Pan Chuang AI sharing
Author shivani46
Compile Flin
Source | analyticsvidhya
introduce
Keras was originally developed as a convenient add-on to Theano. For a long time, keras first supported Tensorflow, and then became a full part of it. However, our article will not focus on the complex fate of this framework, but its functions.

install
Installing Keras is very simple because it is a normal python package:
pip install Keras
Now we can start analyzing it, but first, let's talk about the back end.
back-end
The back end is a major factor in increasing the popularity of keras. Keras supports the use of many other frameworks as back ends. If you want to use Theano as the backend, you have two options:
- Edit the keras.json configuration file located on the path $HOME/.keras/keras.json (or% USERPROFILE%.keraskeras.json in the case of Windows operating system). We need a backend field:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}
- The second method is to set the environment variable KERAS_BACKEND, as follows:
KERAS_BACKEND=theano python -c "from keras import backend"
Therefore, the Keras backend is expanding and will take over the world over time!
Practical examples
It seems that we can now take a [less] deep neural network as an example.
data
Training any machine learning model starts with data. Keras contains multiple training data sets, but they have been placed in a convenient form, and it is not allowed to show all the functions of keras.
Therefore, we will use a more primitive data set. It will be a data set of 20 newsgroups - 20000 news posts from Usenet group (this is the mail exchange system in the 1990s, similar to FIDO, which readers may be more familiar with), roughly evenly divided into 20 categories.
We will train our network to correctly distribute messages to these newsgroups.
from sklearn.datasets import fetch_20newsgroups newsgroups_train = fetch_20newsgroups(subset='train') newsgroups_test = fetch_20newsgroups(subset='test') Here is an example of the content of a document from the training sample: newsgroups_train ['data'] [0]
Pretreatment
Keras contains tools that facilitate preprocessing text, pictures, and time series, the most common data types. Today we work with text, so we need to decompose them into tags and convert them into matrix form.
tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(newsgroups_train["data"]) # now the tokenizer knows the dictionary for this corpus of texts x_train = tokenizer.texts_to_matrix(newsgroups_train["data"], mode='binary') x_test = tokenizer.texts_to_matrix(newsgroups_test["data"], mode='binary') As a result, we got binary matrices of the following sizes: x_train shape: (11314, 1000) x_test shape: (7532, 1000) We also need to convert class labels to matrix form for training using cross-entropy. To do this, we will translate the class number into the so-called one-hot vector: y_train = keras.utils.to_categorical(newsgroups_train["target"], num_classes) y_test = keras.utils.to_categorical(newsgroups_test["target"], num_classes) At the output, we also get binary matrices of the following sizes: y_train shape: (11314, 20) y_test shape: (7532, 20)
As we can see, the size of these matrices is partly consistent with the data matrix (in the first coordinate - the number of documents in the training and test samples) and partly inconsistent with the data matrix. At the second coordinate, we have the number of classes (20, as the name of the dataset implies).
That's it. Now we're going to teach our network to classify news!
Model
The model in Keras can be described in two main ways:
Sequential API
#The first one is a consistent description of the model, like this:
model = Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
or like this:
model = Sequential([
Dense(512, input_shape=(max_words,)),
Activation('relu'),
Dropout(0.5),
Dense(num_classes),
Activation('softmax')
])
Functional API
Some time ago, it was possible to create models using functional API s - the second way:
a = Input(shape=(max_words,))
b = Dense(512)(a)
b = Activation('relu')(b)
b = Dropout(0.5)(b)
b = Dense(num_classes)(b)
b = Activation('softmax')(b)
model = Model(inputs=a, outputs=b)
There is no specific difference between the methodologies, choose the preferred one.
This allows you to save models in a human-readable form, as well as instantiate models from such a description:
from keras.models import model_from_yaml
yaml_string = model.to_yaml()
model = model_from_yaml(yaml_string)
It should be noted that the model saved as text (by the way, it can also be saved as JSON) does not contain weights.
To save and load weights, use the function save accordingly_ Weight and load_weights.
Model rendering
Visualization cannot be ignored. Keras has built-in model visualization:
from keras.utils import plot_model plot_model(model, to_file='model.png', show_shapes=True)
This code will save the following image under the name model.png:
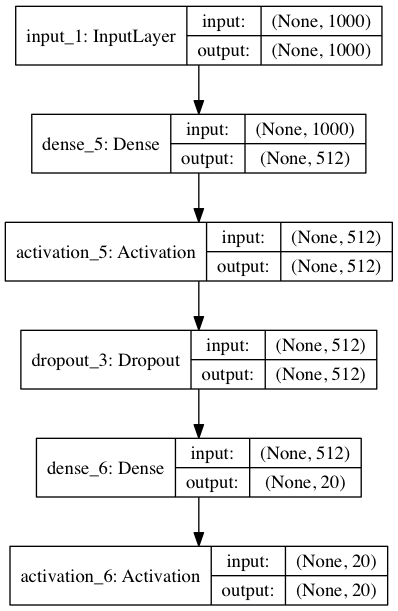
Here, we also show the input and output dimensions of the layer. The first of the size tuples is the batch size. Because it does not require any cost, batch processing can be arbitrary.
from IPython.display import SVG from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
Note that visualization requires the Graphviz package and the Python package pydot.
pip install pydot-ng
The Graphviz package in Ubuntu is installed like this (similar in other Linux distributions):
apt install graphviz
On macOS (using HomeBrew package system):
brew install graphviz
Preparation model
So we have formed our model. Now you need to be ready for work:
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
What do compiled function parameters mean?
loss - this is the error function. In our example, it is cross entropy. It is for this function that we prepare our label in the form of matrix;
Optimizer - the optimizer used may have ordinary random gradient descent, but Adam shows the best convergence on this problem;
metrics - an indicator that considers the quality of the model. In our example, it is accuracy, that is, the proportion of correct guesses.
Custom loss
Although Keras contains most popular error functions, your task may require something unique. In order to write your own loss function, you need to do one thing: just define a function that takes the vector of correct and predicted answers and outputs a number for each output.
For training, let's create our own function to calculate the cross entropy. To make it different, we'll introduce what's called clipping -- cutting off vector values from the top and bottom.
from keras import backend as K
epsilon = 1.0e-9
def custom_objective(y_true, y_pred):
'''Yet another cross-entropy'''
y_pred = K.clip(y_pred, eps, 1.0 - eps)
y_pred /= K.sum(y_pred, axis=-1, keepdims=True)
cce = categorical_crossentropy(y_pred, y_true)
return cce
Here y_true and Y_ The pre tensors are from Tensorflow, so the Tensorflow function is used to deal with them.
To use another loss function, it is sufficient to change the value of the loss function parameter by compiling the object passing our loss function (in Python, the function is also an object, although this is a completely different story):
model.compile(loss=custom_objective,
optimizer='adam',
metrics=['accuracy'])
Training and testing
Finally, it's time to train the model:
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1)
The fit method does exactly that. It takes a training sample as input and labels – x_train and y_train,batch_size, which limits the number of samples provided at one time, the number of epochs for training epochs (an epoch is the training sample that the model passes completely at one time), and the proportion of training samples submitted for verification - validation_split.
This method returns the error history of each training step.
Finally, test. This method evaluates test samples as inputs and their labels. This indicator is set for work preparation, so nothing else is required. (but we will also specify the batch size).
score = model.evaluate(x_test, y_test, batch_size=batch_size)
Callback
I need to say a few more words about Keras callback, an important feature. Many useful functions are realized through them.
For example, if you have been training the network for a long time, you need to know when to stop if the errors on the dataset stop decreasing. In English, the function described here is called "early stop".
from keras.callbacks import EarlyStopping
early_stopping=EarlyStopping(monitor='value_loss')
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=[early_stopping])
Run an experiment and check how quickly early stopping works in our example?
Tensor plate
In addition, as a callback, you can save the log in Tensorboard convenient 0 format (we talked about it in an article on Tensorflow, in short - this is a special utility for processing and visualizing information from Tensorflow logs).
from keras.callbacks import TensorBoard
tensorboard=TensorBoard(log_dir='./logs', write_graph=True)
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=0.1,
callbacks=[tensorboard])
After training (even during training!), you can start Tensorboard by specifying the absolute path of the directory containing logs:
tensorboard –logdir=/path/to/logs
For example, you can see the changes of target indicators in the validation set there:
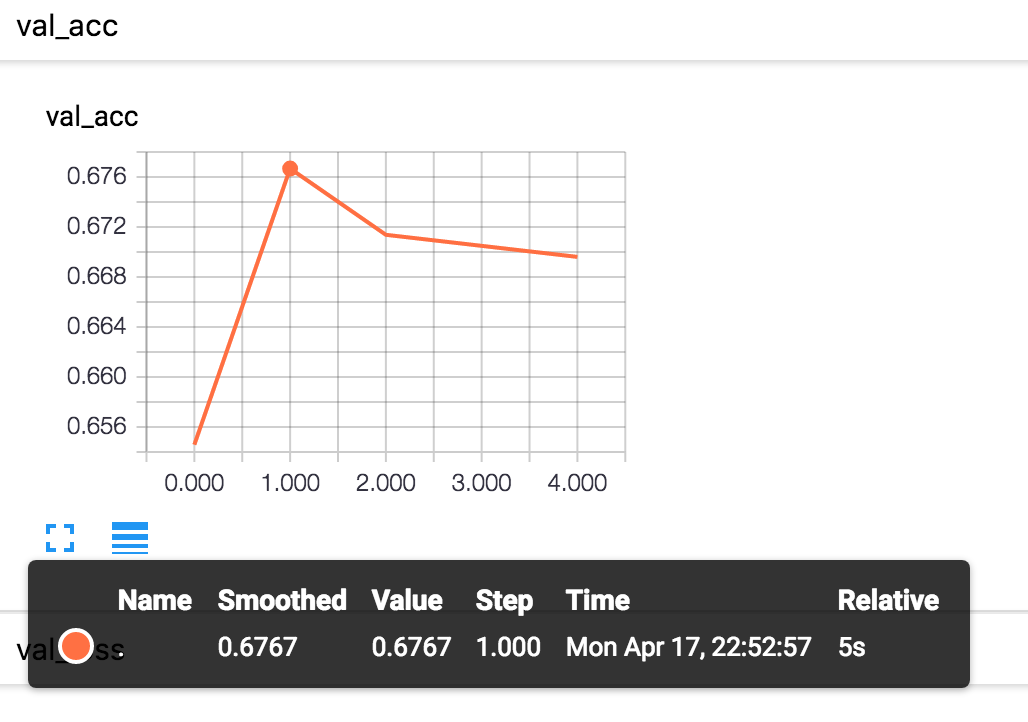
Advanced Chart
Now let's look at building a slightly more complex calculation diagram. A neural network can have multiple inputs and outputs, and the input data can be transformed through various mappings.
In order to reuse the parts of complex computing graph (especially for migration learning), it is meaningful to describe the model in a modular style, so that you can easily retrieve and save the parts of the model and apply them to new input data.
It is most convenient to describe the model by mixing two methods - the Functional API and Sequential API described earlier.
Let's take the Siamese Network model as an example to see this method. In practice, similar models are actively used to obtain vector representations with useful attributes. For example, the similarity model can be used to learn to map face photos into vectors, so that the vectors of similar faces are close to each other. In particular, image search applications such as FindFace take advantage of this.
You can see the description of the model in the figure:
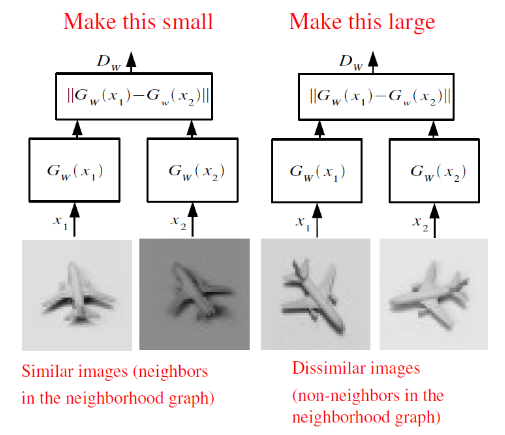
Here, the function G converts the input image into a vector, and then calculates the distance between the vectors of a pair of images. If the pictures are from the same class, the distance should be minimized, and if they are from different classes, the distance should be maximized.
After training such a neural network, we can represent any image as a vector G(x), and use this representation to find the nearest image or as the feature vector of other machine learning algorithms.
First, we define a function to map the input vector on Keras.
def create_base_network(input_dim):
seq = Sequential()
seq.add(Dense(128, input_shape=(input_dim,), activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(128, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(128, activation='relu'))
return seq
Note that we have described the model using the Sequential API, but we wrap its creation in a function. Now we can create such a model by calling this function and apply it to the input data using its Functional API:
base_network = create_base_network(input_dim) input_a = Input(shape=(input_dim,)) input_b = Input(shape=(input_dim,)) processed_a = base_network(input_a) processed_b = base_network(input_b)
Now the variable is processed_a and processing_ The bare vector representation is obtained by applying a previously defined network to the input data.
It is necessary to calculate the distance between them. To this end, Keras provides a wrapper function Lambda, which represents any expression as a layer. Don't forget that we process data in batches, so all tensors always have an additional dimension responsible for the size of the batch.
from keras import backend as K
def euclidean_distance(vects):
x, y = vects
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))
distance = Lambda(euclidean_distance)([processed_a, processed_b])
Great, we get the distance between the internal views, and now collect the input and distance into a model.
model = Model([input_a, input_b], distance)
Thanks to the modular structure, we can use base alone_ Network, which is particularly useful after training the model.
How can I do this? Let's look at the layers of our model:
>>> model.layers
[<keras.engine.topology.InputLayer object at 0x7f238fdacb38>, <keras.engine.topology.InputLayer object at 0x7f238fdc34a8>, <keras.models.Sequential object at 0x7f239127c3c8>, <keras.layers.core.Lambda object at 0x7f238fddc4a8>]
We see the third object in the type list models.Sequential. This is the model that maps the input image to the vector. To extract it and use it as a mature model (you can retrain, validate, and embed it in another diagram), you just pull it out of the layer list:
>>> embedding_model = model.layers[2] >>> embedding_model.layers
[<keras.layers.core.dense object at 0x7f23c4e557f0>,<keras.layers.core.dropout object at 0x7f238fe97908>,<keras.layers.core.dense object at 0x7f238fe44898>,<keras.layers.core.dropout object at 0x7f238fe449e8>,<keras.layers.core.dense object at 0x7f238fe01f60>]
For example, if the output dimension is already base_ For the Siamese network trained on the MNIST data of modeltwo, you can visualize the vector representation as follows:
Let's load the data and convert an image of size 28x28 into a plane vector.
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_test = x_test.reshape(10000, 784)
Let's use the previously extracted model to display the picture:
embeddings = embedding_model.predict(x_test)
Now there are two-dimensional vectors in the embedding, which can be described on a plane:
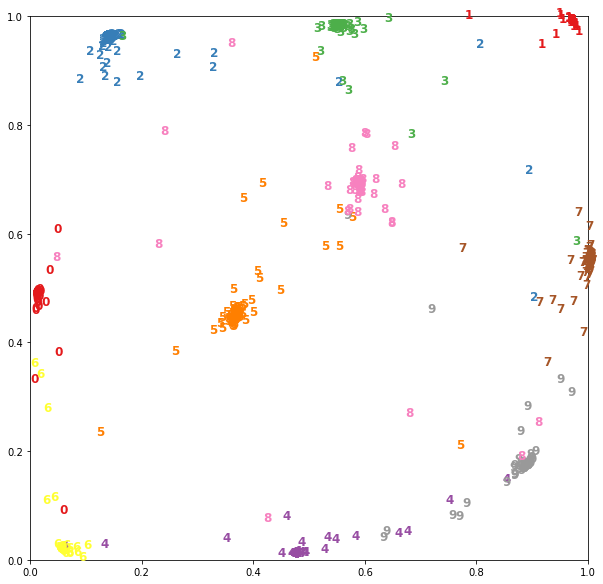
conclusion
That's it, we made the first Keras model!
The obvious advantages of Keras model include the simplicity of creating model, which can be transformed into high-speed prototyping. In general, this framework is becoming more and more popular:
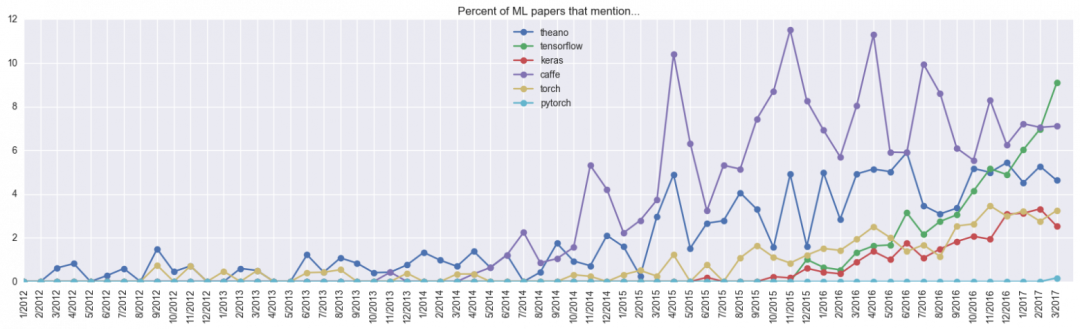
In general, Keras is recommended when you need to quickly build and test networks for specific tasks. However, if you need something complex, such as a non-standard layer or parallelizing code on multiple GPU s, it is better (sometimes inevitable) to use the underlying framework.

Love official account AI deep learning, dry cargo, deep learning, real battle, foreign latest translation, etc., we share the latest events in AI industry, and I hope you will like it. AI Click the card below to follow us~