preface
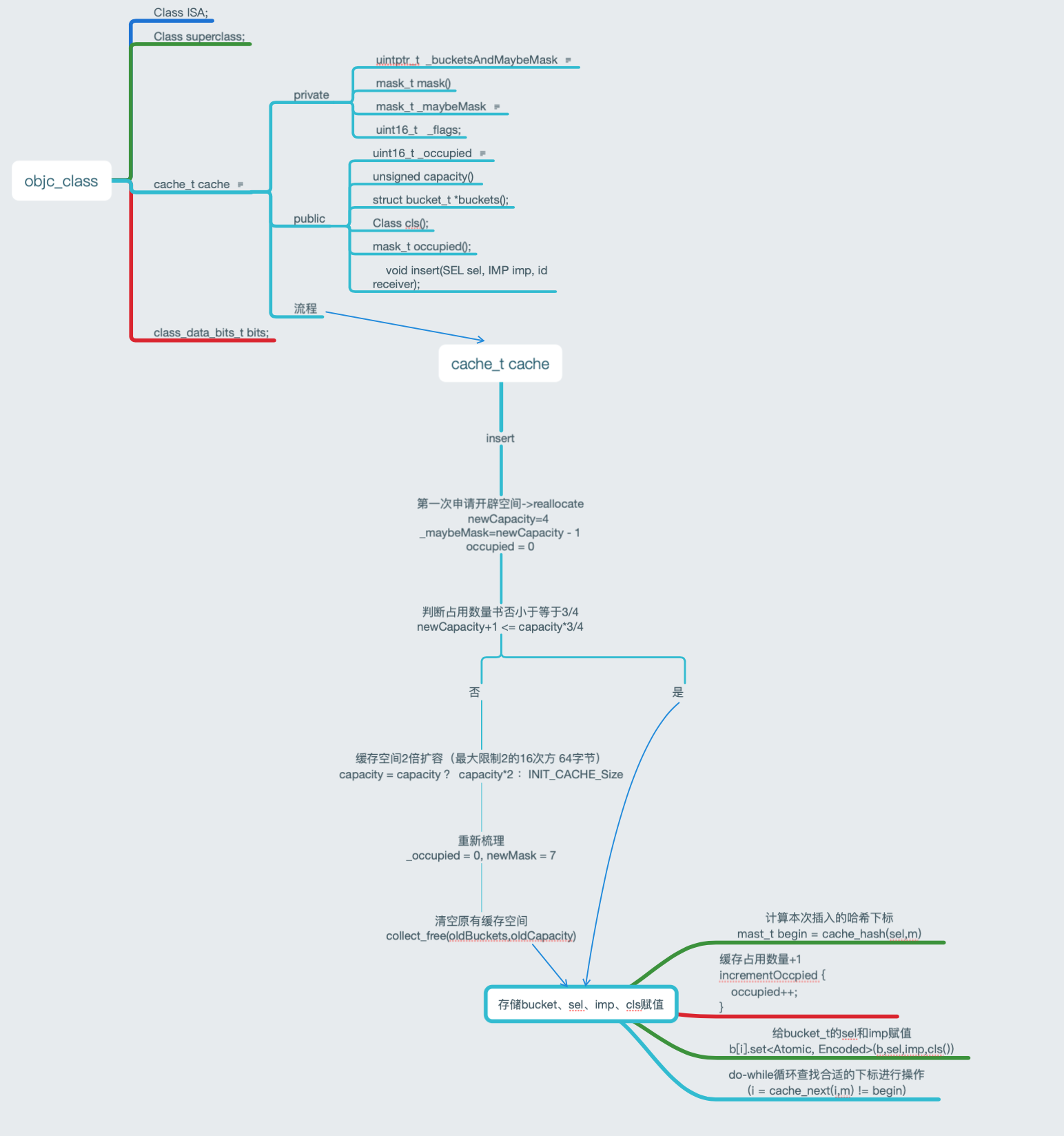
Before Exploration of OC class In this article, we mentioned that the father of NSObject is objc_class, which contains the following information
// Class ISA;
Class superclass;
cache_t cache; // formerly cache pointer and vtable
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
Today, let's explore cache_t.
1, Knowledge preparation
1. Array:
An array is a collection used to store multiple data of the same type. The main advantages and disadvantages are as follows:
Advantages: it is convenient and fast to access the content of a subscript Disadvantages: inserting, deleting and other operations in the array are cumbersome and time-consuming
2. Linked list:
Linked list is a non continuous and non sequential storage structure on the physical storage unit. The logical order of data elements is realized through the pointer link order in the linked list. The main advantages and disadvantages are as follows:
Advantages: it is easy to insert or delete elements of a node Disadvantages: it is time-consuming to access the elements of a location node one by one
3. Hash table:
It is a data structure directly accessed according to the key value. The main advantages and disadvantages are as follows:
Advantages: 1. The speed of accessing an element is very fast. 2. The operation of inserting and deleting is also very convenient Disadvantages: it needs to go through a series of operations, which is complex
2, cache_t interpretation
1.cache_t source code
Look at the cache first_ T data structure
struct cache_t {
private:
explicit_atomic<uintptr_t> _bucketsAndMaybeMask; // 8
union {
struct {
explicit_atomic<mask_t> _maybeMask; // 4
#if __LP64__
uint16_t _flags; // 2
#endif
uint16_t _occupied; // 2
};
explicit_atomic<preopt_cache_t *> _originalPreoptCache; // 8
};
//The cache is empty, which is used for the first time
bool isConstantEmptyCache() const;
bool canBeFreed() const;
// Total usable capacity, capacity - 1
mask_t mask() const;
// Double expansion
void incrementOccupied();
// Set buckets and mask
void setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask);
// Reopen memory
void reallocate(mask_t oldCapacity, mask_t newCapacity, bool freeOld);
// Reclaim oldBuckets based on oldCapacity
void collect_free(bucket_t *oldBuckets, mask_t oldCapacity);
public:
// Total capacity developed
unsigned capacity() const;
// Get buckets
struct bucket_t *buckets() const;
// Get class
Class cls() const;
// Gets the number of cached
mask_t occupied() const;
// Insert the called method into the memory area of buckets
void insert(SEL sel, IMP imp, id receiver);
`````ellipsis n Multi code·······
}
2.cache_t member variable
_ bucketsAndMaybeMask: store different information according to different architectures, X86_64 storage buckets, arm64 high 16 bit storage mask, low 48 bit buckets.
_ maybeMask: the capacity of the current cache, which is not used in arm64 architecture.
_ occupied: the number of methods currently cached.
Authentication under mac (x86#u 64)
(lldb) x/4gx MHPerson.class
0x100008618: 0x00000001000085f0 0x000000010036a140
0x100008628: 0x0000000101304e70 0x0001803000000003
(lldb) p (cache_t *) 0x0000000101304e70
(cache_t *) $1 = 0x0000000101304e70
(lldb) p *$1
(cache_t) $2 = {
_bucketsAndMaybeMask = {
std::__1::atomic<unsigned long> = {
Value = 0
}
}
= {
= {
_maybeMask = {
std::__1::atomic<unsigned int> = {
Value = 0
}
}
_flags = 0
_occupied = 0
}
_originalPreoptCache = {
std::__1::atomic<preopt_cache_t *> = {
Value = nil
}
}
}
}
3.cache_t function
3.1 cache_ Tinsert
3.1.1 Code:
void cache_t::insert(SEL sel, IMP imp, id receiver)
{
runtimeLock.assertLocked();
// Never cache before +initialize is done
if (slowpath(!cls()->isInitialized())) {
return;
}
if (isConstantOptimizedCache()) {
_objc_fatal("cache_t::insert() called with a preoptimized cache for %s",
cls()->nameForLogging());
}
#if DEBUG_TASK_THREADS
return _collecting_in_critical();
#else
#if CONFIG_USE_CACHE_LOCK
mutex_locker_t lock(cacheUpdateLock);
#endif
ASSERT(sel != 0 && cls()->isInitialized());
// Use the cache as-is if until we exceed our expected fill ratio.
mask_t newOccupied = occupied() + 1;
unsigned oldCapacity = capacity(), capacity = oldCapacity;
if (slowpath(isConstantEmptyCache())) {
// Cache is read-only. Replace it.
if (!capacity) capacity = INIT_CACHE_SIZE;
reallocate(oldCapacity, capacity, /* freeOld */false);
}
else if (fastpath(newOccupied + CACHE_END_MARKER <= cache_fill_ratio(capacity))) {
// Cache is less than 3/4 or 7/8 full. Use it as-is.
}
#if CACHE_ALLOW_FULL_UTILIZATION
else if (capacity <= FULL_UTILIZATION_CACHE_SIZE && newOccupied + CACHE_END_MARKER <= capacity) {
// Allow 100% cache utilization for small buckets. Use it as-is.
}
#endif
else {
capacity = capacity ? capacity * 2 : INIT_CACHE_SIZE;
if (capacity > MAX_CACHE_SIZE) {
capacity = MAX_CACHE_SIZE;
}
reallocate(oldCapacity, capacity, true);
}
bucket_t *b = buckets();
mask_t m = capacity - 1;
mask_t begin = cache_hash(sel, m);
mask_t i = begin;
// Scan for the first unused slot and insert there.
// There is guaranteed to be an empty slot.
do {
if (fastpath(b[i].sel() == 0)) {
incrementOccupied();
b[i].set<Atomic, Encoded>(b, sel, imp, cls());
return;
}
if (b[i].sel() == sel) {
// The entry was added to the cache by some other thread
// before we grabbed the cacheUpdateLock.
return;
}
} while (fastpath((i = cache_next(i, m)) != begin));
bad_cache(receiver, (SEL)sel);
#endif // !DEBUG_TASK_THREADS
}
3.1.2 interpretation
- Get the number of currently cached methods (0 for the first time), and then + 1.
- Get the cache capacity from, 0 for the first time.
- Judge whether it is the first cache method. The first cache will open up a memory space of capacity (1 < < init_cache_size_log2 (X86_64 is 2, arm64 is 1)) * sizeof(bucket_t), and set the bucket_ T * first address deposit_ bucketsAndMaybeMask: save the mask of newCapacity - 1 to_ maybeMask,_ occupied is set to 0.
- If it is not the first cache, judge whether it needs to be expanded (the cached capacity exceeds 3 / 4 or 7 / 8 of the total capacity). If it needs to be expanded, double the capacity (but not greater than the maximum value), and then reopen the memory as in step 3, and reclaim the memory of the old cache.
- The hash algorithm calculates the location of the method cache, and do{} while() loops to determine whether the current location can be saved. If the hash conflicts, it will continue to hash until the location that can be saved is found. If it is not found, it will call bad_cache function.
3.1.3 reallocate
code
ALWAYS_INLINE
void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity, bool freeOld)
{
bucket_t *oldBuckets = buckets();
bucket_t *newBuckets = allocateBuckets(newCapacity);
// Cache's old contents are not propagated.
// This is thought to save cache memory at the cost of extra cache fills.
// fixme re-measure this
ASSERT(newCapacity > 0);
ASSERT((uintptr_t)(mask_t)(newCapacity-1) == newCapacity-1);
setBucketsAndMask(newBuckets, newCapacity - 1);
if (freeOld) {
collect_free(oldBuckets, oldCapacity);
}
}
unscramble
Reopen the memory space with the size of newCapacity * sizeof(bucket_t) and_ T * first address deposit_ bucketsAndMaybeMask: save the mask of newCapacity - 1 to_ maybeMask and freeOld represent whether to recycle the old memory. It is false when inserting the method for the first time and true when expanding the capacity later. Call collect_ The free function empties and recycles.
3.1.4 cache_fill_ratio
code
#define CACHE_END_MARKER 1
// Historical fill ratio of 75% (since the new objc runtime was introduced).
static inline mask_t cache_fill_ratio(mask_t capacity) {
return capacity * 3 / 4;
}
unscramble
Reopen the memory space with the size of newCapacity * sizeof(bucket_t) and_ T * first address deposit_ bucketsAndMaybeMask: save the mask of newCapacity - 1 into_ maybeMask and freeOld represent whether to recycle the old memory. It is false when inserting the method for the first time and true when expanding the capacity later. Call collect_ The free function empties and recycles.
3.1.5 allocateBuckets
code
#if CACHE_END_MARKER
bucket_t *cache_t::endMarker(struct bucket_t *b, uint32_t cap)
{
return (bucket_t *)((uintptr_t)b + bytesForCapacity(cap)) - 1;
}
bucket_t *cache_t::allocateBuckets(mask_t newCapacity)
{
// Allocate one extra bucket to mark the end of the list.
// This can't overflow mask_t because newCapacity is a power of 2.
bucket_t *newBuckets = (bucket_t *)calloc(bytesForCapacity(newCapacity), 1);
bucket_t *end = endMarker(newBuckets, newCapacity);
#if __arm__
// End marker's sel is 1 and imp points BEFORE the first bucket.
// This saves an instruction in objc_msgSend.
end->set<NotAtomic, Raw>(newBuckets, (SEL)(uintptr_t)1, (IMP)(newBuckets - 1), nil);
#else
// End marker's sel is 1 and imp points to the first bucket.
end->set<NotAtomic, Raw>(newBuckets, (SEL)(uintptr_t)1, (IMP)newBuckets, nil);
#endif
if (PrintCaches) recordNewCache(newCapacity);
return newBuckets;
}
#else
// The M1 iMac goes here. Because the capacity created by M1 for the first time is 2 and the ratio is 7 / 8, endMarker is not set
bucket_t *cache_t::allocateBuckets(mask_t newCapacity)
{
if (PrintCaches) recordNewCache(newCapacity);
return (bucket_t *)calloc(bytesForCapacity(newCapacity), 1);
}
#endif
unscramble
Open up a memory space of the size of newCapacity * sizeof(bucket_t) and create a new bucket_ T pointer, cache_ end_ When the marker is 1 (______ x86___ 64_______________________ T pointer, sel is 1, imp is newBuckets (the first address of the cache) or newBuckets - 1 according to the schema, and class is nil.
Description of capacity expansion strategy:
Why empty oldBuckets instead of expanding space and then attach a new cache?
First, if the old buckets Take out all the caches and put them into a new one buckets,Consuming performance and time; Second, Apple's cache strategy believes that the newer the better. For example, A After a method is called once, the probability of being called again is very low, It is meaningless to keep the cache after capacity expansion. If you call it again A Method, it will cache again until the next capacity expansion; Third, prevent the infinite increase of cache methods, resulting in slow method search.
3.1.6 setBucketsAndMask
code
void cache_t::setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask)
{
// objc_msgSend uses mask and buckets with no locks.
// It is safe for objc_msgSend to see new buckets but old mask.
// (It will get a cache miss but not overrun the buckets' bounds).
// It is unsafe for objc_msgSend to see old buckets and new mask.
// Therefore we write new buckets, wait a lot, then write new mask.
// objc_msgSend reads mask first, then buckets.
#ifdef __arm__
// ensure other threads see buckets contents before buckets pointer
mega_barrier();
_bucketsAndMaybeMask.store((uintptr_t)newBuckets, memory_order_relaxed);
// ensure other threads see new buckets before new mask
mega_barrier();
_maybeMask.store(newMask, memory_order_relaxed);
_occupied = 0;
#elif __x86_64__ || i386
// ensure other threads see buckets contents before buckets pointer
_bucketsAndMaybeMask.store((uintptr_t)newBuckets, memory_order_release);
// ensure other threads see new buckets before new mask
_maybeMask.store(newMask, memory_order_release);
_occupied = 0;
#else
#error Don't know how to do setBucketsAndMask on this architecture.
#endif
}
unscramble
Set bucket_t * first address deposit_ bucketsAndMaybeMask. Save the mask of newCapacity - 1 to_ maybeMask. _ occupied is set to 0, because buckets has just been set, and there is no real cache method.
3.1.7 collect_free
// Empty the contents of the incoming memory address and recycle memory.
void cache_t::collect_free(bucket_t *data, mask_t capacity)
{
#if CONFIG_USE_CACHE_LOCK
cacheUpdateLock.assertLocked();
#else
runtimeLock.assertLocked();
#endif
if (PrintCaches) recordDeadCache(capacity);
_garbage_make_room ();
garbage_byte_size += cache_t::bytesForCapacity(capacity);
garbage_refs[garbage_count++] = data;
cache_t::collectNolock(false);
}
3.1.8 cache_hash
// Hash algorithm to calculate the insertion position of the method.
static inline mask_t cache_hash(SEL sel, mask_t mask)
{
uintptr_t value = (uintptr_t)sel;
#if CONFIG_USE_PREOPT_CACHES
value ^= value >> 7;
#endif
return (mask_t)(value & mask);
}
3.1.9 cache_next
// Hash algorithm is used to calculate the position of method insertion again after hash conflict.
#if CACHE_END_MARKER
static inline mask_t cache_next(mask_t i, mask_t mask) {
return (i+1) & mask;
}
#elif __arm64__
static inline mask_t cache_next(mask_t i, mask_t mask) {
return i ? i-1 : mask;
}
#else
#error unexpected configuration
#endif
2, bucket_t interpretation
1.bucket_t source code
struct bucket_t {
private:
// IMP-first is better for arm64e ptrauth and no worse for arm64.
// SEL-first is better for armv7* and i386 and x86_64.
#if __arm64__
explicit_atomic<uintptr_t> _imp; // imp address, in uintptr_t (unsigned long) format storage
explicit_atomic<SEL> _sel; // sel
#else
explicit_atomic<SEL> _sel;
explicit_atomic<uintptr_t> _imp;
#endif
// imp encoding, (uintptr_t)newImp ^ (uintptr_t)cls
// imp address to decimal ^ class address to decimal
// imp with uintptr_t (unsigned long) format is stored in the bucket_t medium
// Sign newImp, with &_imp, newSel, and cls as modifiers.
uintptr_t encodeImp(UNUSED_WITHOUT_PTRAUTH bucket_t *base, IMP newImp, UNUSED_WITHOUT_PTRAUTH SEL newSel, Class cls) const {
if (!newImp) return 0;
#if CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_PTRAUTH
return (uintptr_t)
ptrauth_auth_and_resign(newImp,
ptrauth_key_function_pointer, 0,
ptrauth_key_process_dependent_code,
modifierForSEL(base, newSel, cls));
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_ISA_XOR
// imp address to hexadecimal ^ class address to hexadecimal
return (uintptr_t)newImp ^ (uintptr_t)cls;
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_NONE
return (uintptr_t)newImp;
#else
#error Unknown method cache IMP encoding.
#endif
}
public:
// Return sel
inline SEL sel() const { return _sel.load(memory_order_relaxed); }
// imp decoding, (IMP)(imp ^ (uintptr_t)cls)
// Imp address hexadecimal ^ class address hexadecimal, and then converted to imp type
// Principle: C = a ^ B; a = c ^ b; -> b ^ a ^ b = a
inline IMP imp(UNUSED_WITHOUT_PTRAUTH bucket_t *base, Class cls) const {
uintptr_t imp = _imp.load(memory_order_relaxed);
if (!imp) return nil;
#if CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_PTRAUTH
SEL sel = _sel.load(memory_order_relaxed);
return (IMP)
ptrauth_auth_and_resign((const void *)imp,
ptrauth_key_process_dependent_code,
modifierForSEL(base, sel, cls),
ptrauth_key_function_pointer, 0);
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_ISA_XOR
// Imp address hexadecimal ^ class address hexadecimal, and then converted to imp type
return (IMP)(imp ^ (uintptr_t)cls);
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_NONE
return (IMP)imp;
#else
#error Unknown method cache IMP encoding.
#endif
}
// This is just a declaration. For implementation, please see the function analysis below
void set(bucket_t *base, SEL newSel, IMP newImp, Class cls);
···· ellipsis n Line code·····
}
2.bucket_t member variable
- _ SEL, method sel.
- _ IMP, the method implements the hexadecimal of the address. It needs the hexadecimal of the class address on ^ and then converts it to IMP type.
3.bucket_t function
3.1 sel
// Get bucket_ sel.
inline SEL sel() const {
// Return sel
return _sel.load(memory_order_relaxed);
}
3.2 encodeImp
code
// Sign newImp, with &_imp, newSel, and cls as modifiers.
uintptr_t encodeImp(UNUSED_WITHOUT_PTRAUTH bucket_t *base, IMP newImp, UNUSED_WITHOUT_PTRAUTH SEL newSel, Class cls) const {
if (!newImp) return 0;
#if CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_PTRAUTH
return (uintptr_t)
ptrauth_auth_and_resign(newImp,
ptrauth_key_function_pointer, 0,
ptrauth_key_process_dependent_code,
modifierForSEL(base, newSel, cls));
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_ISA_XOR
// imp address to hexadecimal ^ class address to hexadecimal
return (uintptr_t)newImp ^ (uintptr_t)cls;
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_NONE
return (uintptr_t)newImp;
#else
#error Unknown method cache IMP encoding.
#endif
}
unscramble
- Imp code, imp address decimal ^ upper class address decimal. Imp with uintptr_t (unsigned long) format is stored in the bucket_t medium.
- imp encoding, (uintptr_t)newImp ^ (uintptr_t)cls
- imp address to hexadecimal ^ class address to hexadecimal
- imp with uintptr_t (unsigned long) format is stored in the bucket_t medium
3.3 imp function analysis
code
inline IMP imp(UNUSED_WITHOUT_PTRAUTH bucket_t *base, Class cls) const {
uintptr_t imp = _imp.load(memory_order_relaxed);
if (!imp) return nil;
#if CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_PTRAUTH
SEL sel = _sel.load(memory_order_relaxed);
return (IMP)
ptrauth_auth_and_resign((const void *)imp,
ptrauth_key_process_dependent_code,
modifierForSEL(base, sel, cls),
ptrauth_key_function_pointer, 0);
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_ISA_XOR
// Imp address hexadecimal ^ class address hexadecimal, and then converted to imp type
return (IMP)(imp ^ (uintptr_t)cls);
#elif CACHE_IMP_ENCODING == CACHE_IMP_ENCODING_NONE
return (IMP)imp;
#else
#error Unknown method cache IMP encoding.
#endif
}
unscramble
- The imp decodes and returns the imp address in hexadecimal ^ the upper class address in hexadecimal, and then converts it to the imp type (which forms a symmetric encoding and decoding with the above encoding function).
- Encoding and decoding principle: a twice ^ B, or equal to a, i.e. C = a ^ B; a = c ^ b; -> b ^ a ^ b = a.
- The class here is salt in the algorithm. As for why class is used as salt, because these imp s belong to class, class is used as salt.
- imp decoding, (IMP)(imp ^ (uintptr_t)cls)
//IMP address hexadecimal ^ class address hexadecimal, and then converted to IMP type
//Principle: b ^ a ^ b = a
Breakpoint verification
- Run the breakpoint under the main function, and enter this method under the inline IMP imp(UNUSED_WITHOUT_PTRAUTH bucket_t *base, Class cls) const method
(lldb) p imp (uintptr_t) $0 = 48728 (lldb) p (IMP)(imp ^ (uintptr_t)cls) // decode (IMP) $1 = 0x0000000100003840 (KCObjcBuild`-[MHPerson sayHello]) (lldb) p (uintptr_t)cls // (uintptr_t) $2 = 4295001624 (lldb) p 48728 ^ 4295001624 (long) $3 = 4294981696 (lldb) p/x 4294981696 (long) $4 = 0x0000000100003840 (lldb) p (IMP) 0x0000000100003840 // verification (IMP) $5 = 0x0000000100003840 (KCObjcBuild`-[MHPerson sayHello]) (lldb) p 4294981696 ^ 4295001624 // Code verification (long) $6 = 48728
2.3.4 bucket_t::set
// For bucket_t sets sel, imp, and class.
void bucket_t::set(bucket_t *base, SEL newSel, IMP newImp, Class cls)
{
ASSERT(_sel.load(memory_order_relaxed) == 0 ||
_sel.load(memory_order_relaxed) == newSel);
// objc_msgSend uses sel and imp with no locks.
// It is safe for objc_msgSend to see new imp but NULL sel
// (It will get a cache miss but not dispatch to the wrong place.)
// It is unsafe for objc_msgSend to see old imp and new sel.
// Therefore we write new imp, wait a lot, then write new sel.
uintptr_t newIMP = (impEncoding == Encoded
? encodeImp(base, newImp, newSel, cls)
: (uintptr_t)newImp);
if (atomicity == Atomic) {
_imp.store(newIMP, memory_order_relaxed);
if (_sel.load(memory_order_relaxed) != newSel) {
#ifdef __arm__
mega_barrier();
_sel.store(newSel, memory_order_relaxed);
#elif __x86_64__ || __i386__
_sel.store(newSel, memory_order_release);
#else
#error Don't know how to do bucket_t::set on this architecture.
#endif
}
} else {
_imp.store(newIMP, memory_order_relaxed);
_sel.store(newSel, memory_order_relaxed);
}
}
3, lldb validate cache_t structure
1. Code breakpoints are as follows:

2. Steps
(lldb) p/x pclass
(Class) $1 = 0x0000000100008610 MHPerson
(lldb) p (cache_t *)(0x0000000100008610 + 0x10) // (type conversion) offset 16 bytes and get the cache_t pointer (isa8 bytes, superclass8 bytes)
(cache_t *) $2 = 0x0000000100008620
(lldb) p *$2 // cache output
(cache_t) $3 = {
_bucketsAndMaybeMask = {
std::__1::atomic<unsigned long> = {
Value = 4298515360
}
}
= {
= {
_maybeMask = {
std::__1::atomic<unsigned int> = {
Value = 0 // _ maybeMask - the cache capacity is 0. Because the method has not been called yet, the cache space has not been opened up
}
}
_flags = 32816
_occupied = 0 // _ occupied - number of method caches. The method has not been called yet
}
_originalPreoptCache = {
std::__1::atomic<preopt_cache_t *> = {
Value = 0x0000803000000000
}
}
}
}
(lldb)
(lldb) p [p sayHello] // lldb call method
2021-06-29 14:54:29.435481+0800 KCObjcBuild[58858:5603051] age - 19831
(lldb) p *$2
(cache_t) $4 = {
_bucketsAndMaybeMask = {
std::__1::atomic<unsigned long> = {
Value = 4302342320
}
}
= {
= {
_maybeMask = {
std::__1::atomic<unsigned int> = {
// _ maybeMask - the cache capacity is 7,
// x86_ The first development capacity of 64 architecture should be 4, and the value result should be 3
// Rerun direct walk sayh is 3
Value = 7
}
}
_flags = 32816
_occupied = 3 //_ The occupied- method caches the number, because the setter getter method is invoked in the method so that it is 3, if not called, it should be 1.
}
_originalPreoptCache = {
std::__1::atomic<preopt_cache_t *> = {
Value = 0x0003803000000007
}
}
}
}
// Memory translation mode value
// Take out the buckets in order_ t
(lldb) p $4.buckets()[0]
(bucket_t) $5 = {
_sel = {
std::__1::atomic<objc_selector *> = (null) {
Value = nil
}
}
_imp = {
std::__1::atomic<unsigned long> = {
Value = 0
}
}
}
(lldb) p $4.buckets()[1]
(bucket_t) $6 = {
_sel = {
std::__1::atomic<objc_selector *> = "" {
Value = ""
}
}
_imp = {
std::__1::atomic<unsigned long> = {
Value = 48720
}
}
}
(lldb) p $6.sel()
(SEL) $7 = "sayHello"
(lldb) p $6.imp(nil, pclass)
(IMP) $8 = 0x0000000100003840 (KCObjcBuild`-[MHPerson sayHello])
(lldb) p $4.buckets()[2]
(bucket_t) $11 = {
_sel = {
std::__1::atomic<objc_selector *> = "" {
Value = ""
}
}
_imp = {
std::__1::atomic<unsigned long> = {
Value = 48144
}
}
}
(lldb) p $11.sel()
(SEL) $12 = "age"
(lldb) p $11.imp(nil, pclass)
(IMP) $13 = 0x0000000100003a00 (KCObjcBuild`-[MHPerson age])
3 lldb debugging result analysis
- Call a method_ occupied is 1_ maybeMask is 7 (the first call of code execution is 4), and the cache mentioned in the above is parsed according to the allocateBuckets function_ END_ When marker is 1 (arm | x86 | 64 | i386 schema is 1), the end tag is stored
- After calling the setter getter method of age_ occupied is 3_ maybeMask is 7. In this way, with the above cached method, the number of cache methods reaches 3.
4, Flow chart