regular expression
establish
Creation method
Method 1: use the constructor to create. The syntax is new regexp (regular expression, matching pattern). The specific of this method is flexible and can pass variables, but it is cumbersome to use
const str = '1234 abcd' let reg reg = new RegExp(/\d/, 'g') console.log(str.match(reg)) // [ '1', '2', '3', '4' ] const arg = '123' reg = new RegExp(arg, 'g') console.log(str.match(reg)) // [ '123' ]
Method 2: use literal quantity to create. The syntax is / regular expression / matching pattern. The specific use of this method is simple but inflexible, and variables cannot be passed
const str = '1234 abcd' const reg = /\d/g console.log(str.match(reg)) // [ '1', '2', '3', '4' ]
When the constructor is used, the regular expression is in a string format, resulting in the use of \ to meet the need for additional escape\
const str = '1234 abcd'
const reg = new RegExp('\\d','g')
console.log(str.match(reg)) // [ '1', '2', '3', '4' ]
console.log(str.match(/\d/g)) // [ '1', '2', '3', '4' ]
Matching pattern
There are 3 matching modes:
- i: Ignore case
- g: Global matching: by default, the first item that meets the condition will exit. If global matching is enabled, all items will be matched
- m: For multi line matching, the default ^ and $will not regard the newline character \ n as a new beginning or end of a text, and if you turn on multi line matching, it will be regarded as a new text
const str = 'abcd\nABCD' console.log(str.match(/abcd/g)) // [ 'abcd' ] console.log(str.match(/abcd/ig)) // [ 'abcd', 'ABCD' ] console.log(str.match(/^abcd/ig)) // [ 'abcd' ] console.log(str.match(/^abcd/igm)) // [ 'abcd', 'ABCD' ]
Match symbol
Single character
Special symbols that match a single character:
- .: matches any character
- \.: match one character
- \: matches a \ character
- \/: match a / character
- \(: matches one character
- \): match one) character
- \d: Match a numeric character
- \D: Match a non numeric character
- \w: Match a letter, number, underscore character
- \W: Matches a character other than a letter, number, or underscore
- \s: Match spaces (spaces, tabs, etc.)
- \S: Match non whitespace characters
- \b: Match implicit boundary
- \B: Matching non implicit boundary
const str = '123 abc .$\\/_' console.log(str.match(/./g)) // [ '1', '2', '3', ' ', 'a', 'b', 'c', ' ', '.', '$', '\', '/', '_' ] console.log(str.match(/\./g)) // [ '.' ] console.log(str.match(/\\/g)) // [ '\' ] console.log(str.match(/\//g)) // [ '/' ] console.log(str.match(/\d/g)) // [ '1', '2', '3' ] console.log(str.match(/\D/g)) // [ ' ', 'a', 'b', 'c', ' ', '.', '$', '\', '/', '_' ] console.log(str.match(/\w/g)) // [ '1', '2', '3', 'a', 'b', 'c', '_' ] console.log(str.match(/\W/g)) // [ ' ', ' ', '.', '$', '\', '/' ] console.log(str.match(/\s/g)) // [ ' ', ' ' ] console.log(str.match(/\S/g)) // [ '1', '2', '3', 'a', 'b', 'c', '.', '$', '\', '/', '_' ]
There will be an implicit boundary between words and symbols. Words refer to English or numeric characters, and symbols refer to Chinese and other symbolic characters (such as spaces and special symbols)
Pure words also produce implicit boundaries at the beginning and end, while pure symbols do not
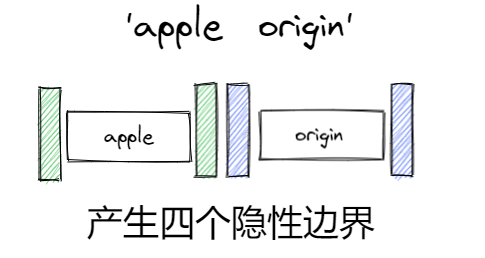
let str str = '123abc' console.log(str.match(/\b/g)) // [ '', '' ] str = 'Cluck' console.log(str.match(/\b/g)) // null str = 'apple origin' console.log(str.match(/\b/g)) // [ '', '', '', '' ] // >Combination of multiple symbols str = 'Cluck &*^% \\ + -' console.log(str.match(/\b/g)) // null, pure symbols do not produce boundaries str = 'apple Cluck &*^% \\ + -origin' console.log(str.match(/\b/g)) // ['', '', '', ''], multiple symbols only affect the implicit boundary once // >The general usage scenario is to match a specific word str = 'gegeda gegedagegeda' console.log(str.match(/\bgegeda\b/g)) // [ 'gegeda' ]
position
- ^: matches the beginning of a line of characters
- $: matches the end of a line of characters
const str = '1221 1331' console.log(str.match(/^1.../g)) // [ '1221' ] console.log(str.match(/...1$/g)) // [ '1331' ]
quantity
- *: match any characters (including 0)
- ?: Match 0 or 1 characters
- +: match at least 1 character
- {n} : matches characters that occur exactly n times
- {n, m}: matches characters that appear n ~ m times
- {n,}: matches characters that appear n times or more
reg = /a*bc/ // Match bc or any a followed by bc
reg = /a?bc/ // Match bc or abc
reg = /a+bc/ // Match abc or more than one a followed by bc
reg = /a{3}bc/ // Match aaabc
reg = /(ab){3}c/ // Match ABC
reg = /a{1,3}bc/ // Match abc or abbc or abbbc
reg = /a{3,}bc/ // Match 3 or more a followed by bc
or
- |: indicates or relates
- []: represents or relationship
- [n-m]: matches any character in the n-m range
- [a-z]: match any lowercase letter
- [A-Z]: match any capital letter
- [A-z]: match any letter
- [0-9]: match any number
- [^ x]: match any non-x character
- [n-m]: matches any character in the n-m range
|Slightly different from [] usage, | can be used to match the or of multiple characters, while [] is used to match the or of a single character
reg = /a|b/ // Match a or b reg = /[ab]/ // Match a or b reg = /a|bc|d/ // Match a or bc or d reg = /a[bc]d/ // Match abd or acd reg = /^[0-9]/ // Match any non numeric character
In [] expression, all special symbols need not be escaped
const str = '.\\/()'
console.log(str.match(/[.\/()]/g)) // [ '.', '/', '(', ')' ]
Special Usage
Greedy / lazy matching
-
Greedy matching:. *, Match to the end of the entire string
-
Inert matching:. *?: Match to the nearest satisfaction
const str = '"data: aaa" "data: bbb"' let reg reg = /"data:.*"/g console.log(str.match(reg)) // ['"data: aaa" "data: bbb'], matching to the end“ reg = /"data:.*?"/g console.log(str.match(reg)) // ['"data: AAA', '" data: BBB'], only match to the next“
Forward / backward assertion
-
Forward look ahead assertion: (? = str): a position of the matching string. The character immediately after this position is str
-
Forward and backward assertion: (? < = STR): a position of the matching string. The character immediately before this position is str
-
Negative forward assertion: (?! str): a position in the matching string. The character immediately after this position cannot be str
-
Negative backward assertion: (? <! STR): a position of the matching string. The character immediately before this position cannot be str
The first / last line assertion matches a position, not a character. If the matching needs to contain STR, you need to match the str syntax additionally
const str = 'a1bc a2bc a3bc a4bc' let reg reg = /a(?=1).../g console.log(str.match(reg)) // [ 'a1bc' ] reg = /..(?<=2)b./g console.log(str.match(reg)) // [ 'a2bc' ] reg = /a(?!1).../g console.log(str.match(reg)) // [ 'a2bc', 'a3bc', 'a4bc' ] reg = /..(?<!2)b./g console.log(str.match(reg)) // [ 'a1bc', 'a3bc', 'a4bc' ]
Regular method
regexp.exec (str)
- Function: get regular matching information
- Parameters:
- str: string: verified string
- Return value: array < any > | null, an array of inspection information. If it does not match, null is returned
const str = 'abcd 1234' const reg = /^a../g console.log(reg.exec(str)) // [ 'abc', index: 0, input: 'abcd 1234', groups: undefined ]
regexp.test (str)
- Function: check whether the string meets regular matching
- Parameters:
- str: string: verified string
- Return value: boolean, inspection result
const str = 'abcd 1234' const reg = /^a../g console.log(reg.test(str)) // true