Example analysis of simple crawler
With the exchange rate crawler demonstration written before
The website has been revised and this crawler code is invalid
But let's put it out and give you an introduction to reptiles
I am a novice, do not spray
import requests
from bs4 import BeautifulSoup
link = "https://www.msn. Cn / zh CN / money / currentyconverter "#msn Finance
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
soup = BeautifulSoup(r.text, 'html.parser')
list_soup = soup.find("div", class_= "mjrcurrncsrow mjcurrncs-data")
for money_info in soup.find_all('div',class_='mcrow'):
name = money_info.find("span",class_="cntrycol").get_text("title").strip()
exchange_rate= money_info.find("span", class_= "pricecol").get_text("aria-label").strip()
Money_data = {
'currency': name,
'exchange rate': exchange_rate
}
print (Money_data)
import requests#This package is used to access the website
from bs4 import BeautifulSoup
link = "https://www.msn. Cn / zh CN / money / currentyconverter "#msn Finance
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
headers are the following requests The parameters of the get function can be viewed in the documents of the requests package. OK, let me show you. In fact, this header is the header information of HTTP.
When visiting the website, sometimes you must provide your browser information (header information), and the 'user agent' inside is the user agent configuration, which is used to disguise your crawler as normal access.
The above code is the user agent configuration of Firefox browser
The crawler is disguised as a normal access, but in fact, if you access too fast and too much, it is easy to be seen, and then the IP is blocked. Generally, the IP will only last 24 hours. Don't worry.
If you are blocked, a 403 error is usually displayed
How do I view user agents? Enter a browser and enter the browser name in the blank website bar: / / version, for example, enter edge://version Enter to view
Note that {'user agent': '(inside this)' is the user agent data.
r = requests.get(link, headers= headers)
Actually, requests The get () function also has other parameters. It is about the knowledge of HTTP in the computer network and is used for url splicing query.
These two parameters should be sufficient
Now we climb out of r, in fact, is the content of the server response when we visit the website.
You can add a sentence after the above code
print(r.text)
Comment out all the following code and run it. The output is the HTML source code of the website. It is equivalent to opening the browser web page and pressing F12 to see the code. All the data we want is contained in it.
The text suffix must be added in order to correctly output the text form.
requests is the only non GMO Python HTTP library that humans can safely enjoy. Attach a link to the official document Requests: make HTTP service human - Requests 2.18.1 document (python-requests.org)
Beautiful Soup is a Python library that can extract data from HTML or XML files, with links to official documents Beautiful Soup 4.2.0 documentation
Beautiful Soup is the key point to learn, because we need to extract key information to facilitate our analysis when we climb to the data.
soup = BeautifulSoup(r.text, 'html.parser')
The meaning of this code is to put the source code we crawled out into the beautiful Soup for parsing. The latter parameter is the HTML parser we specified parser. This parser is located in python's standard library and does not need to be installed separately. Of course, there are other parsers, but they need to be installed. For details of the parser, please refer to the official documentation of beautiful soup.
Then the code is parsed. You can add a sentence after the above code
print(soup)
All comments are also left out later. It is found that the output is more neat than print(r.text). This is because Beautiful Soup transforms complex HTML documents into a complex tree structure, and each node is a Python object.
Simply put, we should use the find function in Beautiful Soup,
list_soup = soup.find("div", class_= "mjrcurrncsrow mjcurrncs-data")
The usage is to add the find suffix to the soup we resolved before. The find function searches by node. The detailed usage is in the official documents.
In the front quotation marks is the name of the label. For example, < div > or < p >, < span >
This is followed by the class attribute of the tag. The find function can only use the class attribute to query, not other attributes of the tag. It's written in class_= "" note the sign ''
After this code is executed, put the node code of < div class = "mjrcurrncsrow mjcurrncs data" > and its child nodes into the list_ It's inside the soup.
You can add a sentence after it
print(list_soup)
Look at the results.
Then the difficulty is to find the data we want to extract on the browser.
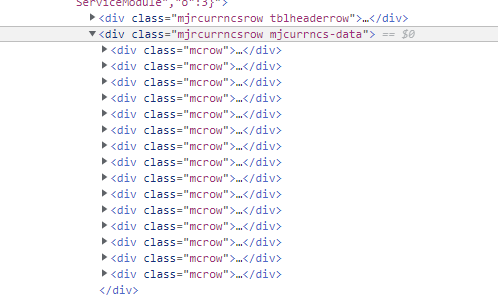
Click the above line of code to see the figure below
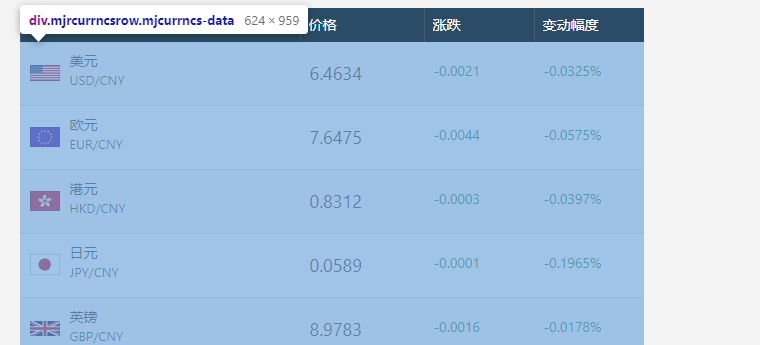
These are selected, which proves that the data we want is in the collapse of this line of code < div class = "mjrcurrncsrow mjcurrncs data" >. You can observe that its child nodes are < div class = "mcrow" > like this.
Continue to select downlink code observation


Find the key points, and then use the method shown in the figure below
Click this button (I use the edge browser)
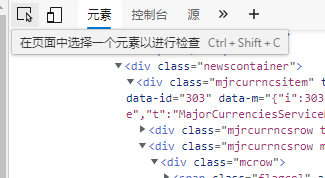
Select dollar
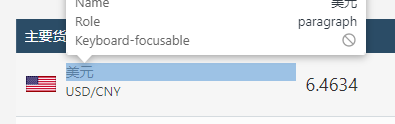
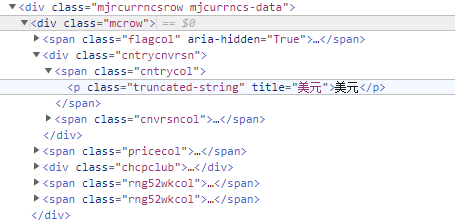
The blue line is the code of the selected dollar data, but observe other data
You will find that there are many tags with the same name < div class = "mcrow" >, which will be a problem in crawling many websites
Open another label with the same name and observe

You will find that these tags < span > and class attributes are exactly the same as the previous dollar.
If we just use
name = money_info.find("span",class_="cntrycol").get_text("title").strip()
To query, you will only find us dollars without other data. The same is true of exchange rate data
So we use the for loop
for money_info in soup.find_all('div',class_='mcrow'):
Batch data processing. And money_info is the result of each query using the find function. The code snippet of < div class = "mcrow" > is displayed.
For example, the first cycle, money_info is the code of the dollar child node
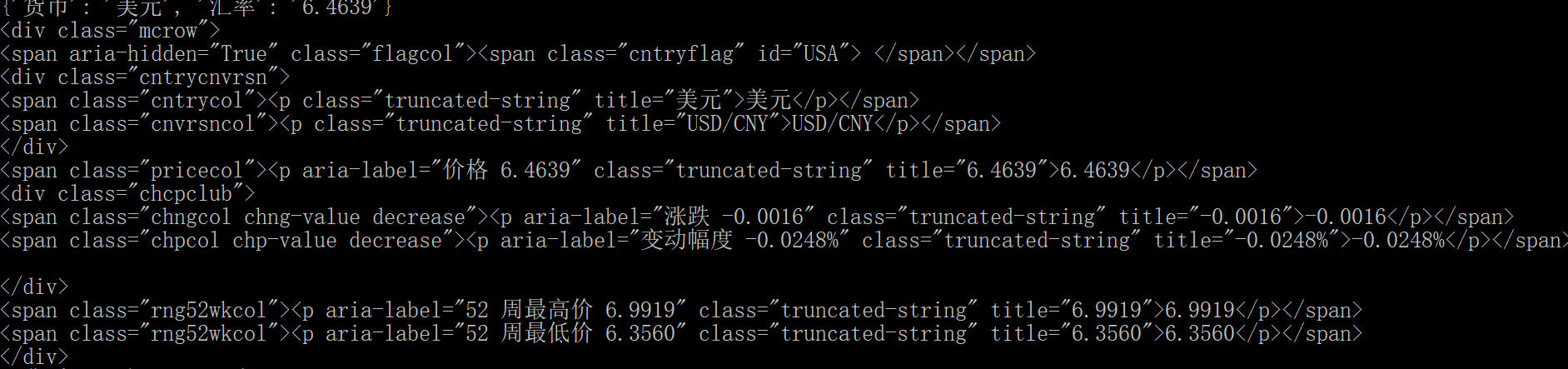
And find_all is a function similar to find. find_ The all () method searches all tag child nodes of the current tag and determines whether the filter conditions are met.
find_ The all () method will return all tags in the document that meet the criteria, although sometimes we just want to get a result For example, if there is only one < body > tag in the document, use find_ The all () method is not appropriate to find the < body > tag,
find will only output the first search result.
Details of usage are in the official documents. The above instructions are also extracted from official documents.
Pay attention to find_all() returns a list containing many elements. We use for to process each element in the list in turn.
Next, analyze the code in the for loop,
First sentence
name = money_info.find("span",class_="cntrycol").get_text("title").strip()
money_info is actually an object parsed and processed by beautiful soup, just like the above soup and soup_list, and then we use the find function to query the node where the dollar name data is located. This requires us to actively find the node where the data we want is located. Then query.
"span" is the parameter, the label of the node, and the class_ It is also a parameter. The following "cntrycol" is the CSS class name, which is also used to determine the location of data.
And the suffix get_text is also a function in BeautifulSoup,
If you only want to get the text content contained in the tag, you can use get_text() method, which gets all the text content contained in the tag, including the content in the child tag, and returns the result as a Unicode string.
Here I want to correct a mistake, that is get_ The parameter of text is not used like this. The following is the description of the official document.
markup = '<a href="http://example.com/">\nI linked to <i>example.com</i>\n</a>' soup = BeautifulSoup(markup) soup.get_text() u'\nI linked to example.com\n' soup.i.get_text() u'example.com'
You can specify the separator of the text content of tag through parameters:
# soup.get_text("|")
u'\nI linked to |example.com|\n'
You can also remove the front and back blanks of the obtained text content:
# soup.get_text("|", strip=True)
u'I linked to|example.com'
So in my code, get_ The parameter "title" of text () is invalid and can be removed. Before that, only the text content of USD was found in the node (where the data is located) found by the find function.
And observe that there are no blank characters and newline characters on the left and right of the text, so it is not necessary strip() is the suffix of this function.
So the code can be written like this
name = money_info.find("span",class_="cntrycol").get_text()
The same effect.

Select the exchange rate and observe the code** Pay attention! The black text I circled (the only one that shows black in this line of code) is the text content** The previous title = "USD", title="6.4634", Aria label = "price 6.4634" are the attributes of HTML tags. Not text content. So we use get_ The text() function gets the dollar and 6.4634.
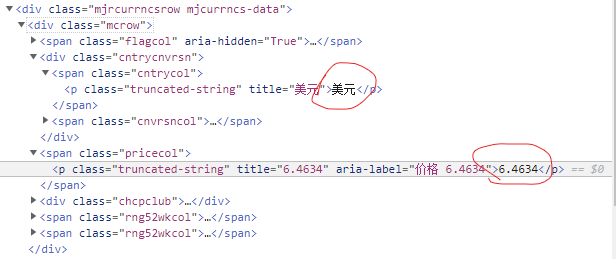
exchange_rate= money_info.find("span", class_= "pricecol").get_text("aria-label").strip()
In the same way, you can also delete some useless code.
exchange_rate= money_info.find("span", class_= "pricecol").get_text()
At this point, you can find that for parameters, sometimes double quotation marks "" and sometimes single quotation marks' '. In Python, double quotation marks and single quotation marks can be mixed, and there is no difference between them.
Then we build a dictionary and put the data in it. Then print out.
Money_data = {
'currency': name,
'exchange rate': exchange_rate
}
When you print a dictionary, there will be a line break character after it to wrap a line.
Use the for loop to print the dictionary every time.
So the final code is
import requests
from bs4 import BeautifulSoup
link = "https://www.msn. Cn / zh CN / money / currentyconverter "#msn Finance
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
soup = BeautifulSoup(r.text, 'html.parser')
list_soup = soup.find("div", class_= "mjrcurrncsrow mjcurrncs-data")
for money_info in soup.find_all('div',class_='mcrow'):
name = money_info.find("span",class_="cntrycol").get_text()
exchange_rate= money_info.find("span", class_= "pricecol").get_text()
Money_data = {
'currency': name,
'exchange rate': exchange_rate
}
print (Money_data)
The results are as follows,
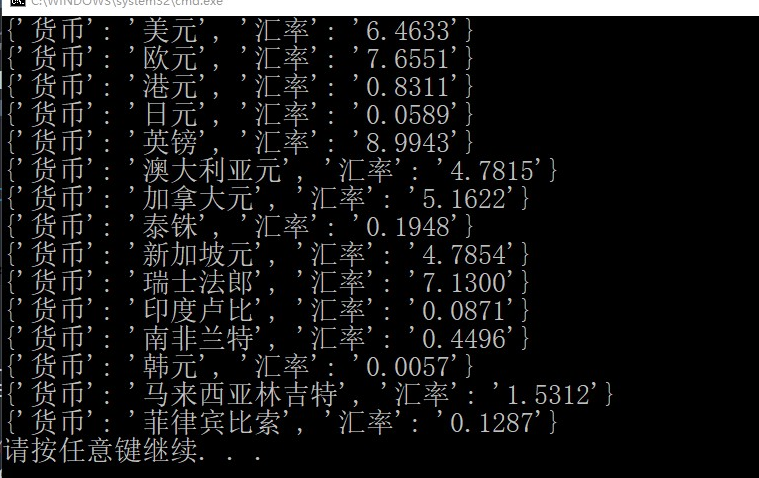
Although not very beautiful. ha-ha.
Our reptile is finished!
Of course, this is only a very, very simple case. For some websites with complex mechanisms, such as crawling book information in Douban, because there are many books, we need to turn the page, which requires us to realize the page turning function in the code. There are also methods, but they are more complex. You can know it by Baidu. In addition, some websites also need login verification. Of course, these are more complex. We need to cheat the website for verification. In addition, if you climb too much in a short time, you may be blocked. In order to avoid this situation, we can also carry out IP proxy. These operations are also very complex.
In conclusion, reptiles are actually illegal. Try to restrain yourself.
.