summary:
Blockchain: in essence, it is a distributed ledger, which is distributed all over the world and is difficult to be tampered with
Ethereum Eth: Eth is a kind of blockchain technology and the second elder brother in the blockchain (the eldest brother is bitcoin)
Financial attribute of blockchain: establish an online trading system around a credible account book that cannot be tampered with. Ethereum, for example, has issued more than 110 million Ethereum coins that can be traded on Ethereum books. The current market price of each coin is 2.7w RMB, and the market value of Ethereum is 2.9 trillion. These coins can be used for financial transactions; Transaction demand stimulates technology investment
Blockchain Technology: including transaction procedures, account book procedures, mine pool procedures and mining procedures (account book encryption and packaging);
Ore pool: the ore pool program works like a contractor. It receives bookkeeping tasks and distributes them to many miners to complete together. There are reasons for the existence of ore pools. The computing power of the whole network increases sharply, and it is difficult for individual miners to complete their tasks, so there are ore pools.
Miner: the work is simple, usually receives tasks from the mine pool, and reports the results after a large number of fixed process calculations.
Ethminer: it is an open source miner program of Ethereum, which is responsible for receiving calculation tasks, reporting calculation results and obtaining remuneration.
To sum up, blockchain technology includes multiple link technologies. This paper mainly analyzes the miner program from the code of Ethminer.
Stratum Ethereum communication protocol:
Miners need to rely on communication protocols to receive and report tasks from the mine pool. Stratum protocol is commonly used by Ethereum.
Stratum is a protocol encapsulated on the tcp protocol and in Jason format. You can choose whether to use SSL for encryption.
Main format of Stratum protocol:
Request:
{
"id": communication ID
"method": Method name,
"params": [
Method parameters
]
}reply:
{
"id": ID,And requests ID corresponding
"result": All the replies are placed in result in
"error": Is there an error in the request
}Method: Subscribe
client request:
{
"id":1,
"method":"eth_submitLogin",
"worker":"xyz-test2",
"params":["0xcBFC5Cb9b315Cd82685c0Ba17A82db872Be66b01","x"],
"jsonrpc":"2.0"
}server reply:
{
"id":1,
"jsonrpc":"2.0",
"result":true
}worker: it's the miner's name
A string of 40 bit hexadecimal numbers in params is the wallet address
There are also differences in the reporting format of some miners. Some worker s' fields are empty, and their names are separated by points after the wallet address, such as:
0xcBFC5Cb9b315Cd82685c0Ba17A82db872Be66b01. xyz-test2
Note that the client request and the reply id of the server are the same, and the client id will increase. This rule applies to the process when the client initiates the request
Method: request task
client send request:
{"id":2,"method":"eth_getWork","params":[],"jsonrpc":"2.0"}Send user name and password
sever reply:
{"id":2,"jsonrpc":"2.0","result":{"status":"ok"}}After the client subscribes successfully, it will send a message requesting a task
After the server simply replies ok, it can start to delegate computing tasks
Method: issue task
{
"id":0,
"jsonrpc":"2.0",
"result":[
"0xe41d8d6a87364b010c92c9a4ef44965ee801faf64b90dc9b40f71ff74eea3e02", #headerhash
"0x0ae1dc880080eca07b1a976949eb91b4f67fa533a59767f24c2e1d332182a024", #seedhash
"0x00000000ffff00000000ffff00000000ffff00000000ffff00000000ffff0000", #boundary
"0xd1d351" #Represents the block number
]
}After receiving the miner's request for a task, the mine pool will issue a calculation task every 1 to 2 seconds, and the ID of the calculation task is 0;
The meaning of each field, such as the notes on the code; This part of information is the input required for calculation;
headerhash is the head hash value of each block, which is different for each task
The value of seedhash is used to calculate the DAG map. It is updated every era (about 100 hours in epoch). The DAG map calculated with the same seedhash is the same
Boundary represents the difficulty limit. The smaller the boundary, the higher the difficulty, and the calculation result should be less than the boundary
Block number, the block number corresponding to hashhead. This information is not useful in calculation
Method: submit results:
{
"id":4,
"method":"eth_submitWork",
"params":["0x6b3c9a00673eeacc", #nonce value
"0xe41d8d6a87364b010c92c9a4ef44965ee801faf64b90dc9b40f71ff74eea3e02" #headerhash,
"0x2019a97ed06d889e93828c32fd065cf4c82de178462ae91ae9a93390e67730a4" #mix_ Calculation results of hash satisfying conditions
],
"jsonrpc":"2.0"
}The ID submitted by the client is incremented one by one
nonce value: This is calculated from a randomly selected value in the DAG diagram
Headerhash: corresponds to the headerhash distributed by the task. The chain will match the distributed task through this value
Results: nonce value is a number found in DAG diagram;
mix_hash is the result that meets the difficulty requirements after setting the calculation process with nonce and heartbeat
Method: whether the server accepts:
If the task matches and passes, the Server replies:
{
"id":4,
"jsonrpc":"2.0",
"result":true
}If the Server does not accept the results:
{
"id": 123,
"result": false,
"error": [
-1,
"Job not found",
NULL
]
}Ethash calculation principle:
Firstly, we focus on the input parameters and calculation results of ethcash calculation; Refer to the previous stratum protocol
Input parameters: headerhash and seedhash
Calculation results: nonce value and mix_hash
Calculation process:
First create a dag diagram based on the input seedhash:
bool static ethash_compute_cache_nodes(
node* const nodes, //Cache for storing DAG diagram
uint64_t cache_size, //DAG graph cache size
ethash_h256_t const* seed //seedhash
)
{
//Confirm the cache first_ Size correct
if (cache_size % sizeof(node) != 0) {
return false;
}
//Calculate the cache_ How many nodes does size contain
uint32_t const num_nodes = (uint32_t) (cache_size / sizeof(node));
//First pass the seedhash through sha3_512 is stored in nodes [0] bytes
SHA3_512(nodes[0].bytes, (uint8_t*)seed, 32);
//Loop pair nodes [n] Bytes as Sha3_ five hundred and twelve
for (uint32_t i = 1; i != num_nodes; ++i) {
SHA3_512(nodes[i].bytes, nodes[i - 1].bytes, 64);
}
//Cyclic cross calculation hash
for (uint32_t j = 0; j != ETHASH_CACHE_ROUNDS; j++) {
for (uint32_t i = 0; i != num_nodes; i++) {
uint32_t const idx = nodes[i].words[0] % num_nodes;
node data;
data = nodes[(num_nodes - 1 + i) % num_nodes];
for (uint32_t w = 0; w != NODE_WORDS; ++w) {
data.words[w] ^= nodes[idx].words[w];
}
SHA3_512(nodes[i].bytes, data.bytes, sizeof(data));
}
}
//Do size conversion
fix_endian_arr32(nodes->words, num_nodes * NODE_WORDS);
return true;
}After the DAG diagram is created, mix hash calculation can be performed. The calculation process is as follows:
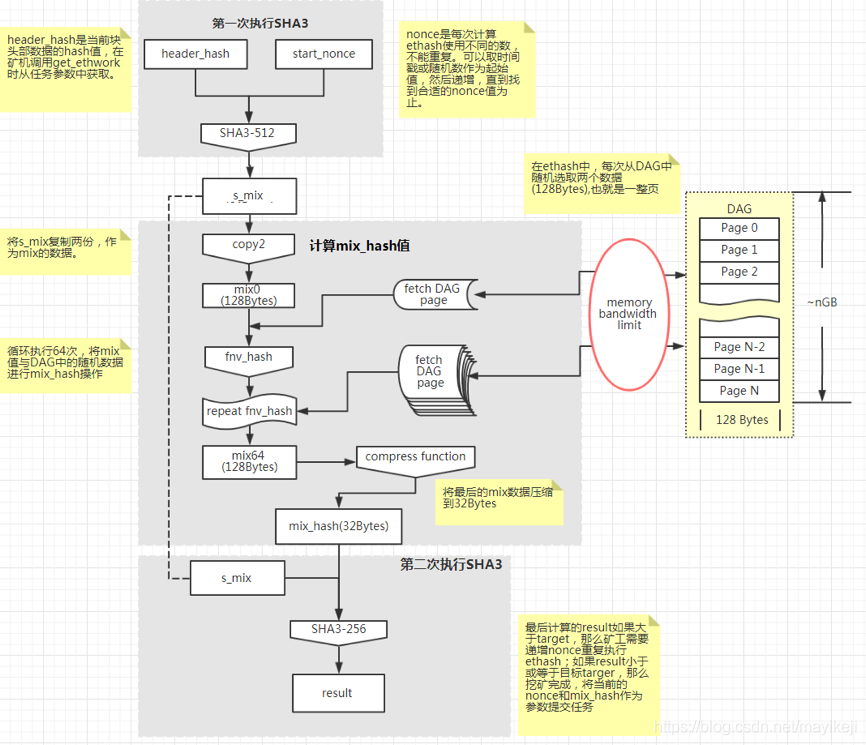 It can be seen from the figure that the calculated input values are headerhash and nonce values, and nonce values are taken at random. Calculate an index from headerhash and nonce values, take out the data corresponding to the index in the DAG diagram, and calculate the hash repeatedly to obtain a result;
It can be seen from the figure that the calculated input values are headerhash and nonce values, and nonce values are taken at random. Calculate an index from headerhash and nonce values, take out the data corresponding to the index in the DAG diagram, and calculate the hash repeatedly to obtain a result;
However, this result does not necessarily meet the requirements, so a comparison will be made:
bool EthashCUDAMiner::report(uint64_t _nonce)
{
Nonce n = (Nonce)(u64)_nonce;
Result r = EthashAux::eval(work().seedHash, work().headerHash, n);
//r.value
if (r.value < work().boundary)
return submitProof(Solution{ n, r.mixHash });
return false;
}If the difficulty requirements are met, the calculation results will be reported to the ore pool, otherwise continue to find the nonce value that meets the difficulty requirements.
The smaller the boundary, the more cycles you need to go through to find a suitable nonce value, and the higher the difficulty.
Combination code:
Knowing the above principles, we analyze them in combination with the ethminer source code:
Code entry:
main
->cli.execute();
->doMiner();
The main class in doMiner is PoolManager
void doMiner()
{
new PoolManager(m_PoolSettings);
if (m_mode != OperationMode::Simulation)
for (auto conn : m_PoolSettings.connections)
cnote << "Configured pool " << conn->Host() + ":" + to_string(conn->Port());
// Start PoolManager includes startup and operation. In PoolManager, stratum protocol processing is associated with miner computing
PoolManager::p().start();
// Information output can be ignored first
m_cliDisplayTimer.expires_from_now(boost::posix_time::seconds(m_cliDisplayInterval));
m_cliDisplayTimer.async_wait(m_io_strand.wrap(boost::bind(
&MinerCLI::cliDisplayInterval_elapsed, this, boost::asio::placeholders::error)));
// Normally, the process sleeps. If an external signal is received, execute exit
unique_lock<mutex> clilock(m_climtx);
while (g_running)
g_shouldstop.wait(clilock);
// Exit operation
if (PoolManager::p().isRunning())
PoolManager::p().stop();
cnote << "Terminated!";
return;
}PoolManager::start(), calling rotateConnect.
void PoolManager::start()
{
m_running.store(true, std::memory_order_relaxed);
m_async_pending.store(true, std::memory_order_relaxed);
m_connectionSwitches.fetch_add(1, std::memory_order_relaxed);
//rotateConnect is called here
g_io_service.post(m_io_strand.wrap(boost::bind(&PoolManager::rotateConnect, this)));
}Communication module EthStratumClient:
Several important things are done in rotateConnect:
void PoolManager::rotateConnect()
{
//Create a Stratum processing class
p_client = std::unique_ptr<PoolClient>(
new EthStratumClient(m_Settings.noWorkTimeout, m_Settings.noResponseTimeout));
//setClientHandlers to p_client initializes a series of callback functions, that is, at which stage stratum resolves, miner is called to perform calculation
if (p_client)
setClientHandlers();
//Connect to the server and start working
p_client->connect();
}Several important callback functions are set in setClientHandlers
void PoolManager::setClientHandlers()
{
// Called when a connection is established with the server
p_client->onConnected([&]() {
// Farm start will create and start each calculation module (CUDAMINER,CPUMINER)
Farm::f().start();
})
// Called when disconnected from the service
p_client->onDisconnected([&]() {
}
p_client->onWorkReceived([&](WorkPackage const& wp) {
//The task information obtained by stratum (p_client) communication is handed over to a calculation module
Farm::f().setWork(m_currentWp);
});
p_client->onSolutionAccepted([&]() {
//When the calculation result calculated by the calculation module is successfully accepted by the server, notify the calculation module to carry out some statistical work
Farm::f().accountSolution(_minerIdx, SolutionAccountingEnum::Accepted);
}}
}After the initialization and connect processes are completed, the messages received by the stratum module are finally processed in the processResponse through the following process
connect_handler
->recvSocketData
->onRecvSocketDataCompleted
->processResponse
void EthStratumClient::onRecvSocketDataCompleted(
const boost::system::error_code& ec, std::size_t bytes_transferred)
{
if (jRdr.parse(line, jMsg))
{
try
{
// Process the received message. If a new task is received, it will be m deleted_ Newjobprocessed is set to true
processResponse(jMsg);
}
catch (const std::exception& _ex)
{
cwarn << "Stratum got invalid Json message : " << _ex.what();
}
}
//If there is a new task, call onWorkReceived for processing. This callback is set in setClientHandlers mentioned above
//Here, the work of communication and computing modules is connected
//Set m in processResponse above_ Newjobprocessed is true, and new tasks will be processed here
if (m_newjobprocessed)
if (m_onWorkReceived)
m_onWorkReceived(m_current);
}Calculation module (each miner):
As we mentioned earlier, the functions associated with the communication module and the calculation module call Farm:: f() in onWorkReceived setWork(m_currentWp); Function makes the computing module work
Farm::f().setWork works as follows:
void Farm::setWork(WorkPackage const& _newWp)
{
for (unsigned int i = 0; i < m_miners.size(); i++)
{
m_currentWp.startNonce = _startNonce + ((uint64_t)i << m_nonce_segment_with);
// Call miner modules managed by Farm, setWork
m_miners.at(i)->setWork(m_currentWp);
}
}Miner is an abstract class. Miner::setWork does one thing by assigning work to the member variable:
void Miner::setWork(WorkPackage const& _work){
..............
// Assign to member variable for use
m_work = _work;
}Inherit miner's class and obtain m by calling Miner::work()_ work
WorkPackage Miner::work() const
{
boost::mutex::scoped_lock l(x_work);
return m_work;
}Many miner implementations inherit miner classes, such as CUDAMiner and cpuminer; CUDAMiner is a class that calls NVIDIA GPU to speed up the calculation process. It is a classic implementation. We take this class as an example to continue the analysis
The most important part of CUDAMiner is workLoop, which is calculated repeatedly:
void CUDAMiner::workLoop()
{
while (!shouldStop())
{
if (current.epoch != w.epoch)
{
// As mentioned earlier, 3000 blocks take about 100 hours and a century, and initEpoch should be called every time the century changes
// The function ethash is eventually called in initEpoch_ generate_ dag generate dag graph
if (!initEpoch())
break; // This will simply exit the thread
// As DAG generation takes a while we need to
// ensure we're on latest job, not on the one
// which triggered the epoch change
current = w;
continue;
}
// Find nonce that meets the difficulty
search(current.header.data(), upper64OfBoundary, current.startNonce, w);
}
}Look at what is done in search:
void CUDAMiner::search(
uint8_t const* header, uint64_t target, uint64_t start_nonce, const dev::eth::WorkPackage& w){
while (!done)
{
volatile Search_results& buffer(*m_search_buf[current_index]);
// If the calculation process finds a consistent result, m_search_buf will be filled with assignment
uint32_t found_count = std::min((unsigned)buffer.count, MAX_SEARCH_RESULTS);
// run_ethash_search calls GPU for calculation
if (!done)
run_ethash_search(
m_settings.gridSize, m_settings.blockSize, stream, &buffer, start_nonce);
if (found_count)
{
uint64_t nonce_base = start_nonce - m_streams_batch_size;
for (uint32_t i = 0; i < found_count; i++)
{
uint64_t nonce = nonce_base + gids[i];
// The calculation result is reported to the server, which corresponds to the output value mentioned in the stratum protocol. There is a header function in nonce, mixes and w
Farm::f().submitProof(
Solution{nonce, mixes[i], w, std::chrono::steady_clock::now(), m_index});
}
}
}
}ethash_ What to do in search:
__global__ void ethash_search(volatile Search_results* g_output, uint64_t start_nonce)
{
uint32_t const gid = blockIdx.x * blockDim.x + threadIdx.x;
uint2 mix[4];
// Use start_nonce does not find a matching result, exit, replace nonce and continue calculation
if (compute_hash(start_nonce + gid, mix))
return;
// If a value matching the result is found
uint32_t index = atomicInc((uint32_t*)&g_output->count, 0xffffffff);
if (index >= MAX_SEARCH_RESULTS)
return;
// Fill the value in the output buffer so that the outer function can obtain the result
g_output->result[index].gid = gid;
g_output->result[index].mix[0] = mix[0].x;
g_output->result[index].mix[1] = mix[0].y;
g_output->result[index].mix[2] = mix[1].x;
g_output->result[index].mix[3] = mix[1].y;
g_output->result[index].mix[4] = mix[2].x;
g_output->result[index].mix[5] = mix[2].y;
g_output->result[index].mix[6] = mix[3].x;
g_output->result[index].mix[7] = mix[3].y;
}compute_ The process of hash calling GPU calculation is complex. Here is the result judgment
DEV_INLINE bool compute_hash(uint64_t nonce, uint2* mix_hash)
{
// If the calculation result is greater than the target value, it means that the calculation fails this time, and returns true to enter the next round of calculation
if (cuda_swab64(keccak_f1600_final(state)) > d_target)
return true;
// If the calculation result is less than the target value, it indicates that the calculation result is funny. It is filled in the brought out parameter and returned
mix_hash[0] = state[8];
mix_hash[1] = state[9];
mix_hash[2] = state[10];
mix_hash[3] = state[11];
return false;
}The main process of this code is analyzed. The part of the algorithm involved is the most difficult part and the essence; I hope interested friends can study and share;
CUDA Programming:
When it comes to Ethminer, it's hard not to mention GPU Programming; Some friends can find relevant information on the Internet; My research is not very deep, simply say my understanding;
GPU design is to use many small hardware cores to complete parallel computing; Since it is parallel computing, it is necessary to meet
1. In the calculation process, the data can be divided into decoupled blocks, each core completes a small calculation, and finally put together the result; The kernel arrangement is two-dimensional, so the final data processing is much like the matrix processing in linear algebra
2. GPU computing is fast, but memory can't keep up with GPU computing speed; So put the data into the video memory in advance; And a group of GPU cores can access the same memory at high speed at the same time; Therefore, in programming, each GPU moves a small piece of data to memory, and a group of GPUs complete the migration of a group of data at the same time, which can speed up the speed of memory access
Based on the above two considerations, the complexity of GPU Programming is increased too much, and many understandable processes on the CPU are confused on the GPU
I didn't fully understand ethminer's GPU algorithm. I hope to share it with experts. However, the dag diagram generated code is relatively simple, and some clues can be seen by comparing the dag diagram code of CPU
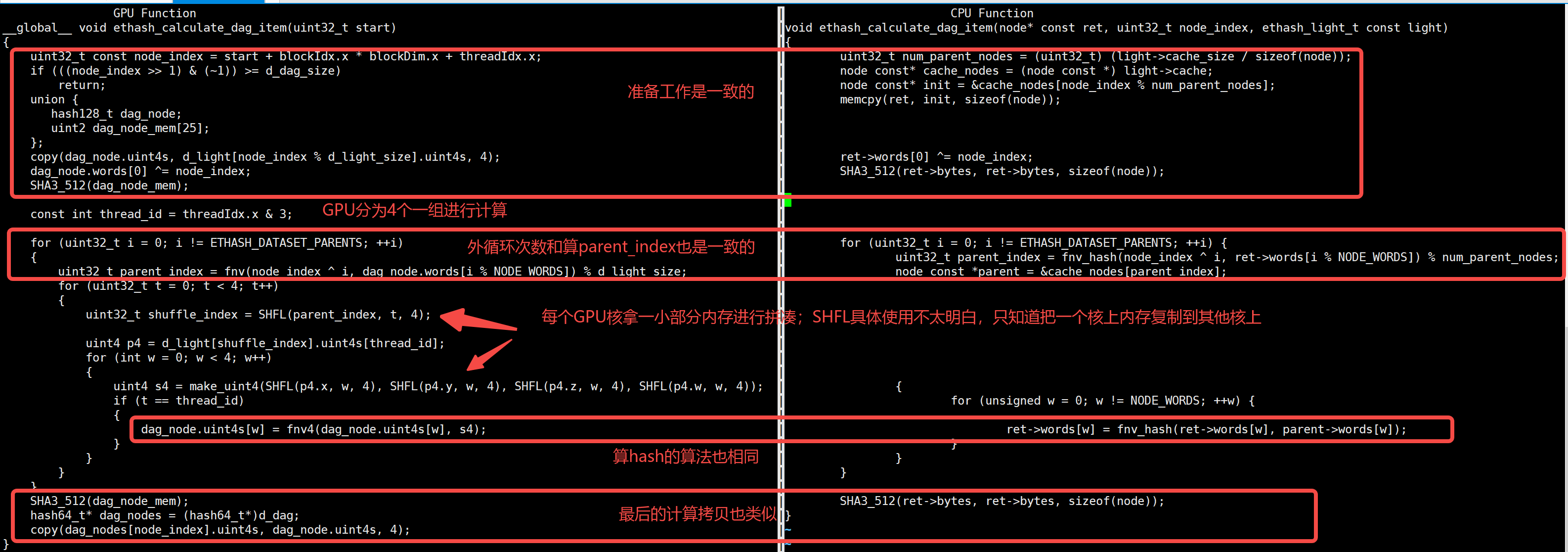
Please guide friends who are good at CUDA Programming