Full text outline
It's not easy to create. I hope I can praise, comment and collect. Students who want to study together can chat privately. We can add groups and study together!!
Process is the most basic concept in the operating system. The definition of a process in Linux kernel design is "a process is a program in execution". Process is actually the execution process of a program. Since the birth of the computer, the architecture has been von Neumann's mode of storing instruction sets, which has not changed. After the code is edited - > compiled, an intermediate file will be generated, which may be a binary file or a file that can be recognized by some virtual machines. This file will be loaded into memory to complete the execution of the program in a specific environment, and the program is regarded as a process in the execution process.
Process lifecycle
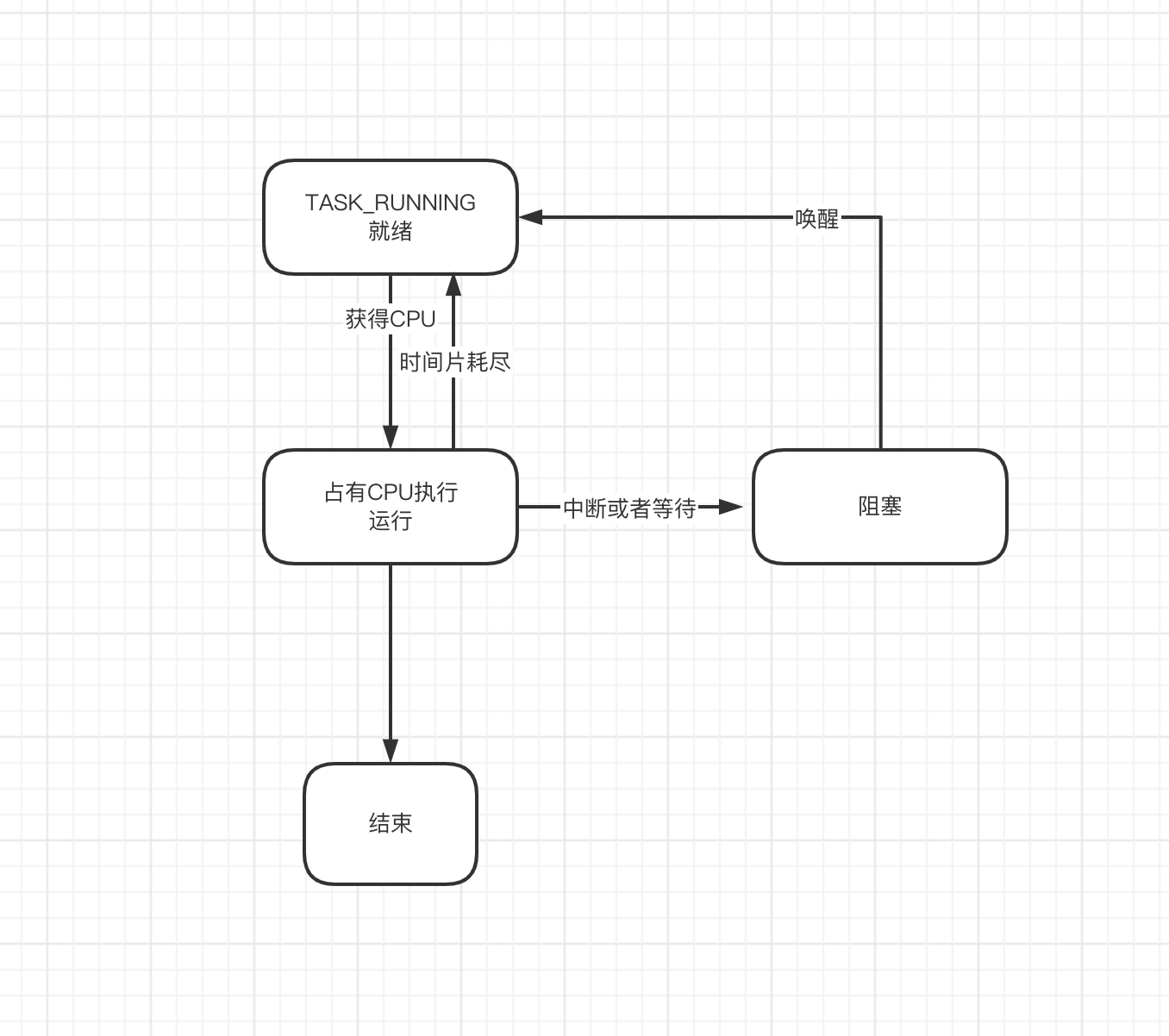
Processes are generally in one of these four states. How do we start a process when we start it?
In Linux, when a process is started, another process usually executes the fork call. This call will create a new process from the current process. When the Linux system is started, one process is process 0. At the beginning, all processes execute the fork call through this process to complete the process creation. After the fork is executed, the process will continue to call the exec method to complete the loading and initialization of the new process address space, and then enter the ready state. The process scheduler will select one from the currently ready process queue according to certain policies, allocate CPU time slices, and the process will enter the running state. The process during execution may be suspended, such as waiting for IO, or directly executing, or using the time slice or not executing. These three results correspond to the next different behavior of the process.
- If the wait condition is encountered, the process will be suspended and enter the blocking state
- If the execution is completed, the process enters a dead state (note that it is not a zombie process, but just two concepts). The process entering this state will wait for the wait() call of the parent process. If there is no parent process, the process will be hosted by process 0. Process 0 will execute a wait call to complete the final exit.
- If the time slice runs out, the process will enter the ready queue again and wait for the next execution.
So far, we have basically described the whole life process of the process. Next, the above steps will be described in detail.
Process descriptor
Here's a question:

What is the structure of the process in the operating system? Open the Linux source code. In Linux, every process is abstracted into a task. Linux is written in c language. c language has no concept of class. It is often used to describe a complex structure: stuct. Therefore, in Linux, the structure corresponding to the process is task_struct, in include / Linux / sched H inside:
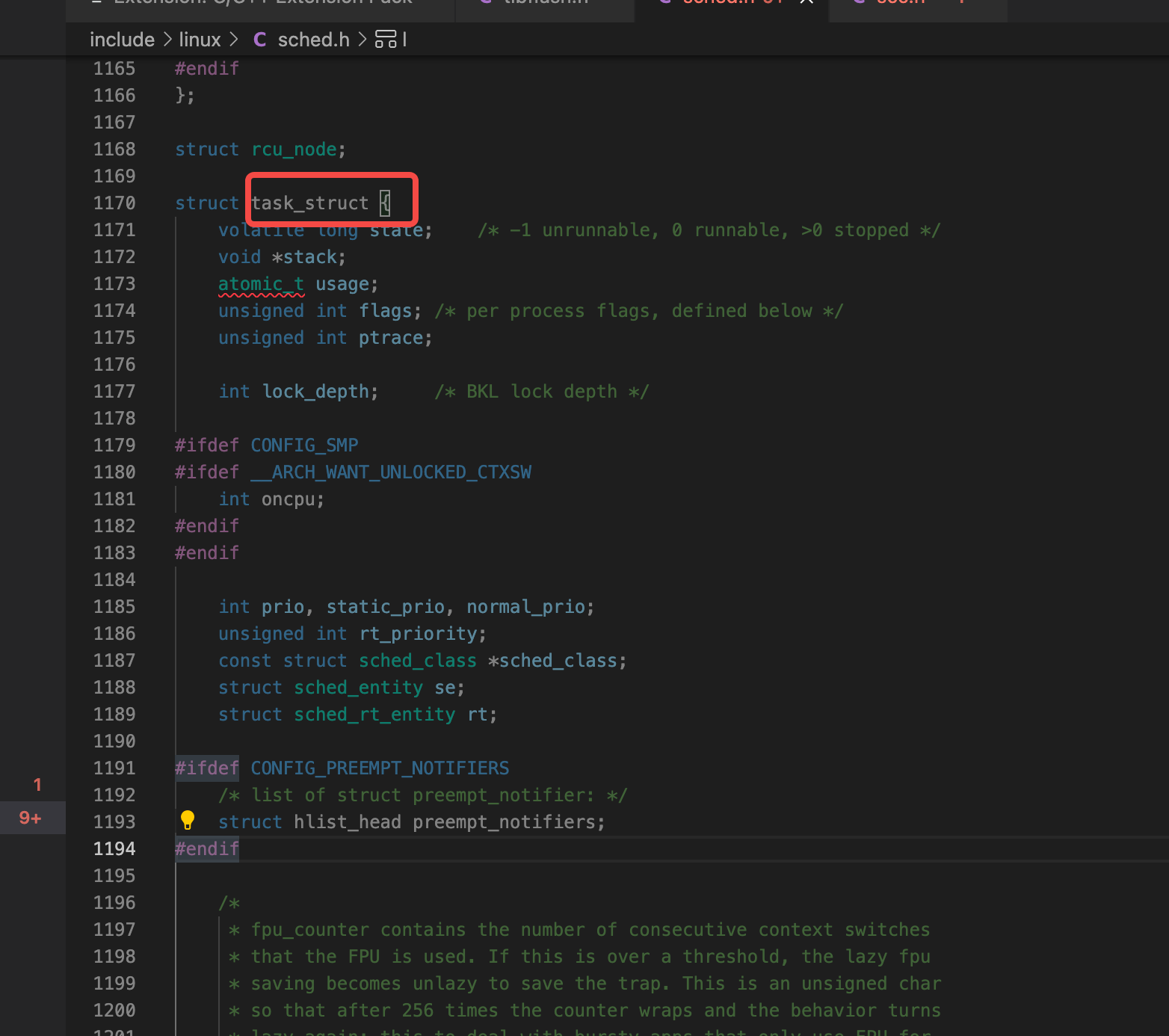
This structure is very large and has many fields. This structure is also called process descriptor. Used to describe all the properties and operations of a process.
In this structure, there are several important fields to focus on:
Process id:pid
In task_ In struct, there is a pid_t-type field: pid, which is the process number. It uniquely identifies a process globally.

In linux, you can use commands
ps -ef
View the pid of a process and the pid of the parent process
Process status: state
The state of the process is mentioned above. This state is in task_struct uses a long field to save

There are many others. You can turn them over if you are interested.
Create process
So, how do you create a process? Take a look at how the Linux operating system works.
Linux divides the creation process into two steps:
- Call fork to copy the current process descriptor (task_struct) to a new process and allocate pid.
- The new resource needs to be loaded by the exec process
Why do you do this? First, let's see what fork did
fork call
In the linux kernel, fork calls kernel/fork.. Do in C_ Fork (), take a look at this function.
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
The parameter of this function, clone_flags represent options when copying, such as whether to copy address space, whether to share cgroup, etc. do_fork has a lot of logic, but the core logic is:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
}
The last call is in copy_process, this function will complete the copy of the process and complete the new process task by copying the current process_ Assignment of struct.
copy_process
copy_ The process of process is also very complex. Simplify it as follows:
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
// Assign a structure
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
p->bts = NULL;
// Assign pid
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
if (clone_flags & CLONE_NEWPID) {
retval = pid_ns_prepare_proc(p->nsproxy->pid_ns);
if (retval < 0)
goto bad_fork_free_pid;
}
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
if (current->nsproxy != p->nsproxy) {
retval = ns_cgroup_clone(p, pid);
if (retval)
goto bad_fork_free_pid;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr: NULL;
// Set some cgroup options for this process
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
cgroup_fork_callbacks(p);
cgroup_callbacks_done = 1;
write_lock_irq(&tasklist_lock);
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
perf_event_fork(p);
return p;
}
copy_ After the simplification of process, the following things have been done:
1. Call dup_task_struct to create a structure instance for the new child process.
- Assign pid
- Set the unique members of the child process to distinguish it from the parent process.
- Return structure
As you can see from this function, in fact, copy_ What process does is very lightweight and only involves the copy of some fields. There is no copy for the address space and memory occupied by the process. This is the reason for the high performance of fork calls.
cow copy on write
It can be seen from the above that fork is actually just a copy, but it can some lightweight structures. For the memory held by the process, after forking, the new process and the parent process are shared. Many people can't understand this. Simply draw a picture:
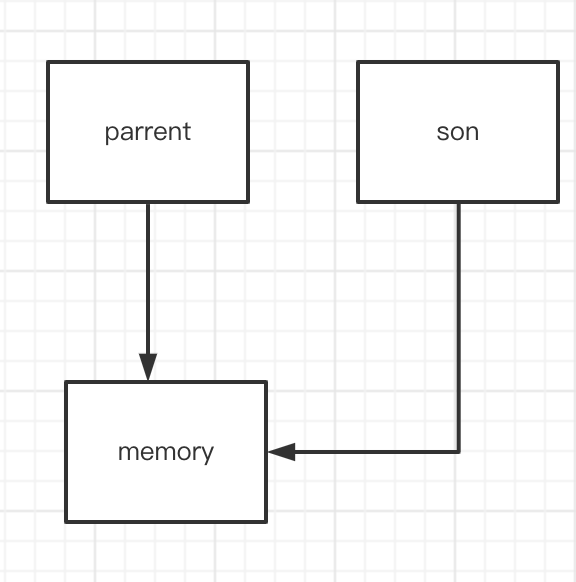
After forking, get the task_ The struct structure is actually a shallow copy. The parent and child processes hold the same pointer to the address space at the same time, which causes them to access the same address space. If both start writing this address space at the same time, there will be a data problem. If you make a deep copy directly in fork, the fork call overhead is actually very serious. In order to solve this problem, Linux uses copy on write technology
~~~~
Copy when writing, as the name suggests, is to copy when writing. The corresponding here is that the child process does not copy when reading the shared memory. If it is modified, it needs to copy a new piece of memory. This is also an inert modification. This scenario is very suitable for those read-only but not write subprocesses. For example, when Redis takes RDB snapshots, the subprocesses fork ed out are read-only but not write.
~~~
cow not only ensures the high performance of fork, but in some scenarios, after the child process is created, it will load its own address space. For example, it will open up its own memory to do some things without sharing with the parent process. This is also most scenarios. At this time, if the parent process gives priority to writing shared memory, memory copy will also occur, which is also an unnecessary overhead. In order to solve this problem, the linux operating system has made an optimization.
After fork ing, the child process exec function is called immediately to execute the child process logic, and it is intended to give priority to the child process.
Combined with the above description, I think this optimization is not difficult to understand.
At this point, a process is created.
Linux thread
In Linux, there is no concept of thread, which is quite different from other operating systems. Linux threads and processes are actually the same thing, using task_struct, but the member assignment is different. Most of the concepts now say that threads are lightweight processes. In fact, they mean that most of the resources of the newly created process regarded as threads are shared with the parent process and are not allowed to copy when writing. Use the address space of the current process to complete. Therefore, you will find that when using threads, race conditions may occur and synchronization is required. This is because the newly created threads share the current process resources!
Process scheduling
After creating the process, the process will access the ready state and wait for scheduling. Scheduling refers to that the operating system allocates cpu to processes according to a certain strategy and lets them use cpu to execute tasks.
Preemptive scheduling and cooperative scheduling
~~~
There are many strategies for Linux process scheduling, but there are only two core ideas, either preemptive scheduling or cooperative scheduling.
Preemptive scheduling: it means that the scheduler can forcibly suspend a task and then let the next task continue to execute.
Collaborative scheduling: collaborative scheduling refers to the process that needs to actively yield the CPU, and then other processes continue to execute.
~~~
Linux is designed from the beginning, which is the idea of preemptive scheduling. There will be many problems in cooperative scheduling. For example, after the process falls into the kernel, it obtains the cpu for execution. If it waits for a long time and does not give up the cpu, the system will fall into busy waiting time and other tasks will go into hunger. Preemptive scheduling can better control the time each process uses cpu.
Process priority and time slice
~~~ Since it is preemptive scheduling, there are several problems.
-
When to suspend the current task?
-
After suspending, which task to choose next to continue?
On these two issues, Linux introduces two concepts:
Time slice: time slice refers to how long the process runs. In Unix system, time slice and nice value correspond one by one. The value range of nice value is [- 19.20], and the higher the value, the lower the priority!
Process priority: each process has a priority. Those with high priority will get more time slices and run more frequently.
With these two concepts, process scheduling can be completed. for example
~~~ Nice value = 0 means it can run for 100ms, nice value = 20 means it can run for 5ms. Then consider the following two scenarios: -
If a nice value = 0 and a nice value = 20, the process with nice=0 will run for 100ms and the process with nice=20 will run for 5ms. Within 105ms, there is a process context switch, which is acceptable.
-
If there are two processes with nice=20, there will be two context switches in 10ms, which will obviously waste a lot of computing resources.
The scheduling method of getting up early linux does. In linux 2 After 6, a completely fair scheduling strategy CFS (complete fair schedule) is proposed Code in kernel/sched_fair.h medium.
CFS
CFS has four main components
- Time bookkeeping
- Process selection
- Scheduler entry
- Sleep and wake
Time bookkeeping
CFS no longer uses the concept of time slice, but instead accounts for the running time of each process
In / scheude.kernel In H: sched_entity records this information.
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 last_wakeup;
u64 avg_overlap;
u64 nr_migrations;
u64 start_runtime;
u64 avg_wakeup;
}
sum_exec_runtime is a record of the running time of a process. But CFS is not directly concerned with sum_exec_runtime, but the field below it: vruntime. This is called the process virtual runtime. CFS schedules the process according to the virtual runtime.
vruntime virtual runtime
The virtual runtime is the weighted result of the real running time of the process. The simplified calculation formula is as follows:
curr->vruntime += (delat_exec * 1024)/ curr->load->weight
delta_exec is the real runtime.
vruntime update
vruntime is updated in: kernel / sched_ fair. Medium H:
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_of(cfs_rq)->clock;
unsigned long delta_exec;
if (unlikely(!curr))
return;
/*
* Get the amount of time the current task was running
* since the last time we changed load (this cannot
* overflow on 32 bits):
*/
delta_exec = (unsigned long)(now - curr->exec_start);
if (!delta_exec)
return;
__update_curr(cfs_rq, curr, delta_exec);
curr->exec_start = now;
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
}
This function updates sched_ Relevant information in entity.
Process selection
The above describes how the virtual runtime is calculated and updated, so how does CFS use vruntime to select the next scheduled process?
CFS will select the process with the smallest vruntime to allocate CPU every time
Here is a brief description of why this is done, because CFS talks about perfect fair scheduling, but due to clock delay, perfect fairness does not exist, so we can only try to be fair. First, each process has a weight, which is determined by the nice value. The smaller the nice value, the higher the weight. According to the calculation formula, the higher the weight, the smaller the increase of vruntime for the same time each time. for instance.
~~~
For the two processes AB, the weight of A is 10 and the weight of B is 100. If they run for 100ms at the same time, the increase of vruntime for A is 10, but the increase of vruntime for B is 1. CFS selects the one with the smallest vruntime to execute each time, so B will be preferentially selected. It is equivalent to that B executes 10 times and A will be executed once. This also echoes with the weight.
Then there is another problem. How do you know which process has the smallest vruntime?
~~~
As mentioned above, each process has a unique process number: pid, so you can form a process queue according to this, and then sort, taking the smallest one each time. This is OK, but it needs to be reordered after each update, which is obviously unacceptable for software with high performance requirements such as the operating system. So how to support efficient minimum search and dynamic update?
~~~
The answer is red black tree! Some people may be afraid to see here. In fact, red and black trees are not so difficult, but many people don't know the specific application scenarios. Linux uses the red black tree to organize the runnable process queue. Each time, select the leftmost leaf node of the red black tree to run, and put it back after running.
static struct sched_entity *pick_next_entity(struct cfs_rq *cfs_rq)
{
struct sched_entity *se = __pick_next_entity(cfs_rq);
struct sched_entity *left = se;
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
/*
* Prefer last buddy, try to return the CPU to a preempted task.
*/
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
clear_buddies(cfs_rq, se);
return se;
}
This completes the specific selection logic. Space is limited, so I won't say how to update the nodes in the tree for the time being.
process exit
The process will exit after executing its own task. Exit from work is by: kernel / exit C completed.
It mainly includes:
- Set task_ The struct state field is PF_EXISTING
- Free up memory space
- Delete referenced resource descriptor
- Call exit_notify to tell the parent process to exit. If the parent process has exited, it will be sent to the init process
- Trigger schedule() to schedule a new process
After completing these operations, the process is in: EXIT_ZOMBIE state. Processes in this state will no longer be scheduled by the scheduler.
Orphan process
If the parent process is found to have exited when the process exits, this process is called an orphan process. When the orphan process exits, it will send a signal to the parent process and wait for the wait call of the parent process. If there is no parent process, the task in the orphan process_ Stauct resources will not be recycled. To solve this problem, call exit in the process_ When notify (), it will judge whether the parent process exists. If it does not exist, it will execute forget_original_parent(), and then managed to process 0, that is, init process.
forget_original_parent:
static void forget_original_parent(struct task_struct *father)
{
struct task_struct *p, *n, *reaper;
LIST_HEAD(dead_children);
exit_ptrace(father);
write_lock_irq(&tasklist_lock);
reaper = find_new_reaper(father);
list_for_each_entry_safe(p, n, &father->children, sibling) {
struct task_struct *t = p;
do {
t->real_parent = reaper;
if (t->parent == father) {
BUG_ON(task_ptrace(t));
t->parent = t->real_parent;
}
if (t->pdeath_signal)
group_send_sig_info(t->pdeath_signal,
SEND_SIG_NOINFO, t);
} while_each_thread(p, t);
reparent_leader(father, p, &dead_children);
}
write_unlock_irq(&tasklist_lock);
BUG_ON(!list_empty(&father->children));
list_for_each_entry_safe(p, n, &dead_children, sibling) {
list_del_init(&p->sibling);
release_task(p);
}
}
Find parent: find again_ new_ reaper()
static struct task_struct *find_new_reaper(struct task_struct *father)
{
struct pid_namespace *pid_ns = task_active_pid_ns(father);
struct task_struct *thread;
thread = father;
while_each_thread(father, thread) {
if (thread->flags & PF_EXITING)
continue;
if (unlikely(pid_ns->child_reaper == father))
pid_ns->child_reaper = thread;
return thread;
}
if (unlikely(pid_ns->child_reaper == father)) {
write_unlock_irq(&tasklist_lock);
if (unlikely(pid_ns == &init_pid_ns))
panic("Attempted to kill init!");
zap_pid_ns_processes(pid_ns);
write_lock_irq(&tasklist_lock);
/*
* We can not clear ->child_reaper or leave it alone.
* There may by stealth EXIT_DEAD tasks on ->children,
* forget_original_parent() must move them somewhere.
*/
pid_ns->child_reaper = init_pid_ns.child_reaper;
}
return pid_ns->child_reaper;
}
ending
Here, the process life cycle is basically clear, from how to create a process to process scheduling to exit. The next chapter explains the communication mode and synchronization mode between processes. It's not easy to create. I hope I can praise, comment and collect. Students who want to study together can chat privately. We can add groups and study together!!