Process of document analysis
- Divide the document into separate entries suitable for inverted indexing
- Unify entries into a standard format, such as removing tenses from English
When the analyzer executes the above contents, it actually encapsulates the above functions into a package
Character filter: pass the string through each character filter in order, sort the string before word segmentation, and a character filter is used to remove html or convert & into and
Word splitter: the string is divided into single entries by the word splitter. When a simple word splitter encounters spaces and punctuation marks, it will split the text into entries
Token filter: entries pass through each token filter in order May change entries, lowercase, delete useless entries, add synonyms, etc
es built in analyzer:
Standard analyzer
Simple analyzer
Space Analyzer
Language analyzer
Usage scenario of analyzer:
Disassemble the text
Index a document. The full-text field of the document is analyzed into terms to create an inverted index,
When searching, the query string is passed through the same analysis process to ensure that the search entry format is consistent with the entry in the index
Test word splitter
Test standard word splitter
Start the es of windows and send the following get request:
http://localhost:9200/_analyze
The request body is as follows
{
"analyzer": "standard",
"text": "Text to analyze"
}
The response is as follows You can see that it is divided into words
{
"tokens": [
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "analyze",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 2
}
]
}
Specify parser
IK word splitter
If the default word splitter is used and Chinese is used, the following effects will be achieved
Chinese is divided into words one by one
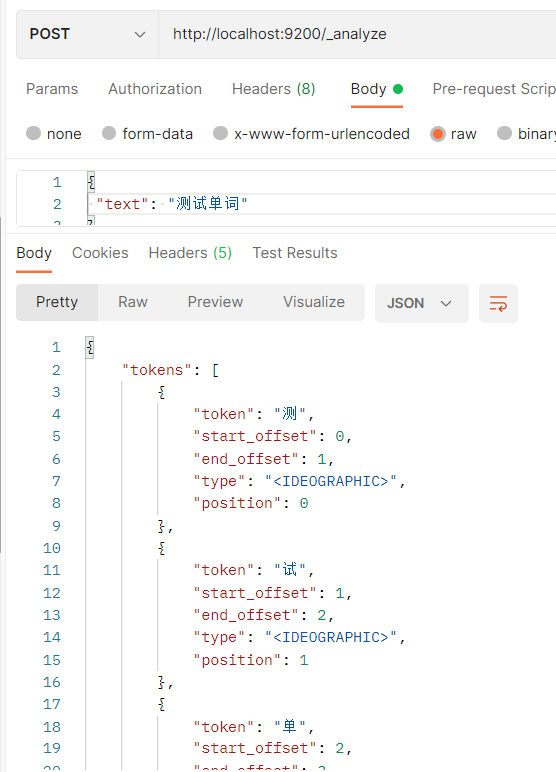
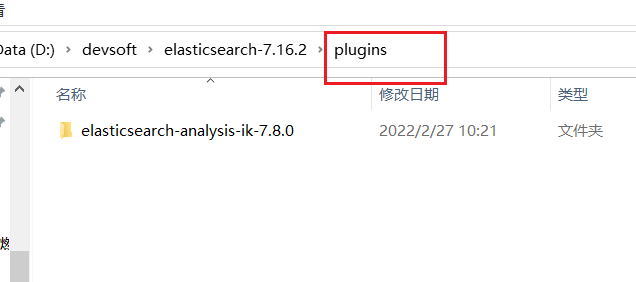
IK Chinese word splitter is adopted, and the download address is:
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.8.0
Unzip the file and put it in the plugin directory of ES, and then restart es
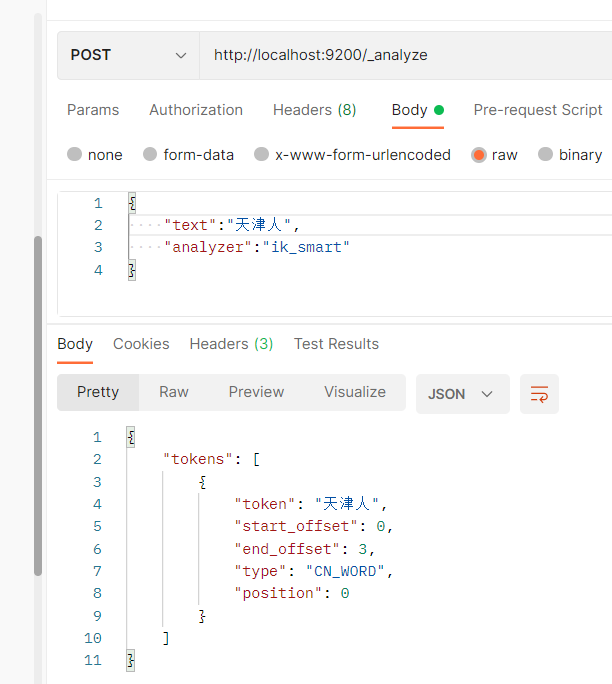
Send a post request, http://localhost:9200/_analyze , the request body is as follows
{
"text":"Test words",
"analyzer":"ik_max_word"
}
As a result, we can see that the words are segmented

ik_max_word: the most fine-grained split
ik_smart: the coarsest granularity split
The differences between the two word splitters are as follows ik_max_word splitting is more detailed
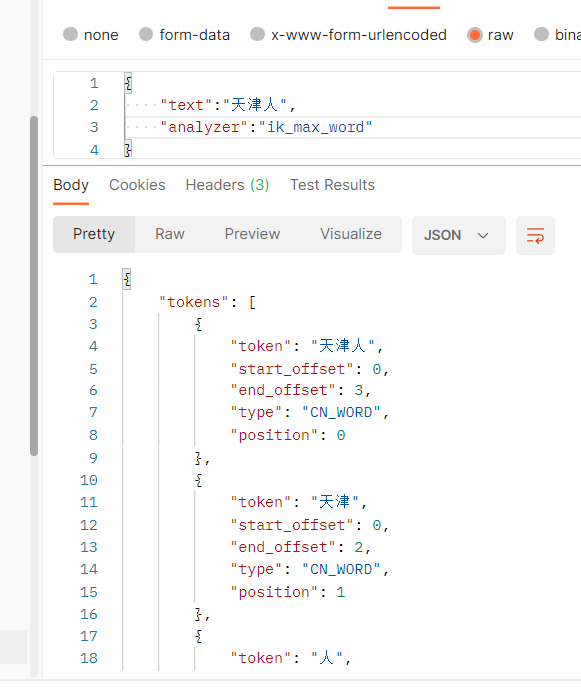
IK word breaker extended vocabulary
In the directory of ik participle,
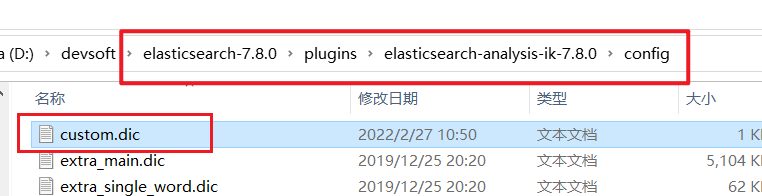
Create a new custom DIC file Fill in the following words for the contents of the document
Freldrod
At ikanalyzer cfg. XML Set the location of the extended vocabulary 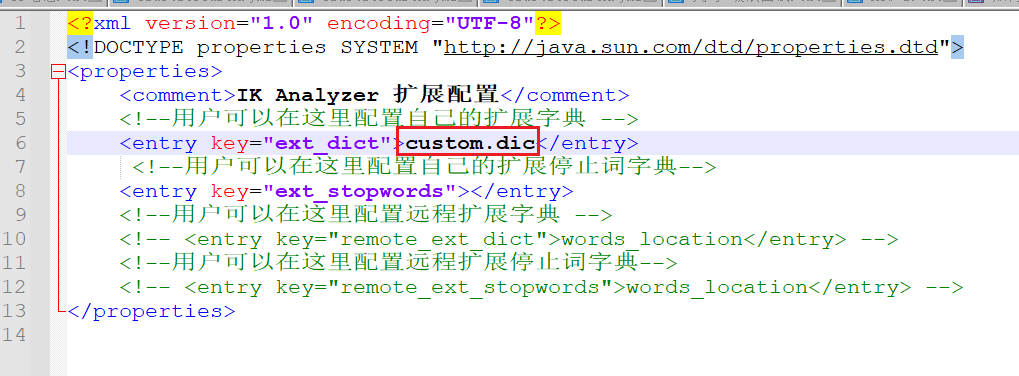
Then restart es and test it
{
"text": "freichrod",
"analyzer":"ik_max_word"
}
The results are as follows: the extended words are successfully associated
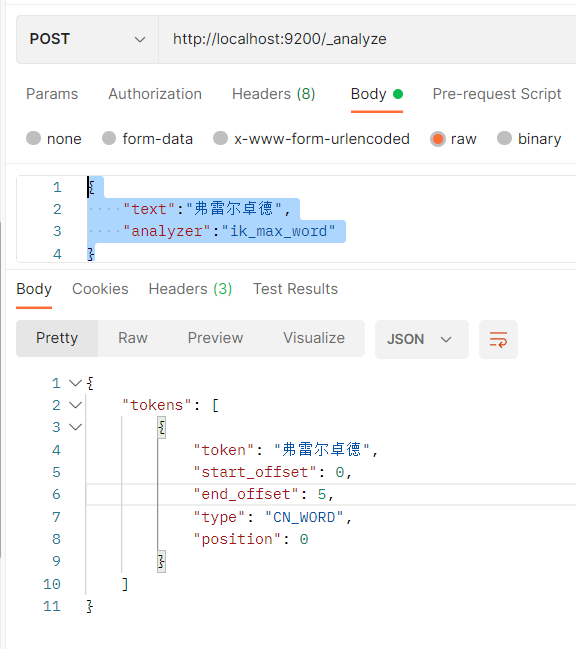
Custom analyzer
Set your own character filter, word splitter and vocabulary unit filter to create a custom analyzer
Using the put request, create the following index to know the relevant configuration of the analyzer
http://localhost:9200/my_index
The body of the request is as follows:
{
"settings":{
"analysis":{
"char_filter":{
"&_to_and":{
"type":"mapping",
"mappings":[
"&=> and " // Convert & into and
]
}
},
"filter":{
"my_stopwords":{
"type":"stop",
"stopwords":[
"the",
"a"
]
}
},
"analyzer":{
"my_analyzer":{ // The name of the word breaker
"type":"custom", // Word breaker type, here is a custom word breaker
"char_filter":[ // Character filter
"html_strip",
"&_to_and"
],
"tokenizer":"standard", // Use a standard word splitter
"filter":[ // Use character filter
"lowercase",
"my_stopwords"
]
}
}
}
}
}
Test:
# GET http://127.0.0.1:9200/my_index/_analyze
{
"text":"The quick & brown fox",
"analyzer": "my_analyzer"
}
The word segmentation results are as follows
{
"tokens": [
{
"token": "quick",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "and",
"start_offset": 10,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "fox",
"start_offset": 18,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 4
}
]
}
You can see that the is not segmented because it is a stop word
And & becomes and