Basic concepts
Index (index)
Saving a piece of data to elastic search is called indexing a piece of data
Type
In Index, you can define one or more types, which are similar to tables in MySQL. Each type of data is put together.
Document
A piece of data (Document) saved in a certain type under an index. In ES, each data is called a Document. The Document is in JSON format, and the Document is like the content saved in a Table in MySQL.
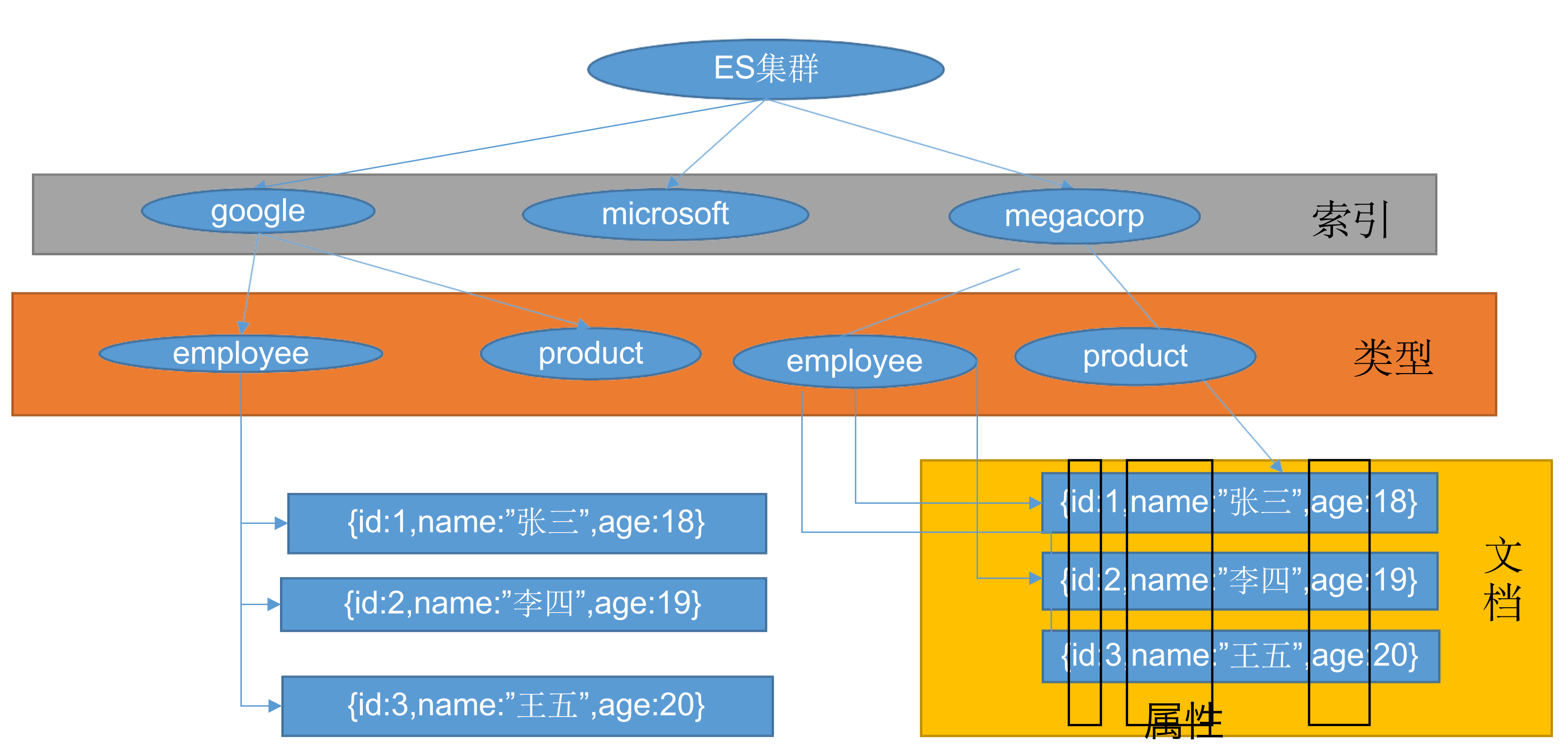
Inverted index
Docker installation ES, Kibana
Download Image File
docker pull elasticsearch:7.4.2 es Search Engines docker pull kibana:7.4.2 Visual retrieval data
Install ES
Create a config folder locally to store the ES configuration
mkdir ~/code/elasticsearch/config
Create a data folder to store ES data
mkdir ~/code/elasticsearch/data
Start ES with docker
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v ~/code/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v ~/code/elasticsearch/data:/usr/share/elasticsearch/data \ -v ~/code/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2
Access on Browser http://localhost:9200/ , if the following is displayed, the installation / startup is successful

Install Kibana
After Kibana is installed in docker, start it using docker run
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.21.133:9200 -p 5601:5601 \ -d kibana:7.4.2
Wait a moment and enter in the browser http://127.0.0.1:5601 Visit Kibana.
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-E8C5x89O-1640056227734)(elasticSearch learning notes. assets / screenshot 2021-12-19 10.53.12.png)]
Preliminary search
_cat
View all nodes
get /_cat/nodes
View es health
get /_cat/health
View master node
get /_cat/master
View all indexes
get /_cat/indices
Index a document
PUT
To save a piece of data, you need to specify an id. Under which type is saved in that index, a unique identifier is specified. If the same request is sent multiple times, it is regarded as an update operation by ES
Save a piece of data with "id" of 1 in the external type under the customer index
put customer/external/1
{"name": "Clover You"}
After sending the above request successfully, you will get the returned result:
{
"_index": "costomer",
"_type": "extenal",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
In the returned data, all are marked with "" All are called metadata, such as "_index"
- _ Index under which index is the currently inserted data
- _ Type under which type is the currently inserted data
- _ id the id of this data
- _ Version the version number of the current data
- Result current operation result
- created indicates new data
- updated means to modify the data
- noop no action
- _ shards slicing
POST
The method of POST is similar to that of PUT, except that the id can not be specified in POST. If you do not specify an id, an id is automatically generated. If you specify an id, the data of this id will be modified and the version number will be added.
post customer/external/1
{"name": "Clover You"}
consult your documentation
Querying documents using GET requests
get customer/external/1
{
"_index": "costomer",
"_type": "extenal",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "Clover You"
}
}
- _ Under which index is the document queried by index
- _ Under which type is the document queried by type
- _ id unique id of the queried document
- _ Version number of the version document
- _ seq_ The no concurrency control field will be + 1 every time it is updated, which is used as an optimistic lock
- _ primary_term and_ seq_ Like no, the main partition will be reassigned. If it is restarted, it will change
If you need an optimistic lock, you need to bring it_ seq_no and_ primary_term parameter:
put customer/external/1?if_seq_no=0&if_primary_term=1
Update document
In addition to using the POST and PUT methods described above to update the document, you can also use a special interface to update it. This operation will compare the old and new document metadata. If there is no change, it will not be updated.
post costomer/extenal/1/_update
{
"doc": {
"name": "new name"
}
}
remove document
Send a DELETE request to specify the index, type and unique ID to DELETE the specified document
delete costomer/extenal/1
Delete index
ES does not provide an interface for deleting types, but it provides an interface for deleting indexes
delete costomer
{
"acknowledged": true
}
Batch operation
ES provides a batch operation interface index/type/_bulk, this interface supports operations such as adding, modifying, deleting, etc. It needs to send a POST request, and the data format is as follows:
{"index": {"_id": 10}}
{"name": "Clover"}
{"index": {"_id": 11}}
{"name": "Clover You"}
The data of this interface needs two lines and a group. The first line is {"action, such as: add, modify, delete": {"_id": document unique ID}}, and the second line is the data to be operated, {"name": "Clover You"}
POST /costomer/extenal/_bulk
{"index": {"_id": 10}}
{"name": "Clover"}
{"index": {"_id": 11}}
{"name": "Clover You"}
{
"took" : 5,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "costomer",
"_type" : "extenal",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "costomer",
"_type" : "extenal",
"_id" : "11",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 201
}
}
]
}
- How many milliseconds did the took take to complete
- Errors are there any errors
- Each child of items corresponds to each operation. They are independent. Any operation error will not affect other operations.
Batch operation of the whole ES
Except index / type/_ In addition to the bulk interface, there is another_ The bulk interface can operate the entire ES
Its operation is similar to index / type/_ The operation of bulk is not very different
post /_bulk
{"index", {"_index": "costomer", "_type": "extenal", "_id": "123"}}
{"name": "clover"}
- _ Index specifies the index of the operation
- _ Type specifies the type of operation
- _ id document unique id
Advanced Search
SearchAPI
ES supports retrieval in two basic ways
-
One is to send search parameters by using the REST request URI
GET /bank/_search?q=*&sort=account_number:asc
-
The other is to send them by using the REST request body
GET /bank/_search { "query": { "match_all": {}, }, "sort": [ {"account_number": "asc"} ] }
Query DSL
ElasticSearch provides a JSON style DSL (domain specific language) that can execute queries. It is called Query DSL
// Basic grammar
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE
}
}
// If a field is targeted, its syntax:
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE
}
}
}
match full text retrieval
The full-text search is sorted according to the score, and the word segmentation matching of the search conditions will be carried out by using the to row index
GET /bank/_search
{
"query": {
"match": {
"address": "mill lane"
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 19,
"relation" : "eq"
},
"max_score" : 9.507477,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 9.507477,
"_source" : {
...
"address" : "198 Mill Lane",
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 5.4032025,
"_source" : {
...
"address" : "990 Mill Road",
}
},
...
]
}
}
match_phrase matching
The value to be matched is retrieved as a whole word (without word segmentation), which is consistent with like in MySQL
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "Mill Lane"
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 9.507477,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 9.507477,
"_source" : {
...
"address" : "198 Mill Lane",
}
}
]
}
}
multi_match multi field matching
Multiple fields can be retrieved using the row index
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill urie",
"fields": ["address", "city"]
}
}
}
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 6.505949,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 6.505949,
"_source" : {
...
"address" : "198 Mill Lane",
"city" : "Urie"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 5.4032025,
"_source" : {
...
"address" : "990 Mill Road",
"city" : "Lopezo"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 5.4032025,
"_source" : {
...
"address" : "715 Mill Avenue",
"city" : "Blackgum",
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "472",
"_score" : 5.4032025,
"_source" : {
"address" : "288 Mill Street",
"city" : "Movico",
}
}
]
}
}
bool compound query
If you need to use more complex queries, you can use bool queries, which can help us construct more complex queries. He can combine multiple query criteria
- must_not must not be a specified condition
- must meet the specified conditions
- should try to meet the specified conditions
GET /bank/_search
{
"query": {
"bool": {
"must":[
{
"match": {
"address": "Street"
}
}
],
"should": [
{
"match": {
"gender": "f"
}
}
]
}
}
}
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 385,
"relation" : "eq"
},
"max_score" : 1.661185,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "13",
"_score" : 1.661185,
"_source" : {
...
"gender" : "F",
"address" : "789 Madison Street",
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "32",
"_score" : 1.661185,
"_source" : {
"gender" : "F",
"address" : "702 Quentin Street"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "87",
"_score" : 0.95395315,
"_source" : {
...
"gender" : "M",
"address" : "446 Halleck Street"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "107",
"_score" : 0.95395315,
"_source" : {
...
"gender" : "M",
"address" : "694 Jefferson Street"
}
},
]
}
}
term retrieval
When retrieving precise fields, term is officially recommended. If it is not an exact field, term is not recommended. For example, a string may not be an exact field. Because ES uses word segmentation when saving documents
GET /bank/_search
{
"query": {
"term": {
"age": {
"value": 30
}
}
}
}
aggregations
Aggregation provides the ability to group and extract data from data. The simplest aggregation method is roughly equal to SQL GROUP BY and SQL aggregation function. In ES, you have the ability to perform a search and return hits (hit results) and aggregate results at the same time. You can separate all hits in a response. This is very powerful and effective. You can execute queries and multiple aggregations, get their (any) return results in one use, and use a concise and simplified API to avoid network roundtrip.
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
For example, search the age distribution and average age of all people with mill in address
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg": {
"avg": {
"field": "age"
}
}
}
}
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 5.4032025,
"hits" : [...]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
},
"ageAvg" : {
"value" : 34.0
}
}
}
Aggregate by age and request the average salary of these people in these age groups
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"ageAvg" : {
"value" : 28312.918032786885
}
},
{
"key" : 39,
"doc_count" : 60,
"ageAvg" : {
"value" : 25269.583333333332
}
},
{
"key" : 26,
"doc_count" : 59,
"ageAvg" : {
"value" : 23194.813559322032
}
},
{
"key" : 32,
"doc_count" : 52,
"ageAvg" : {
"value" : 23951.346153846152
}
},
{
"key" : 35,
"doc_count" : 52,
"ageAvg" : {
"value" : 22136.69230769231
}
},
{
"key" : 36,
"doc_count" : 52,
"ageAvg" : {
"value" : 22174.71153846154
}
},
{
"key" : 22,
"doc_count" : 51,
"ageAvg" : {
"value" : 24731.07843137255
}
},
{
"key" : 28,
"doc_count" : 51,
"ageAvg" : {
"value" : 28273.882352941175
}
},
{
"key" : 33,
"doc_count" : 50,
"ageAvg" : {
"value" : 25093.94
}
},
{
"key" : 34,
"doc_count" : 49,
"ageAvg" : {
"value" : 26809.95918367347
}
},
{
"key" : 30,
"doc_count" : 47,
"ageAvg" : {
"value" : 22841.106382978724
}
},
{
"key" : 21,
"doc_count" : 46,
"ageAvg" : {
"value" : 26981.434782608696
}
},
{
"key" : 40,
"doc_count" : 45,
"ageAvg" : {
"value" : 27183.17777777778
}
},
{
"key" : 20,
"doc_count" : 44,
"ageAvg" : {
"value" : 27741.227272727272
}
},
{
"key" : 23,
"doc_count" : 42,
"ageAvg" : {
"value" : 27314.214285714286
}
},
{
"key" : 24,
"doc_count" : 42,
"ageAvg" : {
"value" : 28519.04761904762
}
},
{
"key" : 25,
"doc_count" : 42,
"ageAvg" : {
"value" : 27445.214285714286
}
},
{
"key" : 37,
"doc_count" : 42,
"ageAvg" : {
"value" : 27022.261904761905
}
},
{
"key" : 27,
"doc_count" : 39,
"ageAvg" : {
"value" : 21471.871794871793
}
},
{
"key" : 38,
"doc_count" : 39,
"ageAvg" : {
"value" : 26187.17948717949
}
},
{
"key" : 29,
"doc_count" : 35,
"ageAvg" : {
"value" : 29483.14285714286
}
}
]
}
}
}
Find out all age distributions, and the average salary of M and F in these age groups, as well as the overall average salary of this age group
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
# Age distribution
"ageAgg": {
"terms": {
"field": "age",
"size": 2
},
"aggs": {
# Gender distribution by age
"genderAgg": {
"terms": {
"field": "gender.keyword",
"size": 2
},
"aggs": {
# Average wage per gender
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
# Average wage per age group
"ageBalanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
{
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 879,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M",
"doc_count" : 35,
"balanceAvg" : {
"value" : 29565.628571428573
}
},
{
"key" : "F",
"doc_count" : 26,
"balanceAvg" : {
"value" : 26626.576923076922
}
}
]
},
"ageBalanceAvg" : {
"value" : 28312.918032786885
}
},
{
"key" : 39,
"doc_count" : 60,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "F",
"doc_count" : 38,
"balanceAvg" : {
"value" : 26348.684210526317
}
},
{
"key" : "M",
"doc_count" : 22,
"balanceAvg" : {
"value" : 23405.68181818182
}
}
]
},
"ageBalanceAvg" : {
"value" : 25269.583333333332
}
}
]
}
}
}
Mapping
Mapping is used to define how documents are processed, that is, how they are retrieved and indexed. For example, we can customize:
- Which string fields should be treated as full-text search fields
- Which attribute contains numbers, dates, or geographic coordinates
- Formatting information for date
- You can use custom rules to control the mapping of dynamic fields
- Two data tables in a relational database are independent. Even if they have columns with the same name, they will not affect their use, but this is not the case in ES. ES is a search engine developed based on Lucene, and the final processing method of files with the same name under different type s in ES is the same in Lucene.
- Two users under two different types_ Name, under the same index of ES, is actually considered to be the same filed. You must define the same filed mapping in two different types. Otherwise, the same field names in different types will conflict in processing, resulting in the decrease of Lucene processing efficiency.
- ElasticSearch 7.x
- The type parameter in the URL is optional. For example, indexing a document no longer requires a document type.
- ElasticSearch 8.x
- The type parameter in the URL is no longer supported
- Solution: migrate the index from multi type to single type, and each type of document has an independent index
Create mapping
You can create a mapping rule when you create an index
PUT /my_index
{
"mappings": {
"properties": {
"age": {"type": "integer"},
"email": {"type": "keyword"},
"name": {"type": "text"}
}
}
}
Add new field mapping
PUT my_index/_mapping
{
"prope rties": {
"employee-id": {
"type": "long",
"index": false
}
}
}
- index specifies whether the field participates in retrieval. The default value is true
data migration
Existing mappings cannot be modified
If you need to migrate the data in the old index to the specified index, you can use_ reindex API, create the corresponding index first:
PUT newindex
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"email": {
"type": "keyword"
},
"employer": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"firstname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
Finally, send the specified request to migrate the data
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newindex"
}
}
- Source source data
- Index the index where the source data is located
- Type the type of the source data. If it is not available, it can be left blank
- dest target data
- Index target index
- Type is migrated to the specified type of the target index
participle
A tokenizer receives a character stream, divides it into independent tokens (word elements, usually independent words), and then outputs the tokens stream. When it encounters blank characters, it divides the text, and it will "Quick brown fox!" Split into [Quick, brown, fox!]. The tokenizer is also responsible for recording the order or position position position of each * * term (used for phrase and word proximity query), as well as the * * start * * and * * end * * character offsets of the original * * word * * represented by the term (character offset, used to highlight search content). ES provides many built-in word splitters, which can be used to build custom analyzers
POST _analyze
{
"analyzer": "standard",
"text": "hello world"
}
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "world",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}
ik participle
reach GitHub Install the corresponding version of ik word splitter in and unzip it to the plugins directory. Finally, restart ES
docker restart esid
IK provides two kinds of word splitters, namely ik_smart ,ik_max_word
Using ik in ik participle_ Smart, which can intelligently segment the specified text
ik_smart effect
POST _analyze
{
"analyzer": "ik_smart",
"text": "The sun rises from the East but falls to the West,The sea of acquaintances is scattered at the table"
}
{
"tokens" : [
{
"token" : "day",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "Out of",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "east",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "but",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "Fall on",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "west",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "Acquaintance",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "A sea of people",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "but",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "scattered",
"start_offset" : 14,
"end_offset" : 15,
"type" : "CN_CHAR",
"position" : 9
},
{
"token" : "to",
"start_offset" : 15,
"end_offset" : 16,
"type" : "CN_CHAR",
"position" : 10
},
{
"token" : "seat",
"start_offset" : 16,
"end_offset" : 17,
"type" : "CN_CHAR",
"position" : 11
}
]
}
ik_max_word effect
POST _analyze
{
"analyzer": "ik_max_word",
"text": "The sun rises from the East but falls to the West,The sea of acquaintances is scattered at the table"
}
{
"tokens" : [
{
"token" : "sunrise",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "Out of",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "east",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "but",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "Fall on",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "west",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "Acquaintance",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "A sea of people",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "but",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "scattered",
"start_offset" : 14,
"end_offset" : 15,
"type" : "CN_CHAR",
"position" : 9
},
{
"token" : "to",
"start_offset" : 15,
"end_offset" : 16,
"type" : "CN_CHAR",
"position" : 10
},
{
"token" : "seat",
"start_offset" : 16,
"end_offset" : 17,
"type" : "CN_CHAR",
"position" : 11
}
]
}
Custom extended Thesaurus
In ik participle configuration, modify elasticsearch / plugins / ik / config / ikanalyzer cfg. XML file
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer Extended configuration</comment> <!--Users can configure their own extended dictionary here --> <entry key="ext_dict"></entry> <!--Users can configure their own extended stop word dictionary here--> <entry key="ext_stopwords"></entry> <!--Users can configure the remote extension dictionary here --> <entry key="remote_ext_dict">http://192.168.21.133/es/fenci.txt</entry> <!--Users can configure the remote extended stop word dictionary here--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
Handle http://192.168.21.133/es/fenci.txt Change the location of your own thesaurus as follows:
online retailers Qiao Biluo Your highness giobilo
You can use nginx to deploy your thesaurus
After modification, restart ElasticSearch docker restart container_id
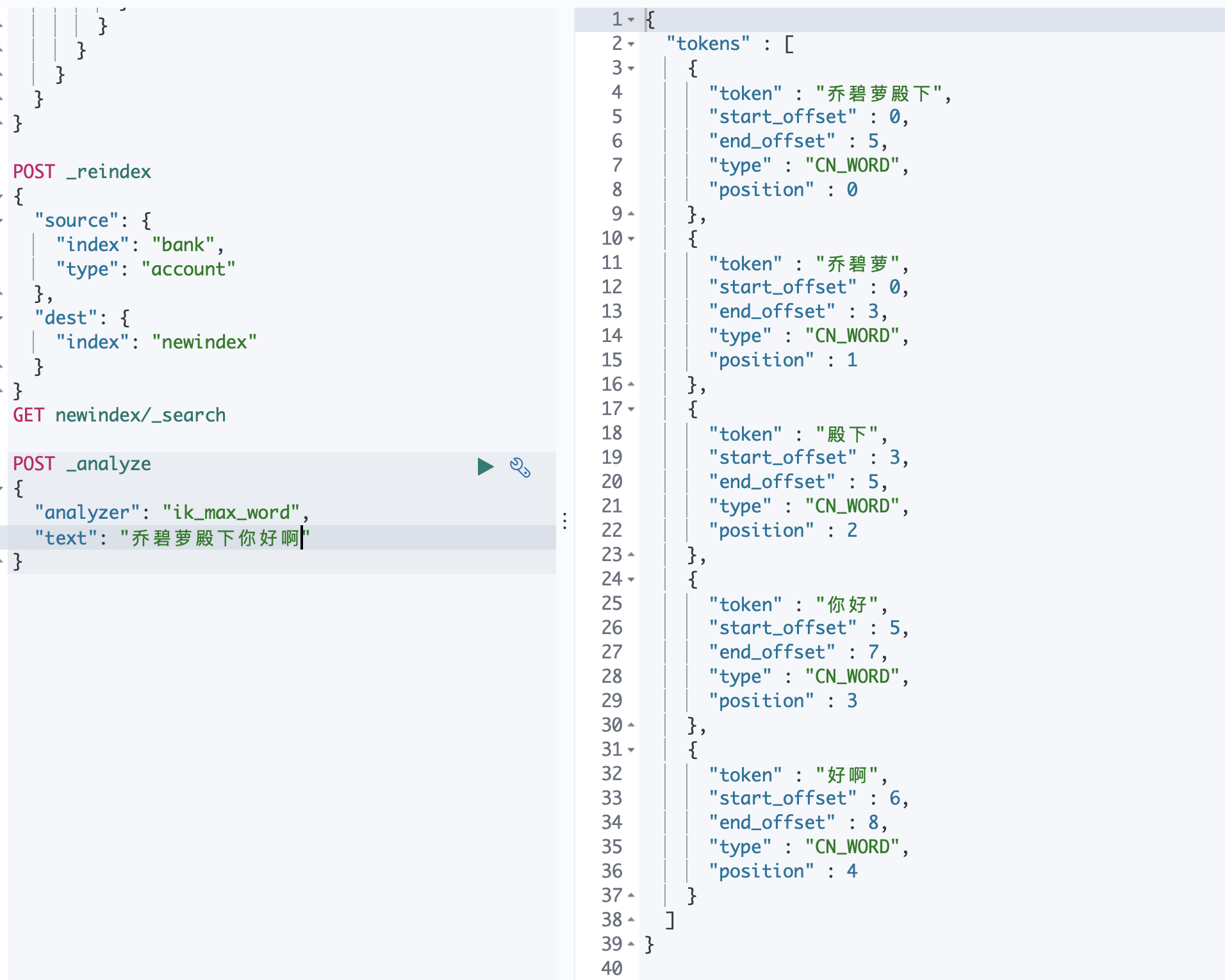
See the effect:
Before adding Thesaurus
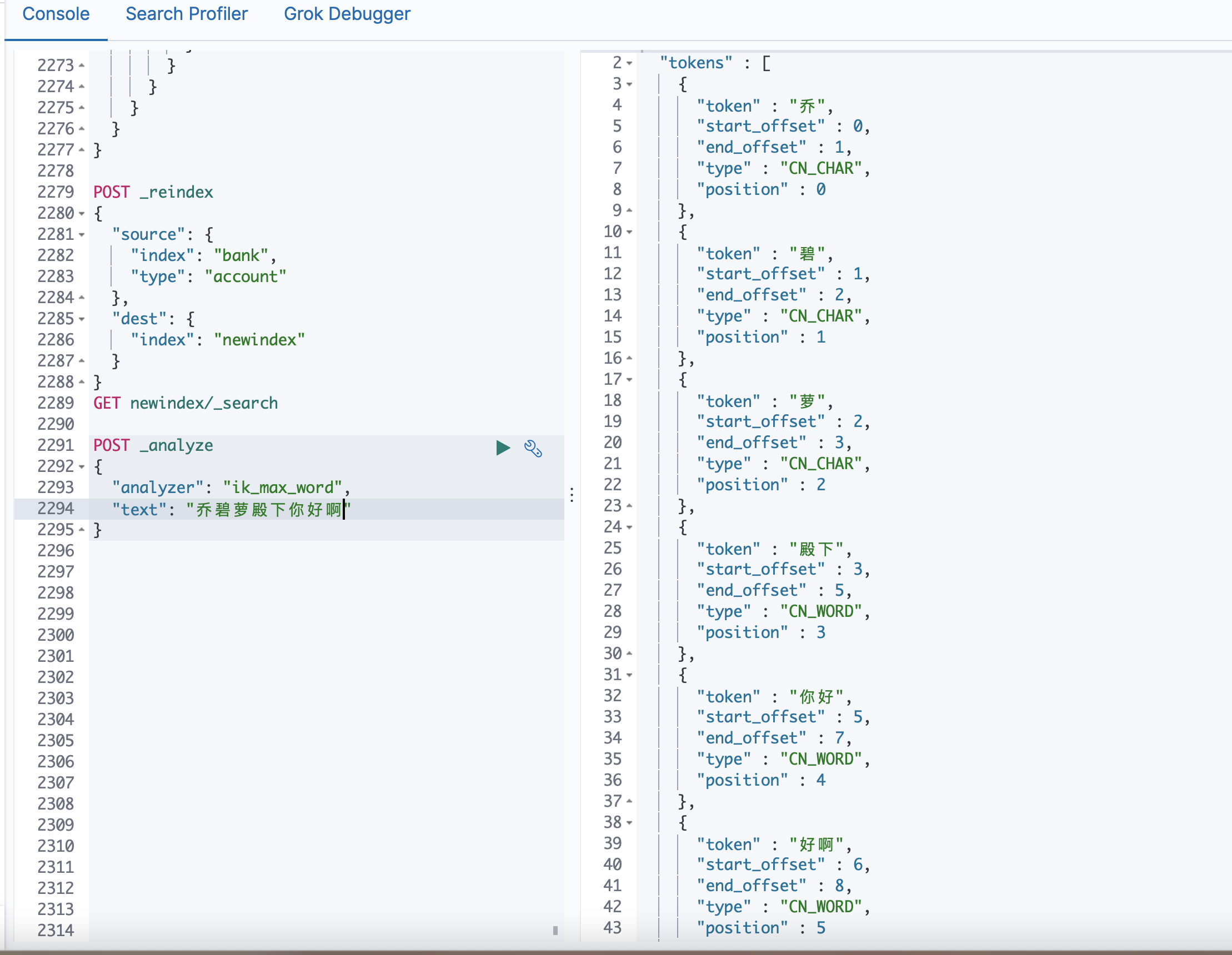
After adding Thesaurus
Integrate SpringBoot
Use official high-order dependencies
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.4.2</version> </dependency>
You also need to modify the ES version imported by SpringBoot by default. Just match the version number to the version you need to import
<properties> <elasticsearch.version>7.4.2</elasticsearch.version> </properties>
Configure ES
@Configuration
public class GuliMallElasticSearchConfig {
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
)
);
}
}
Basic use
IndexRequest
IndexRequest is used to index a document. If the index does not exist, it will be created
@Autowired
private RestHighLevelClient esClient;
void indexTest() throws IOException {
IndexRequest request = new IndexRequest("users");
request.id("1");
User user = new User();
user.setUserName("clover");
user.setAge(19);
request.source(new Gson().toJson(user), XContentType.JSON);
IndexResponse index = esClient.index(request, GuliMallElasticSearchConfig.COMMON_OPTIONS);
log.info("index: {}", index);
}
-
IndexRequest
It has the following three constructs: specified index, specified index and type, specified index, type and unique identifier. In 7 The first construct is most commonly used in X. you can use (New indexrequest ("XXX")) ID ("XXX") to specify a unique ID.
- public IndexRequest(String index)
- public IndexRequest(String index, String type)
- public IndexRequest(String index, String type, String id)
Parameters can be passed through the source method. This method has many overloads, but these two methods are most commonly used
- Public indexrequest source (Map < string,? > source) can pass a Map, which is very convenient
- Public indexrequest source (string source, xContentType, xContentType) can pass a JSON string after specifying xContentType as JSON.
After the request is constructed, use the corresponding api in RestHighLevelClient to send the request.
Complex retrieval
The row is aggregated by age and requests the average salary of these people in these age groups
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
@Test
@DisplayName("Complex retrieval")
void searchRequestTest() throws IOException {
// Create a retrieval request
SearchRequest request = new SearchRequest();
// Specify index
request.indices("bank");
// Create search criteria
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(100);
// "query": {
// "match_all": {}
// }
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
// "query": {
// "match": {"address", "mill"}
// }
// searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
// polymerization
//"aggs": {
// "ageAgg": {
// "terms": {
// "field": "age",
// "size": 100
// }
// }
//}
searchSourceBuilder.aggregation(AggregationBuilders.terms("ageAgg").field("age").size(100)
//"aggs": {
// "ageAgg": {
// "terms": {
// "field": "age",
// "size": 100
// },
// "aggs": {
// "ageAvg": {
// "avg": {
// "field": "balance"
// }
// }
// }
// }
//}
.subAggregation(AggregationBuilders.avg("balanceAvg").field("balance"))
);
// Specify DSL
request.source(searchSourceBuilder);
// Perform retrieval
SearchResponse search = esClient.search(request, GuliMallElasticSearchConfig.COMMON_OPTIONS);
}