Learning Video: Getting Started with ElasticSearch (based on ELK technology stack elasticsearch version 7.8.x)
Learning Outline:
- Chapter 1 Overview of Elasticsearch
- Chapter 2 Introduction to Elasticsearch
- Chapter 3 Elasticsearch Environment
- Chapter 4 Elasticsearch Advancements
- Chapter 5 Elasticsearch Integration
- Chapter 6 Elasticsearch Optimization
- Chapter 7 Elasticsearch Interview Questions
Chapter 1 Overview of ElasticSearch
Structured data:
 Unstructured data:
Unstructured data:
Semi-structured data:
Technical Selection
What is Elasticsearch
The Elastic Stack includes Elastic search, Kibana, Beats, and Logstash (also known as ELK Stack). Can safely and reliably obtain data from any source, in any format, and then search, analyze, and visualize the data in real time.
Elaticsearch, short for ES, is an open source, highly scalable, distributed full-text search engine and the core of the entire ElasticStack technology stack.
It can store and retrieve data in almost real time. It is very scalable and can be extended to hundreds of servers to handle PB-level data.
Full Text Search Engine
Google, Baidu type of website search, are based on the keywords in the page to generate an index, we enter keywords when searching, they will return that keyword, that is, all the pages to which the index matches; There are also common projects where log searches are used, and so on. For these unstructured data texts, relational database search is not very well supported.
In general, traditional databases, full-text retrieval is a chicken rib because no one uses the database to store text fields. Full-text retrieval requires scanning the entire table, and even SQL syntax optimization will have little effect if there is a large amount of data. Indexes are built, but maintenance can be cumbersome, and they are rebuilt for insert and update operations.
Based on the above reasons, it can be concluded that in some production environments, performance is very poor using the conventional search method:
- The data object searched is a large amount of unstructured text data.
- File records reach hundreds of thousands or millions or more.
- Supports a large number of queries based on interactive text.
- Full-text search queries with very flexible requirements.
- There are special requirements for highly relevant search results, but no relational database is available to satisfy them.
- Relatively low demand for different record types, non-text data operations, or secure transaction processing. To solve the performance problems of structured data search and non-structured data search, we need a professional, robust and powerful full-text search engine.
The full-text search engine mentioned here refers to the mainstream search engine currently widely used. It works by a computer indexer that scans every word in an article to create an index on each word, indicating the number and location of the word in the article. When a user queries, the retrieval program searches based on a pre-established index and feeds the results back to the user's retrieval method. This process is similar to retrieving a word list from a dictionary.
Elasticsearch application case
- GitHub: In early 2013, Solr was abandoned and Elasticsearch was used for PB-level searches. "GitHub uses Elasticsearch to search 20TB of data, including 1.3 billion files and 13 billion lines of code."
- Wikipedia: Start a core search architecture based on Elasticsearch
- Baidu: Elasticsearch is currently widely used as text data analysis, collecting all kinds of index data and user-defined data on all servers in Baidu, through multidimensional analysis and display of various data, to assist in locating and analyzing instance anomalies or business-level anomalies. At present, it covers more than 20 lines of business (including cloud analysis, networking federation, forecasting, library, direct number, wallet, wind control, etc.) inside Baidu, with a single cluster of up to 100 machines and 200 ES nodes, importing 30TB+ data every day.
- Sina: Use Elasticsearch analysis to process 3.2 billion real-time logs.
- Ali: Use Elasticsearch to build a log collection and analysis system.
- Stack Overflow: A website for Bug solving, a website for programmers to communicate in English.
Chapter 2 Introduction to ElasticSearch
Environmental preparation
Elastic website: Open Source Search: Developers of Elasticsearch, ELK Stack, and Kibana | Elastic
ElasticSearch mirror download address: https://mirrors.huaweicloud.com/elasticsearch/
The Windows version of the Elasticsearch package is decompressed and installed. The directory structure of the decompressed Elasticsearch is as follows:
| Catalog | Meaning |
|---|---|
| bin | Executable Script Directory |
| config | configure directory |
| jdk | Built-in JDK directory |
| lib | class libraries |
| logs | Log Directory |
| modules | Module Directory |
| plugins | Plug-in Directory |
After unzipping, go to the bin file directory and click elasticsearch. The bat file starts the ES service.
Port 9300 is the communication port for components between Elasticsearch clusters and port 9200 is the http protocol RESTful port accessed by browsers.
Open the browser and enter the address: http://localhost:9200 , the test returns the results as follows:
Here are the results from the Mac computer
{
"name": "air.local",
"cluster_name": "elasticsearch",
"cluster_uuid": "Zf7_bFjkSC6COYPBgeybTw",
"version": {
"number": "7.8.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date": "2020-06-14T19:35:50.234439Z",
"build_snapshot": false,
"lucene_version": "8.5.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
RESTful & JSON
REST refers to a set of architectural constraints and principles. Applications or designs that meet these constraints and principles are RESTful.
A few things to know:
- POST is not idempotent, PUT is idempotent. POST is created, PUT is updated.
RESTFul is an abstract concept that needs to be understood. It is recommended that you consult more relevant materials to further understand it.
JSON: JavaScript Object Notation (JavaScript Object Representation)
- JSON is a syntax for storing and exchanging text information, similar to XML.
- JSON is smaller, faster, and easier to parse than XML.
{
"sites": [
{ "name":"Baidu" , "url":"www.baidu.com" },
{ "name":"google" , "url":"www.google.com" },
{ "name":"micro-blog" , "url":"www.weibo.com" }
]
}
Postman / ApiPost
If you send requests directly to the Elasticsearch server through a browser, you need to include HTTP-standard methods in the requests you send, while most of the features of HTTP only support GET and POST methods. Therefore, in order to facilitate client access, you can use Postman software.
Postman is a powerful web debugging tool that provides powerful web APIs and HTTP request debugging.
Also recommended: ApiPost - API Documentation, Debugging, Mock, Testing Integrated Collaboration Platform
Both of these tools will be used later when we send requests to the ES server.
Index operation
Inverted Index (Understanding)
Forward row index (traditional):
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
Inverted index:
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
Elasticsearch is a document-oriented database where a data is a document.
For ease of understanding, compare the concept of storing document data in Elasticsearch with that of MySQL, a relational database:
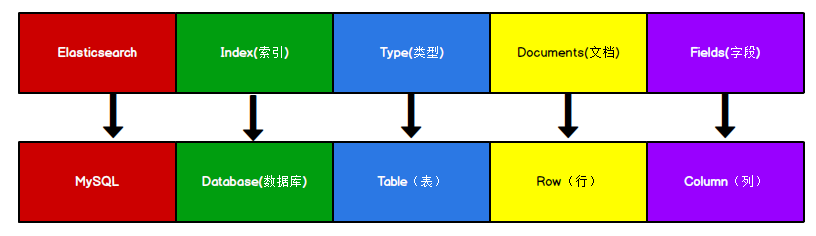
The concept of Type has been gradually weakened:
- Elasticsearch 6.X, can already contain only one type under an index
- Elasticsearch 7. In X, the concept of Type has been deleted.
Create Index - PUT
Comparing relational databases, creating an index is equivalent to creating a database.
In ApiPost, make a PUT request to the ES server: http://127.0.0.1:9200/shopping
After the request, the server returns a response:
{
"acknowledged": true, // Response results
"shards_acknowledged": true, // Fragmentation results
"index": "shopping" // Index Name
}
Background log:
[2022-03-09T21:41:00,928][INFO ][o.e.c.m.MetadataCreateIndexService] [air.local] [shopping] creating index, cause [api], templates [], shards [1]/[1], mappings
If a PUT request is repeated: http://127.0.0.1:9200/shopping Adding an index returns an error message:
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [shopping/8g4CcOYrRneyo-XSmAFs1Q] already exists",
"index_uuid": "8g4CcOYrRneyo-XSmAFs1Q",
"index": "shopping"
}
],
"type": "resource_already_exists_exception",
"reason": "index [shopping/8g4CcOYrRneyo-XSmAFs1Q] already exists",
"index_uuid": "8g4CcOYrRneyo-XSmAFs1Q",
"index": "shopping"
},
"status": 400
}
Query Single Index - GET
Send GET requests to the ES server: http://127.0.0.1:9200/shopping
{
"shopping": { // Index Name
"aliases": {}, // alias
"mappings": {}, // mapping
"settings": { // Set up
"index": { // Settings-Index
"creation_date": "1617861426847", // Setup-Index-Creation Time
"number_of_shards": "1", // Settings-Index-Number of Primary Slices
"number_of_replicas": "1", // Settings-Index-Number of Primary Slices
"uuid": "J0WlEhh4R7aDrfIc3AkwWQ", // Settings-Index-Number of Primary Slices
"version": { // Settings-Index-Number of Primary Slices
"created": "7080099"
},
"provided_name": "shopping" // Settings-Index-Number of Primary Slices
}
}
}
}
Query all indexes - GET
Send GET requests to the ES server: http://127.0.0.1:9200/_cat/indices?v](http://127.0.0.1:9200/_cat/indices?v)
_in Request Path cat means view, indices means index, so the whole meaning is to look at all the indexes in the current ES server, just like SHOW TABLES in MySQL. The server responds as follows:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open shopping 8g4CcOYrRneyo-XSmAFs1Q 1 1 0 0 208b 208b
| surface | Meaning |
|---|---|
| health | Current server health: green (complete cluster) yellow (single normal, incomplete cluster) red (single abnormal) |
| status | Index Open and Close Status |
| index | Index Name |
| uuid | Index Uniform Number |
| pri | Number of main slices |
| rep | Number of copies |
| docs.count | Number of Documents Available |
| docs.deleted | Document Deletion Status (Logical Deletion) |
| store.size | The overall size of the main and sub-slices |
| pri.store.size | Space occupied by main slice |
Delete Index - DELETE
Send a DELETE request to the ES server: http://127.0.0.1:9200/shopping
The results are as follows:
{
"acknowledged": true
}
View all indexes again, GET http://127.0.0.1:9200/_cat/indices?v And returns the following results:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
Document Basic Operations
Create Document - POST
Assuming the index is created, let's create the document and add the data.
Documents here can be analogous to table data in a relational database, and the data added is in JSON format.
Content-Type Select application/json
Send a POST request to the ES server: http://127.0.0.1:9200/shopping/_doc , the content of the request body JSON is:
{
"title":"Mi phones",
"category":"millet",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
Note that requests must be sent here as POST, not PUT, or an error will occur.
{
"_index": "shopping", // Indexes
"_type": "_doc", // Type-Document
"_id": "ANQqsHgBaKNfVnMbhZYU", // Unique identifier, which can be analogous to the primary key in MySQL, randomly generated
"_version": 1, // Edition
"result": "created", // As a result, create here indicates success
"_shards": { // Slicing
"total": 2, // Fragmentation-Total
"successful": 1, // Fragmentation-Total
"failed": 0 // Fragmentation-Total
},
"_seq_no": 0,
"_primary_term": 1
}
After the above data is created, since no data uniqueness identifier (ID) is specified, by default, the ES server randomly generates one.
If you want to customize the unique identity, you need to specify at creation time: http://127.0.0.1:9200/shopping/_doc/1001 , Requestor JSON:
{
"title":"Mi phones",
"category":"millet",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
Return results:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001", // Custom Unique Identification
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
If you specify the data primary key when adding data, the request can also be PUT, not POST.
Primary Key Query - GET
When viewing a document, you need to indicate its unique identity, similar to the primary key query for data in MySQL.
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_doc/1001
The results are as follows:
This query can only query one data.
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 4,
"_seq_no": 6,
"_primary_term": 1,
"found": true,
"_source": {
"title": "Mi phones",
"category": "millet",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
Query a non-existent data and make a GET request to the ES server: http://127.0.0.1:9200/shopping/_doc/1111
The results are as follows:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1111",
"found": false
}
Full Query - GET
View all the data under the index and make a GET request to the ES server: http://127.0.0.1:9200/shopping/_search
The results are as follows:
{
"took": 133,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "AlsTb38BaAVJP39iKv8b",
"_score": 1,
"_source": {
"title": "Mi phones",
"category": "millet",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "Mi phones",
"category": "millet",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"title": "Mi phones",
"category": "millet",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
Full Modification - PUT
Since the result is idempotent, you can use PUT
As with new documents, enter the same URL address request, and if the body of the request changes, the original data content will be overwritten (all information).
Send a POST request to the ES server: http://127.0.0.1:9200/shopping/_doc/1001
The content of the request body is: (All information will be overwritten)
{
"title":"Huawei Mobile Phone",
"category":"Huawei",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":1999.00
}
After successful modification, the server responds to the result:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 5,
"result": "updated", // Data Updated
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1
}
Local Modification - POST
POST is used because it is a local modification and power cannot be guaranteed.
When modifying data, you can also modify only the local information of a given data.
Send a POST request to the ES server: http://127.0.0.1:9200/shopping/_update/1001
JSON of the requester: (only local information will be modified)
{
"doc": {
"title":"Mi phones",
"category":"millet"
}
}
Return results:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 6,
"result": "updated", // Data Updated
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 1
}
Delete - DELETE
Deleting a document does not immediately remove it from disk; it is simply marked as deleted (logical deletion).
Send a DELETE request to the ES server: http://127.0.0.1:9200/shopping/_doc/1001
Return results:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 7,
"result": "deleted", // Delete succeeded
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1
}
Document Query Operation - GET
Conditional Query
URL parameterized query
Example: Find a document where category is millet
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search?q=category: millet
_ search?q=key:value means query as key, value
URL s are queried in the form of parameters, which can easily make the bad person malicious or the parameter values appear in Chinese. To avoid these situations, queries can be made using body requests with JSON.
Query with Request Body
Example: Find a document where category is millet
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"query":{
"match":{
"category":"millet"
}
}
}
Find All Content with Request Body
Example: Query all document contents.
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"query":{
"match_all":{}
}
}
Paging Query
Example: There are 2 pieces of data per page, querying the contents of page 1.
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"query":{
"match_all":{}
},
"from":0,
"size":2
}
Query Sorting
Example: Find the most expensive phone by sorting.
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"query":{
"match_all":{}
},
"sort":{
"price":{
"order":"desc"
}
}
}
Multi-Conditional Query
Example: Find out the millet mobile phone, and the price is 3999 yuan.
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
must is equivalent to & operation
{
"query":{
"bool":{
"must":[{
"match":{
"category":"millet"
}
},{
"match":{
"price":3999.00
}
}]
}
}
}
Example: Find out millet or Huawei brand mobile phones.
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
should equals || operation
{
"query":{
"bool":{
"should":[{
"match":{
"category":"millet"
}
},{
"match":{
"category":"Huawei"
}
}]
}
}
}
Range Query
MARK: There is a problem with this query!!!!!!
Example: Find a brand of millet or Huawei that costs more than 2000.
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"query":{
"bool":{
"should":[{
"match":{
"category":"millet"
}
},{
"match":{
"category":"Huawei"
}
}],
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
}
Full Text Retrieval
match is a fuzzy query after splitting.
Example: Like the search engine, such as brand input "Xiaohua", return the results back to the brand with "millet" and "Huawei".
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"query":{
"match":{
"category" : "Xiaohua"
}
}
}
perfect match
match_phrase is a global fuzzy query.
Example: Input "Xiaohua" only matches "Xiaohua" related content, not "Xiaohua" and "Hua".
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"query":{
"match_phrase":{
"category" : "Xiaohua"
}
}
}
Highlight Query
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the JSON request body as follows
{
"query":{
"match":{
"category" : "millet"
}
},
"highlight":{
"fields":{
"category":{} // <--Highlight this field
}
}
}
Response results: Note the highlight field
{
"took": 98,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.9400072,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "AlsTb38BaAVJP39iKv8b",
"_score": 0.9400072,
"_source": {
"title": "Mi phones",
"category": "millet",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
},
"highlight": {
"category": [
"<em>Small</em><em>rice</em>"
]
}
}
]
}
}
Aggregate queries
Aggregation allows users to make statistical analysis of es documents, similar to GROUP BY in relational databases, but there are many other aggregations, such as Max max, avg mean, and so on.
Example: Grouping by price field
Send GET requests to the ES server: http://127.0.0.1:9200/shopping/_search , with the following JSON requests:
{
"aggs":{//Aggregation Operation
"price_group":{//Name, name freely
"terms":{//Grouping
"field":"price"//Grouping Fields
}
}
}
}
Response results:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "AlsTb38BaAVJP39iKv8b",
"_score": 1,
"_source": {
"title": "Mi phones",
"category": "millet",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "Mi phones",
"category": "millet",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"title": "IPhone",
"category": "Apple",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
}
]
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 3999,
"doc_count": 2
},
{
"key": 4999,
"doc_count": 1
}
]
}
}
}
The results returned above will be accompanied by the original data. If you want the results without the original data, the JSON request body is as follows:
{
"aggs":{
"price_group":{
"terms":{
"field":"price"
}
}
},
"size":0
}
Response results:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 3999,
"doc_count": 2
},
{
"key": 4999,
"doc_count": 1
}
]
}
}
}
Query Mapping
Having an index library is equivalent to having a database in the database.
Next, you need to build a map in the index, similar to the table structure in the database.
Creating a database table requires setting field names, types, lengths, constraints, and so on. The same is true for index libraries, which need to know what fields are under this type and what constraints each field has. This is called mapping.
Create an index:
# PUT http://127.0.0.1:9200/user
Create a map:
# PUT http://127.0.0.1:9200/user/_mapping
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "keyword", // Note that there is no ambiguous match
"index": true
},
"tel":{
"type": "keyword", // Note that there is no ambiguous match
"index": false // Note that errors will be reported when querying
}
}
}
Append data:
#PUT http://127.0.0.1:9200/user/_create/1001
{
"name":"millet",
"sex":"Male",
"tel":"1111"
}
Example: Query name contains "small" data: (results can be found)
#GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"name":"Small"
}
}
}
Example: Find data where sex contains "men": (No results found)
# GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"sex":"male"
}
}
}
- Find unwanted results because the type of "sex" when creating a map is keyword
- The keyword must match exactly, and "sex" can only be "male" to get the original data
Inquiry Phone:
# GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"tel":"11"
}
}
}
The results are as follows:
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "user",
"node": "4P7dIRfXSbezE5JTiuylew",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [tel] since it is not indexed."
}
}
}
]
},
"status": 400
}
The error was due to a false "index" for "tel" when creating the map.