1. elatic engineer certification examination
If you have the strength, you can take the exam. It will be helpful for the appreciation and salary increase
2. es architecture
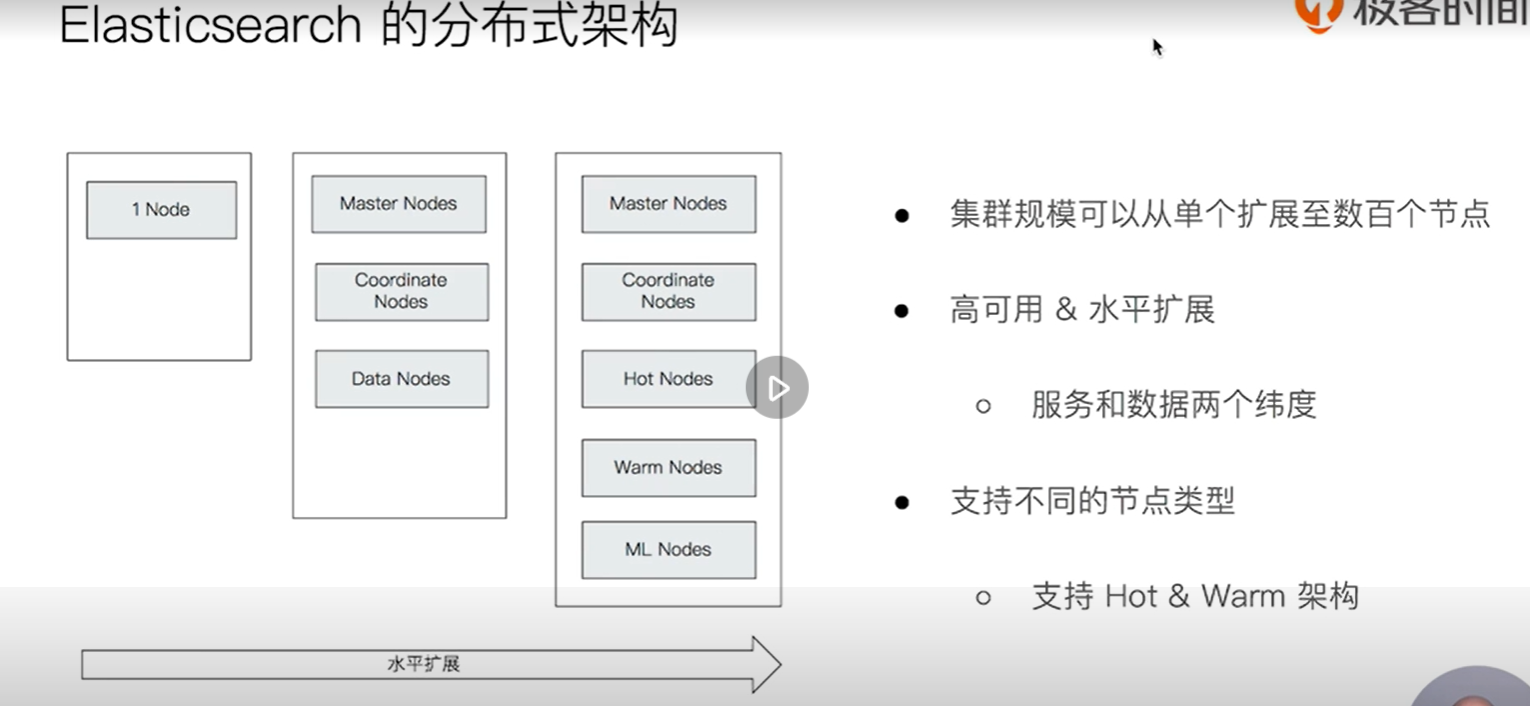


Ecosphere

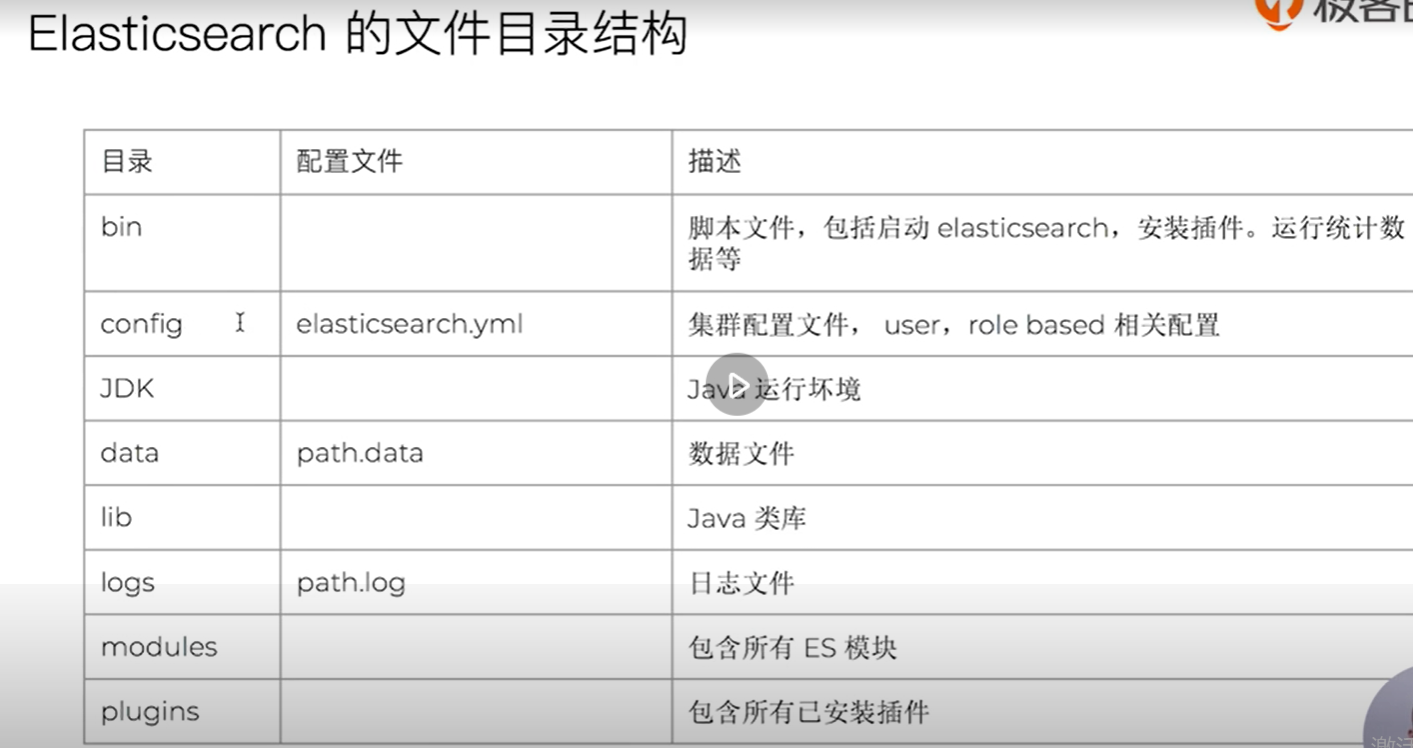
install
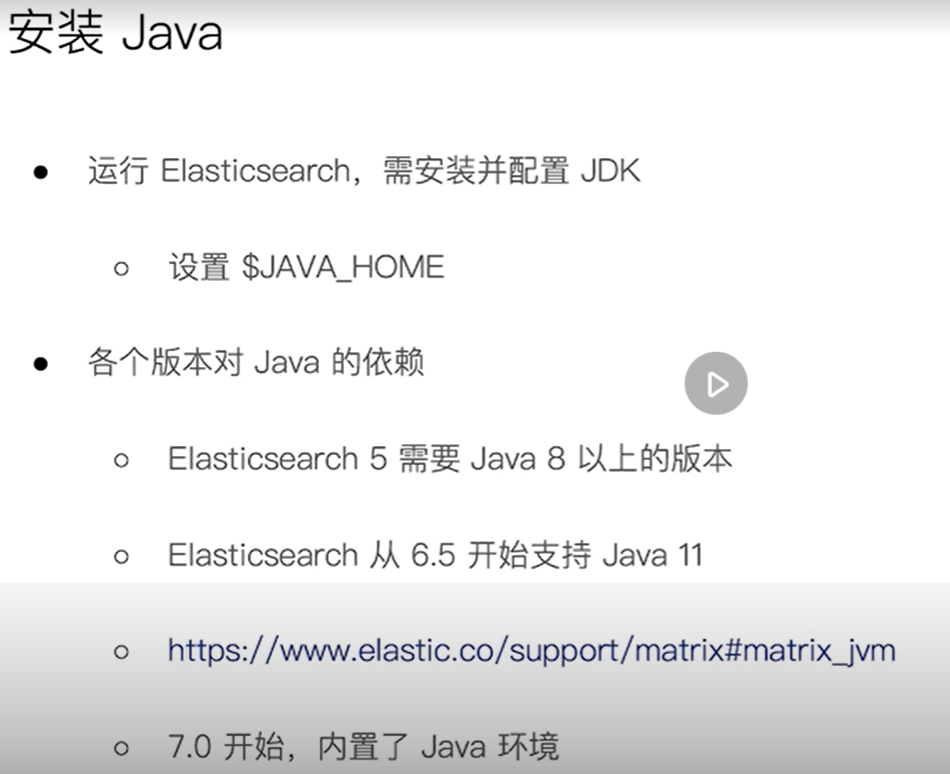
jvm configuration

Install plug-ins
Use elasticsearch plugin in elasticsearch-7.1.0/bin to install the plug-in. es will download and install the plug-in through the network.
. / elasticsearch plugin list to view the installed plug-ins.
Install international word segmentation plug-in:. / elasticsearch plugin install analysis ICU
Start es
./elasticsearch
If the startup fails: can not run elasticsearch as root,
es cannot be started with root. For solutions, refer to https://www.cnblogs.com/gcgc/p/10297563.html
Use background start mode:. / elasticsearch -d
If you find using 127.0.0.1:9200 to open with a browser,
But if you can't access the IP address of a computer, such as 192.168.0.101:9200, don't be nervous,
Because this IP is ES by default, 127.0.0.1 is used. If you want to use other IP, you need to configure it.
You can use the
When network.host is set to 0.0.0.0 and configured to 0.0.0.0, it will be found that 127.0.0.1 or machine IP can be accessed. The test can be configured to 0.0.0.0
Or configure the IP address you want first
For example:
network.host: 192.168.0.103 However, an error is reported: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured This is because if network.host is changed, ES needs to configure the cluster IP seed_hosts to find the cluster machines of the same intranet, The default is node-1, that is, if a stand-alone ES, the primary node is node-1 So just configure: cluster.initial_master_nodes: ["node-1"] that will do Refer to http://www.freedom.com/article/620549947/
network.host
network.host can also set some special values, such as "local", "site", "global", IP4 and IP6. For more details, please refer to "Special values for network.host".
Once you have customized network.host, Elasticsearch assumes that you are moving from development mode to production mode, and upgrades many system startup checks from warnings to exceptions. For more information, see "Development mode vs production mode".
If network.host is configured, es will fail to start and an error will be reported:
[2020-03-17T20:29:25,386][ERROR][o.e.b.Bootstrap ] [DESKTOP-UINEBG0] node validation exception [1] bootstrap checks failed [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
Because this is the cluster mode, you must configure the parameters of the cluster
Multi instance es

The above is to install multiple es on one computer
Configuration cluster parameter description
# Cluster name, default is elasticsearch cluster.name: wali # Machine name of the machine node.name: slave1 # Network segment of es machine network.host: 127.0.0.1 # Open http interface http.port: 8200 # Discovery cluster, that is, the IP address of the domain name where most of the machines in the cluster are configured (if three es cluster servers are in one machine, then one IP address is enough) discovery.seed_hosts: ["127.0.0.1"] # Don't configure like this. It's not good to bring the port number. It says "host". It must be the IP address or domain name #discovery.seed_hosts: ["127.0.0.1:8300","127.0.0.1:8200"] # The name of the initialized node when the es cluster is built # If other nodes start, the following nodes must be started to be available. # And the whole es cluster can be used. Only two nodes can be used to elect the primary node. # For example, slave1 is configured, which does not mean that this slave1 will become a primary node or a child node, depending on the election cluster.initial_master_nodes: ["slave1"] # This function is similar to discovery.seed_hosts, but es7 does not recommend it. It may be removed later # Do not configure discovery.zen.ping.unicast.hosts if discovery.seed'hosts and cluster.initial'master'nodes are configured #discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
cluster.name: wali node.name: slave2 network.host: 127.0.0.1 http.port: 8300 # discovery.seed_hosts: ["127.0.0.1"] discovery.seed_hosts: ["127.0.0.1:8300","127.0.0.1:8200"] cluster.initial_master_nodes: ["slave1"] #discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
The cluster configuration of ES requires at least 2 machines. This is not zk. zk needs at least three
kibana
Sinicization
By adding
I18n.locale: "zh CN", it supports Chinese display.
es monitoring tool cerebro
Use this tool to get a more direct view of es operation
Logstash
Execute bin/logstash -f logstash.conf
In linux, the corresponding logstash.tar.gz is used instead of the zip package
Basic concept of es

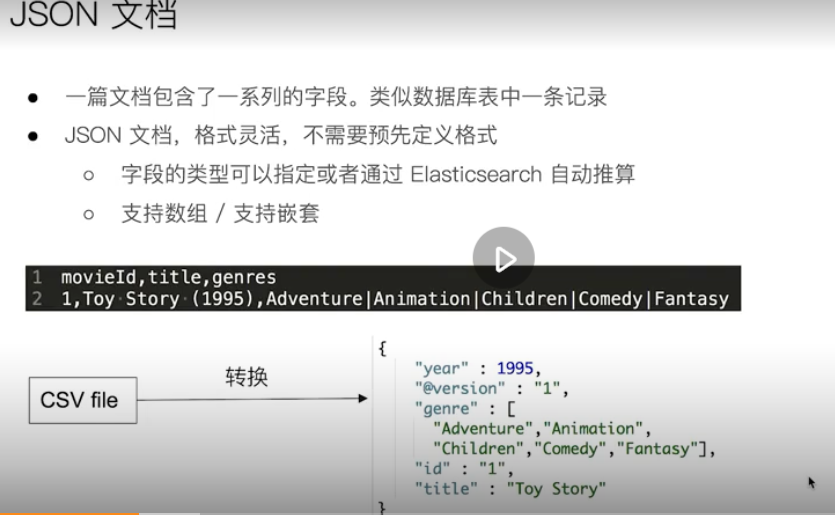


Abstraction and analogy

That is to say, the type s of indexes after es7 are all "doc"
Index related API
#View index related information GET kibana_sample_data_ecommerce #Total number of documents to view index GET kibana_sample_data_ecommerce/_count #Check the top 10 documents for document format POST kibana_sample_data_ecommerce/_search { } #_cat indices API #View indexes GET /_cat/indices/kibana*?v&s=index #View index in green GET /_cat/indices?v&health=green #Sort by number of documents GET /_cat/indices?v&s=docs.count:desc #View specific fields GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt #How much memory is used per index? GET /_cat/indices?v&h=i,tm&s=tm:desc
es node

Election master

node type


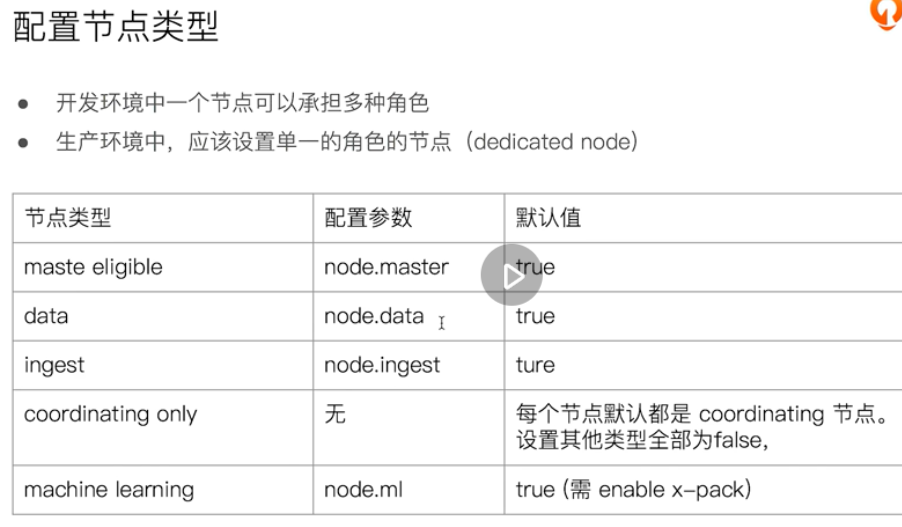
If the number of ES cluster servers in production is too small, it will follow the development, regardless of the details
Fragmentation



Operation of documents

create

get

index

update
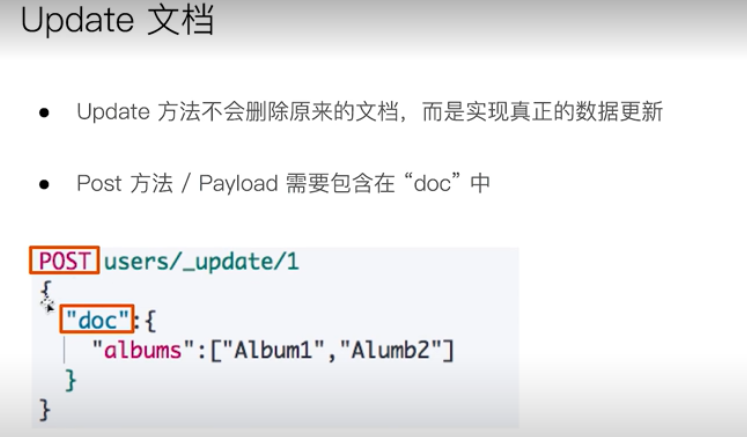
update can also add fields
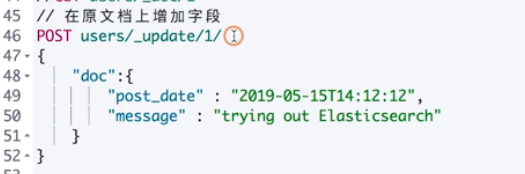
Bulk API batch operation

Batch operation can improve efficiency, otherwise the network overhead is very large
Common error return

Inverted index
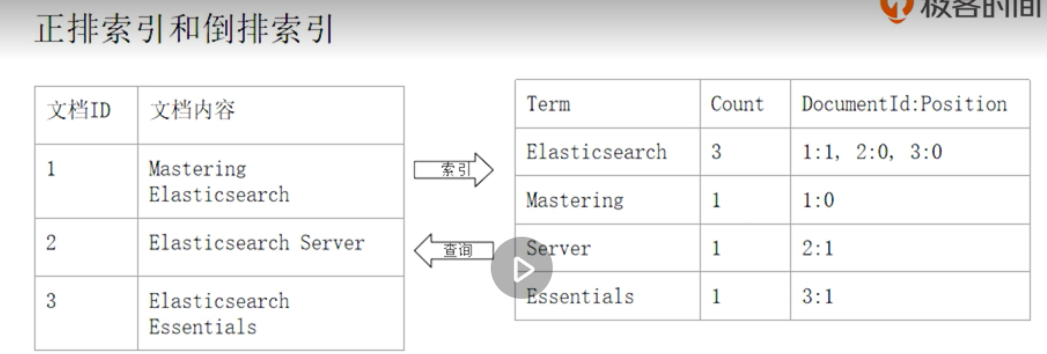
Forward index type catalog contents of a Book
The inverted index is the content of the corresponding directory


Analyst participle



Using the analyzer API

standard
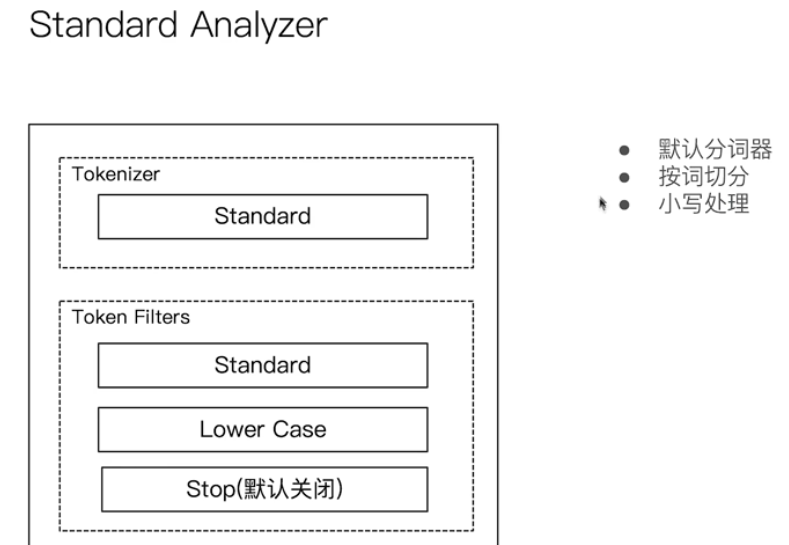
Participle demo
#Simple Analyzer – non alphabetic segmentation (symbols filtered), lowercase processing #Stop Analyzer - lowercase processing, the, a, is #Whitespace Analyzer – split by spaces, not lowercase #Keyword Analyzer – uses input as output without segmentation #Pattern analyzer – regular expression, default \ W + (non character delimited) #Language – provides word breakers in more than 30 common languages #2 running Quick brown-foxes leap over lazy dogs in the summer evening #See the effects of different analyzer s #standard GET _analyze { "analyzer": "standard", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #simpe GET _analyze { "analyzer": "simple", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } GET _analyze { "analyzer": "stop", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #stop GET _analyze { "analyzer": "whitespace", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #keyword GET _analyze { "analyzer": "keyword", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } GET _analyze { "analyzer": "pattern", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } #english GET _analyze { "analyzer": "english", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." } POST _analyze { "analyzer": "icu_analyzer", "text": "What he said is true. "" } POST _analyze { "analyzer": "standard", "text": "What he said is true. "" } POST _analyze { "analyzer": "icu_analyzer", "text": "This apple is not very delicious" }
Chinese participle


Search API

response
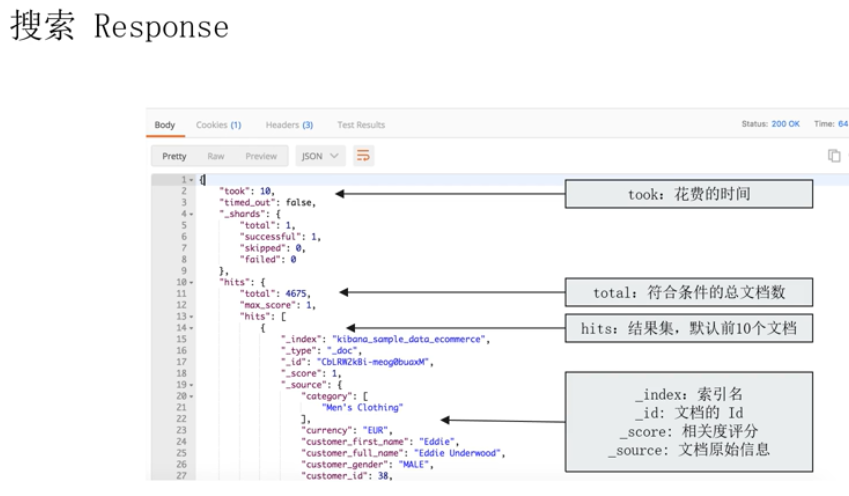
Search relevance
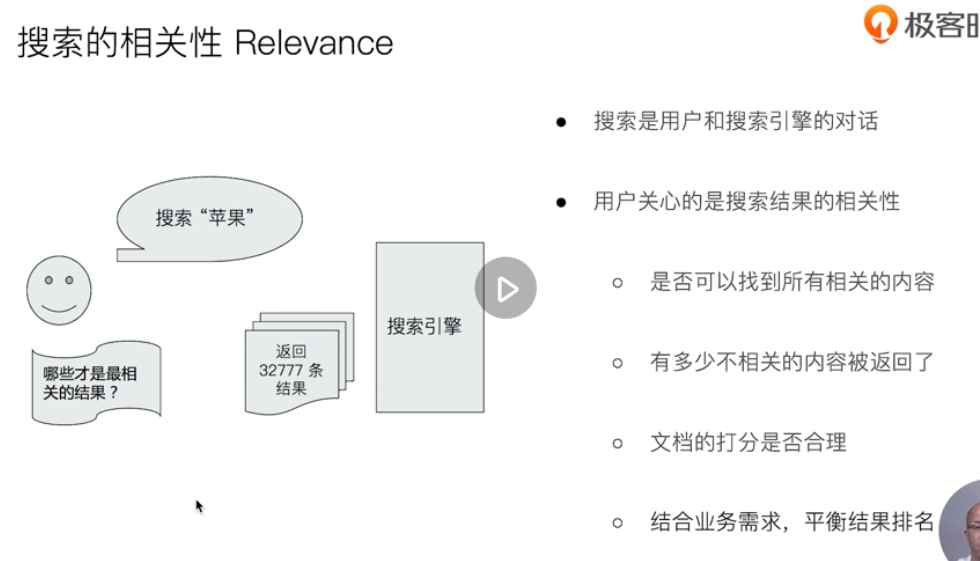

Measuring relevance

quest Body and Query DSL
sort

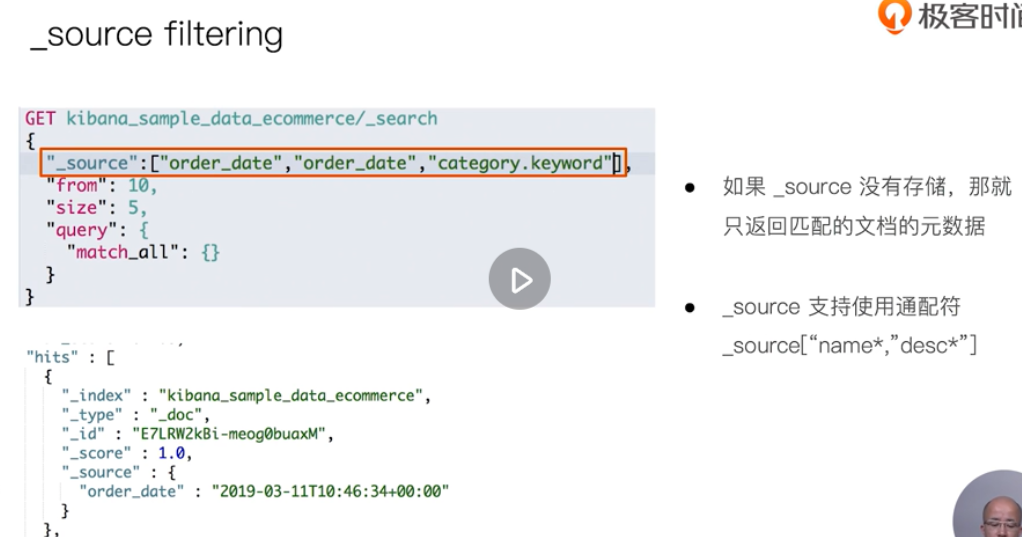
_source filtering
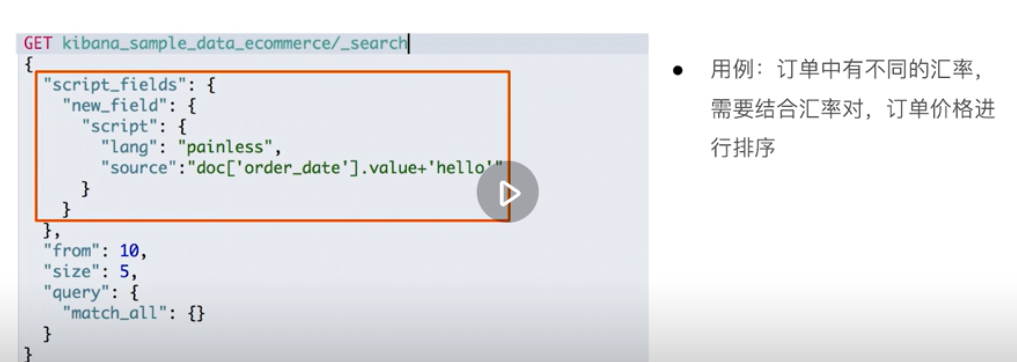
Script fields
Phrase Search
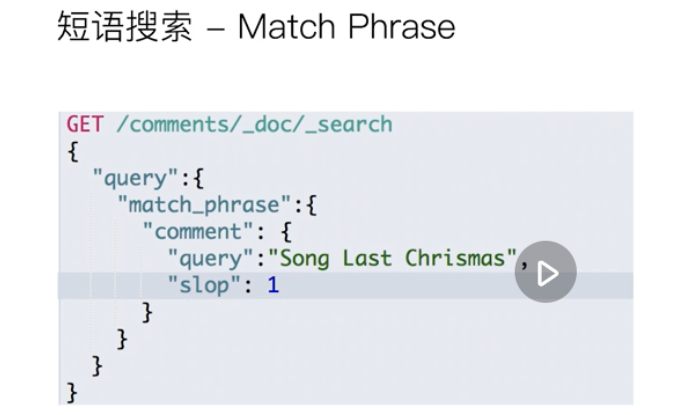
With slop, you can query the corresponding content, but there are other values in the middle, such as "song a last Chris"
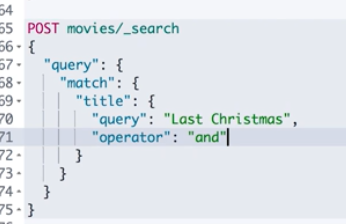
title with and as result must have Last Christmas
Query string


Mapping



Automatic type recognition
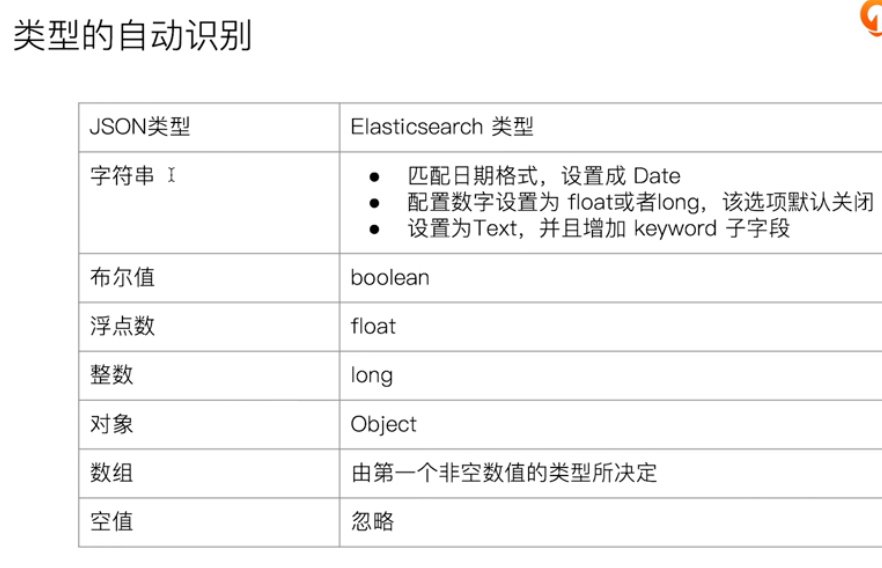
Null ignore, can be replaced by an empty string, or configure null_value for the field
Update mapping field type

Default dynatic is true
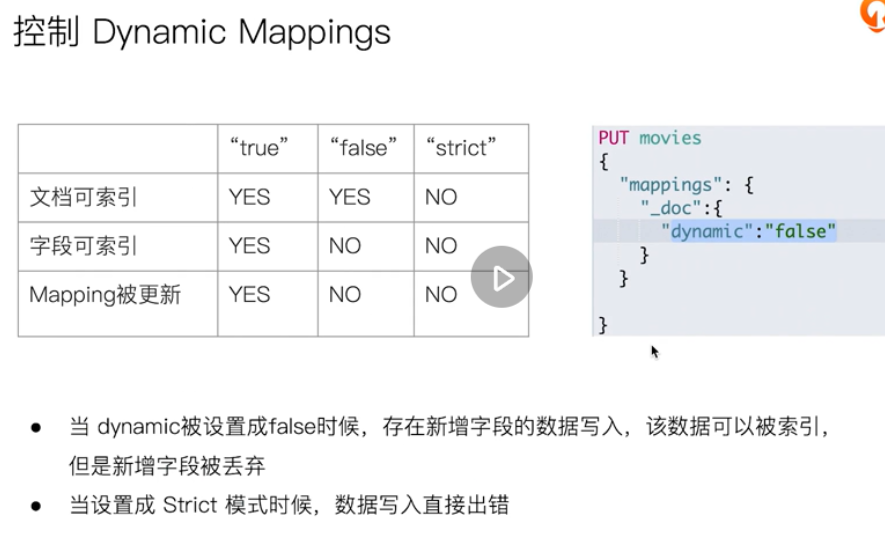
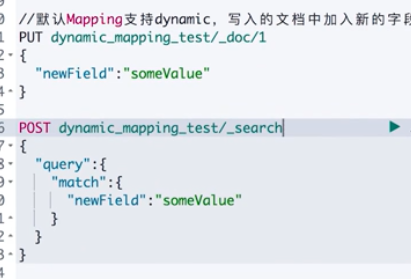
Mapping settings



null_value

copy to


array

mapping multi field features and configuring custom Analyzer


exact values, full text
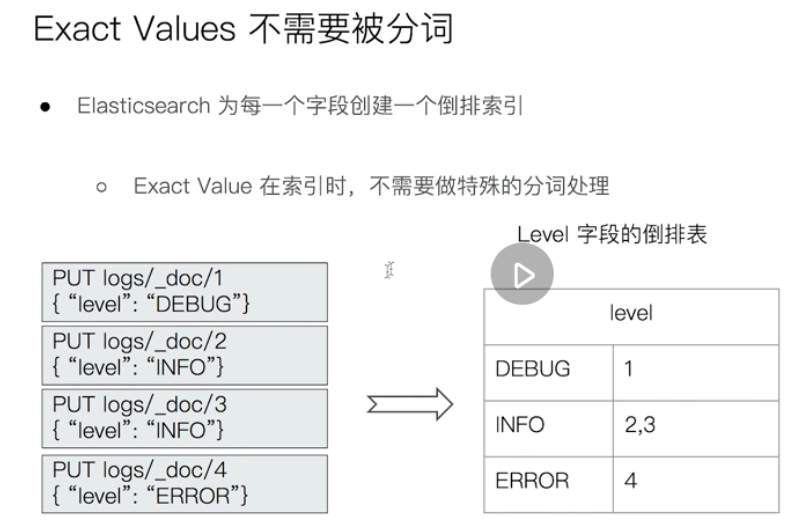
Custom participle




Reference resources https://www.elastic.co/guide/en/elasticsearch/reference/master/analysis-stop-tokenfilter.html

index template





Aggregate analysis

Aggregation classification

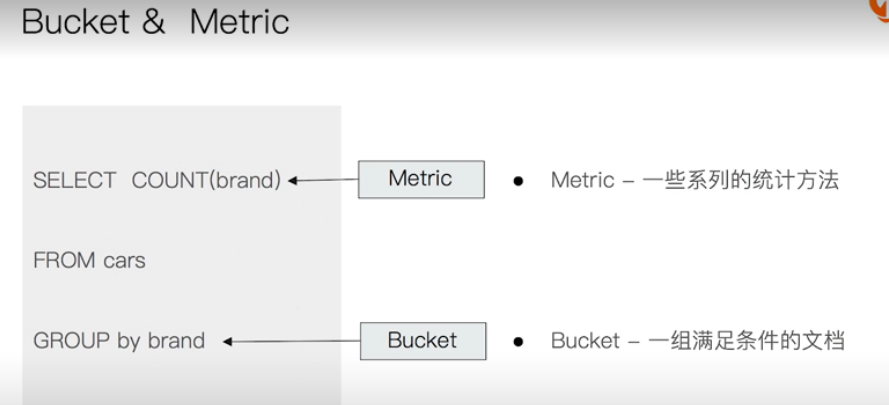



nesting

es summary



Drill down
term query

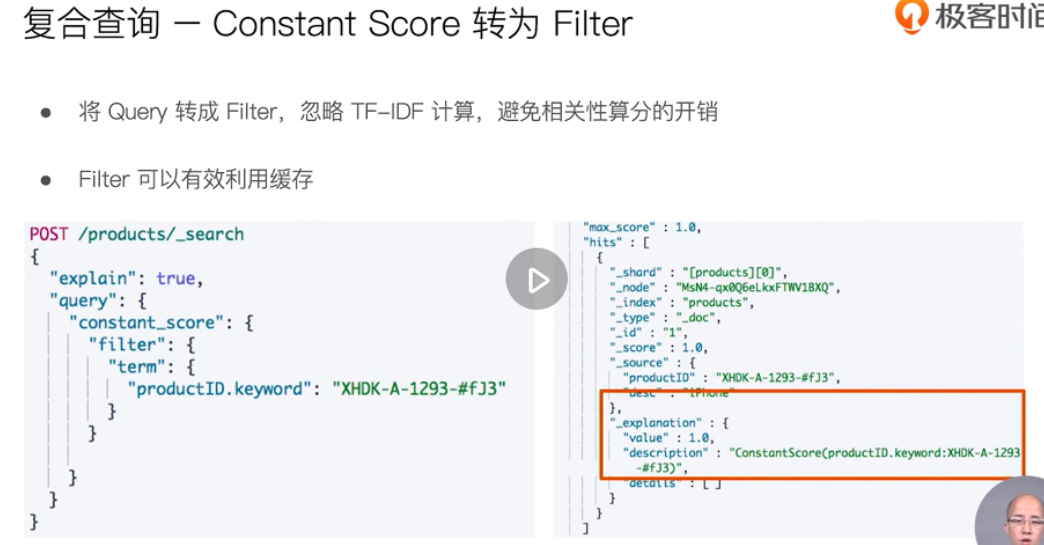
Full text query

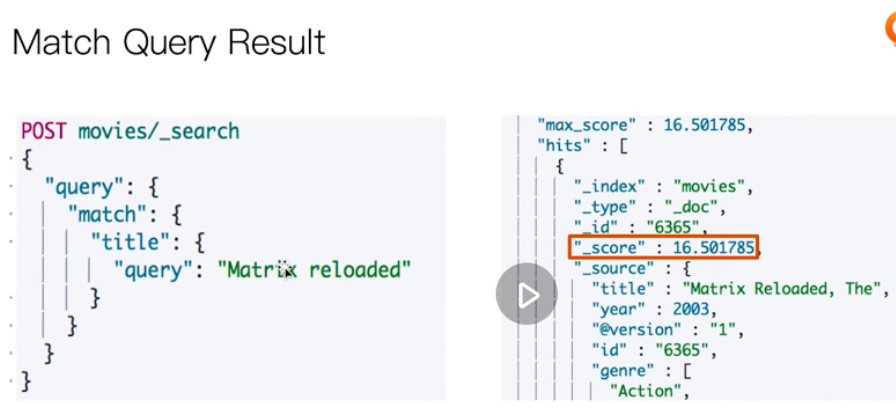

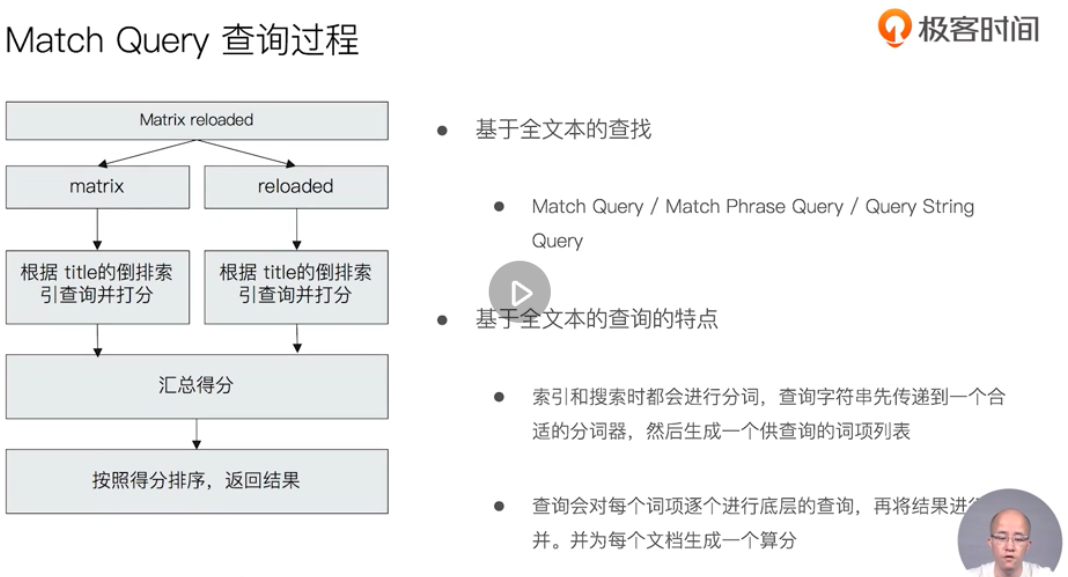

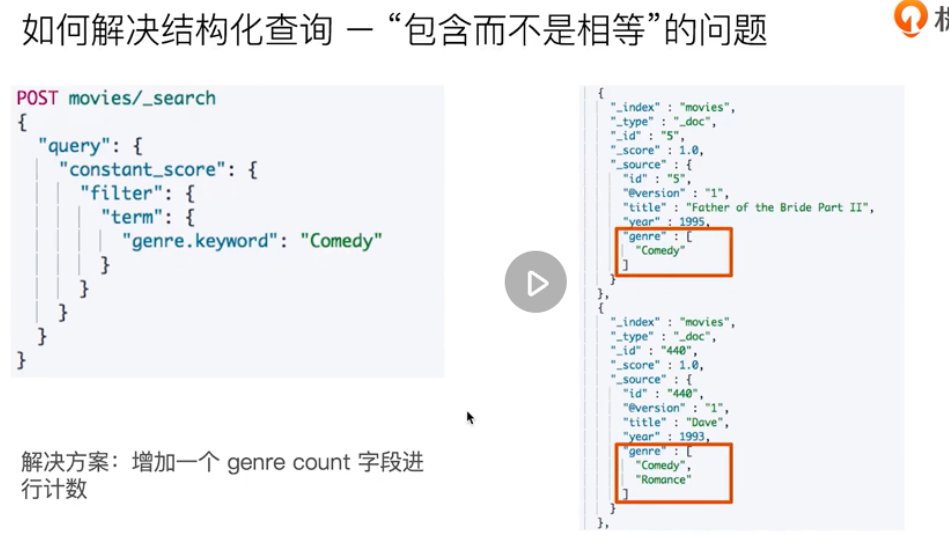
Structured search


Date range
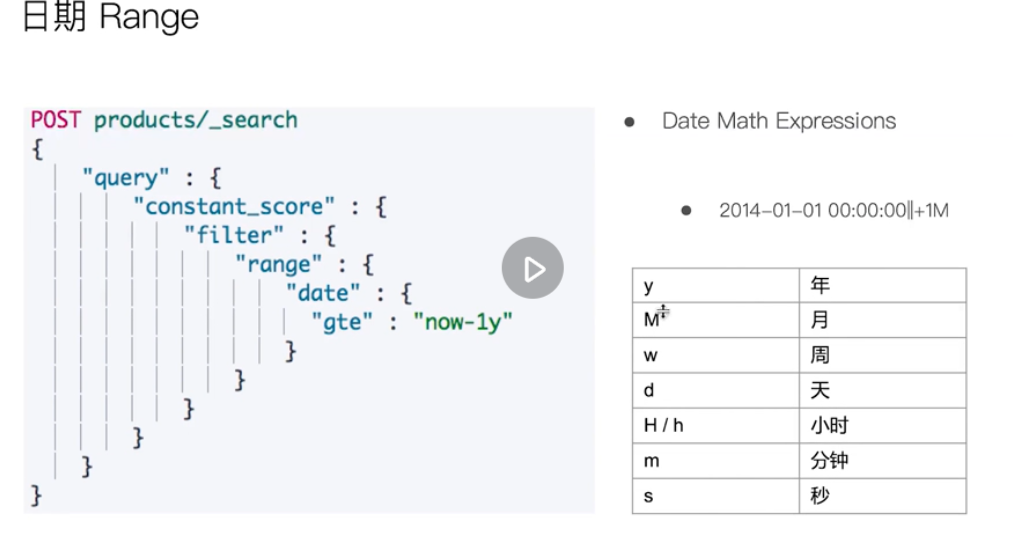

Relevance score of search
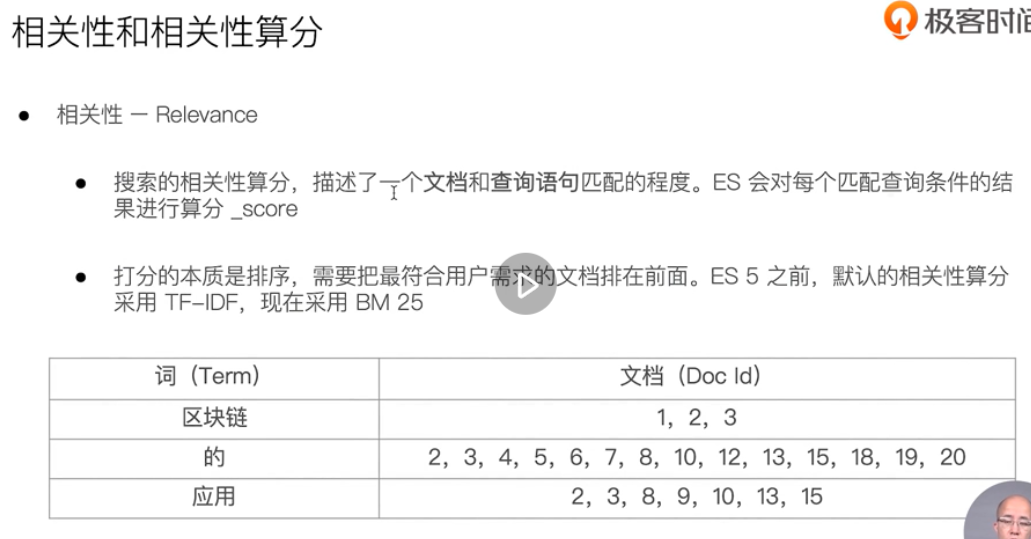
Word frequency TF



Boosting

Multi string and multi field query, filter

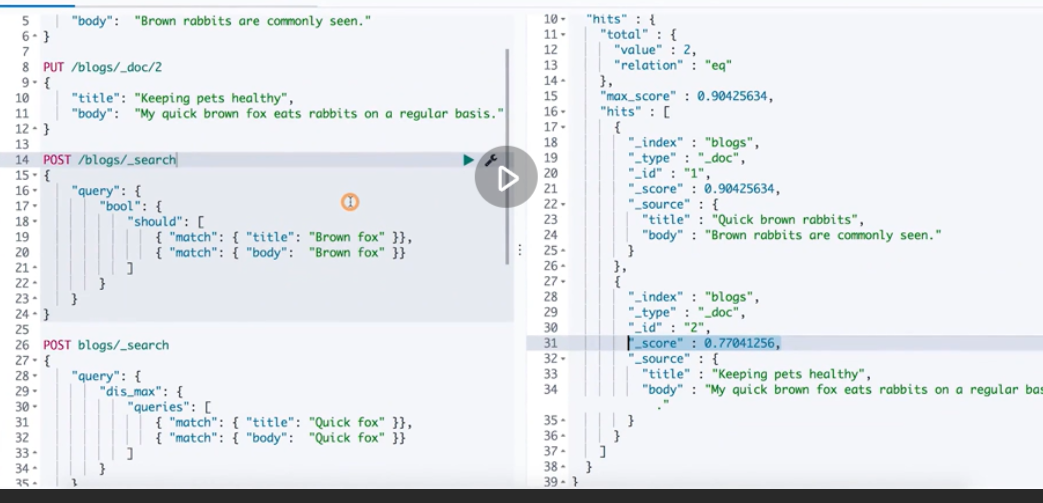
bool query






boost affects the order and content of returned results
not quite not
DELETE news POST /news/_bulk { "index": { "_id": 1 }} { "content":"Apple Mac" } { "index": { "_id": 2 }} { "content":"Apple iPad" } { "index": { "_id": 3 }} { "content":"Apple employee like Apple Pie and Apple Juice" } POST news/_search { "query": { "bool": { "must": { "match":{"content":"apple"} } } } } POST news/_search { "query": { "bool": { "must": { "match":{"content":"apple"} }, "must_not": { "match":{"content":"pie"} } } } } POST news/_search { "query": { "boosting": { "positive": { "match": { "content": "apple" } }, "negative": { "match": { "content": "pie" } }, "negative_boost": 0.5 } } }
In combination with the above, most not or negative can filter the information without pie or rank it last. Negative can control the accuracy of the query
Single string multi field query


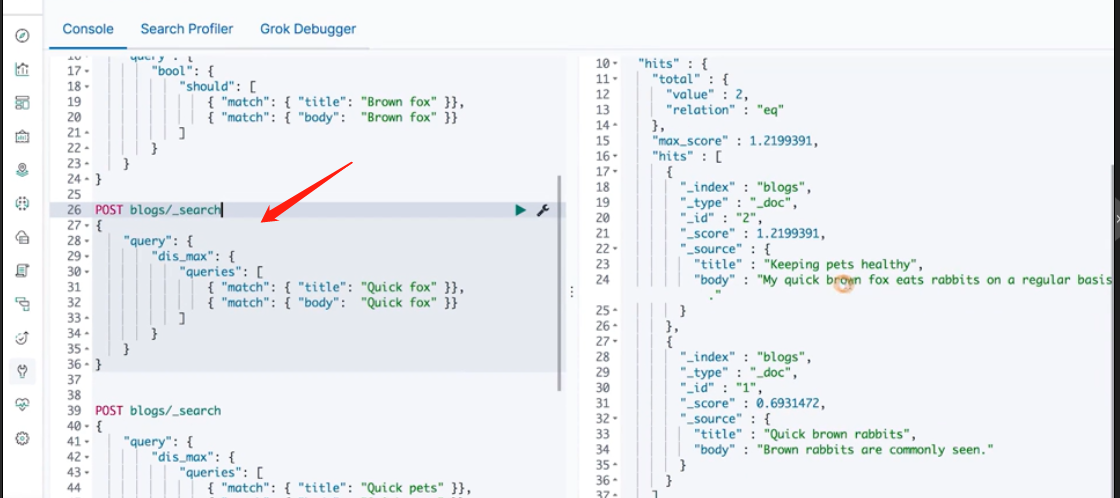

Single string multi field query: Multi Match


Here title^10 stands for weight

Multilingual and Chinese word segmentation





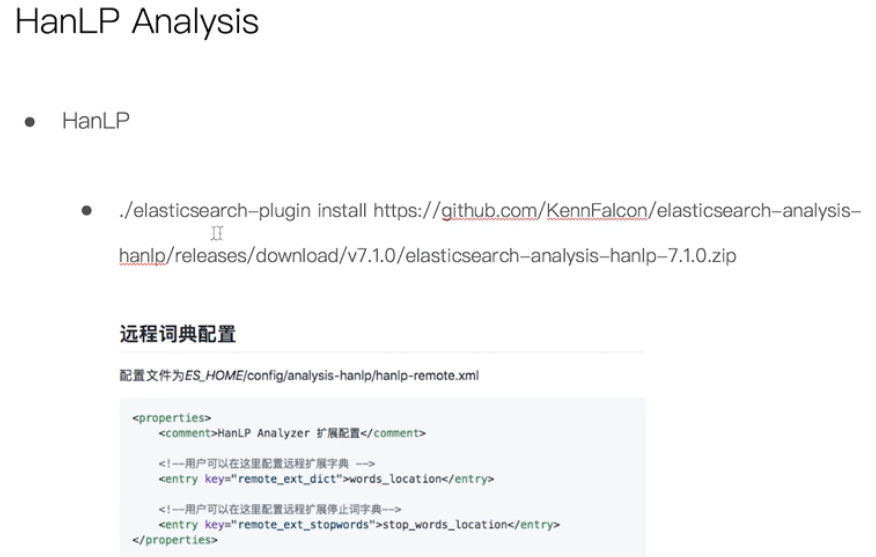

Test relevance


Query with search Template and index Alias

index alias

When the index is renamed or rebuilt, the alias can be used to make the front end not need to be modified and continue to access.
Comprehensive sorting: Function Score Query optimization score


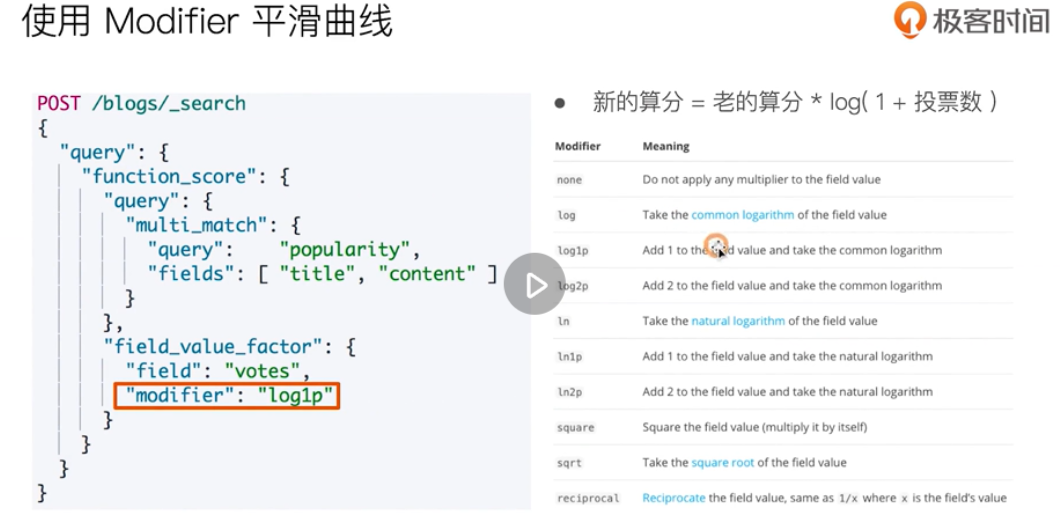
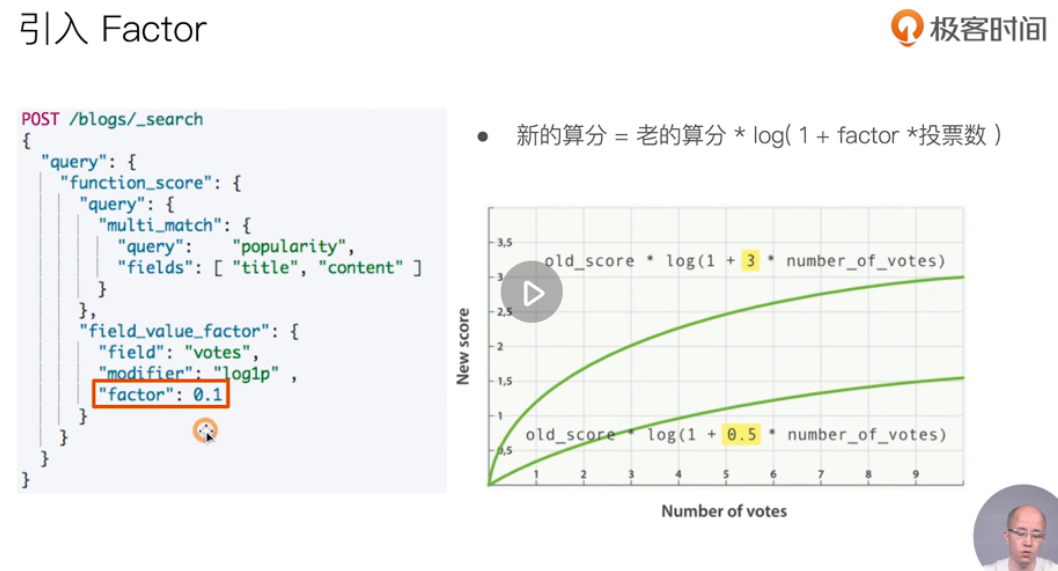

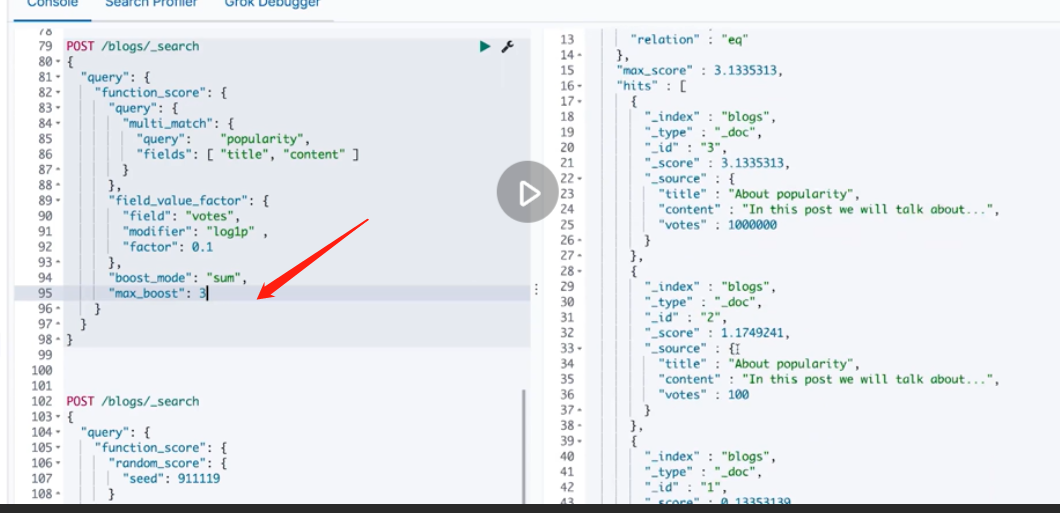

That is, the seed value is the same, and the random content is consistent
term&Phrase Suggester




Autocomplete and context based prompt


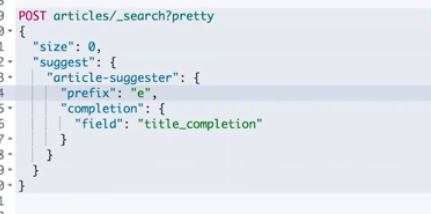
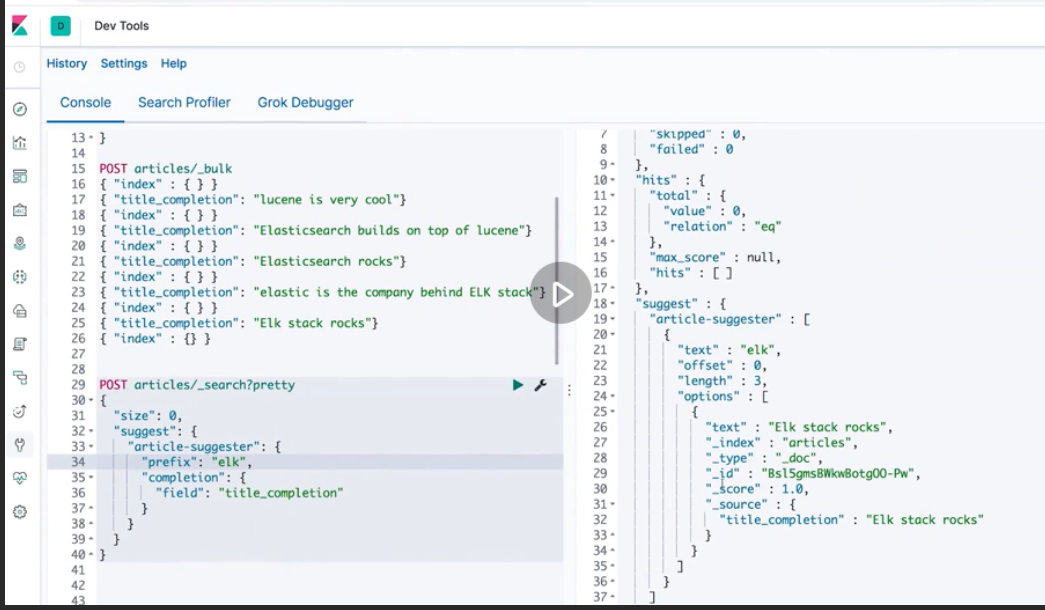
Context prompt:


Configure cross cluster search

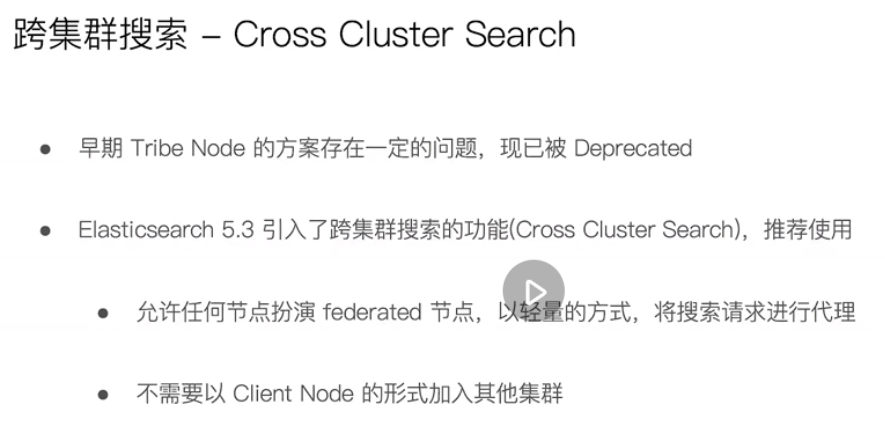
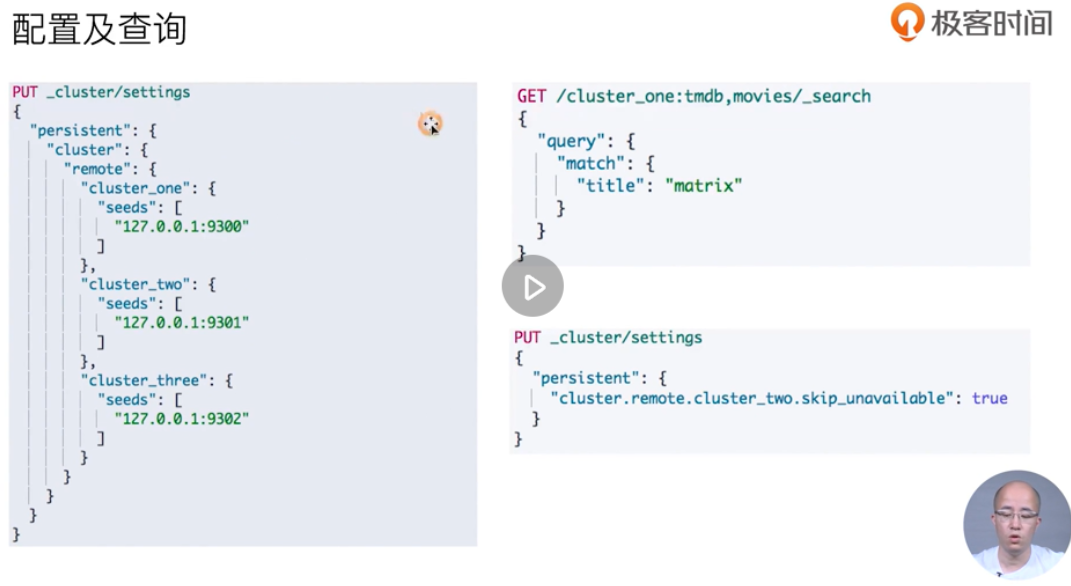
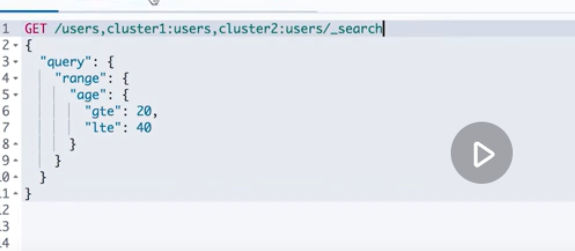
Cross cluster search is the example above
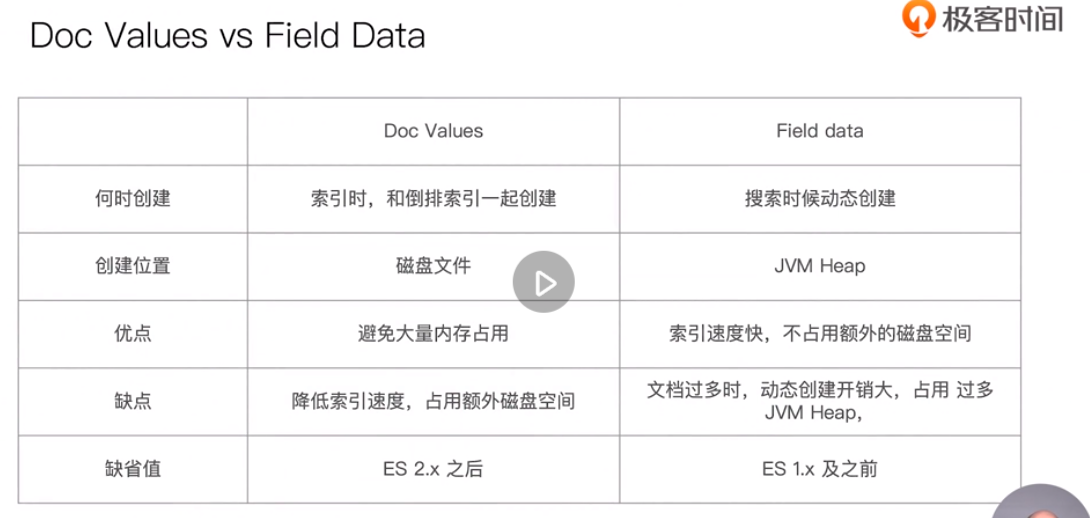
Sorting and DOC values & fiedlddata


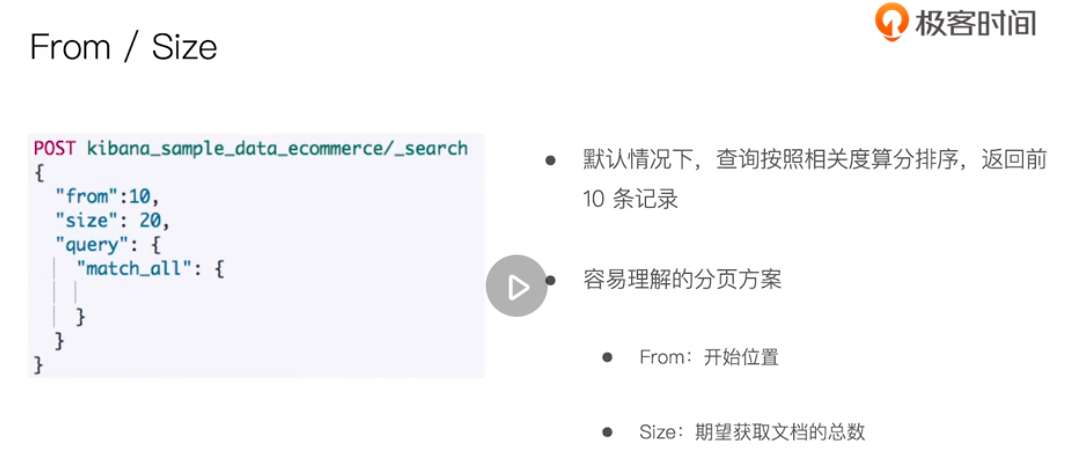
Paging and traversal
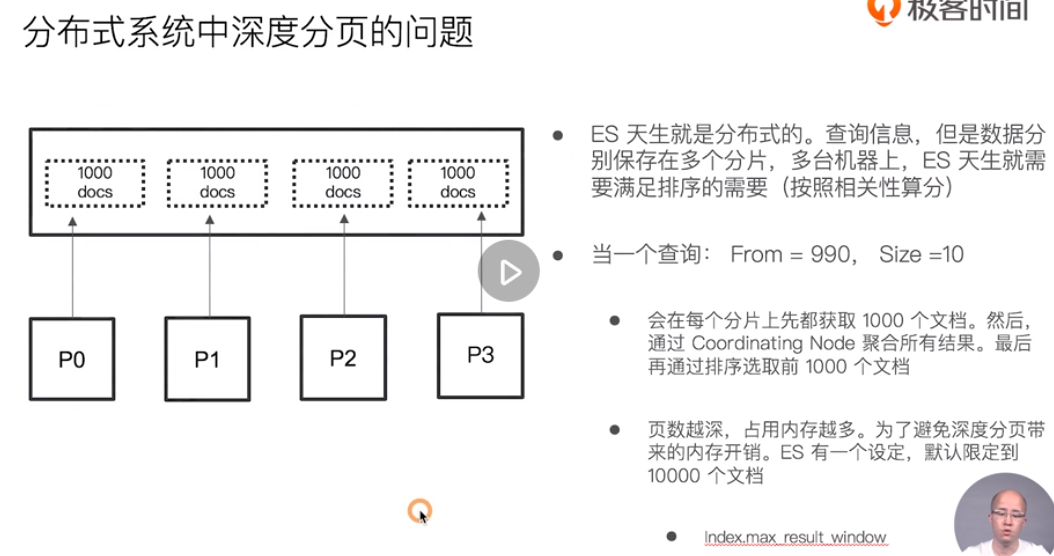
If the default from exceeds 10000 or the size exceeds 10000, an error will be reported.
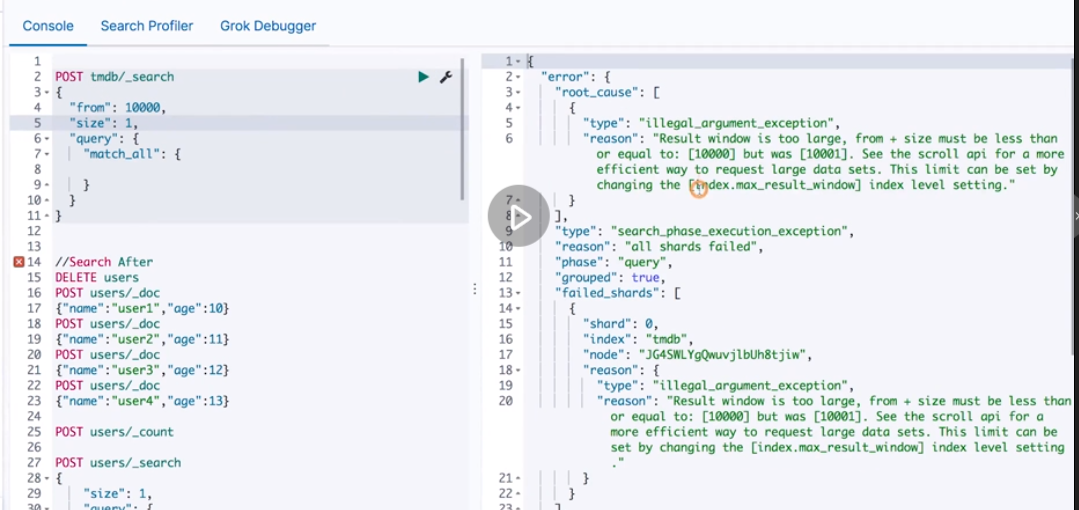
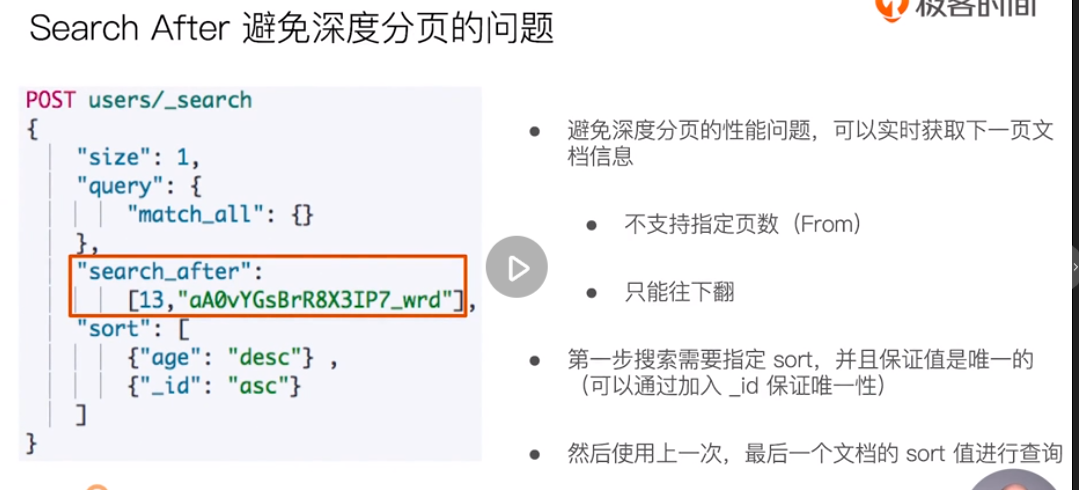
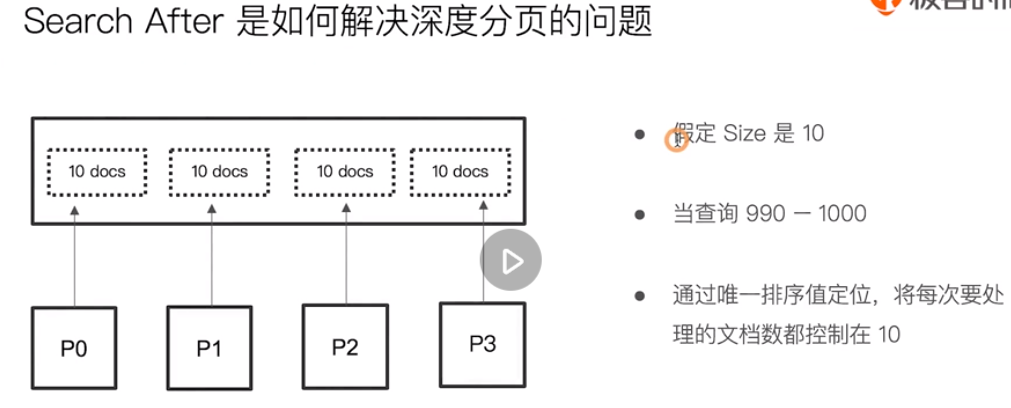
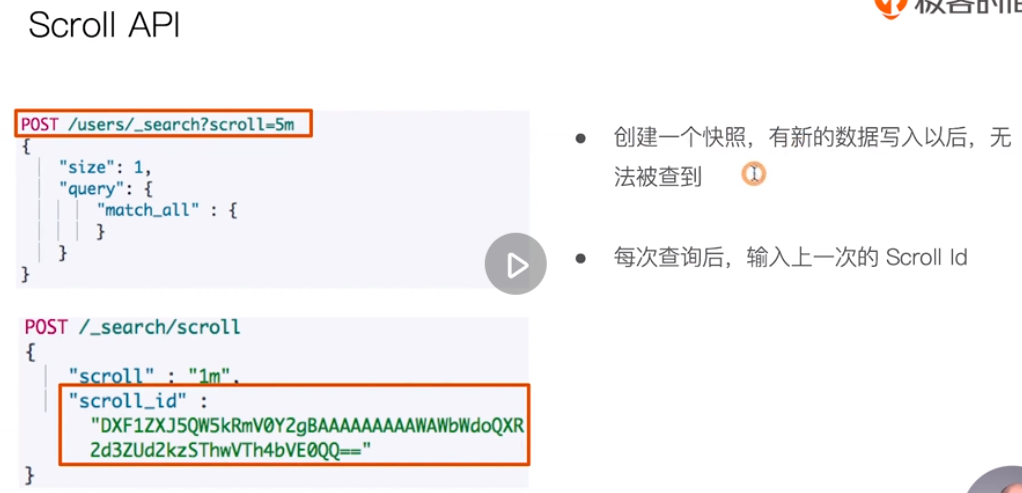

Handle concurrent read and write operations
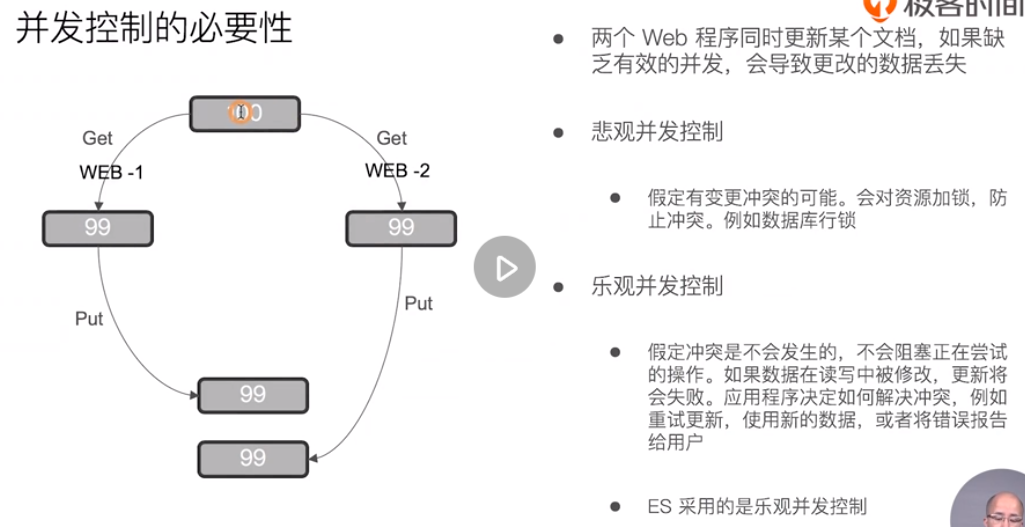

Concurrent update. If the version is wrong, an error will be reported
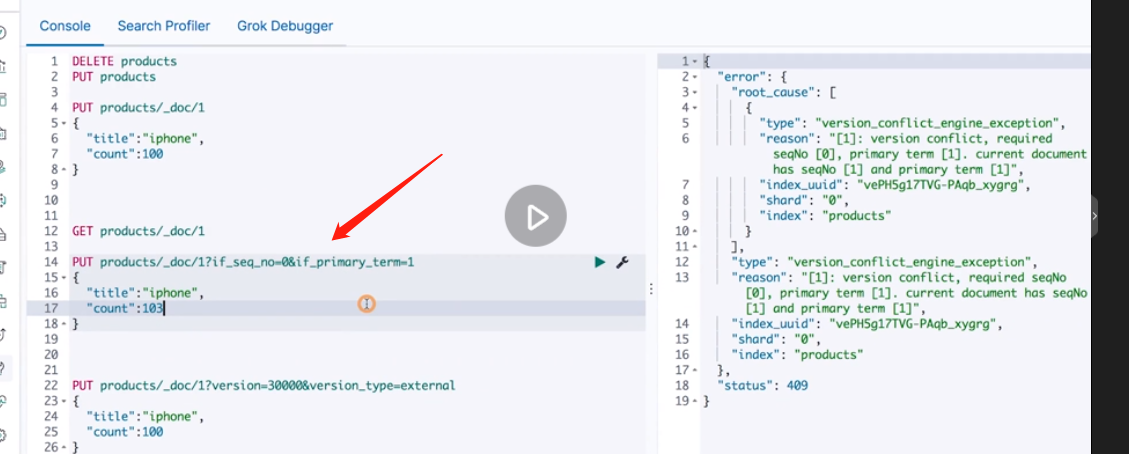
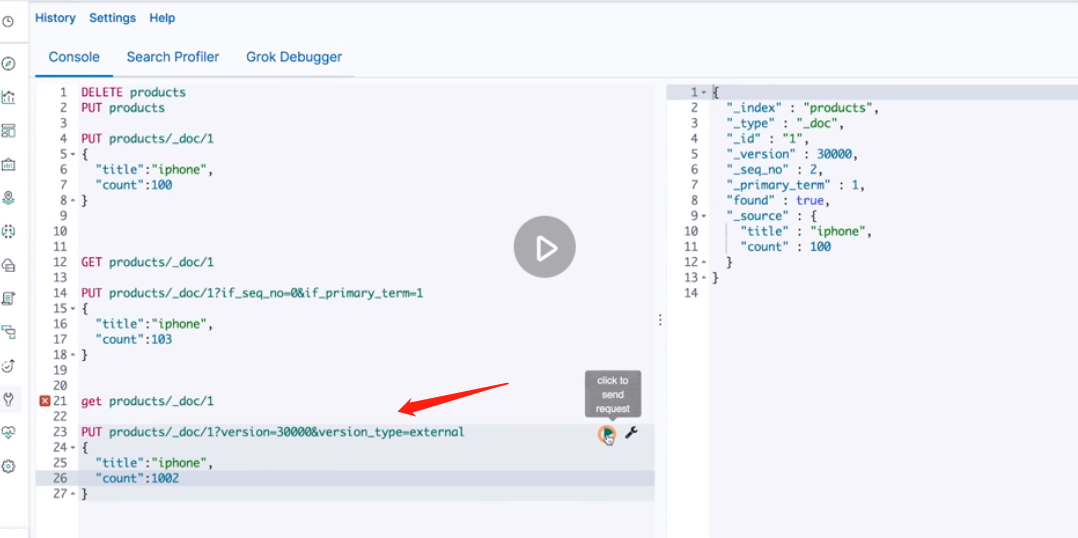
It can also be updated through version
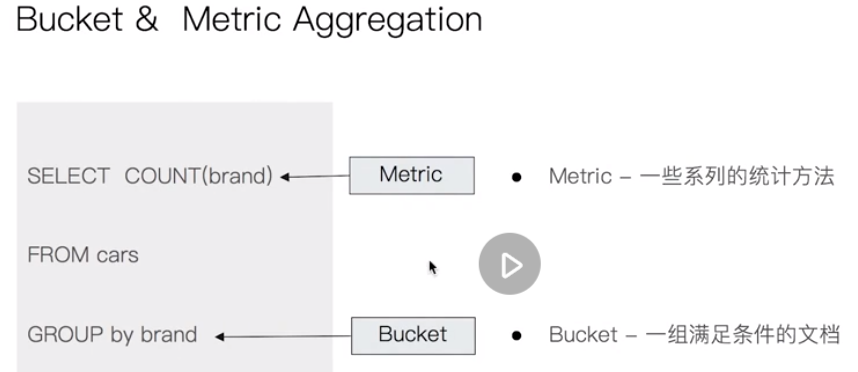
In depth aggregation analysis
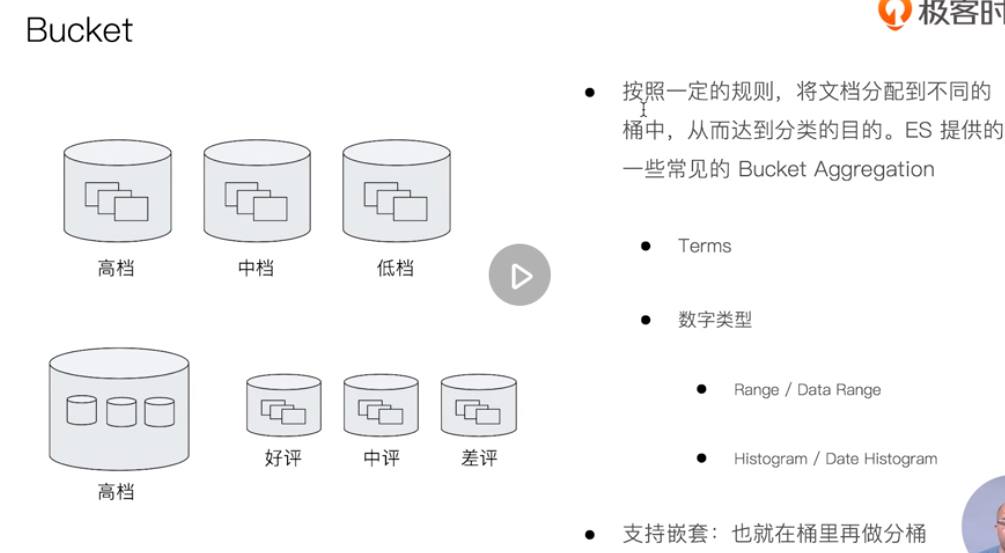
Bucket & metric aggregation analysis and nested aggregation
aggregation usage



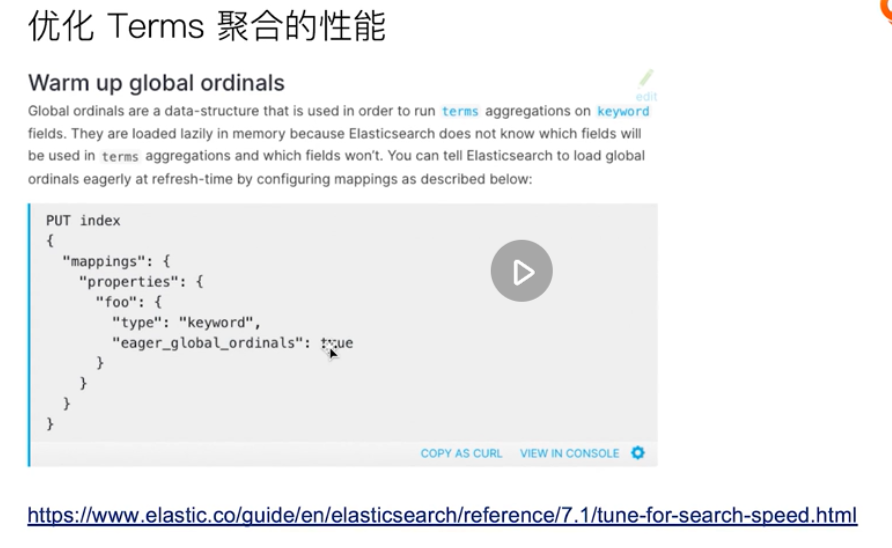
This configuration can be opened when aggregate queries are frequent, index data is updated or added frequently, and performance requirements are high


pipeline aggregation analysis: aggregation and re aggregation


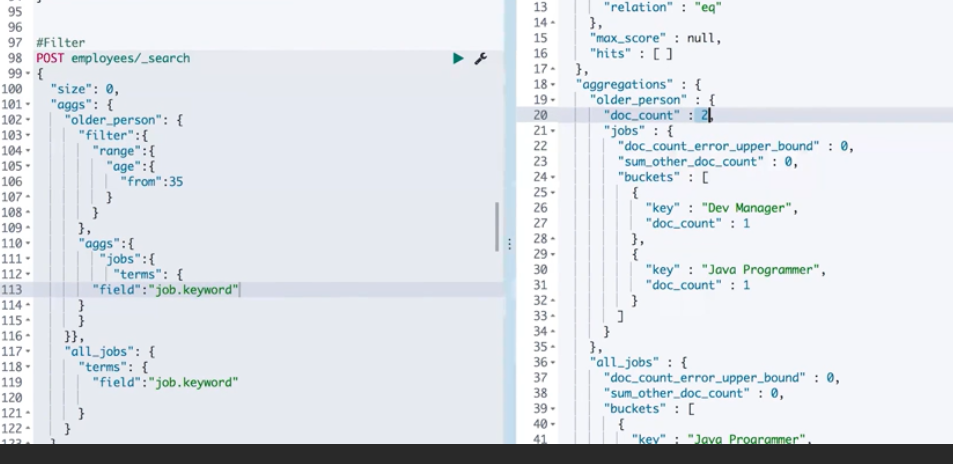
Aggregation scope and ordering


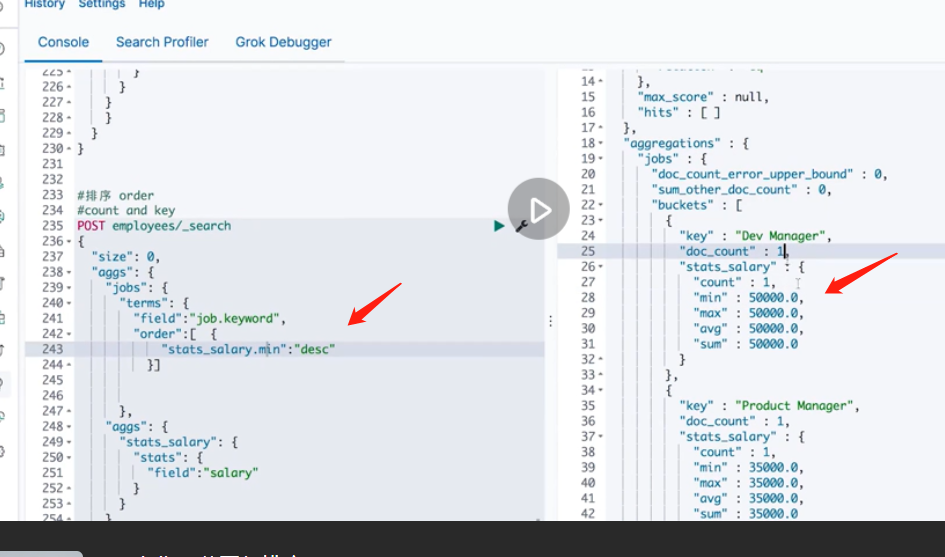
It can be sorted according to the attributes corresponding to stats, such as the minimum value
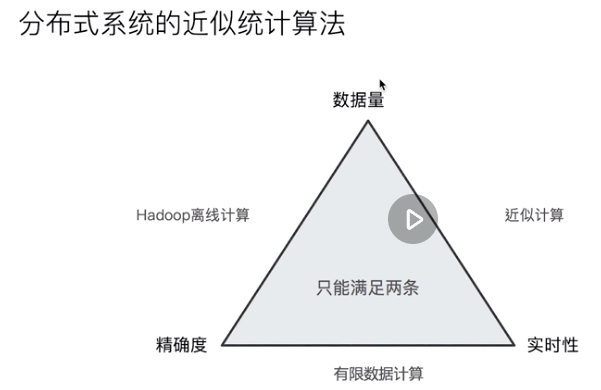
Principle and accuracy of aggregate analysis
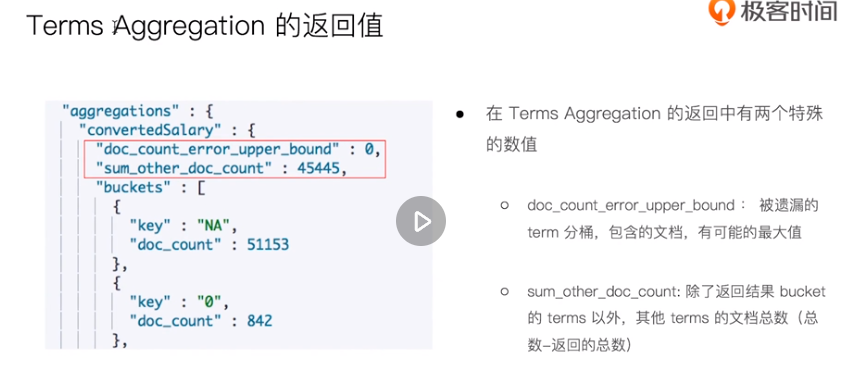
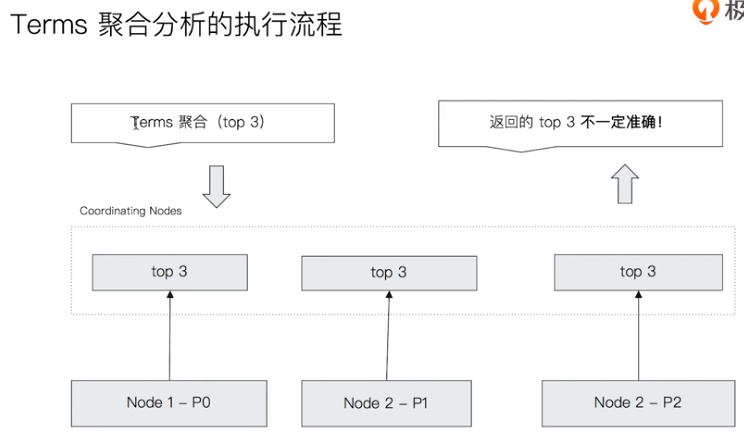


ES modeling






Data modeling best practices




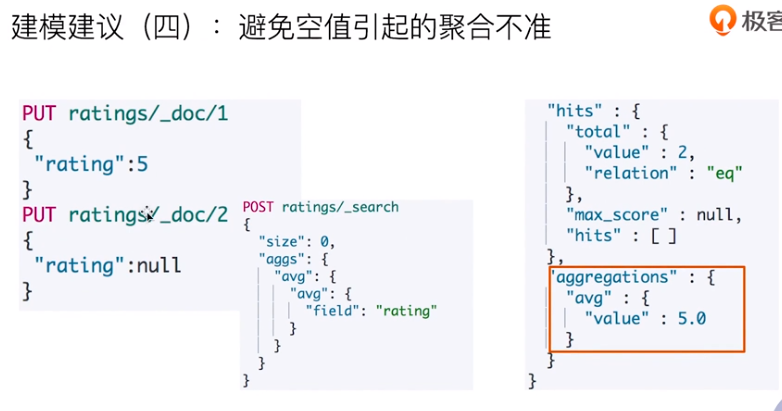

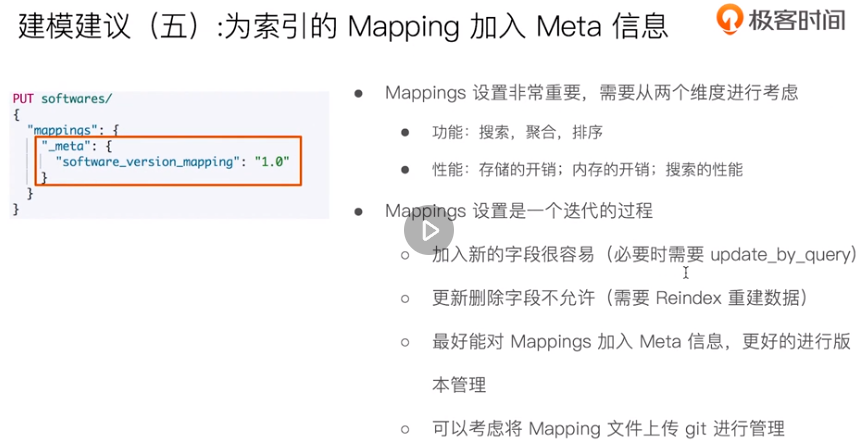
Segment merging, merge optimization



Improve cluster read performance

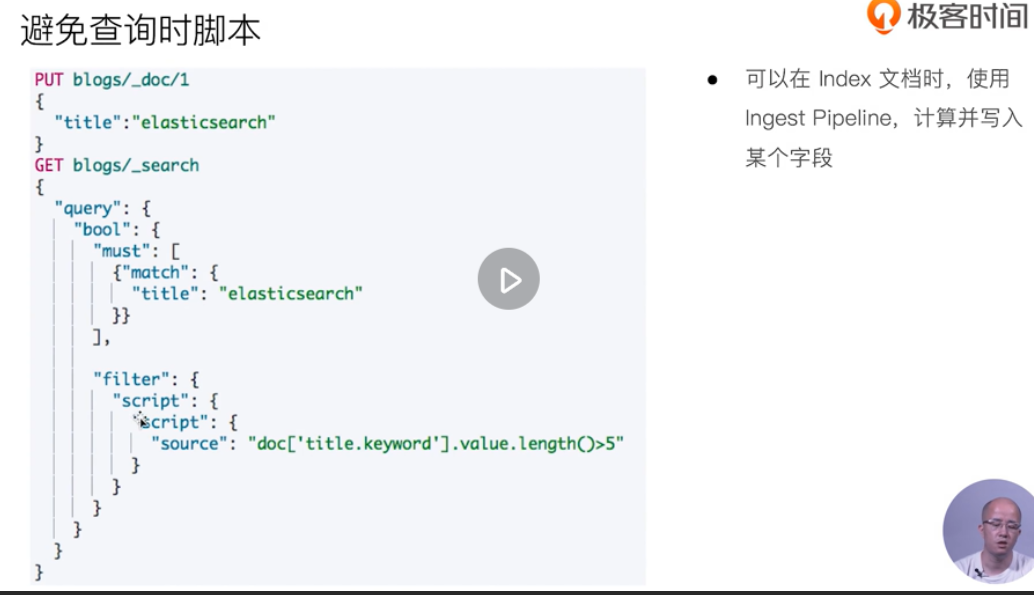



Cluster write performance

http 429 Too Many Requests (this happens when too much content is written, or when too much is written)



The string text will generate a corresponding keyword by default. This is not good. If it is not used






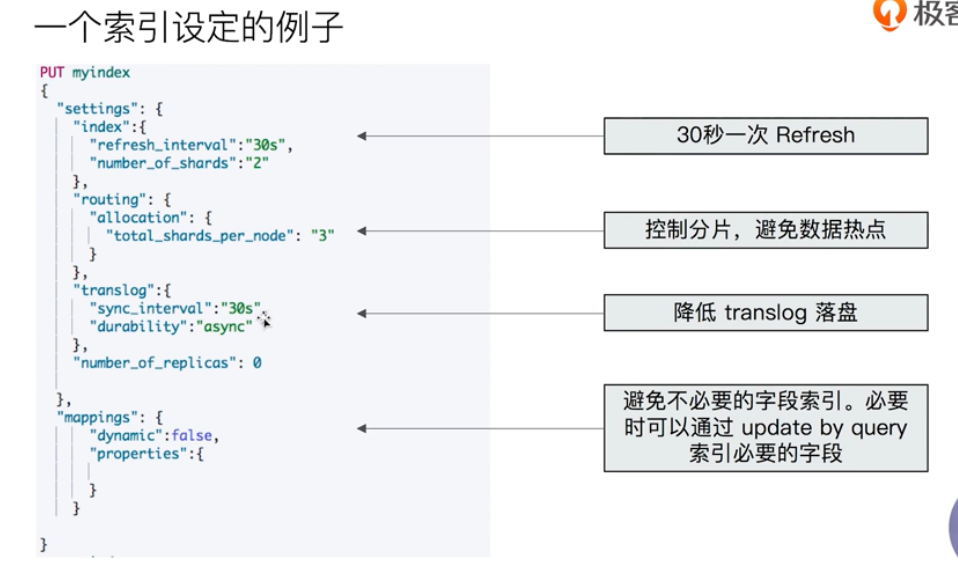
Cache and use breaker to limit memory usage






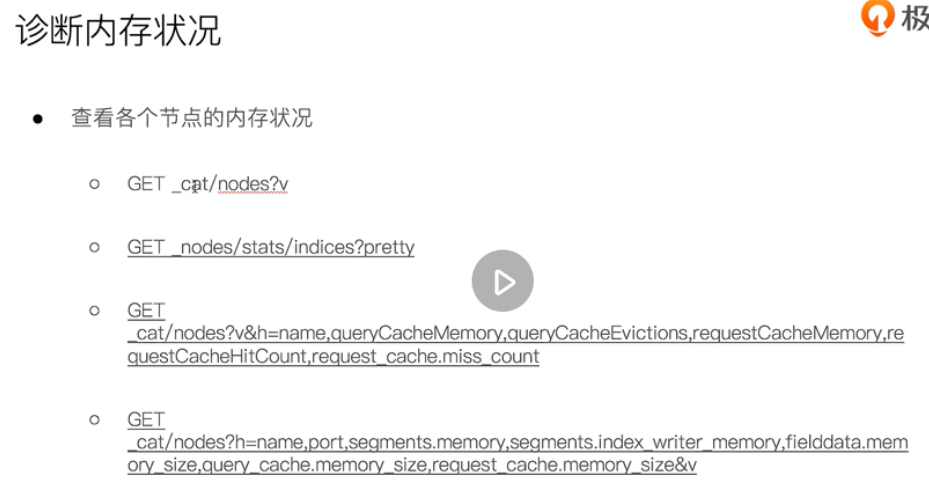



circuit breaker


Cluster backup


Index lifecycle management

The performance of shrink api is better than reindex-
The rollover API can use alias to point to a new index

That is, when the amount of data in an index is too large, you can use this method to write the data into a new index.


management tool
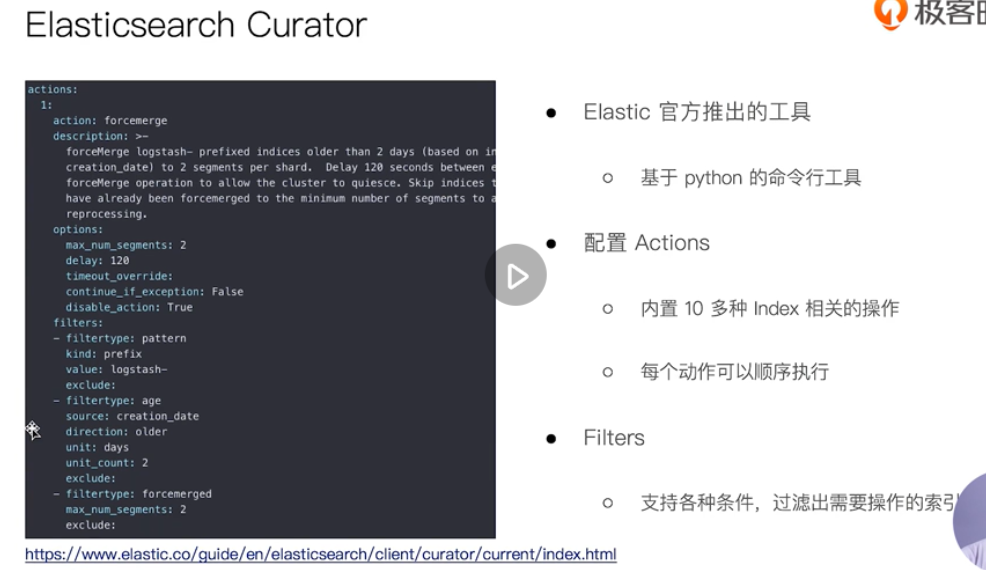
elasticsearch curator
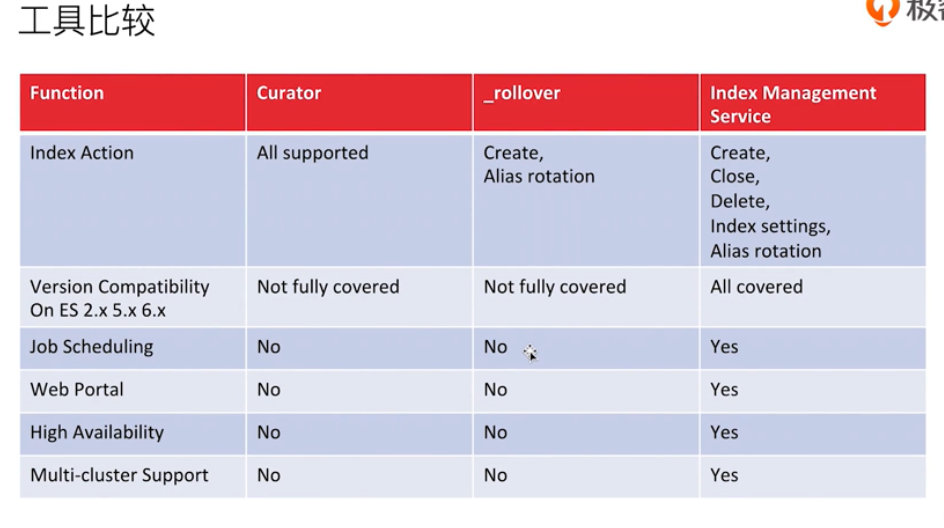
Cluster data backup

You should not simply back up the files in the data directory of es, which is not recommended by the official.

The above documents can be referred to: https://github.com/geektime-geekbang/geektime-ELK