Source: blog csdn. net/weixin_ 44671737/article/details/114456257
abstract
For a company, the amount of data is increasing. It is difficult to find this information quickly. In the computer field, there is a special field IR (information retrieval) to study how to obtain information and do information retrieval.
Domestic search engines such as Baidu also belong to this field. It is very difficult to implement a search engine by themselves. However, information search is very important for every company. Developers can also choose some open-source projects in the market to build their own on-site search engine. This paper will build such an information retrieval project through ElasticSearch.
1. Technical selection
- The search engine service uses ElasticSearch
- The external web services provided are springboot web
1.1 ElasticSearch
Elasticsearch is a Lucene based search server. It provides a distributed multi-user full-text search engine based on RESTful web interface. Elasticsearch is developed in the Java language and released as an open source under the Apache license terms. It is a popular enterprise search engine. Elasticsearch is used in cloud computing. It can achieve real-time search, stable, reliable, fast and easy to install and use.
The official client is in Java NET (C#), PHP, Python, Apache Groovy, Ruby and many other languages are available. According to the ranking of DB engines, Elasticsearch is the most popular enterprise search engine, followed by Apache Solr and based on Lucene. 1
At present, ElasticSearch and Solr are the most common open source search engines in the market. Both of them are implemented based on Lucene. ElasticSearch is relatively heavyweight and performs better in distributed environment. The selection of the two needs to consider specific business scenarios and data levels. In the case of small amount of data, it is completely necessary to use search engine services such as Lucene and retrieve them through relational database.
1.2 springBoot
Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can "just run".2
Now, springBoot is the absolute mainstream in web development. It is not only the advantage of development, but also has a very good performance in deployment, operation and maintenance. In addition, the spring ecosystem has too much influence and can find various mature solutions.
1.3 ik word splitter
elasticSearch itself does not support Chinese word segmentation. You need to install a Chinese word segmentation plug-in. If you need to do Chinese information retrieval, Chinese word segmentation is the basis. Select ik here. After downloading, put it into the plugin directory of the installation location of elasticSearch.
2 environmental preparation
elastiSearch and kibana (optional) need to be installed, and lk word segmentation plug-in is required.
- Install the elasticsearch website The author uses 7.5 1.
- ik plugin download ik plugin github address Note that you can download the same ik plug-in as you downloaded the elasticsearch version.
- Put the ik plug-in into the plugins package under the elasticsearch installation directory, create a new registration ik, extract the downloaded plug-in into the directory, and the plug-in will be loaded automatically when you start es.

- Set up springboot project idea - > new project - > spring initializer
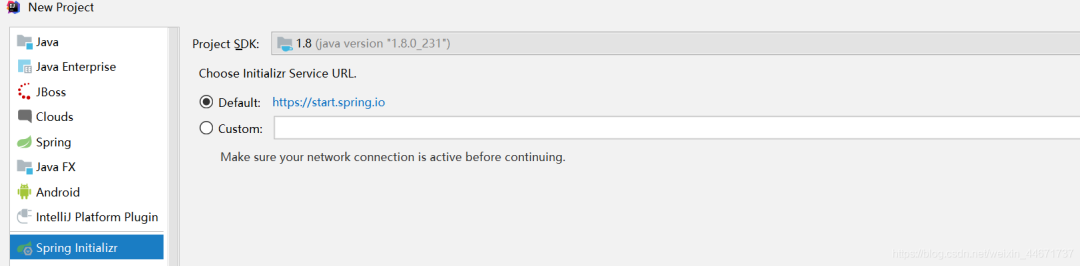
3 project structure
- Get data and use ik word segmentation plug-in
- Store data in the es engine
- The stored data is retrieved by es retrieval
- The java client using es provides external services
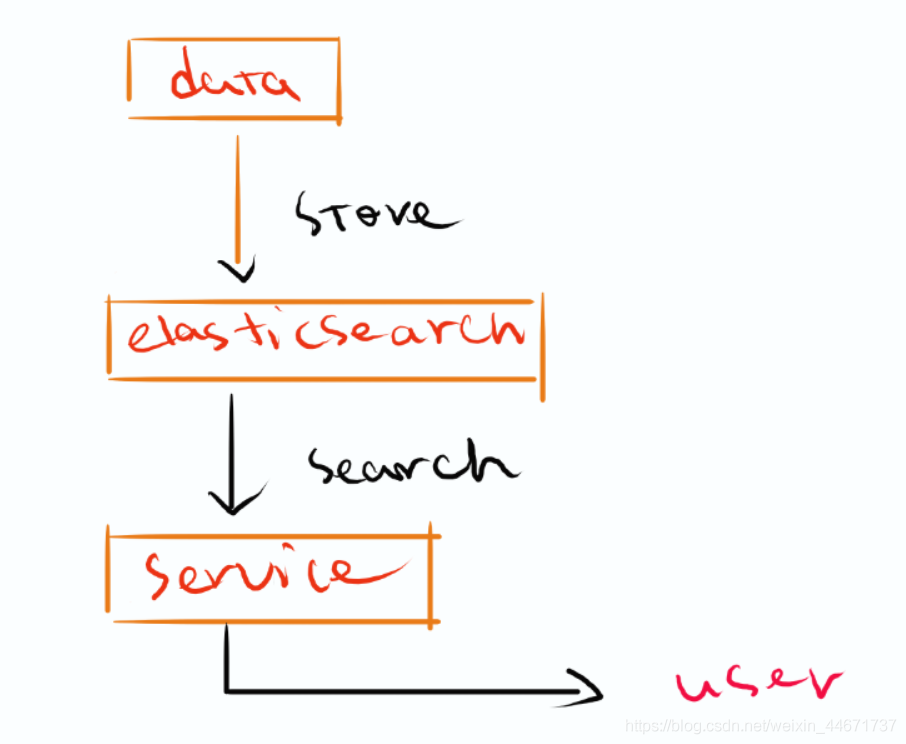
4 realization effect
4.1 search page
Simply implement a search box similar to Baidu.
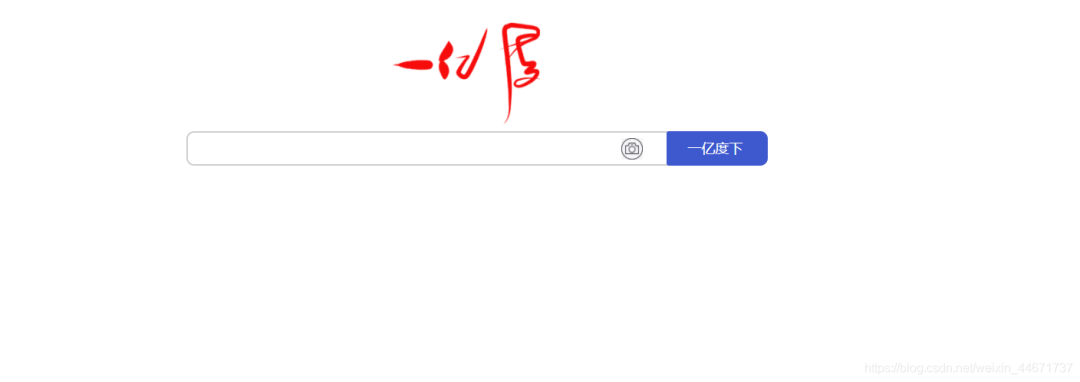
4.2 search results page
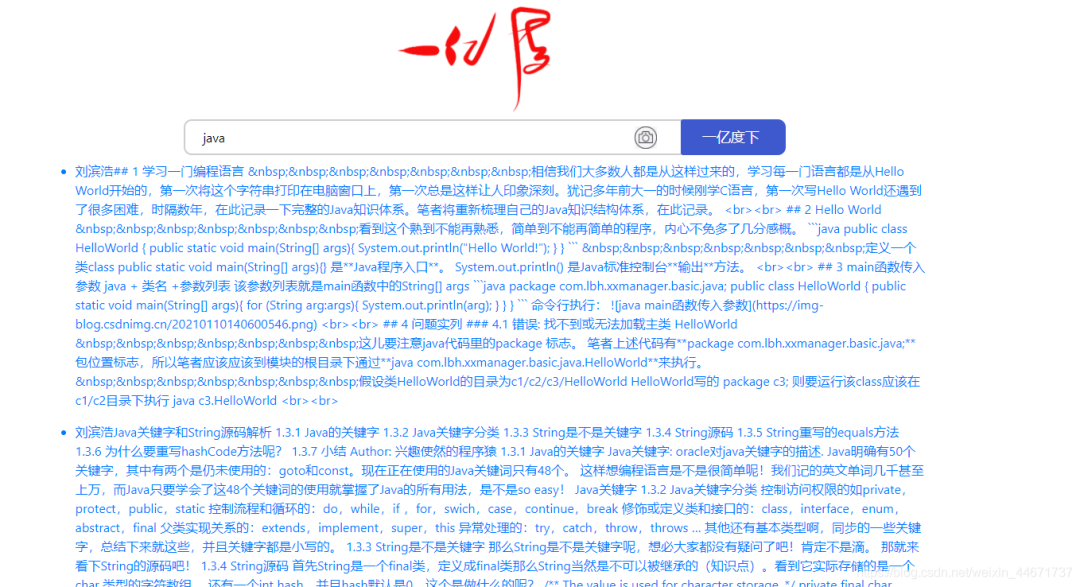
Click the first search result is my personal blog post. In order to avoid the problem of data copyright, the author stores all personal blog data in the es engine.
5 specific code implementation
5.1 implementation object of full-text retrieval
The following entity classes are defined according to the basic information of the blog. You mainly need to know the url of each blog post. Check the retrieved articles to jump to the url.
package com.lbh.es.entity;
import com.fasterxml.jackson.annotation.JsonIgnore;
import javax.persistence.*;
/**
* PUT articles
* {
* "mappings":
* {"properties":{
* "author":{"type":"text"},
* "content":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},
* "title":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},
* "createDate":{"type":"date","format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"},
* "url":{"type":"text"}
* } },
* "settings":{
* "index":{
* "number_of_shards":1,
* "number_of_replicas":2
* }
* }
* }
* ---------------------------------------------------------------------------------------------------------------------
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@Entity
@Table(name = "es_article")
public class ArticleEntity {
@Id
@JsonIgnore
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name = "author")
private String author;
@Column(name = "content",columnDefinition="TEXT")
private String content;
@Column(name = "title")
private String title;
@Column(name = "createDate")
private String createDate;
@Column(name = "url")
private String url;
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getCreateDate() {
return createDate;
}
public void setCreateDate(String createDate) {
this.createDate = createDate;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
5.2 client configuration
Configure the client of es through java.
package com.lbh.es.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;
/**
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@Configuration
public class EsConfig {
@Value("${elasticsearch.schema}")
private String schema;
@Value("${elasticsearch.address}")
private String address;
@Value("${elasticsearch.connectTimeout}")
private int connectTimeout;
@Value("${elasticsearch.socketTimeout}")
private int socketTimeout;
@Value("${elasticsearch.connectionRequestTimeout}")
private int tryConnTimeout;
@Value("${elasticsearch.maxConnectNum}")
private int maxConnNum;
@Value("${elasticsearch.maxConnectPerRoute}")
private int maxConnectPerRoute;
@Bean
public RestHighLevelClient restHighLevelClient() {
// Split address
List<HttpHost> hostLists = new ArrayList<>();
String[] hostList = address.split(",");
for (String addr : hostList) {
String host = addr.split(":")[0];
String port = addr.split(":")[1];
hostLists.add(new HttpHost(host, Integer.parseInt(port), schema));
}
// Convert to HttpHost array
HttpHost[] httpHost = hostLists.toArray(new HttpHost[]{});
// Building connection objects
RestClientBuilder builder = RestClient.builder(httpHost);
// Asynchronous connection delay configuration
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(connectTimeout);
requestConfigBuilder.setSocketTimeout(socketTimeout);
requestConfigBuilder.setConnectionRequestTimeout(tryConnTimeout);
return requestConfigBuilder;
});
// Configuration of asynchronous connections
builder.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.setMaxConnTotal(maxConnNum);
httpClientBuilder.setMaxConnPerRoute(maxConnectPerRoute);
return httpClientBuilder;
});
return new RestHighLevelClient(builder);
}
}
5.3 business code writing
It includes some information of retrieved articles. You can view relevant information from the dimensions of article title, article content and author information.
package com.lbh.es.service;
import com.google.gson.Gson;
import com.lbh.es.entity.ArticleEntity;
import com.lbh.es.repository.ArticleRepository;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.io.IOException;
import java.util.*;
/**
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@Service
public class ArticleService {
private static final String ARTICLE_INDEX = "article";
@Resource
private RestHighLevelClient client;
@Resource
private ArticleRepository articleRepository;
public boolean createIndexOfArticle(){
Settings settings = Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1)
.build();
// {"properties":{"author":{"type":"text"},
// "content":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"}
// ,"title":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},
// ,"createDate":{"type":"date","format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"}
// }
String mapping = "{\"properties\":{\"author\":{\"type\":\"text\"},\n" +
"\"content\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"search_analyzer\":\"ik_smart\"}\n" +
",\"title\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"search_analyzer\":\"ik_smart\"}\n" +
",\"createDate\":{\"type\":\"date\",\"format\":\"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd\"}\n" +
"},\"url\":{\"type\":\"text\"}\n" +
"}";
CreateIndexRequest indexRequest = new CreateIndexRequest(ARTICLE_INDEX)
.settings(settings).mapping(mapping,XContentType.JSON);
CreateIndexResponse response = null;
try {
response = client.indices().create(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
if (response!=null) {
System.err.println(response.isAcknowledged() ? "success" : "default");
return response.isAcknowledged();
} else {
return false;
}
}
public boolean deleteArticle(){
DeleteIndexRequest request = new DeleteIndexRequest(ARTICLE_INDEX);
try {
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
public IndexResponse addArticle(ArticleEntity article){
Gson gson = new Gson();
String s = gson.toJson(article);
//Create index create object
IndexRequest indexRequest = new IndexRequest(ARTICLE_INDEX);
//Document content
indexRequest.source(s,XContentType.JSON);
//http request through client
IndexResponse re = null;
try {
re = client.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return re;
}
public void transferFromMysql(){
articleRepository.findAll().forEach(this::addArticle);
}
public List<ArticleEntity> queryByKey(String keyword){
SearchRequest request = new SearchRequest();
/*
* Create search content parameter setting object: SearchSourceBuilder
* Compared with matchQuery, multiMatchQuery targets multiple fi eld s, that is, when there is only one fieldNames parameter in multiMatchQuery, its function is equivalent to matchQuery;
* When fieldNames has multiple parameters, such as field1 and field2, the query results either contain text in field1 or text in field2.
*/
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders
.multiMatchQuery(keyword, "author","content","title"));
request.source(searchSourceBuilder);
List<ArticleEntity> result = new ArrayList<>();
try {
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit:search.getHits()){
Map<String, Object> map = hit.getSourceAsMap();
ArticleEntity item = new ArticleEntity();
item.setAuthor((String) map.get("author"));
item.setContent((String) map.get("content"));
item.setTitle((String) map.get("title"));
item.setUrl((String) map.get("url"));
result.add(item);
}
return result;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public ArticleEntity queryById(String indexId){
GetRequest request = new GetRequest(ARTICLE_INDEX, indexId);
GetResponse response = null;
try {
response = client.get(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
if (response!=null&&response.isExists()){
Gson gson = new Gson();
return gson.fromJson(response.getSourceAsString(),ArticleEntity.class);
}
return null;
}
}
5.4 external interface
It is the same as developing web programs using spring boot.
I won't introduce the basics of Spring Boot. I recommend this practical tutorial:
https://github.com/javastacks/spring-boot-best-practice
package com.lbh.es.controller;
import com.lbh.es.entity.ArticleEntity;
import com.lbh.es.service.ArticleService;
import org.elasticsearch.action.index.IndexResponse;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.List;
/**
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@RestController
@RequestMapping("article")
public class ArticleController {
@Resource
private ArticleService articleService;
@GetMapping("/create")
public boolean create(){
return articleService.createIndexOfArticle();
}
@GetMapping("/delete")
public boolean delete() {
return articleService.deleteArticle();
}
@PostMapping("/add")
public IndexResponse add(@RequestBody ArticleEntity article){
return articleService.addArticle(article);
}
@GetMapping("/fransfer")
public String transfer(){
articleService.transferFromMysql();
return "successful";
}
@GetMapping("/query")
public List<ArticleEntity> query(String keyword){
return articleService.queryByKey(keyword);
}
}
5.5 page
The main reason why we use thymeleaf on this page is that I really don't know the front end. I only know the simple h5, so I just make a page that can be displayed.
Search page
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>YiyiDu</title>
<!--
input:focus Set the blue outer border when the input box is clicked
text-indent: 11px;and padding-left: 11px;Sets the distance between the starting position of the input character and the left border
-->
<style>
input:focus {
border: 2px solid rgb(62, 88, 206);
}
input {
text-indent: 11px;
padding-left: 11px;
font-size: 16px;
}
</style>
<!--input Initial state-->
<style class="input/css">
.input {
width: 33%;
height: 45px;
vertical-align: top;
box-sizing: border-box;
border: 2px solid rgb(207, 205, 205);
border-right: 2px solid rgb(62, 88, 206);
border-bottom-left-radius: 10px;
border-top-left-radius: 10px;
outline: none;
margin: 0;
display: inline-block;
background: url(/static/img/camera.jpg?watermark/2/text/5YWs5LyX5Y-377ya6IqL6YGT5rqQ56CB/font/5a6L5L2T/fontsize/400/fill/cmVk) no-repeat 0 0;
background-position: 565px 7px;
background-size: 28px;
padding-right: 49px;
padding-top: 10px;
padding-bottom: 10px;
line-height: 16px;
}
</style>
<!--button Initial state-->
<style class="button/css">
.button {
height: 45px;
width: 130px;
vertical-align: middle;
text-indent: -8px;
padding-left: -8px;
background-color: rgb(62, 88, 206);
color: white;
font-size: 18px;
outline: none;
border: none;
border-bottom-right-radius: 10px;
border-top-right-radius: 10px;
margin: 0;
padding: 0;
}
</style>
</head>
<body>
<!--contain table of div-->
<!--contain input and button of div-->
<div style="font-size: 0px;">
<div align="center" style="margin-top: 0px;">
<img src="../static/img/yyd.png" th:src = "@{/static/img/yyd.png}" alt="100 million degrees" width="280px" class="pic" />
</div>
<div align="center">
<!--action Realize jump-->
<form action="/home/query">
<input type="text" class="input" name="keyword" />
<input type="submit" class="button" value="Under 100 million degrees" />
</form>
</div>
</div>
</body>
</html>
Search results page
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<link rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/4.3.1/css/bootstrap.min.css">
<meta charset="UTF-8">
<title>xx-manager</title>
</head>
<body>
<header th:replace="search.html"></header>
<div class="container my-2">
<ul th:each="article : ${articles}">
<a th:href="${article.url}"><li th:text="${article.author}+${article.content}"></li></a>
</ul>
</div>
<footer th:replace="footer.html"></footer>
</body>
</html>
6 Summary
It took me two days to study the following es. In fact, this thing is very interesting. Now the most basic in the IR field is still based on statistics, so for search engines such as es, it has a good performance in the case of big data.
Every time I write the actual combat, I actually feel that I can't start, because I don't know what to do? So I also hope to get some interesting ideas, and the author will do the actual combat.
Recent hot article recommendations:
1.1000 + Java interview questions and answers (2021 latest version)
2.Hot! The Java collaboration is coming...
3.Play big! Log4j 2.x re explosion...
4.Spring Boot 2.6 was officially released, a wave of new features..
5.Java development manual (Songshan version) is the latest release. Download it quickly!
Feel good, don't forget to like + forward!