Cut the crap and get straight to the point.
I believe everyone knows XXL-JOB very well, so this article does not introduce the source code too much. It focuses on several knowledge points thought of in the process of looking at the source code, which are not necessarily correct. Please criticize and correct.
XXL-JOB introduction
- XXL-JOB is a lightweight distributed task scheduling platform. Its core design goal is rapid development, simple learning, lightweight and easy expansion. Now the source code is open and connected to the online product lines of many companies, which can be used out of the box.
- XXL-JOB is divided into Dispatching Center, actuator and data center. The dispatching center is responsible for task management and scheduling, actuator management, log management, etc., and the actuator is responsible for task execution and execution result callback.
Task scheduling - Implementation of "class time wheel"
Time wheel
The time wheel comes from HashedWheelTimer in Netty. It is a ring structure, which can be compared with a clock. There are many buckets on the clock face. Each bucket can store multiple tasks. A List is used to save all tasks due at that time. At the same time, a pointer rotates one grid by one with the passage of time, and executes all tasks due on the corresponding bucket. The task determines which bucket to put by taking the module. Similar to the principle of HashMap, newTask corresponds to put and uses List to solve Hash conflicts.
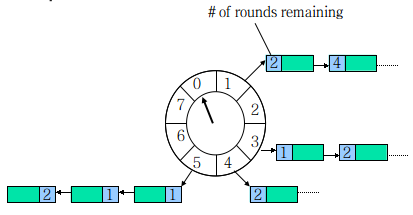
Taking the above figure as an example, assuming that a bucket is 1 second, the time period represented by one round of pointer rotation is 8 s. assuming that the current pointer points to 0, it is necessary to schedule a task to be executed after 3 s. obviously, it should be added to the square of (0 + 3 = 3), and the pointer can be executed after 3 s; If the task is to be executed after 10s, it should be executed after the pointer has gone through a round of zero 2 spaces. Therefore, it should be put into 2, and the round(1) should be saved into the task at the same time. When checking expired tasks, only those with round 0 are executed, and the round of other tasks on the bucket is reduced by 1.
Of course, there is also the implementation of optimized "layered time wheel", please refer to https://cnkirito.moe/timer/ .
"Time wheel" in XXL-JOB
- The scheduling method in XXL-JOB has changed from Quartz to self-developed scheduling, much like time wheel. It can be understood that there are 60 buckets and each bucket is 1 second, but there is no concept of round.
- See the figure below for details.
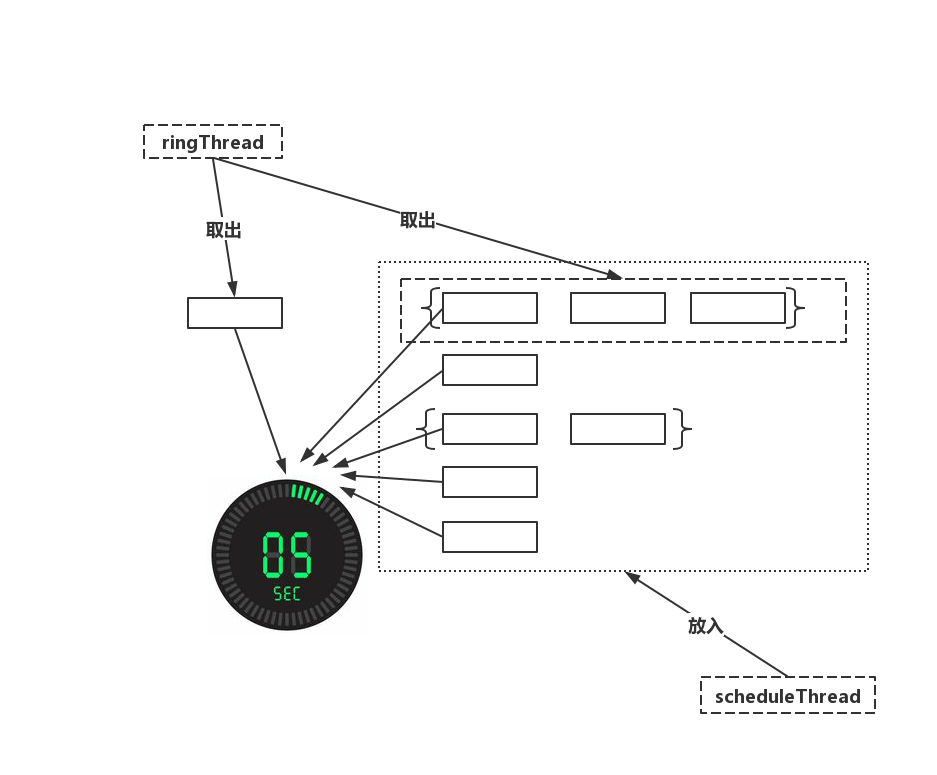
- In XXL-JOB, there are two threads responsible for task scheduling, namely ringThread and scheduleThread. Their functions are as follows.
1. scheduleThread: read the task information, pre read the tasks to be triggered in the next 5s, and put them into the time wheel. 2. ringThread: fetch and execute the tasks in the current bucket and the previous bucket.
- Let's see why it is a "class time wheel" in combination with the source code. Notes are attached to the key code. Please pay attention to it.
// Ring structure
private volatile static Map<Integer, List<Integer>> ringData = new ConcurrentHashMap<>();
// Next task start time (in seconds)% 60
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// Put the task into the time wheel
private void pushTimeRing(int ringSecond, int jobId){
// push async ring
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList<Integer>();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
}
Copy code// A task that takes two timescales at the same time
List<Integer> ringItemData = new ArrayList<>();
int nowSecond = Calendar.getInstance().get(Calendar.SECOND);
// Avoid taking too long to process, cross the scale and check one scale forward;
for (int i = 0; i < 2; i++) {
List<Integer> tmpData = ringData.remove( (nowSecond+60-i)%60 );
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
// function
for (int jobId: ringItemData) {
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null);
}
Copy codeHash algorithm in consistent hash routing
- As we all know, when XXL-JOB executes a task, the specific executor on which the task runs is determined according to the routing policy. One of the policies is the consistency Hash policy (the source code is in ExecutorRouteConsistentHash.java). It is natural to think of the consistency Hash algorithm.
- Consistency Hash algorithm is to solve the problem of load balancing in distributed systems. When using Hash algorithm, a fixed part of requests can fall on the same server, so that each server can process a fixed part of requests (and maintain the information of these requests) to play the role of load balancing.
- The ordinary remainder hash (hash (such as user id)% number of server machines) algorithm has poor scalability. When adding or offline server machines, the mapping relationship between user id and server will fail a lot. Consistency hash is improved by hash ring.
- Consistency hash algorithm in practice, when there are few server nodes, there will be the problem of consistency hash skew mentioned in the previous section. One solution is to add more machines, but adding machines has cost, so add virtual nodes.
- For the specific principle, please refer to https://www.jianshu.com/p/e968c081f563 .
- The following figure shows a Hash ring with virtual nodes, where ip1-1 is the virtual node of IP1, ip2-1 is the virtual node of IP2, and ip3-1 is the virtual node of IP3.
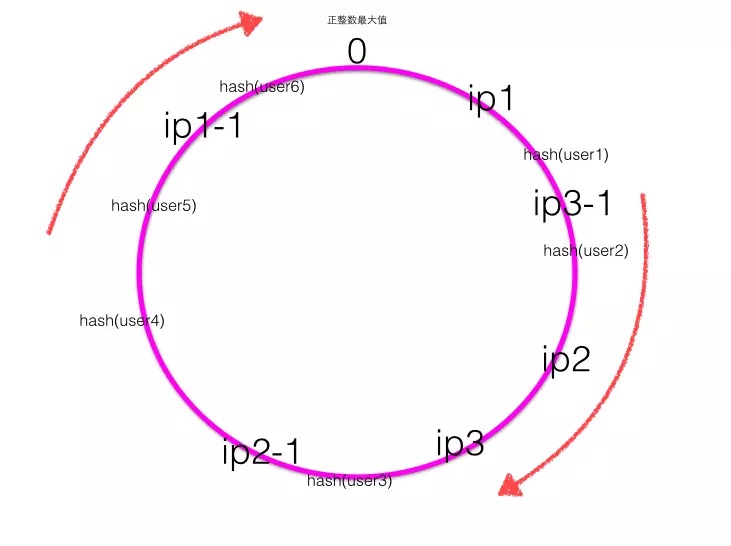
It can be seen that the key of consistent Hash algorithm is Hash algorithm, which ensures the uniformity of virtual nodes and Hash results, and uniformity can be understood as reducing Hash conflict. Please refer to the knowledge points of Hash conflict Look at [Hash] from HashMap and Redis dictionary....
- The Hash function of consistency Hash in XXL-JOB is as follows.
// jobId converted to md5 // The reason why hashCode() is not used directly is to expand the hash value range and reduce conflicts byte[] digest = md5.digest(); // 32-bit hashCode long hashCode = ((long) (digest[3] & 0xFF) << 24) | ((long) (digest[2] & 0xFF) << 16) | ((long) (digest[1] & 0xFF) << 8) | (digest[0] & 0xFF); long truncateHashCode = hashCode & 0xffffffffL; Copy code
- Seeing the Hash function in the figure above reminds me of the Hash function of HashMap
f(key) = hash(key) & (table.length - 1) // The reason for using > > > 16 is that both the high and low bits of hashCode() have a certain influence on f(key), making the distribution more uniform and reducing the probability of hash conflict. hash(key) = (h = key.hashCode()) ^ (h >>> 16) Copy code
- Similarly, the high and low bits of md5 encoding of jobId have an impact on the Hash result, reducing the probability of Hash conflict.
Implementation of sharding task - maintaining thread context
- XXL-JOB's slicing task realizes the distributed execution of tasks, which is actually the focus of the author's research. Many scheduled tasks in daily development are executed on a single machine. It is best to have a distributed solution for subsequent tasks with a large amount of data.
- For the routing strategy of fragment tasks, the author of the source code proposed the concept of fragment broadcasting. At the beginning, he was still a little confused. After reading the source code, it became clear gradually.
- Those who have seen the source code have also encountered such an episode. Why hasn't the routing strategy been implemented? As shown in the figure below.
public enum ExecutorRouteStrategyEnum {
FIRST(I18nUtil.getString("jobconf_route_first"), new ExecutorRouteFirst()),
LAST(I18nUtil.getString("jobconf_route_last"), new ExecutorRouteLast()),
ROUND(I18nUtil.getString("jobconf_route_round"), new ExecutorRouteRound()),
RANDOM(I18nUtil.getString("jobconf_route_random"), new ExecutorRouteRandom()),
CONSISTENT_HASH(I18nUtil.getString("jobconf_route_consistenthash"), new ExecutorRouteConsistentHash()),
LEAST_FREQUENTLY_USED(I18nUtil.getString("jobconf_route_lfu"), new ExecutorRouteLFU()),
LEAST_RECENTLY_USED(I18nUtil.getString("jobconf_route_lru"), new ExecutorRouteLRU()),
FAILOVER(I18nUtil.getString("jobconf_route_failover"), new ExecutorRouteFailover()),
BUSYOVER(I18nUtil.getString("jobconf_route_busyover"), new ExecutorRouteBusyover()),
// What about the agreed implementation??? It turned out to be null
SHARDING_BROADCAST(I18nUtil.getString("jobconf_route_shard"), null);
Copy code- After further investigation, we have reached a conclusion. After I talk slowly, first, what are the execution parameters of the piecemeal task passed? Look at xxljobtrigger A piece of code in the trigger function.
...
// If it is piecemeal routing, this logic is used
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST == ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList() != null && !group.getRegistryList().isEmpty()
&& shardingParam == null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
// The last two parameters, i, are the index and group of the current machine in the actuator cluster getRegistryList(). Size () is the total number of actuators
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
}
...
Copy code- The parameters are passed to the actuator through self-developed RPC, which is specifically responsible for the jobthread of task execution In run, you see the following code.
// ShardingUtil is included in the parameters of fragment broadcasting than set ShardingUtil.setShardingVo(new ShardingUtil.ShardingVO(triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal())); ... // Pass execution parameters to jobHandler for execution handler.execute(triggerParamTmp.getExecutorParams()) Copy code
- Then look at ShardingUtil and discover the secret. Please look at the code.
public class ShardingUtil {
// Thread context
private static InheritableThreadLocal<ShardingVO> contextHolder = new InheritableThreadLocal<ShardingVO>();
// Slicing parameter object
public static class ShardingVO {
private int index; // sharding index
private int total; // sharding total
// Times omit get/set
}
// Parameter object injection context
public static void setShardingVo(ShardingVO shardingVo){
contextHolder.set(shardingVo);
}
// Fetch parameter object from context
public static ShardingVO getShardingVo(){
return contextHolder.get();
}
}
Copy code- Obviously, the ShardingJobHandler responsible for the sharding task takes out the sharding parameters in the thread context. Here is also a code~
@JobHandler(value="shardingJobHandler")
@Service
public class ShardingJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
// Slice parameters
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("Slice parameter: current slice serial number = {}, Total number of slices = {}", shardingVO.getIndex(), shardingVO.getTotal());
// Business logic
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log("The first {} slice, Hit fragmentation start processing", i);
} else {
XxlJobLogger.log("The first {} slice, ignore", i);
}
}
return SUCCESS;
}
}
Copy code- Therefore, the distributed implementation is based on the partition parameters index and total. In short, it gives the identification of the current actuator. According to this identification, the task data or logic can be distinguished to realize distributed operation.
- Aside: why not execute directly by injecting partition parameters externally?
1. It may be that only fragment tasks use these two parameters. 2. IJobHandler only has String type parameters
Thinking after reading the source code
- 1. After looking at the source code this time, the design goal of XXL-JOB is indeed in line with the requirements of rapid development, simple learning, lightweight and easy expansion.
- 2. As for the self-developed RPC, there is no specific consideration, and the company's RPC framework should be considered for specific access.
- 3. The deficiency of Quartz scheduling given by the author needs to be further understood by the author.
- 4. The compatibility of many abnormal conditions such as downtime, failure and timeout in the framework is worth learning.
- 5. Rolling logs and log system implementation need to be further understood.