Book constructor
The Book object is divided into two scenarios:
- Parse the Book object directly from the e-Book file
- Generate Book object from data object
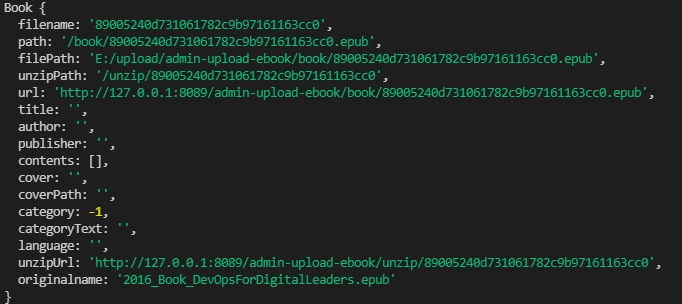
class Book {
constructor(file, data) {
if (file) {
this.createBookFromFile(file)
} else {
this.createBookFromData(data)
}
}
createBookFromFile(file) {
console.log('createBookFromFile', file)
}
createBookFromData(data) {
console.log('createBookFromData', data)
}
}
module.exports = Book
Create a Book object from a file
Add the following three constants in utils\constant.js:
- MimeType may be application/epub or application/epub+zip. Here, I use the StartWith method of string to judge
const { env } = require('./env')
const UPLOAD_PATH =
env === 'dev' ? 'E:/upload/admin-upload-ebook' : '/root/upload/admin-upload-ebook'
const UPLOAD_URL = env === 'dev' ? 'http://127.0.0.1:8089/admin-upload-ebook' : 'http://www.book.llmysnow.top/admin-upload-ebook'
module.exports = {
// ...
UPLOAD_PATH,
MIME_TYPE_EPUB: 'application/epub',
UPLOAD_URL
}
After reading the e-Book from the file, initialize the Book object
const { MIME_TYPE_EPUB, UPLOAD_URL, UPLOAD_PATH } = require('../utils/constant')
const fs = require('fs')
class Book {
// ...
createBookFromFile(file) {
const {
destination: des, // File local storage directory
filename, //File name
path, // File path
mimetype = MIME_TYPE_EPUB, // File resource type
originalname // Original file name
} = file
// E-book file suffix
const suffix = mimetype.startsWith(MIME_TYPE_EPUB) ? '.epub' : ''
// Original path of e-book
const oldBookPath = path
// New path for e-books
const bookPath = `${des}/${filename}${suffix}`
// Ebook Download URL link
const url = `${UPLOAD_URL}/book/${filename}${suffix}`
// Folder path after e-book decompression
const unzipPath = `${UPLOAD_PATH}/unzip/${filename}`
// Folder URL after e-book decompression
const unzipUrl = `${UPLOAD_URL}/unzip/${filename}`
if (!fs.existsSync(unzipPath)) {
fs.mkdirSync(unzipPath, { recursive: true }) // Iteratively create unzipped folders
}
if (fs.existsSync(oldBookPath) && !fs.existsSync(bookPath)) {
fs.renameSync(oldBookPath, bookPath) // rename file
}
this.filename = filename // file name
this.path = `/book/${filename}${suffix}` // epub folder relative path
this.filePath = this.path // epub folder relative path
this.unzipPath = `/unzip/${filename}` // Relative path after epub decompression
this.url = url // epub file download link
this.title = '' // title
this.author = '' // author
this.publisher = '' // press
this.contents = [] // catalogue
this.cover = '' // Cover image URL
this.coverPath = '' // Cover picture path
this.category = -1 // Category ID
this.categoryText = '' // Classification name
this.language = '' // languages
this.unzipUrl = unzipUrl // Unzipped folder link
this.originalname = originalname // Original name of e-book
}
}
E-book analysis
After initialization, you can call the parse method of the Book instance to parse the e-Book
- Here we use the epub library Source code : we directly copy epub.js to utils\epub.js
Install the two libraries that epub.js depends on:
npm i xml2js adm-zip
Parsing e-books using epub Library
Add the parse method in the Book class of models\Book.js
- Parse the data in epub.metadata and assign it to this

const Epub = require('../utils/epub')
class Book {
// ....
parse() {
return new Promise((resolve, reject) => {
const bookPath = `${UPLOAD_PATH}${this.path}`
if (!fs.existsSync(bookPath)) reject(new Error('E-book does not exist'))
const epub = new Epub(bookPath)
epub.on('error', err => reject(err))
epub.on('end', err => {
if (err) reject(err)
const { title, creator, creatorFileAs, language, publisher, cover } = epub.metadata
if (!title) reject(new Error('Book title is empty'))
this.title = title
this.language = language || 'en'
this.author = creator || creatorFileAs || 'unknown'
this.publisher = publisher || 'unknown'
this.rootFile = epub.rootFile
const handleGetImage = (err, file, mimeType) => {
if (err) reject(err)
const suffix = mimeType && mimeType.split('/')[1]
const coverPath = `${UPLOAD_PATH}/img/${this.filename}.${suffix}`
const coverUrl = `${UPLOAD_URL}/img/${this.filename}.${suffix}`
fs.writeFileSync(coverPath, file, 'binary')
this.coverPath = `/img/${this.filename}`
this.cover = coverUrl
resolve(this)
}
try {
this.unzip()
this.parseContents(epub).then(({ chapters }) => {
this.contents = chapters
epub.getImage(cover, handleGetImage)
})
} catch (e) {
reject(e)
}
})
epub.parse()
})
}
}
Get pictures using epub Library
epub format content can review this article: Project technical architecture ePub eBook in
- content.opf (some may not be called this, but the file points to the file container.xml. Generally, it is right to find the file in OPF format). The content has about five parts, one of which is called the manifest file list, which contains the information of the cover
<meta name="cover" content="cover-image"/> <item id="cover-image" href="images/cover.jpg" media-type="image/jpeg"/> <!-- The other is No meta Label is cover Yes, through properties obtain --> <item id="Aimages_978-3-319-64337-3_CoverFigure" href="images/978-3-319-64337-3_CoverFigure.jpg" media-type="image/jpeg" properties="cover-image"/>
Modify the source code of obtaining the cover image in utils\epub.js
- If you encounter other formats, you can continue to improve them here later
getImage(id, callback) {
if (this.manifest[id]) {
if ((this.manifest[id]['media-type'] || "").toLowerCase().trim().substr(0, 6) != "image/") {
return callback(new Error("Invalid mime type for image"));
}
this.getFile(id, callback);
} else {
const coverId = Object.keys(this.manifest).find(key =>
this.manifest[key].properties === 'cover-image'
)
if (coverId) {
this.getFile(coverId, callback)
} else {
callback(new Error("File not found"));
}
}
};
E-book catalog analysis
In the process of e-book parsing, we need to define e-book directory parsing. The first step is to unzip the e-book
class Book {
//...
unzip() {
const AdmZip = require('adm-zip')
const zip = new AdmZip(Book.genPath(this.path)) // Resolve file path
zip.extractAllTo(Book.genPath(this.unzipPath), true)
}
}
genPath is a property method of Book, which can be declared using the static property
class Book {
//...
static genPath(path) {
if (!path.startsWith('/')) path = `/${path}`
return `${UPLOAD_PATH}${path}`
}
}
E-book parsing algorithm
-
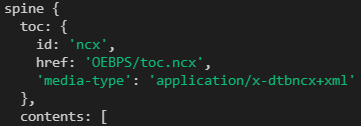
First, get the href of the toc in the epub instance spin (if not, get it through the manifest), and then read the corresponding ncx file according to this address
-
Because ncx is an XML file, it needs to be converted into json in combination with xml2js (get json.ncx.navMap)

-
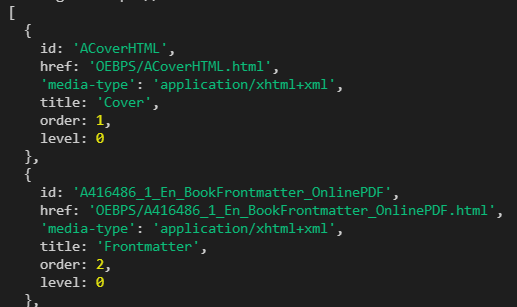
epub.flow array contains the display order of e-book directories, but this is not necessarily the actual directory. It is better to find the directory in combination with json.ncx.navMap.navPoint
-
Finally, add some useful information to the chapter and finally push it into the array, as follows:
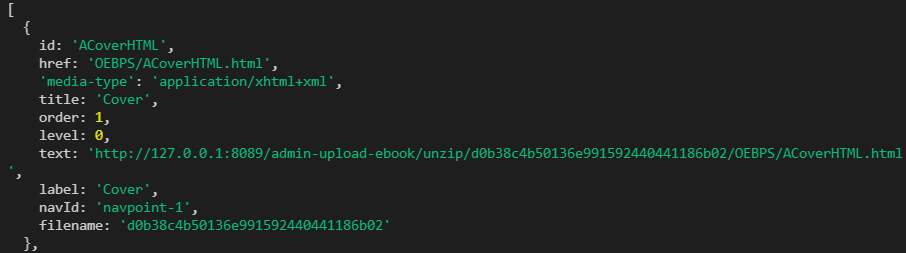
-
The directory also has levels. For example, there is a first section in the first chapter and a first section in the first section, so it needs to be flattened with the flatten method. According to this idea, we can write the flat method of ES10 and attach a reduce Version (we can also use the ternary operator, so there is only one line)
const arr = [1, [2, [3, [4, [5]], [6]], [7]]] console.log(arr.flat(Infinity)) // [1, 2, 3, 4, 5, 6, 7] function flatten(arr) { return [].concat( ...arr.map(item => { if (Array.isArray(item)) return [].concat(...flatten(item)) return item }) ) } console.log(flatten(arr)) // [1, 2, 3, 4, 5, 6, 7] function flattenReduce(arr) { return arr.reduce((acc, cur) => { if (Array.isArray(cur)) return acc.concat(flattenReduce(cur)) return acc.concat(cur) }, []) } console.log(flattenReduce(arr)) // [1, 2, 3, 4, 5, 6, 7]
const xml2js = require('xml2js').parseString
class Book {
//...
parseContents(epub) {
function getNcxFilePath() {
const spine = epub && epub.spine
const manifest = epub && epub.manifest
const ncx = spine.toc && spine.toc.href
const id = spine.toc && spine.toc.id
if (ncx) return ncx
return manifest[id].href
}
function findParent(array, level = 0, pid = '') {
return array.map(item => {
item.level = level
item.pid = pid
if (item.navPoint && item.navPoint.length > 0) {
item.navPoint = findParent(item.navPoint, level + 1, item['$'].id)
} else if (item.navPoint) {
item.navPoint.level = level + 1
item.navPoint.pid = item['$'].id
}
return item
})
}
function flatten(array) {
return [].concat(
...array.map(item => {
if (item.navPoint && item.navPoint.length > 0) {
return [].concat(item, ...flatten(item.navPoint))
} else if (item.navPoint) {
return [].concat(item, item.navPoint)
}
return item
})
)
}
const ncxFilePath = Book.genPath(`${this.unzipPath}/${getNcxFilePath()}`) // Get ncx file path
if (fs.existsSync(ncxFilePath)) {
return new Promise((resolve, reject) => {
const xml = fs.readFileSync(ncxFilePath, 'utf-8') // Read ncx file
const filename = this.filename
// Convert ncx files from xml to json
xml2js(
xml,
{
explicitArray: false, // When set to false, the parsing result will not wrap the array
ignoreAttrs: false, // Resolve properties
},
(err, json) => {
if (err) reject(err)
const navMap = json.ncx.navMap
if (navMap.navPoint && navMap.navPoint.length > 0) {
navMap.navPoint = findParent(navMap.navPoint)
const newNavMap = flatten(navMap.navPoint) // Split directory into flat structure
const chapters = []
epub.flow.forEach((chapter, index) => {
// If the directory is larger than the number resolved from ncx, skip directly
if (index + 1 > newNavMap.length) return
const nav = newNavMap[index] // Find the corresponding navMap according to the index
chapter.text = `${UPLOAD_URL}/unzip/${this.filename}/${chapter.href}`
if (nav && nav.navLabel) {
chapter.label = nav.navLabel.text || ''
} else {
chapter.label = ''
}
chapter.level = nav.level
chapter.pid = nav.pid
chapter.navId = nav['$'].id
chapter.filename = filename
chapter.order = index + 1
chapters.push(chapter)
})
resolve({ chapters })
} else {
reject(new Error('Directory resolution failed, the number of directories is 0'))
}
}
)
})
} else {
throw new Error('The catalog file does not exist')
}
}
}
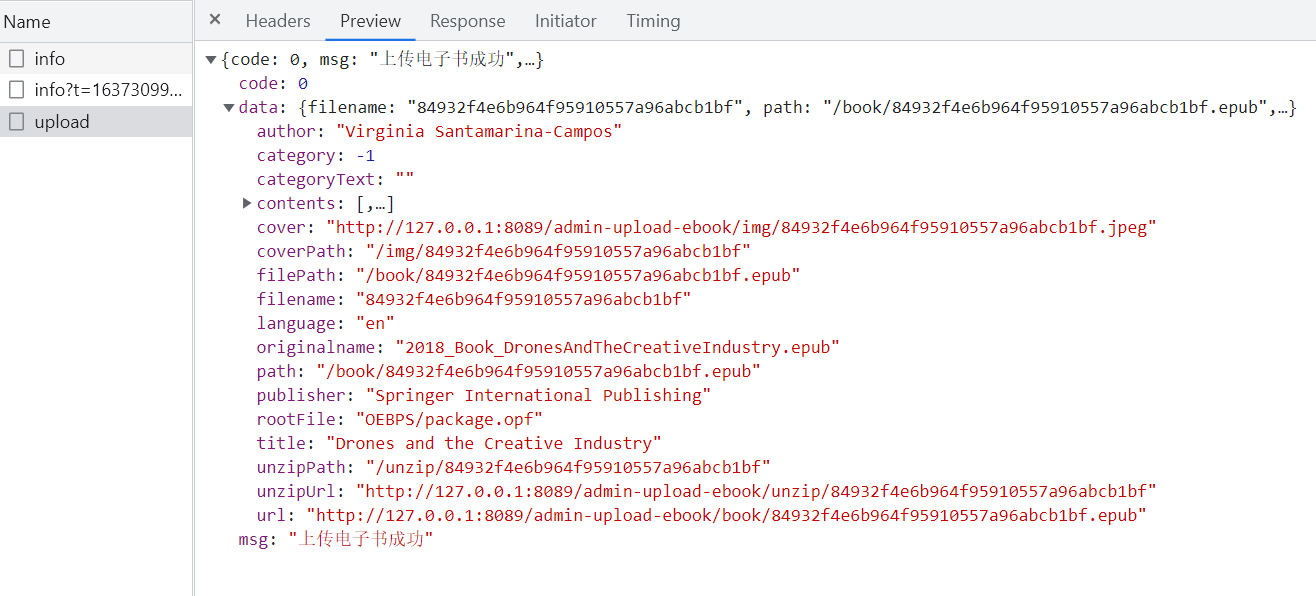
data received by the front end