Reptile experience sharing
The teacher's requirements are as follows
1. Find a web page
News link: https://sports.sina.com.cn
sina sports
sina sports
sina sports
Forever god!!!!!
Why did you choose a certain wave web page? Of course, it is the result of many attempts, which made you climb many web pages, but many of them either have problems or Chinese garbled code. They are so angry that only this certain wave web page is very nice!!!!
2. Read the seed page
It should also be interpreted as reading its source code. I right-click according to the teacher and choose to view the web page source code, but the Mac operation is not like this!
What do you want - the following is from Baidu Encyclopedia
1. First open safari browser, click the menu bar above, and select "preferences".
2. Then in the pop-up window, select the "advanced" tab and check "display development menu in menu bar".
3. Return to the page where you want to view the source code, click the development options menu at the top, click display page source file, display page resources and display error console.
4. Back to the web page, you can see the source code of the current web page displayed below.
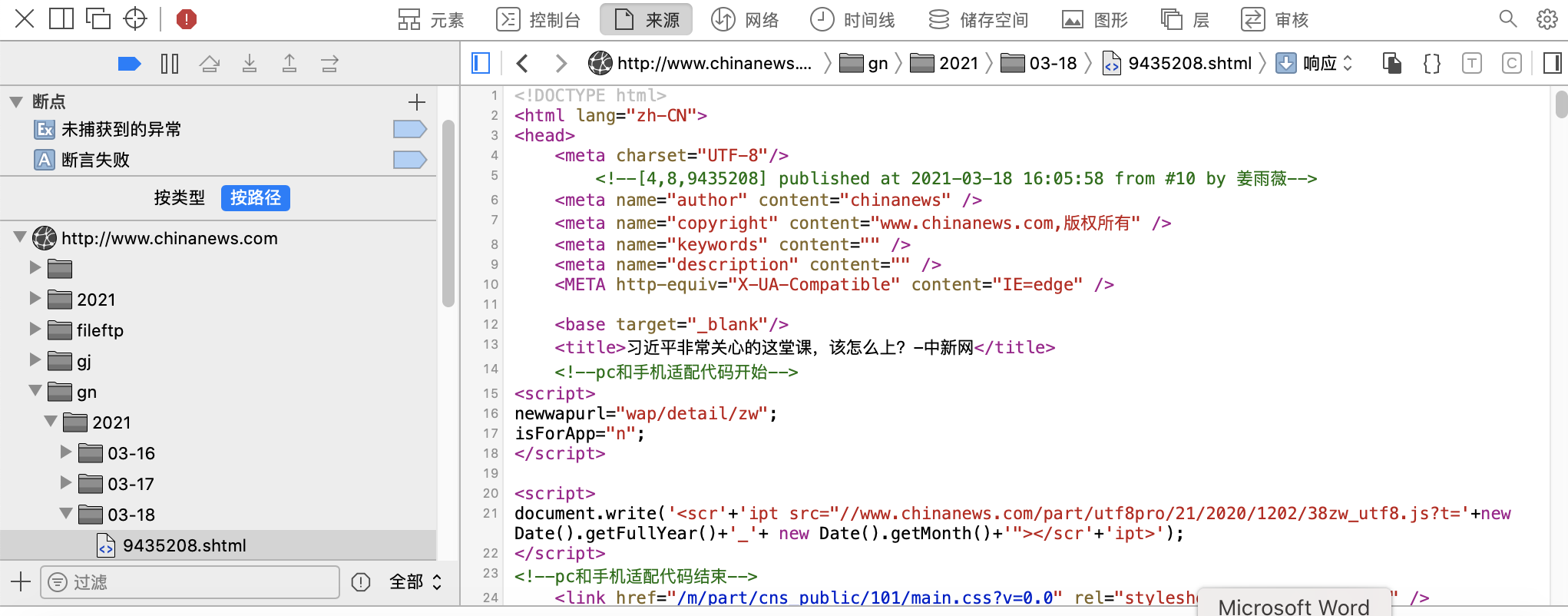 Then I don't understand it very well (I can almost understand it in the later stage), and then go to the next one!
Then I don't understand it very well (I can almost understand it in the later stage), and then go to the next one!
3. Analyze all news links in the seed page
(to be honest, at the beginning, I didn't quite understand what the teacher asked us to do)
Analyze the news links of the seed page, that is, crawl out all a links
At first, I didn't understand the teacher's code, but I saw some videos and codes of crawlers on the Internet and ran again. The code given by the teacher was almost a preliminary understanding.
Then I tried to write my own code. Unlike the teacher, I introduced the request function of http library to write it, which means that my homework has its own ideas, hahaha, but it's almost the same in essence
//Introduce http module
const https = require ('https')
const cheerio = require ('cheerio')
var myurl = 'https://sports.sina.com.cn'
//Create request object
var req = https.request(myurl,res => {
let chunks =[]//Because there are many chunks, use chunks to accept it
//The data event is that data is transmitted, data is responded to, and then it is received with chunk
res.on('data',chunk => chunks.push(chunk))
//end indicates that all data has been transmitted. A callback can be made at this time
res.on('end',()=>{
//Spliced into a complete data stream, and then converted into html code
let htmlstr = Buffer.concat(chunks).toString('utf-8')
//console.log(htmlstr)
var all=[]
let $ = cheerio.load(htmlstr)//Using cherio to parse the whole web page, $object is equal to our deblocking object
$('a').each((index,item) =>{
//Traverse each function
//console.log( $(item).attr('href'))
all.push( $(item).attr('href'))
})
console.log(all)
})
})
//Request sent
req.end()
The operation results are as follows:
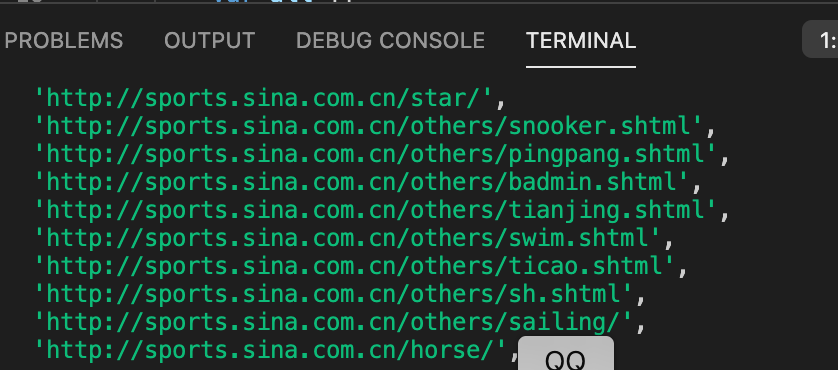
I feel that I have completed the first step. The result of this operation is to print out all a links of sina sports network, but the problems encountered later are really various!!!!!!!
According to the results we print now, we can see that some web pages are not standardized, so we need to write a piece of code to make its output format standardized
The code is as follows:
if (typeof(mine) == "undefined") return true;
if (mine.toLowerCase().indexOf('http://') >= 0 || mine. toLowerCase(). indexOf('https://') >= 0) mine = mine; // Http: / /, or HTTPS: / /
else if (mine.startsWith('//')) mine = 'http:' + mine ; initial
else mine = myurl.substr(0, myurl.lastIndexOf('/') ) + mine; //other
4. Start formal crawling (see 1.js for complete code)
Then write variables according to the content you want to crawl. The teacher gives examples to illustrate
//Import http module
const https = require ('https')
const http = require ('http')
const cheerio = require ('cheerio')
const fs = require ('fs')
require('date-utils');
var myurl = 'https://sports.sina.com.cn '/ / create request object
var keywords_format = " $('meta[name=\"keywords\"]').eq(0).attr(\"content\")";
var title_format = "$('title').text()";
var date_format = "$('meta[property=\"article:published_time\"]').eq(0).attr(\"content\")";
var author_format = "$('meta[property=\"article:author\"]').eq(0).attr(\"content\")";
var desc_format = " $('meta[name=\"description\"]').eq(0).attr(\"content\")";
var url_reg =/\/.+\/\d{4}-\d{2}-\d{2}\/.+[.]shtml/;
var source_name ='Sina News'
var myEncoding = "utf-8";
Prevent websites from blocking our Crawlers
var headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36'
}
At the beginning, I each 'a' link, and then directly began to operate on the database, but I found that in this way, the information crawled every time is the same!! All are sina sports general pages, which comes down to the original reason: you always get the content of the home page because you only visit the url of the home page and don't visit other links. So now we need to introduce a newget function to continue to access other links before file operation.
But the problem comes again. Directly perform the newget function on the accessed link and directly report an error
Mentality collapse, woo woo ~
Later, after being instructed by experts, ha ha ha ha found that because some of the 'a' links we climbed to start with 'http' and some start with 'https', we need to write them by category. It sounds very complicated, but after writing a newget function, we can copy and change the other one
The classification is as follows: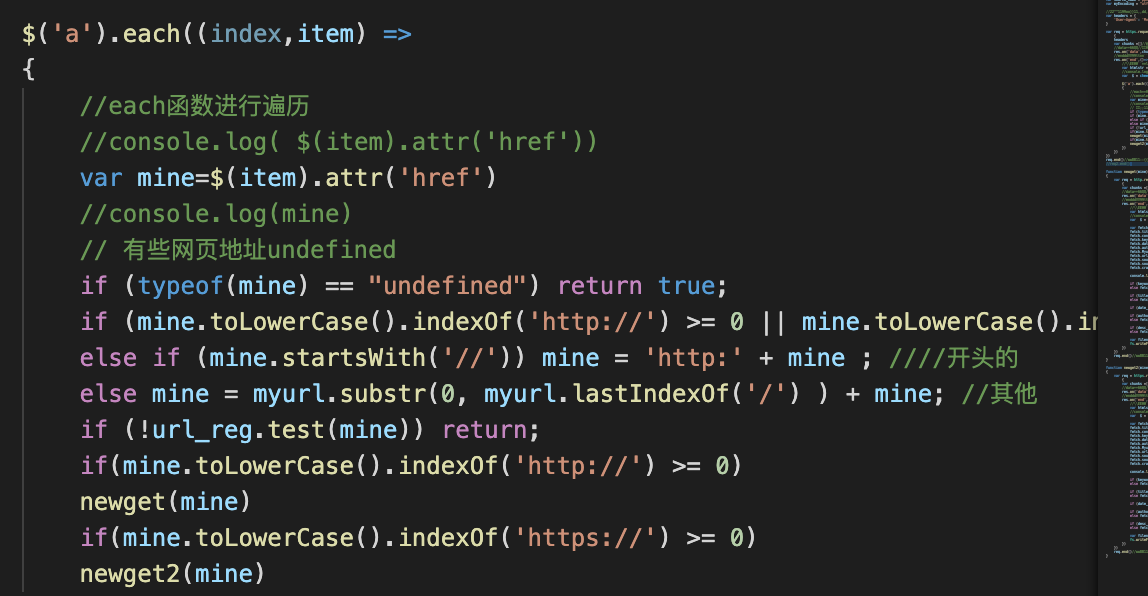
The newget function is as follows:
function newget(mine)
{
var req = http.request(mine,res =>
{
var chunks =[]//Because there are many chunks, use chunks to accept it
//The data event is that data is transmitted, data is responded to, and then it is received with chunk
res.on('data',chunk => chunks.push(chunk))
//end indicates that all data has been transmitted. A callback can be made at this time
res.on('end',()=>{
//Spliced into a complete data stream, and then converted into html code
var htmlstr = Buffer.concat(chunks).toString('utf-8')
//console.log(htmlstr)
var $ = cheerio.load(htmlstr)//Using cherio to parse the whole web page, $object is equal to our deblocking object
var fetch = {};
fetch.title = "";
fetch.content="";
fetch.keywords = "";
fetch.date = "";
fetch.author = "";
fetch.Myurl=myurl;
fetch.url=mine;
fetch.source_name = source_name;
fetch.source_encoding = myEncoding;
fetch.crawltime=new Date();
console.log('Transcoding succeeded:'+fetch.url)
if (keywords_format == "") fetch.keywords =""; // eval(keywords_format); // Use sourcename without keywords
else fetch.keywords = eval(keywords_format);
if (title_format == "") fetch.title = ""
else fetch.title = eval(title_format); //title
if (date_format != "") fetch.publish_date = eval(date_format); //Publication date
if (author_format == "") fetch.author = source_name; //eval(author_format); // author
else fetch.author = eval(author_format);
if (desc_format == "") fetch.content = "";
else fetch.content = eval(desc_format);
var filename = source_name + "_" + (new Date()).valueOf()+"_" + ".json";
fs.writeFileSync(filename, JSON.stringify(fetch));
})
})
req.end()//Request sent to
}
The newget2 function only needs to change the http at the beginning of the newget function to https
Then start running!!!!
success!! (in fact, most of the crawling process experiences failures and all kinds of errors are reported, which will not be shown here one by one)
The operation results are as follows:
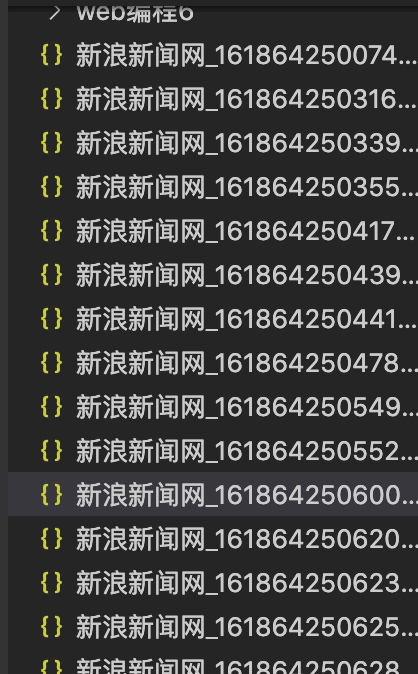

I'm so excited!!!!
5. Create and use database
Enter / usr/local/MySQL/bin/mysql -u root -p on the terminal to enter mysql
Then enter the password
Re input
create database crawl;
use crawl; (be sure to pay attention to the end of the sentence + semicolon, otherwise you will make mistakes many times)
6. Store in the database (see 2. JS for complete code)
First create a table (fetches code) according to your own needs. After the table is created successfully, slightly modify the database code
But after running the code
indeed
Wrong report 😭😭😭😭😭

If there is a problem, solve it!!!
then
The reason for the error indicates that there is a problem with my insertion statement
I wrote eight '
But what I want to insert is seven fields
So change!!!!
Fresh code out
//var filename = source_name + "_" + (new Date()).valueOf()+"_" + ".json";
//fs.writeFileSync(filename, JSON.stringify(fetch));
var fetchAddSql = 'INSERT INTO fetches(url,source_name,source_encoding,title,' +'keywords,author,crawltime,content) VALUES(?,?,?,?,?,?,?,?)';
var fetchAddSql_Params = [fetch.url, fetch.source_name, fetch.source_encoding,fetch.title, fetch.keywords, fetch.author,fetch.crawltime, fetch.content];
mysql.query(fetchAddSql, fetchAddSql_Params, function(qerr, vals, fields) {
if (qerr) {
console.log(qerr);
}
});
success
Check the author and title in fetches;
select author, title from fetches;
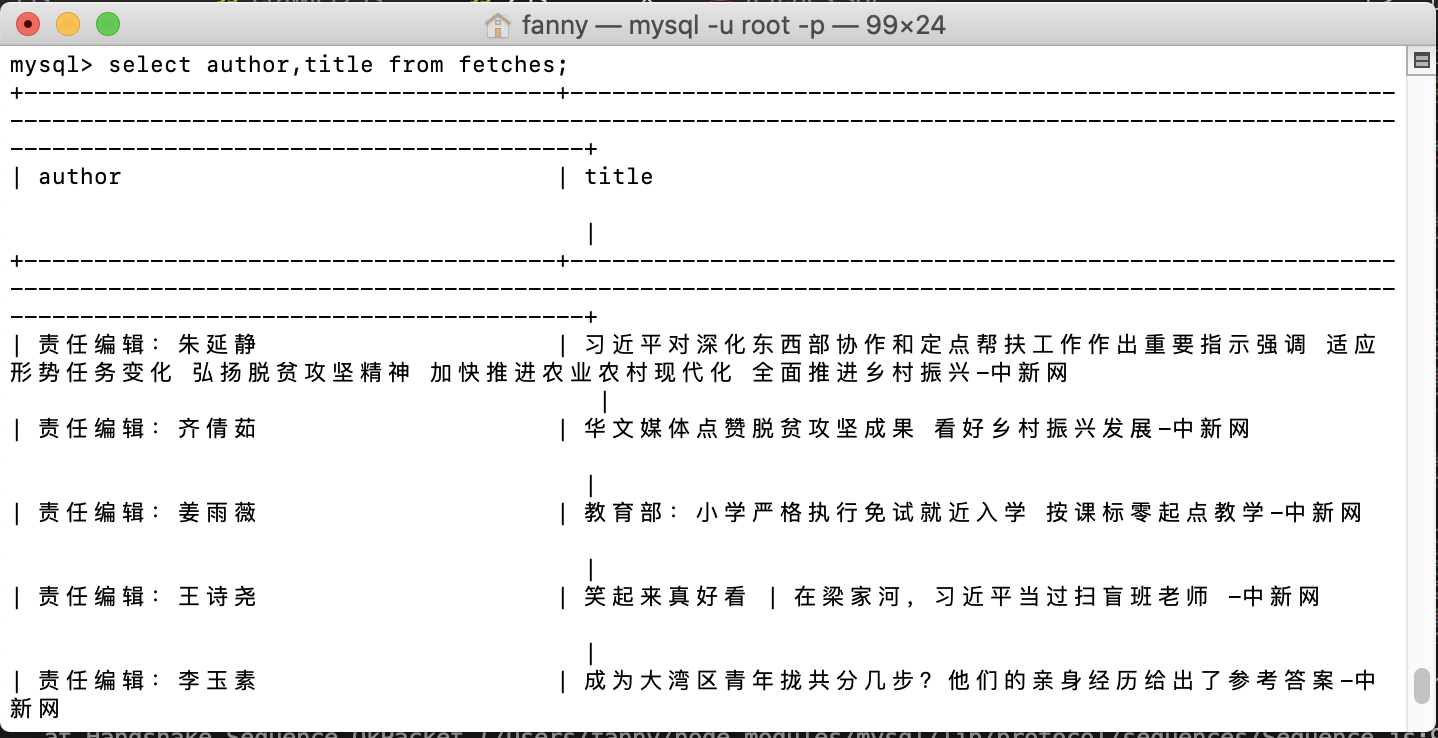
So excited!!!!!
7. Use mysql to view the data you crawled
Have a try
The result is optimistic

8. Send the request to the later section for query with the web page
First create a front end (file 4.html)
Note: use English! Otherwise, it will be garbled: (in fact, it can also be added at the beginning
< meta charset = "utf-8" / >, convert all codes into -- utf-8)

It'll be like this
Then create a back-end (file 4)
After running, the query results are as follows:

9. Build a website with express and access mysql
Similarly, create the front end first (note in English) (see 5.html)

Then create the back-end file 5 js
`
The results are as follows:

10. Use express scaffold to create network framework
The good guy followed the teacher's example, kept reporting mistakes and said, "command not find express“
Then ask for help from the boss. Anyway, the express path is wrong
So the solution is:
First manually create a file called "e_1"
Then create a new terminal window located in the folder
Enter express -e at the terminal
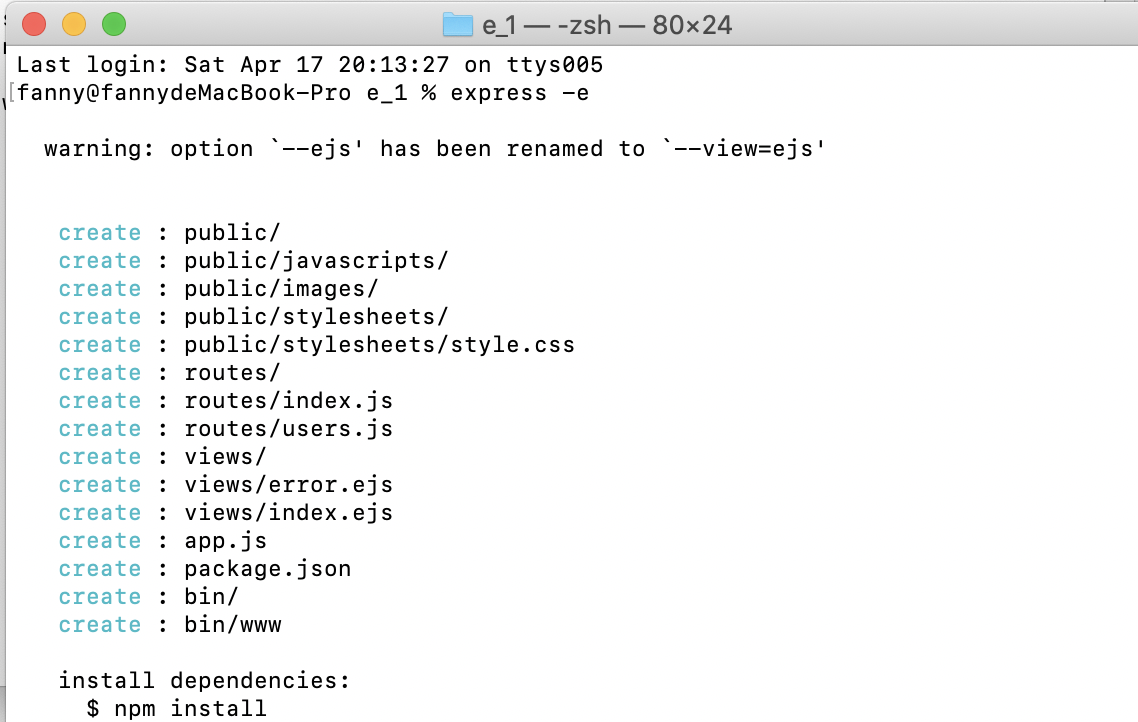
That's it
Then enter npm install mysql --save to install the mysql package into the project and save the dependencies into package json
Then enter npm install to install the package All the dependencies listed in JSON are installed to complete the website construction

After that, modify the index in the routes directory js
Then, in e_1/public / create a search html
however
Error or error! I can't query on the page at all
unable to solve
Find a teaching assistant - find a problem - solve a problem
The first is index A small problem with the sql statements written in JS is the authorrom. The two are connected together, which makes it impossible to query the database normally
Modify! The main problem is index Process in JS_ get
Method: in search HTML adds an action in the form to execute the carriage return operation and makes it jump to index JS / process_get to handle
Fresh code
index modification
var express = require('express');
var router = express.Router();
var mysql = require('../mysql.js');
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/process_get', function(request, response) {
//sql strings and parameters
var fetchSql = "select url,source_name,title,author " +
"from fetches where title like '%" + request.query.title + "%'";
console.log(request.query.title);
mysql.query(fetchSql, function(err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json"
});
if(err){
console.log(err);
return;
}
console.log(result);
response.write(JSON.stringify(result));
response.end();
});
});
module.exports = router;
search modification
<!DOCTYPE html>
<html>
<header>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js"></script>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</header>
<body>
<form action="/process_get">
<br> title:<input type="text" name="title">
<input class="form-submit" type="button" value="query">
</form>
<div class="cardLayout" style="margin: 10px 0px">
<table width="100%" id="record2"></table>
<tr class="cardLayout"><td>url</td><td>source_name</td><td>title</td><td>author</td><td>publish_date</td></tr>
</div>
<script>
$(document).ready(function() {
$("input:button").click(function() {
$.get('/process_get?title=' + $("input:text").val(), function(data) {
$("#record2").empty();
$("#record2").append('<tr class="cardLayout"><td>url</td><td>source_name</td>' +
'<td>title</td><td>author</td></tr>');
for (let list of data) {
let table = '<tr class="cardLayout"><td>';
Object.values(list).forEach(element => {
table += (element + '</td><td>');
});
$("#record2").append(table + '</td></tr>');
}
});
});
});
</script>
</body>
</html>
Then input: node at the terminal/ bin/www
This is different from the teacher's input
It depends on what's in your directory
Then open it with a chrome browser http://127.0.0.1:3000/search.html
Be sure to add the port name
Otherwise, it will not open like me
The results are as follows: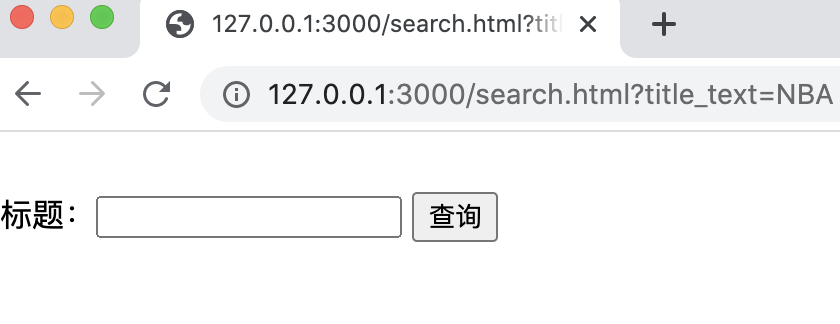
Enter NBA:

Is that it?
No, no!
Good guy, I ran the previous code again today, and then I found 5 J S can't run. I'm so sad. I keep reporting errors and saying Error: Cannot find module 'express'. I can't solve it. Then I found after pointing out:
My 5 There is no node in the directory where JS is located_ The modules folder doesn't store other modules, so it keeps reporting errors. Solution: find node in other places_ After the modules folder, copy to 5 JS file, just run it again!
11. Further make our website more beautiful
1. Re evaluate index JS and search Modify HTML
Amend as follows:
index.js
var express = require('express');
var router = express.Router();
var mysql = require('../mysql.js');
/* GET homepage */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/process_get', function(request, response) {
//sql
var fetchSql = "select url,source_name,title,author " +
"from fetches where author like '%" + request.query.author + "%'";
var tarray=request.query.title.split(" ");
for(var i=0;i<tarray.length;i++){
fetchSql+="and title like '%"+ tarray[i] + "%'";
}
fetchSql+="order by publish_date"
mysql.query(fetchSql, function(err, result, fields) {
response.writeHead(200, {
"Content-Type": "application/json"
});
response.write(JSON.stringify(result));
response.end(); ``
});
});
module.exports = router;
Modification 1: the search parameter author is added
Modification 2: since most titles are long, in order to facilitate the query of composite elements (for example, the query of "a and B" and the space is used as the division symbol), the split("") obtains an array (such as "A,B") divided by spaces, and then circularly imports it with the "and title like" statement to successfully complete the matching search (complete the fuzzy query with like and wildcards).
search.html modification
<!DOCTYPE html>
<html>
<header>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js"></script>
</header>
<head>
<style>
.cardLayout{
border:rgb(224, 23, 117) solid 10px;
margin: 5px 0px;
}
tr{
border: solid 3px;
}
td{
border:solid 3px;
}
</style>
</head>
<body>
<form>
<br> title:<input type="text" id="input1" name="title_text">
<br> Author:<input type="text" id="input2" name="title_text">
<input class="form-submit" type="button" id="btn1"value="query">
<input type="reset">
</form>
<div class="cardLayout">
<table width="100%" id="record2"></table>
</div>
<script>
$(document).ready(function() {
$("#btn1").click(function() {
$.get('/process_get?title=' + $("#input1").val()+'&author='+$("#input2").val(), function(data) {
$("#record2").empty();
$("#record2").append('<tr class="cardLayout"><td>url</td><td>source_name</td>' +
'<td>title</td><td>author</td><td>publish_date</td></tr>');
for (let list of data) {
let table = '<tr class="cardLayout"><td>';
Object.values(list).forEach(element => {
table += (element + '</td><td>');
});
$("#record2").append(table + '</td></tr>');
}
});
});
});
</script>
</body>
</html>
The main modification is to add a section of style to make the page more beautiful (I like rose red recently, ha ha ha)
That's it:
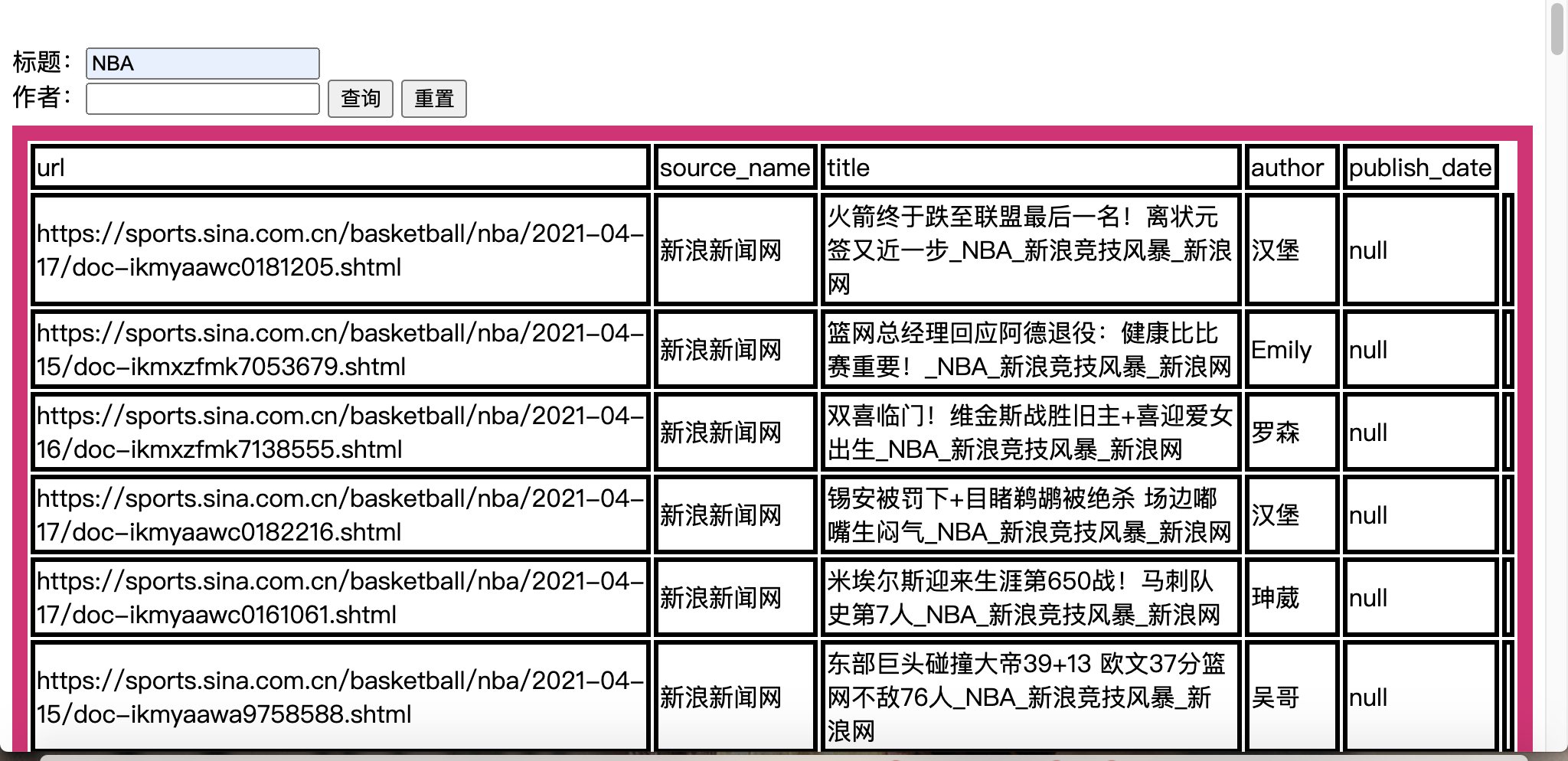
Compound title search
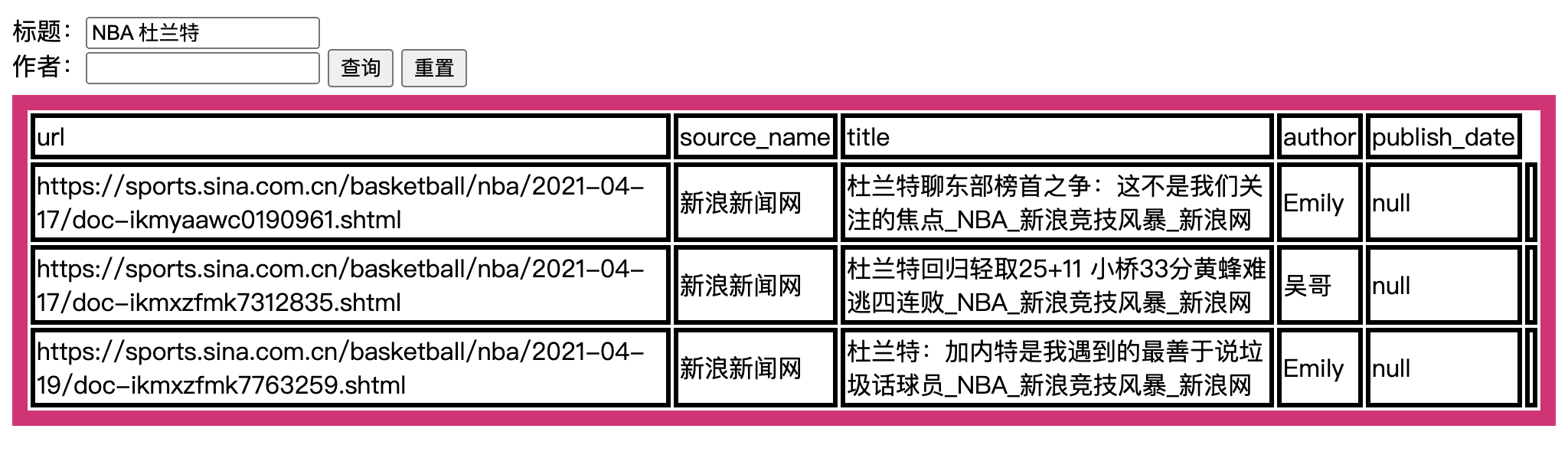
Then the point comes!!!!!
Paging operation—— Because there are too many pages
This step is learned from the online boss
1. Step 1: fine tune the html file: first introduce the bootstrap package on the original basis
The main thing is to introduce bootstrap package!!!!!
<head>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.js"></script>
<link href="http://www.itxst.com/package/bootstrap-table-1.14.1/bootstrap-4.3.1/css/bootstrap.css" rel="stylesheet" />
<link href="http://www.itxst.com/package/bootstrap-table-1.14.1/bootstrap-table-1.14.1/bootstrap-table.css" rel="stylesheet" />
<script src="http://www.itxst.com/package/bootstrap-table-1.14.1/bootstrap-table-1.14.1/bootstrap-table.js"></script>
<style>
.cardLayout{
border:rgb(224, 23, 117) solid 10px;
margin: 5px 0px;
}
tr{
border: solid 2px;
}
td{
border:solid 2px;
}
</style>
</head>
2. Step 2: then modify the part of the form displayed in the get function (using the bootstrap method)
<script>
$(document).ready(function() {
$("#btn1").click(function() {
/*$.get('/process_get?title=' + $("#input1").val()+'&author='+$("#input2").val(), function(data) {
$("#record2").empty();
$("#record2").append('<tr class="cardLayout"><td>url</td><td>source_name</td>' +
'<td>title</td><td>author</td><td>publish_date</td></tr>');
for (let list of data) {
let table = '<tr class="cardLayout"><td>';
Object.values(list).forEach(element => {
table += (element + '</td><td>');
});
$("#record2").append(table + '</td></tr>');
}
});*/
$.get('/process_get?title=' + $("#input1").val()+'&author='+$("#input2").val(), function(data) {
$("#record2").bootstrapTable({
search:true, //Add search control
method: 'get', //Request mode
pagination: true, //Show pagination
striped: true, //Whether to display interlaced color
uniqueId: "userId", //The unique identifier of each row, which is generally the primary key column
pageSize: 5, //Record lines per page
sidePagination : 'client',
columns:[{
field:'url', //Corresponding database field name
title:'link',
},{
field:'source_name',
title:'source'
},{
field:'title',
title:'title'
},{
field:'author',
title:'author'
}],
data: data,
});
});
});
});
</script>
Achievement display:
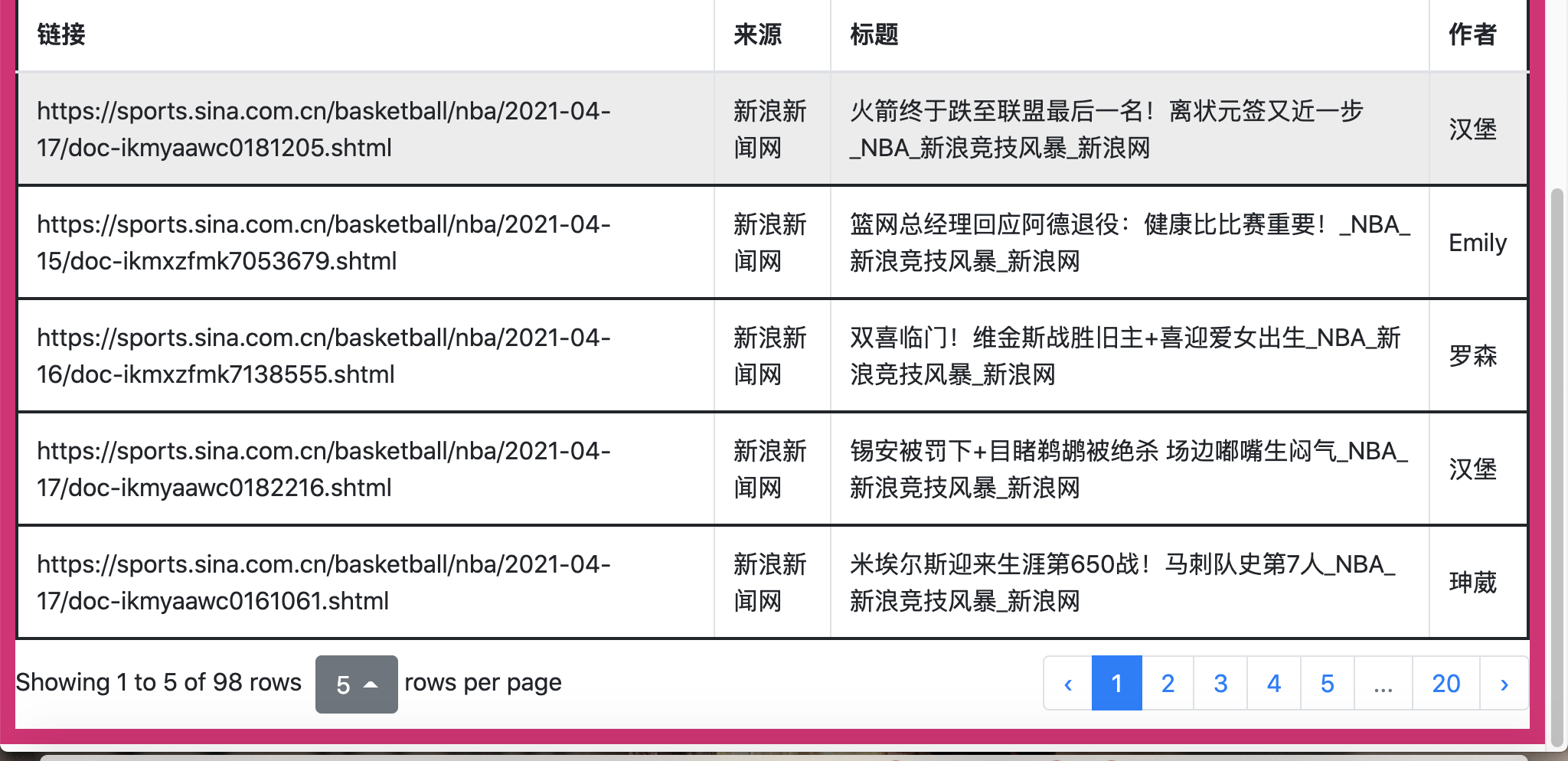
End - sprinkle flowers 🎉🎉🎉
Learning paging succeeded
12. Summary
It's really not easy. At first, I didn't understand all kinds of grammars of JS and HTML, and I couldn't understand all kinds of random reading on the Internet. Later, I found that it was most useful to understand the code given by the teacher first. I followed the teacher's code step by step. If there were any problems, I solved them by asking the teacher, the teaching assistant and the boss. During this period, I also encountered many difficulties and reported various errors, At the beginning, I experienced a lot of setbacks in selecting crawling websites. It's really not easy to find all "utf-8". In the last step, I think it's also very difficult to paginate. During this period, I tried many writing methods, which has always been impossible. Finally, I saw a tutorial on the Internet and wrote it step by step. Finally, it's OK. The above is the first reptile experience. I hope it will get better and better in the future!