Catalog
5. union and union all operators
0. Links to related articles
1. select operator
SELECT is used to select data from DataSet/DataStream and to filter out certain columns.
Example:
// Remove all columns from the table SELECT * FROM Table; // Remove the name and age columns from the table SELECT name,age FROM Table;
At the same time, functions and aliases can be used in SELECT statements, such as the WordCount we mentioned above:
SELECT word, COUNT(word) FROM table GROUP BY word;
2. where operator
WHERE is used to filter data from datasets/streams, together with SELECT, to split relationships horizontally based on certain conditions, that is, to select qualified records.
Example:
SELECT name,age FROM Table where name LIKE '% Xiao Ming %'; SELECT * FROM Table WHERE age = 20;
WHERE is filtered from the original data, so Flink SQL also supports the combination of expressions =, <, >, <>, >=, <=, and AND, OR in the WHERE condition, and the data that ultimately meets the filter condition will be selected. WHERE can be combined with IN and NOT IN. For instance:
SELECT name, age FROM Table WHERE name IN (SELECT name FROM Table2);
3. distinct operator
DISTINCT is used to deweigh datasets/streams based on the results of SELECT.
Example:
SELECT DISTINCT name FROM Table;
For streaming queries, the State required to compute query results may grow indefinitely, and users need to control the state range of the query themselves to prevent it from becoming too large.
4. group by operator
GROUP BY is a grouping operation on data. For example, we need to calculate the total score of each student in the breakdown.
Example:
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
5. union and union all operators
UNION is used to merge two result sets, requiring the two result set fields to be identical, including field type and field order.
Unlike UNION ALL, UNION weights the result data.
Example:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2;
6. join operator
JOIN is used to combine data from two tables to form a result table. Flink supports JOIN types including:
join - inner join left join - left outer join right join - right outer join full join - full outer join
The semantics of the JOIN here are consistent with the JOIN semantics we use in relational databases.
Example:
JOIN (associates order form data with commodity table)
select * from orders inner join product on orders.productid = product.id
The difference between LEFT JOIN and JOIN is that when the right table has no data with the JOIN on the left, the corresponding field on the right complements the NULL output, and RIGHT JOIN is equivalent to the position where the left and right tables interact. FULL JOIN is equivalent to UNION ALL operation after RIGHT JOIN and LEFT JOIN.
Example:
select * from orders left join product on orders.productid = product.id select * from orders right join product on orders.productid = product.id select * from orders full outer join product on orders.productid = product.id
7. group window operator
Apache Flink currently has three Bounded Window s, depending on the division of window data:
Tumble, scrolling window, fixed size of window data, no overlap of window data;
Hop, sliding window, fixed size of window data, fixed window rebuild frequency, overlay of window data;
Session, session window, window data has no fixed size, windows are divided according to their data activity, and window data does not overlap.
7.1. tumble window operator
The Tumble scrolling window has a fixed size, and the window data does not overlap. The specific semantics are as follows:
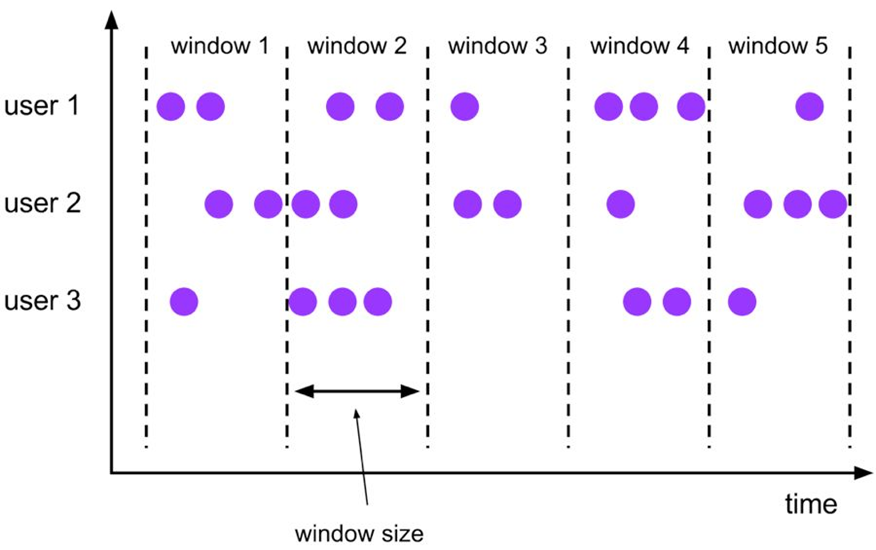
The syntax for the Tumble scrolling window is as follows:
select
[gk],
[tumble_start(timecol, size)],
[tumble_end(timecol, size)],
agg1(col1),
...
aggn(coln)
from tab1
group by [gk], tumble(timecol, size)Where:
[gk] determines whether aggregation by field is required;
TUMBLE_START represents the start time of the window;
TUMBLE_END represents the end time of the window;
timeCol is a time field in the stream table;
Size represents the size of the window, such as seconds, minutes, hours, days.
For example, if we want to calculate the daily order volume for each person, aggregate groups by user:
select
user,
tumble_start(rowtime, interval '1' day) as wstart,
sum(amount)
from orders
group by tumble(rowtime, interval '1' day), user;7.2. hop window operator
Hop sliding windows are similar to scrolling windows in that they have a fixed size, but unlike scrolling windows, sliding windows can control the frequency of new sliding windows through the slide parameter. Therefore, when the slide value is less than the window size value, multiple sliding windows overlap, with the following specific semantics:
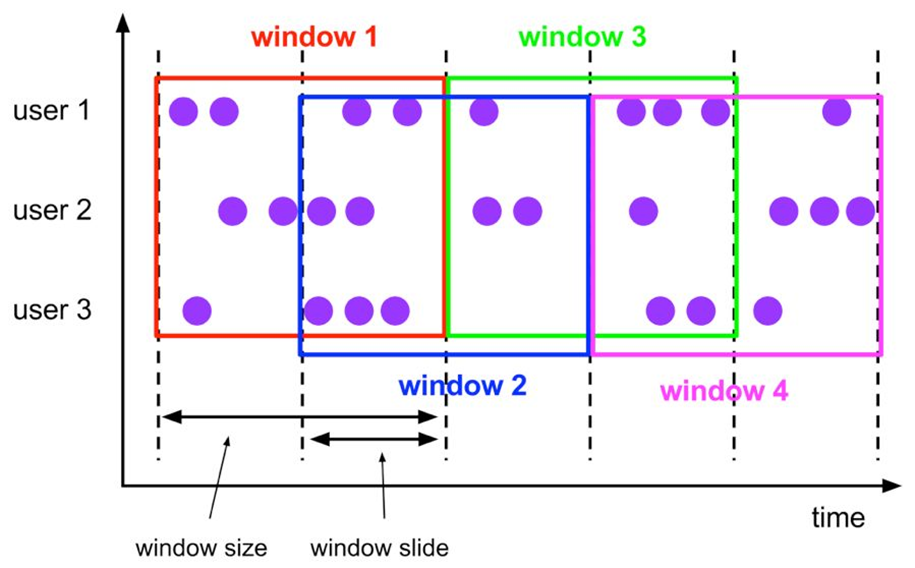
The corresponding syntax for Hop sliding window is as follows:
select
[gk],
[hop_start(timecol, slide, size)] ,
[hop_end(timecol, slide, size)],
agg1(col1),
...
aggn(coln)
from tab1
group by [gk], hop(timecol, slide, size)Each field has a similar meaning to the Tumble window:
[gk] determines whether aggregation by field is required;
HOP_START indicates the start time of the window;
HOP_END indicates the end time of the window;
timeCol represents the time field in the stream table;
Slide represents the size of each window slide;
Size represents the size of the entire window, such as seconds, minutes, hours, days.
For example, we need to calculate sales of each item every hour for the past 24 hours:
select
product,
sum(amount)
from orders
group by product,hop(rowtime, interval '1' hour, interval '1' day)7.3. session window operator
Session time windows do not have a fixed duration, but their boundaries are defined by interval inactivity time, that is, if no events occur during the defined interval, the session window closes.
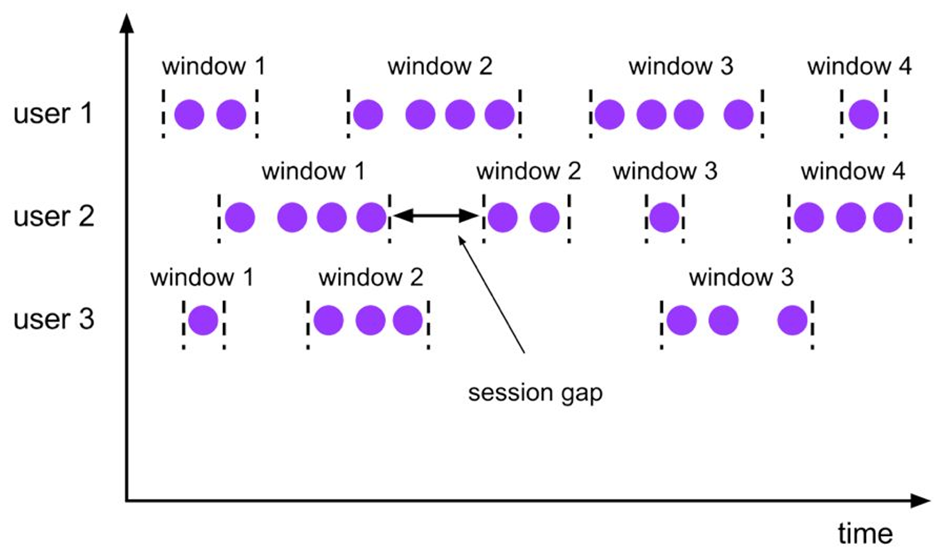
The corresponding syntax for the Seeeion session window is as follows:
select
[gk],
session_start(timecol, gap) as winstart,
session_end(timecol, gap) as winend,
agg1(col1),
...
aggn(coln)
from tab1
group by [gk], session(timecol, gap)[gk] determines whether aggregation by field is required;
SESSION_START indicates the start time of the window;
SESSION_END indicates the end time of the window;
timeCol represents the time field in the stream table;
A gap represents the length of the inactive cycle of window data.
For example, we need to calculate the order volume within 12 hours of each user's visit time:
select
user,
session_start(rowtime, interval '12' hour) as sstart,
session_rowtime(rowtime, interval '12' hour) as send,
sum(amount)
from orders
group by session(rowtime, interval '12' hour), user