Characteristic engineering concept:
Feature engineering transforms raw data into more representative data prediction model The process of features of potential problems can be realized by selecting the most relevant features, extracting features and creating features. Among them, feature creation is often realized by dimension reduction algorithm.
Purpose of Feature Engineering:
Reduce the calculation cost and increase the upper limit of the model
Feature selection feature_selection
Feature extraction, feature creation and feature selection

The first step of Feature Engineering: understanding the business
Four feature selection methods: filtering method, embedding method, packaging method and dimension reduction algorithm
1, Filter method
Filtering methods are usually used as preprocessing steps, and feature selection is completely independent of any machine learning algorithm. It selects features according to the scores in various statistical tests and various indicators of correlation.

1.1 variance filtering
1.1.1 VarianceThreshold
This is to filter the class of features through the variance of the feature itself. For example, if the variance of a feature itself is very small, it means that the samples have basically no difference in this feature. Maybe most of the values in the feature are the same, or even the values of the whole feature are the same, then this feature has no effect on sample differentiation.
No matter what the next feature engineering needs to do, the feature with variance of 0 should be eliminated first.
VarianceThreshold has an important parameter threshold, which indicates the threshold of variance and discards all features with variance less than threshold. If it is not filled in, it defaults to 0, that is, delete all features with the same record.
#View variance x.var()
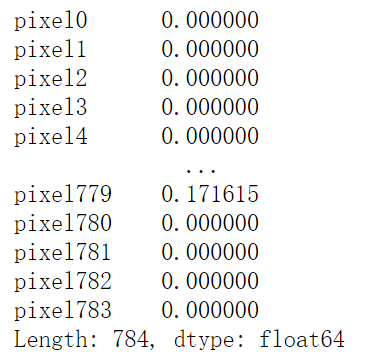
Filter features with zero variance
from sklearn.feature_selection import VarianceThreshold selector=VarianceThreshold() X_var0=selector.fit_transform(X) X_var0.shape
#Output
>(42000, 708)
It can be seen that we have deleted the feature with variance of 0, but there are still more than 708 features left. It is obvious that further feature selection is needed. However, if we know how many features we need, variance can also help us make feature selection in one step. For example, if we want to leave half of the features, we can set a variance threshold to halve the total number of features. As long as we find the median of the feature variance and enter this median as the value of the parameter threshold:
Filter features with median variance
from sklearn.feature_selection import VarianceThreshold import numpy as np X_fsvar=VarianceThreshold(np.median(X.var().value)).fit_transform(X) x_fsvar
#Output
>(42000, 392)
When the feature is a binary classification, the value of the feature is Bernoulli random variable, and the variance of these variables can be calculated as:
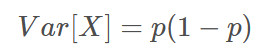
Where X is the feature matrix and p is the probability of a class of binary classification features in this feature.
#If the feature is a Bernoulli random variable, assume p=0.8, that is, delete the feature when one of the two classification features accounts for more than 80% x_bvar = VarianceThreshold(.8*(1-.8)).fit_transform(x) x_bvar.shape >(42000, 685)
1.1.2 influence of variance filtering on the model
The influence of variance filtering on the model is observed by comparing the effect and running time of KNN and random forest before and after variance filtering respectively
KNN is a classification algorithm in K-nearest neighbor algorithm. Its principle is very simple. It uses the distance between each sample and other sample points to judge the similarity of each sample point, and then classifies the samples. KNN must traverse each feature and each sample, so the more features, the slower the calculation of KNN.
1. Import module and prepare data
#Comparison of KNN vs random forest under different variance filtering effects from sklearn.ensemble import RandomForestClassifier as RFC #Random forest classification model from sklearn.neighbors import KNeighborsClassifier as KNN #KNN from sklearn.model_selection import cross_val_score #Cross validation import numpy as np #The same purpose as the initial data preparation X = data.iloc[:,1:] y = data.iloc[:,0] #Only half of the features are left. Find the median of the feature variance, and then enter this median as the value of the parameter threshold X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)
2. KNN variance before filtering
#======[TIME WARNING: 35mins +]======# cross_val_score(KNN(),X,y,cv=5).mean() #For magic commands in python, you can directly use%% timeit to calculate the time required to run the code in this cell #In order to calculate the time required, the code in the cell needs to be run many times (usually 7 times) and then averaged, #Therefore, running%% timeit will take much longer than running the code in the cell alone #======[TIME WARNING: 4 hours]======# %%timeit cross_val_score(KNN(),X,y,cv=5).mean()
#Output

3. After KNN variance filtering
#======[TIME WARNING: 20 mins+]======# cross_val_score(KNN(),X_fsvar,y,cv=5).mean() #======[TIME WARNING: 2 hours]======# %%timeit cross_val_score(KNN(),X_fsvar,y,cv=5).mean()
#Output
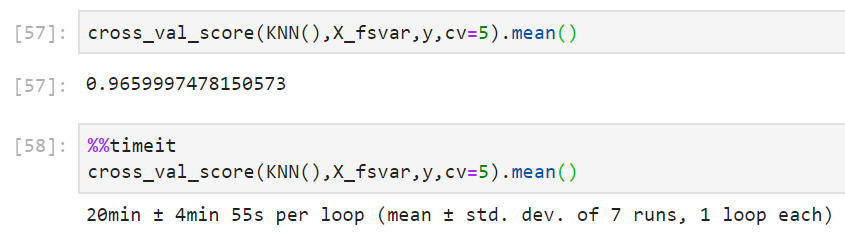
It can be seen that for KNN, the effect of filtering is very obvious: the accuracy is slightly improved, but the average running time is reduced by 10 minutes, and the efficiency of the algorithm after feature selection is increased by 1 / 3.
4. Random forest variance before filtering
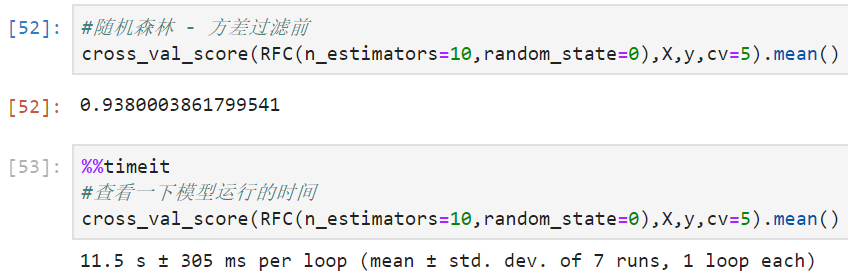
cross_val_score(RFC(n_estimators=10,random_state=0),X,y,cv=5).mean()
#Output
5. After random forest variance filtering
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsvar,y,cv=5).mean()
#Output
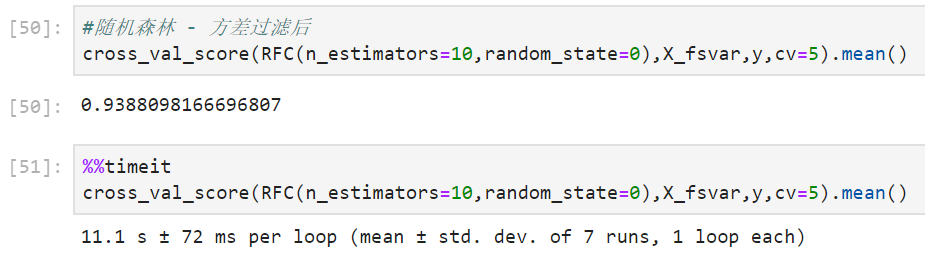
First of all, it can be observed that the accuracy of random forest is slightly lower than that of KNN, but the running time is less than 1% of KNN, which only takes more than ten seconds. Secondly, after variance filtering, the accuracy of random forest also increased slightly, but the running time was almost unchanged, still 11 seconds.
1.1.3 why do random forests run so fast? Why does variance filtering have little effect on random forest?
>Nearest neighbor algorithm KNN, single decision tree, support vector machine, SVM, neural network and regression algorithm all need to traverse features or raise dimensions for operation, so they have a large amount of operation and take a long time. Therefore, feature selection such as variance filtering is particularly important for them.
>For algorithms that do not need to traverse features, such as random forest, it randomly selects features for branching, and the operation itself is very fast, so the effect of feature selection is mediocre for it.
No matter how the filtering method reduces the number of features, the random forest will only select a fixed number of features to model; The nearest neighbor algorithm is different. The fewer features, the fewer dimensions of distance calculation. The model will obviously become lightweight with the reduction of features.
- The main object of filtering method is: algorithms that need to traverse features or upgrade dimensions
- The main purpose of filtering method is to help the algorithms reduce the computational cost on the premise of maintaining the performance of the algorithm.
Filtering method is not effective for random forest, but it is effective for tree model?
In terms of algorithm principle, the traditional decision tree needs to traverse all features and branch after calculating the impure, while the random forest randomly selects features for calculation and branching. Therefore, the operation of random forest is faster, and the filtering method is useless for random forest, but useful for decision tree
In sklearn, both the decision tree and the random forest are randomly selected for branching, but the number of features randomly extracted by the decision tree in the modeling process far exceeds the number of features randomly extracted by each tree in the random forest (for example, for this 780 dimensional data, each tree in the random forest will only extract 10-20 features, while the decision tree may extract 300-400 features), Therefore, the filtering method is useless for random forest, but it is useful for decision tree
Therefore, in sklearn, each tree in random forest is much simpler than a single decision tree, and the calculation of random forest under high-dimensional data is much faster than that of decision tree.
For the affected algorithms, the impact of variance filtering can be summarized as follows:
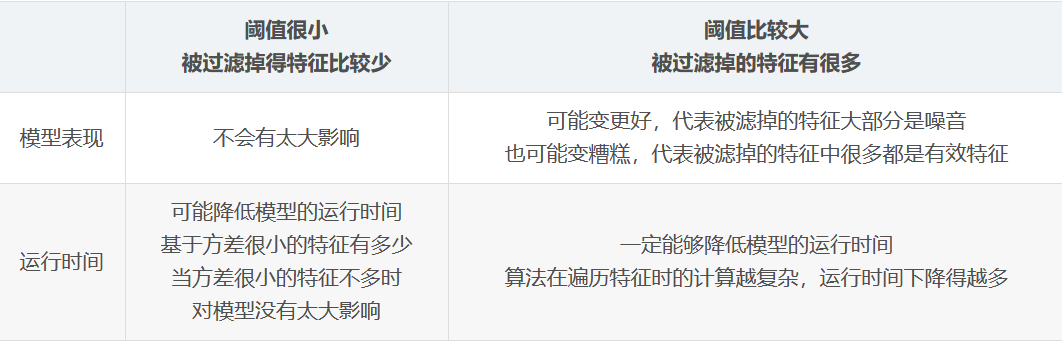
- If the accuracy of the model increases after filtering out the features using variance, it indicates that most of the filtered features are noise in the current random mode (random_state = 0).
- If the effect of the model becomes worse after filtering, and many of the filtered features have effective features, we will give up filtering and use other means for feature selection
The random forest can also be adjusted n_estimators parameters to improve the accuracy of the model, random forest is a very powerful model
1.1.4 select the super parameter threshold
How do we know whether the noise filtered by variance is an effective feature? Will the filtered model get better or worse?
Each data set is different, so you can only try it yourself.
You can draw a learning curve to find the best point of the model. But in reality, we often don't do this, because it will take a lot of time.
Usually, we only use variance filtering with a threshold of 0 or a small threshold to eliminate some features that are obviously unavailable, and then we will choose a better feature selection method to continue to reduce the number of features