Video directions 👉 Station B dark horse micro service Super recommended!!
Getting to know Elasticsearch
1. Understand ES
- Elastic search is a very powerful open source search engine with many powerful functions, which can help us quickly find the content we need from massive data
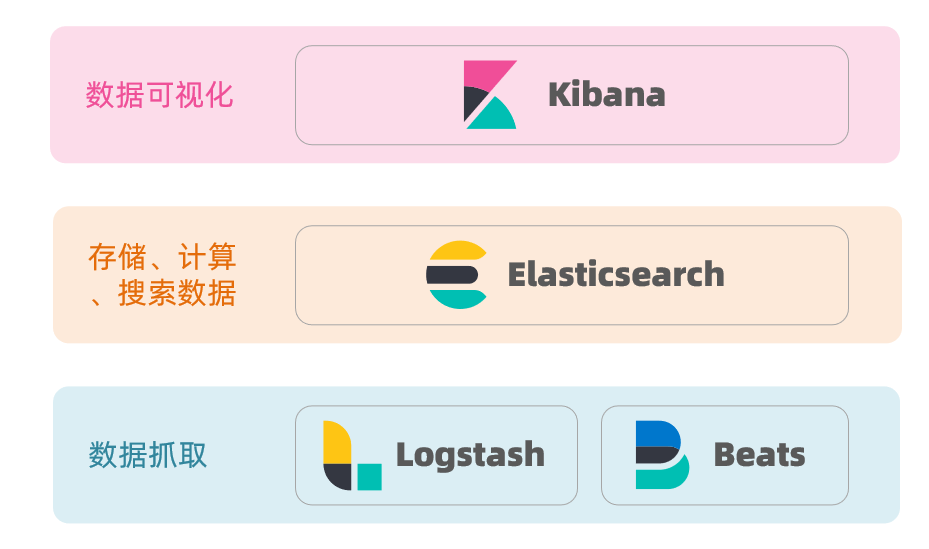
- Elastic search combines kibana, Logstash and Beats, that is, elastic stack (ELK). It is widely used in log data analysis, real-time monitoring and other fields
- Elastic search is the core of elastic stack, which is responsible for storing, searching and analyzing data
2. Inverted index
2.1 forward index
The concept of inverted index is based on forward indexes such as MySQL
So what is a forward index? For example, create an index for the id in the following table (tb_goods):
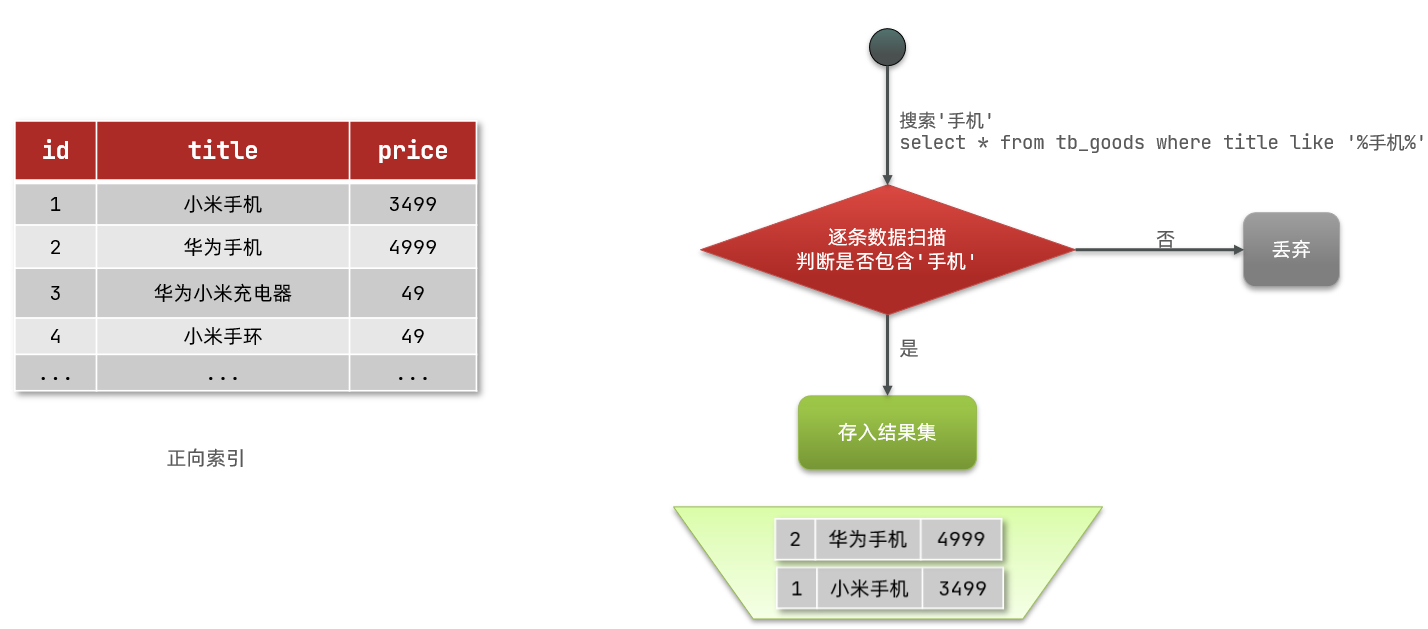
If the query is based on id, the index is directly used, and the query speed is very fast.
However, if the fuzzy query is based on the title, the data can only be scanned line by line. The process is as follows:
- Users search for data if the title matches "% mobile%"
- Get data line by line, such as data with id 1
- Judge whether the title in the data meets the user search criteria
- If yes, it will be put into the result set, and if not, it will be discarded. Then return to step 1
Progressive scanning, that is, full table scanning, will reduce the query efficiency as the amount of data increases. When the amount of data reaches millions, it is...
2.2 inverted index
There are two very important concepts in inverted index:
- Document: data used to search. Each piece of data is a document. For example, a web page, a product information
- Term: for document data or user search data, use some algorithm to segment words, and the words with meaning are terms. For example, if I am Chinese, I can be divided into several terms: I, yes, Chinese, Chinese and Chinese
Creating inverted index is a special process for forward index. The process is as follows:
- The data of each document is segmented by the algorithm to get each entry
- Create a table. Each row of data includes the entry, the document id where the entry is located, the location and other information
- Because entries are unique, you can create indexes for entries, such as hash table knots
For example, chestnuts:
As shown in the figure:

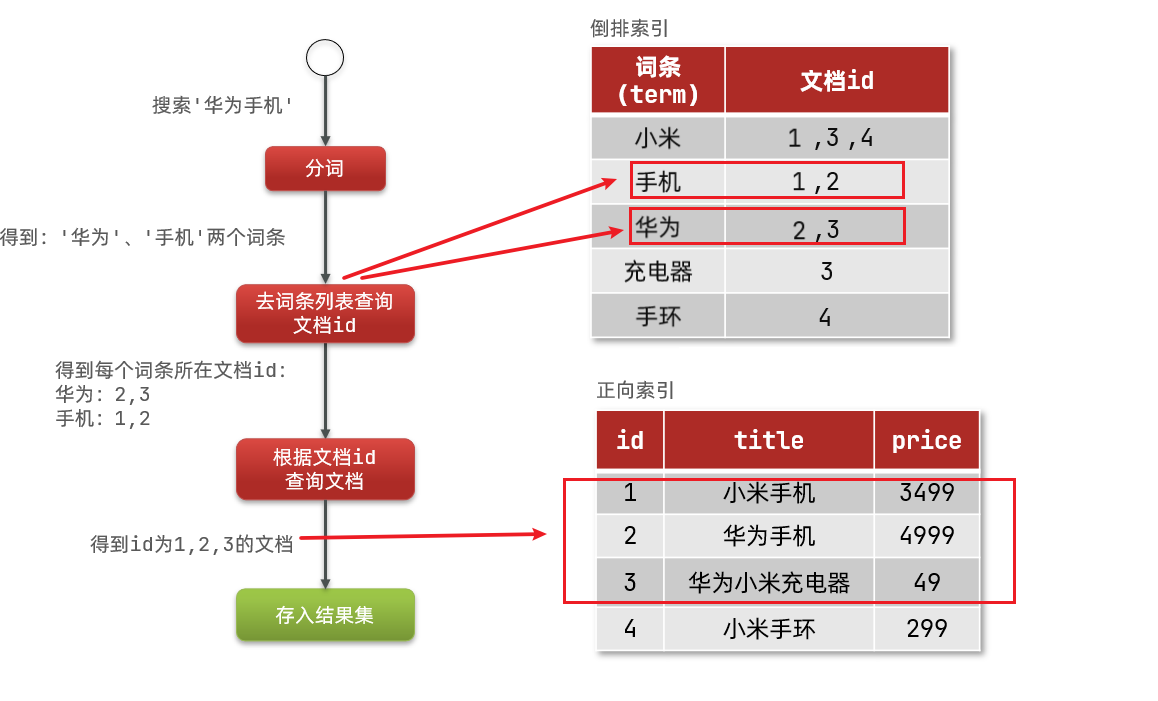
The search process of inverted index is as follows (take the search of "Huawei mobile phone" as an example):
1) The user enters the condition "Huawei mobile phone" to search.
2) Segment the user's input content to get the entry: Huawei and mobile phone.
3) Take the entry and look it up in the inverted index to get the document id containing the entry: 1, 2 and 3.
4) Take the document id to the forward index to find the specific document.
As shown in the figure:
Although it is necessary to query the inverted index first and then the inverted index, the index is established for both terms and document id, and the query speed is very fast! Full table scanning is not required.
2.3 forward and reverse
So why is one called forward index and the other called inverted index?
- Forward indexing is the most traditional way of indexing according to id. However, when querying according to terms, you must first obtain each document one by one, and then judge whether the document contains the required terms. It is the process of finding terms according to the document.
- On the contrary, the inverted index first finds the term that the user wants to search, obtains the id of the document protecting the term according to the term, and then obtains the document according to the id. It is the process of finding documents according to entries.
Advantages and disadvantages of forward index and inverted index:
Forward index:
- advantage:
- Multiple fields can be indexed
- Searching and sorting according to index fields is very fast
- Disadvantages:
- When searching according to non index fields or some entries in index fields, you can only scan the whole table.
Inverted index:
- advantage:
- According to the entry search, fuzzy search, the speed is very fast
- Disadvantages:
- Only entries can be indexed, not fields
- Cannot sort by field
3. Some concepts of ES
3.1 documents and fields
Elasticsearch is stored for * * Document * *. It can be a piece of product data and an order information in the database. The Document data will be serialized into json format and stored in elasticsearch:

JSON documents often contain many fields, similar to columns in the database.
3.2 indexing and mapping
An Index is a collection of documents of the same type.
For example:
- All user documents can be organized together, which is called the user's index;
- The documents of all commodities can be organized together, which is called the index of commodities;
- The documents of all orders can be organized together, which is called the order index;

Therefore, we can treat the index as a table in the database.
The database table will have constraint information, which is used to define the table structure, field name, type and other information. Therefore, there is mapping in the index library, which is the field constraint information of the document in the index, similar to the structure constraint of the table.
3.3 mysql and elasticsearch
| MySQL | Elasticsearch | explain |
|---|---|---|
| Table | Index | An index is a collection of documents, similar to a database table |
| Row | Document | Documents are pieces of data, similar to rows in a database. Documents are in JSON format |
| Column | Field | A Field is a Field in a JSON document, similar to a Column in a database |
| Schema | Mapping | Mapping is a constraint on documents in the index, such as field type constraints. Table structure similar to database (Schema) |
| SQL | DSL | DSL is a JSON style request statement provided by elasticsearch. It is used to operate elasticsearch and implement CRUD |
- Mysql: good at transaction type operation, which can ensure data security and consistency
- Elastic search: good at searching, analyzing and calculating massive data
Therefore, in enterprises, the two are often used in combination:
- Write operations requiring high security are implemented using MySQL
- The search requirements with high query performance are implemented by ELasticsearch
- Based on some way, the two can realize data synchronization and ensure consistency

4. Install Elasticsearch, kibana and IK word breakers
4.1 deploy single point Elasticsearch
Because we also need to deploy kibana containers, we need to interconnect es and kibana containers. Here, first create a network:
docker network create es-net
Method 1: you can directly pull (the speed is slow)
Method 2: use the tar package of the provided image
Here, we use the 7.12.1 image of elastic search, which is very large and close to 1G. It is not recommended that you pull yourself.
Here is method 2. You can upload it to the virtual machine, and then run the command to load it:
# Import data docker load -i es.tar
Similarly, kibana's tar package needs to do the same.
Run the docker command to deploy a single point es:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
Command interpretation:
- -E "cluster. Name = es docker cluster": set the cluster name
- -e "http.host=0.0.0.0": the monitored address can be accessed from the Internet
- -e "ES_JAVA_OPTS=-Xms512m -Xmx512m": memory size
- -E "discovery. Type = single node": non cluster mode
- -V es data: / usr / share / elasticsearch / data: mount the logical volume and bind the data directory of ES
- -V es logs: / usr / share / elasticsearch / logs: mount the logical volume and bind the log directory of ES
- -V es plugins: / usr / share / elasticsearch / plugins: mount the logical volume and bind the plug-in directory of ES
- --privileged: granted access to the logical volume
- --Network es net: join a network called es net
- -p 9200:9200: port mapping configuration
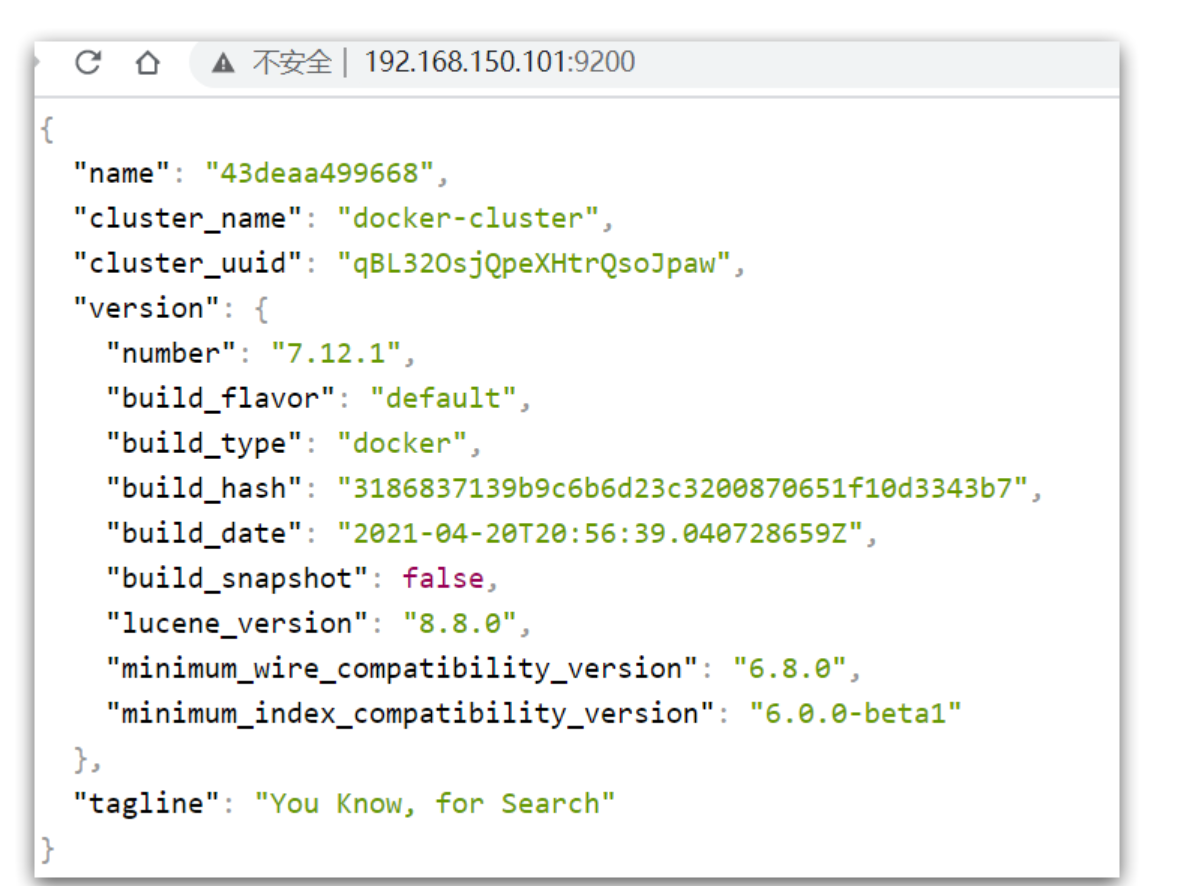
Enter in the browser: http://192.168.150.101:9200 (you need to change the ip address of your virtual machine) you can see the response result of elasticsearch:
4.2 deploying kibana
Run the docker command to deploy kibana:
docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.12.1
Command interpretation:
- --Network es net: join a network called es net, which is in the same network as elastic search
- -e ELASTICSEARCH_HOSTS=http://es:9200 ": set the address of elasticsearch. Because kibana is already on the same network as elasticsearch, you can directly access elasticsearch with the container name
- -p 5601:5601: port mapping configuration
At this point, enter the address in the browser to access: http://192.168.150.101:5601 , you can see the results
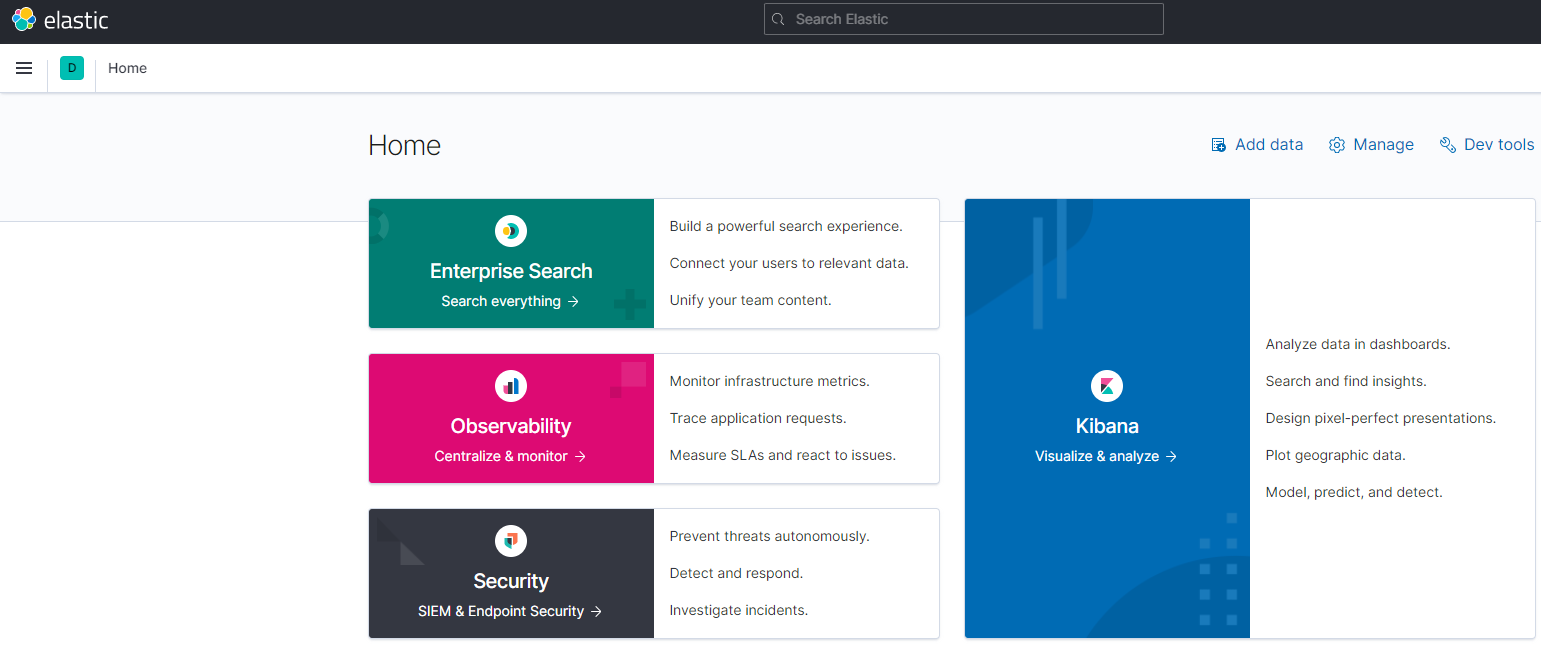
4.3 installing IK word splitter
Install the IK plug-in online (slower):
# Enter the inside of the container docker exec -it elasticsearch /bin/bash # Download and install online ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip #sign out exit #Restart container docker restart elasticsearch
Here is a demonstration of installing the iK plug-in offline:
To view the data volume Directory:
To install the plug-in, you need to know the location of the plugins directory of elasticsearch, and we use the data volume mount. Therefore, you need to view the data volume directory of elasticsearch through the following command:
docker volume inspect es-plugins
Display results:
[
{
"CreatedAt": "2022-05-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
Note the plugins directory is mounted in the: / var / lib / docker / volumes / es plugins / _datadirectory.
Upload the prepared folder to the plug-in data volume of the es container:
That is, / var / lib / docker / volumes / es plugins / _data:
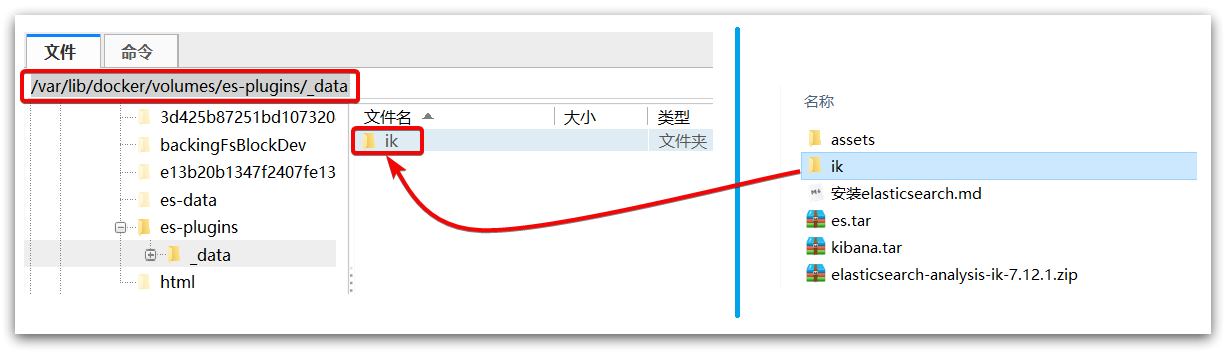
Restart container:
docker restart es
The IK word breaker contains two modes:
- ik_smart: intelligent segmentation, coarse granularity
- ik_max_word: thinnest segmentation, fine granularity
We tested it on the Kibana console above
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "Dark horse programmer learning java fantastic"
}
result:
{
"tokens" : [
{
"token" : "dark horse",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "programmer",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "program",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "member",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "study",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 5
},
{
"token" : "fantastic",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "Great",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "Yes",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
}
]
}
5. Expand and deactivate Dictionaries
5.1 extended dictionary
With the development of the Internet, "word making movement" is becoming more and more frequent. There are many new words that do not exist in the original vocabulary list, such as "aoligai", "wisdom podcast", etc.
Therefore, our vocabulary also needs to be constantly updated. IK word splitter provides the function of expanding vocabulary.
1) Open the IK word splitter config Directory:
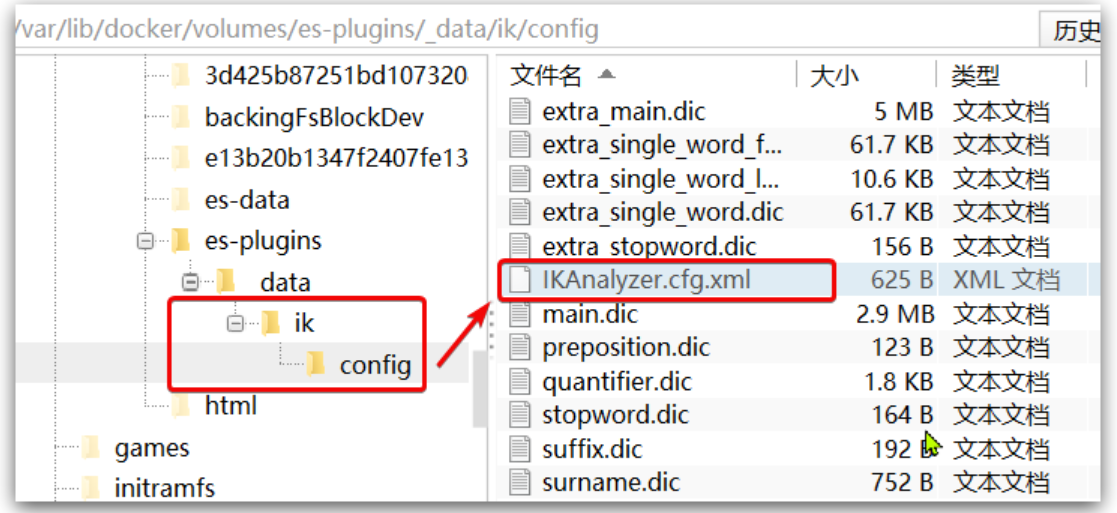
2) In the IKAnalyzer.cfg.xml configuration file, add:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here *** Add extended dictionary-->
<entry key="ext_dict">ext.dic</entry>
</properties>
3) Create a new ext.dic. You can copy a configuration file under the config directory for modification
Intelligence Podcast awesome
4) Restart elasticsearch
docker restart es
The ext.dic configuration file has been successfully loaded in the log
5) Test effect:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "Intelligence Podcast Java Employment over 90%,awesome"
}
5.2 disable dictionary
In Internet projects, the transmission speed between networks is very fast, so many languages are not allowed to be transmitted on the network, such as sensitive words such as religion and politics, so we should also ignore the current words when searching.
The IK word splitter also provides a powerful stop word function, allowing us to directly ignore the contents of the current stop vocabulary when indexing.
1) Add the contents of IKAnalyzer.cfg.xml configuration file:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here-->
<entry key="ext_dict">ext.dic</entry>
<!--Users can configure their own extended stop word dictionary here *** Add stop word dictionary-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>
3) Add a stop word in stopword.dic
xxx
4) Restart elasticsearch
# Restart service docker restart elasticsearch docker restart kibana # View log docker logs -f elasticsearch
The stopword.dic configuration file has been successfully loaded in the log
5) Test effect:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "Intelligence Podcast Java The employment rate exceeds 95%%,xxx Like everything,awesome"
}
Last favorite little partner, remember the third company! 😏🍭😘