The previous article explained the use and source code of zookeeper, so this time we continue to understand the relevant contents of dubbo, the golden partner of zookeeper. Of course, dubbo is also a typical rpc framework, so we analyze it one by one from the client and server, and there are a series of subsequent articles. Take your time.
SPI mechanism
Before analyzing dubbo's source code, first analyze dubbo's SPI mechanism. The overall design of dubbo is a micro kernel architecture. The micro kernel architecture is to write the main process and provide a set of plug-in search mechanism at the same time. At each process point of the main process, find the corresponding plug-in according to the configuration to complete the specific work, so that each process point can be customized, which provides great convenience for developers. (in dubbo, plug-ins are also called extension points)
The plug-in search mechanism in dubbo is SPI mechanism. As for why it is called SPI, there is also a set of SPI mechanism (full name: Service Provider Interface) and service discovery mechanism in Java. dubbo itself extends this set of mechanism. Then we can start with Java SPI.
The Java SPI mechanism can be analyzed by the following code. First write an interface, then two implementation classes of this interface, and finally a test class of JavaSpi. A very simple piece of logic. First build a ServiceLoader object in the test class, then obtain the iterator in the object, and finally judge whether there is a value in the iterator. If so, accept it with the interface just created, Then call the corresponding method. In fact, we can infer the iterator What is returned in the next () code is the instance of the interface, that is, the two implementation classes created above. As for how to do it, go on.
public interface Robot {
void sayHello();
}
public class Bumblebee implements Robot{
@Override
public void sayHello() {
System.out.println("Hello, I am Bumblebee.");
}
}
public class OptimusPrime implements Robot{
@Override
public void sayHello() {
System.out.println("Hello, I am Optimus Prime.");
}
}
public class JavaSpiTest {
@Test
public void testSayHello() {
//Create a ServiceLoader object,
ServiceLoader<Robot> serviceLoader = ServiceLoader.load(Robot.class);
//serviceLoader.forEach(Robot::sayHello);
//Get all instance information collections under the service
Iterator<Robot> iterator = serviceLoader.iterator();
/**
* Loop to create all service instances and execute corresponding methods
*/
while (iterator.hasNext()) {
/**
* Get a service instance
*/
Robot robot = iterator.next();
//Call instance method
robot.sayHello();
}
// serviceLoader.forEach(Robot::sayHello);
}
}The first thing you need to know is what the ServiceLoader object is, and its location is in Java The Iterable iterator interface is implemented under the util package. The specific Chinese meaning translates to: Service loader. In fact, we don't need to care about it here. We just need to know that there is an object provided by Java that can build service loading. Specifically, we need to look at the hasNext method and next method after obtaining the iterator. The code above is below. It should be noted that the iterator obtained above is the lazyitterer object, so the code of hasNext method and next method is also in the lazyitterer object.

From the following code, we can see that the real call of the hasNext method returns the hasNextService method, and the code of the hasNextService method can see that the value of the fullName variable is: META-INF/services / interface path, and then use this variable value to obtain the configuration file information, and finally assign it to nextName. In the following next method, that is, in the called nextService method, the nextName variable will be used to obtain the specific instance object and return it.
In other words, as long as you write a file with the name of the interface path under the path META-INF/services /, and then write the corresponding implementation class path in the file, you can load it. So if the above test class wants to succeed, it also needs a name: com spi. jdk. Robot file, in which the path corresponding to the two implementation classes should be written.
private static final String PREFIX = "META-INF/services/";
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}Java SPI is actually a dynamic loading mechanism realized by the combination of "interface based programming + policy mode + configuration file". So let's talk about Java SPI first. Let's see how dubbo's SPI is implemented.
From the above Java SPI mechanism, it is not difficult to see that its biggest disadvantage is that it can not obtain the implementation on demand. If the desired implementation class can only be obtained through iteration and then judged, dubbo also said that its SPI is the SPI implementation of basic Java, so dubbo's microkernel design must not obtain different implementations through iteration like Java SPI, Therefore, dubbo's SPI is written in the form of key value pairs, and different implementations are found through keys. Let's take a look at how dubbo is implemented.
ExtensionLoader
As mentioned above, dubbo does not use Java SPI, but implements a set of more powerful SPI mechanism. The extension class can be loaded into the specified SPI through the loader logic. Next, use a section of test class code to lead to the specific logic of ExtensionLoader class.
public class DubboSpiTest {
//Testing dubbo spi mechanism
@Test
public void sayHello() throws Exception {
//1. Get the extensionloader of the interface
ExtensionLoader<Robot> extensionLoader = ExtensionLoader.getExtensionLoader(Robot.class);
//2. Get the corresponding instance according to the specified name
Robot robot = extensionLoader.getExtension("optimusPrime");
robot.sayHello();
Robot optimusPrime = extensionLoader.getExtension("optimusPrime");
optimusPrime.sayHello();
Robot robot2 = extensionLoader.getDefaultExtension();
robot2.sayHello();
}
}The first thing we see above is the acquisition of ExtensionLoader class. An ExtensionLoader object is obtained through the getExtensionLoader method of ExtensionLoader object, and the input parameter is the interface class. Here's the code to see what it contains.
When entering the getExtensionLoader method, the first thing to judge is that the input parameter object cannot be empty, it must be an interface, and this interface must be SPI Class annotation modification, and then in extension_ Get the ExtensionLoader object corresponding to the current input parameter interface in the loaders collection. If there is a direct return, otherwise, an ExtensionLoader object belonging to the input parameter interface will be created and stored in EXTENSION_LOADERS set, and then return. The content created here is over.
It should be noted that extension_ The loaders collection is the ConcurrentMap object, and the parent object of the ConcurrentMap object is the map object, and extension_ The static constants declared by the loaders collection. Here dubbo actually uses this collection for global caching. The key of the map collection is the input parameter interface object, and the value is the exclusive ExtensionLoader object.
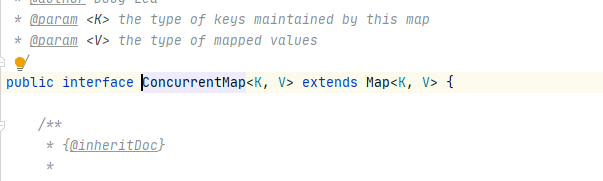
private static final ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<>();
private static <T> boolean withExtensionAnnotation(Class<T> type) {
return type.isAnnotationPresent(SPI.class);
}
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
/**
* check
* 1,Not empty
* 2,It's an interface
* 3,The @ SPI annotation is required on the interface
*/
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
/**
* Start with extension_ From loaders (loaded ExtensionLoader)
* Each interface type corresponds to an ExtensionLoader, which corresponds to multiple extension points
*/
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type)); // Each interface type corresponds to an ExtensionLoader
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}When the ExtensionLoader object corresponding to the interface is obtained, it goes to the place where getExtension obtains the implementation class. The input parameter here is the key of the key value pair implemented in dubbo SPI, and the value is the specific implementation class. See the code in detail.
The code is also very simple at first glance. The first step is to judge that the input parameter cannot be empty or the character true. The second step is to use the getOrCreateHolder method to obtain the Holder object. If there is a return, on the contrary, call the createExtension method to create an instance and then return. What needs to be noted here is the Holder object, which itself has only one value attribute, However, the value attribute is modified by volatile key value, and the following code is written to realize the singleton mode, that is, the Holder object corresponding to the input parameter must be unique. (the key usage of volatile and the implementation of singleton mode will not be repeated here)
Then analyze the getOrCreateHolder method and createExtension method. The getOrCreateHolder method is very simple (this is good code, low coupling and high readability). The purpose of this method is to obtain the instance object according to the input parameters in the cachedInstances collection. If there is no data in the collection, create a Holder object and store it in the collection. Note: the set here is different from the set above. The set above is a global static constant set and here is a private constant set. In other words, this collection can only be used in the current class, and the whole project above can be used.
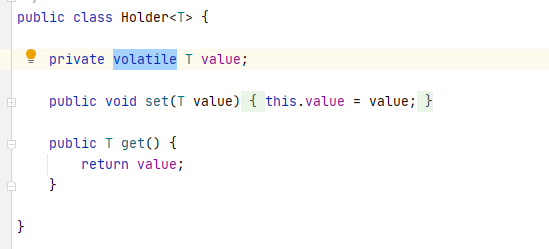
// Cache all instance key s and corresponding holders
private final ConcurrentMap<String, Holder<Object>> cachedInstances = new ConcurrentHashMap<>();
/**
* Find the extension with the given name. If the specified name is not found, then {@link IllegalStateException}
* will be thrown.
*/
@SuppressWarnings("unchecked")
public T getExtension(String name) {
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
/**
* name key configured in the configuration file under META-INF/dubbo
*
* 1,Get the Holder of the Extension instance corresponding to the key (double lock verification) - > getorcreateholder internally caches all instance keys and corresponding holders through cachedInstances
* 2,Create the Extension instance corresponding to the key and store it in the holder
* 3,Return the corresponding Extension instance
*/
final Holder<Object> holder = getOrCreateHolder(name);
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//The core method of creating instances
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}
private Holder<Object> getOrCreateHolder(String name) {
/**
* cachedInstances: Cache all instance key s and corresponding holders
*/
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<>());
holder = cachedInstances.get(name);
}
return holder;
}Continue to look at the createExtension method. Here is the key content of dubbo SPI. The code is relatively long. Let's talk about the logic in the createExtension method in sections.
The first step is to call the getExtensionClasses method according to the input parameter to obtain the corresponding instance class (this is not obtained by the get method. The getExtensionClasses method returns a collection, and get is the value taking method of the collection). Then it is to judge that if the instance is empty, an exception will be thrown directly, Then it can be judged that this method is to obtain existing instances or create non existing instances.
Step 2: save the instance object into extension_ The instances collection. Note that this collection is not the same as the private static constant collection above. It is also used for global caching. The key of this collection is the instance class object and the value is the initialization of the instance object.
The third step is to inject the dependent instance into the instance. What does this mean? I'll explain it later.
The fourth step is to assemble it into the Wrapper. This can be understood as dubbo's AOP, which is face-to-face. The enhancement and configuration of instances will be described in detail later. At this point, the method ends, and then returns the created instance.
// Cache all instance classes and corresponding instance objects
private static final ConcurrentMap<Class<?>, Object> EXTENSION_INSTANCES = new ConcurrentHashMap<>();
/**
* Create the corresponding extension instance according to name
* @param name Instance key
* @return
*/
@SuppressWarnings("unchecked")
private T createExtension(String name) {
// Get the Class of the corresponding instance according to the key
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
/**
* 1,Create extension instance
*/
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
/**
* Inject the instance on which it depends into the instance
*/
injectExtension(instance);
/**
* Assemble into Wrapper
*/
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
//Traverse the Class of Wrapper type
for (Class<?> wrapperClass : wrapperClasses) {
/**
* Wrap the current instance into the Wrapper, inject dependencies into the Wrapper through structural injection, and wrap the instance through the Wrapper, so as to enhance the method in the Wrapper method; It is the key to realize AOP
*/
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}Let's continue to look at the getExtensionClasses method in the first step. Let's start with the code, because there are too many logic in the back. I'll choose a relatively important logic. It's impossible to turn over all the logic of dubbo here. Later, you can find the annotated source code of dubbo in my download resources and read it for yourself.
In the code, you can see that the first thing you get is the set of cachedClasses cache objects, which is the set of instance objects of the interface of the current expansion point. The later code implementation is the dcl writing method of singleton mode, that is, to ensure that there is only one cachedClasses cache object in the current project, Finally, call the loadExtensionClasses method to create an interface instance and put it into the cache.
The specific code of loadExtensionClasses method is not analyzed completely. The purpose of this method is to load the extension class configuration from the specified location. Let's look at the first loaddirectory (map < string, class <? > > extensionclasses, string dir, string type) method. The specific code is not displayed, and the concrete logic is to splice the file directory address which needs to be read according to the string of the input, then determine whether it is correct and assemble into URL object, and finally call loadResource method. The loadResource method is to read the information from the file and encapsulate it into the object, then invoke the loadClass method. The loadclass method encapsulates the last extension point. See the following code for details.
// Cache all instance key s under the interface type and the Class corresponding to the instance
private final Holder<Map<String, Class<?>>> cachedClasses = new Holder<>();
/**
* Get extended Class
* @return
*/
private Map<String, Class<?>> getExtensionClasses() {
// Holder<Map<String, Class<?>>> cachedClasses
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
// synchronized in getExtensionClasses
private Map<String, Class<?>> loadExtensionClasses() {
cacheDefaultExtensionName();
/**
* loadDirectory Method loads the extension class configuration from the specified location
* "META-INF/dubbo/internal/" DubboInternalLoadingStrategy
* "META-INF/dubbo/", DubboLoadingStrategy
* "META-INF/services/", ServicesLoadingStrategy
*/
Map<String, Class<?>> extensionClasses = new HashMap<>();
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName());
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName());
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName());
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
return extensionClasses;
}
The loadClass method code is as follows. Firstly, there are three situations in the extension point itself. In the first extension point, there is @ Adaptive annotation. If so, it will be stored in the cached Adaptive class cache object. In addition, it can be seen from the code that an extension point can only exist in one interface object; The second extension point class has the constructor of interface type, which indicates that it is the extension point of Wrapper and will be stored in the cachedWrapperClasses cache collection. There can be multiple interfaces of this kind; The third is the ordinary extension point. This one is to assign values to the incoming extension point set.
To sum up, the code flow of the previous step and the flow of this step are to obtain all the instances corresponding to the current extension point. As for why it is the current extension point, in fact, when we obtain the extension point in the first step, we have stored the interface in the private constant, that is to say, the cache in the extension point of my current interface has only the corresponding instance cache, The cache of my current interface is stored in the global constant cache of my whole project.

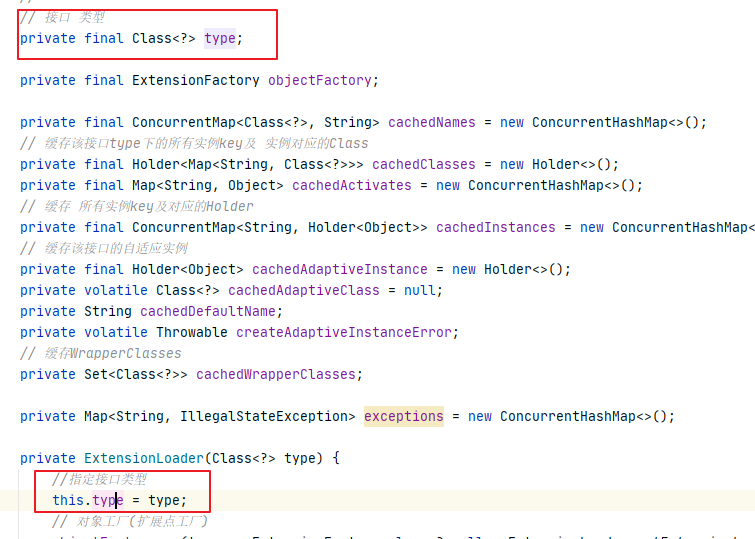
private volatile Class<?> cachedAdaptiveClass = null;
// Cache WrapperClasses
private Set<Class<?>> cachedWrapperClasses;
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("Error occurred when loading extension class (interface: " +
type + ", class line: " + clazz.getName() + "), class "
+ clazz.getName() + " is not subtype of interface.");
}
if (clazz.isAnnotationPresent(Adaptive.class)) {
// The extension point Class has Adaptive annotation
cacheAdaptiveClass(clazz);
} else if (isWrapperClass(clazz)) { // The extension point class has a constructor of interface type, indicating that it is a Wrapper
// Add to set < class <? > > Cachedwrapperclasses are cached
cacheWrapperClass(clazz);
} else { // Prove to be ordinary extensionClasses
clazz.getConstructor();
if (StringUtils.isEmpty(name)) {
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL);
}
}
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
cacheActivateClass(clazz, names[0]);
for (String n : names) {
cacheName(clazz, n);
saveInExtensionClass(extensionClasses, clazz, n);
}
}
}
}
/**
* cache Adaptive class which is annotated with <code>Adaptive</code>
*/
private void cacheAdaptiveClass(Class<?> clazz) {
if (cachedAdaptiveClass == null) {
cachedAdaptiveClass = clazz;
} else if (!cachedAdaptiveClass.equals(clazz)) {
throw new IllegalStateException("More than 1 adaptive class found: "
+ cachedAdaptiveClass.getClass().getName()
+ ", " + clazz.getClass().getName());
}
}
/**
* cache wrapper class
* <p>
* like: ProtocolFilterWrapper, ProtocolListenerWrapper
*/
private void cacheWrapperClass(Class<?> clazz) {
if (cachedWrapperClasses == null) {
cachedWrapperClasses = new ConcurrentHashSet<>();
}
cachedWrapperClasses.add(clazz);
}
/**
* put clazz in extensionClasses
*/
private void saveInExtensionClass(Map<String, Class<?>> extensionClasses, Class<?> clazz, String name) {
Class<?> c = extensionClasses.get(name);
if (c == null) {
extensionClasses.put(name, clazz);
} else if (c != clazz) {
throw new IllegalStateException("Duplicate extension " + type.getName() + " name " + name + " on " + c.getName() + " and " + clazz.getName());
}
}The above calculation basically completes the first step of the createExtension method. Then continue to the next step. I won't show the code again. Let's continue to look at the screenshot. After the cache of the instance is completed and the specific instance is obtained with the passed in key, note that the instance is only the class object corresponding to the key written in the configuration file. The real initialization is in the next step. Here, the initialization object is stored in the private constant cache extension mentioned above_ In the instances collection, that is to say, this is equivalent to lazy loading. When a specific key is passed in, the corresponding instance object for initialization will be loaded.
The next step of injectExtension method is to inject the dependent instance into the instance. Let's see the specific code below. What you can see in the following code segment is that if you want to inject an instance into an instance, it must be a set method with parameters, and the parameters are consistent with the method name (the method name minus the set character). When these conditions are met, an instance will be created using the objectFactory factory object, The objectFactory factory object is also created when the extension point is created in the first step. Interestingly, the factory object is also an extension point modified by @ SPI annotation. There are four instances. We choose the implementation of SPI. See the code below.
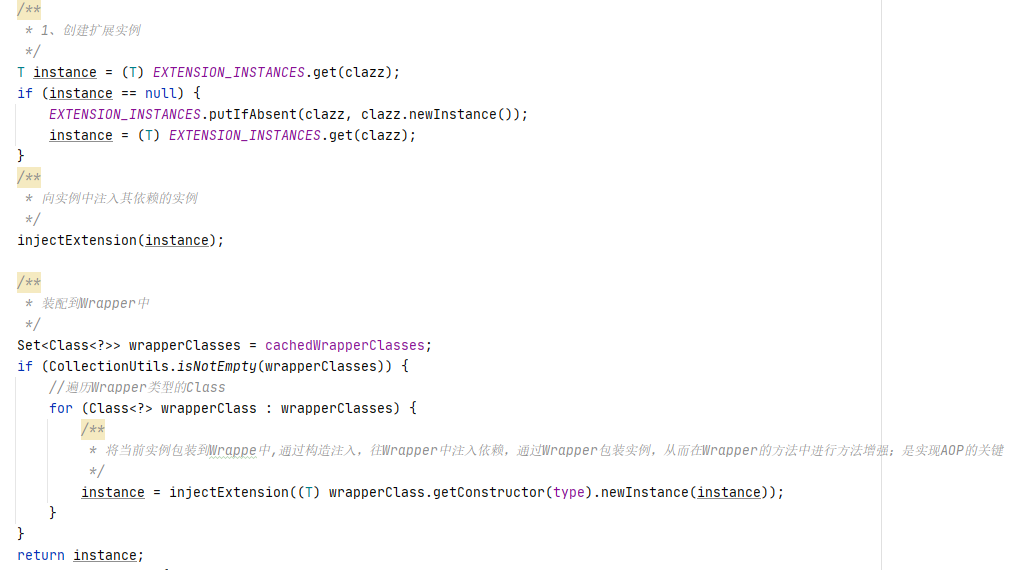
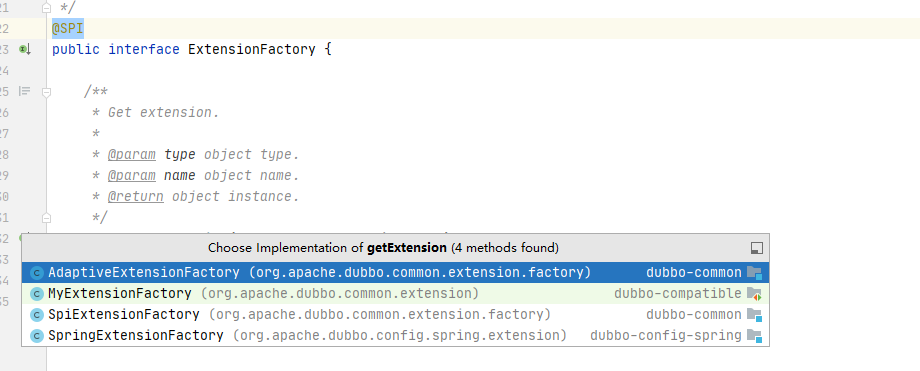
private T injectExtension(T instance) {
try {
if (objectFactory != null) {
for (Method method : instance.getClass().getMethods()) {
/**
* Injection through set method
*/
if (isSetter(method)) {
/**
* Check {@link DisableInject} to see if we need auto injection for this property
*/
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
// The set method can only have one parameter
Class<?> pt = method.getParameterTypes()[0];
// If the type of the set method parameter is the basic data type, it will be skipped, that is, the injection of the basic data type is not supported
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
// Gets the property name corresponding to the set method
String property = getSetterProperty(method);
/**
* pt:Attribute type Class
* property:Attribute name
*
* Obtain the Extension instance to be injected according to the type and name
* ExtensionFactory objectFactory;
* There are many implementations, such as:
* SpiExtensionFactory
* SpringExtensionFactory
*/
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("Failed to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}It can be seen that this step is also to obtain the extension point corresponding to the interface first. Of course, judge whether it is modified by @ SPI annotation. When it is confirmed to be an extension point, then obtain the adaptive instance of the extension point.
We can see the second code, that is, the old-fashioned way to fetch the cache. If the cache does not exist, create an instance and then put it into the cache. The key point is to create the instance. You can see in the getAdaptiveExtensionClass method that the value will be fetched in the cacheddadaptiveclass cache. If it does not exist, Will generate the Java source code of adaptive classes (I won't explain this paragraph because I don't understand it). It should be noted that the cacheddadaptiveclass cache that we have learned so far can only save value when loading the configuration file, but the configuration file was not loaded in the previous step, that is, when obtaining the extension point of the first section of code, so it must be injected with the generated java source code, As for the injection method, it is the injectExtension method (this is very simple and not shown. It is to obtain the set method, initialize the object of the produced java source code, pass it in by entering parameters, and then execute the method).
/**
* SpiExtensionFactory
*/
public class SpiExtensionFactory implements ExtensionFactory {
@Override
public <T> T getExtension(Class<T> type, String name) {
if (type.isInterface() && type.isAnnotationPresent(SPI.class)) {
ExtensionLoader<T> loader = ExtensionLoader.getExtensionLoader(type);
if (!loader.getSupportedExtensions().isEmpty()) {
return loader.getAdaptiveExtension();
}
}
return null;
}
}
@SuppressWarnings("unchecked")
public T getAdaptiveExtension() {
// Holder<Object> cachedAdaptiveInstance
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
if (createAdaptiveInstanceError == null) {
synchronized (cachedAdaptiveInstance) {
instance = cachedAdaptiveInstance.get();
if (instance == null) {
try {
// Create an adaptive instance of the interface
instance = createAdaptiveExtension();
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("Failed to create adaptive instance: " + t.toString(), t);
}
}
}
} else {
throw new IllegalStateException("Failed to create adaptive instance: " + createAdaptiveInstanceError.toString(), createAdaptiveInstanceError);
}
}
return (T) instance;
}
@SuppressWarnings("unchecked")
/**
* Create an adaptive instance of the interface
*/
private T createAdaptiveExtension() {
try {
// getAdaptiveExtensionClass() is the core
return injectExtension((T) getAdaptiveExtensionClass().newInstance());
} catch (Exception e) {
throw new IllegalStateException("Can't create adaptive extension " + type + ", cause: " + e.getMessage(), e);
}
}
private Class<?> getAdaptiveExtensionClass() {
getExtensionClasses();
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
/**
* Get interface adaptation instance Class
*/
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
private Class<?> createAdaptiveExtensionClass() {
/**
* First, the Java source code of the adaptive class will be generated, and then the source code will be compiled into Java bytecode and loaded into the JVM
* Use a StringBuilder to build the Java source code of the adaptive class;
* This way of generating bytecode is also very interesting. Sir, it can be converted into Java source code, compiled and loaded into the jvm.
* In this way, you can better control the generated Java classes. Moreover, there is no need to care about the api of each bytecode generation framework.
* Because XXX Java files are common to Java and we are most familiar with them. But the readability of the code is not strong, and XX needs to be built bit by bit Java content
*/
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
ClassLoader classLoader = findClassLoader();
/**
* @SPI("javassist")
* public interface Compiler
*/
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(code, classLoader);
}The above is the specific content of the injectExtension method. The harder thing is to dynamically generate Java source code and so on. Returning to the createExtension method, the next step is to assemble the Wrapper instance. The first step is to obtain the class object previously stored in the cachedWrapperClasses cache (that is, the getExtensionClasses method), then wrap the current instance into the Wrapper, inject dependencies into the Wrapper through structure injection, and wrap the instance through the Wrapper, Thus, method enhancement in Wrapper's method is the key to realizing AOP.

The above is an analysis of Java SPI and dubbo SPI. Some points may not be explained accurately. Specifically, I have to turn over the source code by myself. Each has a different understanding, and I can't guarantee that my understanding is comprehensive. If I have any questions in the process of turning over the source code, I can leave a message in the comment area, and I will reply after reading it, The next article officially starts the analysis of dubbo process source code.