo and some features. Then it introduces some key annotations of the loading mechanism, @ SPI, @ Adaptive, @ Activate. Then it introduces the workflow and implementation principle of ExtensionLoader, which is the core of the whole mechanism. Finally, the implementation principle of class dynamic compilation used in extension is introduced. Through reading this article, we will have an in-depth understanding of the Dubbo SPI loading mechanism and the source code of this part. It will be easier for fat friends to read the source code by themselves.
Overview of loading mechanism
Dubbo's good expansibility is inseparable from two aspects: one is that various design patterns are properly used for different scenarios in the whole framework; the other is the loading mechanism we want to talk about. Based on the loading mechanism of Dubbo SPI, the interface of the whole framework is completely decoupled from the specific implementation, which lays a foundation for the good expansibility of the whole framework.
Dubbo provides many extension points that can be used directly by default. Almost all the functional components of Dubbo are implemented based on the extension mechanism (SPI). These core extension points will be described in detail later.
Dubbo SPI does not directly use Java SPI, but has made certain improvements in its thinking, forming a set of its own configuration specifications and features. At the same time, Dubbo SPI is compatible with Java SPI. When the service starts, Dubbo will find all the implementations of these extension points.
Java SPI
Before talking about Dubbo SPI, let's talk about Java SPI. The full name of SPI is Service Provider Interface, which was originally provided to manufacturers for plug-in development. For detailed definitions and explanations of Java SPI, see here. Java SPI uses a policy pattern, with multiple implementations of one interface. We only declare the interface, and the specific implementation is not directly determined in the program, but controlled by the configuration outside the program for the assembly of the specific implementation. The specific steps are as follows:
- Define an interface and corresponding methods.
- Write an implementation class of the interface.
- In the META-INF/services / directory, create a file named after the full path of the interface, such as com example. rpc. example. spi. HelloService.
- The file content is the full path name of the specific implementation class. If there are multiple, separate them with a line break.
- In the code through Java util. Serviceloader to load specific implementation classes. In this way, the specific implementation of HelloService can be implemented by the file com example. rpc. example. spi. Determined by the implementation class configured in HelloService. The class I configured here is com example. rpc. example. spi. HelloServiceImpl.
The project structure is as follows:
The Java SPI sample code is as follows:
public interface HelloService {
void sayHello();
}public class HelloServiceImpl implements HelloService{
@Override
public void sayHello() {
System.out.printf("hello world!");
}
}public static void main(String[] args) {
ServiceLoader<HelloService> serviceLoader = ServiceLoader.load(HelloService.class);
//Get all SPI implementations,
// Loop through the sayHello() method,
// It will print out hello world. There is only one implementation here: HelloServiceImpl
for (HelloService helloService : serviceLoader) {
//hello world will be output here
helloService.sayHello();
}
}As you can see from the above code list, the main method is passed through Java util. Serviceloader can obtain all interface implementations, and the specific implementation to call can be determined by user-defined rules.
Improvement of extension point loading mechanism
Dubbo's extension point loading is enhanced from the SPI (Service Provider Interface) extension point discovery mechanism of JDK standard.
Dubbo has made some improvements to the SPI of JDK standard:
- The SPI of the JDK standard instantiates all implementations of the extension point at one time. If there is an extension implementation, initialization is time-consuming, but if it is not used, it will also be loaded, which will be a waste of resources.
- If the extension point fails to load, you can't even get the name of the extension point.
- Added support for IoC and AOP extension points. One extension point can directly inject setter into other extension points.
Dubbo SPI transformation of HelloService interface
- Create the configuration file com. Under the directory META- INF/dubbo/ internal example. rpc. example. spi. Helloservice, the file contents are as follows
impl=com.example.rpc.example.spi.HelloServiceImpl
- Add SPI annotation for the interface class and set the default implementation to impl
@SPI("impl")
public interface HelloService {
void sayHello();
}- Implementation class invariant
public class HelloServiceImpl implements HelloService{
@Override
public void sayHello() {
System.out.printf("hello world!");
}
}- Call Dubbo SPI
public static void main(String[] args) {
//Get the interface helloservice through ExtensionLoader Default implementation of class
ExtensionLoader<HelloService> extensionLoader = ExtensionLoader.getExtensionLoader(HelloService.class);
HelloService helloService = extensionLoader.getDefaultExtension();
//hello world will be printed here
helloService.sayHello();
}Expansion point annotation
Comments on expansion points: @ SPI
@SPI annotations can be used on classes, interfaces and enumeration classes. They are all used on interfaces in the Dubbo framework. Its main function is to mark that this interface is a Dubbo SPI interface, that is, an extension point, which can have multiple different built-in or user-defined implementations. The runtime needs to find the specific implementation class through configuration@ The source code of SPI annotation is as follows.
@SPI annotation source code
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface SPI {
/**
* key name of default implementation
* default extension name
*/
String value() default "";
}We can see that the SPI annotation has a value attribute. Through this attribute, we can pass in different parameters to set the default implementation class of the interface. For example, we can see that the Transporter interface uses Netty as the default implementation. The code is as follows.
@SPI("netty")
public interface Transporter {
...
}In many places in Dubbo, getextension (Class < T > type, string name) is used to obtain the specific implementation of the extension point interface. At this time, the incoming Class will be verified to determine whether it is an interface and whether there are @ SPI annotations. Both are indispensable.
Extension point Adaptive annotation: @ Adaptive
@Adaptive annotations can be marked on classes, interfaces, enumerated classes and methods, but in the whole Dubbo framework, only a few places are used at the class level, such as adaptive extensionfactory and adaptive compiler, and the rest are marked on methods. If it is marked on the method of the interface, that is, method level annotation, the implementation class can be obtained dynamically through parameters. Method level annotation will automatically generate and compile a dynamic adaptive class when getExtension is first used, so as to achieve the effect of dynamically implementing the class.
Let me give an example. Take the Protocol interface as an example. The two methods of export and refer interface have added @ Adaptive annotation. The code is as follows. When Dubbo initializes the extension point, it will generate a Protocol$Adaptive class, which will implement the two methods. There will be some abstract general logic in the method through the parameters passed in @ Adaptive, Find and call the real implementation class. Readers familiar with the decorator pattern will easily understand the logic of this part. The specific implementation principle will be described later.
The following is the automatically generated Protocol$Adaptive#export implementation code, as shown below. Some irrelevant codes are omitted.
Protocol$Adaptive#export
public class Protocol$Adaptive implements org.apache.dubbo.rpc.Protocol {
public org.apache.dubbo.rpc.Exporter export(org.apache.dubbo.rpc.Invoker arg0) throws org.apache.dubbo.rpc.RpcException {
if (arg0 == null) throw new IllegalArgumentException("org.apache.dubbo.rpc.Invoker argument == null");
if (arg0.getUrl() == null)
throw new IllegalArgumentException("org.apache.dubbo.rpc.Invoker argument getUrl() == null");
org.apache.dubbo.common.URL url = arg0.getUrl();
//Find the name of the implementation class through the protocol key
String extName = (url.getProtocol() == null ? "dubbo" : url.getProtocol());
if (extName == null)
throw new IllegalStateException("Failed to get extension (org.apache.dubbo.rpc.Protocol) name from url (" + url.toString() + ") use keys([protocol])");
ScopeModel scopeModel = ScopeModelUtil.getOrDefault(url.getScopeModel(), org.apache.dubbo.rpc.Protocol.class);
//Try to get the real extension point implementation class according to the parameters in the url
org.apache.dubbo.rpc.Protocol extension = (org.apache.dubbo.rpc.Protocol) scopeModel.getExtensionLoader(org.apache.dubbo.rpc.Protocol.class).getExtension(extName);
//Finally, the bind method of the specific extension point will be called
return extension.export(arg0);
}
}We can see from the generated source code that many general functions are implemented in the automatically generated code, which will eventually call the real interface implementation.
When the annotation is placed on the implementation class, the entire implementation class will be directly used as the default implementation, and the above code will no longer be generated automatically. Among multiple implementations of the extension point interface, only one implementation can be annotated with @ Adaptive annotation. If multiple implementation classes have this annotation, an exception will be thrown: More than 1 adaptive class found@ The source code of Adaptive annotation is as follows.
Adaptive annotation source code
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface Adaptive {
//Multiple key s can be set in the array, which will be matched at one time in order
String[] value() default {};
}The annotation can also pass in the value parameter, which is an array. We can see in code listing 4.9 that Adaptive can pass in multiple key values. When initializing the interface of Adaptive annotation, the key values of the incoming URL will be matched first. If the first key does not match, the second key will be matched, and so on. Until all keys are matched, if they are not matched, the "Hump rule" will be used for matching. If they are not matched, an IllegalStateException will be thrown.
What is the "Hump rule"? If the wrapper class (Wrapper) does not specify the key value with Adaptive, Dubbo will automatically separate the interface names according to the hump case and connect them with symbols as the name of the default implementation class. For example, the YyylnvokerWrapper in org.apache.dubbo.xxx.YyylnvokerWpapper will be converted to yyy.invoker.wrapper.
Why do some implementations label @ adaptive on the implementation class?
On the implementation Class, it is mainly to directly fix the corresponding implementation without dynamically generating code implementation, just as the policy pattern directly determines the implementation Class. The implementation method in the code is: two @ Adaptive related objects will be cached in ExtensionLoader. One is cached in cacheddadaptive Class, that is, the Class type of the specific implementation Class of Adaptive; The other one is cached in cachedaptability instance, that is, the concrete instantiation object of Class. During extension point initialization, if it is found that the implementation Class has @ Adaptive annotation, it will be directly assigned to cacheddadaptiveclass. When the Class is instantiated later, the code will not be generated dynamically, cacheddadaptiveclass will be instantiated directly, and the instance will be cached in cacheddadaptivenstance. If the annotation is on the interface method, the implementation of the extension point will be dynamically obtained according to the parameters, and the Adaptive Class will be generated and cached in cacheddadaptivelnstance.
Extension point auto Activate annotation: @ Activate
@Activate can be marked on classes, interfaces, enumeration classes, and methods. It is mainly used in scenarios where multiple extension points are implemented and need to be activated according to different conditions. For example, multiple filters need to be activated at the same time because each Filter implements different functions. © Activate can pass in many parameters, as shown in the following table:
| Parameter name | effect |
|---|---|
| String[] group() | If the grouping in the URL matches, it is activated, and multiple can be set |
| String[] value() | If the search URL contains the key value, it will be activated |
| String[] before() | Fill in the extension point list to indicate which extension points should be before this extension point |
| String[] after() | The same as above indicates what needs to be after this extension point |
| int order() | Integer, direct sort information |
How ExtensionLoader works
ExtensionLoader is the main logical class of the whole extension mechanism. In this class, all work such as configuration loading, extension class caching, adaptive object generation and so on are sold. Let's talk about the workflow of the whole ExtensionLoader in combination with the code.
Workflow
The logical entry of ExtensionLoader can be divided into getExtension, getAdaptiveExtension and getActivateExtension. They are to obtain common extension classes, adaptive extension classes and automatically activated extension classes respectively. The overall logic starts from calling these three methods. Each method may have different overloaded methods, which can be adjusted according to different incoming parameters. The specific process is shown in the figure.
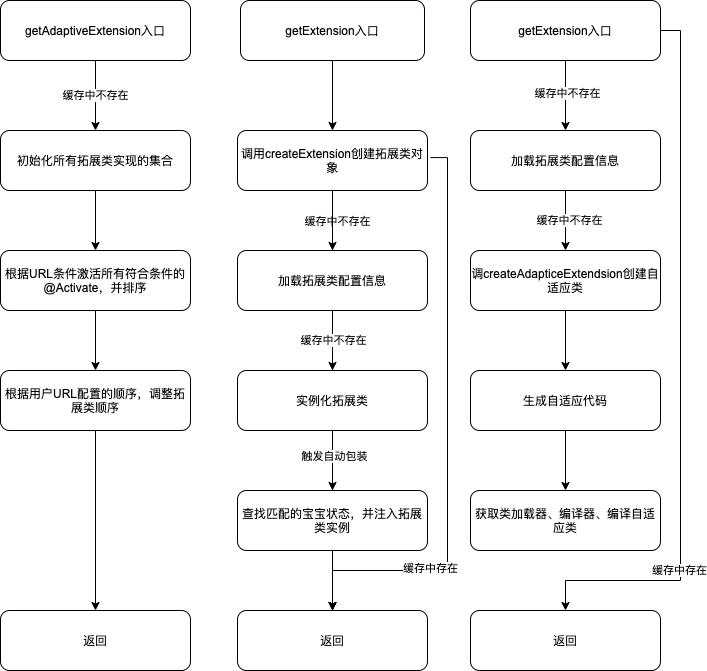
Among the three entries, getActivateExtension is more dependent on getExtension, while getadaptive extension is relatively independent.
The getActivateExtension method just activates multiple ordinary extension classes at the same time according to different conditions. Therefore, only some general judgment logic will be made in this method, such as whether the interface contains @ Activate annotation, whether the matching conditions are met, etc. Finally, the specific extension point implementation class is obtained by calling the getExtension method.
getExtension(String name) is the core method in the whole extension loader, which implements a complete normal extension class loading process. At each step of the loading process, it will first check whether the required data already exists in the cache. If it exists, it will be read directly from the cache, and if not, it will be reloaded. This method returns only one extension point implementation class by name at a time. The initialization process can be divided into four steps:
- The framework reads the configuration file under the corresponding path of SPI, loads all extension classes and caches them according to the configuration (not initialized).
- Initialize the corresponding extension class according to the passed in name.
- Try to find qualified wrapper classes: setter methods containing extension points, such as setProtocol(Protocol protocol) methods, will be automatically injected into the implementation of the protocol extension point; It contains the same constructor as the extension point type and injects an extension class instance for it. For example, a ClassA is initialized this time. After initialization, it will find the wrapper class that needs ClassA in the construction parameters, then inject the ClassA instance and initialize the wrapper class.
- Returns the corresponding extension class instance.
getAdaptiveExtension is also relatively independent. Only the loading configuration information part shares the same method with getExtension. Like getting ordinary extension classes, the framework will first check whether there are initialized Adaptive instances in the cache, and if not, call createadaptive extension to reinitialize. The initialization process is divided into four steps:
- Like getExtension, load the configuration file first.
- Generate the code string of the adaptive class.
- Get the class loader and compiler, and compile the code string just generated with the compiler. Dubbo has three types of compiler implementations, which will be explained in section 4.4.
- Returns the corresponding adaptive class instance.
Next, let's take a detailed look at the implementation of getExtension, getadaptive extension and getActivateExtension.
Implementation principle of getExtension
The main process of getExtension has been mentioned above. Let's talk about the implementation principle of each step in detail.
When calling the getExtension(String name) method, it will first check whether there is ready-made data in the cache. If not, it will call createExtension to start creation. There is a special point here. If the name passed in by getExtension is true, the default extension class will be loaded and returned.
During the process of calling createExtension to start creation, it will also check whether there is configuration information in the cache. If there is no extension class, it will read all configuration files from META-INF/services /, META-INF/dubbo /, META-INF/dubbo/internal /, read the character stream through I/O, and then parse the string, Get the full name of the corresponding extension point implementation class in the configuration file (such as org.apache.dubbo.common.extensionloader.activate.impl. Groupactivateeximpl). The source code of the extension point configuration information loading process is as follows.
Source code of extension point configuration information loading process
private Map<String, Class<?>> getExtensionClasses() {
// Gets the loaded extension class from the cache
Map<String, Class<?>> classes = cachedClasses.get();
// duplication check
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
// Start loading extension class
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
/**
* Synchronize in GetExtensionClass
* synchronized in getExtensionClasses
*/
private Map<String, Class<?>> loadExtensionClasses() {
//Check for SPI comments. If so, get the name filled in the annotation and cache it as the default implementation name.
//For example, @ SPI ("impl") will save impl as the default implementation
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
for (LoadingStrategy strategy : strategies) {
// Load the configuration file under the specified folder
loadDirectory(extensionClasses, strategy, type.getName());
// Compatible with legacy ExtensionFactory
if (this.type == ExtensionInjector.class) {
loadDirectory(extensionClasses, strategy, ExtensionFactory.class.getName());
}
}
return extensionClasses;
}
/**
* Load the configuration file under the specified folder
* @param extensionClasses
* @param strategy
* @param type
*/
private void loadDirectory(Map<String, Class<?>> extensionClasses, LoadingStrategy strategy, String type) {
//Load org apache. xxxxx
loadDirectory(extensionClasses, strategy.directory(), type, strategy.preferExtensionClassLoader(),
strategy.overridden(), strategy.excludedPackages(), strategy.onlyExtensionClassLoaderPackages());
String oldType = type.replace("org.apache", "com.alibaba");
//Load com alibaba. xxxxx
loadDirectory(extensionClasses, strategy.directory(), oldType, strategy.preferExtensionClassLoader(),
strategy.overridden(), strategy.excludedPackages(), strategy.onlyExtensionClassLoaderPackages());
}After the extension point configuration is loaded, all extension implementation classes are obtained through reflection and cached. Note that Class is only loaded into the JVM, but Class initialization is not done. When loading the Class file, the extension point type will be determined according to the annotation on the Class, and then cached according to the type classification. The cache classification code of the extension Class is as follows:
Cache classification of extended classes
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name,
boolean overridden) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error occurred when loading extension class (interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + " is not subtype of interface.");
}
// Detect whether there are Adaptive annotations on the target class
if (clazz.isAnnotationPresent(Adaptive.class)) {
// If multiple adaptive classes are found, set cacheddadaptiveclass cache
cacheAdaptiveClass(clazz, overridden);
// Detect whether clazz is a Wrapper type
} else if (isWrapperClass(clazz)) {
// If it is a wrapper class, store clazz it in the cachedWrapperClasses cache
cacheWrapperClass(clazz);
} else {
if (StringUtils.isEmpty(name)) {
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
cacheActivateClass(clazz, names[0]);
for (String n : names) {
//It is neither adaptive type nor wrapper type. The rest are ordinary extension classes, which will also be cached
//Note: automatic activation is also a kind of common extension class, but it will be activated at the same time according to different conditions
cacheName(clazz, n);
saveInExtensionClass(extensionClasses, clazz, n, overridden);
}
}
}
}Finally, find the corresponding class according to the passed in name and pass class The forname method initializes and injects other dependent extension classes (automatic loading feature) into it. After the extension class is initialized, the wrapper extension class set < class <? > will be checked once Wrapperclasses, find the constructor containing the same type as the extension point, and inject it with the newly initialized extension class.
Dependency injection
injectExtension(instance); // Inject dependencies into extended class instances
List<Class<?>> wrapperClassesList = new ArrayList<>();
wrapperClassesList.addAll(cachedWrapperClasses);
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
// Loop to create Wrapper instance
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
if (wrapper == null
|| (ArrayUtils.contains(wrapper.matches(), name) && !ArrayUtils.contains(wrapper.mismatches(), name))) {
// Pass the current instance as a parameter to the constructor of the Wrapper, and create the Wrapper instance through reflection.
// Then inject dependencies into the Wrapper instance, and finally assign the Wrapper instance to the instance variable again
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
instance = postProcessAfterInitialization(instance, name);
}
}
}In the injectExtension method, dependency attributes can be injected into the class. It uses extensionfactory #getextension (class < T > type, string name) to obtain the corresponding bean instance. This factory interface will be described in detail later. Let's first understand the implementation principle of injection.
The injectExtension method generally implements the IoC mechanism similar to Spring. Its implementation principle is relatively simple: first, obtain all the methods of the class through reflection, then traverse the methods starting with string set to obtain the parameter type of the set method, and then find the extension class instance with the same parameter type through ExtensionFactory. If found, set the value into it. The code is as follows.
Inject dependency extension class implementation code
for (Method method : instance.getClass().getMethods()) {
//Find a method starting with set, which must have only one parameter and be public
if (!isSetter(method)) {
continue;
}
/**
* Check whether this property needs to be injected automatically
* Check {@link DisableInject} to see if we need auto injection for this property
*/
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
// Get setter method parameter type
Class<?> pt = method.getParameterTypes()[0];
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
// Get the property name, such as the property name corresponding to the setName method
String property = getSetterProperty(method);
// Get dependent objects from ObjectFactory
Object object = injector.getInstance(pt, property);
if (object != null) {
// Set dependency by calling setter method through reflection
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("Failed to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}From the source code, we can know that the construction parameter injection of the wrapper class is also realized through the injectExtension method.
Implementation principle of getAdaptiveExtension
In the getAdaptiveExtension() method, an implementation class string will be automatically generated for the extension point interface. The implementation class mainly includes the following logic: a default implementation will be generated for each method with Adaptive annotation in the interface (an empty implementation will be generated for the method without annotation). Each default implementation will extract the Adaptive parameter value from the URL and dynamically load the extension point based on it. Then, the framework will use different compilers to compile the implementation class string into an Adaptive class and return it. This section mainly explains the implementation principle of string code generation.
The logic of generating code is mainly divided into 7 steps, and the specific steps are as follows:
- Generate header information such as package, import and class name. Only one class ExtensionLoader will be introduced here. In order not to write the import method of other classes, the full path is used when calling other methods. The class name will change to the format of "interface name + $Adaptive". For example, the Protocol interface will generate Protocol $Adaptive.
- Traverse all methods of the interface to obtain the return type, parameter type, exception type, etc. of the method. Prepare for step (3) to determine whether it is null.
- Generate a verification code with an empty parameter, such as whether the parameter is empty. If there is a remote call, a check with an empty Invocation parameter will also be added.
- Generate the default implementation class name. If © If no default value is set in the Adaptive annotation, it will be generated according to the class name. For example, YyylnvokerWrapper will be converted to YYY invoker. wrapper. The generated rule is to keep looking for capital letters and connect them with. After you get the default implementation class name, you also need to know which extension point this implementation is.
- Generate code to get the extension point name. Different acquisition codes are generated according to the key value configured in the @ Adaptive annotation. For example, if it is @ Adaptive("protocol"), a URL will be generated getProtocol() .
- Generate and obtain the specific extension implementation class code. Finally, the real implementation of the adaptive extension class is obtained through the getExtension(extName) method. If the corresponding implementation class is not found according to the key configured in the URL, the default implementation class name generated in step (4) will be used.
- Generate call result code.
Let's use Dubbo. The source code comes with a unit test to demonstrate the code generation process. The code is as follows.
Adaptive class generated code
//Configuration in SPI configuration file impl1=org.apache.dubbo.common.extension.ext1.impl.SimpleExtImpl1
@SPI
public interface HasAdaptiveExt {
//There are @ Adaptive annotations on the Adaptive interface and echo method
@Adaptive
String echo(URL url, String s);
}
//Call this adaptive class in the test method.
SimpleExt ext = ExtensionLoader.getExtensionLoader(HasAdaptiveExt.class).getAdaptiveExtension(); Generate adaptive code
package org.apache.dubbo.common.extension.adaptive;
import org.apache.dubbo.rpc.model.ScopeModel;
import org.apache.dubbo.rpc.model.ScopeModelUtil;
public class HasAdaptiveExt$Adaptive implements org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt {
public java.lang.String echo(org.apache.dubbo.common.URL arg0, java.lang.String arg1) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("has.adaptive.ext", "adaptive");
if(extName == null) throw new IllegalStateException("Failed to get extension (org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt) name from url (" + url.toString() + ") use keys([has.adaptive.ext])");
ScopeModel scopeModel = ScopeModelUtil.getOrDefault(url.getScopeModel(), org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt.class);
//The implementation class becomes org. In the configuration file apache. dubbo. common. extension. adaptive. impl. HasAdaptiveExt_ ManualAdaptive
org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt extension = (org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt)scopeModel.getExtensionLoader(org.apache.dubbo.common.extension.adaptive.HasAdaptiveExt.class).getExtension(extName);
return extension.echo(arg0, arg1);
}
}After generating the code, the code must be compiled to generate a new classo. The compiler in Dubbo is also an Adaptive interface, but the @ Adaptive annotation is added to the implementation class Adaptive compiler. In this way, the Adaptive compiler will be the default implementation of the Adaptive class and can be used without code generation and compilation.
If an interface has @ SPI("impl") annotation and a method has @ Adaptive("impl2") annotation, which key will be used as the default implementation? From the above dynamically generated SAdaptive class, we can know that the final dynamically generated implementation method will be URL Getparameter ("impl2", "impl"), that is, first find the extension implementation class through the key passed in the @ Adaptive annotation; if it is not found, find it through the key in the @ SPI annotation; if there is no default value in the @ SPI annotation, convert the class name to key and then find it.
Implementation principle of getActivateExtension
Next, the implementation principle of @ Activate starts with its entry method. Getactivateextension (URL, string key, string group) method can obtain all automatic activation extension points. The parameters are the URL, the key specified in the URL (separated by commas) and the group information (group)0 specified in the URL. The implementation logic is very simple. When calling this method, the main process is divided into four steps:
(1) Check the cache, if not in the cache, initialize the collection of all extension class implementations.
(2) Traverse the entire @ Activate annotation set, and get all extension class implementations that meet the activation conditions according to the incoming URL matching conditions (matching group, name, etc.). Then according to @ Activate. Sort by the before, after, order and other parameters configured in.
(3) Traverse all user-defined extension class names, adjust the activation order of extension points according to the order configured by the user URL, and follow the order configured by the user in the URL.
(4) Returns a collection of all automatic activation classes.
Get the implementation of the Activate Extension class, which is also obtained through getExtension. Therefore, getExtension can be regarded as the cornerstone of the other two extensions.
It should be noted that if - default is passed in the URL parameter, all default @ Activate will not be activated, and only the extension point specified in the URL parameter will be activated. If an extension point name beginning with a symbol is passed in, the extension point will not be activated automatically. For example: - xxxx indicates that the extension point named xxxx will not be activated.
Implementation principle of ExtensionInjector
After the previous introduction, we can know that the ExtensionLoader class is the core of the whole SPI. But how was the ExtensionLoader class itself created?
We know that the RegistryFactory class dynamically finds the registry through the @ adaptive (("Protocol"}) annotation, dynamically selects the corresponding registry factory according to the protocol parameter in the URL, and initializes the specific registry client. The ExtensionLoader class that implements this feature is created through the factory method ExtensionInjector#getInstance, and the injection interface also has SPI annotations and multiple implementations.
ExtensionInjector interface
@SPI
public interface ExtensionInjector {
/**
* Get instance of specify type and name.
*
* @param type object type.
* @param name object name.
* @return object instance.
*/
<T> T getInstance(Class<T> type, String name);
@Override
default void setExtensionAccessor(ExtensionAccessor extensionAccessor) {
}
}Since the injection interface has multiple implementations, how to determine which injection class to implement? We can see that the implementation class factory of Adaptive extensioninjector has @ Adaptive annotation. Therefore, the Adaptive extension injector will be the default implementation at the beginning. The relationship between injection classes is shown in the figure
<img src="https://qiniu-cdn.janker.top/oneblog/20220108200711372.png" style="zoom:50%;" />
As you can see, in addition to adaptive extensioninjector, there are two implementation classes, SpiExtensionInjector and SpringExtensionInjector. In other words, in addition to obtaining extension point instances from the container managed by Dubbo SPI, we can also obtain them from the Spring container.
So how do you get through between Dubbo and the spring container? Let's first look at the implementation of spring extensioninjector. This injection class provides a method to initialize the spring context. Before use, it will call the init method to initialize the spring context in spring extensioninjector. When calling getInstance to get the extension class, the context is ready. If it does not return null, continue to execute getOptionalBean (get Bean), if any. The code is as follows
private ApplicationContext context;
public ApplicationContext getContext() {
return context;
}
public void init(ApplicationContext context) {
this.context = context;
}
public <T> T getInstance(Class<T> type, String name) {
if (context == null) {
// ignore if spring context is not bound
return null;
}
//check @SPI annotation
if (type.isInterface() && type.isAnnotationPresent(SPI.class)) {
return null;
}
T bean = getOptionalBean(context, name, type);
if (bean != null) {
return bean;
}
//logger.warn("No spring extension (bean) named:" + name + ", try to find an extension (bean) of type " + type.getName());
return null;
}
When was the Spring context saved? We can learn from code search that static methods will be called in ReferenceBean and ServiceBean to save the Spring context, that is, when a service is published or referenced, the corresponding Spring context will be saved.
Let's take another look at SpiExtensionInjector, which is mainly to obtain the Adaptive implementation class corresponding to the extension point interface. For example, if an extension point implementation class ClassA has @ Adaptive annotation, calling SpiExtensionInjector#getInstance will directly return the ClassA instance. The code is as follows.
SpiExtensionInjector source code
public <T> T getInstance(Class<T> type, String name) {
if (type.isInterface() && type.isAnnotationPresent(SPI.class)) {
ExtensionLoader<T> loader = extensionAccessor.getExtensionLoader(type);
if (loader == null) {
return null;
}
//Get all extension point loaders by type
if (!loader.getSupportedExtensions().isEmpty()) {
return loader.getAdaptiveExtension();
}
}
return null;
}After some circulation, we finally returned to the default implementation of Adaptive extensionninjector, because the injection class has @ Adaptive annotation. The default injector obtains all extension injection classes in the initialization method and caches them, including SpiExtensionnInjector and SpringExtensionnInjector. The initialization method of Adaptive extensioninjector is as follows.
//Expand syringe collection
private List<ExtensionInjector> injectors = Collections.emptyList();
public void initialize() throws IllegalStateException {
//Gets the ExtensionLoader for the extension
ExtensionLoader<ExtensionInjector> loader = extensionAccessor.getExtensionLoader(ExtensionInjector.class);
List<ExtensionInjector> list = new ArrayList<ExtensionInjector>();
//Get supported extension classes
for (String name : loader.getSupportedExtensions()) {
//Get the extension class name through the extension class name and add it to the injectors in the collection
list.add(loader.getExtension(name));
}
injectors = Collections.unmodifiableList(list);
}The factories cached by adaptive extension injector will be sorted by TreeSet, with SPI in the front and Spring in the back. When the getInstance method is called, it will traverse all factories and obtain the extension class from the SPI container first; If not, look in the Spring container again. We can understand that adaptive extensionninjector holds all the specific factory implementations. Its getInstance method only traverses all the factories it holds, and finally calls the getInstance method implemented by SPI or Spring factory. The getInstance method code is as follows:
public <T> T getInstance(Class<T> type, String name) {
//Traverse all factories to find them in the order of SPI - > spring
for (ExtensionInjector injector : injectors) {
T extension = injector.getInstance(type, name);
if (extension != null) {
return extension;
}
}
return null;
}Implementation principle of extension point dynamic compilation
The adaptive feature of Dubbo SPI makes the whole framework very flexible, and dynamic compilation is the basis of the adaptive feature, because the dynamically generated adaptive Class is only a string, which needs to be compiled to get the real Class. Although we can use reflection to dynamically proxy a Class, there is a certain gap between the performance and the directly compiled Class. Dubbo SPI flexibly creates new adaptive classes based on the original classes through dynamic code generation and dynamic compiler. The following describes the types and corresponding implementation principles of Dubbo SPI dynamic compiler.
overall structure
There are three code compilers in Dubbo: JDK Compiler, Javassist Compiler and adaptive Compiler. These compilers all implement the Compiler interface, and the relationship between Compiler classes is shown in the figure
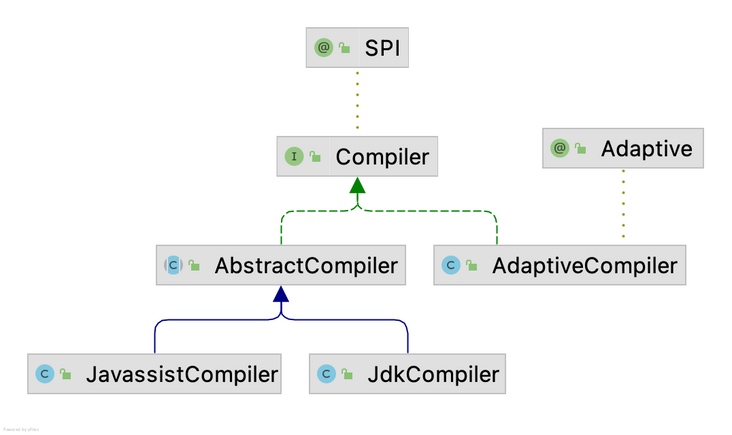
The Compiler interface contains an SPI annotation. The default value of the annotation is @ SPI("javassist"). Obviously, the javassist Compiler will be the default Compiler. If the user wants to change the default Compiler, it can be configured through the < Dubbo: application Compiler = "JDK" / > tag.
The @ Adaptive annotation on the Adaptive Compiler indicates that the Adaptive Compiler will be fixed as the default implementation. The main function of this Compiler is similar to that of the Adaptive extensioninjector to manage other compilers. The code is as follows:
Adaptive compiler logic
public static void setDefaultCompiler(String compiler) {
//Sets the default compiler name
DEFAULT_COMPILER = compiler;
}
@Override
public Class<?> compile(String code, ClassLoader classLoader) {
Compiler compiler;
ExtensionLoader<Compiler> loader = frameworkModel.getExtensionLoader(Compiler.class);
String name = DEFAULT_COMPILER; // copy reference
if (name != null && name.length() > 0) {
compiler = loader.getExtension(name);
} else {
compiler = loader.getDefaultExtension();
}
//Obtain the corresponding translator extension class implementation through ExtensionLoader, and call the real compile for compilation
return compiler.compile(code, classLoader);
}The adaptive compiler #setdefaultcompiler method will be called in ApplicationConfig, that is, when Dubbo starts, it will parse the < Dubbo: application compiler = "JDK" / > tag in the configuration, obtain the set value and initialize the corresponding compiler. If there is no label setting, use the setting in @ SPI("javassist"), that is, JavassistCompiler. Then take a look at AbstpactCompiler. It is an abstract class that cannot be instantiated, but it encapsulates general template logic. It also defines an abstract method doCompile, which is left to subclasses to implement specific compilation logic. Both JavassistCompiler and JdkCompiler implement this abstract method.
The main Abstract Logic of AbstractCompiler is as follows:
- Through regular matching, the package path and class name are obtained, and then the full path class name is spliced according to the package path and class name.
- Try to pass class Forname loads the class and returns to prevent repeated compilation. If the class does not exist in the class loader, proceed to step 3.
- Call the doCompile method to compile. This abstract method is implemented by subclasses. The following describes the specific implementation of the two compilers.
The following describes the specific implementation of the two compilers.
Javassist dynamic code compilation
There are many ways to dynamically generate classes in Java, which can be generated directly based on bytecode. Common tool libraries include CGLIB, ASM, Javassist, etc. The adaptive extension point uses the method of generating string code and then compiling it into Class.
The implementation principle of javassistcompiler in Dubbo is also very clear. Since we have generated code strings before, in JavassistCompiler, we constantly match the different parts of the code through regular expressions, then call the API in the Javassist library to generate code from different parts, and finally get a complete Class object. The specific steps are as follows:
(1) Initialize Javassist and set default parameters, such as the current classpath.
(2) Match out all imported packages through regular matching, and add import using Javassist.
(3) Match all extensions packages through regular matching, create Class objects, and add extensions using Javassist.
(4) Match out all the implements packages through regular matching, and add the implements using Javassist.
(5) Match all the contents in the class through regular matching, that is, get the contents in {}, then match all the methods through regular matching, and use Javassist to add class methods.
(6) Generate Class object.
JavassistCompiler inherits the abstract class Abstractcompiler and needs to implement an abstract method doCompileo defined by the parent class. The above steps are the implementation of the whole doCompile method in JavassistCompiler.
JDK dynamic code compilation
JdkCompiler is another implementation of the Dubbo compiler. It uses the JDK built-in compiler. The native JDK compiler package is located in javax Tools. It mainly uses three things: javafileobject interface, ForwardingJavaFileManager interface and javacompiler Compilationtask method. The whole dynamic compilation process can be briefly summarized as follows: first initialize a JavaFileObject object, and introduce the code string into the construction method as a parameter, then call JavaCompiler.. Compilementtask method compiles concrete classes. The java file manager is responsible for managing the input / output locations of class files. The following is a brief description of each interface / method:
- JavaFileObject interface. The string code is wrapped into a file object and provides an interface to get the binary stream. The JavaFileObjectlmpl class in the Dubbo framework can be regarded as an extended implementation of the interface. The generated string code needs to be passed in the construction method. The input and output of this file object are ByteArray streams. Since the relationship between SimpleJavaFileObject and JavaFileObject belongs to the knowledge of JDK, it will not be explained in depth in this article. Interested readers can view the JDK source code by themselves.
- JavaFileManager interface. It mainly manages the reading and output location of files. There is no implementation class that can be used directly in JDK, and the only implementation class ForwardingJavaFileManager constructor is of protected type. Therefore, a JavaFileManagerlmpl class is customized in Dubbo, and the resources are loaded through a custom class loader classloader lmpl.
- JavaCompiler. The compilation task compiles JavaFileObject objects into concrete classes.
Summary
This chapter has a lot of content. First, it introduces some general information of Dubbo SPI, including the differences between Dubbo SPI and Java SPI, the new features of Dubbo SPI, configuration specifications and internal cache. Secondly, it introduces the three most important annotations in Dubbo SPI: @ SPI, @ Adaptive, @ Activate, and explains the function and implementation principle of these annotations. Then, combined with the source code of the ExtensionLoader class, this paper introduces the three key entries in the whole Dubbo SPI: getExtension, getadaptive extension and getActivateExtension, and explains the working principle of the factory that creates the ExtensionLoader (ExtensionInjector). Finally, the implementation principle of dynamic compilation in Adaptive mechanism is explained.
Wechat search: share Java dry goods, make friends and join the technical exchange group
