summary
In various logs and tty output, we can always find various incorrectly encoded characters.
�😸� `\xef\xbf\xbd\xf0\x9f\x98\xb8\xef\xbf\xbd` '\xe7\xb2\xbe\xe5\xa6\x99' `<<"ä½ å¥½">>`
In this case, we subconsciously have three ideas:
- What is this (what should be the original content)?
- Where did you come from?
- Why is that?
- What should I do?
For my personal understanding, garbled code is just "an error for text data = = interpretation = = or = = display = =".
Conclusion (cause):
- Improper encoding issue. For example, text data encoded using utf8 is decoded using gbk.
- The font is missing character missing in font.
- Text data was not properly split. It is improperly handled by the program during network transmission or storage.
Next, share my information on these related issues.
preparation
Let's take Python 3 as an example and learn some simple and necessary processing methods first.
The data types used to process characters in Python 3 are as follows:
| represent | type | element type | length |
|---|---|---|---|
| 'subtle ' | <class 'str'> | <class 'str'> | 2 |
| b'\xe7\xb2\xbe\xe5\xa6\x99' | <class 'bytes'> | <class 'int'> | 6 |
Note that for every element in 'str', py3 it is not just range 256. See:
Python2:
Python 2.7.18 Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: chr() arg not in range(256)
Python3:
Python 3.9.1 >>> chr(0x70ce) 'To hold'
It is obvious that the 6 bytes of b'\xe7\xb2\xbe\xe5\xa6\x99' is the binary data after utf8 encoding of these two Chinese characters. It is equivalent to bytes([0xe7, 0xb2, 0xbe, 0xe5, 0xa6, 0x99]]).
Convert bytes < - > str
>>> bs = 'Subtle'.encode('utf8') # str to bytes/binary
>>> type(bs), len(bs), type(bs[0])
(<class 'bytes'>, 6, <class 'int'>)
>>> bs2 = bytes('Subtle', 'utf8') # alternative way to convert
>>> bs2
b'\xe7\xb2\xbe\xe5\xa6\x99'
>>> origin_s = bs.decode('utf8') # bytes to str
>>> origin_s, type(origin_s), len(origin_s), type(origin_s[0])
('Subtle', <class 'str'>, 2, <class 'str'>)There are many ways to construct binaries
cons_byte = bytes([231, 178, 190, 229, 166, 153]) cons_byte2 = b'\xe7\xb2\xbe\xe5\xa6\x99' >>> cons_byte, cons_byte2 (b'\xe7\xb2\xbe\xe5\xa6\x99', b'\xe7\xb2\xbe\xe5\xa6\x99')
Please note that when we get a piece of binary data. Even if we know that it is string encoded data, we can't directly restore the original character data without knowing the encoding method.
At this time, it will be very convenient if everyone agrees that the string in memory is unicode and the binary is utf8 encoded. Get a binary and directly decode utf8 it.
If we don't know the unknown byte data encoding type, we can try to analyze it with chardet:
>>> chardet.detect(b'\xe7\xb2\xbe\xe5\xa6\xfe')
{'encoding': 'ISO-8859-1', 'confidence': 0.73, 'language': ''}
>>> chardet.detect(b'\xe7\xb2\xbe\xe5\xa6\x99')
{'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''}Sometimes, there are some problems with bytes data (IO error or program bug). Although we know how to encode it, there are still errors in decoding. At this point, try setting the errors parameter of the decode function to try your luck:
Here, we change xe5\xa6\x99 to xe5\xa6\==xfe = = and change the original binary data to an illegal utf8 encoded bytes.
>>> b'\xe7\xb2\xbe\xe5\xa6\xfe'.decode('utf8', errors='strict')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 3-4: invalid continuation byte
>>> b'\xe7\xb2\xbe\xe5\xa6\xfe'.decode('utf8', errors='ignore')
'essence'You can see that the decode function has worked hard to correctly parse the Chinese characters corresponding to the first three bytes. In fact, it is not recommended that you write this in the program. After all, finding the problem is the right way (not covering up the past).
Several forms of garbled code
➊ improper coding.
We try to use gbk and ASC II methods to parse the "Hello, great" of utf coding:
>>> r = 'You're great'.encode('utf8')
>>> r
b'\xe4\xbd\xa0\xe5\xa5\xbd\xe6\xa3\x92\xe6\xa3\x92\xe5\x93\x92'
>>> r.decode('gbk', errors='ignore')
'YouソDrain barrier'
>>> ''.join([chr(c) for c in r])
'ä½\xa0好æ£\x92æ£\x92å\x93\x92'Take a look at this wall ½\ xa0å¥ ½ æ£ \ x92 æ£ \ x92 å \ x93\x92, does it smell like that?
➊ attached ➀ in ancient times = = roller weight copy = = and = = hot==
About 15 years ago, friends who had written win32 programs probably had some impressions. We can also try to reproduce:
The roller copy seems to be caused by 0xFFFD of unicode:
>>> [chr(0xFFFD)]*10 ['�', '�', '�', '�', '�', '�', '�', '�', '�', '�'] >>> ''.join([chr(0xFFFD)]*10).encode('utf8') b'\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd\xef\xbf\xbd' >>> ''.join([chr(0xFFFD)]*10).encode('utf8').decode('gbk') 'Roller copy roller copy roller copy roller copy roller copy roller copy'Similarly, write each byte of a binary as a default value (0xCC), and then decode it randomly = = perm = =:
>>> bytes([0xCD]*10).decode('gbk', errors='ignore') 'Tuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntuntun' >>> bytes([0xCC]*10).decode('gbk', errors='ignore') 'Hot, hot, hot, hot'
➋ missing font
This is better understood. There is no character in the font you use. In most cases, it shows.
Character, unicode, Emoji, and encoding.
In order to clarify the concept of garbled code, it is necessary to understand that it is a "character" in the computer system.
First, we need to define the meaning of a character. Let's not define it first, but give some examples:
- A Chinese character (such as a character) in Chinese is = = a = = character. This concept must be deeply rooted in the hearts of the people.
- The visible character in ASCII (for example, A) is A character.
- 😂 Please note that this is not a picture.
- Some invisible control characters are also characters.
Let's first study the popular "smiling and crying face" symbol:
>>> s = '😂'
>>> s
'😂'
>>> s.encode('utf8')
b'\xf0\x9f\x98\x82'
>>> [hex(b) for b in s.encode('utf8')]
['0xf0', '0x9f', '0x98', '0x82']
>>> bytes([0xf0, 0x9f, 0x98, 0x82]).decode('utf8')
'😂'
>>> chr(0x1f602)
'😂'
>>> ord('😂')
128514
>>> hex(ord('😂'))
'0x1f602'In fact, the crying face symbol is a unicode "character".
- It is a character that is emphasized again.
- Its explanation is "face with tears of joy".
- Its unicode number is U+1F602.
- The corresponding utf-8 code is 0xf0 0x9f 0x98 0x82, a total of 4 bytes.
- It is in the Emoticons block of unicode (range U+1F600 - U+1F64F), which is commonly referred to as Emoji.
How to construct an emoji unicode character? We can construct this character in many ways, such as
- By unicode number chr(0x1F602)
- Decode bytes([0xf0, 0x9f, 0x98, 0x82]).decode('utf8 ') through binary data.
At the same time, we also learned the relationship between bytes / str / unicode in Python 3: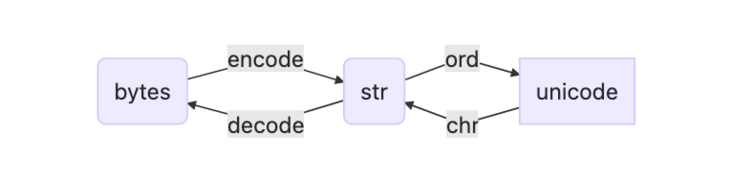
Besides, this 😂, It also has two variants. For details, please refer to the wikipedia page related to unicode.
Interesting record
Case confusion
>>> 'BAfflE' 'BAfflE' >>> 'BAfflE'.upper() 'BAFFLE' >>> 'BAfflE'.upper() == 'BAFFLE' True >>> 'BAfflE' == ''BAfflE'.upper() lower() False >>> len('BAfflE') 4 >>> len('BAfflE'.upper()) 6
reference resources:
In the second reference, the author's views are mainly as follows:
Indeed, an array of unicode characters performs better on these tests than many of the specialized string classes.
The author found that in the Python library at that time, the "length", "reversal", "interception", "case conversion" and "traversal" of unicode strings could not be handled well in the string types at that time.
Therefore, he hopes to have a direct support for list like operations on unicode, which is also very enlightening to me.