● 🧑 Personal homepage: You're handsome. You say it first
● 📃 Welcome to praise 👍 follow 💡 Collection 💖
● 📖 Having chosen the distance, he only cares about the wind and rain.
● 🤟 If you have any questions, please feel free to write to me!
● 🧐 Copyright: This article is original by [you Shuai, you say first.] and launched by CSDN. Infringement must be investigated.
1.C + + keyword
Compared with the 32 keyword C language, C + + provides 63 keywords.
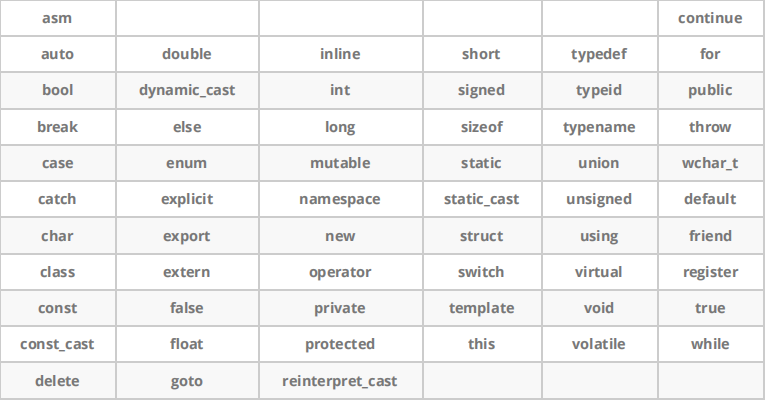
We found that we have learned some keywords in the C language stage.
2. Namespace
2.1 definition of namespace
In C/C + +, there are a large number of variables, functions and classes to be learned later. The names of these variables, functions and classes will exist in the global scope, which may lead to many conflicts. The purpose of using namespace is to localize the name of identifier to avoid naming conflict or name pollution. The emergence of namespace keyword is aimed at this problem.
1. Use of namespace
For example 🌰:
int rand = 0;
There is no problem with this code
But if we introduce header files
#include<stdlib.h>
The system will report the error of rand redefinition.
Simply put, the variable you named has the same name as the variable in the function library. For this problem, C language can't solve this problem well. So c + + has a namespace to solve this problem.
In the keywords we just talked about, we noticed a keyword called namespace, that is, namespace.
With the namespace, we modify the above code
#include<stdlib.h>
namespace MY
{
int rand = 0;
}
At this time, rand and the rand in the library form a barrier, which is equivalent to a domain. The compiler will not access the domain itself. Only we can access the contents of the domain manually.
printf("%d",MY::rand);
Only then can the content in the domain be accessed.
If the left is empty, go to the global area by default. You can access global variables in this way. Although these variables are in the domain, the variables in the domain still belong to global variables and are placed in the static area.
💡: Namespaces can only be defined globally.
2. Unlike functions, namespaces can be nested and defined.
namespace m
{
int rand = 0;
namespace n
{
int random = 0;
}
}
//At this point, if you want to access random
printf("%d",m::n::rand);
3. Multiple namespaces with the same name are allowed in the same project, and the compiler will finally synthesize them in one namespace.
2.2 use of namespace
There are three ways to use namespaces:
● add namespace name and scope qualifier:
int main()
{
printf("%d\n", MY::rand);
return 0;
}
● use using to introduce members in the namespace
using MY::b;
int main()
{
printf("%d\n", rand);
return 0;
}
● use the using namespace namespace name to introduce
using namespce MY;//Expand all contents in the namespace
int main()
{
printf("%d\n", rand);
return 0;
}
The third way is to expand all the contents in the namespace. Although it is convenient, the barrier formed by the namespace disappears. Therefore, in large projects, this method should be used with caution.
3. C + + input & output
The first line of C + +:
#Include < iostream > / / library input / output stream of C + +
using namespace std;//The implementation of the C + + library is defined in a namespace called std
int main()
{
cout<<"hello world"<<endl;
return 0;
}
Input stream
int main()
{
int a
cin>>a;
}
Compared with scanf, cin can automatically identify the type and does not need% d,% c, etc. to distinguish the variable type.
Output stream
int main()
{
int a
cin>>a;
cout<<a<<endl;//endl is equivalent to "\ n"
}
Similar to cin, cout can automatically identify types compared with printf.
💡: When using cout standard output (console) and cin standard input (keyboard), the < iostream > header file and std standard namespace must be included
4. Default parameters
The default parameter is to specify a default value for the parameter of the function when the function is declared or defined. When calling the function, if no argument is specified, the default value is adopted; otherwise, the specified argument is used
void TestFunc(int a = 0)
{
cout<<a<<endl;
}
int main()
{
TestFunc(); // When no parameter is passed, the default value of the parameter is used and 0 is output
TestFunc(10); // When passing parameters, use the specified arguments and output 10
}
Every parameter of a function like this has a default value. We call it full default parameter
void Fun(int a = 10,int b = 5,int c = 1)
{
cout<<a<<b<<c<<endl;
}
Now that there is a full default, there will be a semi default, but the semi default is not a default, not a default half, but a partial default, and must be continuously default from right to left.
void Fun(int a,int b,int c = 1)
{
cout<<a<<b<<c<<endl;
}
💡:
1. Default parameters cannot appear in function declaration and definition at the same time
2. The default parameter must be a constant or a global variable
3.C language does not support default parameters
5. Function overloading
5.1 function overload concept
Function overloading is a special case of functions. C + + allows to declare several functions with the same name with similar functions in the same scope. The formal parameter list (number or type or order of parameters) of these functions with the same name must be different. It is often used to deal with the problems of similar functions and different data types.
//1. Different parameter types
int Add(int left, int right)
{
return left+right;
}
double Add(double left, double right)
{
return left+right;
}
//2. The number of parameters is different
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
// 3. The order of parameters is different
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
💡: Overload cannot be formed by different return values
For example 🌰:
void fun(int a)
{
cout<<a<<endl;
}
int fun(int a)
{
return a;
}
At this time, if you call fun(1), the system cannot distinguish which you want to call.
Only when any of the above three conditions is met can it constitute overload, and the rest do not constitute overload.
Does C language support function overloading?
The answer is No.
Why?
The knowledge involved in this section is complex. Let's talk about it briefly here.
C language distinguishes functions simply by function names, while C + + distinguishes functions by function name length, function name and function parameters, such as f() function, which is identified in (linux Environment) system_ Z1fv 1 is the length of the function name, f is the function name, v is the initial letter of the function parameter, and v is void. For another example, func(int i,double x), which is in the system_ Z4ffuncid is identified in this way.
5.2extern C
Sometimes in C + + projects, it may be necessary to compile some functions in the style of C. add extern "C" before the function, which means to tell the compiler to compile the function according to the rules of C language. For example, tcmalloc is a project implemented by google in C + +. It provides two interfaces: tcmallc() and tcfree. However, if it is a C project, it cannot be used, so it uses extern "C" to solve it.
6. Reference
6.1 quoted concepts
Instead of defining a new variable, a reference gives an alias to an existing variable. The compiler will not open up memory space for the referenced variable. It shares the same memory space with the variable it references.
🌰:
void TestRef()
{
int a = 10;
int& aa = a;//< = = = = define reference type
printf("%p\n", &a);
printf("%p\n", &aa);
}
💡: The reference type must be of the same type as the reference entity.
6.2 reference characteristics
1. Reference must be initialized when defining
int a = 10; int& b;//error int& b = a;//Correct usage
2. A variable can have multiple references
int a = 10; int& b = a; int& c = a; int& d = b;//That's OK
3. Reference once an entity is referenced, other entities cannot be referenced
int a = 10; int& b = a; int c = 20; b = c;//The meaning of this code is to assign the value of c to b, not to change b into an alias of c
So far, we have learned three methods of swap function
void swap(int* p1, int* p2) // Transmission address
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void swap(int& r1, int& r2) // Pass reference
{
int tmp = r1;
r1 = r2;
r2 = tmp;
}
void swap(int r1, int r2) // Value transmission
{
int tmp = r1;
r1 = r2;
r2 = tmp;
}
// These three constitute function overloading
// However, there is ambiguity in the call of swap(x, y). He does not know whether the call passes value or reference
6.3 usage scenarios
1. Make parameters
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
2. Return value
Let's first review the process of function value passing and return
int add(int a,int b)
{
int c = a+b;
return c;
}
int main()
{
int ret = add(1,3);
cout<<ret<<endl;
return 0;
}
When a function returns a value, it does not assign the value of c to RET, in other words, it does not return c, but copies c to return. What do you mean? When the function returns a value, it will put the value of c in a temporary variable, and then assign the value to ret through this temporary variable. At this time, do you wonder what this temporary variable is? In fact, this temporary variable is usually used as a register when c is small. If c is large, the temporary variable is placed in the stack frame calling the Add function.
So what happens to this program if the reference is used as the return value?
int& add(int a,int b)
{
int c = a+b;
return c;
}
int main()
{
int ret = add(1,3);
cout<<ret<<endl;
return 0;
}
Here, the reference return means that the copy return of c will not be generated, and the reference of c will be returned directly.
This will lead to the following two problems:
1. There is illegal access. Because the return value of add(1,3) is a reference to c, after the add stack frame is destroyed, it will access the c location space.
2. If the stack frame of the add function is destroyed and the space is cleared, the random value is obtained when taking the value of c, and the random value is given to ret.
Having said so much, I just want to tell you that the reference return is applicable to the case where the return object has not been destroyed when it is out of the function scope.
🌰:
int& Count()
{
static int n = 0;
n++;
return n;
}
n is a static variable, which is placed in the static area. If it is out of the function scope, it will not be destroyed. At this time, it can be returned by reference.
Let's look at a reference application
const int N = 10;
int& At(int i)
{
static int a[N];
return a[i];
}
int main()
{
for(int i = 0;i<N;i++)
{
At(i) = 10+i;//write in
}
for(int i = 0;i<N;i++)
{
cout<<At(i)<<" ";//read out
}
cout<<endl;
}
Writing this is equivalent to writing a value to a function. However, if the & in the At function is removed, an error will occur, because the value of At(i) after removal is a temporary variable, which has a constant attribute and is an R-value.
6.4 comparison of value transfer and reference transfer efficiency
Taking value as a parameter or return value type, during parameter transfer and return, the function will not directly transfer the argument or return the variable itself, but transfer a temporary copy of the argument or return variable. Therefore, using value as a parameter or return value type is very inefficient, especially when the parameter or return value type is very large.
Therefore, when there is a lot of data to be processed, it is more efficient to pass parameters and return values by reference.
6.5 frequently cited
//Permission amplification const int a = 10; int& b = a;
Is there a problem with this code?
The answer is yes.
A has been given a constant attribute, and then b becomes a reference to A. as long as there is no const in front of the type, it can be modified by default, so add a const before int.
//Permission unchanged const int a = 10; const int& b = a;
The meaning of this code is that the values of a and b are 10, and b is a constant reference of a and cannot be changed.
This situation is also supported
//Permission reduction int c = 10; const int& d = c;
There is another piece of constant attribute that needs attention
//1. double d = 11.98; int i = d; //2. double d = 11.98; int& i = d; //3. double d = 11.98; const int& i = d;
What is the difference between these three ways of writing?
First of all, let's look at the first one. Assign d of double type to d of int type. We've seen in C linguistics that this is allowed, but d will be truncated. What's the truncation process like? In fact, the truncated part of d will be stored in a temporary variable and then assigned to i. In this way, you will find that the second writing method is problematic. Why? Similarly, the truncated part is stored in the temporary variable and i is used as the reference of the temporary variable, but the temporary variable has a constant attribute and cannot be modified, so the third writing method is correct.
After learning this, we found that const type & takes all types and can receive variables of any type.
Therefore, we recommend that const & be used if the value of the parameter is not changed in the function.
6.6 difference between pointer and reference
- References must be initialized when defined, and pointers are not required
- After a reference references an entity during initialization, it can no longer reference other entities, and the pointer can point to any entity of the same type at any time
- There is no NULL reference, but there is a NULL pointer
- In sizeof, the meaning is different: the reference result is the size of the reference type, but the pointer is always the number of bytes in the address space (in 32-bit platform)
(4 bytes) - Reference self addition means that the referenced entity increases by 1, and pointer self addition means that the pointer is offset by one type backward
- There are multi-level pointers, but there are no multi-level references
- The access to entities is different. The pointer needs to be explicitly dereferenced, and the reference compiler handles it by itself
- References are relatively safer to use than pointers
7. Inline function
7.1 inline function concept
The function decorated with inline is called inline function. During compilation, the C + + compiler will expand where the inline function is called, without the overhead of function stack. The inline function improves the efficiency of program operation.
For example 🌰:
inline int Add(int x,int y)
{
ret = x+y;
return ret;
}
int main()
{
int ret = Add(1,2);
cout<<ret<<endl;
}
At this time, the compiler will not call functions, that is, it will not create stack frames, but expand the contents of the functions, which is a bit similar to macro replacement.
With the inline function, we don't need to use the macro of C, because the macro is very complex and easy to make mistakes.
7.2 inline function properties
- Inline is a method of exchanging space for time, which saves the cost of calling functions. Therefore, functions with long code or loop / recursion are not suitable for inline functions.
- Inline is only a suggestion for the compiler. The compiler will optimize automatically. If there are loops / recursions in the function defined as inline, the compiler will ignore inline during optimization.
- Inline does not recommend the separation of declaration and definition, which will lead to link errors. Because the inline is expanded, there will be no function address, and the link will not be found.