1, Background
es comes with a lot of word splitters, such as standard, whitespace, language (such as english), but they are not very good for Chinese word segmentation. A third-party word splitter ik is installed here to realize word segmentation.
2, Install ik word splitter
1. Find the word breaker matching this es version from github
# Download address https://github.com/medcl/elasticsearch-analysis-ik/releases
2. Use the es built-in plug-in to manage the elastic search plugin for installation
- Install directly from network address
cd /Users/huan/soft/elastic-stack/es/es02/bin # Download plug-ins ./elasticsearch-plugin -v install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip # Check whether the plug-in has been downloaded successfully ./elasticsearch-plugin list
- Install locally
cd /Users/huan/soft/elastic-stack/es/es02/bin # Download the plug-in (file is followed by the local address of the plug-in) ./elasticsearch-plugin install file:///path/to/plugin.zip
be careful:
If there are spaces in the path of the local plug-in, they need to be wrapped in double quotes.
3. Restart es
# Find es process jps -l | grep 'Elasticsearch' # Kill es process kill pid # Start es /Users/huan/soft/elastic-stack/es/es01/bin/elasticsearch -d -p pid01
3, Test ik participle
ik word splitter provides two word segmentation modes
- ik_max_word: split the text that needs word segmentation with the smallest granularity and divide more words as much as possible.
- ik_smart: split the text that needs word segmentation at the maximum granularity.
1. Test the default word segmentation effect
sentence
GET _analyze
{
"analyzer": "default",
"text": ["Chinese sub words"]
}
result
{
"tokens" : [
{
"token" : "in",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<ideographic>",
"position" : 0
},
{
"token" : "writing",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<ideographic>",
"position" : 1
},
{
"token" : "branch",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<ideographic>",
"position" : 2
},
{
"token" : "Words",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<ideographic>",
"position" : 3
},
{
"token" : "language",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<ideographic>",
"position" : 4
}
]
}
You can see that the default word segmentation device can not achieve the effect of our Chinese word segmentation.
2. Test ik_max_word segmentation effect of word
sentence
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["Chinese sub words"]
}
result
{
"tokens" : [
{
"token" : "chinese",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "participle",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "terms",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
We can see that word segmentation based on ik can achieve the effect we need.
3. Test IK_ Word segmentation effect of smart
sentence
GET _analyze
{
"analyzer": "ik_smart",
"text": ["Chinese sub words"]
}
result
{
"tokens" : [
{
"token" : "chinese",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "branch",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "terms",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
4. Enable and disable words of custom ik
1. Locate ik's configuration directory
${IK_HOME}/config/analysis-ik
/Users/huan/soft/elastic-stack/es/es01/config/analysis-ik
2. Modify ikanalyzer cfg. XML file
<!--?xml version="1.0" encoding="UTF-8"?--> <properties> <comment>IK Analyzer Extended configuration</comment> <!--Users can configure their own extended dictionary here --> <entry key="ext_dict">custom-ext.dic</entry> <!--Users can configure their own extended stop word dictionary here--> <entry key="ext_stopwords">custom-stop.dic</entry> <!--Users can configure the remote extension dictionary here --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--Users can configure the remote extended stop word dictionary here--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
3. custom-ext.dic and custom-stop Contents of DIC

be careful:
1. The file of custom word segmentation must be UTF-8 encoding.
4. Full path of configuration file
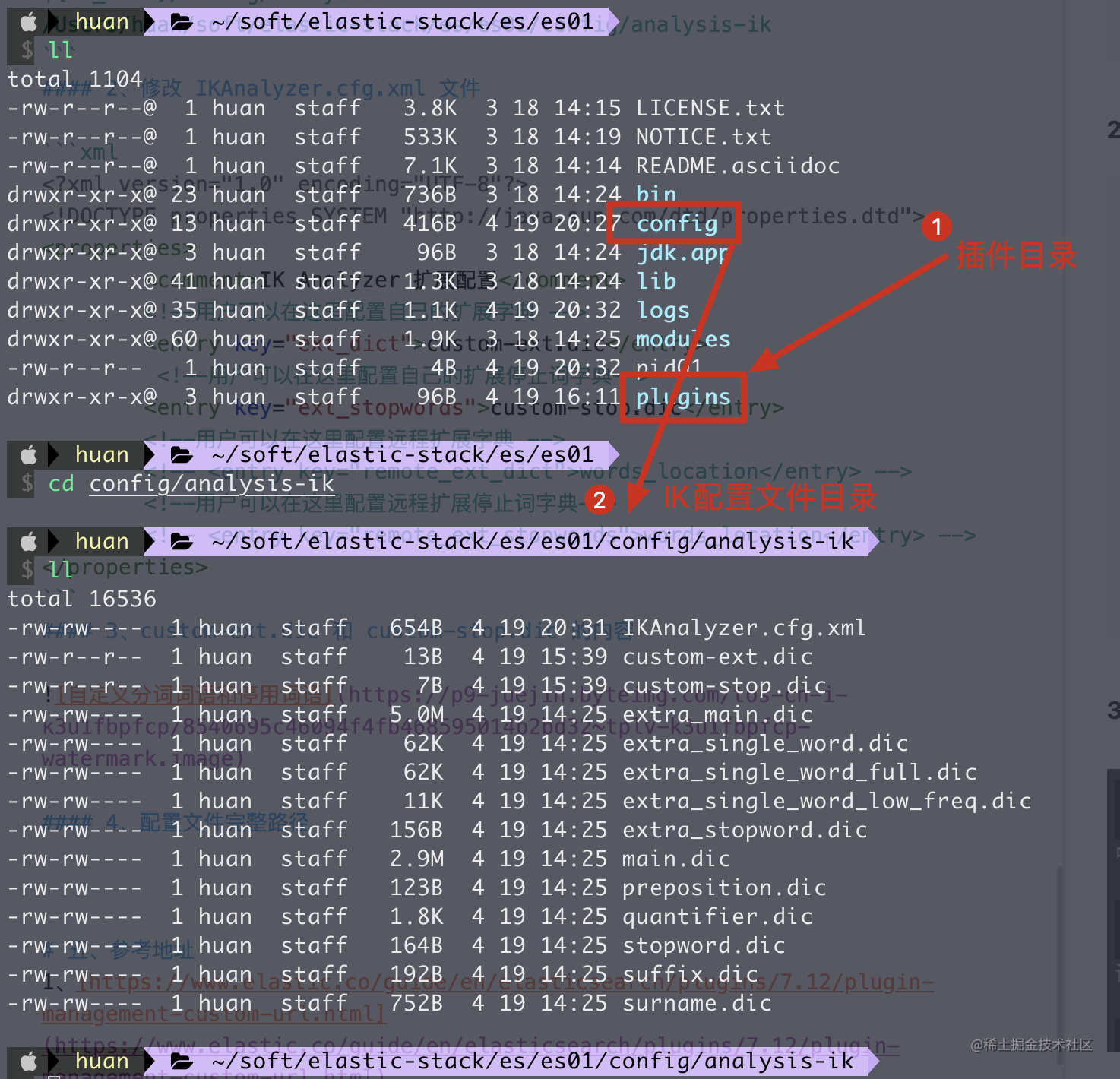
5. View word segmentation results

5. Hot update IK word segmentation
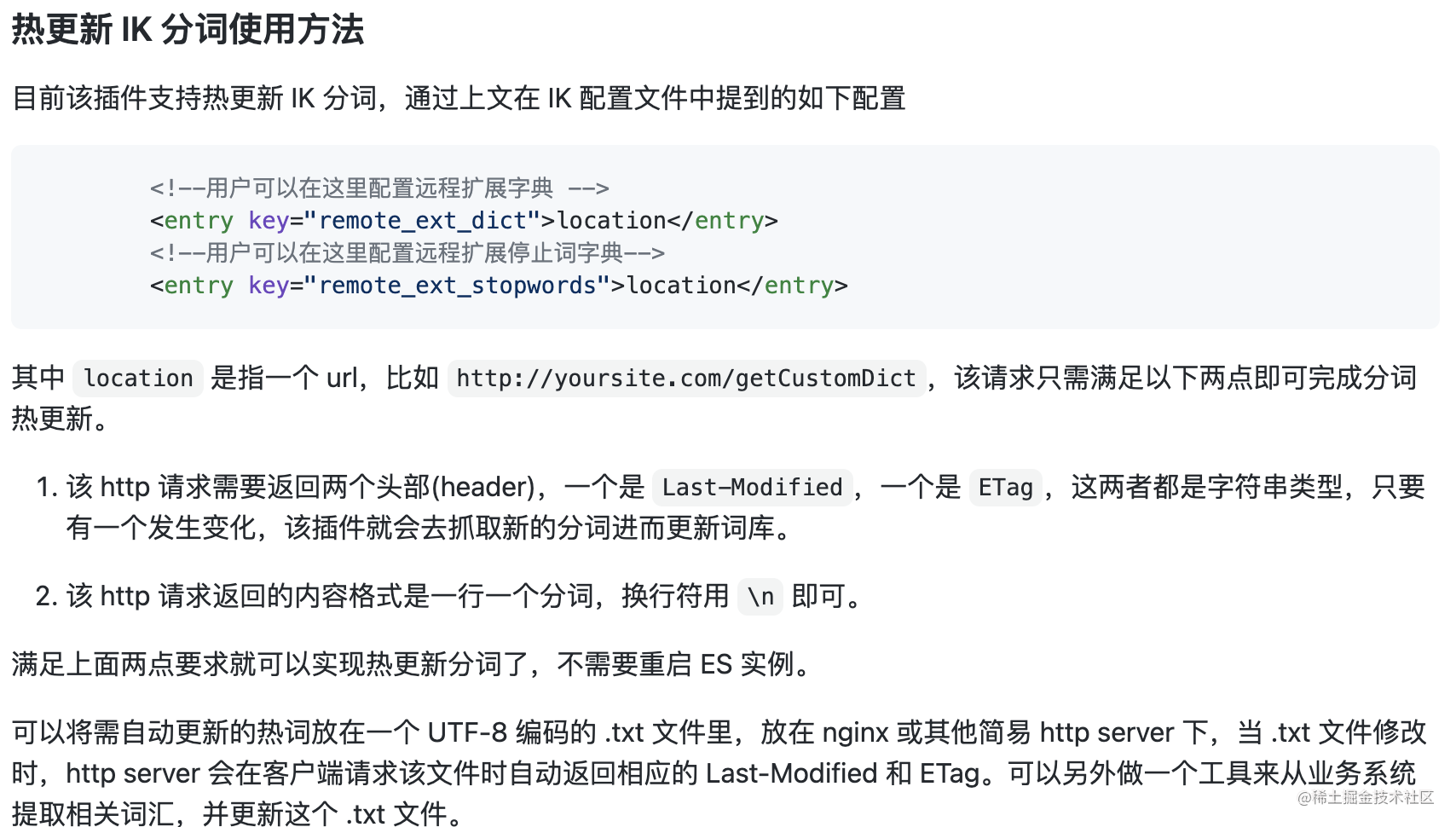
1. Modify ikanalyzer cfg. XML file to configure the remote dictionary.
$ cat /Users/huan/soft/elastic-stack/es/es01/config/analysis-ik/IKAnalyzer.cfg.xml 11.87s 16.48G 2.68 <!--?xml version="1.0" encoding="UTF-8"?--> <properties> <comment>IK Analyzer Extended configuration</comment> <!--Users can configure the remote extension dictionary here --> <entry key="remote_ext_dict">http://localhost:8686/custom-ext.dic</entry> <!--Users can configure the remote extended stop word dictionary here--> <entry key="remote_ext_stopwords"></entry> </properties>
be careful:
1. The custom-ext.dic file here will be configured in nginx below to ensure access.
2. The http request needs to return two headers, one is last modified and the other is ETag. Both of them are string types. As long as one of them changes, the plug-in will grab new participles and update the thesaurus.
3. The content format returned by the http request is one word per line, and the newline character \ n can be used. 4. Place a custom-ext.dic file in the nginx directory

After modifying the custom-ext.dic file for many times, you can see that the result of word segmentation will also change in real time, so the hot update of word segmentation is realized.
5, Reference address
1,https://www.elastic.co/guide/en/elasticsearch/plugins/7.12/plugin-management-custom-url.html
2,https://github.com/medcl/elasticsearch-analysis-ik/releases
3,https://github.com/medcl/elasticsearch-analysis-ik</ideographic></ideographic></ideographic></ideographic></ideographic>