Part4.1: ElasticSearch Windows
4.1 related concepts
4.1.1 single machine & cluster
- When a single ElasticSearch server provides services, it often has the maximum load capacity. If it exceeds this threshold, the performance of the server will be greatly reduced or even unavailable. Therefore, in the production environment, it usually runs in the specified server cluster.
- In addition to load capacity, single point servers also have other problems
- Limited storage capacity of a single machine
- Single server is prone to single point of failure and cannot achieve high availability
- The concurrent processing capability of single service is limited
- When configuring a server cluster, there is no limit on the number of nodes in the cluster. If there are more than or equal to 2 nodes, it can be regarded as a cluster. Generally, considering high performance and high availability, the number of nodes in the cluster is more than 3
4.1.2 Cluster
- A cluster is organized by one or more server nodes to jointly hold the whole data and provide indexing and search functions together. An elasticsearch cluster has a unique name ID, which is "elasticsearch" by default. This name is very important because a node can only join a cluster by specifying the name of the cluster.
4.1.3 Node
- The cluster contains many servers, and a node is one of them. As a part of the cluster, it stores data and participates in the indexing and search functions of the cluster.
- A node is also identified by a name. By default, this name is the name of a random Marvel comic character, which will be given to the node at startup. This name is very important for management, because in this management process, you will determine which servers in the network correspond to which nodes in the ElasticSearch cluster.
- A node can join a specified cluster by configuring the cluster name. By default, if you don't have any elasticsearch nodes running in your network, any node will be scheduled to join a cluster called "elasticsearch", which means that if you start several nodes in your network and assume that they can find each other, They will automatically form and join a cluster called "elastic search".
- In a cluster, you can have as many nodes as you want.
4.2 Windows cluster
- Note: This is to start three nodes on one machine to simulate the cluster. In principle, three nodes are deployed on three machines to realize the cluster in the actual production environment, which is more accurate.
- It is also possible for a single machine to start multiple nodes to form a cluster, but high availability is prone to problems in some performance aspects.
4.2.1 deployment cluster
-
ElasticSearch7.8.0 download link: https://pan.baidu.com/s/13cOY9Ch6RZMQln4OHy6X_A
Extraction code: embs -
Create the elasticsearch cluster folder and copy three elasticsearch services internally.
-
Modify config / elasticsearch. In the file directory of each node YML profile
-
node01
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # Cluster related configuration information # Use a descriptive name for your cluster: # Configuration information of node 1 cluster.name: test-elasticsearch-cluster # # ------------------------------------ Node ------------------------------------ # Node related configuration information # Use a descriptive name for the node: # Node name, which is unique in the same cluster node.name: node01 # Is the current node a master node node.master: true # Is the current node a data node node.data: true # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # Path configuration related information # Path to directory where to store the data (separate multiple locations by comma): # #path.data: /path/to/data # # Path to log files: # #path.logs: /path/to/logs # # ----------------------------------- Memory ----------------------------------- # Memory configuration related information # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # Network configuration related information # Set the bind address to a specific IP (IPv4 or IPv6): # ip address network.host: localhost # # Set a custom port for HTTP: # http port http.port: 1001 # tcp listening port transport.tcp.port: 9301 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # Cluster service discovery registration related configuration # Pass an initial list of hosts to perform discovery when this node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # Cluster node information. The port number used here is tcp, which is used inside the cluster discovery.seed_hosts: ["localhost:9301", "localhost:9302", "localhost:9303"] # Communication timeout between nodes discovery.zen.fd.ping_timeout: 1m # Node timeout retries discovery.zen.fd.ping_retries: 5 # Bootstrap the cluster using an initial set of master-eligible nodes: # List of nodes in the cluster that can be selected as the master node #cluster.initial_master_nodes: ["node01", "node02"] # # For more information, consult the discovery and cluster formation module documentation. # # ---------------------------------- Gateway ----------------------------------- # Gateway configuration # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # Cross domain configuration # Require explicit names when deleting indices: # #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*"
-
node02
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # Cluster related configuration information # Use a descriptive name for your cluster: # Configuration information of node 1 cluster.name: test-elasticsearch-cluster # # ------------------------------------ Node ------------------------------------ # Node related configuration information # Use a descriptive name for the node: # Node name, which is unique in the same cluster node.name: node02 # Is the current node a master node node.master: true # Is the current node a data node node.data: true # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # Path configuration related information # Path to directory where to store the data (separate multiple locations by comma): # #path.data: /path/to/data # # Path to log files: # #path.logs: /path/to/logs # # ----------------------------------- Memory ----------------------------------- # Memory configuration related information # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # Network configuration related information # Set the bind address to a specific IP (IPv4 or IPv6): # ip address network.host: localhost # # Set a custom port for HTTP: # http port http.port: 1002 # tcp listening port transport.tcp.port: 9302 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # Cluster service discovery registration related configuration # Pass an initial list of hosts to perform discovery when this node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # Cluster node information. The port number used here is tcp, which is used inside the cluster discovery.seed_hosts: ["localhost:9301", "localhost:9302", "localhost:9303"] # Communication timeout between nodes discovery.zen.fd.ping_timeout: 1m # Node timeout retries discovery.zen.fd.ping_retries: 5 # Bootstrap the cluster using an initial set of master-eligible nodes: # List of nodes in the cluster that can be selected as the master node #cluster.initial_master_nodes: ["node01", "node02"] # # For more information, consult the discovery and cluster formation module documentation. # # ---------------------------------- Gateway ----------------------------------- # Gateway configuration # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # Cross domain configuration # Require explicit names when deleting indices: # #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*"
-
node03
# ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # Cluster related configuration information # Use a descriptive name for your cluster: # Configuration information of node 1 cluster.name: test-elasticsearch-cluster # # ------------------------------------ Node ------------------------------------ # Node related configuration information # Use a descriptive name for the node: # Node name, which is unique in the same cluster node.name: node03 # Is the current node a master node node.master: true # Is the current node data node.data: true # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # Path configuration related information # Path to directory where to store the data (separate multiple locations by comma): # #path.data: /path/to/data # # Path to log files: # #path.logs: /path/to/logs # # ----------------------------------- Memory ----------------------------------- # Memory configuration related information # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # Network configuration related information # Set the bind address to a specific IP (IPv4 or IPv6): # ip address network.host: localhost # # Set a custom port for HTTP: # http port http.port: 1003 # tcp listening port transport.tcp.port: 9303 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # Cluster service discovery registration related configuration # Pass an initial list of hosts to perform discovery when this node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # Cluster node information. The port number used here is tcp, which is used inside the cluster discovery.seed_hosts: ["localhost:9301", "localhost:9302", "localhost:9303"] # Communication timeout between nodes discovery.zen.fd.ping_timeout: 1m # Node timeout retries discovery.zen.fd.ping_retries: 5 # Bootstrap the cluster using an initial set of master-eligible nodes: # List of nodes in the cluster that can be selected as the master node #cluster.initial_master_nodes: ["node01", "node02"] # # For more information, consult the discovery and cluster formation module documentation. # # ---------------------------------- Gateway ----------------------------------- # Gateway configuration # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # Cross domain configuration # Require explicit names when deleting indices: # #action.destructive_requires_name: true http.cors.enabled: true http.cors.allow-origin: "*"
-
4.2.2 start the cluster
- Delete the data directory (if any) in each node before starting
- Logs in the logs folder can also be deleted
- Execute bin / elasticsearch Bat, start the node server. After starting, it will automatically join the cluster with the specified name.
- Possible problems
- Port occupied
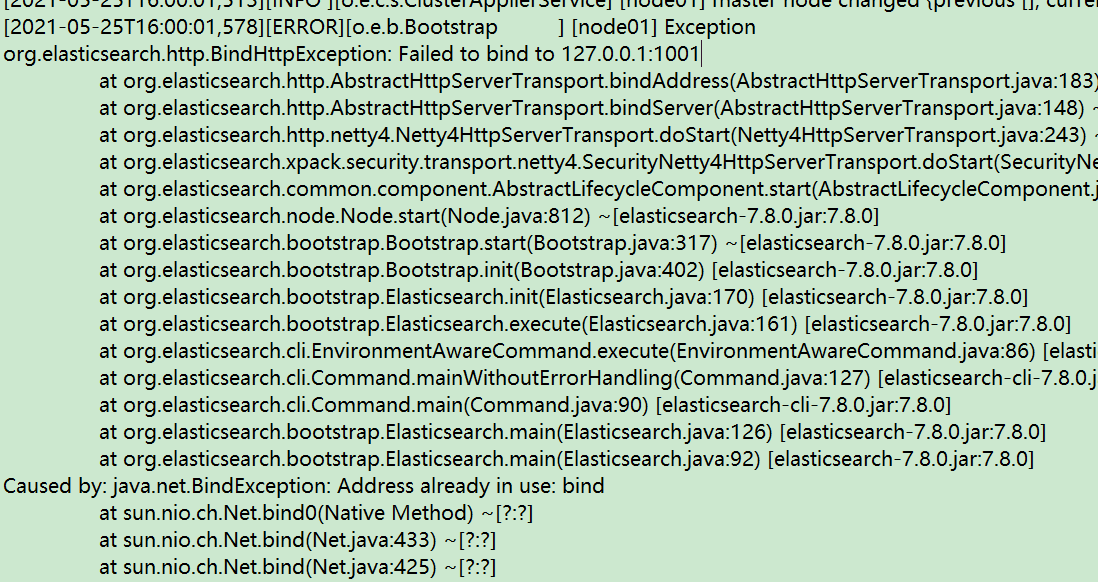
- You can modify the configuration file, switch to other ports, or kill the program occupying the port (if you are not sure whether the program occupying the port is important, change the port)
- Here I modified the port numbers: 9001, 9002, 9003
- Port occupied
- utf-8 problem
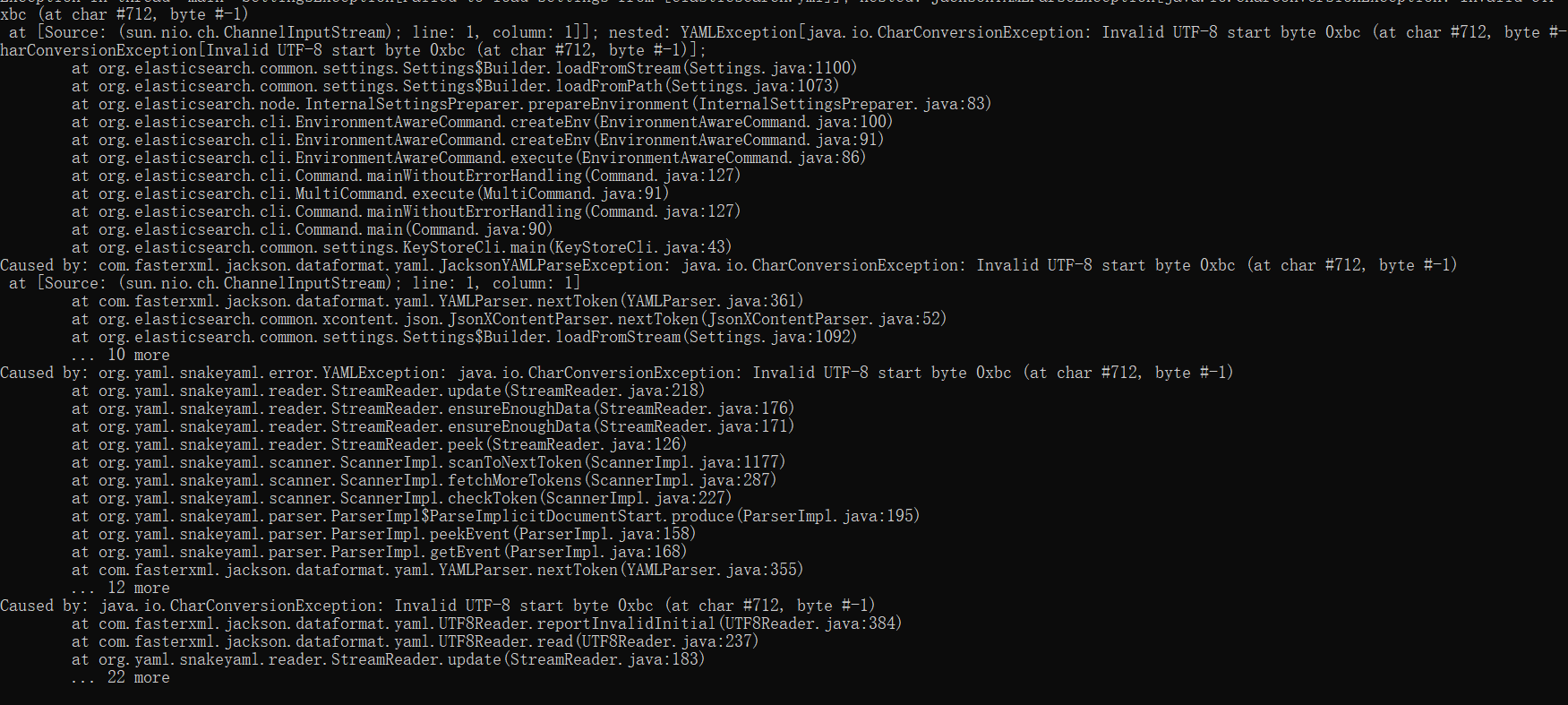
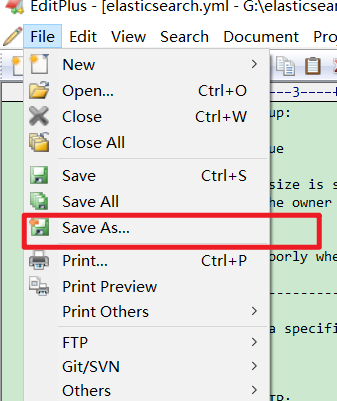
- This is generally because when modifying the yml configuration file, you can directly save the file by ctrl+s, but the text editor has modified the text encoding format instead of utf-8
- When the file is saved in ymf-utl format, it can be modified


4.2.3 test cluster
- View cluster status (postman)
- node01 node: http://localhost:9001/_cluster/health
- node01 node: http://localhost:9002/_cluster/health
- node01 node: http://localhost:9003/_cluster/health
- Sample
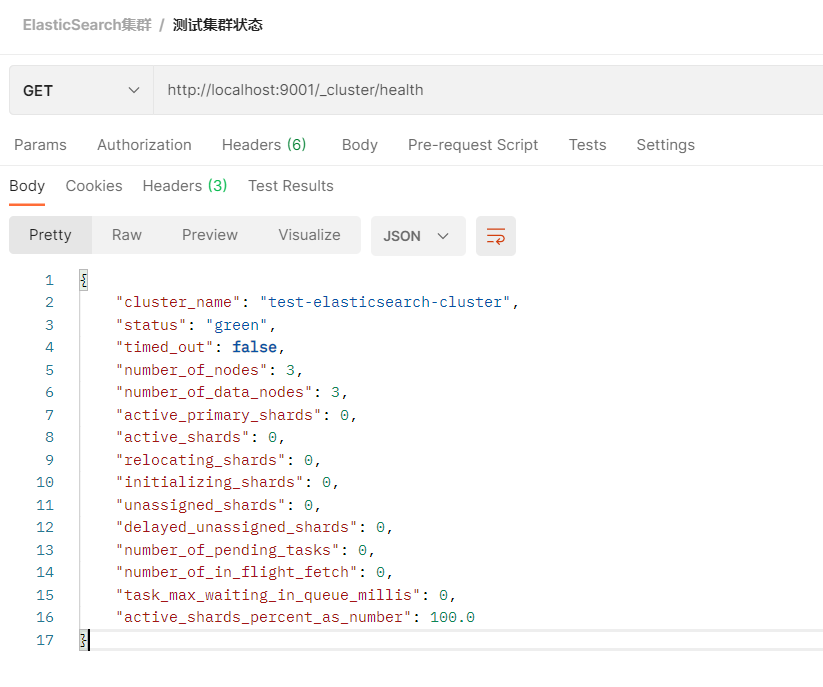
- There is a status field in the returned result, which indicates whether the current cluster is working normally on the whole. Contains three colors:
- green: all primary and replica partitions work normally
- yellow: all primary partitions work normally, but not all replica partitions work normally
- red: the main partition does not operate normally
- Test it
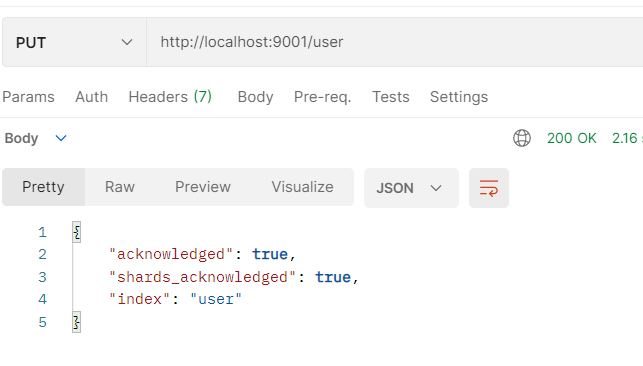
- Add an index to node01 node
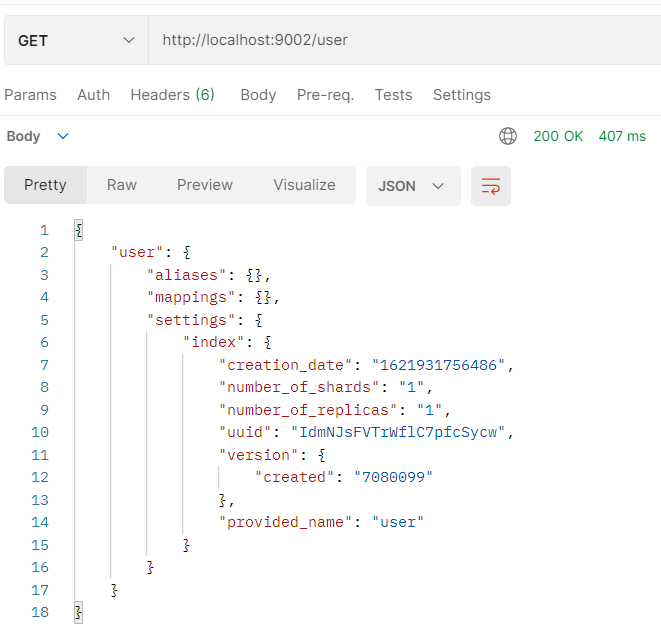
- Query the index on node02
- Add an index to node01 node