let and const of ES6 series
Occurrence of block level scope
Variables declared through var have the characteristics of variable promotion:
if (condition) {
var value = 1;
}
console.log(value);
Beginners may think that value can be created only when condition is true. If condition is false, the result should be an error. However, due to variable promotion, the code is equivalent to:
var value;
if (condition) {
value = 1;
}
console.log(value);
If condition is false, the result will be undefined.
In addition, in the for loop:
for (var i = 0; i < 10; i++) {
...
}
console.log(i); // 10
Even if the loop is over, we can still access the value of i.
In order to strengthen the control of variable life cycle, ECMAScript 6 introduces block level scope.
Block level scopes exist in:
- Function inside
- Block (area between characters {and})
let and const
Block level declarations are used to declare variables that cannot be accessed outside the scope of the specified block.
let and const are both block level declarations.
Let's review the features of let and const:
1. Not promoted
if (false) {
let value = 1;
}
console.log(value); // Uncaught ReferenceError: value is not defined
2. Repeated declaration and error reporting
var value = 1; let value = 2; // Uncaught SyntaxError: Identifier 'value' has already been declared
3. Do not bind global scope
When var declaration is used in the global scope, a new global variable will be created as the attribute of the global object.
var value = 1; console.log(window.value); // 1
However, let and const do not:
let value = 1; console.log(window.value); // undefined
Let's talk about the difference between let and const:
const is used to declare a constant. Once its value is set, it cannot be modified, otherwise an error will be reported.
It is worth mentioning that the const declaration does not allow modification of bindings, but allows modification of values. This means that when you declare an object with const:
const data = {
value: 1
}
// no problem
data.value = 2;
data.num = 3;
// report errors
data = {}; // Uncaught TypeError: Assignment to constant variable.
Temporary dead zone
Temporary dead zone, abbreviated as TDZ.
let and const declared variables will not be promoted to the top of the scope. If these variables are accessed before declaration, an error will be reported:
console.log(typeof value); // Uncaught ReferenceError: value is not definedlet value = 1;
This is because when the JavaScript engine scans the code and finds variable declarations, it either promotes them to the top of the scope (encounters var declarations) or places the declarations in TDZ (encounters let and const declarations). Accessing variables in the TDZ triggers a runtime error. Only after the variable declaration statement has been executed will the variable be moved out of the TDZ and then accessible.
It seems well understood and does not guarantee that you will not make mistakes:
var value = "global";// Example 1 (function() {console.log (value); let value = 'local';} ());// Example 2 {console.log (value); const value = 'local';};
In the two examples, the result will not print "global", but will report an error Uncaught ReferenceError: value is not defined because of TDZ.
Block level scope in loop
var funcs = [];for (var i = 0; i < 3; i++) { funcs[i] = function () { console.log(i); };}funcs[0](); // 3
An old interview question, the solution is as follows:
var funcs = [];for (var i = 0; i < 3; i++) { funcs[i] = (function(i){ return function() { console.log(i); } }(i))}funcs[0](); // 0
The let of ES6 provides a new solution to this problem:
var funcs = [];for (let i = 0; i < 3; i++) { funcs[i] = function () { console.log(i); };}funcs[0](); // 0
The problem is that the let is not promoted, cannot be declared repeatedly, cannot bind to the global scope and other features, but why can the i value be printed correctly here?
If you do not repeat the declaration and declare i with let the second time of the loop, you should report an error. Even if you repeat the declaration without reporting an error for some reason, and iterate over and over again, the value of i should eventually be 3. Others say that the part of the for loop that sets the loop variable is a separate scope, such as:
for (let i = 0; i < 3; i++) { let i = 'abc'; console.log(i);}// abc// abc// abc
This example is correct. What if we change let to var?
for (var i = 0; i < 3; i++) { var i = 'abc'; console.log(i);}// abc
Why is the result different? If there is a separate scope, the result should be the same
If we want to investigate this problem, we must abandon these characteristics! This is because the behavior of the let declaration inside the loop is specifically defined in the standard, which is not necessarily related to the non promotion feature of the let. In fact, this behavior is not included in the early let implementation.
Let's see ECMAScript specification section 13.7 Section 4.7:
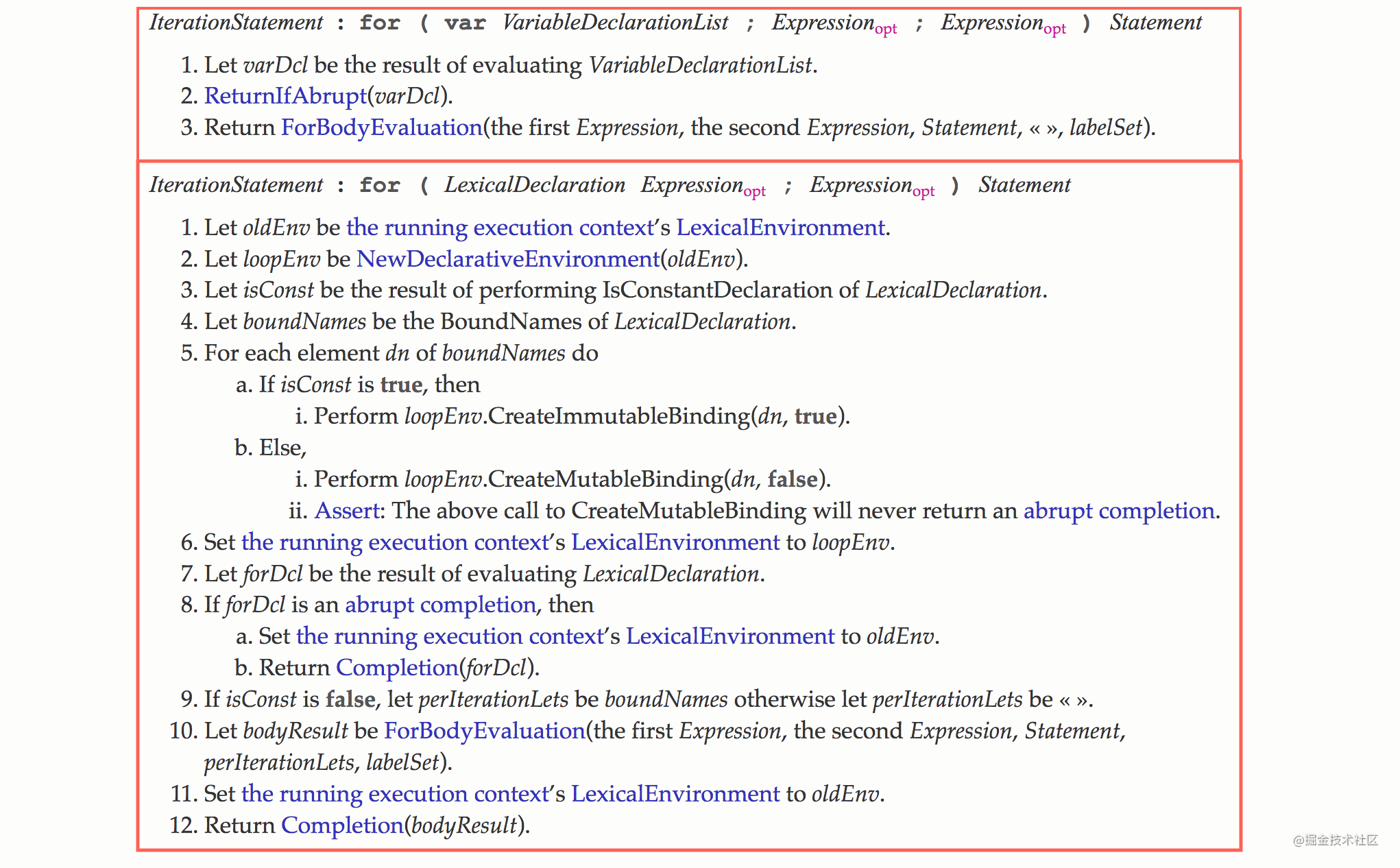
We will find that using let and var in the for loop will use different processing methods at the bottom.
So what does the bottom layer do when using let s?
Simply put, a hidden scope is established in for (let I = 0; I < 3; I + +), that is, within parentheses, which can explain why:
for (let i = 0; i < 3; i++) { let i = 'abc'; console.log(i);}// abc// abc// abc
Then, each iteration of the loop creates a new variable and initializes it with the value of the variable with the same name in the previous iteration. So for the following code
var funcs = [];for (let i = 0; i < 3; i++) { funcs[i] = function () { console.log(i); };}funcs[0](); // 0
It is equivalent to:
// Pseudo code (let I = 0) {functions [0] = function() {console. Log (I)};} (let i = 1) { funcs[1] = function() { console.log(i) };} (let i = 2) { funcs[2] = function() { console.log(i) };};
When the function is executed, the correct value can be found according to the lexical scope. In fact, you can also understand that the let declaration imitates the closure to simplify the loop process.
let and const in loop
But it's not over yet. What if we change let to const?
var funcs = [];for (const i = 0; i < 10; i++) { funcs[i] = function () { console.log(i); };}funcs[0](); // Uncaught TypeError: Assignment to constant variable.
The result will be an error, because although we create a new variable every time, we try to modify the value of const in the iteration, so we will eventually report an error.
Having finished the ordinary for loop, we still have the for in loop~
What are the following results?
var funcs = [], object = {a: 1, b: 1, c: 1};for (var key in object) { funcs.push(function(){ console.log(key) });}funcs[0]()
The result is' c ';
What if we change var to let or const?
Using let, the result will naturally be 'a'. What about const? Error or 'a'?
The result is that 'a' is printed correctly, because in the for in loop, each iteration does not modify the existing binding, but creates a new binding.
Babel
How to compile let and const in Babel? Let's look at the compiled code:
let value = 1;
Compile as:
var value = 1;
We can see that Babel directly compiles let into var. if so, let's write an example:
if (false) { let value = 1;}console.log(value); // Uncaught ReferenceError: value is not defined
If you still compile it directly into var, the printed result must be undefined. However, Babel is very smart. It compiles into:
if (false) { var _value = 1;}console.log(value);
Let's write another intuitive example:
let value = 1;{ let value = 2;}value = 3;
var value = 1;{ var _value = 2;}value = 3;
The essence is the same, that is, change the quantity name to make the variable names inside and outside different.
How do you report errors like const's modified values and repeated statements?
In fact, it directly reports errors to you when compiling
What about the let declaration in the loop?
var funcs = [];for (let i = 0; i < 10; i++) { funcs[i] = function () { console.log(i); };}funcs[0](); // 0
Babel cleverly compiled into:
var funcs = [];var _loop = function _loop(i) { funcs[i] = function () { console.log(i); };};for (var i = 0; i < 10; i++) { _loop(i);}funcs[0](); // 0
Best practices
When we develop, we may think that let should be used by default instead of var. in this case, const should be used for variables that need write protection. However, another approach is becoming more and more popular: const is used by default, and let is used only when it is really necessary to change the value of the variable. This is because the values of most variables should not change after initialization, and unexpected changes in variables are the source of many bug s.
Template string of ES6 series
Basic usage
let message = `Hello World`;console.log(message);
If you happen to want to use a backslash in a string, you can escape with a backslash:
let message = `Hello \` World`;console.log(message);
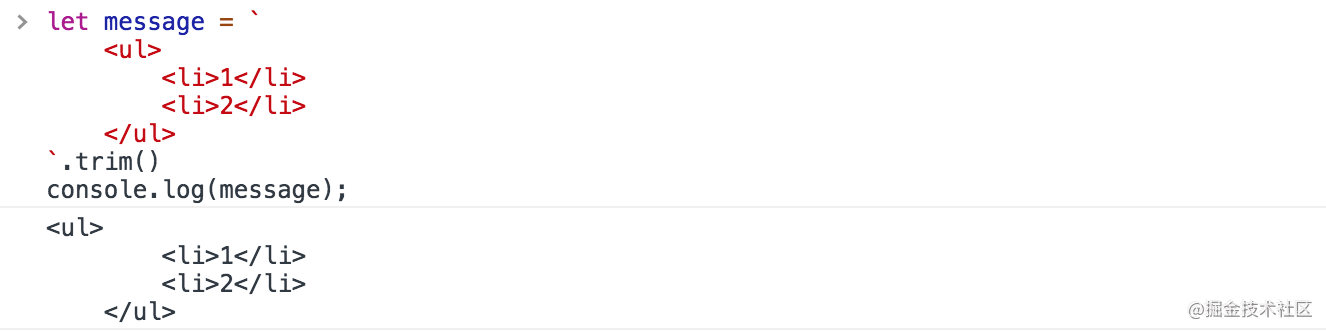
It is worth mentioning that in the template string, spaces, indents and newlines will be retained:
let message = ` <ul> <li>1</li> <li>2</li> </ul>`;console.log(message);

Note that the first line in the printed result is a newline. You can use the trim function to eliminate the newline:
let message = ` <ul> <li>1</li> <li>2</li> </ul>`.trim();console.log(message);
Embedded variable
The template string supports embedded variables. You only need to write the variable name in ${}. In fact, not only variables, but any JavaScript expression is OK:
let x = 1, y = 2;let message = `<ul><li>${x}</li><li>${x + y}</li></ul>`;console.log(message); // <ul><li>1</li><li>3</li></ul>
It is worth mentioning that Template Strings support nesting:
let arr = [{value: 1}, {value: 2}];let message = ` <ul> ${arr.map((item) => { return ` <li>${item.value}</li> ` })} </ul>`;console.log(message);
The printing results are as follows:

Note that there is a comma in the middle of the li tag. This is because when the value in braces is not a string, it will be converted to a string. For example, an array [1, 2, 3] will be converted to 1,2,3. This is how commas are generated.
If you want to eliminate this comma, you can join it first:
let arr = [{value: 1}, {value: 2}];let message = ` <ul> ${arr.map((item) => { return ` <li>${item.value}</li> ` }).join('')} </ul>`;console.log(message);
The printing results are as follows:

Label template
Template tag is a very important capability. The template string can be immediately followed by a function name, which will be called to process the template string, for example:
let x = 'Hi', y = 'Kevin';var res = message`${x}, I am ${y}`;console.log(res);
We can customize the message function to handle the returned string:
// Literals text / / note that in this example, the first and last elements of literals are empty strings function message(literals, value1, value2){ console.log(literals); // [ "", ", I am ", "" ] console.log(value1); // Hi console.log(value2); // Kevin}
We use these parameters to put it back together:
function message(literals, ...values) { let result = ''; for (let i = 0; i < values.length; i++) { result += literals[i]; result += values[i]; } result += literals[literals.length - 1]; return result;}
You can also write:
function message(literals, ...values) { let result = literals.reduce((prev, next, i) => { let value = values[i - 1]; return prev + value + next; }); return result;}
Learning to put it back together is a very important thing, because we have to put it back after all kinds of processing
oneLine
After talking about the basics, we can look at some actual requirements:
let message = ` Hi, Daisy! I am Kevin.`;
For readability or other reasons, I want to wrap lines when writing, but the final output characters are on one line, which needs to be realized with the help of template tags. We try to write a function like this:
// oneLine first version function oneLine (template,... Expressions) {let result = template. Reduce ((prev, next, I) = > {let expression = expressions [I - 1]; return prev + expression + next;}); result = result. replace(/(\s+)/g, " "); result = result. trim(); return result;}
The implementation principle is very simple. Put it back together, and then replace multiple blank characters such as newline character and space with a space.
Use the following:
let message = oneLine ` Hi, Daisy! I am Kevin.`;console.log(message); // Hi, Daisy! I am Kevin.
But if you continue, you will find a problem. What if there are multiple spaces between characters? for instance:
let message = oneLine` Preserve eg sentences. Double spaces within input lines.`;
If this matching method is used, sentances The two spaces between and Double are also replaced with one space.
We can optimize it again. The effect we want is to replace multiple spaces in front of each line with one space. In fact, what should match is the newline character and multiple spaces after the newline character, and then replace it with one space. We can change the regular to:
result = result.replace(/(\n\s*)/g, " ");
You can match the code correctly. The final code is as follows:
// oneLine version 2 function oneLine (template,... Expressions) {let result = template. Reduce ((prev, next, I) = > {let expression = expressions [I - 1]; return prev + expression + next;}); result = result. replace(/(\n\s*)/g, " "); result = result. trim(); return result;}
stripIndents
Suppose there is such HTML:
let html = ` <span>1<span> <span>2<span> <span>3<span>`;
In order to maintain readability, I want the final input style to be:
<span>1<span><span>2<span><span>3<span>
It's actually matching the space in front of each line and replacing it with an empty string.
// Stripindexes function stripindexes (template,... Expressions) {let result = template. Reduce ((prev, next, I) = > {let expression = expressions [I - 1]; return prev + expression + next;}); result = result. replace(/\n[^\S\n]*/g, '\n'); result = result. trim(); return result;}
Perhaps the most difficult is this regular expression:
result = result.replace(/\n[^\S\n]*/g, '\n');
\S means to match a non white space character
[^ \ S\n] means to match characters other than non white space characters and line breaks. In fact, white space characters remove line breaks
\n[^\S\n] * indicates that line breaks are matched and multiple white space characters after line breaks do not contain line breaks
replace(/\n[^\S\n]*/g, '\n') means to replace a newline character and multiple blank characters after the newline character that do not contain a newline character with a newline character. In fact, it means to eliminate the blank characters after the newline character
In fact, it doesn't need to be so troublesome. We can also write as follows:
result = result.replace(/^[^\S\n]+/gm, '');
It seems a little simpler. The reason why it can be written like this is because of the matching pattern. You will find that this time, in addition to matching the global, we also matched multiple lines. The m flag is used to specify that multiple lines of input string should be regarded as multiple lines. Moreover, if the m flag is used, the beginning or end of ^ and $matching is each line in the input string, Not the beginning or end of the entire string.
[^ \ S\n] indicates matching white space characters and removing line breaks
[\ S\n] + indicates that one or more characters starting with the white space character excluding the newline character are matched
result.replace(/[\S\n]+/gm, ') means to replace one or more white space characters at the beginning of each line with an empty string.
The final code is as follows:
// Stripindexes second edition function stripindexes (template,... Expressions) {let result = template. Reduce ((prev, next, I) = > {let expression = expressions [I - 1]; return prev + expression + next;}); result = result. replace(/^[^\S\n]+/gm, ''); result = result. trim(); return result;}
stripIndent
Note that the stripIndent is one letter less than the title of the previous section, and the functions we want to achieve are:
let html = ` <ul> <li>1</li> <li>2</li> <li>3</li> <ul>`;
In fact, it is to remove the newline of the first line and the partial indentation of each line.
This implementation is a little troublesome because we have to calculate how many white space characters to remove in each line.
The realization idea is as follows:
- Use the match function to match the white space characters of each line to get an array containing the white space characters of each line
- The array is traversed and compared to obtain the minimum length of white space characters
- Build a regular expression and replace the minimum length of white space characters on each line
The implementation code is as follows:
let html = ` <ul> <li>1</li> <li>2</li> <li>3</li> <ul>`;function stripIndent(template, ...expressions) { let result = template.reduce((prev, next, i) => { let expression = expressions[i - 1]; return prev + expression + next; }); const match = result.match(/^[^\S\n]*(?=\S)/gm); console.log(match); // Array [ " ", " ", " ", " ", " " ] const indent = match && Math.min(...match.map(el => el.length)); console.log(indent); // 4 if (indent) { const regexp = new RegExp(`^.{${indent}}`, 'gm'); console.log(regexp); // /^.{4}/gm result = result.replace(regexp, ''); } result = result.trim(); return result;}
It is worth mentioning that we generally think that regular is in Means to match any character. In fact, it matches any single character except the newline character.
The final simplified code is as follows:
function stripIndent(template, ...expressions) { let result = template.reduce((prev, next, i) => { let expression = expressions[i - 1]; return prev + expression + next; }); const match = result.match(/^[^\S\n]*(?=\S)/gm); const indent = match && Math.min(...match.map(el => el.length)); if (indent) { const regexp = new RegExp(`^.{${indent}}`, 'gm'); result = result.replace(regexp, ''); } result = result.trim(); return result;}
includeArrays
We mentioned earlier that in order to avoid returning an array in the ${} expression, automatic conversion will lead to multiple commas. We need to join the array at the end ('') every time and look at the example again:
let arr = [{value: 1}, {value: 2}];let message = ` <ul> ${arr.map((item) => { return ` <li>${item.value}</li> ` }).join('')} </ul>`;console.log(message);
Using the label template, we can easily solve this problem:
function includeArrays(template, ...expressions) { let result = template.reduce((prev, next, i) => { let expression = expressions[i - 1]; if (Array.isArray(expression)) { expression = expression.join(''); } return prev + expression + next; }); result = result.trim(); return result;}
Arrow function of ES6 series
review
Let's first review the basic syntax of the down arrow function.
ES6 adds the arrow function:
let func = value => value;
amount to:
let func = function (value) { return value;};
If you need to pass in multiple parameters to a function:
let func = (value, num) => value * num;
If the code block of a function requires multiple statements:
let func = (value, num) => { return value * num};
If you need to return an object directly:
let func = (value, num) => ({total: value * num});
Combined with variable deconstruction:
let func = ({value, num}) => ({total: value * num})// Use VaR result = func ({value: 10, Num: 10}) console log(result); // {total: 100}
Many times, you may not expect to use it like this, so let's take another example. For example, in the technology selection of React and Immutable, we will do this when dealing with an event:
handleEvent = () => { this.setState({ data: this.state.data.set("key", "value") })};
In fact, it can be simplified to:
handleEvent = () => { this.setState(({data}) => ({ data: data.set("key", "value") }))};
compare
In this article, we focus on comparing arrow functions with ordinary functions.
The main differences include:
1. No this
The arrow function does not have this, so you need to find the scope chain to determine the value of this.
This means that if the arrow function is included by a non arrow function, this is bound to the this of the nearest non arrow function.
Simulate an example in actual development:
Our requirement is to click a button to change the background color of the button.
In order to facilitate development, we extract a Button component and directly:
// Pass in the element id value to bind the event new Button("button") that changes the background color when the element is clicked
The HTML code is as follows:
<button id="button">Click color change</button>
The JavaScript code is as follows:
function Button(id) { this.element = document.querySelector("#" + id); this.bindEvent();}Button.prototype.bindEvent = function() { this.element.addEventListener("click", this.setBgColor, false);};Button.prototype.setBgColor = function() { this.element.style.backgroundColor = '#1abc9c'};var button = new Button("button");
It seems that there is no problem, but the result is an error: cannot read property 'style' of undefined
This is because when using addEventListener() to register an event for an element, the value of this in the event function is the reference of the element.
So if we are in setBgColor, console Log (this), this refers to the button element, this Element is undefined. It is natural to report an error.
You may ask, since this points to the button element, we can directly modify the setBgColor function to:
Button.prototype.setBgColor = function() { this.style.backgroundColor = '#1abc9c'};
Can't we solve this problem?
We can do this, but in actual development, we may call other functions in setBgColor, such as writing this:
Button.prototype.setBgColor = function() { this.setElementColor(); this.setOtherElementColor();};
Therefore, we still want this in setBgColor to point to the instance object, so that other functions can be called.
With ES5, we generally do this:
Button.prototype.bindEvent = function() { this.element.addEventListener("click", this.setBgColor.bind(this), false);};
To avoid the influence of addEventListener, bind is used to forcibly bind this of setBgColor() as the instance object
Using ES6, we can better solve this problem:
Button.prototype.bindEvent = function() { this.element.addEventListener("click", event => this.setBgColor(event), false);};
Since the arrow function does not have this, it will look for the value of this in the outer layer, that is, this in bindEvent. At this time, this points to the instance object, so you can call this correctly Setbgcolor method, and this This in setbgcolor will also point to the instance object correctly.
An additional point here is to note that bindEvent and setBgColor use the form of ordinary functions instead of arrow functions. If we change to arrow functions, this in the functions will point to window objects (in non strict mode).
Finally, because the arrow function does not have this, you can't change the direction of this by using call(), apply(), bind(). See an example:
var value = 1;var result = (() => this.value).bind({value: 2})();console.log(result); // 1
2. No arguments
The arrow function does not have its own arguments object, which is not necessarily a bad thing, because the arrow function can access the arguments object of the peripheral function:
function constant() { return () => arguments[0]}var result = constant(1);console.log(result()); // 1
What if we just want to access the parameters of the arrow function?
You can access parameters in the form of named parameters or rest parameters:
let nums = (...nums) => nums;
3. Cannot be called through the new keyword
JavaScript functions have two internal methods: [[Call]] and [[Construct]].
When calling a function through new, execute the [[Construct]] method to create an instance object, and then execute the function body to bind this to the instance.
When calling directly, execute the [[Call]] method to directly execute the function body.
The arrow function has no [[Construct]] method and cannot be used as a constructor. If it is called through new, an error will be reported.
var Foo = () => {};var foo = new Foo(); // TypeError: Foo is not a constructor
4. No new target
Because new cannot be called, there is no new Target value.
About new Target, you can refer to es6.ruanyifeng.com/#docs/class...
5. No prototype
Since the arrow function cannot be called with new, there is no need to build a prototype, so the arrow function does not have the attribute prototype.
var Foo = () => {};console.log(Foo.prototype); // undefined
6. No super
Even if there is no prototype, the properties of the prototype cannot be accessed through super, so the arrow function does not have super, but it is similar to this, arguments and new Like target, these values are determined by the nearest non arrow function on the periphery.
summary
Finally, about the arrow function, the introduction of referencing MDN is as follows:
An arrow function expression has a shorter syntax than a function expression and does not have its own this, arguments, super, or new.target. These function expressions are best suited for non-method functions, and they cannot be used as constructors.
Translated as:
The syntax of the arrow function expression is shorter than the function expression, and does not bind its own this, arguments, super, or new target. These function expressions are best used for non method functions, and they cannot be used as constructors.
So what is non method functions?
Let's first look at the definition of method:
A method is a function which is a property of an object.
The function in the object attribute is called method, so non mehtod means that it is not used as the function in the object attribute, but why is the arrow function more suitable for non method?
Let's take a look at an example to understand:
var obj = { i: 10, b: () => console.log(this.i, this), c: function() { console.log( this.i, this) }}obj.b();// undefined Windowobj.c();// 10, Object {...}
Self executing function
The form of self executing function is:
(function(){ console.log(1)})()
perhaps
(function(){ console.log(1)}())
Use arrows to simplify the writing of self executing functions:
(() => { console.log(1)})()
However, please note that an error will be reported if the following expression is used:
(() => { console.log(1)}())
Why do you report an error?
Symbol type of simulation implementation of ES6 series
preface
In fact, many features of Symbol cannot be simulated... So let's first review what features are available, and then pick something that can be implemented... Of course, in the process of watching, you can also think about whether this feature can be implemented, and if so, how to implement it.
review
ES6 introduces a new primitive data type Symbol, which represents unique values.
1. The symbol value is generated through the symbol function, typeof is used, and the result is "symbol"
var s = Symbol();console.log(typeof s); // "symbol"
2. The new command cannot be used before the Symbol function, otherwise an error will be reported. This is because the generated Symbol is a value of the original type, not an object.
3. The result of instanceof is false
var s = Symbol('foo');console.log(s instanceof Symbol); // false
4. The Symbol function can accept a string as a parameter to represent the description of the Symbol instance, which is mainly for easy identification when displayed on the console or converted to a string.
var s1 = Symbol('foo');console.log(s1); // Symbol(foo)
5. If the Symbol parameter is an object, the toString method of the object will be called to convert it into a string, and then a Symbol value will be generated.
const obj = { toString() { return 'abc'; }};const sym = Symbol(obj);console.log(sym); // Symbol(abc)
6. The parameters of the Symbol function only represent the description of the current Symbol value. The return values of the Symbol function with the same parameters are not equal.
// If there are no parameters, var s1 = Symbol();var s2 = Symbol();console.log(s1 === s2); // false / / with parameters, var s1 = Symbol('foo');var s2 = Symbol('foo');console.log(s1 === s2); // false
7. Symbol value cannot be calculated with other types of values, and an error will be reported.
var sym = Symbol('My symbol');console.log("your symbol is " + sym); // TypeError: can't convert symbol to string
8. The symbol value can be explicitly converted to a string.
var sym = Symbol('My symbol');console.log(String(sym)); // 'Symbol(My symbol)'console.log(sym.toString()); // 'Symbol(My symbol)'
9. The symbol value can be used as an identifier for the attribute name of the object to ensure that there will be no attributes with the same name.
var mySymbol = Symbol();// The first is var a = {};a[mySymbol] = 'Hello!';// The second way to write var a = {[mysymbol]: 'Hello!'}// The third way is var a = {};Object.defineProperty(a, mySymbol, { value: 'Hello!' });// The same result is obtained with the above writing method log(a[mySymbol]); // "Hello!"
10. Symbol is used as the attribute name. This attribute will not appear in the for... In and for... Of loops, nor will it be used by object keys(),Object.getOwnPropertyNames(),JSON.stringify() returns. However, it is not a private property. It has an object Getownpropertysymbols method can obtain all symbol property names of the specified object.
var obj = {};var a = Symbol('a');var b = Symbol('b');obj[a] = 'Hello';obj[b] = 'World';var objectSymbols = Object.getOwnPropertySymbols(obj);console.log(objectSymbols);// [Symbol(a), Symbol(b)]
11. If we want to use the same Symbol value, we can use Symbol for. It takes a string as a parameter and then searches for a Symbol value with that parameter as its name. If yes, this Symbol value will be returned. Otherwise, a new Symbol value with the name of this string will be created and returned.
var s1 = Symbol.for('foo');var s2 = Symbol.for('foo');console.log(s1 === s2); // true
12. Symbol. The keyfor method returns a key of a registered symbol type value.
var s1 = Symbol.for("foo");console.log(Symbol.keyFor(s1)); // "foo"var s2 = Symbol("foo");console.log(Symbol.keyFor(s2) ); // undefined
analysis
After reading the above features, which features do you think can be simulated and implemented?
If we want to simulate the implementation of a Symbol, the basic idea is to build a Symbol function and directly return a unique value.
But before that, let's take a look standard What exactly did you do when calling Symbol?
Symbol ( [ description ] )
When Symbol is called with optional argument description, the following steps are taken:
- If NewTarget is not undefined, throw a TypeError exception.
- If description is undefined, var descString be undefined.
- Else, var descString be ToString(description).
- ReturnIfAbrupt(descString).
- Return a new unique Symbol value whose [[Description]] value is descString.
When calling Symbol, the following steps will be taken:
- If new is used, an error is reported
- If description is undefined, let descString be undefined
- Otherwise, let descString be ToString(description)
- If an error is reported, return
- Returns a new and unique Symbol value whose internal attribute [[Description]] value is descString
Considering that we also need to define a [[Description]] attribute, we can't do this if we directly return a value of basic type, so we finally return an object.
first edition
Referring to the specifications, we can actually start writing:
// Version 1 (function() {var root = this; VAR symbolpolyfill = function Symbol (description) {/ / implement feature point 2: you cannot use the new command if (this instanceof SymbolPolyfill) throw new TypeError('Symbol is not a constructor ') before the Symbol function ; // Implementation feature point 5: if the Symbol parameter is an object, the toString method of the object will be called to convert it into a string, and then a Symbol value will be generated. var descString = description === undefined ? undefined : String(description) var symbol = Object.create(null) Object.defineProperties(symbol, { '__Description__': { value: descString, writable: false, enumerable: false, configurable: false } }); // Implement point 6 of the feature, because calling this method returns a new object. As long as the references between the two objects are different, they will not be the same return Symbol;} root. SymbolPolyfill = SymbolPolyfill;}) ();
Just referring to the specification, we have implemented points 2, 5 and 6 of the feature.
Second Edition
Let's see how to implement other features:
1. Use typeof and the result is "symbol".
With ES5, we can't modify the result of the typeof operator, so this can't be implemented.
3. The result of instanceof is false
Because it is not implemented through new, the result of instanceof is naturally false.
4. The Symbol function can accept a string as a parameter to represent the description of the Symbol instance. This is mainly to make it easier to distinguish when it is displayed on the console or converted to a string.
When printing a native Symbol value:
console.log(Symbol('1')); // Symbol(1)
However, when we simulate the implementation, an object is returned, so this cannot be implemented. Of course, you can modify the console Log is another method.
8. The symbol value can be explicitly converted to a string.
var sym = Symbol('My symbol');console.log(String(sym)); // 'Symbol(My symbol)'console.log(sym.toString()); // 'Symbol(My symbol)'
When calling the String method, if the object has a toString method, the toString method will be called. Therefore, we can achieve these two effects by adding a toString method to the returned object.
// Version 2 / / the code in the front is the same...... var symbol = object create({ toString: function() { return 'Symbol(' + this.__Description__ + ')'; },});// The following code is the same
Third Edition
9. The symbol value can be used as an identifier for the attribute name of the object to ensure that there will be no attributes with the same name.
It seems nothing. This actually conflicts with point 8. This is because when the so-called Symbol value we simulate is actually an object with toString method. When the object is used as the attribute name of the object, it will carry out implicit type conversion or call the toString method we added, Although the descriptions of Symbol('foo ') and Symbol('foo') are the same, they are not equal because they are two objects. However, when they are used as the attribute names of objects, they will be implicitly converted to Symbol(foo) strings. At this time, attributes with the same name will be created. for instance:
var a = SymbolPolyfill('foo');var b = SymbolPolyfill('foo');console.log(a === b); // falsevar o = {};o[a] = 'hello';o[b] = 'hi';console.log(o); // {Symbol(foo): 'hi'}
In order to prevent the occurrence of an attribute with the same Name, after all, this is a very important feature. As a last resort, we need to modify the toString method to return a unique value, so point 8 cannot be implemented. In addition, we need to write another method to generate a unique value, named generateName, We add this unique value to the Name property of the returned object and save it.
// Third Edition (function() {var root = this; VAR generatename = (function() {var postfix = 0; return function (descstring) {postfix + +; return '@ @' + descstring + '' + postfix}}) () var symbolpolyfill = function symbol (description) {if (this instanceof symbolpolyfill) throw new typeerror ('Symbol is not a constructor'); var descString = description === undefined ? undefined : String(description) var symbol = Object. create({ toString: function() { return this.__Name__; } }) Object. defineProperties(symbol, { '__Description__': { value: descString, writable: false, enumerable: false, configurable: false }, '__Name__': { value: generateName(descString) , writable: false, enumerable: false, configurable: false } }); return symbol; } root. SymbolPolyfill = SymbolPolyfill;}) ()
Here's another example:
var a = SymbolPolyfill('foo');var b = SymbolPolyfill('foo');console.log(a === b); // falsevar o = {};o[a] = 'hello';o[b] = 'hi';console.log(o); // Object { "@@foo_1": "hello", "@@foo_2": "hi" }
Fourth Edition
Let's look at the next features.
7.Symbol value cannot be calculated with other types of values, and an error will be reported.
Take the + operator as an example. When performing implicit type conversion, the valueOf method of the object will be called first. If the basic value is not returned, the toString method will be called again. Therefore, we consider reporting an error in the valueOf method, such as:
var symbol = Object.create({ valueOf: function() { throw new Error('Cannot convert a Symbol value') }})console.log('1' + symbol); // report errors
It looks like a simple solution to this problem, but what if we explicitly call the valueOf method? For a native Symbol value:
var s1 = Symbol('foo')console.log(s1.valueOf()); // Symbol(foo)
Yes, for a native Symbol, explicitly calling the valueOf method will directly return the Symbol value, and we can't judge whether it is an explicit or implicit call, so we can only implement half of this. Otherwise, we can implement the implicit call to report an error, or the explicit call to return the value. Then... Let's choose the one that doesn't report an error, that is, the latter.
We have to modify the valueOf function:
// Version 4 / / the code in the front is the same...... var symbol = object create({ toString: function() { return this.__Name__; }, valueOf: function() { return this; }});// The following code is the same
Fifth Edition
10. Symbol is used as the attribute name. This attribute will not appear in the for... In and for... Of loops, nor will it be used by object keys(),Object.getOwnPropertyNames(),JSON.stringify() returns. However, it is not a private property. It has an object Getownpropertysymbols method can obtain all symbol property names of the specified object.
Well, it can't be achieved.
11. Sometimes we want to reuse the same Symbol value, Symbol The for method can do this. It takes a string as a parameter and then searches for a Symbol value with that parameter as its name. If yes, this Symbol value will be returned. Otherwise, a new Symbol value with the name of this string will be created and returned.
This implementation is similar to function memory. We can create an object to store the created Symbol value.
12. Symbol. The keyfor method returns a key of a registered symbol type value.
Traverse forMap and find the key value corresponding to the value.
// Version 5 / / the previous code is the same...... var symbolpolyfill = function() {...} var forMap = {}; Object. defineProperties(SymbolPolyfill, { 'for': { value: function(description) { var descString = description === undefined ? undefined : String(description) return forMap[descString] ? forMap[descString] : forMap[descString] = SymbolPolyfill(descString); }, writable: true, enumerable: false, configurable: true }, 'keyFor': { value: function(symbol) { for (var key in forMap) { if (forMap[key] === symbol) return key; } }, writable: true, enumerable: false, configurable: true }});// The following code is the same
Complete implementation
in summary:
Features that cannot be implemented are: 1, 4, 7, 8, 10
The features that can be realized are: 2, 3, 5, 6, 9, 11 and 12
The final implementation is as follows:
(function() { var root = this; var generateName = (function(){ var postfix = 0; return function(descString){ postfix++; return '@@' + descString + '_' + postfix } })() var SymbolPolyfill = function Symbol(description) { if (this instanceof SymbolPolyfill) throw new TypeError('Symbol is not a constructor'); var descString = description === undefined ? undefined : String(description) var symbol = Object.create({ toString: function() { return this.__Name__; }, valueOf: function() { return this; } }) Object.defineProperties(symbol, { '__Description__': { value: descString, writable: false, enumerable: false, configurable: false }, '__Name__': { value: generateName(descString), writable: false, enumerable: false, configurable: false } }); return symbol; } var forMap = {}; Object.defineProperties(SymbolPolyfill, { 'for': { value: function(description) { var descString = description === undefined ? undefined : String(description) return forMap[descString] ? forMap[descString] : forMap[descString] = SymbolPolyfill(descString); }, writable: true, enumerable: false, configurable: true }, 'keyFor': { value: function(symbol) { for (var key in forMap) { if (forMap[key] === symbol) return key; } }, writable: true, enumerable: false, configurable: true } }); root.SymbolPolyfill = SymbolPolyfill;})()
Iterators and for of ES6 series
origin
A standard for loop code:
var colors = ["red", "green", "blue"];for (var i = 0, len = colors.length; i < len; i++) { console.log(colors[i]);}
It looks simple, but looking back at this code, in fact, we only need the values of the elements in the array, but we need to obtain the array length and declare the index variables in advance. Especially when multiple loops are nested, we need to use multiple index variables, which will greatly increase the complexity of the code. For example, we use double loops for de duplication:
function unique(array) { var res = []; for (var i = 0, arrayLen = array.length; i < arrayLen; i++) { for (var j = 0, resLen = res.length; j < resLen; j++) { if (array[i] === res[j]) { break; } } if (j === resLen) { res.push(array[i]); } } return res;}
In order to eliminate this complexity and reduce errors in loops (such as using variables in other loops incorrectly), ES6 provides iterators and for of loops to solve this problem.
iterator
The so-called iterator is actually an object with the next() method. Every time next() is called, a result object will be returned. The result object has two properties. Value represents the current value and done represents whether the traversal is over.
We directly use the syntax of ES5 to create an iterator:
function createIterator(items) { var i = 0; return { next: function() { var done = i >= item.length; var value = !done ? items[i++] : undefined; return { done: done, value: value }; } };}// Iterator is an iterator object var iterator = createIterator([1, 2, 3]);console.log(iterator.next()); // { done: false, value: 1 }console.log(iterator.next()); // { done: false, value: 2 }console.log(iterator.next()); // { done: false, value: 3 }console.log(iterator.next()); // { done: true, value: undefined }
for of
In addition to iterators, we also need a way to traverse iterator objects. ES6 provides a for of statement. We can directly use for of to traverse the iterator objects generated in the previous section:
var iterator = createIterator([1, 2, 3]);for (let value of iterator) { console.log(value);}
The result reports an error typeerror: iterator is not iteratable, indicating that the generated iterator object is not iteratable.
So what is ergodic?
In fact, as long as an Iterator interface is deployed for a data structure, we call it "iteratable".
ES6 specifies that the default iterator interface is deployed on the symbol of the data structure Iterator attribute, or a data structure with symbol The iterator attribute can be considered "iteratable".
for instance:
const obj = { value: 1};for (value of obj) { console.log(value);}// TypeError: iterator is not iterable
If we directly for of traverse an object, an error will be reported. However, if we add symbol to the object Iterator property:
const obj = { value: 1};obj[Symbol.iterator] = function() { return createIterator([1, 2, 3]);};for (value of obj) { console.log(value);}// 1// 2// 3
From this, we can also find that for of traverses the symbol of the object Iterator property.
Default traversable object
However, if we directly traverse an array object:
const colors = ["red", "green", "blue"];for (let color of colors) { console.log(color);}// red// green// blue
Although we didn't add symbol manually The iterator attribute can still be traversed successfully because ES6 deploys symbol by default Iterator property. Of course, we can also modify this property manually:
var colors = ["red", "green", "blue"];colors[Symbol.iterator] = function() { return createIterator([1, 2, 3]);};for (let color of colors) { console.log(color);}// 1// 2// 3
In addition to arrays, some data structures deploy symbol by default Iterator property.
Therefore, the for... of loop can be used in the following areas:
- array
- Set
- Map
- Class array objects, such as arguments object, DOM NodeList object
- Generator object
- character string
Simulation Implementation for of
In fact, the simulation implementation of for is also relatively simple, basically through symbol Get the iterator object with the iterator property, and then use while to traverse:
function forOf(obj, cb) { let iterable, result; if (typeof obj[Symbol.iterator] !== "function") throw new TypeError(result + " is not iterable"); if (typeof cb !== "function") throw new TypeError("cb must be callable"); iterable = obj[Symbol.iterator](); result = iterable.next(); while (!result.done) { cb(result.value); result = iterable.next(); }}
Built in iterator
In order to better access the contents of the object, for example, sometimes we only need the values in the array, but sometimes we need to use not only the values but also the indexes. ES6 has built the following three iterators for the array, Map and Set sets:
- entries() returns an iterator object that is used to iterate over an array of [key name, key value]. For arrays, the key name is the index value.
- keys() returns an iterator object to iterate over all key names.
- values() returns an iterator object that is used to iterate over all key values.
Take the array as an example:
var colors = ["red", "green", "blue"];for (let index of colors.keys()) { console.log(index);}// 0// 1// 2for (let color of colors.values()) { console.log(color);}// red// green// bluefor (let item of colors.entries()) { console.log(item);}// [ 0, "red" ]// [ 1, "green" ]// [ 2, "blue" ]
Map type is similar to array, but for Set type, you should pay attention to the following:
var colors = new Set(["red", "green", "blue"]);for (let index of colors.keys()) { console.log(index);}// red// green// bluefor (let color of colors.values()) { console.log(color);}// red// green// bluefor (let item of colors.entries()) { console.log(item);}// [ "red", "red" ]// [ "green", "green" ]// [ "blue", "blue" ]
keys() and values() of Set type return the same iterator, which also means that the key name and key value are the same in the data structure of Set.
Moreover, each collection type has a default iterator. In the for of loop, if it is not explicitly specified, the default iterator is used. The default iterator for array and Set collections is the values() method, and the default iterator for Map collections is the entries() method.
This is why direct for of traversal of Set and Map data structures will return different data structures:
const values = new Set([1, 2, 3]);for (let value of values) { console.log(value);}// 1// 2// 3
const values = new Map([["key1", "value1"], ["key2", "value2"]]);for (let value of values) { console.log(value);}// ["key1", "value1"]// ["key2", "value2"]
When traversing the Map data structure, it can be combined with deconstruction assignment:
const valuess = new Map([["key1", "value1"], ["key2", "value2"]]);for (let [key, value] of valuess) { console.log(key + ":" + value);}// key1:value1// key2:value2
How does Babel compile for of
We can be in Babel's Try it out To view the compiled results in:
const colors = new Set(["red", "green", "blue"]);for (let color of colors) { console.log(color);}
For such a piece of code, the compiled results are as follows:
"use strict";var colors = new Set(["red", "green", "blue"]);var _iteratorNormalCompletion = true;var _didIteratorError = false;var _iteratorError = undefined;try { for ( var _iterator = colors[Symbol.iterator](), _step; !(_iteratorNormalCompletion = (_step = _iterator.next()).done); _iteratorNormalCompletion = true ) { var color = _step.value; console.log(color); }} catch (err) { _didIteratorError = true; _iteratorError = err;} finally { try { if (!_iteratorNormalCompletion && _iterator.return) { _iterator.return(); } } finally { if (_didIteratorError) { throw _iteratorError; } }}
At least from the compilation results, we can see that symbol is still used behind the use of for loop Iterator interface.
There are two sections of the compiled code that are slightly complicated. One is a for loop, here:
for ( var _iterator = colors[Symbol.iterator](), _step; !(_iteratorNormalCompletion = (_step = _iterator.next()).done); _iteratorNormalCompletion = true) { var color = _step.value; console.log(color);}
It is somewhat different from the standard for loop writing method. Let's look at the syntax of the for statement:
for (initialize; test; increment) statement;
The three expressions initialize, test and increment are separated by semicolons. They are responsible for initialization operation, loop condition judgment and counter variable update respectively.
The for statement is actually equivalent to:
initialize;while (test) { statement; increment;}
The logic of the code is: initialize first, then execute the test expression before each loop execution, and judge the result of the expression to determine whether to execute the loop body. If the test calculation result is true, execute the statement in the loop body. Finally, execute the increment expression.
And it is worth noting that any of the three expressions in the for loop can be ignored, but the semicolon still needs to be written.
For example, for(;), But this is a dead circle
For example:
var i = 0, len = colors.length;for (; i < len; i++) { console.log(colors[i]);}
Another example:
var i = 0, len = colors.length;for (; i < len; ) { i++;}
Then let's look at the for loop expression compiled by Babel:
for ( var _iterator = colors[Symbol.iterator](), _step; !(_iteratorNormalCompletion = (_step = _iterator.next()).done); _iteratorNormalCompletion = true) { var color = _step.value; console.log(color);}
Using while is equivalent to:
var _iterator = colors[Symbol.iterator](), _step;while (!(_iteratorNormalCompletion = (_step = _iterator.next()).done)) { var color = _step.value; console.log(color); _iteratorNormalCompletion = true;}
Is it easy to understand a lot, and then you will find that, in fact_ Iteratornormalcompletement = true is completely unnecessary
Another slightly more complex piece of code is:
try { ...} catch (err) { ...} finally { try { if (!_iteratorNormalCompletion && _iterator.return) { _iterator.return(); } } finally { ... }}
Because_ iteratorNormalCompletion = (_step = _iterator.next()).done, so_ Iteratornormalcompletement indicates whether a complete iteration process has been completed. If there is no normal iteration completion and the iterator has a return method, it will execute the method.
The reason for this is to mention the return method of the iterator.
Quote teacher Ruan Yifeng's ECMAScript 6 getting started:
In addition to the next method, the traverser object can also have a return method and a throw method. If you write the ergodic object generation function yourself, the next method must be deployed, and whether the return method and throw method are deployed is optional.
The use of the return method is that if the for... Of loop exits early (usually because of an error, or there is a break statement or continue statement), the return method will be called. If an object needs to clean up or release resources before completing the traversal, the return method can be deployed.
We can take an example:
function createIterator(items) { var i = 0; return { next: function() { var done = i >= items.length; var value = !done ? items[i++] : undefined; return { done: done, value: value }; }, return: function() { console.log("Yes return method"); return { value: 23333, done: true }; } };}var colors = ["red", "green", "blue"];var iterator = createIterator([1, 2, 3]);colors[Symbol.iterator] = function() { return iterator;};for (let color of colors) { if (color == 1) break; console.log(color);}// The return method was executed
However, as you can see in the compiled code, the return function is only executed when there is a return function. In fact, the value returned in the return function does not take effect
But if you do not return a value or return a value of a basic type, the result will report an error
TypeError: Iterator result undefined is not an object
This is because the return method must return an object, which is determined by the Generator specification
In short, if it is used in the browser, the return value of the return function does not actually take effect T^T
The simulation of ES6 series implements a Set data structure
Basic introduction
ES6 provides a new data structure Set.
It is similar to an array, but the values of members are unique and there are no duplicate values.
initialization
Set itself is a constructor used to generate a set data structure.
let set = new Set();
The Set function can accept an array (or other data structures with iterable interface) as a parameter for initialization.
let set = new Set([1, 2, 3, 4, 4]);console.log(set); // Set(4) {1, 2, 3, 4}set = new Set(document.querySelectorAll('div'));console.log(set.size); // 66set = new Set(new Set([1, 2, 3, 4]));console.log(set.size); // 4
Properties and methods
The operation methods are:
- add(value): adds a value and returns the Set structure itself.
- delete(value): deletes a value and returns a Boolean value indicating whether the deletion is successful.
- has(value): returns a Boolean value indicating whether the value is a member of Set.
- clear(): clear all members without return value.
for instance:
let set = new Set();console.log(set.add(1).add(2)); // Set [ 1, 2 ]console.log(set.delete(2)); // trueconsole.log(set.has(2)); // falseconsole.log(set.clear()); // undefinedconsole.log(set.has(1)); // false
The reason why each operation is console is to make everyone pay attention to the return value of each operation.
Traversal methods include:
- keys(): the iterator that returns the key name
- values(): the iterator that returns the key value
- entries(): returns the traversal of key value pairs
- forEach(): use the callback function to traverse each member without return value
Note that keys(), values(), and entries() return iterators
let set = new Set(['a', 'b', 'c']);console.log(set.keys()); // SetIterator {"a", "b", "c"}console.log([...set.keys()]); // ["a", "b", "c"]
let set = new Set(['a', 'b', 'c']);console.log(set.values()); // SetIterator {"a", "b", "c"}console.log([...set.values()]); // ["a", "b", "c"]
let set = new Set(['a', 'b', 'c']);console.log(set.entries()); // SetIterator {"a", "b", "c"}console.log([...set.entries()]); // [["a", "a"], ["b", "b"], ["c", "c"]]
let set = new Set([1, 2, 3]);set.forEach((value, key) => console.log(key + ': ' + value));// 1: 1// 2: 2// 3: 3
Properties:
- Set.prototype.constructor: constructor, which is set function by default.
- Set.prototype.size: returns the total number of members of the set instance.
Simulation implementation first edition
If you want to simulate the implementation of a simple Set data structure and implement the add, delete, has, clear and forEach methods, it is still easy to write. Here is the code:
/** * Simulation implementation first edition */(function(global) { function Set(data) { this._values = []; this.size = 0; data && data.forEach(function(item) { this.add(item); }, this); } Set.prototype['add'] = function(value) { if (this._values.indexOf(value) == -1) { this._values.push(value); ++this.size; } return this; } Set.prototype['has'] = function(value) { return (this._values.indexOf(value) !== -1); } Set.prototype['delete'] = function(value) { var idx = this._values.indexOf(value); if (idx == -1) return false; this._values.splice(idx, 1); --this.size; return true; } Set.prototype['clear'] = function(value) { this._values = []; this.size = 0; } Set.prototype['forEach'] = function(callbackFn, thisArg) { thisArg = thisArg || global; for (var i = 0; i < this._values.length; i++) { callbackFn.call(thisArg, this._values[i], this._values[i], this); } } Set.length = 0; global.Set = Set;})(this)
We can write a test code:
let set = new Set([1, 2, 3, 4, 4]);console.log(set.size); // 4set.delete(1);console.log(set.has(1)); // falseset.clear();console.log(set.size); // 0set = new Set([1, 2, 3, 4, 4]);set.forEach((value, key, set) => { console.log(value, key, set.size)});// 1 1 4// 2 2 4// 3 3 4// 4 4 4
Simulation Implementation Second Edition
In the first edition, we used indexOf to judge whether the added elements are repeated. In essence, we still used = = = for comparison. For NaN, because:
console.log([NaN].indexOf(NaN)); // -1
The simulated Set can actually add multiple NANs without de duplication. However, for the real Set data structure:
let set = new Set();set.add(NaN);set.add(NaN);console.log(set.size); // 1
Therefore, we need to process the NaN value separately.
The processing method is to replace the added value with a unique value when judging that it is NaN. For example, a string that is difficult to repeat is similar to @ @ NaNValue. Of course, when it comes to unique values, we can also directly use Symbol. The code is as follows:
/** * Simulation Implementation Second Edition */(function(global) { var NaNSymbol = Symbol('NaN'); var encodeVal = function(value) { return value !== value ? NaNSymbol : value; } var decodeVal = function(value) { return (value === NaNSymbol) ? NaN : value; } function Set(data) { this._values = []; this.size = 0; data && data.forEach(function(item) { this.add(item); }, this); } Set.prototype['add'] = function(value) { value = encodeVal(value); if (this._values.indexOf(value) == -1) { this._values.push(value); ++this.size; } return this; } Set.prototype['has'] = function(value) { return (this._values.indexOf(encodeVal(value)) !== -1); } Set.prototype['delete'] = function(value) { var idx = this._values.indexOf(encodeVal(value)); if (idx == -1) return false; this._values.splice(idx, 1); --this.size; return true; } Set.prototype['clear'] = function(value) { ... } Set.prototype['forEach'] = function(callbackFn, thisArg) { ... } Set.length = 0; global.Set = Set;})(this)
Write segment test case:
let set = new Set([1, 2, 3]);set.add(NaN);console.log(set.size); // 3set.add(NaN);console.log(set.size); // 3
Simulation implementation Third Edition
When simulating the implementation of Set, the most troublesome thing is the implementation and processing of iterators. For example, iterators will be returned when initializing and executing keys(), values(), and entries()
let set = new Set([1, 2, 3]);console.log([...set]); // [1, 2, 3]console.log(set.keys()); // SetIterator {1, 2, 3}console.log([...set.keys()]); // [1, 2, 3]console.log([...set.values()]); // [1, 2, 3]console.log([...set.entries()]); // [[1, 1], [2, 2], [3, 3]]
Moreover, Set also supports the transfer of iterators during initialization:
let set = new Set(new Set([1, 2, 3]));console.log(set.size); // 3
When initializing an iterator, we can Iterators and for of ES6 series Simulate the implementation of the forOf function in and traverse the symbol of the passed in iterator Iterator interface, and then execute the add method in turn.
When we execute the keys() method, we can return an object and deploy symbol The implemented code and final code of the iterator interface are as follows:
/** * Simulation implementation Third Edition */(function(global) { var NaNSymbol = Symbol('NaN'); var encodeVal = function(value) { return value !== value ? NaNSymbol : value; } var decodeVal = function(value) { return (value === NaNSymbol) ? NaN : value; } var makeIterator = function(array, iterator) { var nextIndex = 0; // new Set(new Set()) will call var obj = {next: function() {return nextindex < array. Length? {value: iterator (array [nextindex + +]), done: false}: {value: void 0, done: true};}}// [... Set. Keys()] will call here obj [symbol. Iterator] = function() {return obj} return obj} function forof (obj, CB) {let iteratable, result; if (typeof obj [symbol. Iterator]! = = "function") throw new typeerror (obj + "is not iteratable"); if (typeof CB! = = "function") throw new typeerror ('cb must be callable'); iterable = obj[Symbol.iterator](); result = iterable. next(); while (!result.done) { cb(result.value); result = iterable.next(); } } function Set(data) { this._values = []; this.size = 0; forOf(data, (item) => { this.add(item); }) } Set. prototype['add'] = function(value) { value = encodeVal(value); if (this._values.indexOf(value) == -1) { this._values.push(value); ++this.size; } return this; } Set. prototype['has'] = function(value) { return (this._values.indexOf(encodeVal(value)) !== -1); } Set. prototype['delete'] = function(value) { var idx = this._values.indexOf(encodeVal(value)); if (idx == -1) return false; this._values.splice(idx, 1); --this.size; return true; } Set. prototype['clear'] = function(value) { this._values = []; this.size = 0; } Set. prototype['forEach'] = function(callbackFn, thisArg) { thisArg = thisArg || global; for (var i = 0; i < this._values.length; i++) { callbackFn.call(thisArg, this._values[i], this._values[i], this); } } Set. prototype['values'] = Set. prototype['keys'] = function() { return makeIterator(this._values, function(value) { return decodeVal(value); }); } Set. prototype['entries'] = function() { return makeIterator(this._values, function(value) { return [decodeVal(value), decodeVal(value)]; }); } Set. prototype[Symbol.iterator] = function(){ return this.values(); } Set. prototype['forEach'] = function(callbackFn, thisArg) { thisArg = thisArg || global; var iterator = this.entries(); forOf(iterator, (item) => { callbackFn.call(thisArg, item[1], item[0], this); }) } Set. length = 0; global. Set = Set;}) (this)
Write a test code:
let set = new Set(new Set([1, 2, 3]));console.log(set.size); // 3console.log([...set.keys()]); // [1, 2, 3]console.log([...set.values()]); // [1, 2, 3]console.log([...set.entries()]); // [1, 2, 3]
WeakMap of ES6 series
preface
Let's start with the features of WeakMap, and then talk about some application scenarios of WeakMap.
characteristic
1. WeakMap only accepts objects as key names
const map = new WeakMap();map.set(1, 2);// TypeError: Invalid value used as weak map keymap.set(null, 2);// TypeError: Invalid value used as weak map key
2. The object referenced by the key name of weakmap is a weak reference
This sentence is actually very confusing to me. Personally, I think the real meaning of this sentence should be:
WeakMaps hold "weak" references to key objects,
The translation should be that WeakMap maintains a weak reference to the object referenced by the key name.
Let's talk about weak references first:
In computer programming, weak reference, as opposed to strong reference, refers to a reference that cannot ensure that the object it refers to will not be recycled by the garbage collector. If an object is only referenced by a weak reference, it is considered inaccessible (or weakly accessible) and may therefore be recycled at any time.
In JavaScript, we usually create an object by creating a strong reference:
var obj = new Object();
Only when we manually set obj = null can we recycle the object referenced by obj.
And if we can create a weakly referenced object:
// Suppose you can create a var obj = new WeakObject();
We don't have to do anything. We just wait quietly for the garbage collection mechanism to execute, and the objects referenced by obj will be recycled.
Let's take another look at this sentence:
WeakMaps maintains a weak reference to the object referenced by the key name
Under normal circumstances, let's take an example:
const key = new Array(5 * 1024 * 1024);const arr = [ [key, 1]];
In this way, we actually establish a strong reference of arr to the object referenced by the key (we assume that the real object is called Obj).
Therefore, when you set key = null, only the strong reference of key to Obj is removed, and the strong reference of arr to Obj is not removed, so Obj will not be recycled.
The Map type is similar:
let map = new Map();let key = new Array(5 * 1024 * 1024);// A strong reference map to the object referenced by the key is established set(key, 1);// key = null will not cause the original reference object of the key to be recycled. key = null;
We can prove this problem through Node:
// Allow manual execution of the garbage collection mechanism node -- expose gcglobal gc();// Returns the memory usage of Nodejs. The unit is bytesprocess memoryUsage(); // heapUsed: 4640360 ≈ 4.4Mlet map = new Map();let key = new Array(5 * 1024 * 1024);map.set(key, 1);global.gc();process.memoryUsage(); // heapUsed: 46751472. Note that here it is about 44.6Mkey = null;global.gc();process.memoryUsage(); // heapUsed: 46754648 ≈ 44.6m / / this sentence is actually useless because the key is already null delete(key); global. gc(); process. memoryUsage(); // heapUsed: 46755856 ≈ 44.6M
If you want Obj to be recycled, you need to delete(key) first and then key = null:
let map = new Map();let key = new Array(5 * 1024 * 1024);map.set(key, 1);map.delete(key);key = null;
We still prove through Node:
node --expose-gcglobal.gc();process.memoryUsage(); // heapUsed: 4638376 ≈ 4.4Mlet map = new Map();let key = new Array(5 * 1024 * 1024);map.set(key, 1);global.gc();process.memoryUsage(); // heapUsed: 46727816 ≈ 44.6Mmap.delete(key);global.gc();process.memoryUsage(); // heapUsed: 46748352 ≈ 44.6Mkey = null;global.gc();process.memoryUsage(); // heapUsed: 4808064 ≈ 4.6M
At this time, we will talk about WeakMap:
const wm = new WeakMap();let key = new Array(5 * 1024 * 1024);wm.set(key, 1);key = null;
When we set wm Set (key, 1) actually establishes wm's weak reference to the object referenced by the key, but because let key = new Array(5 * 1024 * 1024) establishes the strong reference of the key to the referenced object, the referenced object will not be recycled. However, when we set key = null, there will be only wm's weak reference to the referenced object. The next time the garbage collection mechanism is executed, The reference object will be recycled.
Let's prove with Node:
node --expose-gcglobal.gc();process.memoryUsage(); // heapUsed: 4638992 ≈ 4.4Mconst wm = new WeakMap();let key = new Array(5 * 1024 * 1024);wm.set(key, 1);global.gc();process.memoryUsage(); // heapUsed: 46776176 ≈ 44.6Mkey = null;global.gc();process.memoryUsage(); // heapUsed: 4800792 ≈ 4.6M
Therefore, WeakMap can help you eliminate the steps of manually deleting object associated data, so you can consider using WeakMap when you can't or don't want to control the life cycle of associated data.
The feature of this weak reference is that WeakMaps maintains a weak reference to the object referenced by the key name, that is, the garbage collection mechanism does not take this reference into account. As long as other references of the referenced object are cleared, the garbage collection mechanism will free the memory occupied by the object. In other words, once it is no longer needed, the key name object and the corresponding key value pair in the WeakMap will disappear automatically without manually deleting the reference.
It is precisely because of this feature that the number of members in the WeakMap depends on whether the garbage collection mechanism is running. The number of members is likely to be different before and after the operation, and the operation time of the garbage collection mechanism is unpredictable. Therefore, ES6 stipulates that the WeakMap cannot be traversed.
Therefore, unlike Map, firstly, there is no traversal operation (i.e. no keys(), values() and entries() methods), no size attribute, and no clear method. Therefore, there are only four methods available in WeakMap: get(), set(), has(), and delete().
application
1. Save relevant data on DOM object
Traditionally, when using jQuery, we use $ The data() method stores relevant information on the DOM object (for example, the ID information of the post is stored on the delete button element). JQuery will use an object to manage the DOM and corresponding data. When you delete the DOM element and set the DOM object to empty, the associated data will not be deleted. You must manually execute $ The removeData() method can delete the associated data, and WeakMap can simplify this operation:
let wm = new WeakMap(), element = document.querySelector(".element");wm.set(element, "data");let value = wm.get(elemet);console.log(value); // dataelement.parentNode.removeChild(element);element = null;
2. Data cache
From the previous example, we can also see that when we need to associate objects and data, such as storing some attributes without modifying the original object or storing some calculated values according to the object, but do not want to manage the life and death of these data, it is very suitable to consider using WeakMap. Data caching is a good example:
const cache = new WeakMap();function countOwnKeys(obj) { if (cache.has(obj)) { console.log('Cached'); return cache.get(obj); } else { console.log('Computed'); const count = Object.keys(obj).length; cache.set(obj, count); return count; }}
3. Private property
WeakMap can also be used to implement private variables, but there are many ways to implement private variables in ES6, which is just one of them:
const privateData = new WeakMap();class Person { constructor(name, age) { privateData.set(this, { name: name, age: age }); } getName() { return privateData.get(this).name; } getAge() { return privateData.get(this).age; }}export default Person;
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-trvkkq1d-1628421362950)( https://lf3-cdn-tos.bytescm.com/obj/static/xitu_juejin_web/dcec27cc6ece0eb5bb217e62e6bec104.svg )] home page boiling point real-time info Booklet activity
-
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (IMG iargvpgq-1628421362951)( https://lf3-cdn-tos.bytescm.com/obj/static/xitu_juejin_web/8f68a2223e9650f14d6e6781cdcd717a.svg )]
-
- [external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-lopn0yui-1628421362953)( https://lf3-cdn-tos.bytescm.com/obj/static/xitu_juejin_web/fd92e44e46bf428b65aa0dc78366a82a.svg )]
-


October 16, 2018 reading 11456

ES6 series let's talk about Promise
preface
The basic use of Promise can be seen from teacher Ruan Yifeng ECMAScript 6 getting started.
Let's talk about something else.
Callback
When it comes to Promise, we usually start with callback or callback hell. What are the bad things caused by using callback?
1. Callback nesting
Using callback, we are likely to write the business code as follows:
doA( function(){ doB(); doC( function(){ doD(); } ) doE();} );doF();Copy code
Of course, this is a simplified form. After some simple thinking, we can judge the execution order as follows:
doA()doF()doB()doC()doE()doD()Copy code
However, in the actual project, the code will be more messy. In order to troubleshoot the problem, we need to bypass a lot of eye-catching content and constantly jump between functions, which makes it more difficult to troubleshoot the problem.
Of course, the reason for this problem is that this nested writing mode is contrary to people's linear thinking mode, so that we have to spend more energy thinking about the real execution order. Nesting and indentation are only the thin branches and ends of this thinking process.
Of course, contrary to people's linear thinking, it's not the worst. In fact, we will add various logical judgments to the code. For example, in the above example, doD() must be completed after doc () is completed. What if doc () fails? Are we going to retry doC()? Or go directly to other error handling functions? When we add these judgments to the process, the code will soon become too complex to maintain and update.
2. Control reversal
When writing code normally, we can naturally control our own code. However, when we use callback, whether the callback function can be executed depends on the API using callback, such as:
// Whether the callback function is executed depends on the buy module import {buy} from '/ buy. js'; buy(itemData, function(res) { console.log(res)}); Copy code
There is generally no problem with the fetch API we often use, but what if we use a third-party API?
When you call a third-party API, will the other party cause your incoming callback function to execute multiple times because of an error?
In order to avoid such problems, you can add judgment to your callback function, but what if the callback function is not executed because of an error? What if the callback function sometimes executes synchronously and sometimes asynchronously?
Let's summarize these situations:
- The callback function executes multiple times
- The callback function did not execute
- Callback functions sometimes execute synchronously and sometimes asynchronously
In these cases, you may have to do some processing in the callback function, and do some processing every time the callback function is executed, which brings a lot of repetitive code.
Callback hell
Let's start with a simple example of callback hell.
Now to find the largest file in a directory, the processing steps should be:
- Use FS Readdir obtains the list of files in the directory;
- Loop through the file, using FS Stat get file information
- Compare and find the largest file;
- The callback is called with the file name of the largest file as the parameter.
The code is:
var fs = require('fs');var path = require('path');function findLargest(dir, cb) { // Read all files in the directory FS Readdir (DIR, function (ER, files) {if (ER) return CB (ER); VAR counter = files.length; VAR erred = false; VAR stats = []; files.foreach (function (file, index) {/ / read the file information fs.stat (path. Join (DIR, file), function (ER, STAT) {if (erred) return; if (ER) { errored = true; return cb(er); } stats[index] = stat; // Calculate the number of files in advance, read the information of one file, and subtract 1. When it is 0, it indicates that the reading is complete. At this time, perform the final comparison operation if (- - counter = = 0) {var large = stats. Filter (function (STAT) {return stat.isfile()}) Reduce (function (prev, next) {if (prev. Size > next. Size) return prev return next}) CB (null, files [stats. Indexof (large)])}})})} copy code
Usage:
// Find the largest file in the current directory findlargest ('. /', function (ER, filename) {if (ER) return console.error (ER) console.log ('large file was:, filename)}); Copy code
You can copy the above code to an example such as index JS file, and then execute node index JS can print out the name of the largest file.
After reading this example, let's talk about other problems of callback Hell:
1. Difficult to reuse
After the callback sequence is determined, it is also difficult to reuse some links, which will affect the whole body.
For example, if you want to use FS The code of stat reading file information is reused, because the callback references the outer layer variables, and the outer layer code needs to be modified after extraction.
2. Stack information is disconnected
As we know, the JavaScript engine maintains an execution context stack. When a function is executed, the execution context of the function will be created and pushed into the stack. After the function is executed, the execution context will be pushed out of the stack.
If the B function is invoked in the A function, JavaScript first pushes the execution context of the A function into the stack, then pushes the execution context of the B function into the stack. When the B function is executed, the B function executes the context out of the stack, and when the A function is executed, the A function executes the context out of the stack.
The advantage is that if we interrupt code execution, we can retrieve the complete stack information and get any information we want.
However, this is not the case for asynchronous callback functions, such as executing FS When reading dir, the callback function is actually added to the task queue, and the code continues to execute. Until the main thread is completed, the completed task will be selected from the task queue and added to the stack. At this time, there is only one execution context in the stack. If the callback reports an error, the information in the stack when calling the asynchronous operation cannot be obtained, It is not easy to determine what went wrong.
In addition, because it is asynchronous, using the try catch statement cannot directly catch errors.
(Promise doesn't solve this problem)
3. External variables
When multiple asynchronous calculations are performed at the same time, such as traversing and reading file information here, because the completion order cannot be expected, you must use variables in the outer scope, such as count, errored, stats, etc., which is not only troublesome to write, but also if you ignore the error in file reading and do not record the error status, you will then read other files, Cause unnecessary waste. In addition, the outer variables may also be accessed and modified by other functions in the same scope, which is easy to cause misoperation.
The reason why we talk about callback hell alone is to say that nesting and indentation are just a stem of callback hell. The problem it causes is far from the reduction of readability caused by nesting.
Promise
Promise has solved most of the above problems.
1. Nesting problem
for instance:
request(url, function(err, res, body) { if (err) handleError(err); fs.writeFile('1.txt', body, function(err) { request(url2, function(err, res, body) { if (err) handleError(err) }) })});Copy code
After using Promise:
request(url).then(function(result) { return writeFileAsynv('1.txt', result)}).then(function(result) { return request(url2)}).catch(function(e){ handleError(e)});Copy code
For the example of reading the largest file, we use promise to simplify it to:
var fs = require('fs');var path = require('path');var readDir = function(dir) { return new Promise(function(resolve, reject) { fs.readdir(dir, function(err, files) { if (err) reject(err); resolve(files) }) })}var stat = function(path) { return new Promise(function(resolve, reject) { fs.stat(path, function(err, stat) { if (err) reject(err) resolve(stat) }) })}function findLargest(dir) { return readDir(dir) .then(function(files) { let promises = files.map(file => stat(path.join(dir, file))) return Promise.all(promises).then(function(stats) { return { stats, files } }) }) .then(data => { let largest = data.stats .filter(function(stat) { return stat.isFile() }) .reduce((prev, next) => { if (prev.size > next.size) return prev return next }) return data.files[data.stats.indexOf(largest)] })}Copy code
2. Control reverse and then reverse
When using the third-party callback API, we may encounter the following problems:
- The callback function executes multiple times
- The callback function did not execute
- Callback functions sometimes execute synchronously and sometimes asynchronously
For the first problem, Promise can only resolve once, and the remaining calls will be ignored.
For the second question, we can use promise Trace function to solve the problem:
function timeoutPromise(delay) { return new Promise( function(resolve,reject){ setTimeout( function(){ reject( "Timeout!" ); }, delay ); } );}Promise.race( [ foo(), timeoutPromise( 3000 )] ).then(function(){}, function(err){});Copy code
For the third question, why do we sometimes execute synchronously and sometimes execute asynchronously?
Let's take an example:
var cache = {...};function downloadFile(url) { if(cache.has(url)) { // If there is a cache, return promise is called for synchronization resolve(cache.get(url)); } return fetch(url). then(file => cache.set(url, file)); // This is an asynchronous call to} console log('1'); getValue. then(() => console. log('2')); console. log('3'); Copy code
In this example, when there is cahce, the print result is 1 2 3. When there is no cache, the print result is 1 3 2.
However, if this mixed synchronous and asynchronous code is used as an internal implementation, only the interface is exposed to external calls. The caller cannot judge whether it is asynchronous or synchronous, which affects the maintainability and testability of the program.
In short, the coexistence of synchronization and asynchrony can not guarantee the consistency of program logic.
However, Promise solves this problem. Let's take an example:
var promise = new Promise(function (resolve){ resolve(); console.log(1);});promise.then(function(){ console.log(2);});console.log(3);// 1 3 2copy code
Even if the promise object immediately enters the resolved state, that is, the resolve function is called synchronously, the method specified in the then function is still asynchronous.
Promise a + specification also has clear provisions:
In practice, ensure that the onFulfilled and onRejected methods execute asynchronously and should be executed in the new execution stack after the event loop in which the then method is called.
Promise anti pattern
1.Promise nesting
// badloadSomething().then(function(something) { loadAnotherthing().then(function(another) { DoSomethingOnThem(something, another); });}); Copy the code / / goodpromise all([loadSomething(), loadAnotherthing()]). then(function ([something, another]) { DoSomethingOnThem(...[something, another]);}); Copy code
2. Broken Promise chain
// badfunction anAsyncCall() { var promise = doSomethingAsync(); promise.then(function() { somethingComplicated(); }); return promise;} Copy code / / goodfunction anasynccall() {var promise = dosomethingasync(); return promise. Then (function() {somethingcompleted()});} Copy code
3. Chaotic assembly
// badfunction workMyCollection(arr) { var resultArr = []; function _recursive(idx) { if (idx >= resultArr.length) return resultArr; return doSomethingAsync(arr[idx]).then(function(res) { resultArr.push(res); return _recursive(idx + 1); }); } return _ recursive(0);} Copy code
You can write:
function workMyCollection(arr) { return Promise.all(arr.map(function(item) { return doSomethingAsync(item); }));}Copy code
If you have to execute in a queue, you can write:
function workMyCollection(arr) { return arr.reduce(function(promise, item) { return promise.then(function(result) { return doSomethingAsyncWithResult(item, result); }); }, Promise.resolve());}Copy code
4.catch
// badsomethingAync.then(function() { return somethingElseAsync();}, function(err) { handleMyError(err);}); Copy code
If something else async throws an error, it cannot be caught. You can write:
// goodsomethingAsync.then(function() { return somethingElseAsync()}).then(null, function(err) { handleMyError(err);}); Copy the code / / goodsomethingasync() then(function() { return somethingElseAsync();}). catch(function(err) { handleMyError(err);}); Copy code
Traffic light problem
Title: the red light is on once every three seconds, the green light is on once every second, and the yellow light is on once every two seconds; How to make the three lights turn on alternately and repeatedly? (implemented with Promse)
Three lighting functions already exist:
function red(){ console.log('red');}function green(){ console.log('green');}function yellow(){ console.log('yellow');}Copy code
Using then and recursion:
function red(){ console.log('red');}function green(){ console.log('green');}function yellow(){ console.log('yellow');}var light = function(timmer, cb){ return new Promise(function(resolve, reject) { setTimeout(function() { cb(); resolve(); }, timmer); });};var step = function() { Promise.resolve().then(function(){ return light(3000, red); }).then(function(){ return light(2000, green); }).then(function(){ return light(1000, yellow); }).then(function(){ step(); });}step();Copy code
promisify
Sometimes, we need to transform the API of callback syntax into Promise syntax. Therefore, we need a Promise method.
The callback syntax has clear parameters. The last parameter is passed into the callback function. The first parameter of the callback function is an error message. If there is no error, it is null. Therefore, we can write a simple promise method directly:
function promisify(original) { return function (...args) { return new Promise((resolve, reject) => { args.push(function callback(err, ...values) { if (err) { return reject(err); } return resolve(...values) }); original.call(this, ...args); }); };}Copy code
Complete can refer to es6-promisif
Promise's limitations
1. Mistakes are eaten
First of all, we should understand that what is error eaten means that the error information is not printed?
No, for example:
throw new Error('error');console.log(233333);Copy code
In this case, due to throw error, the code execution is blocked and 2333333 will not be printed. Another example:
const promise = new Promise(null);console.log(233333);Copy code
The execution of the above code will still be blocked because if Promise is used in an invalid way and an error hinders the construction of a normal Promise, an exception will be obtained immediately instead of a rejected Promise.
However, another example:
let promise = new Promise(() => { throw new Error('error')});console.log(2333333);Copy code
2333333 will be printed normally this time, indicating that the internal error of Promise will not affect the external code of Promise, which is commonly referred to as "eating error".
In fact, this is not the unique limitation of Promise. try... Catch is the same. It will also catch an exception and simply eat the error.
It is precisely because the errors are eaten that the errors in the Promise chain are easy to be ignored. This is why it is generally recommended to add a catch function at the end of the Promise chain, because for a Promise chain without error handling function, any errors will be propagated in the chain until you register the error handling function.
2. Single value
Promise can only have one completion value or one rejection reason. However, in real use, it is often necessary to pass multiple values. The general practice is to construct an object or array and then pass it. After obtaining this value in then, the operation of value assignment will be carried out. Each encapsulation and unpacking will undoubtedly make the code cumbersome.
Seriously, there is no good method. It is recommended to use the deconstruction assignment of ES6:
Promise.all([Promise.resolve(1), Promise.resolve(2)]).then(([x, y]) => { console.log(x, y);});Copy code
3. Unable to cancel
Promise will be executed immediately once it is created, and cannot be cancelled halfway.
4. Unable to know the pending status
When it is in the pending state, it is impossible to know which stage it has reached (just started or about to be completed).