Video tutorial: [crazy God says Java] ElasticSearch7.6.x the latest complete tutorial is easy to understand
Video address: https://www.bilibili.com/video/BV17a4y1x7zq
Refuse white whoring and thank the crazy God for sharing the video tutorial
ElasticSearch overview
ElasticSearch, or es for short, is an open-source and highly extended distributed full-text search engine. It can store and retrieve data in near real time. It has good scalability and can be extended to hundreds of servers to process PB level data. Es also uses Java to develop and use Lucene as its core to realize all indexing and search functions, but its purpose is to hide the complexity of Lucene through a simple RestFul API, so as to make full-text search easier.
According to the statistics of DB Engines, an internationally authoritative database product evaluation organization, ElasticSearch surpassed Solr and became the first search engine application in January 2016.
Who is using:
-
Wikipedia
-
The Guardian (foreign news website)
-
Stack Overflow (foreign program exception discussion forum)
-
GitHub (open source code management)
-
E-commerce website
-
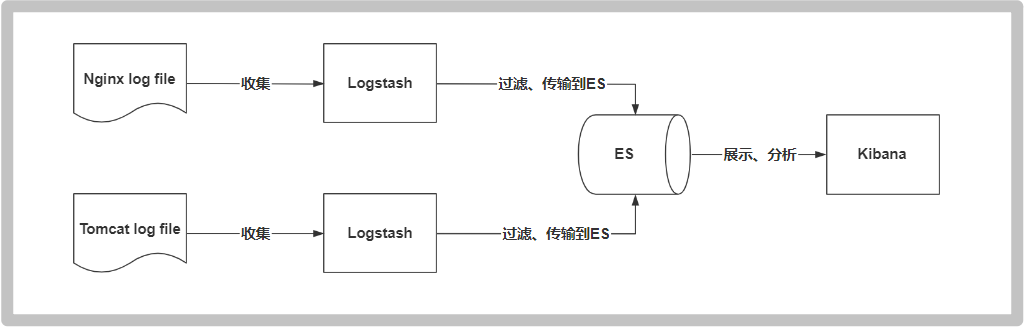
Log data analysis, logstash collection log, es complex data analysis, ELK Technology (elasticsearch + logstash + kibana)
... ...
ES and solr
Introduction to ElasticSearch
Elasticsearch is a real-time distributed search and analysis engine. It makes it possible for you to process big data at an unprecedented speed.
It is used for full-text search, structured search, analysis, and a mixture of the three:
Wikipedia uses elastic search to provide full-text search and highlight keywords, as well as search as you type and did you mean
Suggested function.
The guardian uses Elasticsearch combined with user logs and social network data to provide real-time feedback to their editors, so as to timely understand the public's response to the newly published articles
Yes.
Stack overflow combines full-text search, geographic location query, and more like this function to find relevant questions and answers.
Github uses elastic search to retrieve 130 billion lines of code.
But elasticsearch is not only used for large enterprises, it also allows startups such as DataDog and Klout to turn their initial ideas into scalable solutions. Elasticsearch can run on your laptop or process petabytes of data on hundreds of servers. Elasticsearch is based on Apache Lucene ™ Open source search engine. Whether in open source or proprietary domain, Lucene can be regarded as the most advanced, best performing and most powerful search engine library so far.
However, Lucene is just a library. To use it, you must use Java as the development language and integrate it directly into your application. Worse, Lucene is very complex. You need to deeply understand the relevant knowledge of retrieval to understand how it works.
Elasticsearch is also developed in Java and uses Lucene as its core to realize all indexing and search functions, but its purpose is to use a simple RESTful API
Hide the complexity of Lucene to make full-text search simple.
Solr introduction
Solr is a top-level open source project under Apache ', which is developed in Java. It is a full-text search server based on Lucene. Solr provides richer queries than Lucene
At the same time, it realizes configurable and extensible, and optimizes the index and search performance.
Solr can run independently in Servlet containers such as Jetty and Tomcat. The implementation method of Solr index is very simple. Use POST method to send a message to Solr server
An XM [document describing the Field and its contents. Solr adds, deletes and updates the index according to the xml document. Solr search only needs to send an HTTP GET request, and then
Return query results in Xm|, json and other formats for analysis and organize page layout. Solr does not provide the function of building UI. Solr provides - management interfaces through which you can
To query the configuration and operation of Solr.
solr is an enterprise search server based on lucene, which actually encapsulates lucene.
Solr is an independent enterprise search application server, which provides an API interface similar to web service. Users can request from the search engine server through http
Submit formatted files and generate indexes; You can also make a search request and get the returned results.
Lucene introduction
Lucene is a sub project of 4 jakarta project team of apache Software Foundation. It is an open source full-text retrieval engine toolkit, but it is not - a complete full-text
Search engine, but the architecture of a full-text search engine, provides a complete query engine, index engine and some text analysis engines (English and German).
The purpose of Lucene is to provide software developers with a simple and easy-to-use toolkit to facilitate the realization of full-text retrieval function in the target system, or to build on it
A complete full-text search engine. Lucene is an open source library for full-text retrieval and search, supported and provided by the Apache Software Foundation. Lucene provides a
Simple but powerful application program interface, capable of full-text indexing and searching. Lucene is a mature free and open source tool in the Java development environment. In itself,
Lucene is the most popular free Java information retrieval library at present and in recent years. People often mention the information retrieval program library, although it is related to the search engine, it should not
Confuse information retrieval library with search engine.
Lucene is the architecture of a full-text retrieval engine. What is a full-text search engine?
Full text search engine is a real search engine. Representative foreign search engines include Google, FastlAllTheWeb, AltaVista, Inktomi, Teoma, WiseNut, etc
Baidu is famous in China. They are retrieved and used in the database established by extracting the information of each website (mainly web page text) from the Internet
Users query the relevant records matching the criteria, and then return the results to users in a certain order, so they are the real search engine.
From the perspective of the source of search results, full-text search engines can be divided into two types, - one is to have its own retrieval program (Indexer), commonly known as "Spider" program
Robot program, and self built web database, search results directly from its own database, such as the above mentioned 7 engines; The other is to rent it
He runs a database and arranges search results in a custom format, such as the Lycos engine.
ElasticSearch and Solr comparison
-
Solr is faster when simply searching existing data
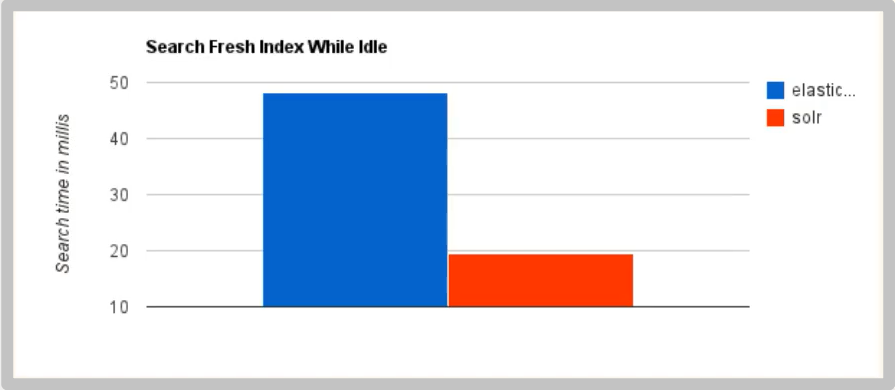
-
When indexing in real time, Solr will cause I/O blocking and poor query performance. ElasticSearch has obvious advantages
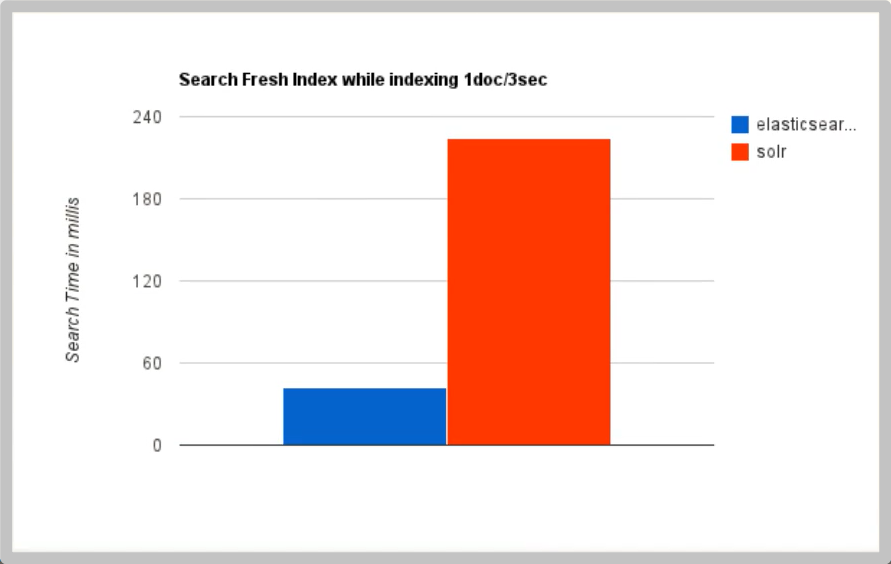
-
As the amount of data increases, the search efficiency of Solr will become lower, while ElasticSearch has no significant change
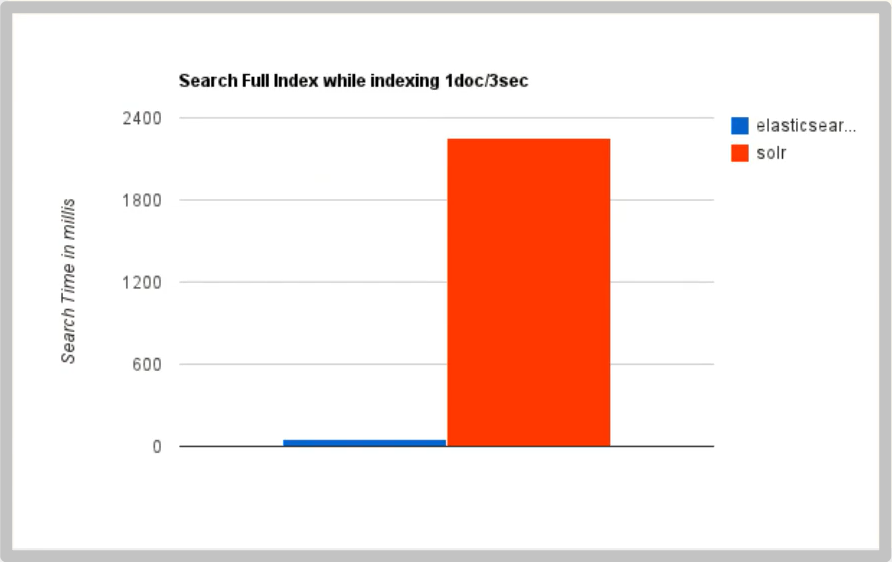
-
By moving the search infrastructure from Solr to ElasticSearch, it will increase by nearly 50% × Search performance of
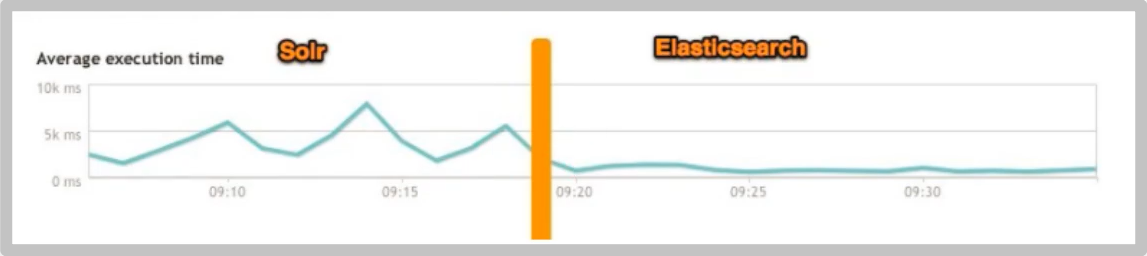
ElasticSearch vs Solr summary
- es is basically out of the box (you can use it after decompression!), It's simple. Solr installation is slightly more complex
- Solr uses Zookeeper for distributed management, while Elasticsearch itself has distributed coordination management function.
- Solr supports data in more formats, such as JSON, XML and CSV, while Elasticsearch only supports JSON file format.
- Solr officially provides more functions, while Elasticsearch itself pays more attention to core functions. Advanced functions are mostly provided by third-party plug-ins. For example, the graphical interface needs kibana friendly support.
- Solr query is fast, but it is slow to update the index (i.e. slow to insert and delete), which is used for applications with many queries such as e-commerce;
- ES has fast indexing (i.e. slow query), i.e. fast real-time query, which is used for facebook, Sina and other searches.
- Solr is a powerful solution for traditional search applications, but Elasticsearch is more suitable for emerging real-time search applications.
- Solr is relatively mature. It has a larger and more mature community of users, developers and contributors. Compared with developers and maintainers, Elasticsearch updates too quickly and learns to use it
High cost.
ElasticSearch installation
-
Environmental requirements: JDK above 1.8, Nodejs
-
Download: Official Website https://www.elastic.co/
-
Windows installation package: elasticsearch-7.15 2-windows-x86_ 64.zip, extract and use
-
Directory structure:
+ bin Startup file + config configuration file + log4j2.properties Log profile + jvm.options Virtual machine configuration file. It is recommended to reduce the memory, + elasticsearch.yml elasticsearch Configuration file, default port 9200, cross domain problem + lib relevant jar package + logs journal + modules modular + plugins plug-in unit
-
Start, double-click / elasticsearch-7.15 2/bin/elasticsearch. bat
Visit 127.0 0.1:9200, get the page
{ "name" : "CRATER-PC", "cluster_name" : "elasticsearch", // Cluster name. A service is also a cluster "cluster_uuid" : "8AWbPdNgRymiY6VXtuiAuA", "version" : { "number" : "7.15.2", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "93d5a7f6192e8a1a12e154a2b81bf6fa7309da0c", "build_date" : "2021-11-04T14:04:42.515624022Z", "build_snapshot" : false, "lucene_version" : "8.9.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
Elasticsearch head installation
-
Download address: https://github.com/mobz/elasticsearch-head
-
After decompression, it is a front-end web package project
-
cd elasticsearch-head
-
npm install
-
npm run start
-
open http://localhost:9100/
After entering the page, there is a cross domain problem (cross ip, cross port), because the 9200 port is connected to the 9100 port. Solve the following problems:
-
Stop ElasticSearch and modify ElasticSearch YML, add the following.
http.cors.enabled: true http.cors.allow-origin: "*"
Restart ElasticSearch again and the head connector succeeds.
You can create a new index at will. At present, it can be understood as a database
As for compliance query, head is a data display tool. It is not recommended to write commands here. Check in Kibana later
Kibana installation
Learn about ELK
ELK is the acronym of Elasticsearch, Logstash and Kibana. It is also called Elastic Stack on the market.
Elasticsearch is a near real-time search platform framework based on Lucene, distributed and interactive through Restful mode. For big data full-text search engine scenarios like Baidu and Google, elasticsearch can be used as the underlying support framework. It can be seen that the search capability provided by elasticsearch is indeed powerful. In the market, we often refer to elasticsearch as es for short.
Logstash is the central data flow engine of ELK. It is used to collect data in different formats from different targets (file / data store / MQ) and support output to different purposes after filtering
Location (file / MQ/redis/elasticsearch/kafka, etc.).
Kibana can display elasticsearch data through friendly pages and provide real-time analysis.
Many developers in the market can - say that ELK is the general name of a log analysis architecture technology stack, but in fact, ELK is not only suitable for log analysis, but also supports log analysis
In any other scenario of data analysis and collection, log analysis and collection are only more representative. Is not unique.
Install Kibana
Kibana is an open source analysis and visualization platform for Elasticsearch, which is used to search and view the data interactively stored in Elasticsearch index. With kibana, advanced data analysis and display can be carried out through various charts. Kibana makes massive data easier to understand. It is easy to operate, and the browser based user interface can quickly create a dashboard to display the Elasticsearch query dynamics in real time. Setting up kibana is very simple. Without coding or additional infrastructure, kibana installation can be completed and Elasticsearch index monitoring can be started in a few minutes.
Official website: https://www.elastic.co/cn/kibana
-
Download Kibana-7.15 2-windows-x86_ 64.zip. Note: Kibana version must be consistent with ES version.
-
Decompression is a standard project
-
Start: double click / bin / kibana bat
-
Visit localhost:5601
-
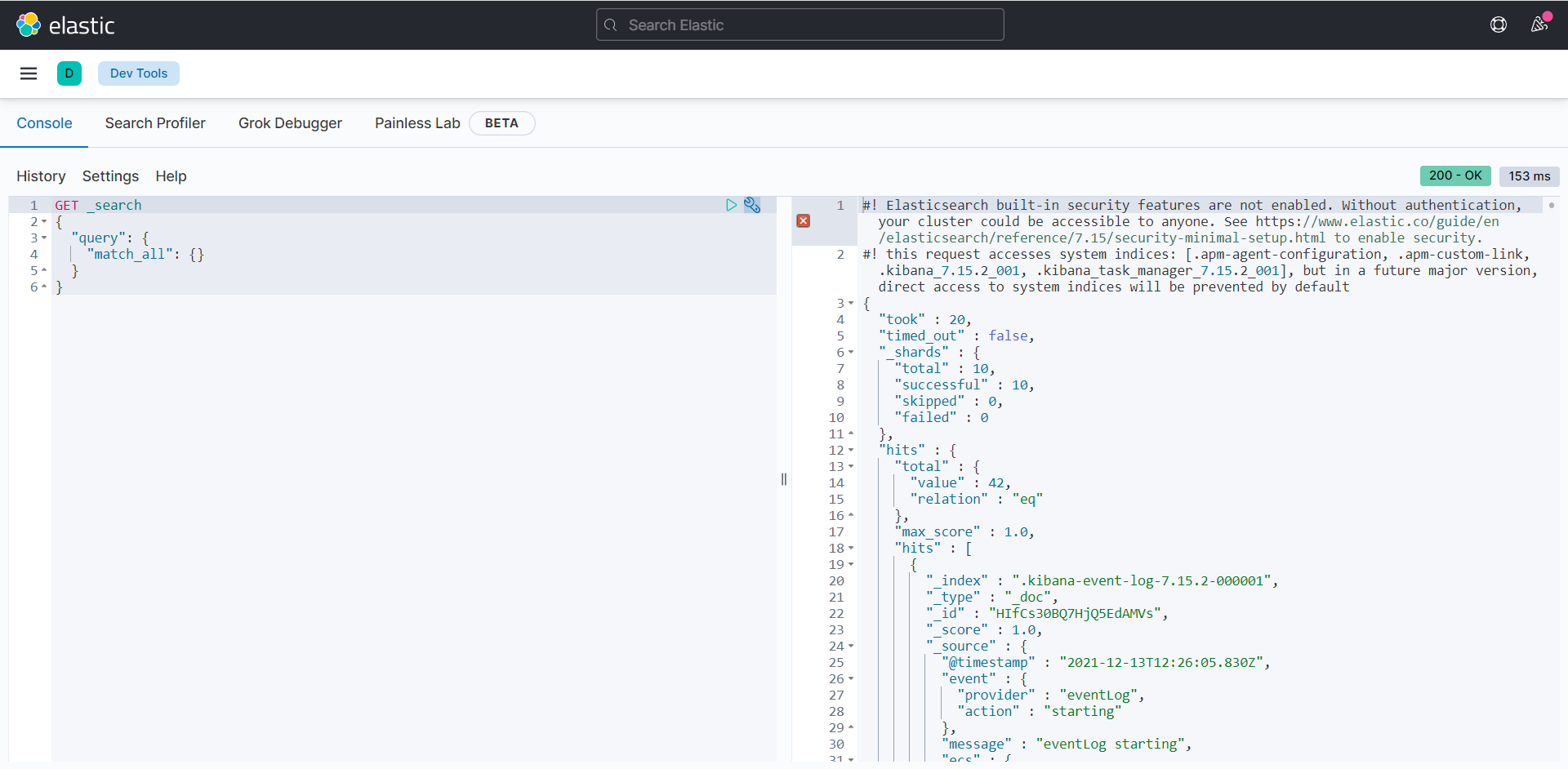
Find Dev Tools in the left menu bar and use development tools on Kibana
-
For localization (internationalization), there is a zh-CN.json file under / x-pack/plugins/translations/translations for translation.
Edit config / kibana YML file, with the following modifications:
#i18n.locale: "en" i18n.locale: "zh-CN"
Restart Kibana and the language becomes Chinese
ElasticSearch core concepts
ElasticSearch is document oriented. Comparison between relational database and ElasticSearch
| Relational DB | ElasticSearch |
|---|---|
| database | Indexes |
| tables | type |
| rows | documents |
| Fields (columns) | fields |
ElasticSearch (cluster) can contain multiple indexes (databases), each index can contain multiple types (tables), each type contains multiple documents (rows), and each document contains multiple fields (columns).
Physical design:
ElasticSearch divides each index into multiple slices in the background, and each slice can be migrated between different servers in the cluster
Logic design:
An index type contains multiple documents, such as document 1 and document 2. When indexing a document, we can find it in this order: index = > type = > document ID. through this combination, we can index a specific document. Note: D doesn't have to be an integer, it's actually a string.
file
Previously, elasticsearch is document oriented, which means that the smallest unit of index and search data is the document. In elasticsearch, the document has several important attributes:
- Self contained. A document contains both fields and corresponding values, that is, key: value
- It can be hierarchical. A document contains itself. That's how complex logical entities come from. It is a json object, and fastjson performs automatic conversion.
- Flexible structure. Documents do not rely on predefined patterns. We know that in relational databases, fields must be defined in advance before they can be used. In elastic search, fields are very flexible. Sometimes, we can ignore the field or add a new field dynamically.
- Although we can add or ignore a field at will, the type of each field is very important, such as an age field type, which can be string or integer. Because elasticsearch will save the mapping between fields and types and other settings. This mapping is specific to each type of each mapping, which is why types are sometimes referred to as mapping types in elastic search.
type
Types are logical containers for documents. Just like relational databases, tables are containers for rows. The definition of a field in a type is called mapping. For example, name is mapped to a string type.
We say that documents are modeless. They do not need to have all the fields defined in the mapping, such as adding a new field. What does elasticsearch do? Elasticsearch will automatically add a new field to the map, but if the field is not sure what type it is, elasticsearch will start to guess. If the value is 18, then
Elasticsearch will think it's plastic surgery. However, elasticsearch may also be wrong, so the safest way is to define the required mapping in advance. This is the same as that of relational databases. First define the fields and then use them. Don't fix any moths.
Indexes
It's the database.
The index is a container of mapping type, and the index in ElasticSearch is a very large collection of documents. The index stores the fields and other settings of the mapping type, which are then stored on each slice.
Physical design: how nodes and shards work
A cluster has at least one node, and a node is an ElasticSearch process. A node can have multiple default indexes. If you create an index, the index will be composed of five primary shards, and each primary shard will have a replica shard
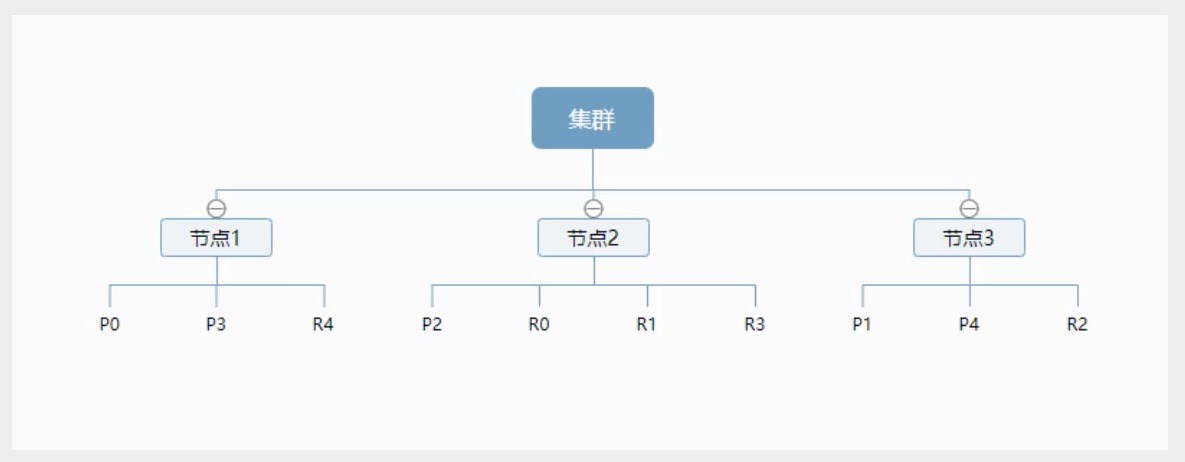
The above figure shows a cluster with three nodes. It can be seen that the primary partition and the corresponding replication partition will not be in the same node, which is conducive to a node hanging and data loss. In fact, a fragment is a Lucene index, a file directory containing inverted index, which enables ElasticSearch to obtain those documents containing specific keywords without scanning all documents.
Inverted index
ElasticSearch uses a structure called inverted index, which uses Lucene inverted index as the bottom layer. This structure is suitable for fast full-text search. An index consists of all non duplicate lists in the document. For each word, there is a document list containing it.
-
For example, there are now two documents, each containing the following:
Study every day, good good up to forever # Contents of document 1 To forever, study every day, good good up # Contents of document 2
-
In order to create an inverted index, first split each document into independent words (or terms and tokens), then create a sorted list containing all non duplicate terms, and then list which document each term appears in:
term doc_1 doc_2 Study √ × To × √ every √ √ forever √ √ day √ √ study × √ good √ √ to √ × up √ √ -
Now, try to retrieve to forever, just look at the document for each term
term doc_1 doc_2 to √ × forever √ √ -
Both documents match, but the matching degree (weight / score) of the first document is higher than that of the second document. If there are no other conditions, both documents containing keywords will be returned.
-
Let's take another example. For example, if we search blog posts through blog tags, the inverted index list is such a structure:
Blog posts (raw data) Index list (inverted index) Blog post ID label label Blog post ID 1 python python 1,2,3 2 python linux 3,4 3 linux,python 4 linux If you want to search for articles with python tags, it will be much faster to find the inverted indexed data than to find all the original data. Just look at the label
Column, and then get the relevant article ID.
Comparison between Elasticsearch index and Lucene index:
In elastic search, the term index is frequently used, which is the use of the term. In elastic search, the index is divided into multiple slices, and each slice is an index of Lucene. Therefore, an elastic search index is composed of multiple Lucene indexes. Unless otherwise specified, when it comes to cable bow, it refers to the index of elastic search.
All the next operations are completed in the Console under Dev Tools in kibana.
IK word breaker plug-in
Word segmentation: that is, a character is divided into keywords. When searching, the character information will be segmented, and the data in the database or index library will be segmented, and then a matching operation will be performed. The default Chinese word segmentation is to treat each word as a word, such as "my name is meteorite crater" will be divided into "I" "Call", "meteorite", "stone" and "pit" obviously do not meet the requirements, so we need to install Chinese word splitter IK to solve this problem.
IK provides two word segmentation algorithms: ik_smart and ik_max_word, where ik_smart is the least segmentation, ik_max_word is the most fine-grained partition.
Install IK word breaker
-
Download: https://github.com/medcl/elasticsearch-analysis-ik/releases
Note: the version needs to be corresponding
elasticsearch-analysis-ik-7.15.2.zip
-
Enter elasticsearch-7.15 2 / plugins directory, create a new ik directory and unzip it
-
Restart ElasticSearch and observe that the plug-in has been loaded

You can also view the plug-in using the elasticsearch plugin command

-
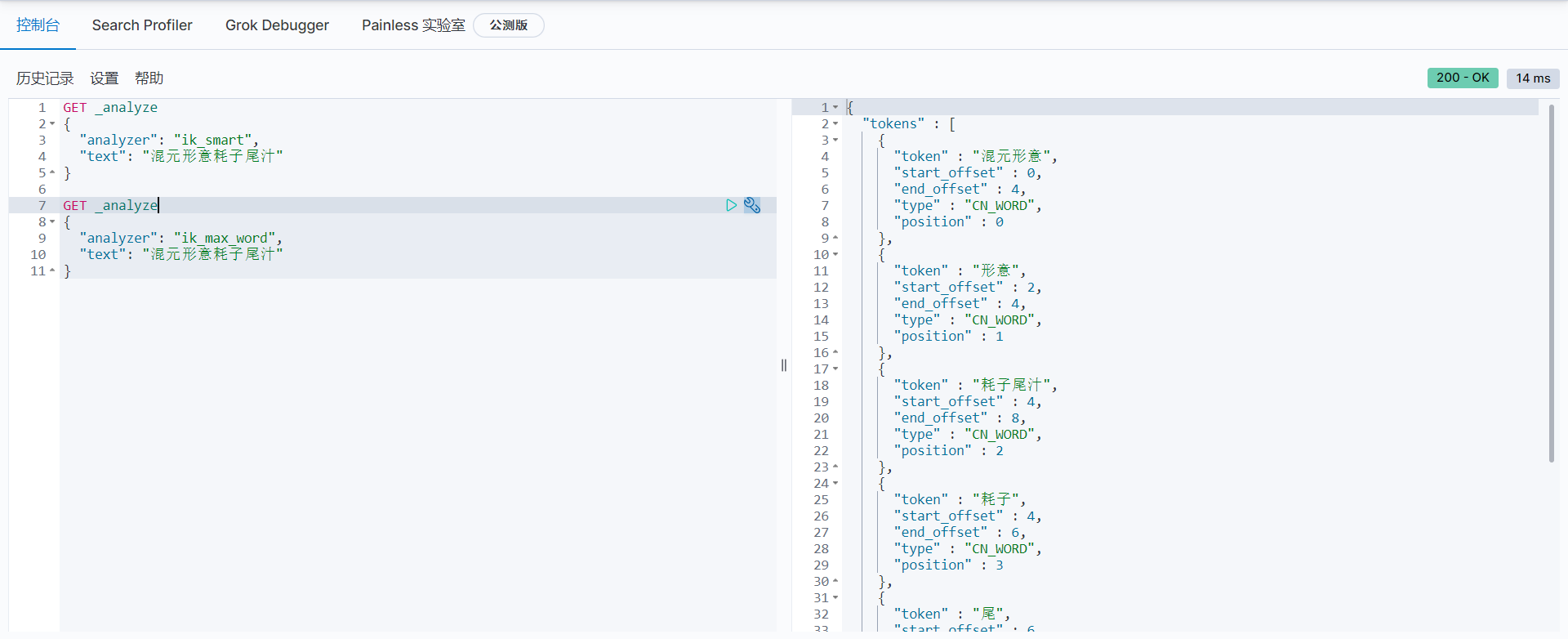
Using Kibana test
ik_smart minimum segmentation:
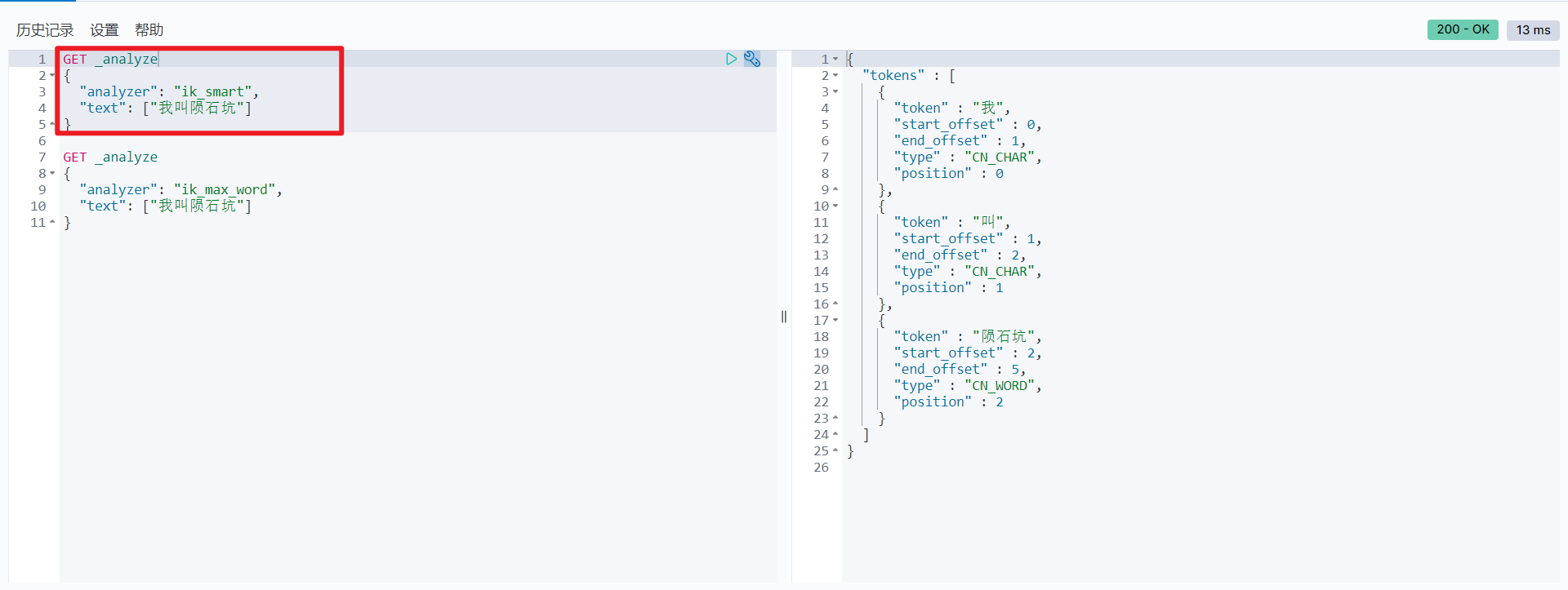
ik_max_word is divided in the most fine-grained way, exhausting all possibilities of Thesaurus:
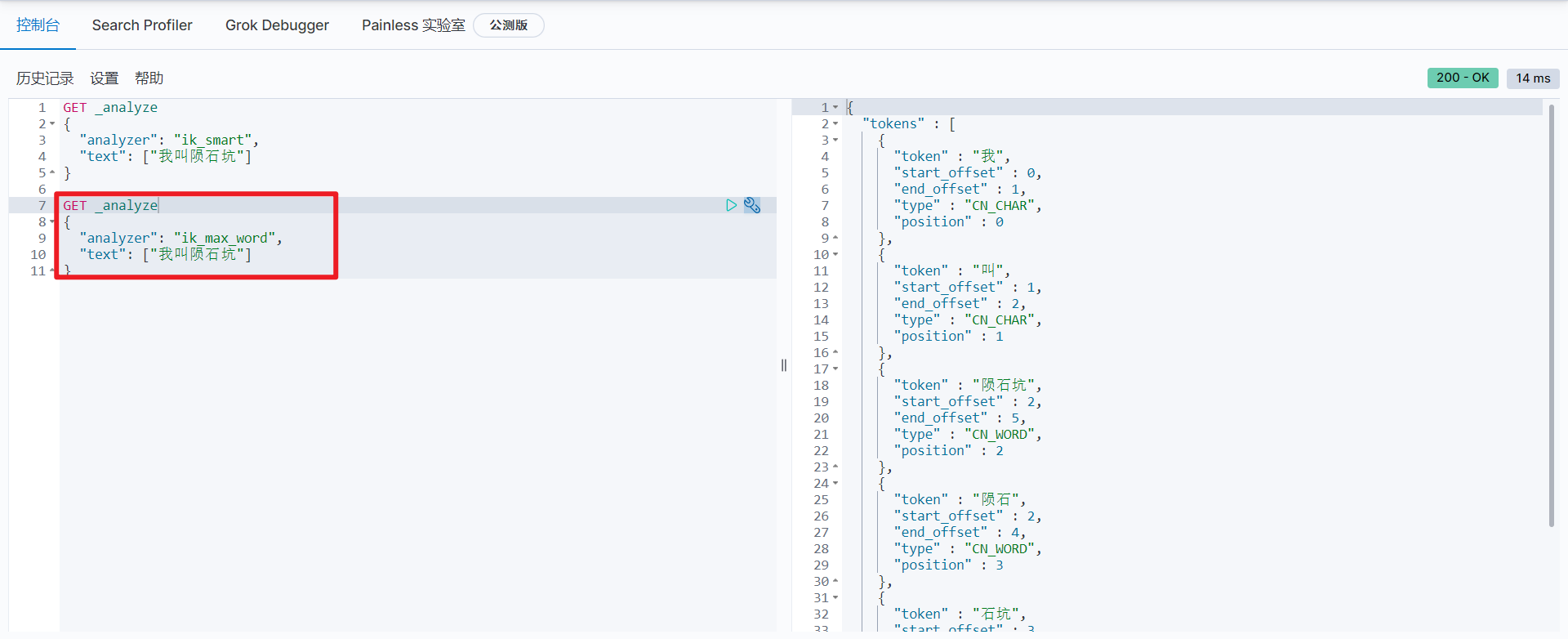
-
In the test, it is found that the following test cases can not remove the desired "mixed yuan shape and meaning" and "mouse tail juice" using any word segmentation algorithm. For this kind of word, it needs to be added to the user-defined dictionary.
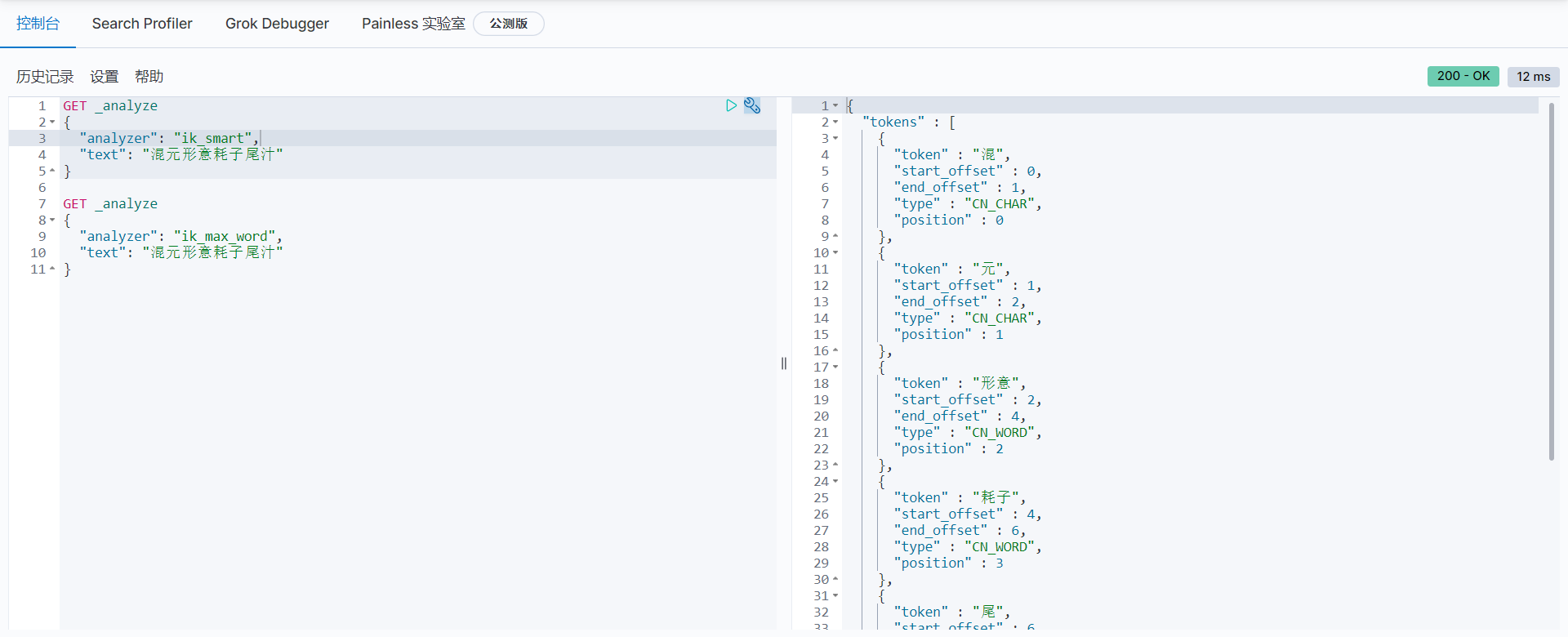
-
Customize the dictionary, and create a new dictionary file in the config directory of ik word breaker plug-in DIC, as follows
Mixed form and meaning Mouse tail juice
Modify ikanalyzer. In the same directory cfg. XML file to configure a custom dictionary on the
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer Extended configuration</comment> <!--Users can configure their own extended dictionary here --> <entry key="ext_dict">crater.dic</entry> <!--Users can configure their own extended stop word dictionary here--> <entry key="ext_stopwords"></entry> <!--Users can configure the remote extension dictionary here --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--Users can configure the remote extended stop word dictionary here--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
After restart, observe the log and load the custom dictionary

-
Test again, the custom words are split out
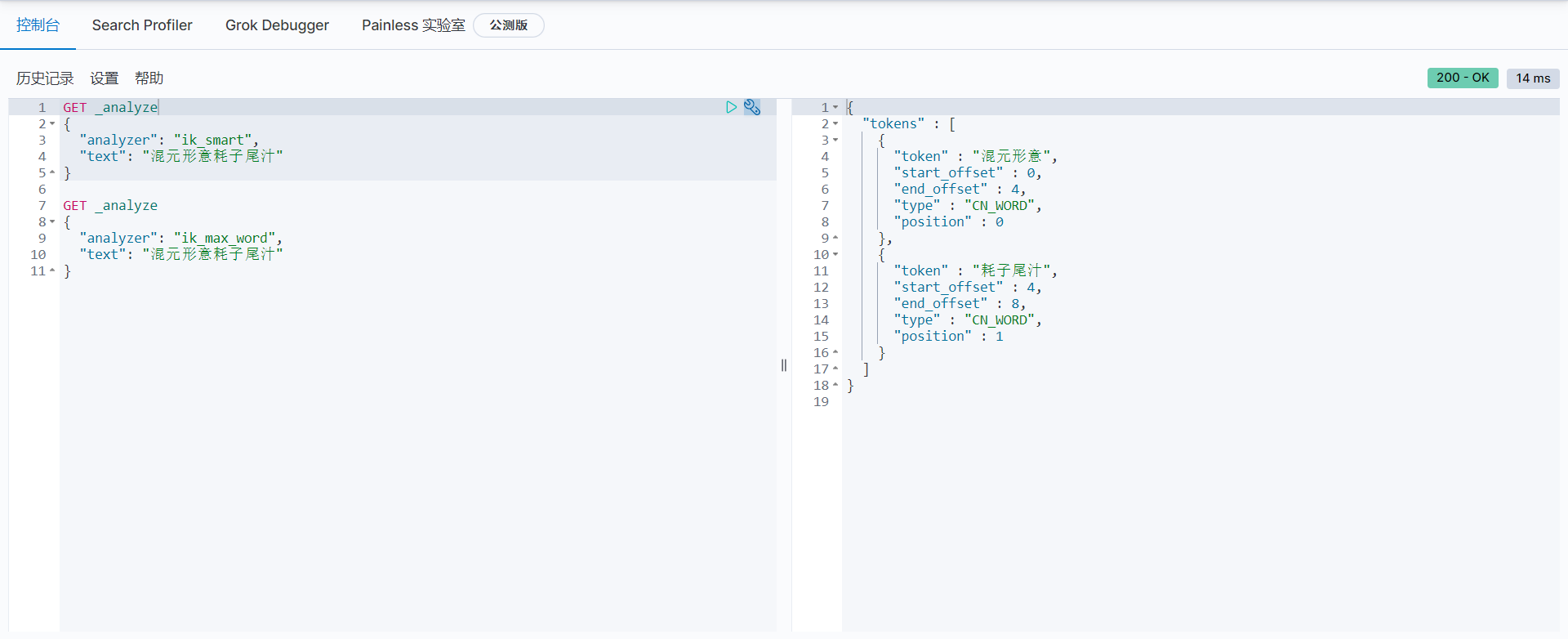
Rest style description
A software architecture style, not a standard, only provides a set of design principles and constraints. It is mainly used for interactive software between client and server. The software designed based on this style can be more concise, more hierarchical, and easier to implement caching and other mechanisms.
Basic command description
| method | url address | describe |
|---|---|---|
| PUT | 127.0. 0.1:9200 / index name / type name / document ID | Create document (specify document ID) |
| POST | 127.0. 0.1:9200 / index name / type name | Create document (random document ID) |
| POST | 127.0. 0.1:9200 / index name / type name / document ID/_update | Modify document |
| DELETE | 127.0. 0.1:9200 / index name / type name / document ID | remove document |
| GET | 127.0. 0.1:9200 / index name / type name / document ID | Query documents by document ID |
| POST | 127.0. 0.1:9200 / index name / type name/_ search | Query all data |
Basic operation of index
New index
-
Create an index
# The later version of the type name is removed PUT /Index name/Type name/file ID {Request body} # Return values include "_index": Current index name "_type" Current type "_version" Current version (1 means it has not been modified)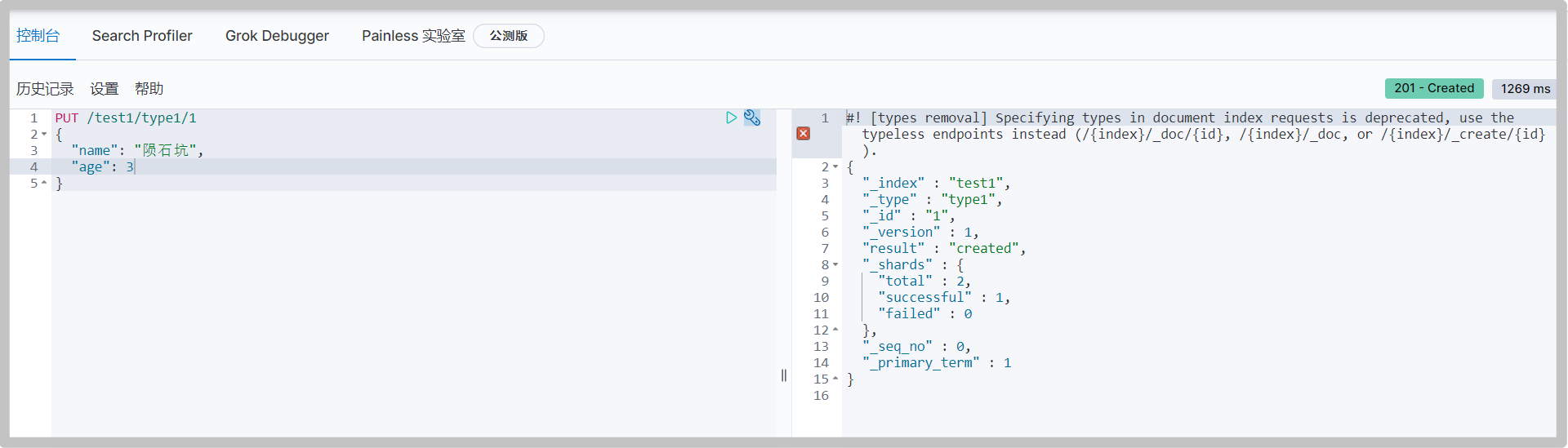
You can also see the new index on the overview and index page in elastic search head
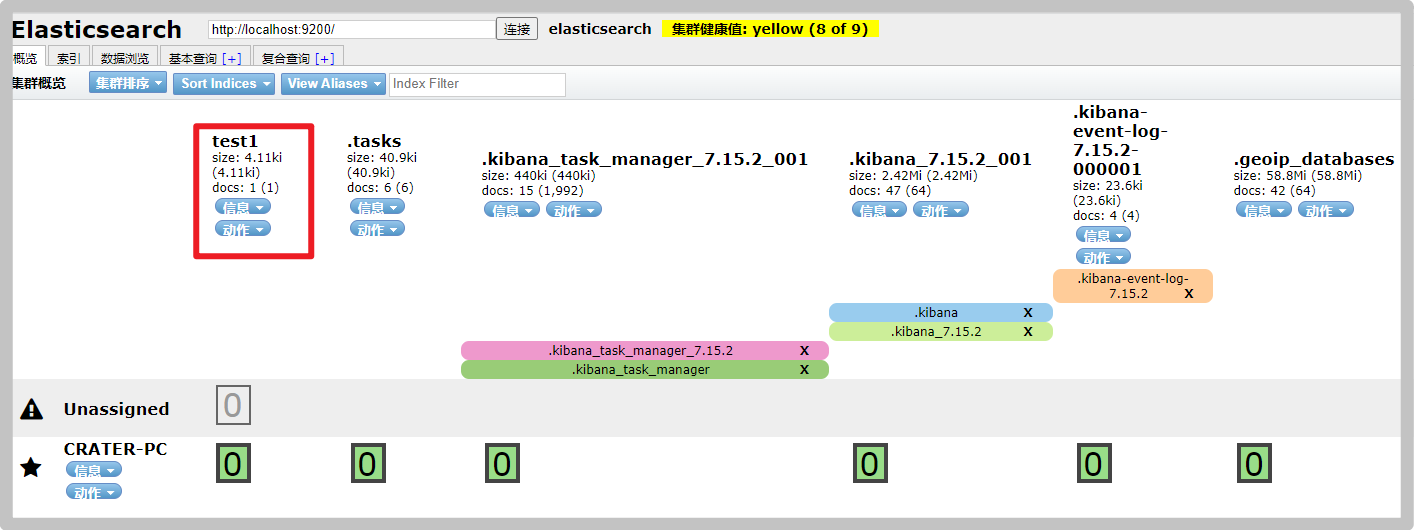
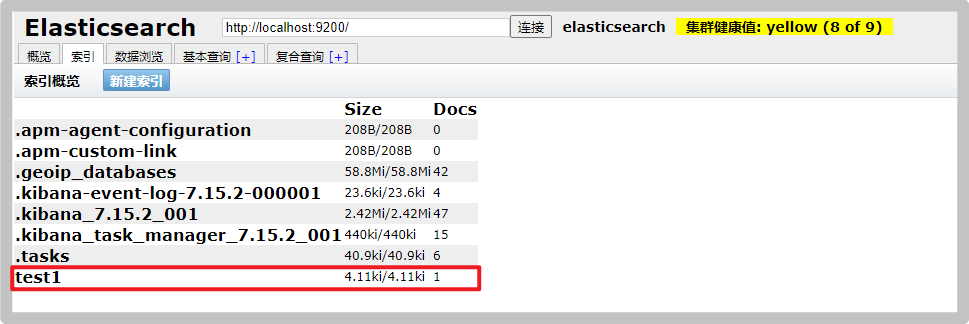
You can see the details of the data on the data index page, and the automatic index addition is completed. This is also the reason why you can learn ES as a database in the early stage.
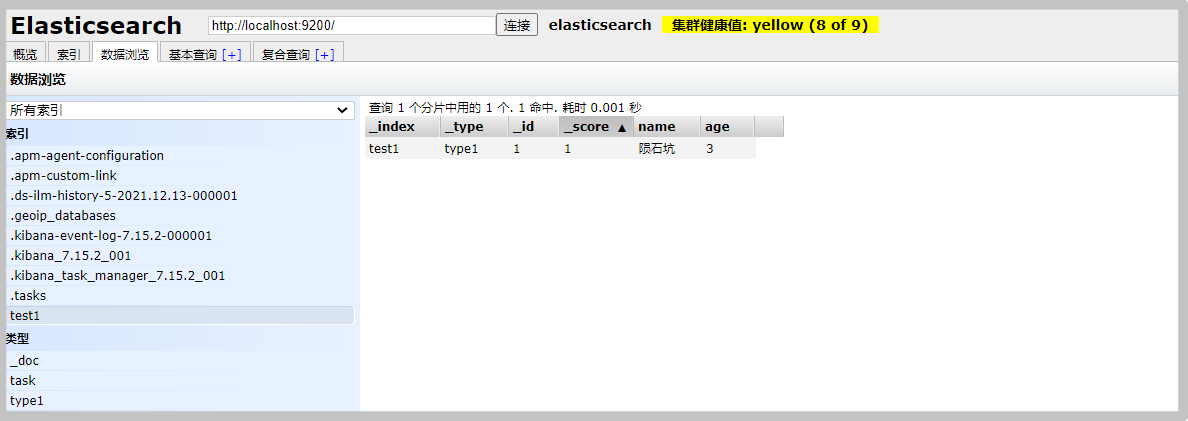
-
Data type of field
-
String type
text,keyword
-
Numerical type
long,Integer,short,byte,double,float,half float,scaled float
-
Date type
date
-
te boolean type
boolean
-
Binary type
binary
-
Wait
-
-
Specifies the type of field
Similar to building a database (establishing indexes and corresponding types of fields), it can also be regarded as the establishment of rules
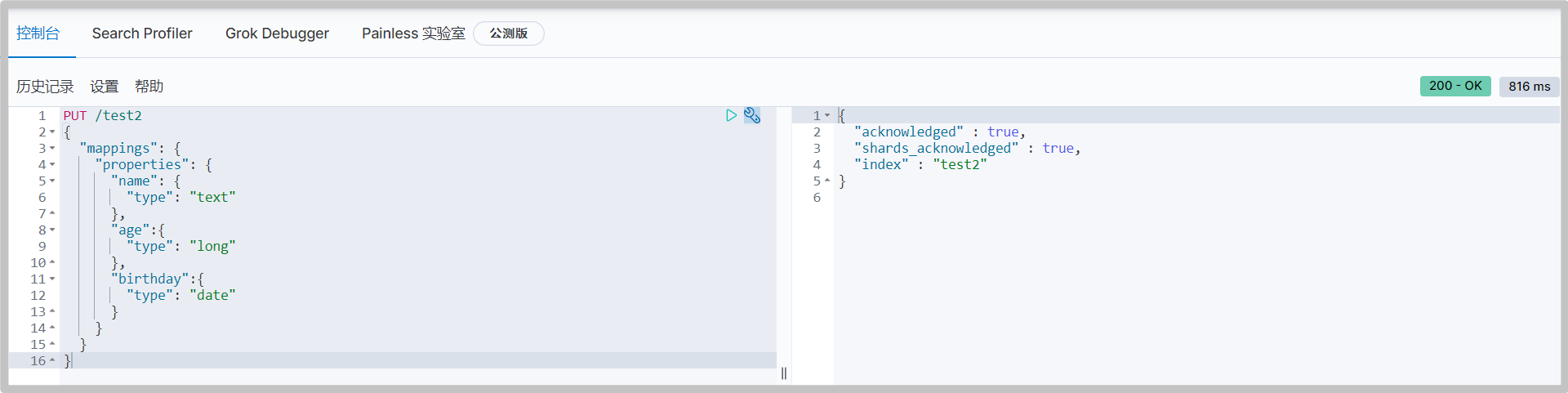
-
Get test2 index information
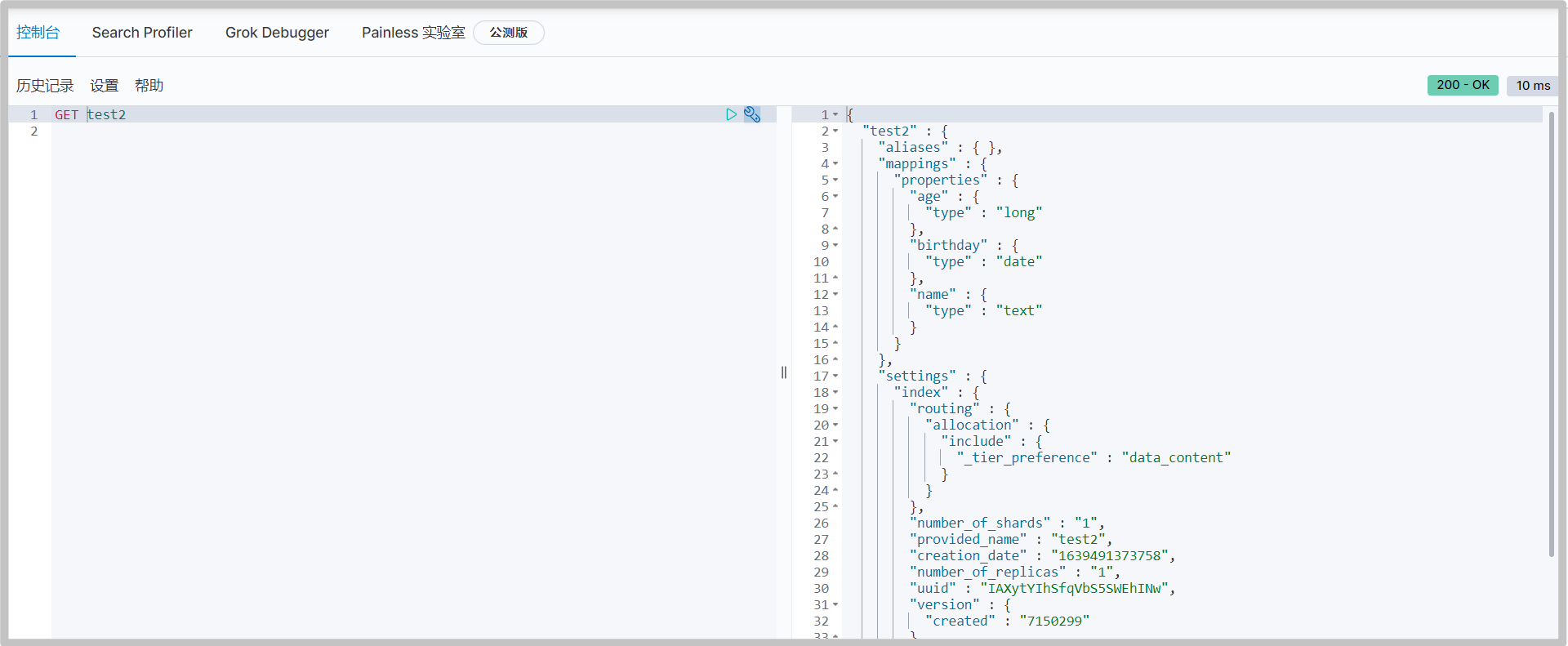
-
Default data type
_ doc default type. Type will be gradually discarded in future versions. It can be unspecified or explicitly specified
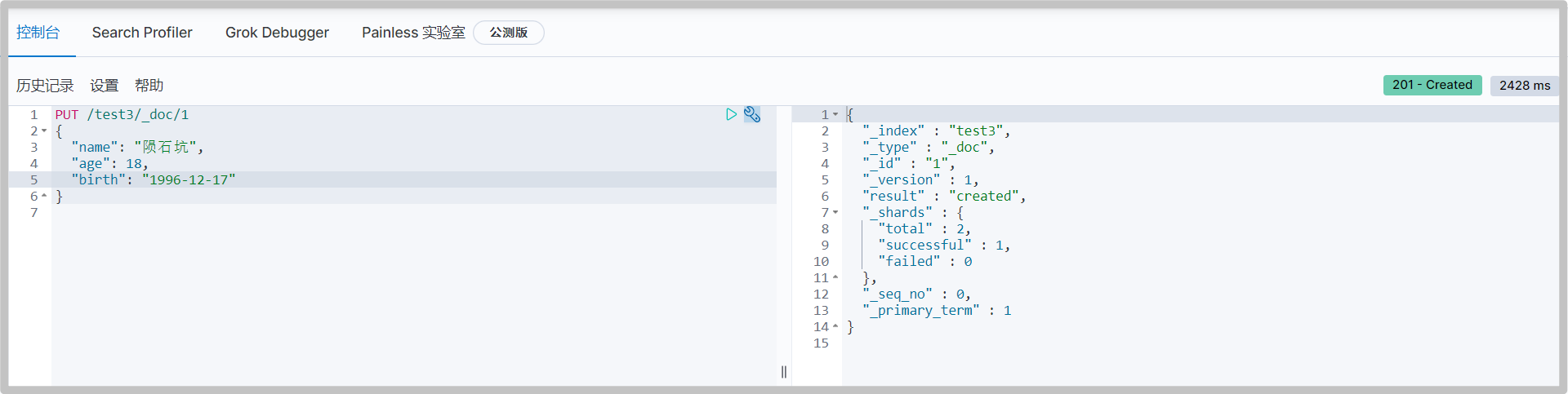
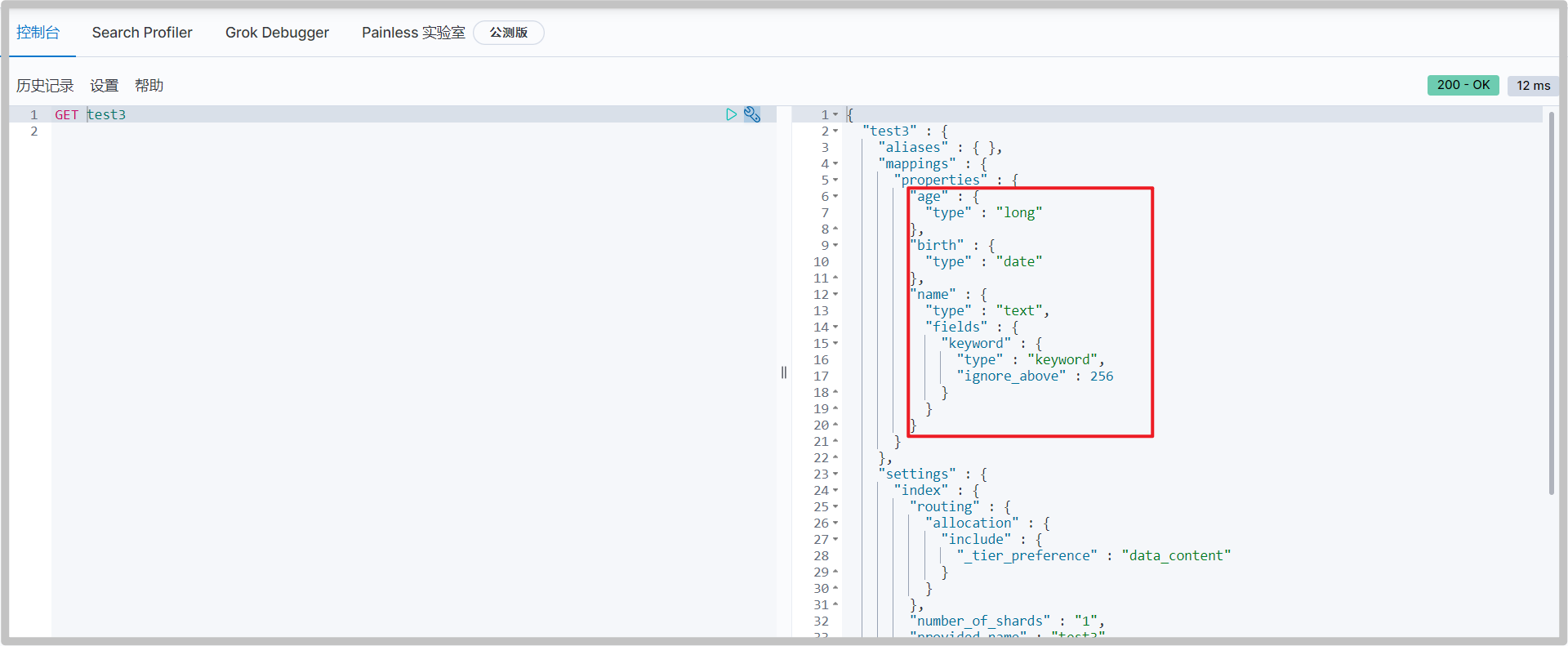
If the document field does not specify a type, ElasticSearch will configure the field type by default.
Extension: through get_ Cat command to view ElasticSearch information
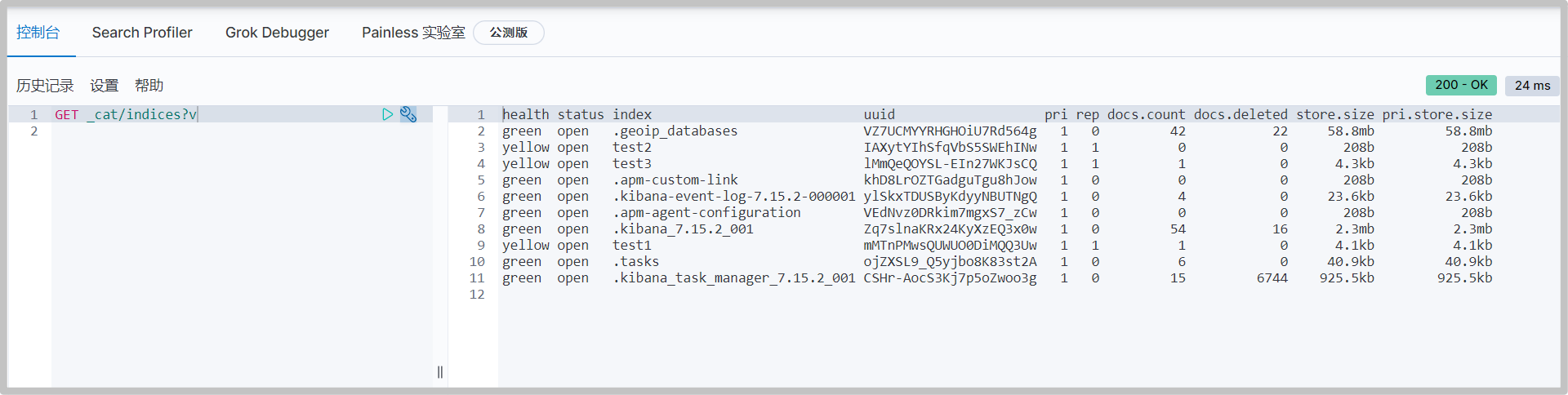
Other commands:
GET _cat/indices GET _cat/aliases GET _cat/allocation GET _cat/count GET _cat/fielddata GET _cat/health GET _cat/indices GET _cat/master GET _cat/nodeattrs GET _cat/nodes GET _cat/pending_tasks GET _cat/plugins GET _cat/recovery GET _cat/repositories GET _cat/segments GET _cat/shards GET _cat/snapshots GET _cat/tasks GET _cat/templates GET _cat/thread_pool
Modify index
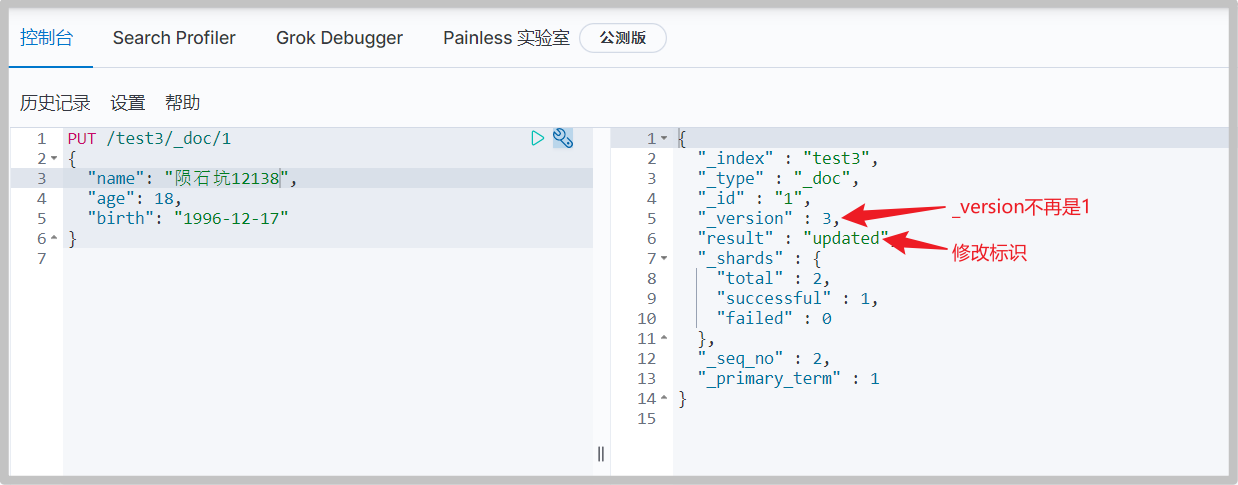
There are two implementation schemes for modification
-
Scheme 1: PUT, change the data to be modified in the request body and add it again, so as to overwrite the old data and realize the modification.
The disadvantage of this scheme is that once the request body misses the field, it will cause data loss.
-
Scheme 2: POST
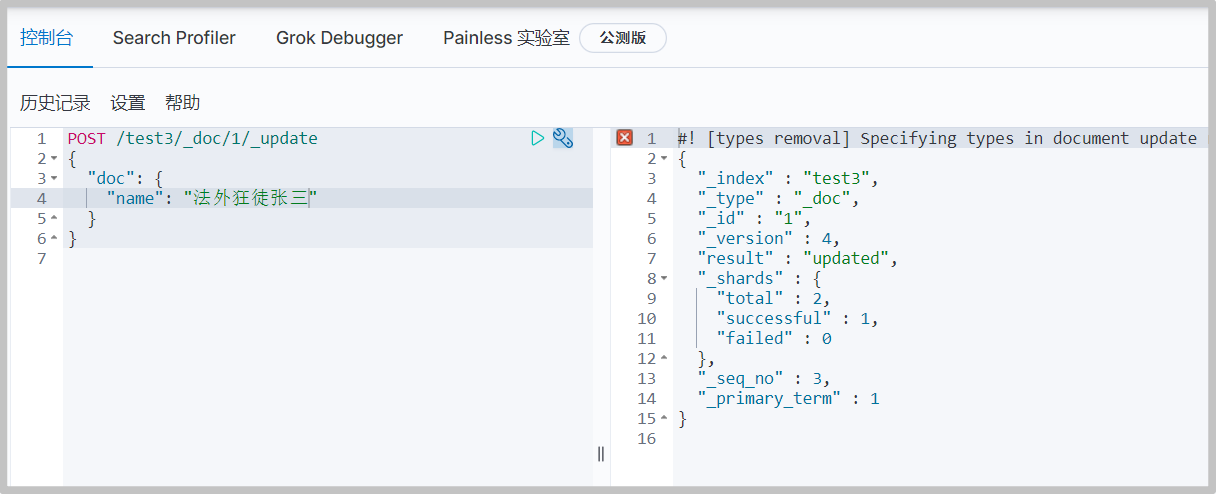
Delete index
-
command
# Delete index DELETE /test1
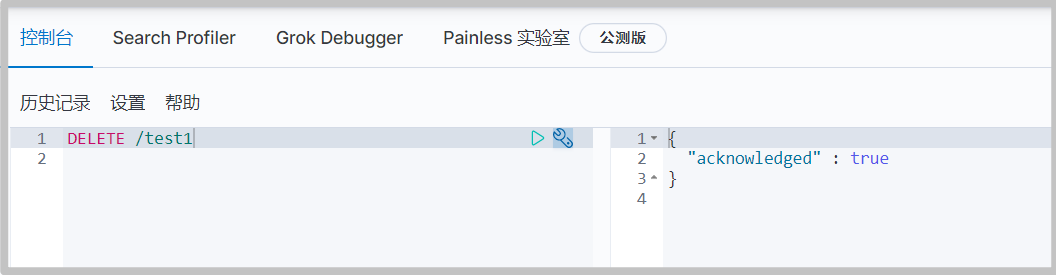
# remove document DELETE /test3/_doc/1
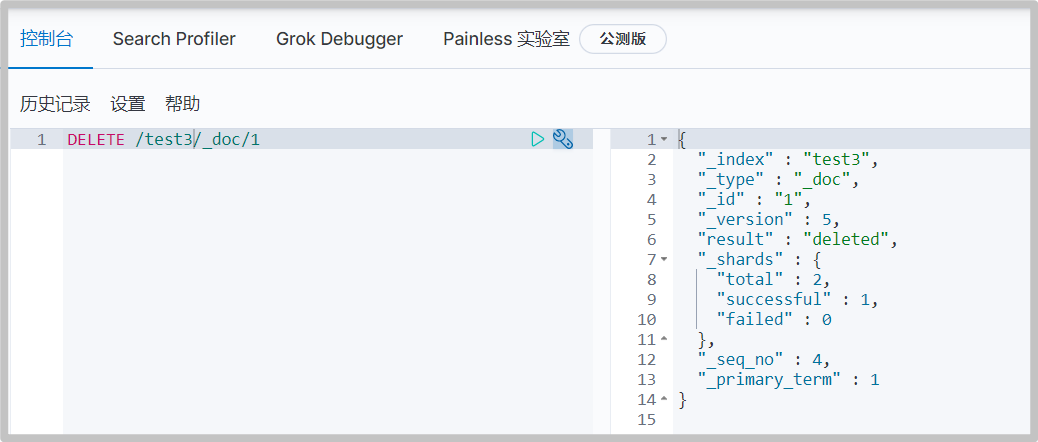
Basic operation of document
Simple query
-
First, add some data
PUT /crater/user/1 { "name": "Crater", "age": 24, "desc": "A meal is as fierce as a tiger. At a glance, the salary is two thousand five", "tags": ["technical nerd","Treasure boy","Straight man"] } PUT /crater/user/2 { "name": "Zhang San", "age": 35, "desc": "Outlaw maniac", "tags": ["Miss Luo","criminal law"] } PUT /crater/user/3 { "name": "Li Si", "age": 30, "desc": "Indescribable", "tags": ["lady","dance"] }
-
Query data
# command GET /crater/user/1

Modify document
-
Update data
Mode 1:
# command PUT /crater/user/3 { "name": "Li si123", "age": 30, "desc": "Indescribable", "tags": ["lady","dance"] }
Mode 2: Recommended
# command POST /crater/user/3/_update { "doc": { "name": "Li Si 456" } }
Simple condition query
-
GET query
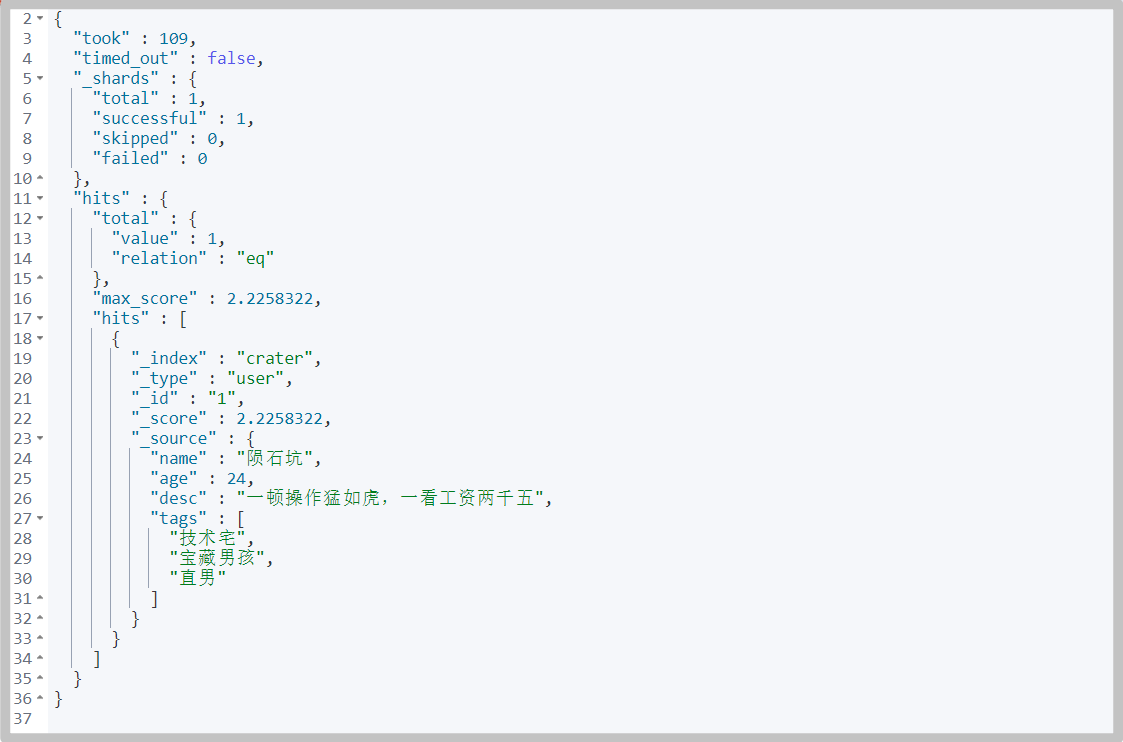
# command GET /crater/user/_search?q=name:Meteorite
Complex condition query
Condition, projection, sorting, paging
Sorting, paging, highlighting, fuzzy query, accurate query
-
Generally, get / criter / user is not used/_ search? Q = name: meteorite is in this form, but the parameter entity is used
# Add another document for testing PUT /crater/user/4 { "name": "Crater master", "age": 18, "desc": "The operation is as fierce as a tiger, and the salary is 2500 yuan", "tags": ["technical nerd","Treasure boy","Straight man"] }# command GET /crater/user/_search { "query": { "match": { "name": "Meteorite" } } }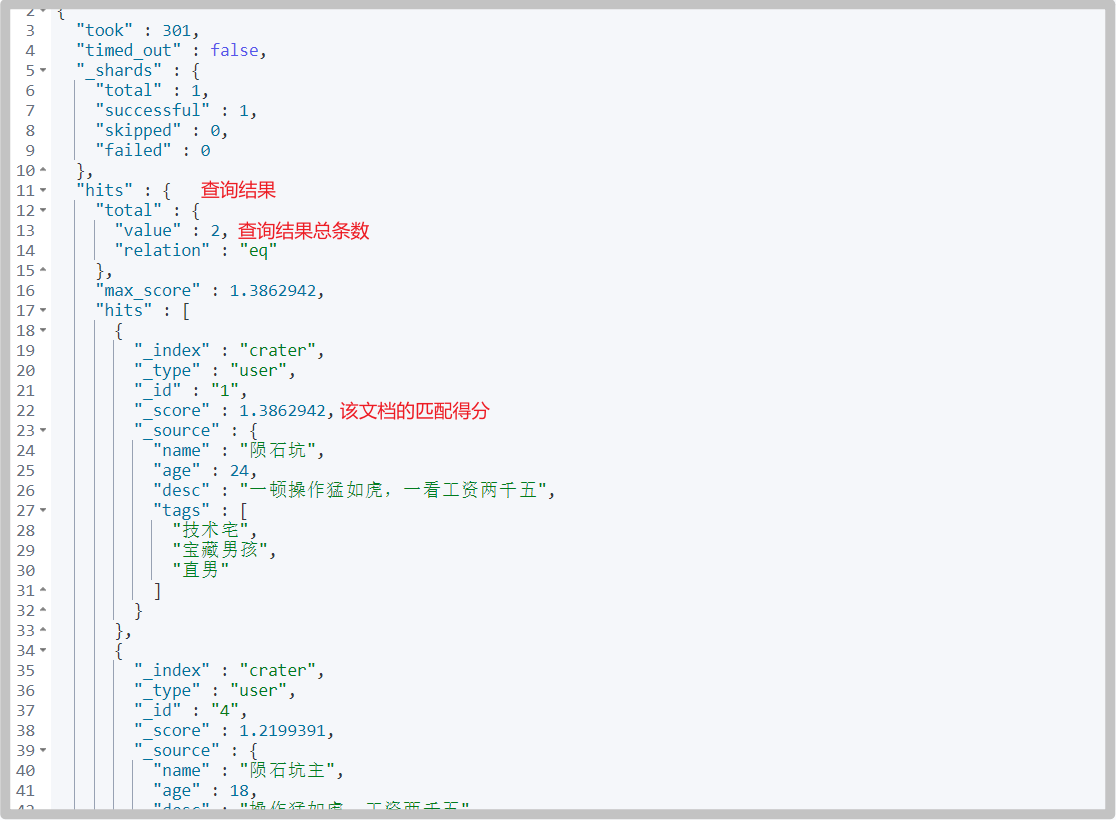
-
You can also filter the properties of the query, similar to the projection of the database
# command GET /crater/user/_search { "query": { "match": { "name": "Meteorite" } }, "_source": ["name","desc"] }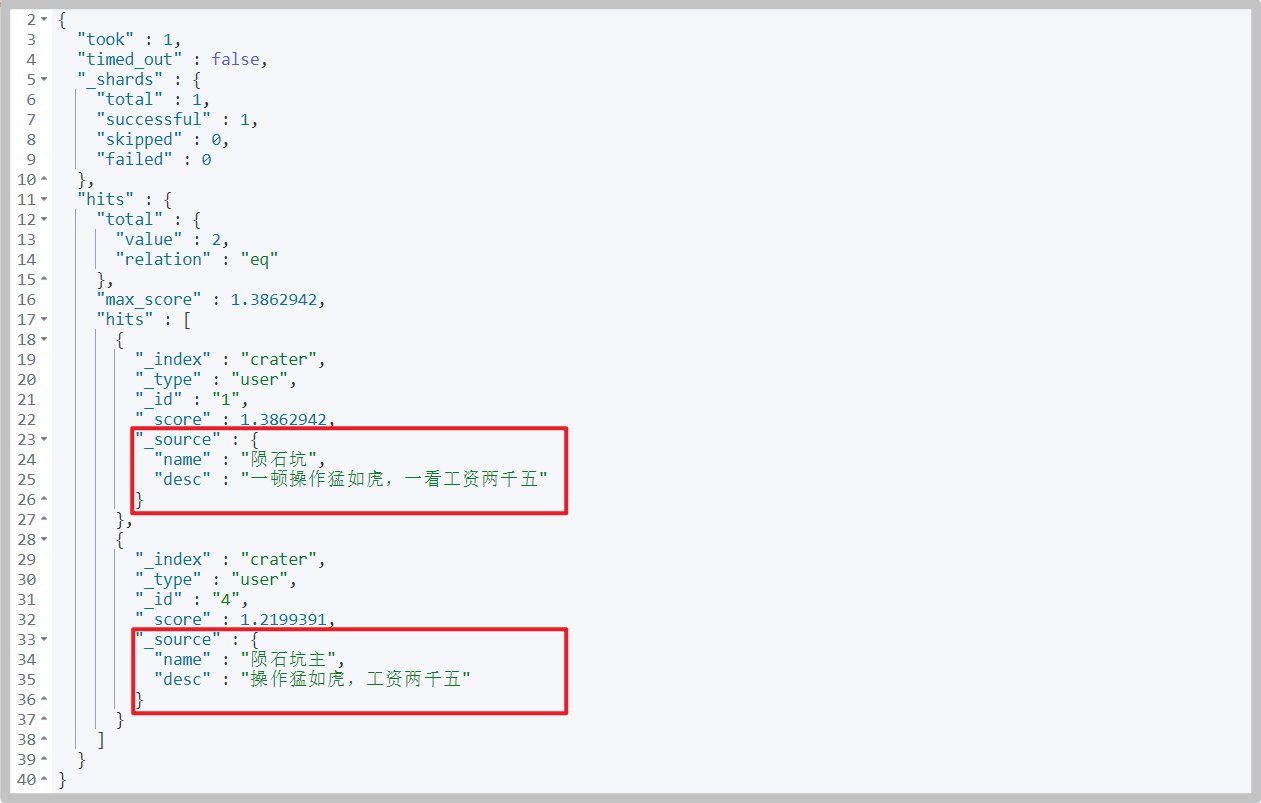
-
You can add sorting, such as sorting in reverse order according to age
# command GET /crater/user/_search { "query": { "match": { "name": "Meteorite" } }, "_source": ["name","age"], "sort": [ { "age": { "order": "desc" } } ] }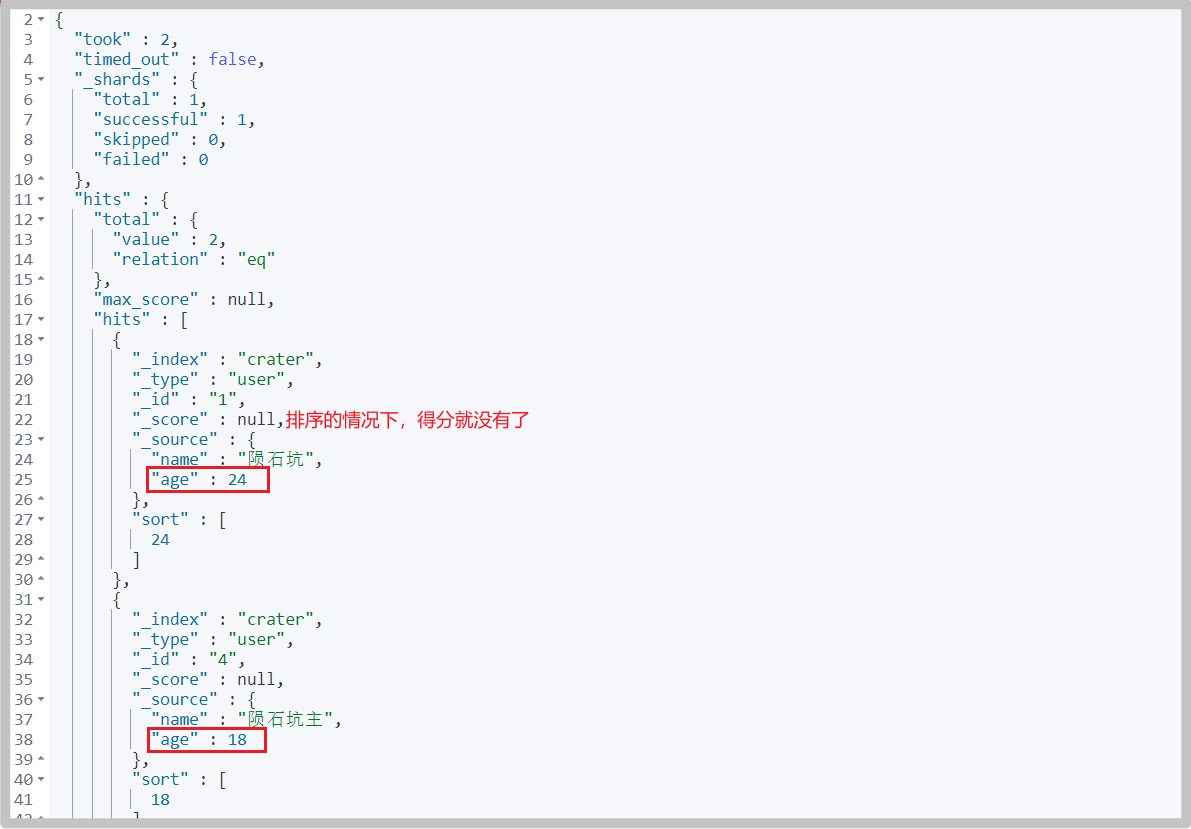
-
You can add paging queries
# command GET /crater/user/_search { "query": { "match": { "name": "Meteorite" } }, "_source": ["name","age"], "sort": [ { "age": { "order": "desc" } } ], "from": 0, # Starting page number, starting from 0 "size": 1 # Number of entries per page }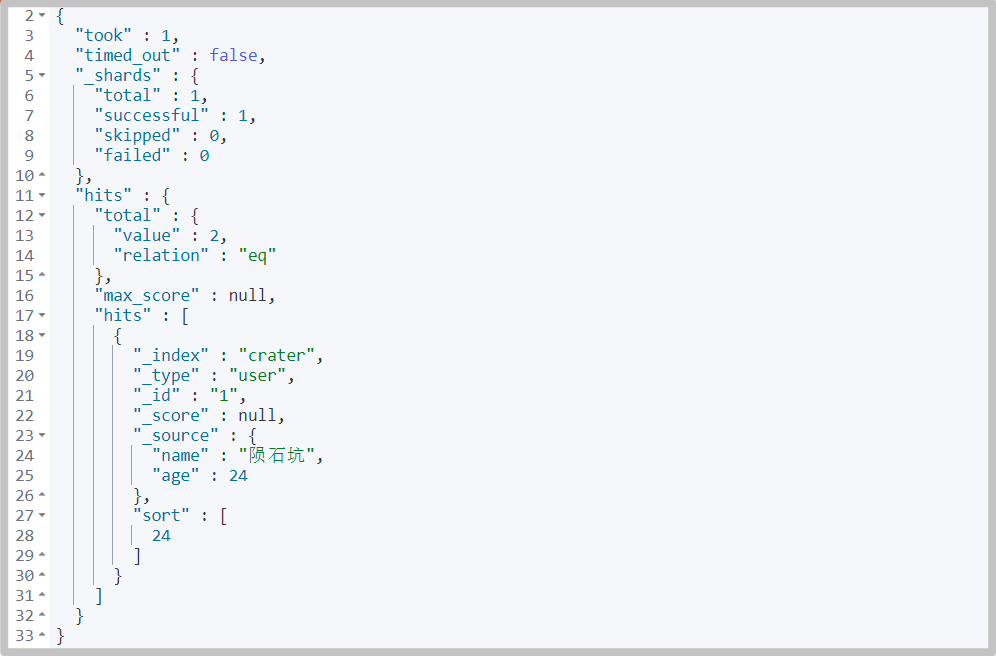
Boolean query
-
must (and), multi condition query, all conditions are met
# command GET /crater/user/_search { "query": { "bool": { "must": [ { "match": { "name": "Meteorite" } }, { "match": { "age": "24" } } ] } } }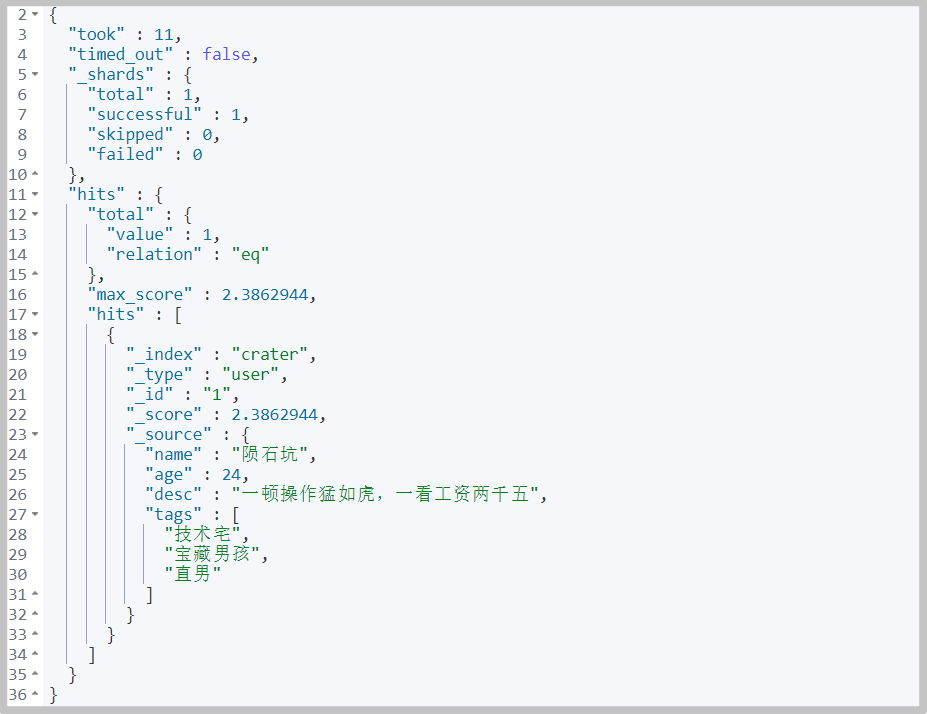
-
should (or) satisfy one condition
# command GET /crater/user/_search { "query": { "bool": { "should": [ { "match": { "name": "Meteorite" } }, { "match": { "age": "24" } } ] } } }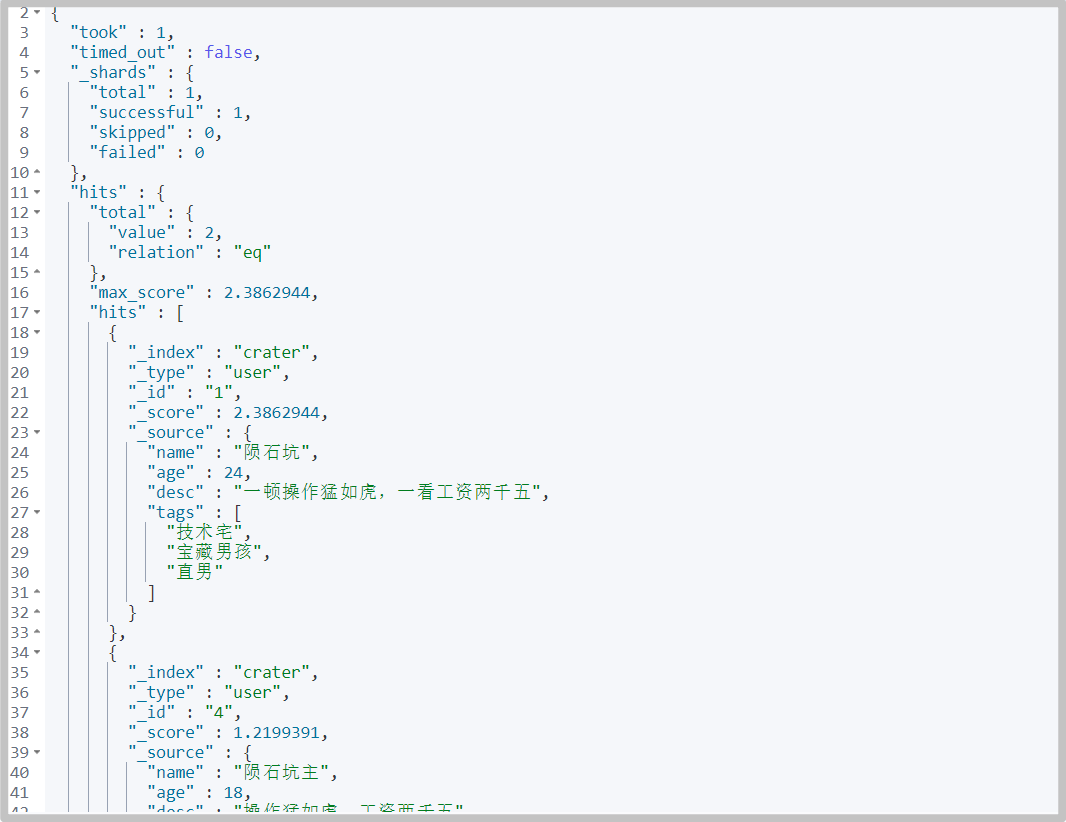
-
must_not(not)
# command GET /crater/user/_search { "query": { "bool": { "must_not": [ { "match": { "name": "Meteorite" } }, { "match": { "age": "24" } } ] } } }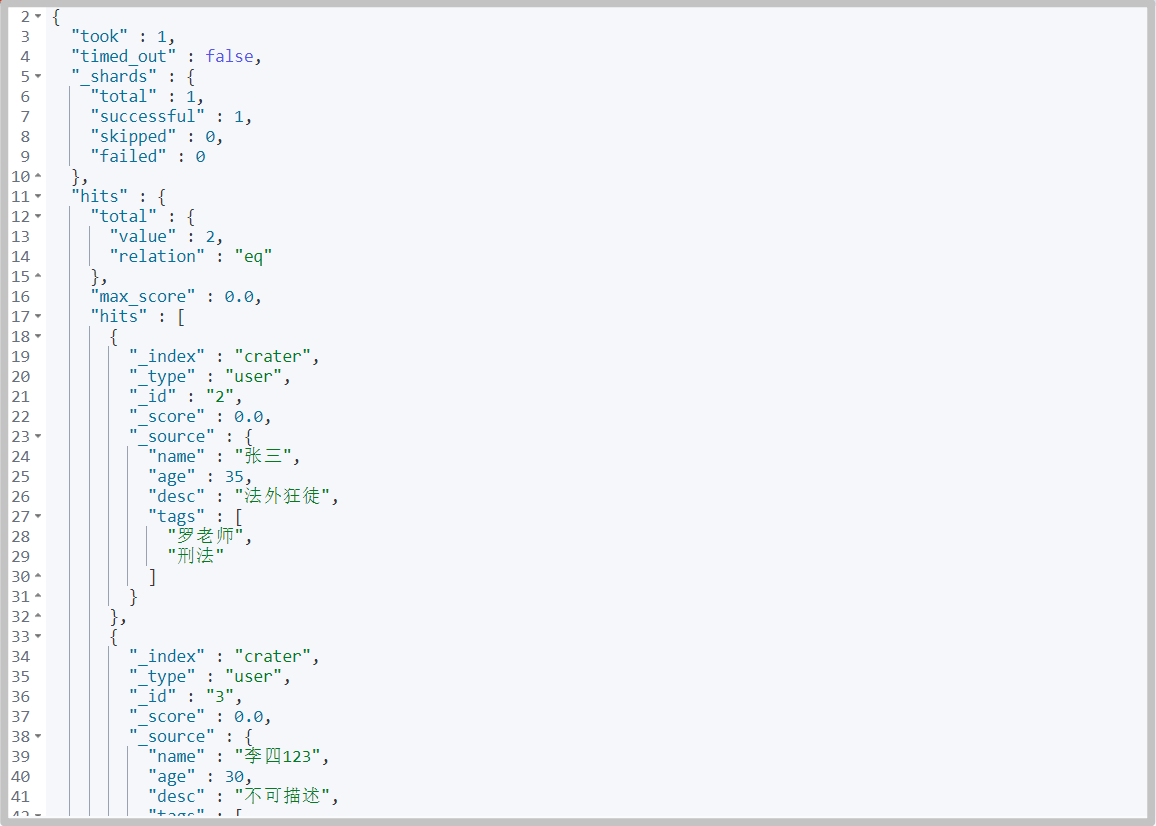
-
At the same time of query, filter is used
# command GET /crater/user/_search { "query": { "bool": { "must": [ { "match": { "name": "Meteorite" } } ], "filter": { "range": { "age": { "gte": 20 } } } } } }
Match multiple criteria
-
Multiple conditions are separated by spaces. As long as one condition is met, it can be found out. Later, the score can be used for judgment and screening
# command GET /crater/user/_search { "query": { "match": { "tags": "Men's house" } } }
Precise query
term query is an accurate search directly through the terms specified in the inverted index
About participle
- term: direct and accurate query
- match: it can be parsed using a word splitter (first analyze the document, and then query through the analyzed document)
The two types are text and keyword
-
text will be parsed by the word splitter. Before indexing, these texts will be segmented, converted into word combinations, and indexed
-
keyword type fields can only be retrieved by themselves
-
Build test
PUT testdb { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } } PUT testdb/_doc/1 { "name": "Crater name", "desc": "Crater desc1" } PUT testdb/_doc/2 { "name": "Crater name", "desc": "Crater desc2" } -
The difference between the two types of word splitter
# Parsed GET _analyze { "analyzer": "standard", "text": "Crater name" }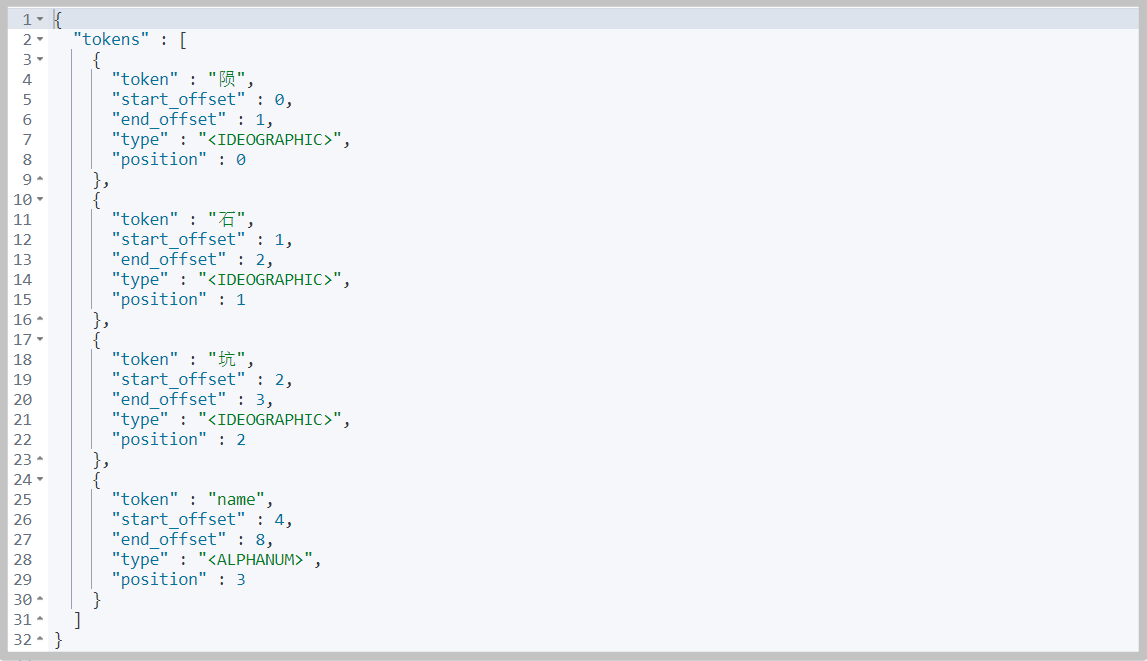
# Not resolved GET _analyze { "analyzer": "keyword", "text": "Crater desc" }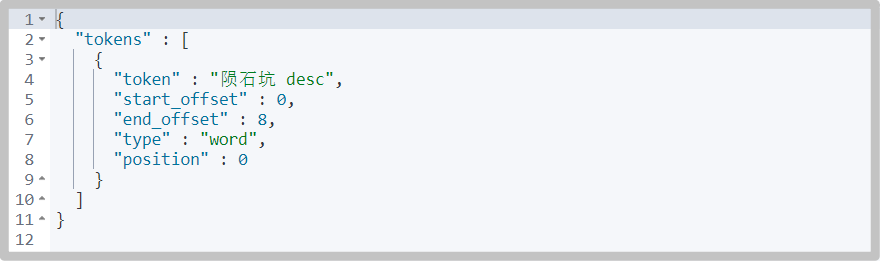
-
test
# Match to match {"name": "crater"}, you can query two pieces of data GET /testdb/_doc/_search { "query": { "match": { "name": "Crater" } } } # Match to match {"desc": "crater"}, no data can be queried, # The keyword type field will not be parsed by the word splitter, but can only be retrieved by itself, such as {"desc": "meteorite crater desc1"} GET /testdb/_doc/_search { "query": { "match": { "desc": "Crater" } } } # If you use term to match {"name": "crater"}, {"desc": "crater"}, you can't query the data, because you need full value accurate matching # If you want to query data: # For name, match the resolved "meteorite", "stone", "crater" and "name" # For DESC, you need to match "crater desc1" and "crater desc2" GET /testdb/_doc/_search { "query": { "term": { "name": "Crater" } } } GET /testdb/_doc/_search { "query": { "term": { "desc": "Crater" } } } # You can also query two pieces of data by match ing {"name": "crater"}, -
Summary:
match (fuzzy) and term (exact) refer to the degree of matching when querying
For example, "meteorite crater name" is a text, which is segmented into "meteorite", "stone", "crater" and "name" when it is created. Therefore, term cannot be used to query "meteorite crater name", but term can be used to query "meteorite", "stone", "crater" and "name", because the index of comparison participle can accurately match these four words
The "meteorite crater desc1" is of keyword type. When it is created, there is no word segmentation and only one index. Therefore, whether match or term is used, the full value is required
match and term are responsible for whether the data of query criteria is word segmentation, and text and keyword are responsible for whether the stored data is word segmentation
Multiple value matching exact query
-
Add test data
PUT testdb/_doc/3 { "t1": "22", "t2": "2021-12-20" } PUT testdb/_doc/4 { "t1": "33", "t2": "2021-12-17" } -
Accurately query multiple values with term
GET testdb/_search { "query": { "bool": { "should": [ { "term": { "t1": "22" } }, { "term": { "t1": "33" } } ] } } }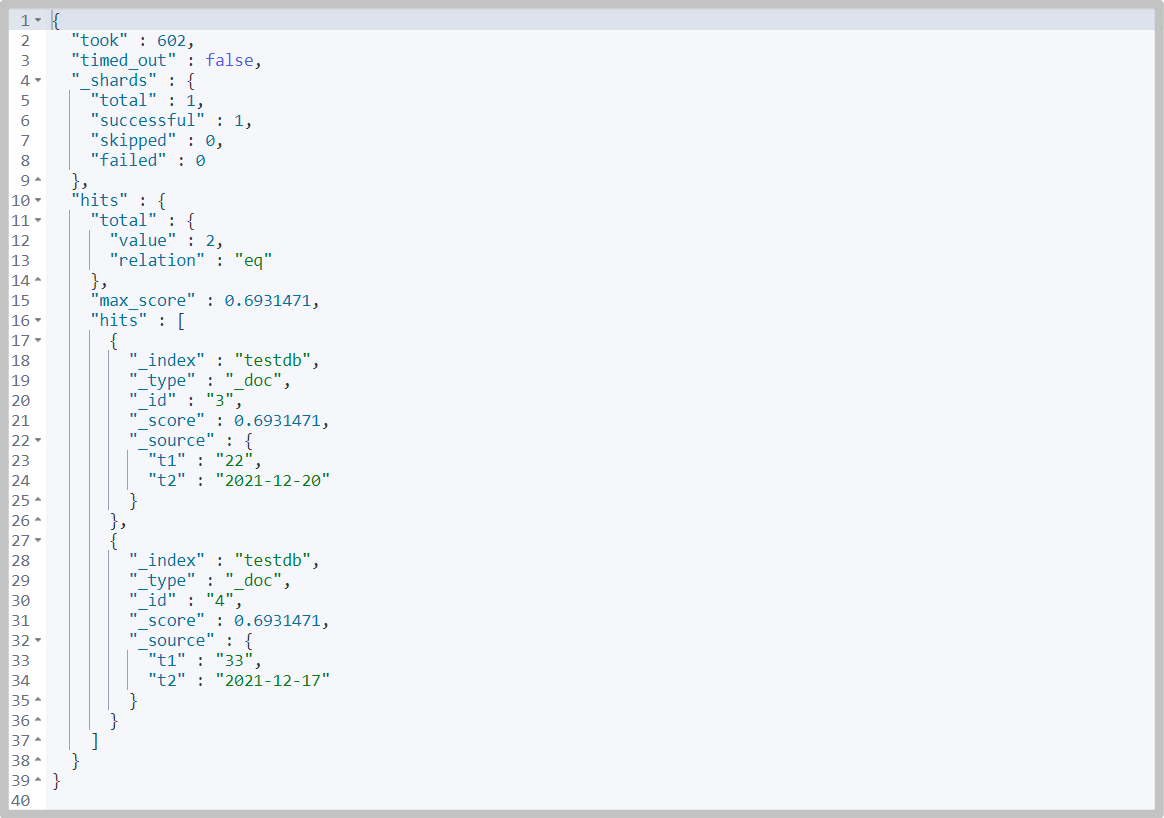
Highlight query
-
When querying, use highlight to specify the highlighted field
You can see that in the query results, the words you want to query in the query conditions are labeled
# command GET crater/user/_search { "query": { "match": { "name": "Meteorite" } }, "highlight": { "fields": { "name": {} } } }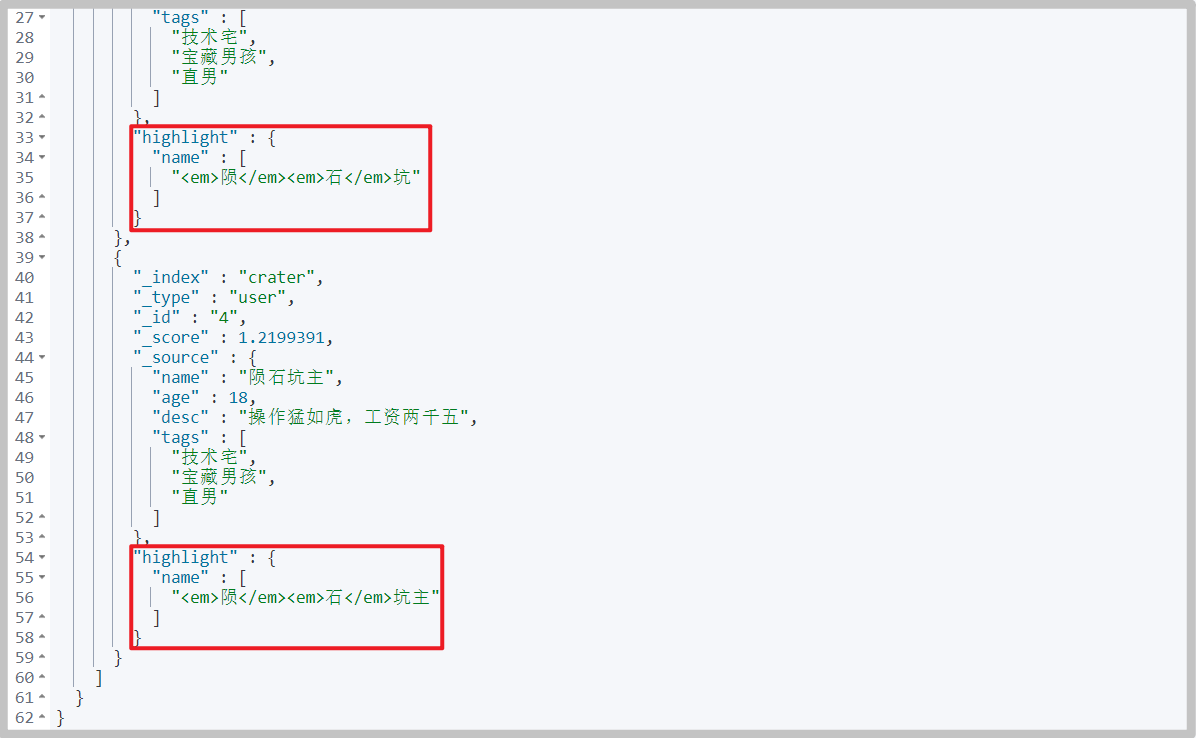
-
The em label is the default label, or you can specify a custom label
# command GET crater/user/_search { "query": { "match": { "name": "Meteorite" } }, "highlight": { "pre_tags": "<p class='key' style='color:red'>", "post_tags": "</p>", "fields": { "name": {} } } }As you can see, the words are wrapped in custom tags

Integrated SpringBoot
Client documentation: https://www.elastic.co/guide/en/elasticsearch/client/index.html
Java REST Client is recommended: https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.html
Select Java High Level REST Client advanced client and operate according to the document:
-
Introducing native dependencies
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.15.2</version> </dependency> -
initialization
Bind nodes in a cluster. A node is also a cluster
RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("localhost", 9200, "http"), new HttpHost("localhost", 9201, "http")));It needs to be closed after use
client.close();
test
-
Building the project environment is the most important dependence
-
Customize ES dependency to ensure consistency with local
<properties> <java.version>1.8</java.version> <!-- custom ES Version dependent to ensure consistency with local --> <elasticsearch.version>7.15.2</elasticsearch.version> </properties> -
Inject RestHighLevelClient (client)
package com.crater.config; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class ElasticSearchClientConfig { @Bean public RestHighLevelClient restHighLevelClient() { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")) ); return client; } }
Index API test
-
Test index creation
@SpringBootTest class CraterEsApiApplicationTests { @Autowired @Qualifier("restHighLevelClient") private RestHighLevelClient client; /** * Test index creation */ @Test void testCreateIndex() throws IOException { // 1. Create index request CreateIndexRequest request = new CreateIndexRequest("crater_index"); // 2. Execute creation request IndicesClient indices = client.indices(); CreateIndexResponse createIndexResponse = indices.create(request, RequestOptions.DEFAULT); System.out.println(createIndexResponse); } }# print contents org.elasticsearch.client.indices.CreateIndexResponse@38e8e841
-
Test get index
/** * Test get index */ @Test void testExistIndex() throws IOException { GetIndexRequest request = new GetIndexRequest("crater_index"); boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println(exists); } -
Test delete index
/** * Test delete index */ @Test void testDeleteIndex() throws IOException { DeleteIndexRequest request = new DeleteIndexRequest("crater_index"); AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT); System.out.println(delete.isAcknowledged()); }
Document API testing
-
Test add document
/** * Test add document */ @Test void testAddDocument() throws IOException { // create object User user = new User("Crater", 17); // Create request IndexRequest request = new IndexRequest("crater_index"); // Rules: get / criter_ index/_ doc/1 request.id("1"); request.timeout(TimeValue.timeValueSeconds(1)); // Data put request JSON request.source(JSON.toJSONString(user), XContentType.JSON); // The client sends a request to get the response result IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT); System.out.println(indexResponse.status()); System.out.println(indexResponse.toString()); }# Return value CREATED IndexResponse[index=crater_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}] -
To obtain a document, first determine whether it exists
/** * To obtain a document, first determine whether it exists: get criter_ index/_ doc/1 */ @Test void testIsExist() throws IOException { GetRequest getRequest = new GetRequest("crater_index", "1"); // Do not get returned_ source context getRequest.fetchSourceContext(new FetchSourceContext(false)); // Do not sort getRequest.storedFields("_none_"); boolean exists = client.exists(getRequest, RequestOptions.DEFAULT); System.out.println(exists); }Get document
/** * Get document */ @Test void testGetDocument() throws IOException { GetRequest getRequest = new GetRequest("crater_index", "1"); GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT); System.out.println(getResponse.getSourceAsString()); System.out.println(getResponse); }# Return value {"age":17,"name":"Crater"} {"_index":"crater_index","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"age":17,"name":"Crater"}} -
Modify document information
/** * Update document information */ @Test void testUpdateRequest() throws IOException { UpdateRequest request = new UpdateRequest("crater_index", "1"); request.timeout(TimeValue.timeValueSeconds(1)); User user = new User("Crater YYDS", 3); request.doc(JSON.toJSONString(user), XContentType.JSON); UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT); System.out.println(updateResponse.status()); } -
Batch insert
/** * Batch insert */ @Test void testBulkRequest() throws IOException { BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("10s"); List<User> users = new ArrayList<>(); users.add(new User("Crater 01", 14)); users.add(new User("Crater 02", 14)); users.add(new User("Crater 03", 14)); users.add(new User("Crater 04", 14)); users.add(new User("Crater 05", 14)); // Batch request for (int i = 0; i < users.size(); i++) { bulkRequest.add( // Batch update and batch delete. You can modify different requests here new IndexRequest("crater_index") .id((i + 1) + "") .source(JSON.toJSONString(users.get(i)), XContentType.JSON) ); } BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT); System.out.println(bulkResponse.status()); }
Actual combat - Jingdong search
Environment construction
-
Build the project environment according to the test environment
-
yml configuration
server.port=9090 # Turn off thymeleaf cache spring.thymeleaf.cache=false
-
Copy static files to directory
File acquisition: pay attention to the crazy God and restore ElasticSearch. The knowledge is priceless and supports genuine
-
New controller
@Controller public class IndexController { @RequestMapping({"/","index"}) public String index() { return "index"; } } -
Start project, access http://127.0.0.1:9090/
Reptile
-
Search for an entry in Jingdong Mall and you can see the url of the visit
https://search.jd.com/Search?keyword=java

-
jsoup package is introduced to parse the data of web pages
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.13.1</version> </dependency> -
Create a new HtmlParseUtil class under utils package
Test, data can be obtained
@Component public class HtmlParseUtil { public static void main(String[] args) throws IOException { List<Content> javas = new HtmlParseUtil().parseJD("MacBok"); for (Content java : javas) { System.out.println(java); } } public List<Content> parseJD(String keyWord) throws IOException{ String url = "https://search.jd.com/Search?keyword=" + keyWord; // When parsing a web page, the Document returned by jsup is the browser Document object Document document = Jsoup.parse(new URL(url), 30000); // Action Document Element element = document.getElementById("J_goodsList"); // Get li tag Elements elements = element.getElementsByTag("li"); // Gets the content in the element List<Content> goodList = new ArrayList<>(); for (Element el : elements) { // For websites with many pictures, lazy loading is adopted for response speed. The real url of JD is saved in data lazy img String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img"); String price = el.getElementsByClass("p-price").eq(0).text(); String title = el.getElementsByClass("p-name").eq(0).text(); goodList.add(new Content(title, img, price)); } return goodList; } }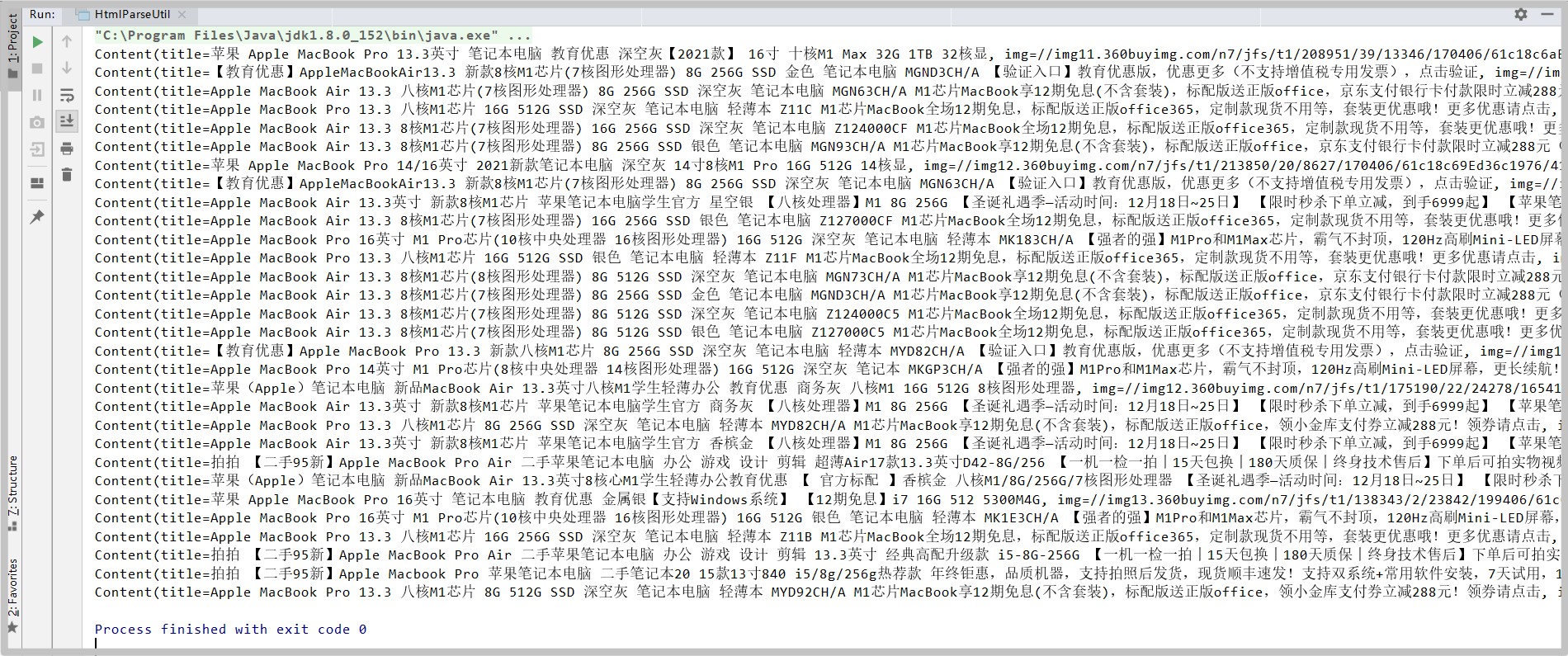
Write business
-
Write Service layer
@Service public class ContentService { @Autowired private RestHighLevelClient restHighLevelClient; @Autowired private HtmlParseUtil htmlParseUtil; public Boolean parseContent(String keywords) throws IOException { List<Content> contents = htmlParseUtil.parseJD(keywords); // Insert the crawled data into ES BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("2m"); for (int i = 0; i < contents.size(); i++) { bulkRequest.add( new IndexRequest("jd_goods") .source(JSON.toJSONString(contents.get(i)), XContentType.JSON) ); } BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); return !bulk.hasFailures(); } } -
Write Controller layer
@RestController public class ContentController { @Autowired private ContentService contentService; @GetMapping("/parse/{keywords}") public Boolean parse(@PathVariable("keywords") String keywords) throws IOException { return contentService.parseContent(keywords); } } -
By calling this interface, data can be added to ES on the premise of creating a new index jd_goods
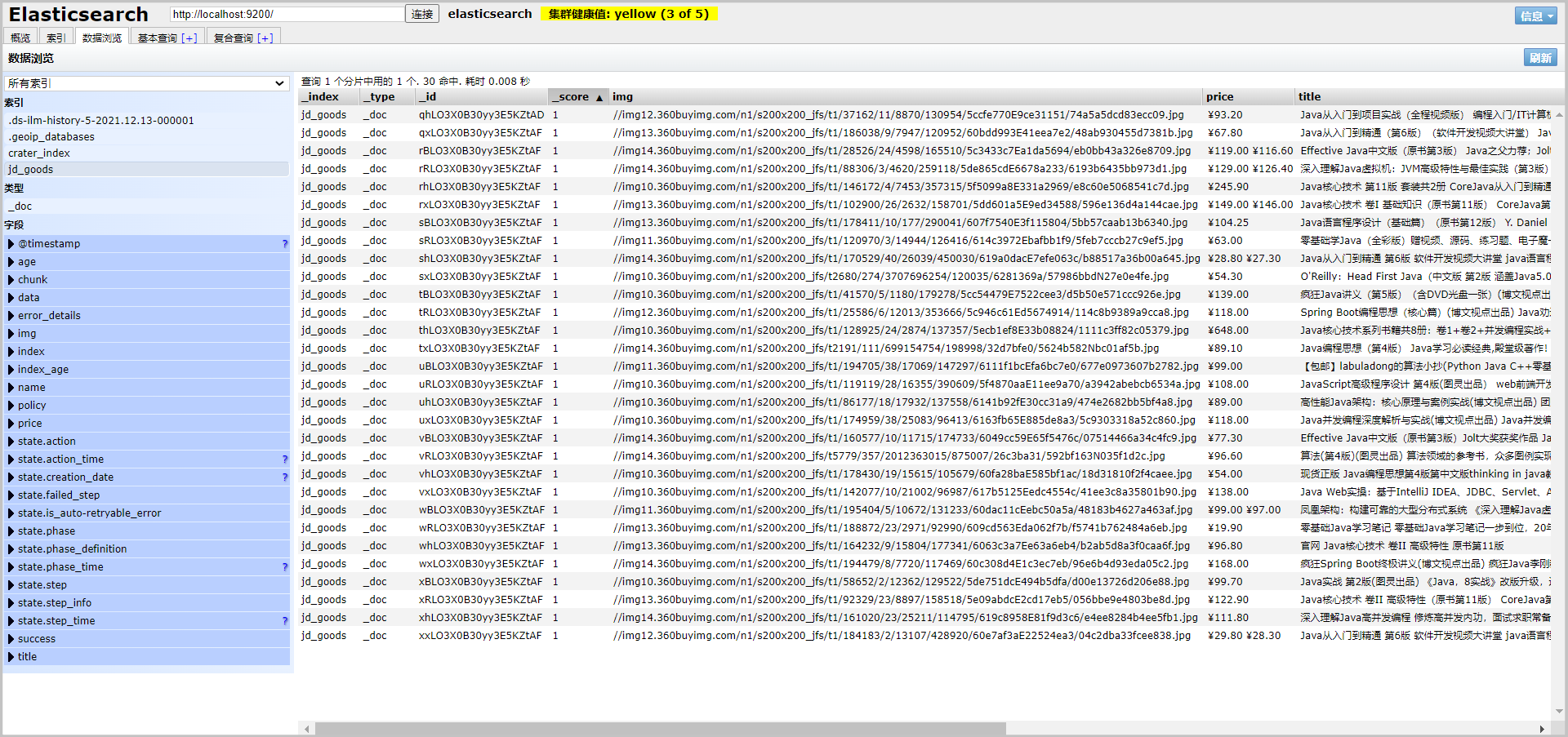
-
Obtain these data to realize the search function
Service layer:
/** * Crawling data into ES */ public List<Map<String, Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException { if (pageNo < 1) { pageNo = 1; } // Condition search SearchRequest searchRequest = new SearchRequest("jd_goods"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // paging sourceBuilder.from(pageNo); sourceBuilder.size(pageSize); // Accurate matching TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword); sourceBuilder.query(termQueryBuilder); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // Perform search searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); // Analytical results List<Map<String, Object>> list = new ArrayList<>(); for (SearchHit documentFields : searchResponse.getHits().getHits()) { list.add(documentFields.getSourceAsMap()); } return list; }Controller layer
@GetMapping("/search/{keywords}/{pageNo}/{pageSize}") public List<Map<String, Object>> search(@PathVariable("keywords") String keywords, @PathVariable("pageNo") int pageNo, @PathVariable("pageSize") int pageSize) throws IOException { return contentService.searchPage(keywords, pageNo, pageSize); }Access this interface and test it

Front end display
Vue is used, but scaffolding is not used
-
Put Vue min.js axios. Copy min.js to / static/js/
Main code, see gitee for detailed code
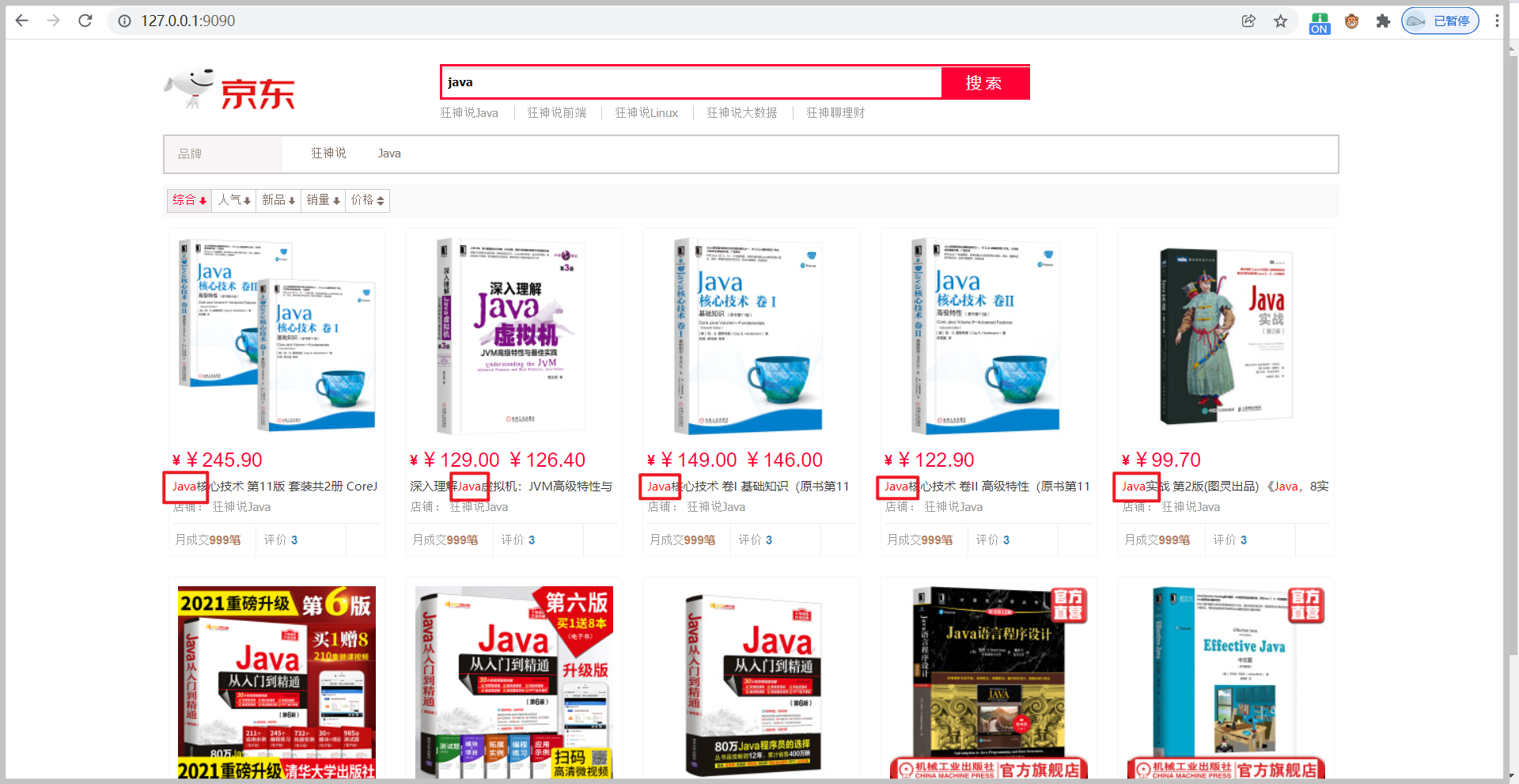
<!-- Product details --> <div class="view grid-nosku"> <div class="product" v-for="result in results"> <div class="product-iWrap"> <!--Product cover--> <div class="productImg-wrap"> <a class="productImg"> <img :src="result.img"> </a> </div> <!--Price--> <p class="productPrice"> <em><b>¥</b>{{result.price}}</em> </p> <!--title--> <p class="productTitle"> <a> {{result.title}} </a> </p> <!-- Shop name --> <div class="productShop"> <span>Shop: Crazy God said Java </span> </div> <!-- Transaction information --> <p class="productStatus"> <span>Monthly transaction<em>999 pen</em></span> <span>evaluate <a>3</a></span> </p> </div> </div> </div><!-- Front end use Vue --> <script th:src="@{/js/axios.min.js}"></script> <script th:src="@{/js/vue.min.js}"></script> <script> new Vue({ el: '#app ', / / bind the outermost div data: { keyword: "", // Search keywords results: [] // search result }, methods: { searchKey() { var keyword = this.keyword; // Docking back-end interface axios.get('search/'+keyword+'/1/10').then(res => { this.results = res.data; }) } } }) </script> -
test
Highlight
-
Add a highlight constructor to the ContentService
// Highlight HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.requireFieldMatch(false); // Are multiple matches highlighted highlightBuilder.field("title"); highlightBuilder.preTags("<span style='color:red'>"); highlightBuilder.postTags("</span>"); sourceBuilder.highlighter(highlightBuilder); -
Parse the highlighted field and replace the original content
for (SearchHit hit : searchResponse.getHits().getHits()) { // Resolve highlighted fields Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField title = highlightFields.get("title"); Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // Original results of query // Replace the original field with a highlighted field if (title != null) { Text[] fragments = title.fragments(); StringBuilder newTitle = new StringBuilder(); for (Text text : fragments) { newTitle.append(text); } sourceAsMap.put("title", newTitle.toString()); // replace } list.add(sourceAsMap); } -
Page title, parse the value into html
<!--title--> <p class="productTitle"> <a v-html="result.title"> </a> </p> -
Test, the keyword is highlighted
Finish scattering flowers!!!