What is FastDFS?
FastDFS is an open source, lightweight, distributed file system.He solves issues such as large data storage and load balancing.Especially suitable for online services with small and medium files (4KB < FileSize < 500MB), such as video, audio, picture websites, etc.
FastDFS is an open source and lightweight distributed file system. It is implemented by pure C and supports UNIX system classes such as Linux and FreeBSD. It is not a universal file system, but can only be accessed through a proprietary API. At present, it provides C, Java and PHP API s tailored for Internet applications to solve large file storage problems, and the pursuit of high performance and scalability FastDFS can be regarded as text-based.A key value pair storage system for a piece, called a distributed file storage service, is more appropriate.
Features of FastDFS?
- Files are not stored in blocks, and the uploaded files correspond to the files in the OS file system
- Save only one file that supports the same content, saving disk space (only one storage is set in a group)
- Download files support the HTTP protocol and can be used with built-in Web Servers or with other Web Servers
- Support online expansion
- Supports master-slave files
- Storage server can save file attributes (meta-data)V2.0 network communication uses libevent, supports military access, overall better performance
FastDFS architecture
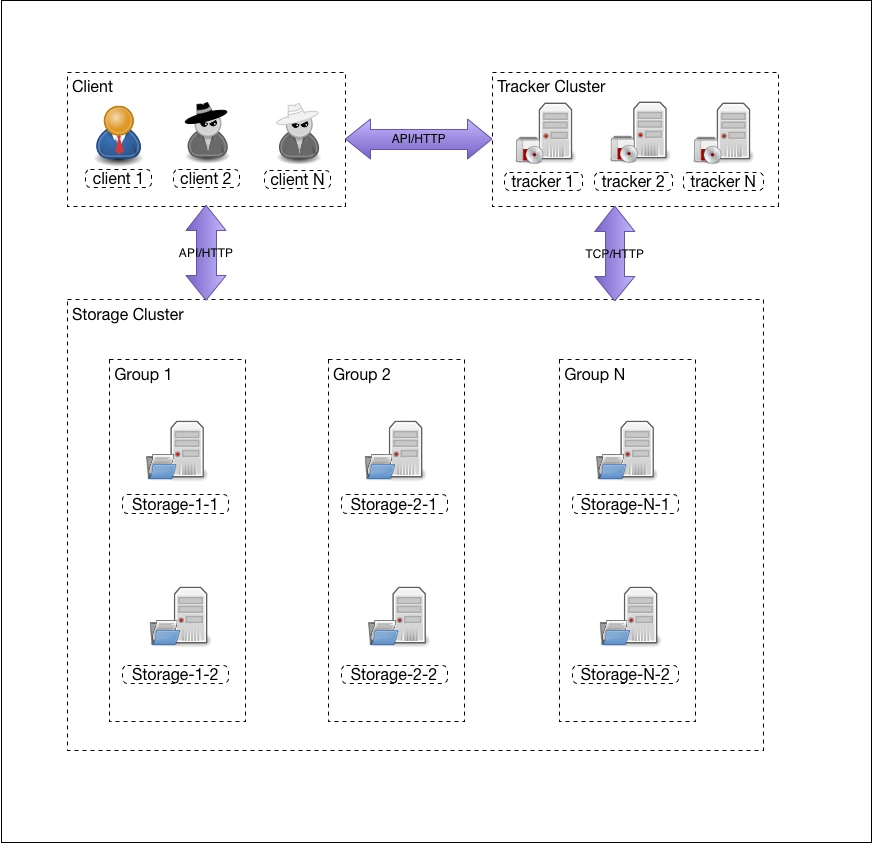
Tracker Server Tracking Server
Track the server, mainly for dispatching and load balancing.Recording in memory the status information of all storage groups and storage servers that exist in the cluster is the hub for interaction between the client and the data server.Compared to master in GlastFS, Master is more streamlined, does not record file index information, and takes up less memory.
Tracker is the coordinator of FastDFS and manages all storgae server s and groups. Each story connects to the tracker after it is started, informs the tarcker of its own grouping, etc., and maintains a periodic heartbeat. Tracker builds a mapping table for the group --> storage server list based on the story's heartbeat.
Tracker has very little meta-information to manage and stores it all in memory.Additionally, meta-information on tracker is generated from information reported by storage and does not need to persist any data. This makes tracker very easy to expand. By adding tracker machines directly, tracker clusters can be extended to serve tracker clusters, where each tracker is completely equivalent, and all trackers accept the heartbeat information from storage.Generate metadata information to provide read and write services.
Storage server storage server
A storage server, also known as a storage node or data server, has file and file properties (meta-data) stored on it.Storage server calls management files directly from the OS's file system.
Strage is organized as a group. A group contains multiple stroage machines. Data is backed up from each other. Storage space is based on the smallest storage volume of the group. Therefore, it is recommended that the storage capacity within the same group be the same to prevent waste of resources.
Organizational storage in groups facilitates application isolation, is responsible for balance, and defines the number of copies (the number of storages within a group is the number of copies of that group).For example, to isolate resources by writing data from different services into different groups, we can also write data from one service into multiple groups for load balancing.
The capacity of a group is limited by the storage capacity of a single machine, and when there is storag corruption within the group, data recovery can only depend on other storage machines in the group, making recovery time very long.
storage within a group depends on the local file system for each story, which can be configured with multiple data store directories.
When storage accepts a write file operation, it chooses one of the storage directories to store the files according to the configured rules.To avoid too many files in a single directory, a level 2 subdirectory, 256 directories at each level, totaling 65536 directories, is created in each data store directory when the store is first started. Newly written files are routed to one of these subdirectories by hash, and then the file data is stored directly as a local file in the directory.
client server client
Clients, as originators of business requests, use the TCP/IP protocol to interact with tracking servers or storage nodes through proprietary interfaces.
group
Groups, also known as volumes., the files on the servers in the same group are identical, the storage servers in the same group are equal, file upload, deletion and other operations can be done on any one storage server, how many groups can be on one storage server, and how many groups can be on each storage server for a device.
Metadata file related properties
Key Value Pair methods, such as width=1024,heigth=768
FastDFS DDL Operation
Upload mechanism
First the client requests the Tracker service to get the IP address and port of the storage server corresponding to the group group to be operated on. Then the client requests to upload the file according to the returned IP address and port number. The storage server receives the request and produces the file. The file content is written to disk and returned to the client file_id, path information, file name, etc. The client saves the phase.Close information upload completed.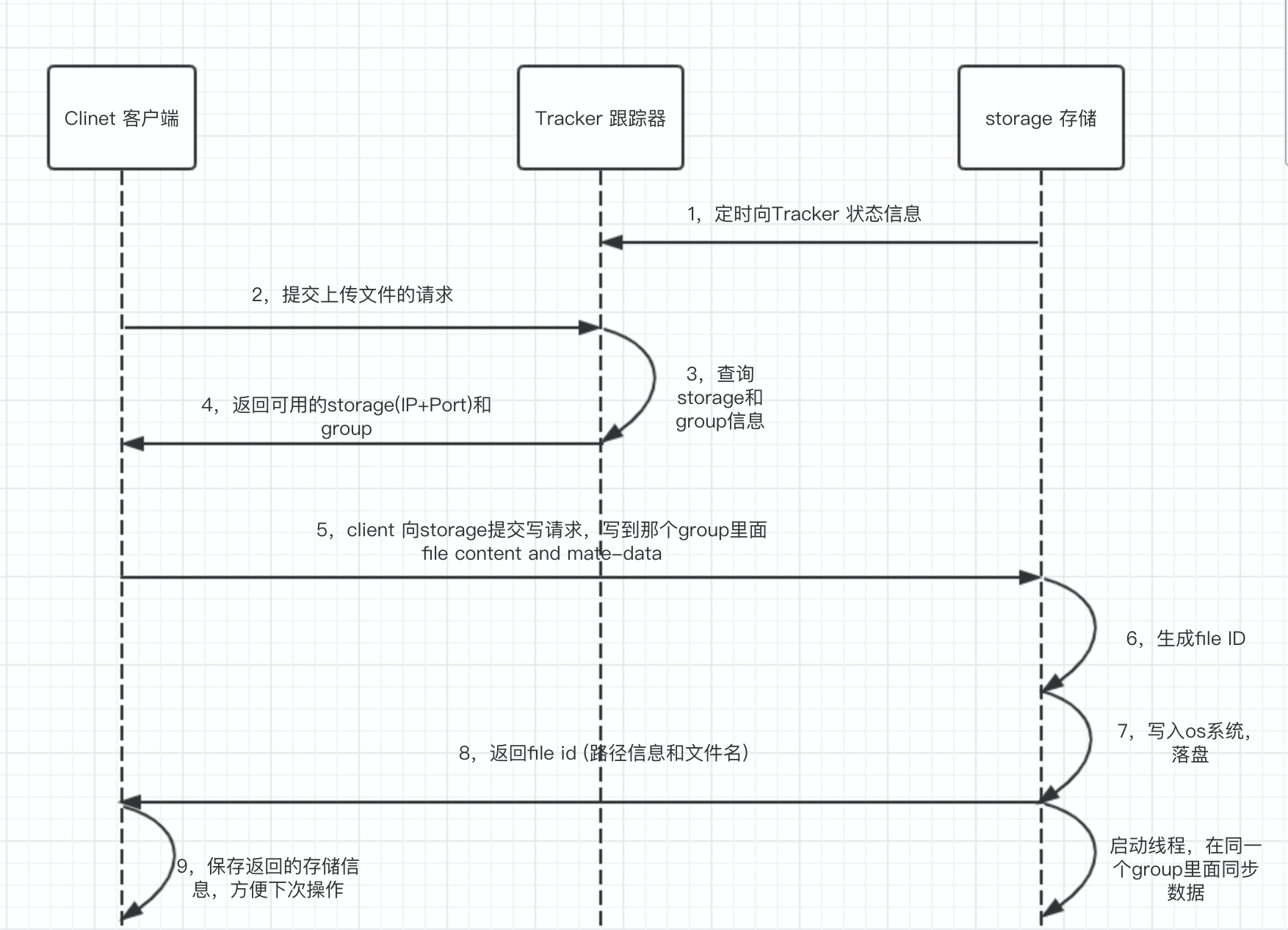
FastDFS memory storage mechanism:
1, select tracker server
When there is more than one tracker server in the cluster, since tracker servers are fully peer-to-peer, clients can choose any tracker when uploading files.When tracker receives a request for upload file, it is assigned a group to store the file, which supports the following rules for selecting a group:
- Round Robin, poll all group s
- Specified Group specifies a certain group
- Load Balance, group with more storage remaining takes precedence
2, select storage server
When a group is selected, tracker will select a storage server within the group to give to the client, supporting the following rules for selecting a storage
- Round Robin polls all storage s within the group
- First server ordered by ip sorted by IP
- First server ordred by priority is sorted by priority, which is configured on the store
3, select storage path
When the storage server is assigned, the client sends a write file request to the storage, and the storage will assign a data storage directory to the file, supporting the following rules:
- Round Robin Multiple Storage Directory Polling
- Priority of Maximum Remaining Storage Space
4, Generate FileID
When the directory is selected, Storage generates a FileID for the file, spliced by storage server ip +file creation time +file size +file crc32 +random number.The binary string is then base64 encoded and converted to a printable string.When two levels of directory are selected as the storage directory, storage assigns a fileid to the files. Each storage directory has two levels of 256*256 subdirectories. Storage hash es twice by file fileid, routes to one of the subdirectories, and stores the files in that subdirectory with fileid as the file name.
5, Generate file name
When a file is stored in a subdirectory, it is considered to be stored successfully. A file name is generated for the file, which is stitched together by group, storage directory, two-level subdirectory, fileid, file suffix name (specified by the client, mainly used to distinguish file types).
6, storage writes to disk
After each story writes a file, it also writes a binlog, which does not contain file data and values contain meta-information such as file names. This binlog is used for background synchronization. storage records the progress of synchronization to other storages within the Group so that it can continue synchronizing after restart, and the progress is recorded with a timestamp.
7. Report regularly to tracker
storage synchronization progress is reported on all trackers as part of the metadata, and trackers use this as a reference when selecting storages (see download mechanism below)
Storage generates a file name that contains the source storage ID/IP address and the file creation timestamp.Storage periodically reports file synchronization to tracker, including file timestamps to other storages in the same group.After the tracker receives the file synchronization report from Storage, it finds the minimum timestamp that each Storage in the group synchronizes to and stores it in memory as a storage property.
Download mechanism
The client requests the Tracker service with the file name information to get the IP and Port of the storage server, and then the client requests the download of the file with the returned IP address and port number. The storage server returns the file to the client after it has not received the request.
As with Upload file, clients can choose any tracker server when downloading files.Tracker sends a download request to a trakcer. It must bring the file name information with it. Tracker parses the group, size, creation time of the file from the file name, and then chooses a storage for the request to serve the read request.Since files within a group are synchronized asynchronously in the background, it is possible that they may appear while reading and have not yet been synchronized to some storage server s. To try to avoid accessing such storage, tracker chooses the readable storage within a group according to the following rules:
- 1, the source storage of the file upload (identified by inverting the storage ID/IP from the file name)
- 2, (Current Time - File Creation Timestamp) >File Synchronization Delay Threshold (e.g. one day)
- 3, the file creation timestamp < the timestamp to which the story was synchronized.(If the current storage synchronizes to a timestamp of 10 and the file creation timestamp of 8, the file has been synchronized)
- 4, File Creation Timestamp== the time stamp to which the storage is synchronized, and (Current Time - File Creation Timestamp) > Maximum time to synchronize a file (for example, 5 minutes).
The file synchronization delay threshold above and the maximum time to synchronize a file are two parameters that are configured in tracker.conf with storage_sync_file_max_delay and storage_sync_file_max_time, respectively.
FastDFS uses time stamps to solve file access problems caused by file synchronization delays.The time of servers within the cluster needs to be consistent, with a time error of no more than 1S, so NTP time servers are recommended to ensure consistent time.
FastDFS File Synchronization Mechanism
We've been talking about file synchronization above, but what's the real synchronization mechanism for files?
FastDFS synchronous files are copied asynchronously by binlog.stroage server records file upload, deletion and other operations using binlog (metadata of record file) files, and synchronizes files according to binlog.Here are a few examples of binlog file contents:
Path to binlog file $base_path/data/sync/binlog. *
1574850031 C M00/4C/2D/rBCo3V3eTe-AP6SRAABk7o3hUY4681.wav 1574850630 C M00/4C/2D/rBCo3V3eUEaAPMwRAABnbqEmTEs918.wav 1574851230 C M00/4C/2D/rBCo3V3eUp6ARGlEAABhzomSJJo079.wav 1574851230 C M00/4C/2D/rBCo3V3eUp6ABSZWAABoDiunCqc737.wav 1574851830 C M00/4C/2D/rBCo3V3eVPaAYKlIAABormd65Ds168.wav 1574851830 C M00/4C/2D/rBCo3V3eVPaAPs-CAABljrrCwyI452.wav 1574851830 C M00/4C/2D/rBCo3V3eVPaAdSeKAABrLhlwnkU907.wav 1574852429 C M00/4C/2D/rBCo3V3eV02Ab4yKAABmLjpCyas766.wav 1574852429 C M00/4C/2D/rBCo3V3eV02AASzFAABorpw6oJw030.wav 1574852429 C M00/4C/2D/rBCo3V3eV02AHSM7AAB0jpYtHQA019.wav
As you can see above, the binlog file has three columns, which are the timestamp, the type of operation, and the file ID (without the group name)
The file operation type uses a single letter encoding, where the source operation is capitalized and the synchronized operation is the corresponding shoe letter
C: upload files
D: Delete the file (delete)
A: Append the file (append)
M: Partial file update
U: set metadata
T: truncate the file
L: Create symbolic links (file de-duplication, save only one copy of the same content)
Storage servers within the same group are peer-to-peer, and file upload, deletion, and other operations can be performed on any one of the storage servers.File synchronization only occurs between storage servers within a group, using the push method, where the source server synchronizes to other storage servers in the group.For other storage servers in the same group, one storage server starts a thread for file synchronization.
File synchronization is incremental, recording the synchronized locations into a mark file.The mark file store path is $base_path/data/sync/.Example mark file contents:
binlog_index=3 binlog_offset=382 need_sync_old=1 sync_old_done=1 until_timestamp=1571976211 scan_row_count=2033425 sync_row_count=2033417
With binlog's asynchronous replication, there must be synchronization delays, such as mysql's master-slave data synchronization.
data recovery
Single disk data recovery
When a storage disk in our Group is damaged and we want to replace it, the data is automatically recovered when the disk is replaced.
How to determine if a single disk data recovery is required: detect the existence of two subdirectories 00/00 and FF/FF (default 256 for each level of subdirectories) in the $Store_path/data directory, and if one does not exist, automatically create the required subdirectories and start the automatic recovery of single disk data.
Single disk data recovery logic:
- 1. Obtain an available storage server from the tracker server as the source server;
- 2, pull the binlog of the storage path (store_path sequence corresponding) from the storage server and store it locally
- 3, more local binlog s copy files from the source storage server to the corresponding directory under $store_path/data/
- 4. The service can not be provided until the recovery of single disk data is completed.
Docker Install FastDFS
Pre-startup analysis
We're using the season/fastdfs:1.2 mirror here, so we'll take his dockerfile and see how it works
cat > Obtain_dockerfile.sh <<-'EOF'
#!/bin/bash
#DOC This is a docker file obtained from docker images to see how to start
export PATH=$PATH
if [ $# -eq 1 ];then
docker history --format {{.CreatedBy}} --no-trunc=true $1 |sed "s/\/bin\/sh\ -c\ \#(nop)\ //g"|sed "s/\/bin\/sh\ -c/RUN/g" | tac
else
echo "sh Obtain_dockerfile.sh $DOCKER_IMAGE"
fi
EOFThe dockerfile obtained by executing the script is as follows
# sh Obtain_dockerfile.sh season/fastdfs:1.2
ADD file:b908886c97e2b96665b7afc54ff53ebaef1c62896cf83a1199e59fceff1dafb5 in /
CMD ["/bin/bash"]
MAINTAINER season summer summer@season
RUN apt-get update && apt-get install -y gcc gcc-multilib libc6-dev-i386 make nano htop --no-install-recommends
RUN rm -rf /var/lib/apt/lists/*
COPY dir:9bb2976272b997f08c6435eb1f63b3801cec525f269b6a1de45ef02ba72dc919 in /FastDFS_v4.08
COPY dir:a74a73cd25b708ddc7dc6556b6f9608066876c344de608fb0f2e14dda04a48ba in /libevent-2.0.14
COPY dir:d5fde946a90870a8850d6e9b0b8b7be4e5e41c0b0f2d18cc19589e6caa56061e in /zlib-1.2.8
COPY dir:46967139f210ec8160e07010de80fea21e3950bf7cc680ccd10f3d01d458afce in /fastdfs-nginx-module
COPY dir:d39817fa72b763e78b1fe17483b6fcbebe769e79caf0a2411a9b35b5b104c5f7 in /nginx-1.8.0
COPY file:232f9aba296194eae5e61a56594f2d9b7fc4f03bfb7739e423335b36c7866653 in /entrypoint.sh
WORKDIR /libevent-2.0.14
RUN ./configure --prefix=/usr/local/libevent-2.0.14 && make && make install && make clean
RUN echo '/usr/local/libevent-2.0.14/include' >> /etc/ld.so.conf
RUN echo '/usr/local/libevent-2.0.14/lib' >> /etc/ld.so.conf
RUN ldconfig
WORKDIR /FastDFS_v4.08
RUN ./make.sh C_INCLUDE_PATH=/usr/local/libevent-2.0.14/include LIBRARY_PATH=/usr/local/libevent-2.0.14/lib && ./make.sh install && ./make.sh clean
WORKDIR /nginx-1.8.0
RUN ./configure --user=root --group=root --prefix=/etc/nginx --with-http_stub_status_module --with-zlib=/zlib-1.2.8 --without-http_rewrite_module --add-module=/fastdfs-nginx-module/src
RUN make
RUN make install
RUN make clean
RUN ln -sf /etc/nginx/sbin/nginx /sbin/nginx
RUN mkdir /fastdfs
RUN mkdir /fastdfs/tracker
RUN mkdir /fastdfs/store_path
RUN mkdir /fastdfs/client
RUN mkdir /fastdfs/storage
RUN mkdir /fdfs_conf
RUN cp /FastDFS_v4.08/conf/* /fdfs_conf
RUN cp /fastdfs-nginx-module/src/mod_fastdfs.conf /fdfs_conf
WORKDIR /
RUN chmod a+x /entrypoint.sh
ENTRYPOINT &{["/entrypoint.sh"]}You can see that our startup was done by executing this script. Now let's look at the following in this script:
#!/bin/bash
#set -e
TRACKER_BASE_PATH="/fastdfs/tracker"
TRACKER_LOG_FILE="$TRACKER_BASE_PATH/logs/trackerd.log"
STORAGE_BASE_PATH="/fastdfs/storage"
STORAGE_LOG_FILE="$STORAGE_BASE_PATH/logs/storaged.log"
TRACKER_CONF_FILE="/etc/fdfs/tracker.conf"
STORAGE_CONF_FILE="/etc/fdfs/storage.conf"
NGINX_ACCESS_LOG_FILE="/etc/nginx/logs/access.log"
NGINX_ERROR_LOG_FILE="/etc/nginx/logs/error.log"
MOD_FASTDFS_CONF_FILE="/etc/fdfs/mod_fastdfs.conf"
# remove log files
if [ -f "/fastdfs/tracker/logs/trackerd.log" ]; then
rm -rf "$TRACKER_LOG_FILE"
fi
if [ -f "/fastdfs/storage/logs/storaged.log" ]; then
rm -rf "$STORAGE_LOG_FILE"
fi
if [ -f "$NGINX_ACCESS_LOG_FILE" ]; then
rm -rf "$NGINX_ACCESS_LOG_FILE"
fi
if [ -f "$NGINX_ERROR_LOG_FILE" ]; then
rm -rf "$NGINX_ERROR_LOG_FILE"
fi
if [ "$1" = 'shell' ]; then
/bin/bash
fi
if [ "$1" = 'tracker' ]; then
echo "start fdfs_trackerd..."
if [ ! -d "/fastdfs/tracker/logs" ]; then
mkdir "/fastdfs/tracker/logs"
fi
n=0
array=()
#Loop Read Profile
while read line
do
array[$n]="${line}";
((n++));
done < /fdfs_conf/tracker.conf
rm "$TRACKER_CONF_FILE"
#${!Array[@]} is the subscript of the array
for i in "${!array[@]}"; do
#Determine if group name is empty
if [ ${STORE_GROUP} ]; then
#If it is not empty, determine if the field storage_group is included and replace the line
[[ "${array[$i]}" =~ "store_group=" ]] && array[$i]="store_group=${STORE_GROUP}"
fi
# Circular Append Configuration
echo "${array[$i]}" >> "$TRACKER_CONF_FILE"
done
touch "$TRACKER_LOG_FILE"
ln -sf /dev/stdout "$TRACKER_LOG_FILE"
fdfs_trackerd $TRACKER_CONF_FILE
sleep 3s #delay wait for pid file
# tail -F --pid=`cat /fastdfs/tracker/data/fdfs_trackerd.pid` /fastdfs/tracker/logs/trackerd.log
# wait `cat /fastdfs/tracker/data/fdfs_trackerd.pid`
tail -F --pid=`cat /fastdfs/tracker/data/fdfs_trackerd.pid` /dev/null
fi
if [ "$1" = 'storage' ]; then
echo "start fdfs_storgaed..."
n=0
array=()
while read line
do
array[$n]="${line}";
((n++));
done < /fdfs_conf/storage.conf
rm "$STORAGE_CONF_FILE"
for i in "${!array[@]}"; do
if [ ${GROUP_NAME} ]; then
[[ "${array[$i]}" =~ "group_name=" ]] && array[$i]="group_name=${GROUP_NAME}"
fi
if [ ${TRACKER_SERVER} ]; then
[[ "${array[$i]}" =~ "tracker_server=" ]] && array[$i]="tracker_server=${TRACKER_SERVER}"
fi
echo "${array[$i]}" >> "$STORAGE_CONF_FILE"
done
if [ ! -d "/fastdfs/storage/logs" ]; then
mkdir "/fastdfs/storage/logs"
fi
touch "$STORAGE_LOG_FILE"
ln -sf /dev/stdout "$STORAGE_LOG_FILE"
fdfs_storaged "$STORAGE_CONF_FILE"
sleep 3s #delay wait for pid file
# tail -F --pid=`cat /fastdfs/storage/data/fdfs_storaged.pid` /fastdfs/storage/logs/storaged.log
#wait -n `cat /fastdfs/storage/data/fdfs_storaged.pid`
tail -F --pid=`cat /fastdfs/storage/data/fdfs_storaged.pid` /dev/null
fi
if [ "$1" = 'nginx' ]; then
echo "starting nginx..."
# ln log files to stdout/stderr
touch "$NGINX_ACCESS_LOG_FILE"
ln -sf /dev/stdout "$NGINX_ACCESS_LOG_FILE"
touch "$NGINX_ERROR_LOG_FILE"
ln -sf /dev/stderr "$NGINX_ERROR_LOG_FILE"
# change mod_fastfdfs.conf
n=0
array=()
while read line
do
array[$n]="${line}";
((n++));
done < /fdfs_conf/mod_fastdfs.conf
if [ -f "$MOD_FASTDFS_CONF_FILE" ]; then
rm -rf "$MOD_FASTDFS_CONF_FILE"
fi
for i in "${!array[@]}"; do
if [ ${GROUP_NAME} ]; then
[[ "${array[$i]}" =~ "group_name=" ]] && array[$i]="group_name=${GROUP_NAME}"
fi
if [ ${TRACKER_SERVER} ]; then
[[ "${array[$i]}" =~ "tracker_server=" ]] && array[$i]="tracker_server=${TRACKER_SERVER}"
fi
if [ ${URL_HAVE_GROUP_NAME} ]; then
[[ "${array[$i]}" =~ "url_have_group_name=" ]] && array[$i]="url_have_group_name=${URL_HAVE_GROUP_NAME}"
fi
if [ ${STORAGE_SERVER_PORT} ]; then
[[ "${array[$i]}" =~ "storage_server_port=" ]] && array[$i]="storage_server_port=${STORAGE_SERVER_PORT}"
fi
echo "${array[$i]}" >> "$MOD_FASTDFS_CONF_FILE"
done
nginx -g "daemon off;"We simply analyzed the script and found that it judged whether to start trakcer, storage or nginx according to the parameters passed after startup. We also looked at what the script is like to start the test now.
Start tracker
docker run -ti -d --name trakcer \
-v /etc/localtime:/etc/localtime
-v /tracker_data:/fastdfs/tracker/data \
--net=host \
--restart=always \
season/fastdfs trackertracker listens on 2222122 after startup, and we can also change the port by passing environment variables
-e port=22222
Configurations in all profiles can be passed in as environment variables
#Environment variables and defaults that tracker can pass disabled=false bind_addr= port=22122 connect_timeout=30 network_timeout=60 base_path=/fastdfs/tracker max_connections=256 accept_threads=1 work_threads=4 store_lookup=2 store_group=group1 store_server=0 store_path=0 download_server=0 reserved_storage_space = 10% log_level=info run_by_group= run_by_user= allow_hosts=* sync_log_buff_interval = 10 check_active_interval = 120 thread_stack_size = 64KB storage_ip_changed_auto_adjust = true storage_sync_file_max_delay = 86400 storage_sync_file_max_time = 300 use_trunk_file = false slot_min_size = 256 slot_max_size = 16MB trunk_file_size = 64MB trunk_create_file_advance = false trunk_create_file_time_base = 02:00 trunk_create_file_interval = 86400 trunk_create_file_space_threshold = 20G trunk_init_check_occupying = false trunk_init_reload_from_binlog = false use_storage_id = false storage_ids_filename = storage_ids.conf id_type_in_filename = ip store_slave_file_use_link = false rotate_error_log = false error_log_rotate_time=00:00 rotate_error_log_size = 0 use_connection_pool = false connection_pool_max_idle_time = 3600 http.server_port=8080 http.check_alive_interval=30 http.check_alive_type=tcp http.check_alive_uri=/status.html
Start storage
docker run -di --name storage \
--restart=always \
-v /storage_data:/fastdfs/storage/data \
-v /store_path:/fastdfs/store_path \
--net=host \
-e TRACKER_SERVER=172.16.1.170:22122 season/fastdfs:1.2 storageTransitive environment variables
disabled=false group_name=group1 bind_addr= client_bind=true port=23000 connect_timeout=30 network_timeout=60 heart_beat_interval=30 stat_report_interval=60 base_path=/fastdfs/storage max_connections=256 buff_size = 256KB accept_threads=1 work_threads=4 disk_rw_separated = true disk_reader_threads = 1 disk_writer_threads = 1 sync_wait_msec=50 sync_interval=0 sync_start_time=00:00 sync_end_time=23:59 write_mark_file_freq=500 store_path_count=1 store_path0=/fastdfs/store_path subdir_count_per_path=256 tracker_server=172.16.1.170:22122 log_level=info run_by_group= run_by_user= allow_hosts=* file_distribute_path_mode=0 file_distribute_rotate_count=100 fsync_after_written_bytes=0 sync_log_buff_interval=10 sync_binlog_buff_interval=10 sync_stat_file_interval=300 thread_stack_size=512KB upload_priority=10 if_alias_prefix= check_file_duplicate=0 file_signature_method=hash key_namespace=FastDFS keep_alive=0 use_access_log = false rotate_access_log = false access_log_rotate_time=00:00 rotate_error_log = false error_log_rotate_time=00:00 rotate_access_log_size = 0 rotate_error_log_size = 0 file_sync_skip_invalid_record=false use_connection_pool = false connection_pool_max_idle_time = 3600 http.domain_name= http.server_port=8888
Test fastdfs
Enter the tracker container
docker exec -it tracker bash
grep 22122 /home/fdfs/client.conf
sed -i "s#`grep 22122 /home/fdfs/client.conf`#tracker_server=172.16.1.170:22122#g" /home/fdfs/client.conf
#Use the following command to view fastdfs cluster status
fdfs_monitor /etc/fdfs/client.conf
#Upload a file under test
fdfs_upload_file /etc/fdfs/client.conf /etc/hosts
group1/M00/00/00/rBABql33W5CAK7yFAAAAnrLoM8Y9254622
#Download Files
root@test01:/etc/fdfs# fdfs_download_file /etc/fdfs/client.conf group1/M00/00/00/rBABql33W5CAK7yFAAAAnrLoM8Y9254622
root@test01:/etc/fdfs# ls -l rBABql33W5CAK7yFAAAAnrLoM8Y9254622
-rw-r--r-- 1 root root 158 Dec 16 10:26 rBABql33W5CAK7yFAAAAnrLoM8Y9254622
root@test01:/etc/fdfs# cat rBABql33W5CAK7yFAAAAnrLoM8Y9254622
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#Delete Files
fdfs_delete_file /etc/fdfs/client.conf group1/M00/00/00/rBABql33W5CAK7yFAAAAnrLoM8Y9254622Start nginx for other programs to access and use
docker run -id --name fastdfs_nginx \
--restart=always \
-v /store_path:/fastdfs/store_path \
-p 8888:80 \
-e GROUP_NAME=group1 \
-e TRACKER_SERVER=172.16.1.170:22122 \
-e STORAGE_SERVER_PORT=23000 \
season/fastdfs:1.2 nginxBe careful:
```nginx.conf
server {
listen 8888;
server_name localhost;
location ~ /group([0-9])/M00 {
root //fastdfs/store_path/data;
ngx_fastdfs_module;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
Changeable Profile ```bash grep -Ev "^#|^$" mod_fastdfs.conf connect_timeout=2 network_timeout=30 base_path=/tmp load_fdfs_parameters_from_tracker=true storage_sync_file_max_delay = 86400 use_storage_id = false storage_ids_filename = storage_ids.conf tracker_server=tracker:22122 storage_server_port=23000 group_name=group1 url_have_group_name=true store_path_count=1 #storage_path0 needs to be the same as storage store_path0=/fastdfs/store_path log_level=info log_filename= response_mode=proxy if_alias_prefix= flv_support = true flv_extension = flv group_count = 0
Cluster building
We just need to start storage and nginx on another machine and then do a load balancing for all