First, build haoop2.0 of eclipse 7.1 development environment, the resources used are linked as follows:
Install Hadoop 2.0 for windows 7.1 environment
Building hadoop development environment under eclipse
In this way, we can develop hadoop in eclipse
catalogue
1, Introduction to MapReduce model
4. MapReduce application execution process
1, Introduction to MapReduce model
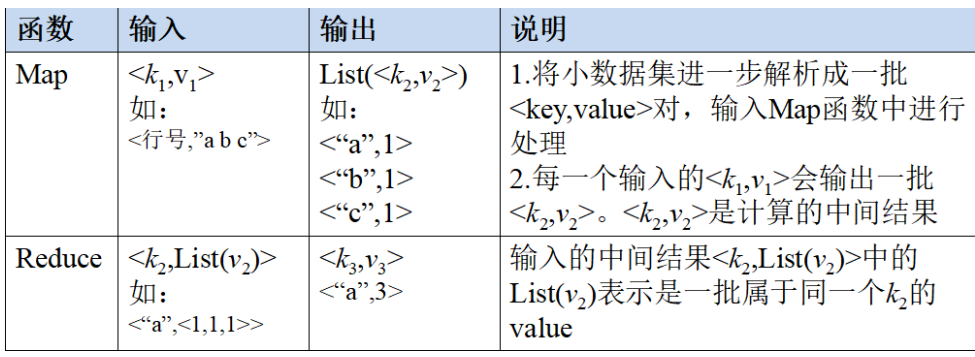
1. Map and Reduce functions
2. MapReduce architecture
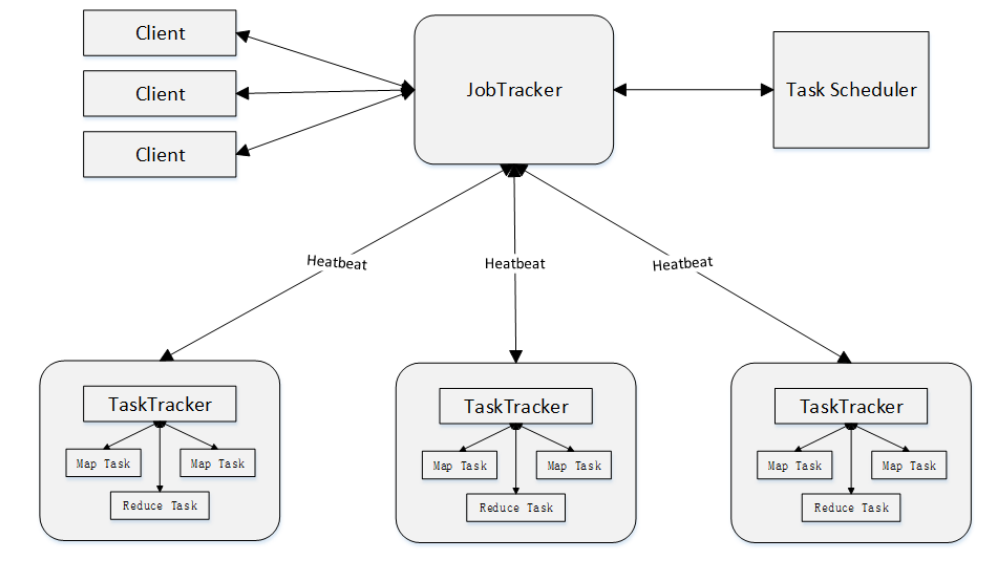
1)Client
The MapReduce program written by the user is submitted to the JobTracker through the Client. The user can view the job running status through some interfaces provided by the Client
2)JobTracker
JobTracker is responsible for resource monitoring and Job scheduling. JobTracker monitors the health status of all tasktrackers and jobs. Once a failure is found, it will transfer the corresponding tasks to other nodes. JobTracker will track the execution progress of tasks, resource usage and other information, and report these information to the task scheduler. When resources are idle, the scheduler will, Choose the right tasks to use these resources
3)TaskTracker
TaskTracker will periodically report the use of resources and the running progress of tasks on this node to JobTracker through "heartbeat". At the same time, it will receive the commands sent by JobTracker and perform corresponding operations (such as starting a new Task, killing a Task, etc.). TaskTracker uses "slot" to divide the amount of resources (CPU, memory, etc.) on this node. A Task has the opportunity to run only after it obtains a slot, and the function of Hadoop scheduler is to allocate the idle slots on each TaskTracker to the Task. There are two kinds of slots: Map slot and Reduce slot, which are used by MapTask and Reduce Task respectively
4)Task
Tasks are divided into Map Task and Reduce Task, both of which are started by TaskTracker
3. MapReduce workflow
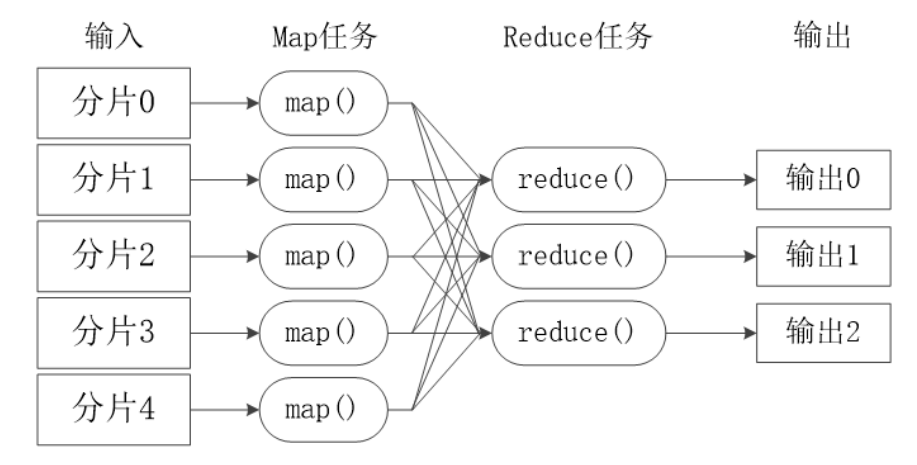
- There is no communication between different Map tasks
- There will be no information exchange between different Reduce tasks
- Users cannot explicitly send messages from one machine to another
- All data exchange is realized through the MapReduce framework itself
2) MapReduce execution stages
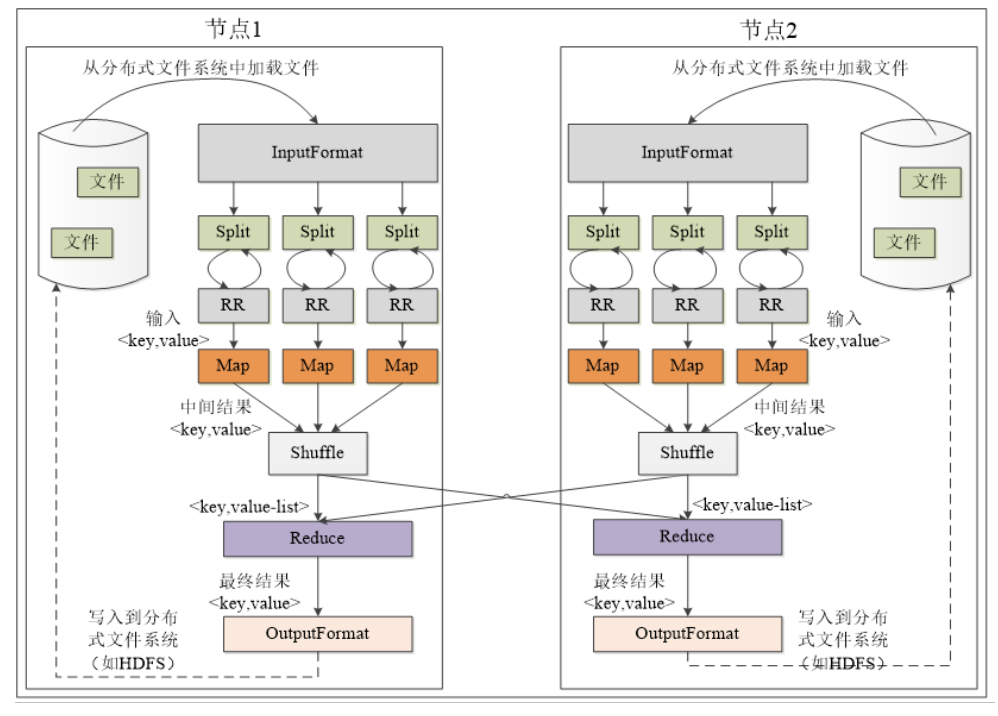
4. MapReduce application execution process
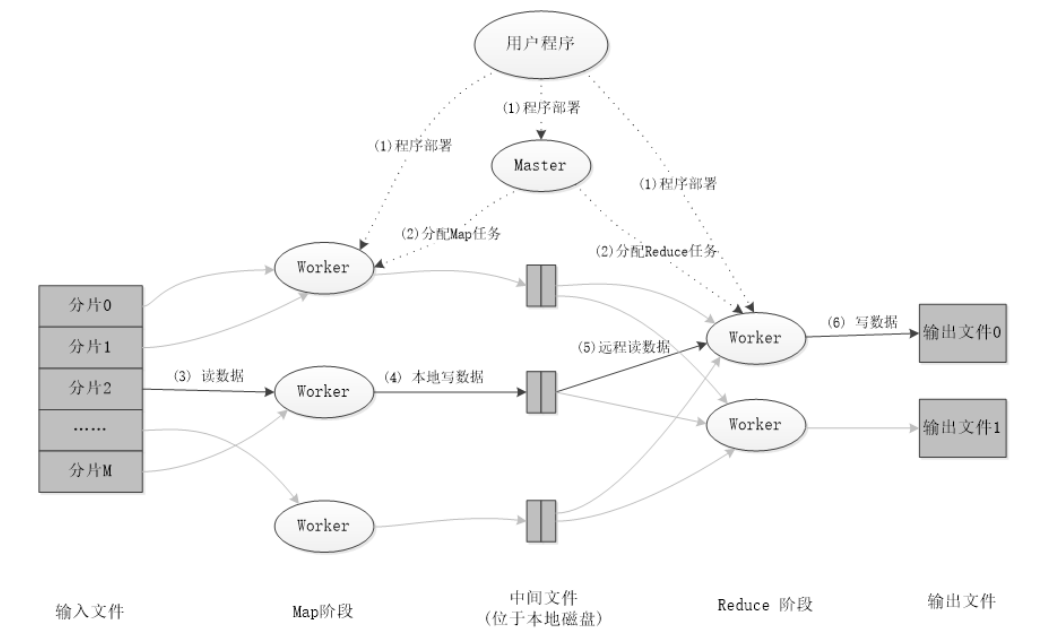
II. MapReduce actual combat
1. Data De duplication
"Data De duplication" is mainly to grasp and use the idea of parallelization to screen data meaningfully. The seemingly complicated tasks such as counting the number of data types on the big data set and calculating the access place from the website log will involve data De duplication.
1.1 example description
De duplicate the data in the data file. Each line in the data file is a piece of data. The sample input is as follows:
1)file1:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
2)file2:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
The sample output is as follows:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
1.2 problem solving ideas
map stage: take the text of each line as the key of the key value pair
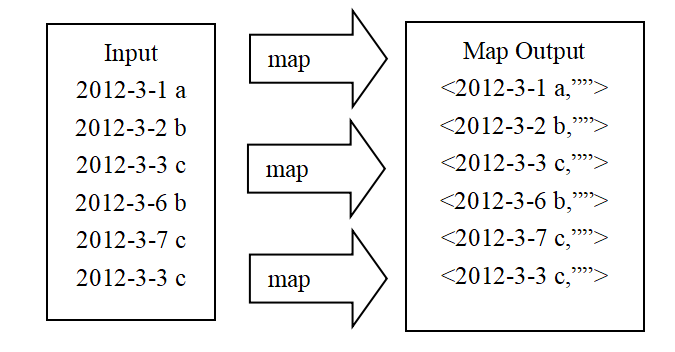
reduce phase: output each common key group
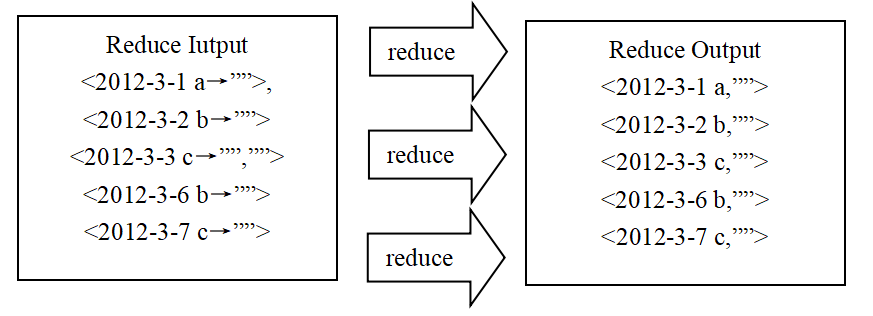
1.3 code display
package datadeduplicate.pers.xls.datadeduplicate;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.log4j.BasicConfigurator;
public class Deduplication {
public static void main(String[] args) throws Exception {
BasicConfigurator.configure(); //Automatically and quickly use the default Log4j environment
//The classes of self-defined mapper and reducer must be passed, the path of input and output must be specified, and the type of output < K3, V3 > must be specified
//1 first write the job and know that conf and jobname are needed to create it
Configuration conf=new Configuration();
String jobName=Deduplication.class.getSimpleName();
Job job = Job.getInstance(conf, jobName);
//2 assemble the customized MyMapper and MyReducer together
//3. Read HDFS content: FileInputFormat is in MapReduce Under lib package
FileInputFormat.setInputPaths(job, new Path(args[0]));
//4 specify the class to resolve < K1, V1 > (who will resolve key value pairs)
//*The specified resolved class can be omitted from writing, because the default setting of the resolved class is textinputformat class
job.setInputFormatClass(TextInputFormat.class);
//5 specify the custom mapper class
job.setMapperClass(MyMapper.class);
//6 specify the type of key2 and value2 output from the map < K2, V2 >
//*The following two steps can be omitted. When the < K3, V3 > and < K2, V2 > types are consistent, the < K2, V2 > type can not be specified
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//7 partitions (1 by default), sorting and grouping. The protocol adopts the default
job.setCombinerClass(MyReducer.class);
//Next, take the reduce step
//8 specify a custom reduce class
job.setReducerClass(MyReducer.class);
//9 specifies the < K3, V3 > type of output
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//10 specify the class that outputs < K3, V3 >
//*The following step can save
job.setOutputFormatClass(TextOutputFormat.class);
//11 specify output path
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//The mapreduce program written in 12 should be run by the resource manager
job.waitForCompletion(true);
//*Finally, if you want to package and run the modified program, you need to call the following line
job.setJarByClass(Deduplication.class);
}
private static class MyMapper extends Mapper<Object, Text, Text, Text>{
private static Text line=new Text();
@Override
protected void map(Object k1, Text v1,Mapper<Object, Text, Text, Text>.Context context) throws IOException, InterruptedException {
line=v1;//v1 is each row of data and assigned to line
context.write(line, new Text(""));
}
}
private static class MyReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text k2, Iterable<Text> v2s,Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
context.write(k2, new Text(""));
}
}
}1.4 display of operation results
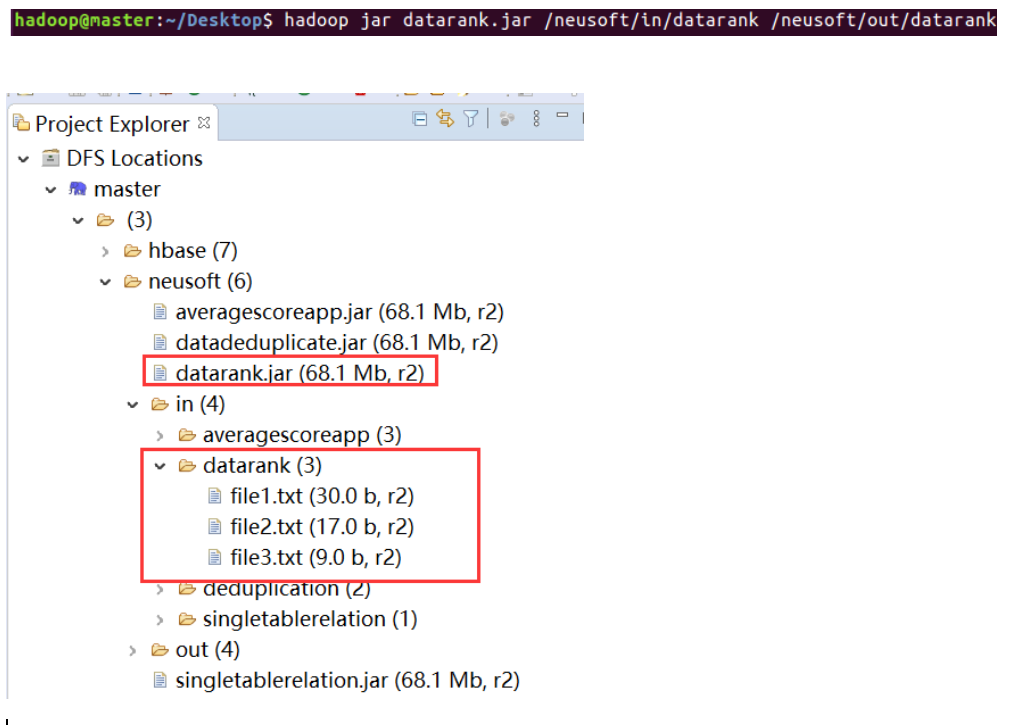
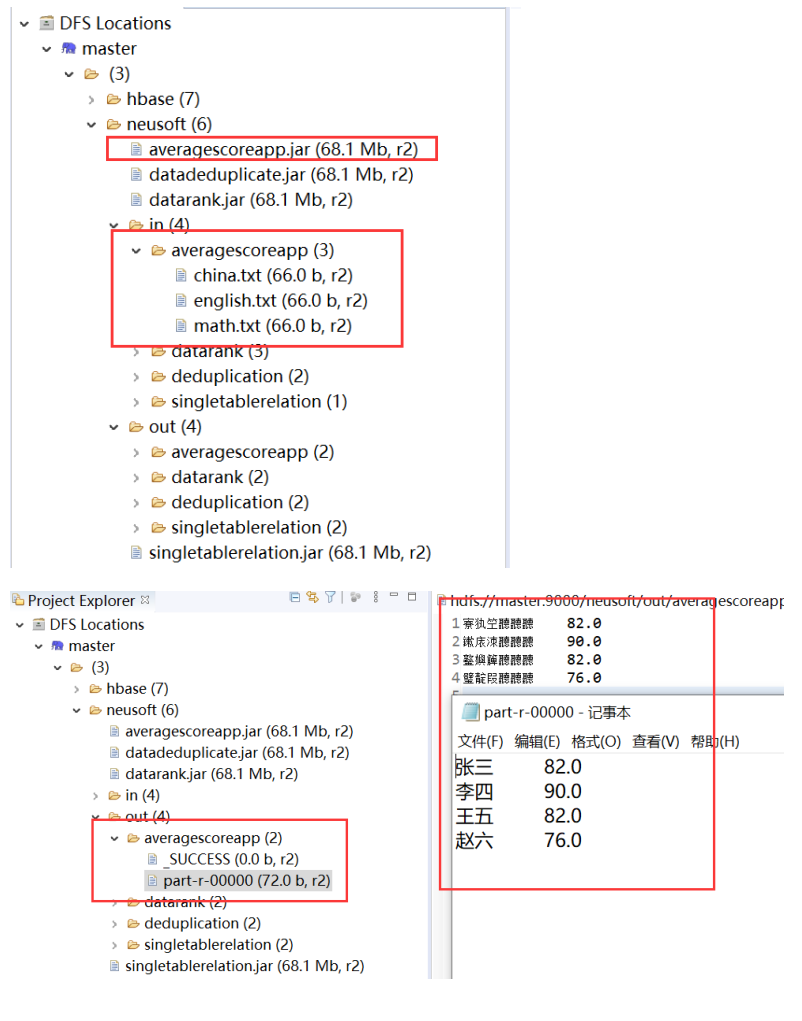
Package the project into a running jar package, and upload the hdfs file system:
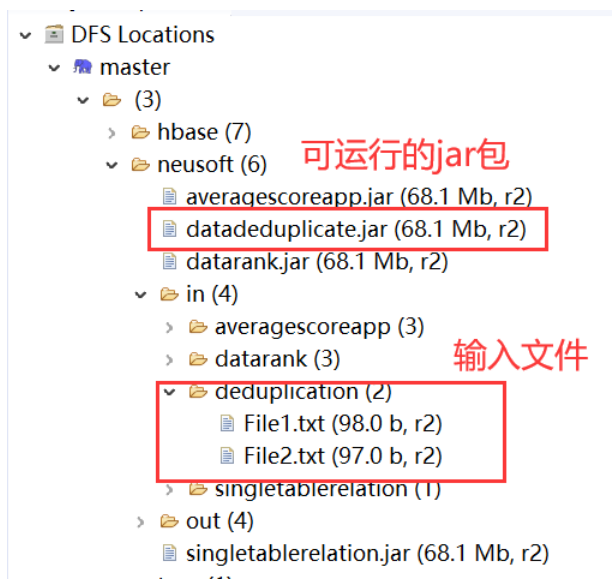
Under the linux system, enter the hadoop command in the terminal and run the jar package on the established hadoop node:

Check the out folder under the hdfs file system in eclipse and find that the previously specified duplication folder is generated, where part-r-00000 is the output of the run.
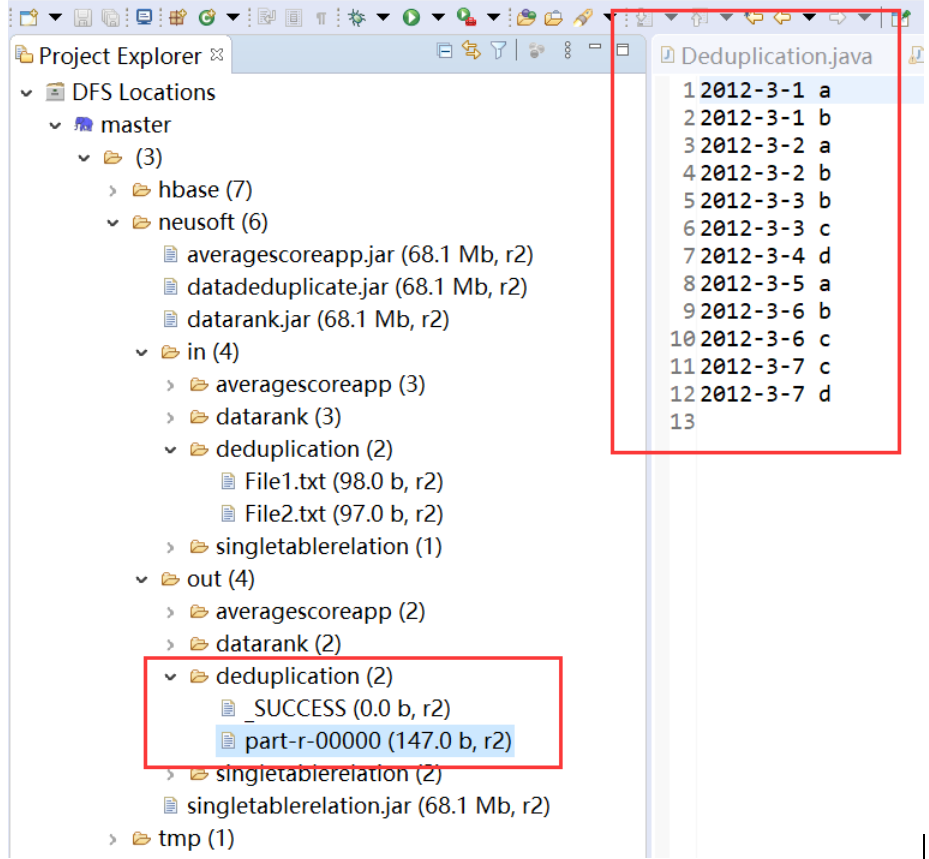
2. Data sorting
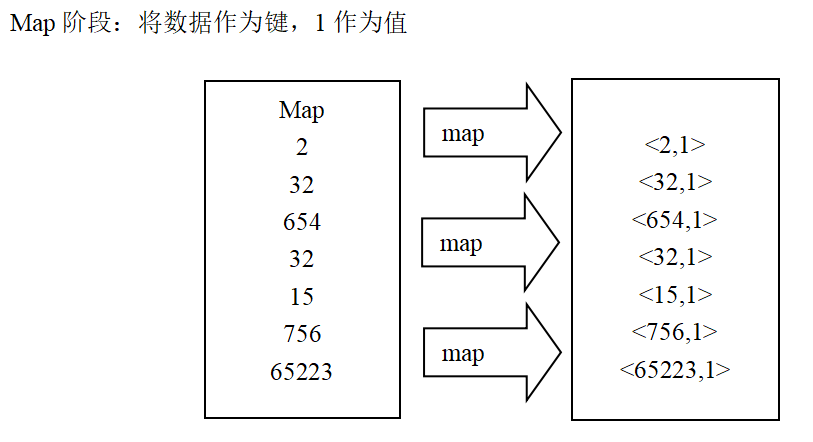
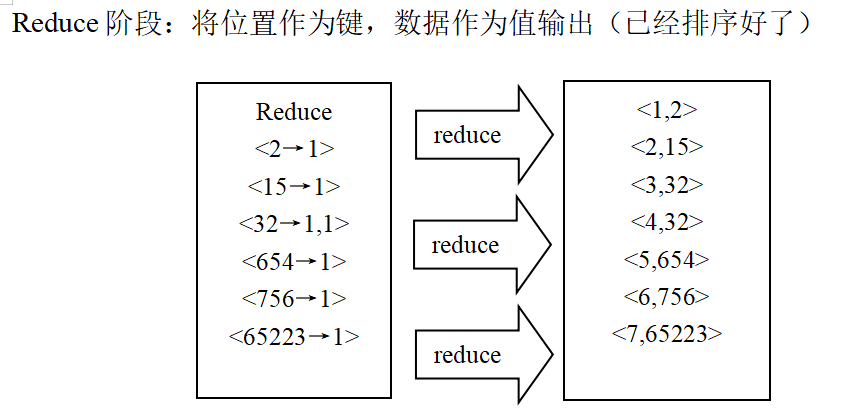
package dararank.pers.xls.datarank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
import java.io.IOException;
public class DataRank {
/**
* Use Mapper to directly output the data in the data file as the key of Mapper output
*/
public static class forSortedMapper extends Mapper<Object, Text, IntWritable, IntWritable> {
private IntWritable mapperValue = new IntWritable(); //Store the value of key
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString(); //Get the read value and convert it to String
mapperValue.set(Integer.parseInt(line)); //Convert String to Int type
context.write(mapperValue,new IntWritable(1)); //Mark each record as (key, value) the number of times key -- number value -- appears
//Each occurrence is marked as (number, 1)
}
}
/**
* Use Reducer to directly output the input key itself as a key
*/
public static class forSortedReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
private IntWritable postion = new IntWritable(1); //Storage ranking
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable item :values){ //The same number may be listed many times, so it must be sorted in parallel many times
context.write(postion,key); //Write rank and specific number
System.out.println(postion + "\t"+ key);
postion = new IntWritable(postion.get()+1); //Rank plus 1
}
}
}
public static void main(String[] args) throws Exception {
BasicConfigurator.configure(); //Automatically and quickly use the default Log4j environment
Configuration conf = new Configuration(); //Set the configuration of MapReduce
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: datarank <in> [<in>...] <out>");
System.exit(2);
}
//Set job
//Job job = new Job(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(DataRank.class);
job.setJobName("DataRank");
//Set the class that handles map and reduce
job.setMapperClass(forSortedMapper.class);
job.setReducerClass(forSortedReducer.class);
//Processing of setting input / output format
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//Set I / O path
for (int i = 0; i < otherArgs.length-1;++i){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
3. Average score
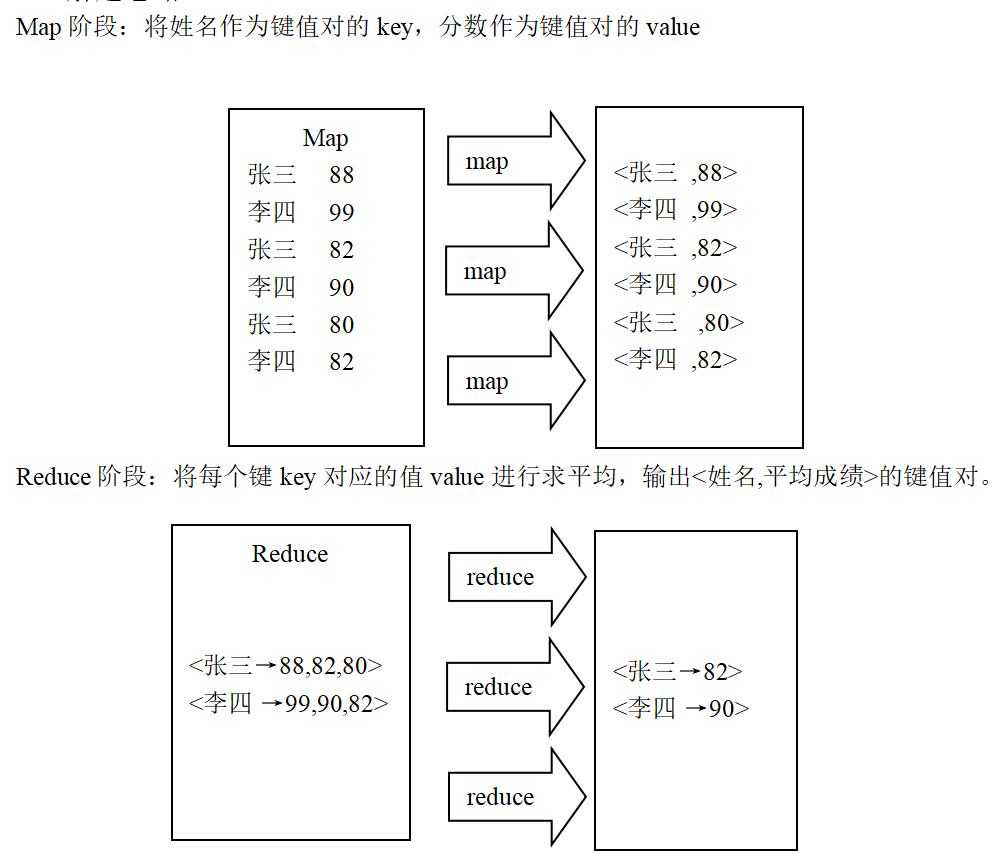
package averagescoreapp.pers.xls.averagescoreapp;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
/**
* Average score
*
*/
public class AverageScoreApp {
public static class Map extends Mapper<Object, Text, Text, IntWritable>{
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//The structure of the results is:
// Zhang San eighty
// Li Si eighty-two
// Wang Wu eighty-six
StringTokenizer tokenizer = new StringTokenizer(value.toString(), "\n");
while(tokenizer.hasMoreElements()) {
StringTokenizer lineTokenizer = new StringTokenizer(tokenizer.nextToken());
String name = lineTokenizer.nextToken(); //full name
String score = lineTokenizer.nextToken();//achievement
context.write(new Text(name), new IntWritable(Integer.parseInt(score)));
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, DoubleWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
//reduce the data structure entered here is:
// Zhang San < 80,85,90 >
// Li Si < 82,88,94 >
// Wang Wu < 86,80,92 >
int sum = 0;//Total score of all courses
double average = 0;//Average score
int courseNum = 0; //Number of courses
for(IntWritable score:values) {
sum += score.get();
courseNum++;
}
average = sum/courseNum;
context.write(new Text(key), new DoubleWritable(average));
}
}
public static void main(String[] args) throws Exception{
BasicConfigurator.configure(); //Automatically and quickly use the default Log4j environment
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: AverageScoreRank <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(AverageScoreApp.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//Set input / output path
for (int i = 0; i < otherArgs.length-1;++i){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
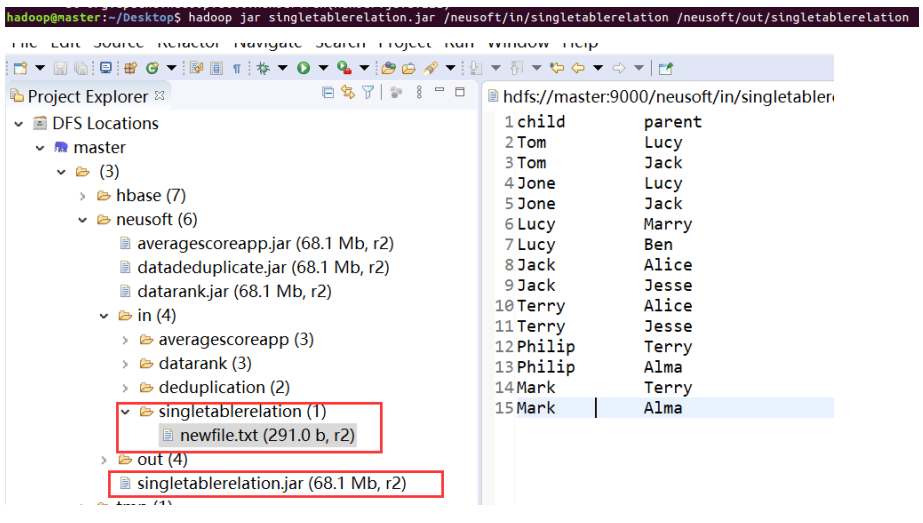
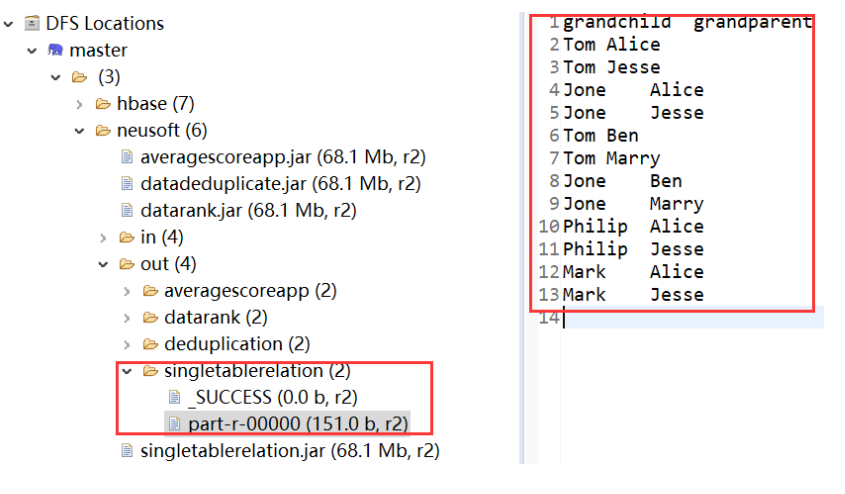
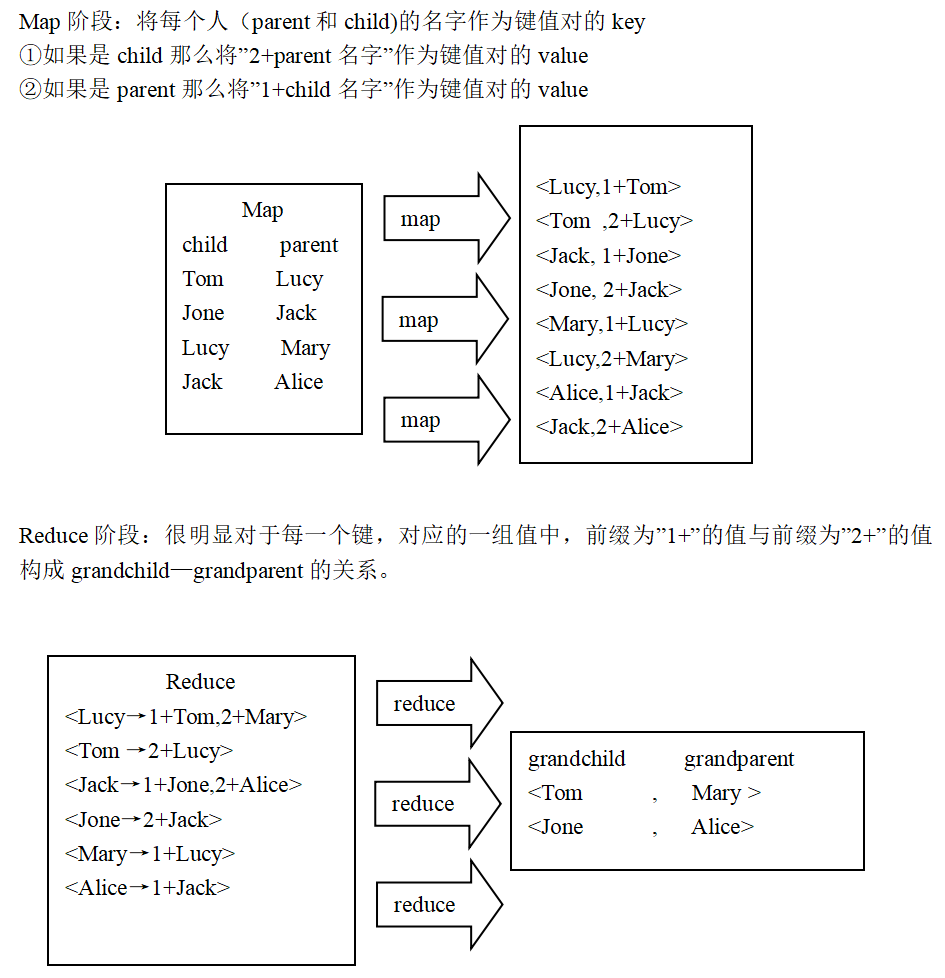
4. Single table Association
package singletabblerelation.pers.xls.singletablerelation;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
public class SingleTableRelation {
public static int time = 0;
public static class Map extends Mapper<LongWritable, Text, Text, Text> {
protected void map(LongWritable key, Text value, Context context)throws java.io.IOException, InterruptedException {
// Identification of left and right tables
int relation;
StringTokenizer tokenizer = new StringTokenizer(value.toString());
String child = tokenizer.nextToken();
String parent = tokenizer.nextToken();
if (child.compareTo("child") != 0) {
// Left table
relation = 1;
context.write(new Text(parent), new Text(relation + "+" + child));
// Right table
relation = 2;
context.write(new Text(child), new Text(relation + "+" + parent));
}
};
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context output)
throws java.io.IOException, InterruptedException {
int grandchildnum = 0;
int grandparentnum = 0;
List<String> grandchilds = new ArrayList<>();
List<String> grandparents = new ArrayList<>();
/** Output header */
if (time == 0) {
output.write(new Text("grandchild"), new Text("grandparent"));
time++;
}
for (Text val : values) {
String record = val.toString();
char relation = record.charAt(0);
// Take out the child corresponding to the key at this time
if (relation == '1') {
String child = record.substring(2);
grandchilds.add(child);
grandchildnum++;
}
// Take out the parent corresponding to the key at this time
else {
String parent = record.substring(2);
grandparents.add(parent);
grandparentnum++;
}
}
if (grandchildnum != 0 && grandparentnum != 0) {
for (int i = 0; i < grandchildnum; i++)
for (int j = 0; j < grandparentnum; j++)
output.write(new Text(grandchilds.get(i)), new Text(
grandparents.get(j)));
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
BasicConfigurator.configure(); //Automatically and quickly use the default Log4j environment
//The classes of self-defined mapper and reducer must be passed, the path of input and output must be specified, and the type of output < K3, V3 > must be specified
//2 assemble the customized MyMapper and MyReducer together
Configuration conf=new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: SingleTableRelation <in> [<in>...] <out>");
System.exit(2);
}
String jobName=SingleTableRelation.class.getSimpleName();
//1. First write the job and know that conf and jobname are needed to create it
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(SingleTableRelation.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//Set I / O path
for (int i = 0; i < otherArgs.length-1;++i){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));
System.exit((job.waitForCompletion(true) ? 0 : 1));
}
}