Elasticsearch basic operations
1, Overview
Elastic search, abbreviated as ES, is an open source, highly extended and RESTful distributed full-text search engine, which can store and retrieve data in near real time; It has good scalability and can be extended to hundreds of servers to process PB level data.
The full-text search engine mentioned here refers to the mainstream search engine widely used at present. Its working principle is that the computer indexing program establishes an index for each word by scanning each word in the article, indicating the number and location of the word in the article. When the user queries, the retrieval program will search according to the pre established index, And feed back the search results to the user's retrieval method. This process is similar to the process of looking up words through the search word table in the dictionary.
Elasticsearch is a document oriented database. A piece of data is a document. The comparison between the document data stored in elasticsearch and the data stored in MySQL:
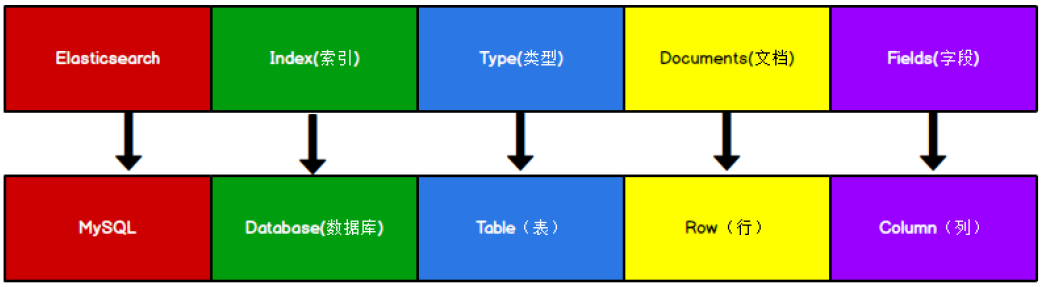
Note: the concept of Type in Elasticsearch has been deleted.
1.1 forward index and inverted index
Forward index:
In MySQL, a forward index is used, such as querying the values of corresponding fields in a record based on the primary key index. However, if a fuzzy query (querying a part of a field) can only locate the complete field value according to the index, this index may become invalid.
Inverted index:
ES adopts inverted index, which performs word segmentation and disassembly of articles, and establishes an index for each word. According to a specific word, you can query the corresponding index value, and according to this index value, you can query the whole article content, which is inverted index.
2, Installer
-
Download address: Past Releases of Elastic Stack Software | Elastic (this article uses the Win format of version 7.8.0)
-
Decompress the compressed package to obtain the following directory structure:
-
After decompression, enter the bin directory and click elastic search Bat file to start ES service:
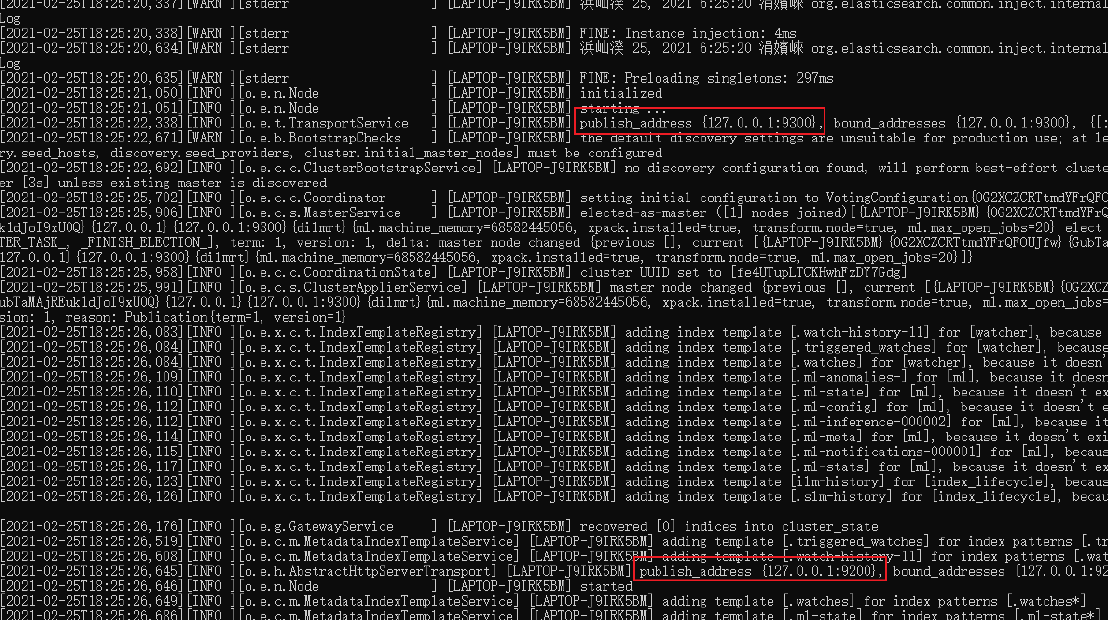
Note: Port 9300 is the communication port of Elasticsearch cluster components, and port 9200 is the HTTP protocol RESTful port accessed by the browser.
-
Open the browser and enter the web address: http://localhost:9200/ , the following interface appears to indicate successful startup:

-
In order to facilitate the use of RESTful requests, install Postman software. Download address: https://www.getpostman.com/apps
3, HTTP operation
3.1 index operation
3.1. 1 create index
Compared with relational databases, creating an index is equivalent to creating a database.
PUT request to create index: http://127.0.0.1:9200/ Index name:
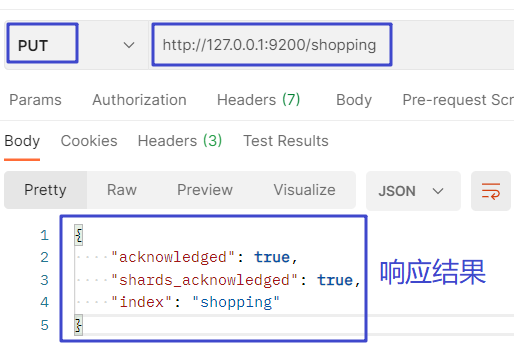
# Response result: true indicates success "acknowledged": true, # Slicing operation succeeded "shards_acknowledged": true, # Index name created "index": "shopping"
If the same index is added repeatedly, an error message is returned:
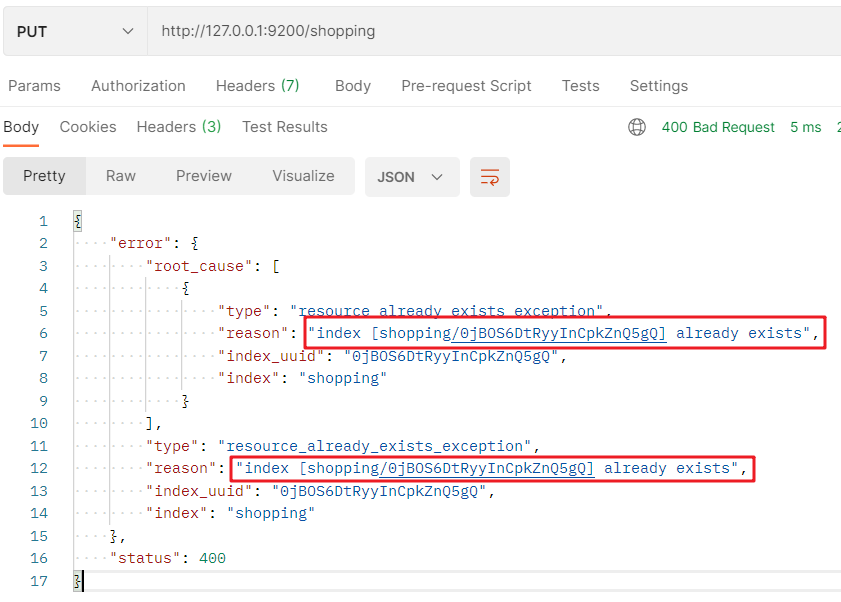
3.1. 2 view index
View all indexes:
View GET} requests for all indexes: http://127.0.0.1:9200/_cat/indices?v :
- _ cat: means to view
- Indexes: indicates all indexes
- ? v: The results are presented in tabular form
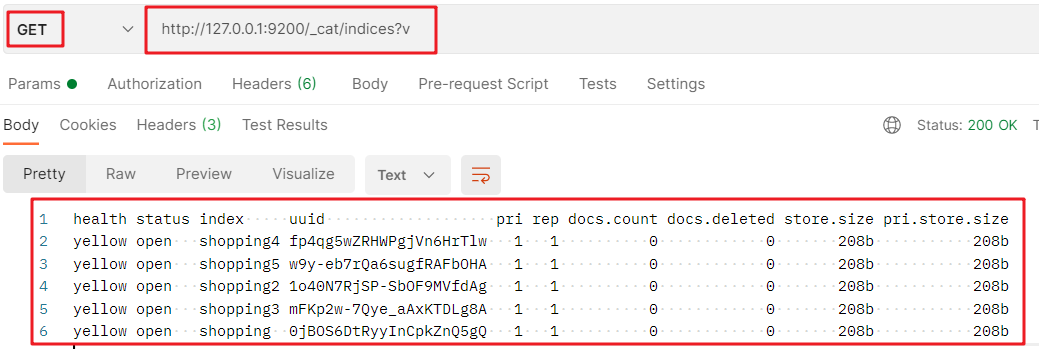
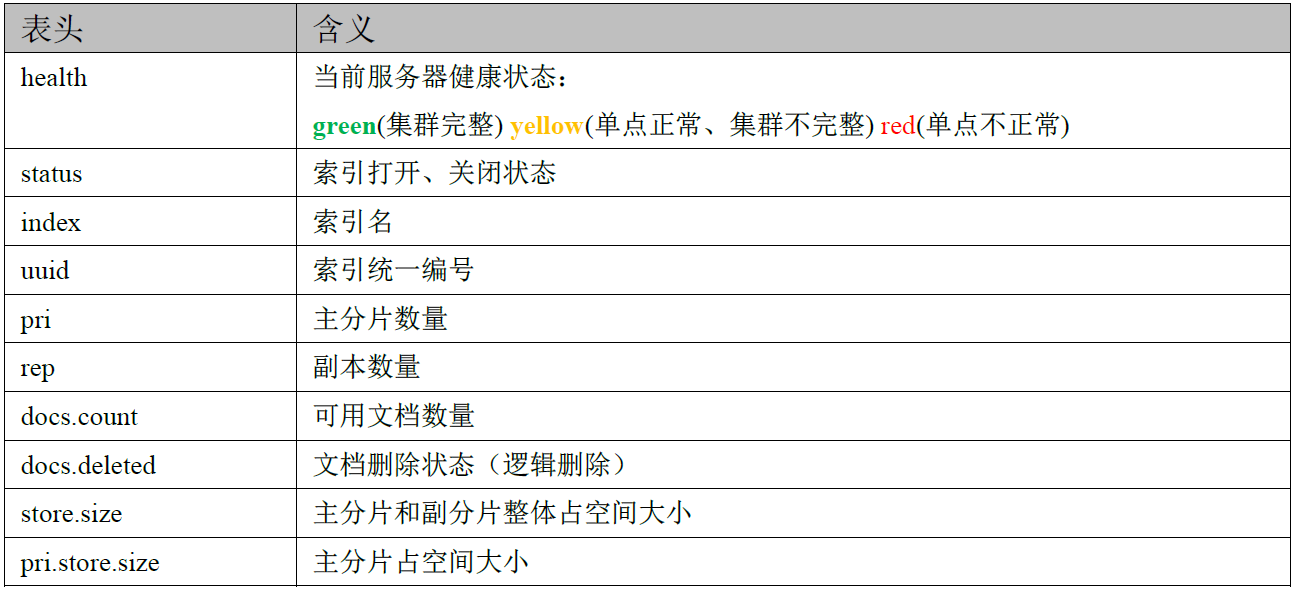
Details of response results are as follows:
To view a single index:
To view GET requests for a single index: http://127.0.0.1:9200/ Index name:
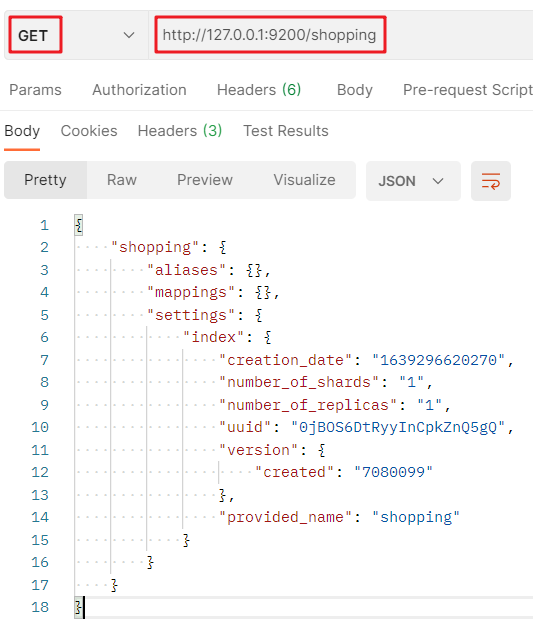
Analysis of response results:
# Index name shopping # alias aliases # mapping mappings # set up settings # Settings - index settings-index # Setting - index - creation time settings-index-creation_date # Set - index - number of primary tiles settings-index-number_of_shards # Set - index - number of sub tiles settings-index-number_of_replicas # Settings - index - unique identification settings-index-uuid # Settings - index - version settings-index-version # Settings - index - name settings-index-provided_name
3.1. 3 delete index
DELETE request to DELETE index: http://127.0.0.1:9200/ Index name:
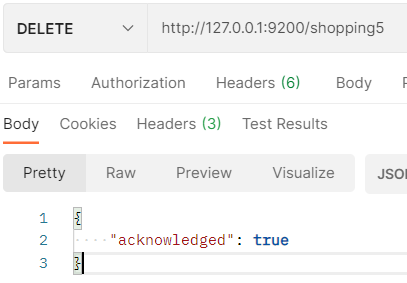
Accessing the index again, the response index does not exist:
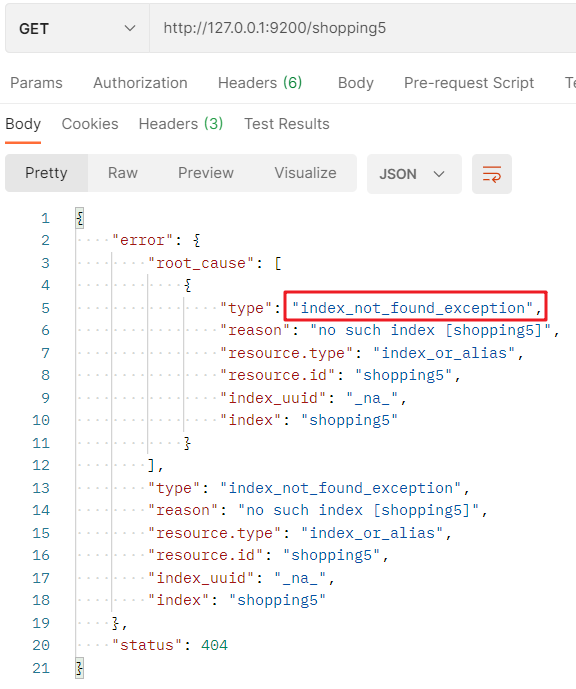
3.2 document operation
3.2. 1 create document
Randomly generated id value:
Creating a document is equivalent to creating a table record in JSON format.
The POST request to create a document is: http://127.0.0.1:9200/ Index name/_ doc + JSON format request body:
- _ doc: indicates the document:
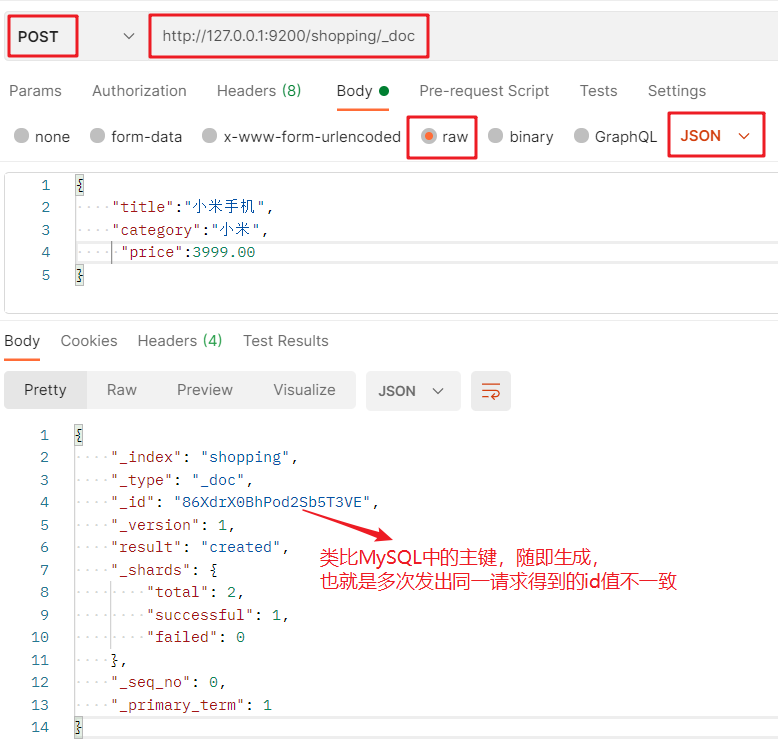
Note: since the PUT operation is idempotent, if the same request is issued multiple times, the latter will overwrite the previous one, and the created document will return_ The id values are different, so you need to use POST to create, while PUT is generally used to modify resources.
Generate fixed id value:
The POST request to create a document is: http://127.0.0.1:9200/ Index name/_ doc/id value + JSON format request body:
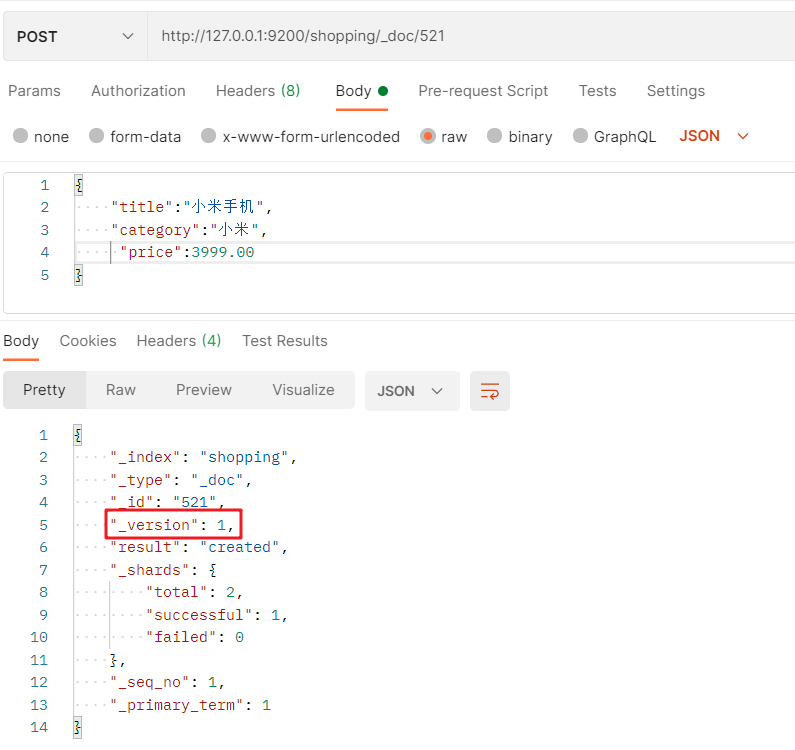
Note: if the data primary key (id) value is specified when creating a document, the request method can also use PUT.
3.2. 2 view documents
When viewing a document, you need to indicate the unique ID of the document, which is similar to MySQL's primary key query.
GET request to query document: http://127.0.0.1:9200/ Index name/_ doc / document primary key value:
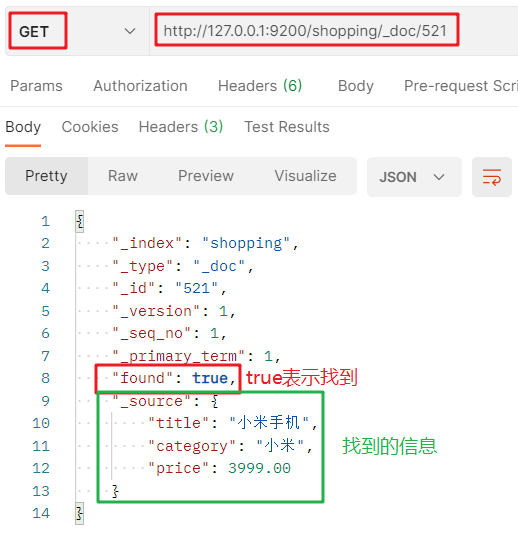
3.2. 3. Modify the document
Modify the entire document
To modify a POST request for the entire document: http://127.0.0.1:9200/ Index name/_ doc / document primary key value + JSON request body:
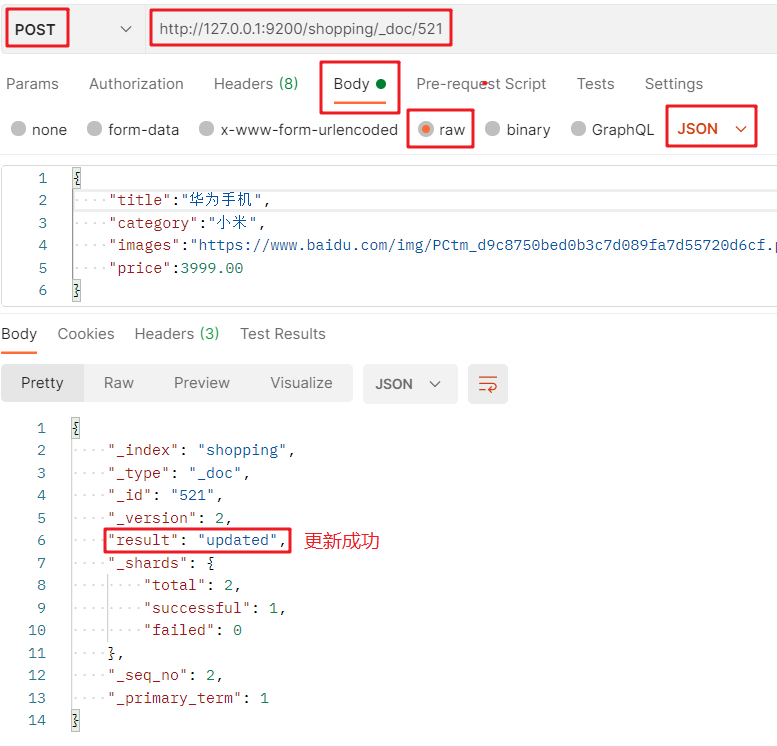
Modify some fields of the document
POST request to modify some fields of the document: http://127.0.0.1:9200/ Index value/_ update / document primary key value + JSON format request body:
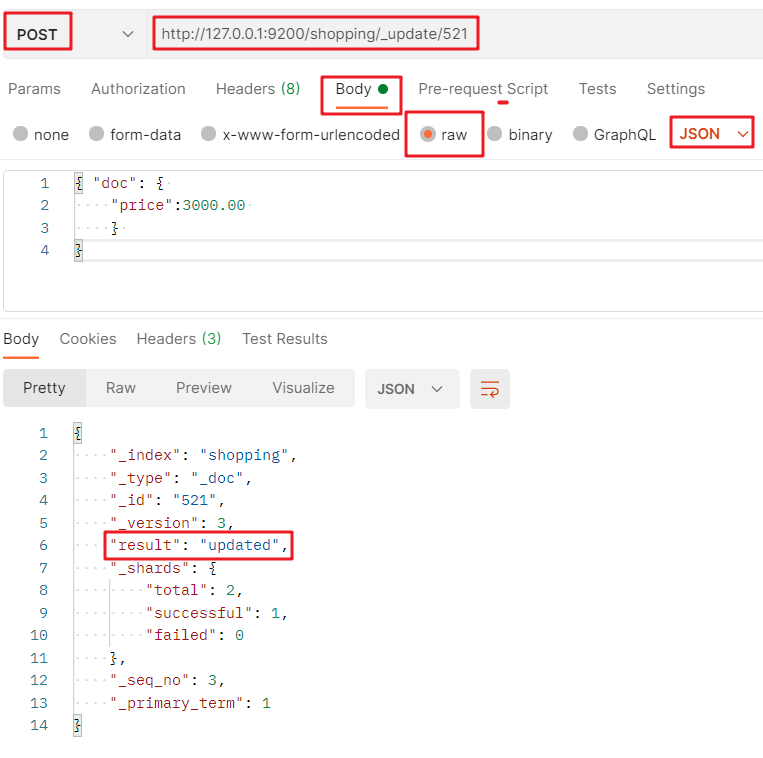
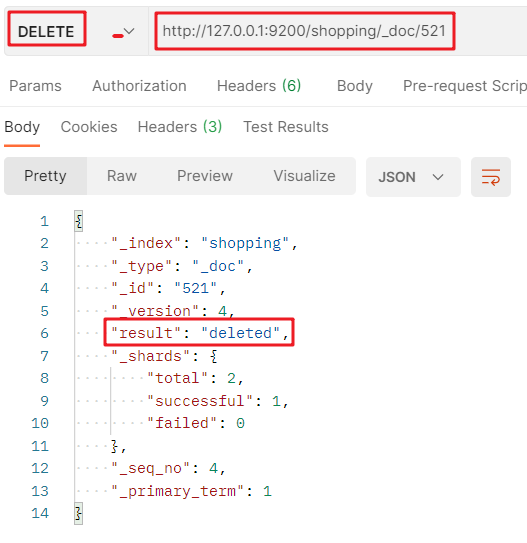
3.2. 4 delete document
Deleting a document does not immediately delete it from the disk. It is just marked as deleted (logical deletion).
DELETE request to DELETE a document: http://127.0.0.1:9200/ Index value/_ doc / document primary key value:
3.3 multiple query methods
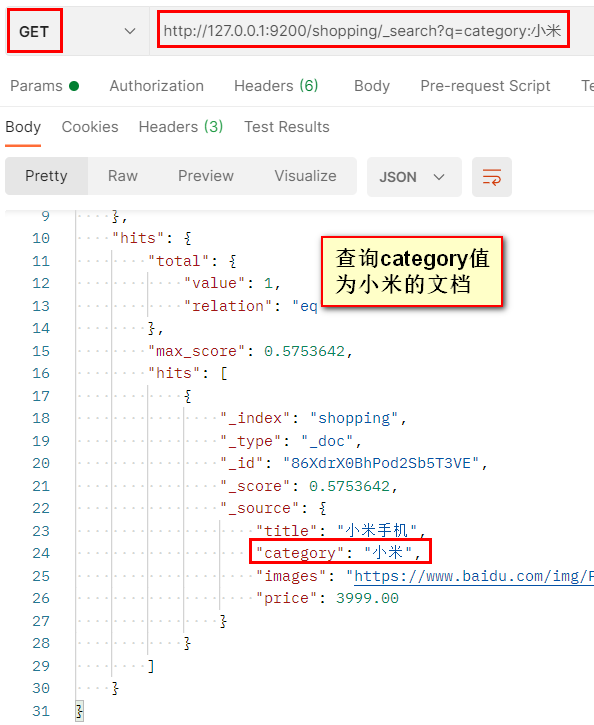
3.3. 1 condition query
After all the results are queried, they are filtered, and only the documents that meet the specified field values are displayed.
Mode 1:
Send GET request: http://127.0.0.1:9200/ Index value/_ search?q = field name: field value
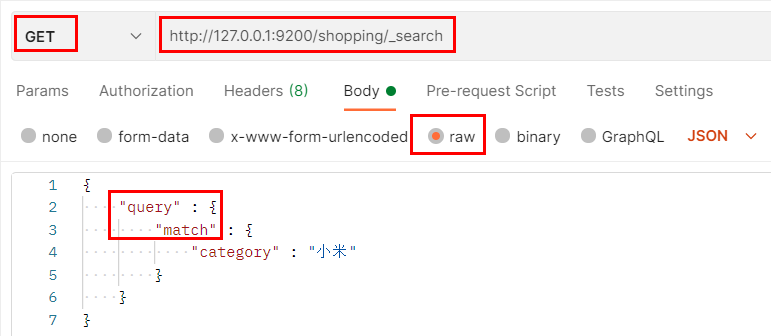
Mode 2:
Send GET request: http://127.0.0.1:9200/ Index value/_ search + JSON format request body
3.3. 2. Full query
Query all documents under an index.
Mode 1:
Send GET request: http://127.0.0.1:9200/ Index name/_ search
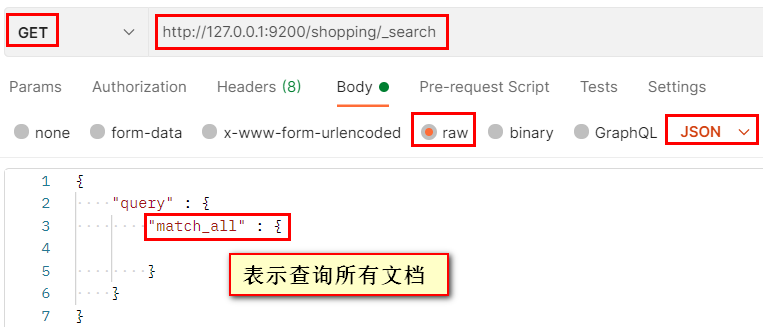
Mode 2:
Send GET request: http://127.0.0.1:9200/ Index name/_ search + JSON format request body
3.3. 3 paging query
Page query results.
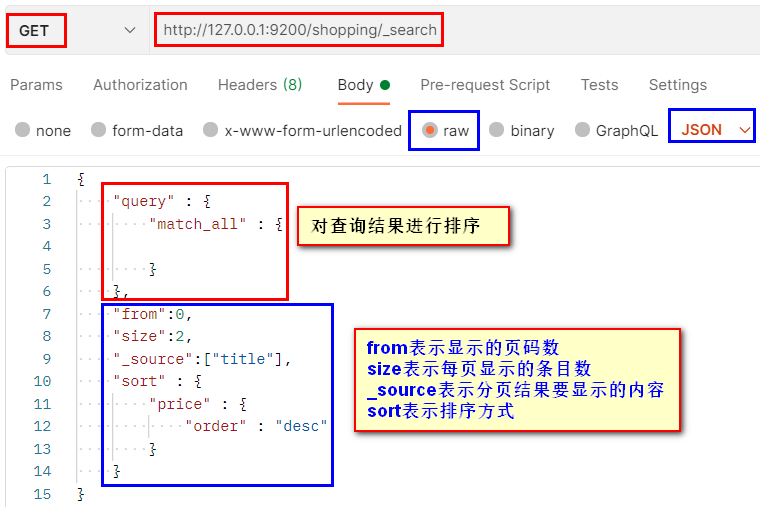
Paging results:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "86XdrX0BhPod2Sb5T3VE",
"_score": null,
"_source": {
// Only the specified title field is displayed
"title": "Mi phones"
},
"sort": [
3999.0
]
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "XndgzH0BZ5WKFcQMlsuM",
"_score": null,
"_source": {
"title": "Huawei mobile phone"
},
"sort": [
2503.36
]
}
]
}
}
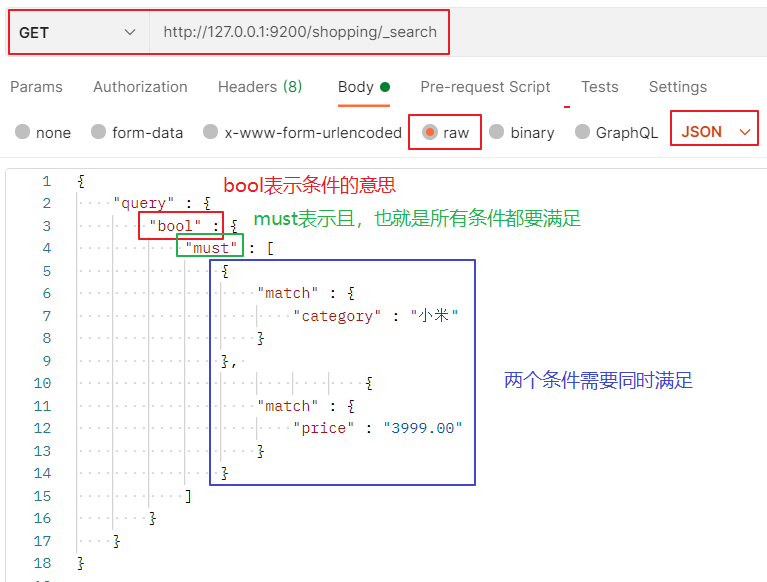
3.3. 4 multi criteria query
Case 1: and conditions
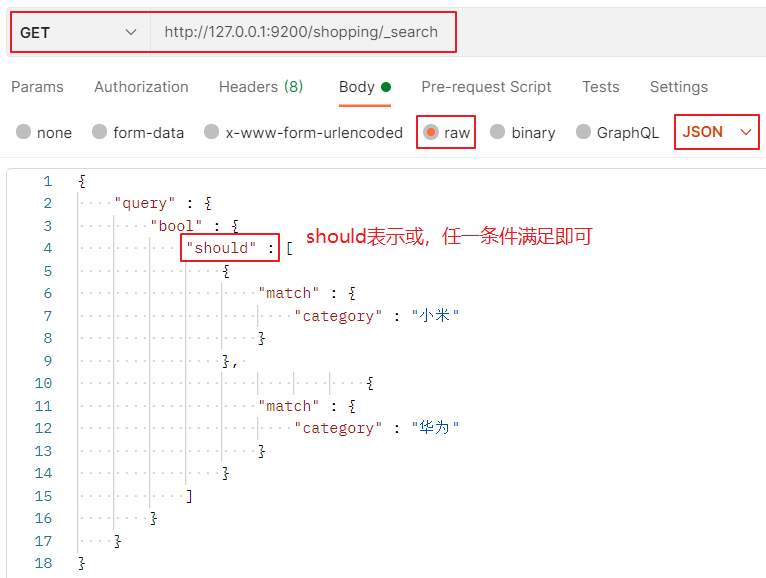
Case 2: or condition
3.3. 5 range query
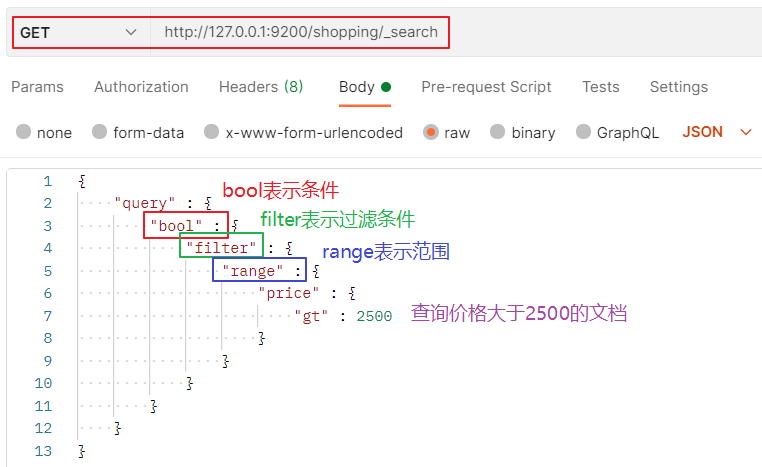
be careful:
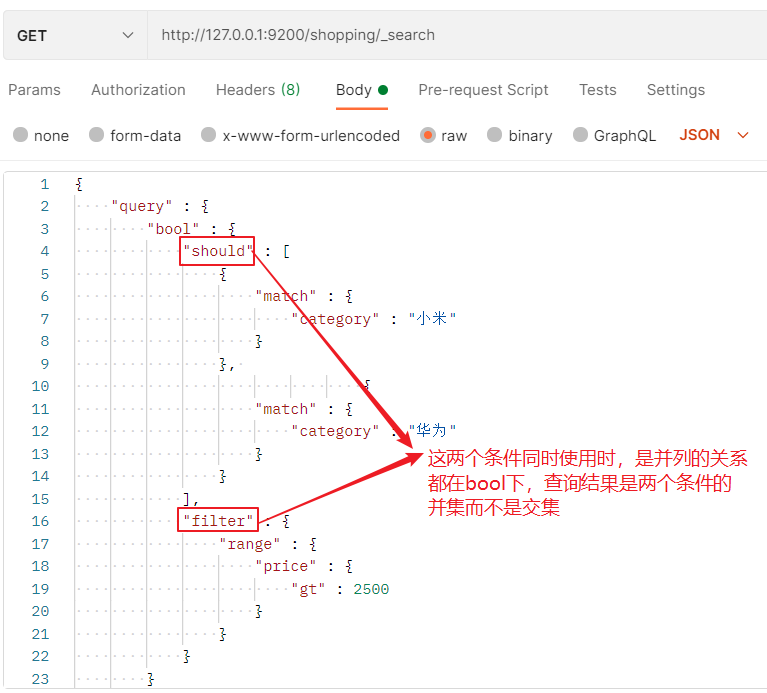
3.3. 6 full text search
Case 1:
Sometimes, when querying, you can query the results without entering the complete value of the field, such as:
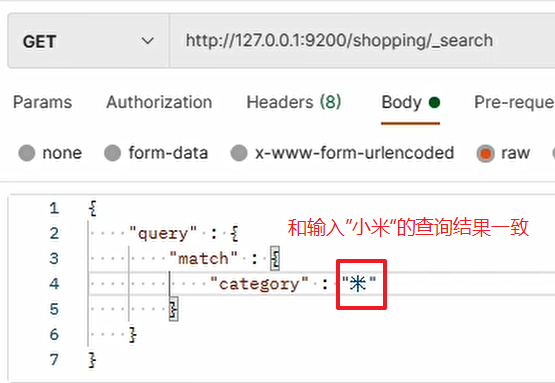
Cause: when saving the document, ES will split the data text and save the disassembly results in the inverted index, so that the corresponding results can be queried even if a part of the text is used.
Case 2:
Enter the combination structure of different field values in the two documents. The value itself does not exist in the field of any document, but all the two documents will be queried. As follows:
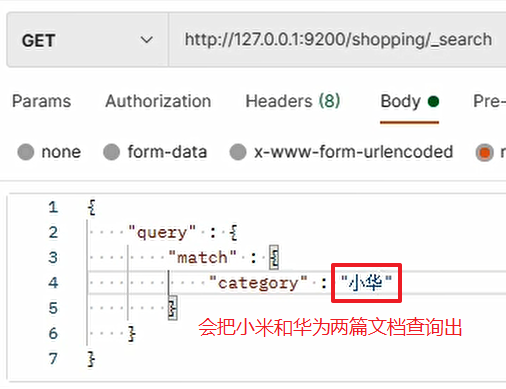
Reason for occurrence: ES will also split the query criteria into "small" and "Hua". The two words correspond to case 1 (matching the inverted index), so it will query all the two documents.
3.3. 7 exact match
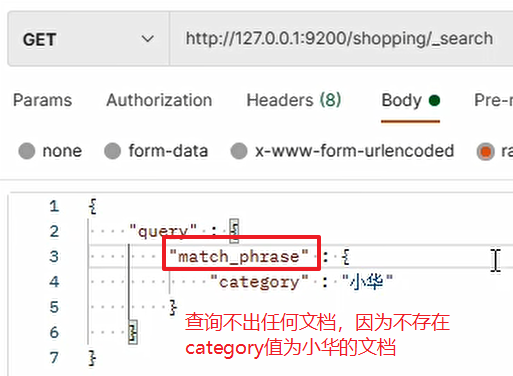
If you want to completely match the query value instead of partial matching in full-text retrieval, you need to use the keyword match_phrase:
3.3. 8 aggregate query
Query results can be grouped, averaged, and maximized.
Examples of grouping operations:
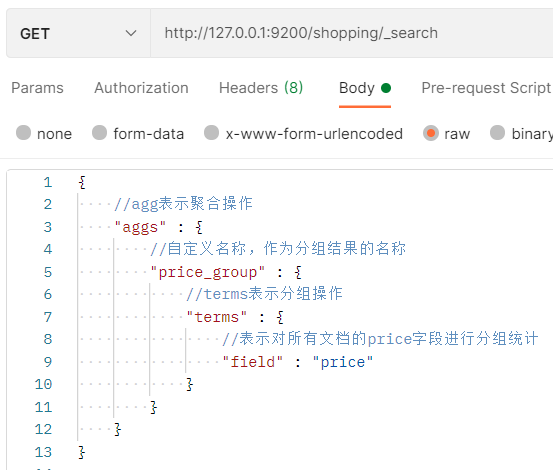
Query results:
"aggregations": {
//Custom grouping result name
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
//Indicates that the number of documents with a price of 2503.3 is 2
{
"key": 2503.3,
"doc_count": 2
},
//Indicates that the number of documents with a price of 3999.0 is 1
{
"key": 3999.0,
"doc_count": 1
}
]
}
}
Example of averaging:
Request body:
{
//agg indicates aggregation operation
"aggs" : {
//Custom name as the name of the result
"price_avg" : {
//avg means average operation
"avg" : {
//Indicates that the price field of all documents is averaged
"field" : "price"
}
}
},
//Only the average results are displayed, not all document details
"size" : 0
}
Query results:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
//The specific content of the document is not displayed. If size=0 is not used, all the specific content of the document will be displayed here
"hits": []
},
"aggregations": {
//Custom name
"price_avg": {
//Average results
"value": 3001.90673828125
}
}
}
3.3. 9 mapping relationship
Text types can be partially matched for full-text retrieval, while K-V types can only be fully matched.
1. Create user index
http://127.0.0.1:9200/user
2. Define the mapping type of the field
Requests sent:

Request body carried:
{
//Set mapping relationship
"properties" : {
//The type of the name field is text, and this field can use an index
"name" : {
"type" : "text",
"index" : true
},
//The type of the sex field is K-V, and this field can use an index
"sex" : {
"type" : "keyword",
"index" : true
},
//The type of the sex field is K-V, and this field cannot use an index
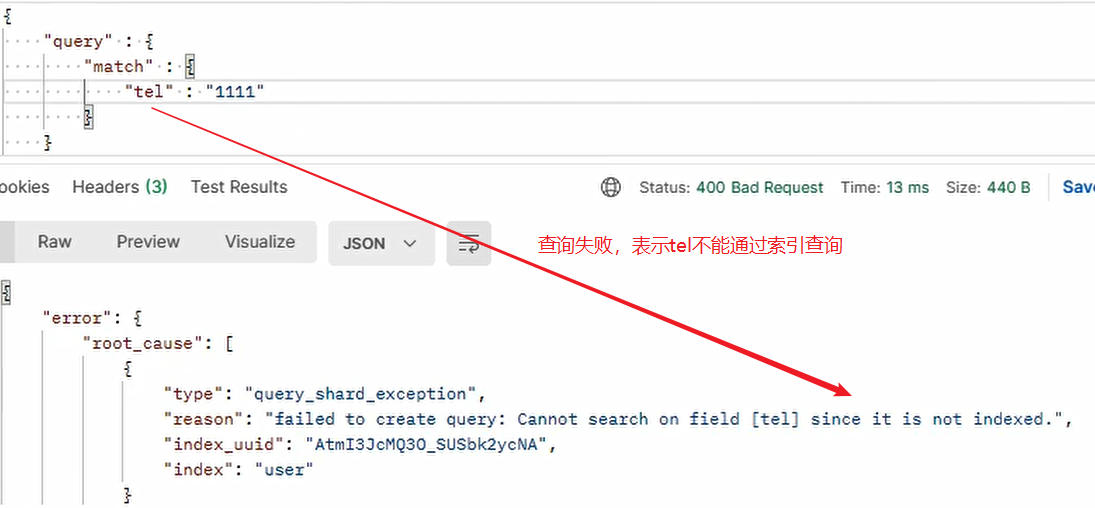
"tel" : {
"type" : "keyword",
"index" : false
}
}
}
3. Create a document
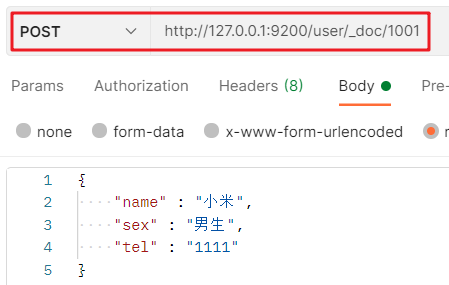
4. Query field values
Case 1:
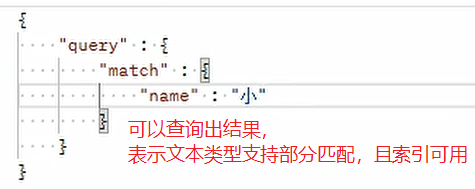
Case 2:
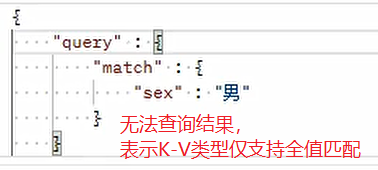
Case 3: