1, Introduction to MP2
1. What is MP2
MP2 is the abbreviation of MPEG-1 Layer II. It is a lossy compressed audio format with file extension mp2. For people in the radio and television production industry, MP2 is a very common audio file format. MP2 is mainly used in digital audio and video coding of standardized digital broadcasting and digital television broadcasting (DAB, DMB, DVB). The standard MPEG II audio format supports 32, 44.1 and 48 kHz sampling rates and bit rates of 32 to 320 kbps / s.
**Note: * * MP2 audio file is not MPEG-2 video file. MPEG - 2 is the standard of video coding, and its extension is mpg.
2. Advantages and disadvantages of MP2
1) Advantages
- When the bit rate of MP2 reaches 256kbps and above, it can have good error recovery ability and better sound quality. It is the leading audio standard in the radio and television industry.
- Compared with MP3, MP2 format has better sound quality.
2) Shortcomings
MP2 file format is usually used in the radio and television industry, so its support rate on ordinary audio players is not high. Before playing MP2 format audio on some players, it is necessary to convert the audio format.
3. Compare with MP3
MP2 and MP3 are both lossy audio formats, but there are some differences between them. In terms of audio data, MP2 has smaller data compression than MP3, resulting in larger audio files. MP2 files compress the audio signal in the ratio of 6:1 And 8:1, while MP3 files compress in the ratio of 10:1 to 12:1. Mp3 with smaller files is easier to spread on the Internet. In terms of application range, MP3 has a wider application range. Mp3 can play well in computers, Internet applications and various audio playback devices, while MP2 is mainly used in the digital radio and television industry.
2, Introduction to MPEG
1. What is MPEG-1
MPEG-1 is the first lossy video and audio compression standard formulated by MPEG organization. Video compression algorithm was defined in 1990. At the end of 1992, MPEG-1 was officially approved as an international standard. MPEG-1 is a video and audio compression format customized for CD media. The transmission rate of a 70 minute CD is about 1.4Mbps. MPEG-1 adopts block motion compensation, discrete cosine transform (DCT), quantization and other technologies, and optimizes the transmission rate of 1.2Mbps. MPEG-1 was subsequently adopted as the core technology by Video CD.
2. Audio layering
MPEG-1 audio is divided into three layers: MPEG-1 Layer1, MPEG-Layer2 and MPEG-Layer3, and the high layer is compatible with the low layer. The third layer protocol is called MPEG-1 Layer 3, or MP3 for short. Mp3 has become a widely spread audio compression technology. This experiment focuses on MP2 (MPEG-Layer2).
MPEG-1 Layer1 adopts 192kbit/s per channel, 384 samples per frame, 32 equal width subbands and fixed segmented data blocks. Subband coding uses DCT (discrete cosine transform) and (fast Fourier transform) to calculate the quantization bit number of subband signal. The psychoacoustic model based on frequency domain masking effect is adopted to make the quantization noise lower than the masking value. Quantization adopts linear quantizer with dead band, which is mainly used for digital cassette (DCC).
MPEG-1 Layer2 adopts 128kbit/s per channel, 1152 samples per frame and 32 subbands, belonging to different framing methods. The psychoacoustic model of common frequency domain and time domain masking effect is adopted, and the bit allocation in high, medium and low frequency bands is limited, and the bit allocation, scale factor and sampling are additionally coded. Layer2 is widely used in digital TV, CD-ROM, CD-I and VCD.
MPEG-1 Layer3 adopts 64kbit/s per channel, uses hybrid filter banks to improve the frequency resolution, and is divided into 6X32 or 18X32 subbands according to the signal resolution, so as to overcome the disadvantage of low resolution of Layer1 and Layer2 with an average of 32 subbands in the medium and low frequency band. Psychoacoustic model 2 is adopted, an uneven quantizer is added, and the quantized value is entropy coded. It is mainly used for ISDN (Integrated Services Digital Network) audio coding.
MPEG-1 was formulated in 1992 and designed for industrial standard. It can compress images with SIF standard resolution (352X240 for NTSC system and 352x288 for PAL system). The transmission rate is 1.5Mbits/sec and plays 30 frames per second. It has CD (refers to CD) sound quality, and the quality level is basically equivalent to VHS. The encoding rate of MPEG can reach up to 4- 5Mbits/sec, but with the increase of the rate, the decoded image quality decreases.
MPEG-1 is also used for video transmission over digital telephone networks, such as asymmetric digital subscriber line (ADSL), video on demand (VOD), and educational networks. At the same time, MPEG-1 can also be used as a recording medium or transmit audio on the INTERNET.
3, Audio coding -- perceptual characteristics of human auditory system
1. Audio compression - redundant information
There are mainly two aspects of redundant information in uncompressed digital audio signals:
First, there is redundancy in the sound signal itself: the signal amplitude distribution is non-uniform (the probability of small amplitude samples is higher than that of large amplitude samples), and there is correlation between samples (time-domain redundancy);
Second, according to the auditory characteristics of human ears, the parts irrelevant to hearing can not be coded.
2. Perceptual characteristics of human auditory system
1) Isoloudness curve
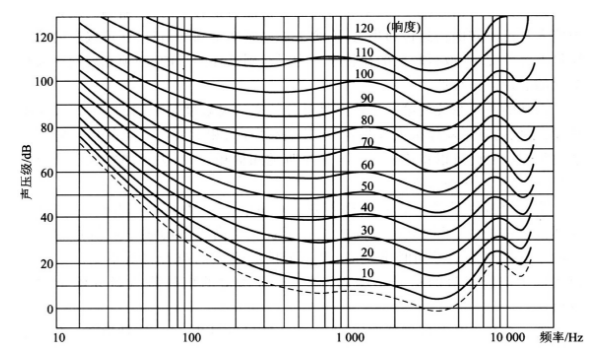
Each curve in the figure represents the same loudness felt by the human ear, and the lowest curve represents the minimum audible threshold. The sound in the lower area cannot be detected by the human ear, so it can not be encoded.
2) Frequency domain masking effect
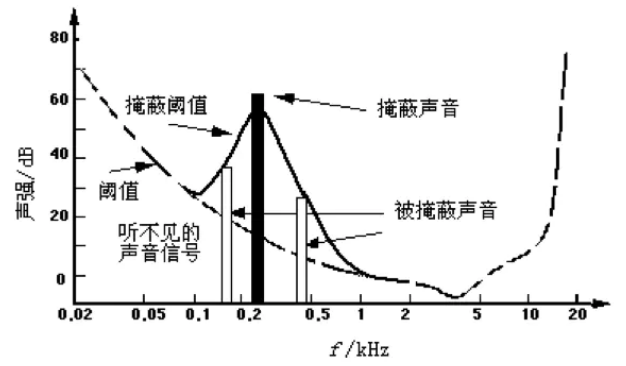
The above figure shows the masking effect of pure tone with sound intensity of 60 dB and frequency of 1000 Hz
A strong pure tone will mask the weak pure tones that sound nearby at the same time. This feature is called frequency domain masking, also known as simultaneous masking, as shown in the above figure.
As can be seen from the above figure, the sound with sound frequency around 300 Hz and sound intensity of about 60 dB masks the sound with sound frequency around 150 Hz and sound intensity of about 40 db. Another example is a pure tone with a sound intensity of 60 dB and a frequency of 1000 Hz, and another pure tone with a frequency of 1100 Hz. The former is 18 dB higher than the latter. In this case, our ears can only hear the strong tone of 1000 Hz. If there is a pure tone of 1000 Hz and a pure tone of 2000 Hz with a sound intensity 18 dB lower than it, our ears will hear both sounds at the same time. If you want 2000 Hz pure tone to be inaudible, you need to reduce it to 45 dB lower than 1000 Hz pure tone. Generally speaking, the closer the weak pure tone is to the strong pure tone, the easier it is to be masked.
3. Time domain masking effect
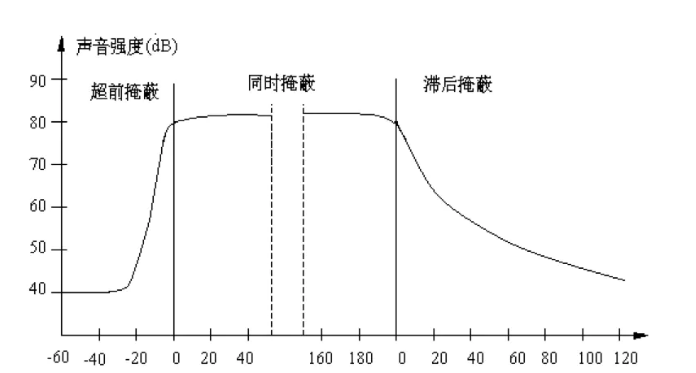
The above figure shows the time domain masking diagram
In addition to masking between simultaneous sounds, there is also masking between adjacent sounds in time, which is called time-domain masking. Time domain masking is divided into pre masking and post masking, as shown in the figure above. The main reason for time-domain masking is that it takes a certain time for human brain to process information. Generally speaking, the lead masking is very short, only about 5 ~ 20 ms, while the lag masking can last for 50 ~ 200 ms.
The synchronous masking effect is related to the frequency and relative volume of different frequencies, while the time masking is only related to time.
If the two sounds are very close in time, we will have difficulty in distinguishing them. For example, if a loud sound is followed by a weak sound, the latter sound is difficult to hear. However, if the second sound is played after the first sound stops for a period of time, the latter sound can be heard. For pure tone, the interval is generally 5 milliseconds. Of course, if the timing is reversed, the effect is the same. If a lower voice appears before a higher voice and the interval is very short, we can't hear the lower voice.
4, MPEG-1 audio compression coding
1. Schematic diagram of MPEG-1 Audio LayerII encoder
Perceptual audio coding is adopted in MPEG-1. The schematic diagram of MPEG-1 Audio LayerII encoder is as follows
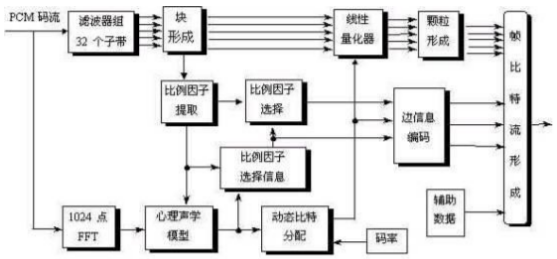
It can be seen that the encoder is divided into two parts: the upper part is the subband coding part, which is also the main line of coding; The lower part is the part where MPEG audio coding allocates bits and other contents according to requirements.
2. MPEG-I psychoacoustic model
The psychoacoustic model determines the maximum quantization noise allowed in each subband, and the quantization noise less than it will be masked. If the signal power in the subband is less than the masking threshold, no coding is performed; Otherwise, the number of bits required for the coefficients to be encoded is determined so that the noise caused by quantization is lower than the masking effect;
◼ Through the subband analysis filter bank, the signal has high time resolution to ensure that the encoded sound signal has high enough quality in the case of short shock signal
◼ In addition, the signal can have high frequency resolution through FFT operation. Here, Layer II adopts 1024 point FFT (512 points in Layer I), which can obtain more accurate spectrum characteristics.
◼ In the low-frequency subband, in order to protect the structure of tone and formant, it is required to use smaller quantization order and more quantization stages, that is, allocate more bits to represent the sample value. The friction sound and noise like sound in speech usually appear in the high-frequency subband, and less bits are allocated to it
◼ Decompose the audio signal into "tones" and "non tones / noise": because the masking ability of the two signals is different
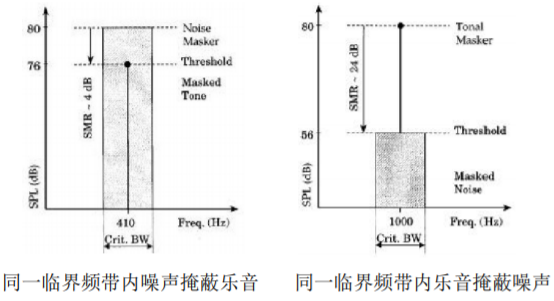
◼ Elimination of tonal and non tonal masking components
Using the absolute threshold given in the standard to eliminate the masked components; Consider that in each critical frequency band, only the component with the highest power is retained in the distance less than 0.5Bark
◼ Calculation of single masking threshold
The single masking threshold of tonal component and non tonal component is obtained according to the algorithm given in the standard.
◼ Calculation of global masking threshold

3. Polyphase filter
The digital audio signal is transformed into 32 equal broadband bands through a polyphase filter bank, which makes the signal have high time resolution and ensures that the encoded sound signal has high enough quality in the case of short impact signal.
However, it should be noted that high time-domain resolution and high-frequency domain resolution can not have both, and we need to make a trade-off.
The output of the filter bank is the quantized coefficient sample of the critical frequency band. If a subband covers multiple critical bands, the critical band with the minimum NMR is selected to calculate the number of bits allocated to the subband.
4. Rate allocation
Noise to mask ratio (NMR):
NMR = SMR – SNR (dB)
SNR is given by MPEG-I standard (as a function of quantization level)
NMR: indicates the error between waveform error and perceptual measurement
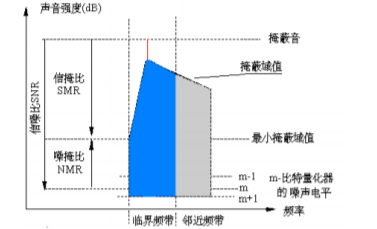
Algorithm: minimize the total noise masking ratio of the whole frame and each subband
Specific methods:
1. Calculate the mask noise ratio MNR (dB) for each subband
2. Find the subband with the lowest MNR and allocate more bits to the subband,
3. Recalculate MNR, continue allocation, and repeat this step until no bits can be allocated.
In this way, the MNR can be minimized on the premise of meeting the requirements of bit rate and masking
5. Calculate scale factor
◼ Calculate the scale factor every 36 samples (Layer I is 12 samples) in each subband, first determine the maximum value of 12 continuous samples, and check the minimum value larger than it in the scale factor tables of Layer II and Layer I as the quantitative scale factor;
◼ A scale factor is calculated for every 12 sample values. In Layer II, each subband is divided into 3 groups with 12 sample values in each group. Therefore, 36 sample values have 3 scale factors;
◼ The scale factor can accurately calculate the sound pressure level of the subband;
◼ Generally, the scale factor decreases continuously from low frequency subband to high frequency subband;
5, MPEG-1 Audio Layer II encoder code debugging
1. Comments on important parts of encoder main() function
The code of the important part of the main() function. Comment the code according to the above coding steps:
int main (int argc, char **argv)
{
typedef double SBS[2][3][SCALE_BLOCK][SBLIMIT];
SBS *sb_sample;
typedef double JSBS[3][SCALE_BLOCK][SBLIMIT];
JSBS *j_sample;
typedef double IN[2][HAN_SIZE];
IN *win_que;
typedef unsigned int SUB[2][3][SCALE_BLOCK][SBLIMIT];
SUB *subband;
frame_info frame;//This structure contains header information, bit allocation table, number of subbands, etc
frame_header header;//This structure contains information such as sampling frequency
char original_file_name[MAX_NAME_SIZE];//File name entered
char encoded_file_name[MAX_NAME_SIZE];//Output file name
short **win_buf;
static short buffer[2][1152];
static unsigned int bit_alloc[2][SBLIMIT], scfsi[2][SBLIMIT];//Bit allocation table for storing each sub-band of dual channel
static unsigned int scalar[2][3][SBLIMIT], j_scale[3][SBLIMIT];// Scale factor of each sub-band storing 12 samples of 3 groups of dual channels
static double smr[2][SBLIMIT], lgmin[2][SBLIMIT], max_sc[2][SBLIMIT];
// FLOAT snr32[32];
short sam[2][1344]; /* was [1056]; */
int model, nch, error_protection;//nch: number of channels, error_protection: error protection measures
static unsigned int crc;
int sb, ch, adb;//abd: bit budget
unsigned long frameBits, sentBits = 0;
unsigned long num_samples;
int lg_frame;
int i;
/* Used to keep the SNR values for the fast/quick psy models */
static FLOAT smrdef[2][32];
static int psycount = 0;
extern int minimum;
time_t start_time, end_time;
int total_time;
sb_sample = (SBS *) mem_alloc (sizeof (SBS), "sb_sample");
j_sample = (JSBS *) mem_alloc (sizeof (JSBS), "j_sample");
win_que = (IN *) mem_alloc (sizeof (IN), "Win_que");
subband = (SUB *) mem_alloc (sizeof (SUB), "subband");
win_buf = (short **) mem_alloc (sizeof (short *) * 2, "win_buf");
/* clear buffers */
memset ((char *) buffer, 0, sizeof (buffer));
memset ((char *) bit_alloc, 0, sizeof (bit_alloc));
memset ((char *) scalar, 0, sizeof (scalar));
memset ((char *) j_scale, 0, sizeof (j_scale));
memset ((char *) scfsi, 0, sizeof (scfsi));
memset ((char *) smr, 0, sizeof (smr));
memset ((char *) lgmin, 0, sizeof (lgmin));
memset ((char *) max_sc, 0, sizeof (max_sc));
//memset ((char *) snr32, 0, sizeof (snr32));
memset ((char *) sam, 0, sizeof (sam));
global_init ();
header.extension = 0;
frame.header = &header;
frame.tab_num = -1; /* no table loaded */
frame.alloc = NULL;
header.version = MPEG_AUDIO_ID; /* Default: MPEG-1 */
total_time = 0;
time(&start_time);
programName = argv[0];//exe file name
if (argc == 1) /* no command-line args */
short_usage ();
else
parse_args (argc, argv, &frame, &model, &num_samples, original_file_name,//Command line parameters
encoded_file_name);
print_config (&frame, &model, original_file_name, encoded_file_name);//Output file parameters
/* this will load the alloc tables and do some other stuff */
hdr_to_frps (&frame);
nch = frame.nch;
error_protection = header.error_protection;
while (get_audio (musicin, buffer, num_samples, nch, &header) > 0) {//Get audio
if (glopts.verbosity > 1)
if (++frameNum % 10 == 0)
fprintf (stderr, "[%4u]\r", frameNum);
fflush (stderr);
win_buf[0] = &buffer[0][0];
win_buf[1] = &buffer[1][0];
adb = available_bits (&header, &glopts);//Calculate bit budget
lg_frame = adb / 8;
if (header.dab_extension) {
/* in 24 kHz we always have 4 bytes */
if (header.sampling_frequency == 1)
header.dab_extension = 4;
/* You must have one frame in memory if you are in DAB mode */
/* in conformity of the norme ETS 300 401 http://www.etsi.org */
/* see bitstream.c */
if (frameNum == 1)
minimum = lg_frame + MINIMUM;
adb -= header.dab_extension * 8 + header.dab_length * 8 + 16;
}
{
int gr, bl, ch;
/* New polyphase filter
Combines windowing and filtering. Ricardo Feb'03 */
for( gr = 0; gr < 3; gr++ )//Divide the 36 values into 3 groups
for ( bl = 0; bl < 12; bl++ )//Each group is divided into 12 offspring
for ( ch = 0; ch < nch; ch++ )
WindowFilterSubband( &buffer[ch][gr * 12 * 32 + 32 * bl], ch,
&(*sb_sample)[ch][gr][bl][0] );//Polyphase filter bank
}
#ifdef REFERENCECODE
{
/* Old code. left here for reference */
int gr, bl, ch;
for (gr = 0; gr < 3; gr++)
for (bl = 0; bl < SCALE_BLOCK; bl++)
for (ch = 0; ch < nch; ch++) {
window_subband (&win_buf[ch], &(*win_que)[ch][0], ch);
filter_subband (&(*win_que)[ch][0], &(*sb_sample)[ch][gr][bl][0]);
}
}
#endif
#ifdef NEWENCODE
scalefactor_calc_new(*sb_sample, scalar, nch, frame.sblimit);
find_sf_max (scalar, &frame, max_sc);
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR_new (*sb_sample, *j_sample, frame.sblimit);
scalefactor_calc_new (j_sample, &j_scale, 1, frame.sblimit);
}
#else
scale_factor_calc (*sb_sample, scalar, nch, frame.sblimit);//Calculate scale factor
pick_scale (scalar, &frame, max_sc);//Select scale factor
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
/* this way we calculate more mono than we need */
/* but it is cheap */
combine_LR (*sb_sample, *j_sample, frame.sblimit);
scale_factor_calc (j_sample, &j_scale, 1, frame.sblimit);
}
#endif
//Select psychoacoustic model to calculate SMR
if ((glopts.quickmode == TRUE) && (++psycount % glopts.quickcount != 0)) {
/* We're using quick mode, so we're only calculating the model every
'quickcount' frames. Otherwise, just copy the old ones across */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smr[ch][sb] = smrdef[ch][sb];
}
} else {
/* calculate the psymodel */
switch (model) {
case -1:
psycho_n1 (smr, nch);
break;
case 0: /* Psy Model A */
psycho_0 (smr, nch, scalar, (FLOAT) s_freq[header.version][header.sampling_frequency] * 1000);
break;
case 1:
psycho_1 (buffer, max_sc, smr, &frame);
break;
case 2:
for (ch = 0; ch < nch; ch++) {
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 3:
/* Modified psy model 1 */
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
break;
case 4:
/* Modified Psycho Model 2 */
for (ch = 0; ch < nch; ch++) {
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 5:
/* Model 5 comparse model 1 and 3 */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1 ");
smr_dump(smr,nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3 ");
smr_dump(smr,nch);
break;
case 6:
/* Model 6 compares model 2 and 4 */
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2 ");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4 ");
smr_dump(smr,nch);
break;
case 7:
fprintf(stdout,"Frame: %i\n",frameNum);
/* Dump the SMRs for all models */
psycho_1 (buffer, max_sc, smr, &frame);
fprintf(stdout,"1");
smr_dump(smr, nch);
psycho_3 (buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout,"3");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_2 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"2");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
case 8:
/* Compare 0 and 4 */
psycho_n1 (smr, nch);
fprintf(stdout,"0");
smr_dump(smr,nch);
for (ch = 0; ch < nch; ch++)
psycho_4 (&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT) s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout,"4");
smr_dump(smr,nch);
break;
default:
fprintf (stderr, "Invalid psy model specification: %i\n", model);
exit (0);
}
if (glopts.quickmode == TRUE)
/* copy the smr values and reuse them later */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smrdef[ch][sb] = smr[ch][sb];
}
if (glopts.verbosity > 4)
smr_dump(smr, nch);
}
#ifdef NEWENCODE
sf_transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation_new (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
//main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
write_header (&frame, &bs);
//encode_info (&frame, &bs);
if (error_protection)
putbits (&bs, crc, 16);
write_bit_alloc (bit_alloc, &frame, &bs);
//encode_bit_alloc (bit_alloc, &frame, &bs);
write_scalefactors(bit_alloc, scfsi, scalar, &frame, &bs);
//encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization_new (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);
//subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
// *subband, &frame);
write_samples_new(*subband, bit_alloc, &frame, &bs);
//sample_encoding (*subband, bit_alloc, &frame, &bs);
#else
transmission_pattern (scalar, scfsi, &frame);
main_bit_allocation (smr, scfsi, bit_alloc, &adb, &frame, &glopts);//Bit allocation
if (error_protection)
CRC_calc (&frame, bit_alloc, scfsi, &crc);
encode_info (&frame, &bs);//code
if (error_protection)
encode_CRC (crc, &bs);
encode_bit_alloc (bit_alloc, &frame, &bs);
encode_scale (bit_alloc, scfsi, scalar, &frame, &bs);
subband_quantization (scalar, *sb_sample, j_scale, *j_sample, bit_alloc,//quantification
*subband, &frame);
sample_encoding (*subband, bit_alloc, &frame, &bs);
#endif
/* If not all the bits were used, write out a stack of zeros */
for (i = 0; i < adb; i++)
put1bit (&bs, 0);
if (header.dab_extension) {
/* Reserve some bytes for X-PAD in DAB mode */
putbits (&bs, 0, header.dab_length * 8);
for (i = header.dab_extension - 1; i >= 0; i--) {
CRC_calcDAB (&frame, bit_alloc, scfsi, scalar, &crc, i);
/* this crc is for the previous frame in DAB mode */
if (bs.buf_byte_idx + lg_frame < bs.buf_size)
bs.buf[bs.buf_byte_idx + lg_frame] = crc;
/* reserved 2 bytes for F-PAD in DAB mode */
putbits (&bs, crc, 8);
}
putbits (&bs, 0, 16);
}
frameBits = sstell (&bs) - sentBits;
if (frameBits % 8) { /* a program failure */
fprintf (stderr, "Sent %ld bits = %ld slots plus %ld\n", frameBits,
frameBits / 8, frameBits % 8);
fprintf (stderr, "If you are reading this, the program is broken\n");
fprintf (stderr, "email [mfc at NOTplanckenerg.com] without the NOT\n");
fprintf (stderr, "with the command line arguments and other info\n");
exit (0);
}
sentBits += frameBits;
}
close_bit_stream_w (&bs);
if ((glopts.verbosity > 1) && (glopts.vbr == TRUE)) {
int i;
#ifdef NEWENCODE
extern int vbrstats_new[15];
#else
extern int vbrstats[15];
#endif
fprintf (stdout, "VBR stats:\n");
for (i = 1; i < 15; i++)
fprintf (stdout, "%4i ", bitrate[header.version][i]);
fprintf (stdout, "\n");
for (i = 1; i < 15; i++)
#ifdef NEWENCODE
fprintf (stdout,"%4i ",vbrstats_new[i]);
#else
fprintf (stdout, "%4i ", vbrstats[i]);
#endif
fprintf (stdout, "\n");
}
fprintf (stderr,
"Avg slots/frame = %.3f; b/smp = %.2f; bitrate = %.3f kbps\n",
(FLOAT) sentBits / (frameNum * 8),
(FLOAT) sentBits / (frameNum * 1152),
(FLOAT) sentBits / (frameNum * 1152) *
s_freq[header.version][header.sampling_frequency]);
if (fclose (musicin) != 0) {
fprintf (stderr, "Could not close \"%s\".\n", original_file_name);
exit (2);
}
fprintf (stderr, "\nDone\n");
time(&end_time);
total_time = end_time - start_time;
printf("total time is %d\n", total_time);
exit (0);
}
2. Basic functions
Enter - h on the command line to output its basic functions
The results shown in the figure below can be obtained
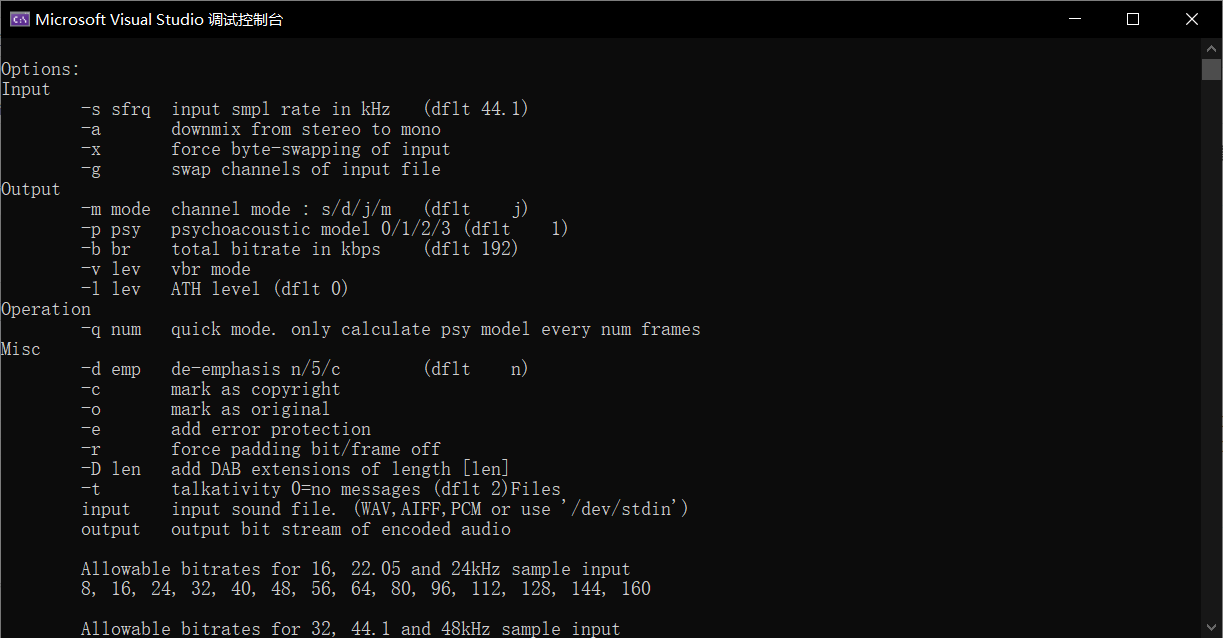
3. Basic command line parameters - Convert format to mp2
The basic command line parameters are as follows:
Command function parameter input file name output file name
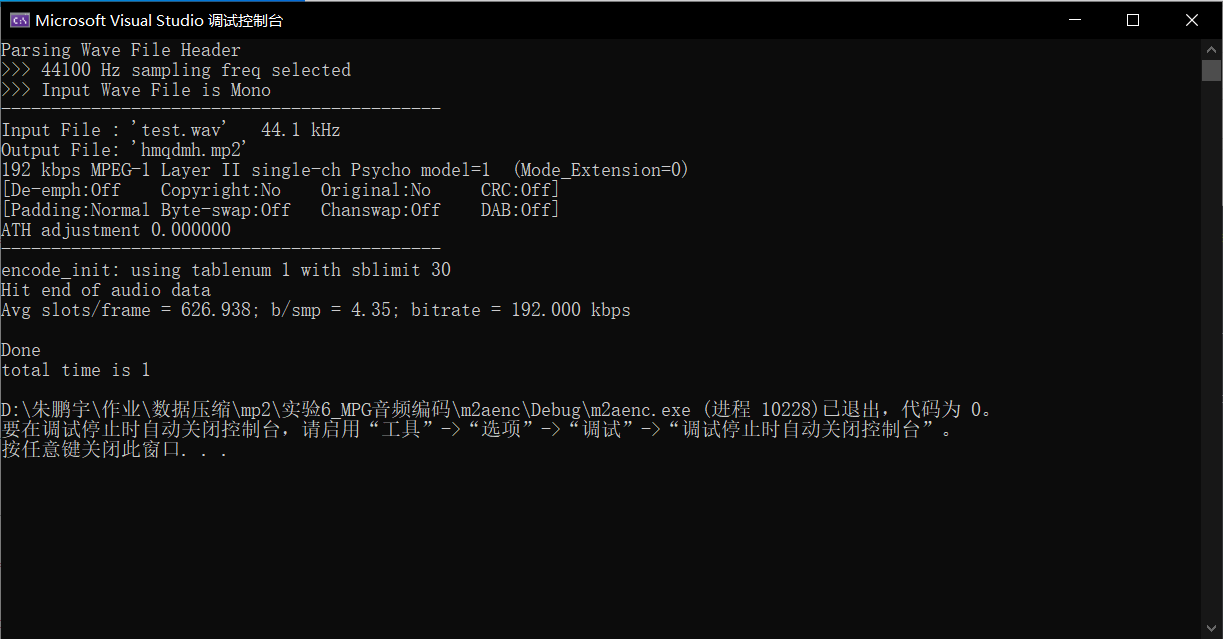
The input is shown in the figure below
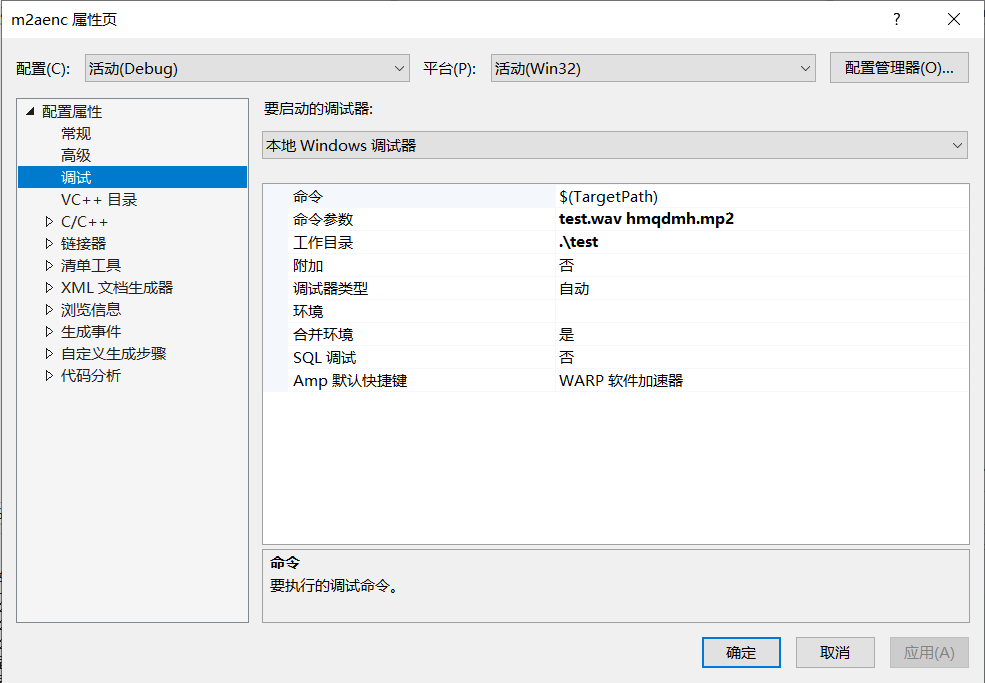
The default output bit rate (192 kbps) is used.
Running the program will get the results shown in the figure below and a mp2 file