This article mainly introduces what is Analysis, what is the word breaker, and how the word breaker of ElasticSearch works. Finally, it will introduce how to do the Chinese word breaker.
First of all, what is Analysis
What is Analysis?
As the name implies, text Analysis is the process of converting the full text into a series of words (term/token), also known as participle. In ES, Analysis is implemented through the word breaker (Analyzer), which can use es built-in Analyzer or customized Analyzer on demand.
Take a simple example of word segmentation: for example, if you enter Mastering Elasticsearch, it will automatically help you to divide two words, one is mastering, the other is elasticsearch. You can see that the words are also converted to lowercase.

After a brief understanding of Analysis and Analyzer, let's take a look at the composition of the word breaker:
The composition of participator
The word breaker is a component specially dealing with word breaker, which consists of the following three parts:
- Character Filters: for raw text processing, such as removing html tags
- Tokenizer: divide words according to rules, such as spaces
- Token Filters: process the segmented words, such as converting upper case to lower case, deleting stopwords, and adding synonyms
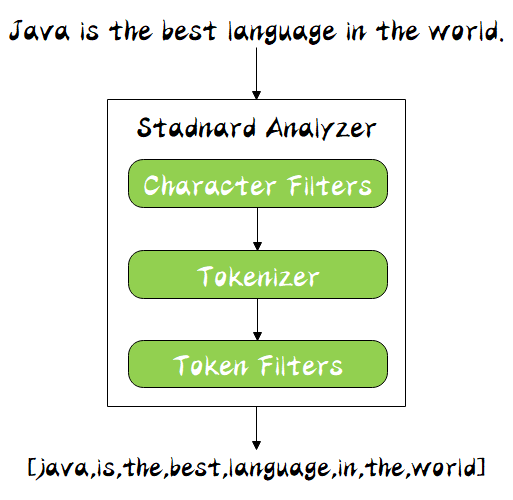
At the same time, the three parts of Analyzer are in order. It can be seen from the figure that they pass through Character Filters, Tokenizer and Token Filters from top to bottom. This order is easy to understand. When a text comes in, it must first process the text data, then remove the word segmentation, and finally filter the result of word segmentation.
Among them, ES has many built-in word breakers:
- Standard Analyzer - default word breaker, segmentation by word, lowercase processing
- Simple Analyzer - non alphabetic segmentation (symbols are filtered), lowercase processing
- Stop Analyzer - lowercase processing, the, a, is
- Whitespace Analyzer - split by spaces, not lowercase
- Keyword Analyzer - no word segmentation, directly treat input as output
- Pattern Analyzer - regular expression, default \ W+
- Language - provides word breakers in more than 30 common languages
- Customer Analyzer - custom word breaker
Next, we will explain the above word breakers. Before we explain, let's look at the very useful API: "analyzer API:
Analyzer API
It can see how the word breaker works in three ways:
- Directly assign Analyzer to test
GET _analyze { "analyzer": "standard", "text" : "Mastering Elasticsearch , elasticsearch in Action" }
- Specify the fields of the index to test
POST books/_analyze { "field": "title", "text": "Mastering Elasticesearch" }
- Test with custom participle
POST /_analyze { "tokenizer": "standard", "filter": ["lowercase"], "text": "Mastering Elasticesearch" }
After understanding the Analyzer API, let's take a look at the ES built-in word breaker:
ES participle
First, we will introduce the following stamdad analyzer word breaker:
Stamdard Analyzer
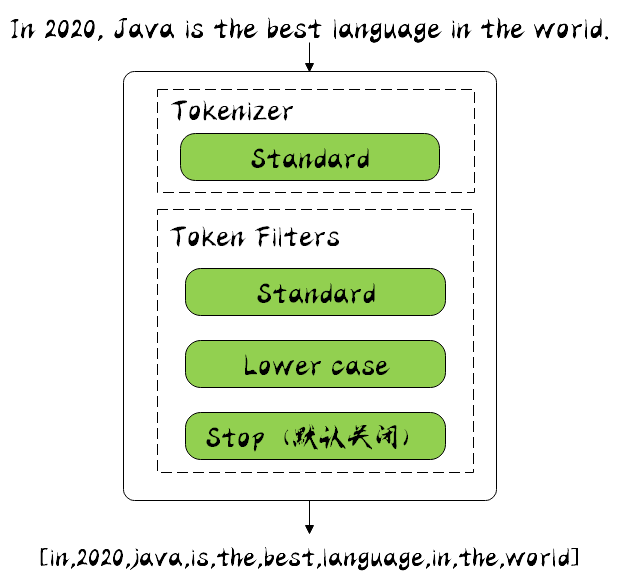
It is the ES default word breaker. It will segment the input text in the way of words. After segmentation, it will be converted to lowercase. The default stopwords is off.
Let's use Kibana to see how it works. In the Dev Tools of Kibana, specify Analyzer as standard, and enter the text In 2020, Java is the best language in the world. Then we run it:
GET _analyze { "analyzer": "standard", "text": "In 2020, Java is the best language in the world." }
The operation results are as follows:
{ "tokens" : [ { "token" : "in", "start_offset" : 0, "end_offset" : 2, "type" : "<ALPHANUM>", "position" : 0 }, { "token" : "2020", "start_offset" : 3, "end_offset" : 7, "type" : "<NUM>", "position" : 1 }, { "token" : "java", "start_offset" : 9, "end_offset" : 13, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "is", "start_offset" : 14, "end_offset" : 16, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "the", "start_offset" : 17, "end_offset" : 20, "type" : "<ALPHANUM>", "position" : 4 }, { "token" : "best", "start_offset" : 21, "end_offset" : 25, "type" : "<ALPHANUM>", "position" : 5 }, { "token" : "language", "start_offset" : 26, "end_offset" : 34, "type" : "<ALPHANUM>", "position" : 6 }, { "token" : "in", "start_offset" : 35, "end_offset" : 37, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "the", "start_offset" : 38, "end_offset" : 41, "type" : "<ALPHANUM>", "position" : 8 }, { "token" : "world", "start_offset" : 42, "end_offset" : 47, "type" : "<ALPHANUM>", "position" : 9 } ] }
It can be seen that the input text has been converted in the way of space and non letter. For example, Java has been converted to lowercase, and some stop words have not been removed, such as in.
Where token is the result of word segmentation, start offset is the start offset, end offset is the end offset, and position is the word segmentation position.
Let's look at the Simple Analyzer word breaker:
Simple Analyzer
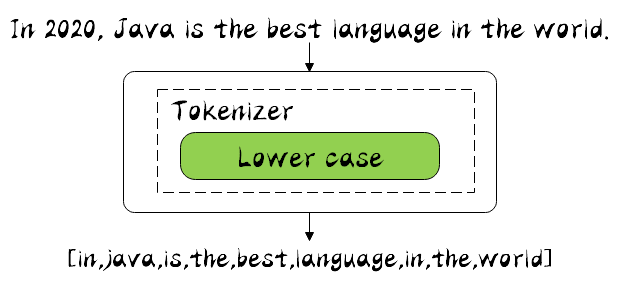
It only includes the Tokenizer of the Lower Case. It will be segmented according to the non letter, and the non letter will be removed. Finally, the segmented good will be converted to lowercase, and then the input text just now will be used, and the word segmenter will be replaced by simple to segment the word. The running results are as follows:
{ "tokens" : [ { "token" : "in", "start_offset" : 0, "end_offset" : 2, "type" : "word", "position" : 0 }, { "token" : "java", "start_offset" : 9, "end_offset" : 13, "type" : "word", "position" : 1 }, { "token" : "is", "start_offset" : 14, "end_offset" : 16, "type" : "word", "position" : 2 }, { "token" : "the", "start_offset" : 17, "end_offset" : 20, "type" : "word", "position" : 3 }, { "token" : "best", "start_offset" : 21, "end_offset" : 25, "type" : "word", "position" : 4 }, { "token" : "language", "start_offset" : 26, "end_offset" : 34, "type" : "word", "position" : 5 }, { "token" : "in", "start_offset" : 35, "end_offset" : 37, "type" : "word", "position" : 6 }, { "token" : "the", "start_offset" : 38, "end_offset" : 41, "type" : "word", "position" : 7 }, { "token" : "world", "start_offset" : 42, "end_offset" : 47, "type" : "word", "position" : 8 } ] }
It can be seen from the results that the number 2020 is removed, indicating that non alphabetic words will indeed be removed, and all words have been converted to lowercase.
Now, let's look at the Whitespace Analyzer word breaker:
Whitespace Analyzer
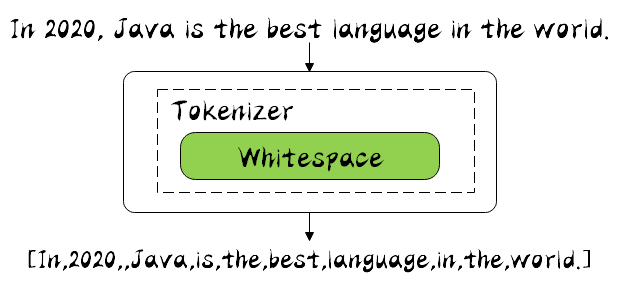
It is very simple. According to its name, it can be seen that it is segmented by spaces. Let's see how it works:
{ "tokens" : [ { "token" : "In", "start_offset" : 0, "end_offset" : 2, "type" : "word", "position" : 0 }, { "token" : "2020,", "start_offset" : 3, "end_offset" : 8, "type" : "word", "position" : 1 }, { "token" : "Java", "start_offset" : 9, "end_offset" : 13, "type" : "word", "position" : 2 }, { "token" : "is", "start_offset" : 14, "end_offset" : 16, "type" : "word", "position" : 3 }, { "token" : "the", "start_offset" : 17, "end_offset" : 20, "type" : "word", "position" : 4 }, { "token" : "best", "start_offset" : 21, "end_offset" : 25, "type" : "word", "position" : 5 }, { "token" : "language", "start_offset" : 26, "end_offset" : 34, "type" : "word", "position" : 6 }, { "token" : "in", "start_offset" : 35, "end_offset" : 37, "type" : "word", "position" : 7 }, { "token" : "the", "start_offset" : 38, "end_offset" : 41, "type" : "word", "position" : 8 }, { "token" : "world.", "start_offset" : 42, "end_offset" : 48, "type" : "word", "position" : 9 } ] }
It can be seen that only by space segmentation, the 2020 number is still in, the Java initial is still uppercase, or reserved.
Next, let's look at the Stop Analyzer word breaker:
Stop Analyzer
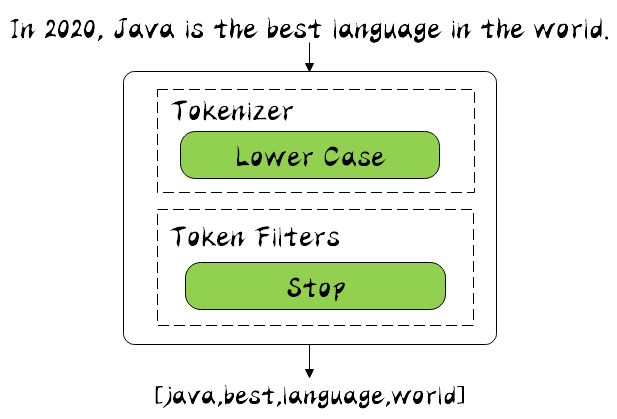
It is composed of the Tokenizer of low case and the Token Filters of stop. Compared with the Simple Analyzer just mentioned, stop has more stop filtering. Stop will remove the, a, is and other modifiers. Let's also see the running results:
{ "tokens" : [ { "token" : "java", "start_offset" : 9, "end_offset" : 13, "type" : "word", "position" : 1 }, { "token" : "best", "start_offset" : 21, "end_offset" : 25, "type" : "word", "position" : 4 }, { "token" : "language", "start_offset" : 26, "end_offset" : 34, "type" : "word", "position" : 5 }, { "token" : "world", "start_offset" : 42, "end_offset" : 47, "type" : "word", "position" : 8 } ] }
You can see that words like in is the are filtered out by stop filter.
Next, let's look at Keyword Analyzer:
Keyword Analyzer

In fact, it does not do word segmentation, but takes the input as the Term output. Let's see the following operation results:
{ "tokens" : [ { "token" : "In 2020, Java is the best language in the world.", "start_offset" : 0, "end_offset" : 48, "type" : "word", "position" : 0 } ] }
We can see that the input text is not segmented, but directly output as Term.
Next, let's look at Pattern Analyzer:
Pattern Analyzer
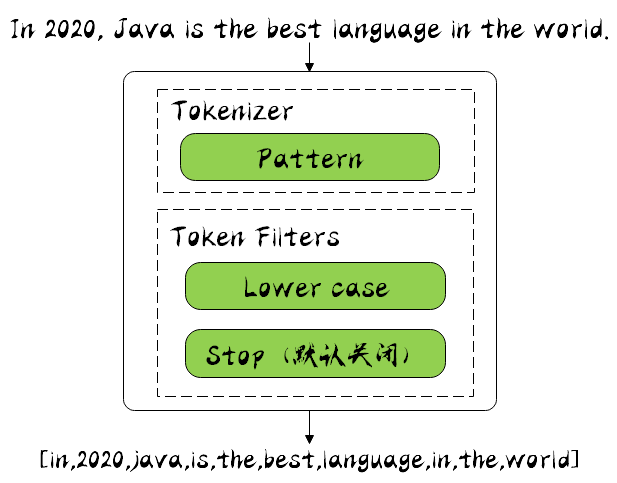
It can be segmented by regular expression. By default, it is segmented by \ W +, i.e. non letter matching. Because the running result is the same as stamdad analyzer, it will not be displayed.
Language Analyzer
ES provides a Language Analyzer word breaker for language input in different countries. You can specify different languages in it. Let's use english for word segmentation:
{ "tokens" : [ { "token" : "2020", "start_offset" : 3, "end_offset" : 7, "type" : "<NUM>", "position" : 1 }, { "token" : "java", "start_offset" : 9, "end_offset" : 13, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "best", "start_offset" : 21, "end_offset" : 25, "type" : "<ALPHANUM>", "position" : 5 }, { "token" : "languag", "start_offset" : 26, "end_offset" : 34, "type" : "<ALPHANUM>", "position" : 6 }, { "token" : "world", "start_offset" : 42, "end_offset" : 47, "type" : "<ALPHANUM>", "position" : 9 } ] }
It can be seen that language has been changed to language, and it also has stop filter, such as in,is and other words have been removed.
Finally, let's look at Chinese participle:
Chinese word segmentation
There are specific difficulties in Chinese word segmentation. Unlike in English, words are separated by natural spaces. In Chinese sentences, words cannot be simply divided into words, but need to be divided into meaningful words, but in different contexts, there are different understandings.
For example:
In these, enterprises, state-owned enterprises, enterprises, there are ten / in these, enterprises, China, there are enterprises, there are ten Countries, yes, enterprises, one after another, bankruptcy / each, state owned, enterprises, one after another, bankruptcy Badminton, auction, over / badminton racket, sell, over
So, let's take a look at the ICU Analyzer word breaker, which provides Unicode support and better support for Asian languages!
First, we use standard to segment words for comparison with ICU.
GET _analyze { "analyzer": "standard", "text": "The state-owned enterprises went bankrupt one after another" }
The operation results will not be shown. Word segmentation is a word by word segmentation, and the obvious effect is not very good. Next, use ICU to segment words, and the segmentation results are as follows:
{ "tokens" : [ { "token" : "All countries", "start_offset" : 0, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "Yes", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "enterprise", "start_offset" : 3, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "one after another", "start_offset" : 5, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "Bankruptcy", "start_offset" : 7, "end_offset" : 9, "type" : "<IDEOGRAPHIC>", "position" : 4 } ] }
It can be seen that the division into countries, enterprises, one after another, bankruptcy, obviously much better than the effect just now.
There are also many Chinese word breakers. Here are a few:
IK:
- Support custom thesaurus and hot update Thesaurus
- https://github.com/medcl/elasticsearch-analysis-ik
jieba:
- The most popular word segmentation system in Python, supporting word segmentation and part of speech tagging
- Support traditional word segmentation, custom dictionary, parallel word segmentation, etc
- https://github.com/sing1ee/elasticsearch-jieba-plugin
THULAC:
- Thu lexual analyzer for Chinese, a set of Chinese word segmentation device in natural language processing and social humanities Computing Laboratory of Tsinghua University
- https://github.com/thunlp/THULAC-Java
You can install it yourself and see its Chinese word segmentation effect.
summary
This paper mainly introduces the word segmentation device of ElasticSearch, learns to use the ﹣ analyzer API to check its word segmentation, and finally introduces how to do Chinese word segmentation.
Reference
Elasticsearch top class collection
The core technology and practice of elastic search
https://www.elastic.co/guide/en/elasticsearch/reference/7.1/indices-analyze.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/analyzer-anatomy.html