1. Introduction to processfunction
1.1 description on API
A function that processes elements of a stream. For every element in the input stream processElement(Object, ProcessFunction.Context, Collector) is invoked. This can produce zero or more elements as output. Implementations can also query the time and set timers through the provided ProcessFunction.Context. For firing timers onTimer(long, ProcessFunction.OnTimerContext, Collector) will be invoked. This can again produce zero or more elements as output and register further timers. NOTE: Access to keyed state and timers (which are also scoped to a key) is only available if the ProcessFunction is applied on a KeyedStream. NOTE: A ProcessFunction is always a org.apache.flink.api.common.functions.RichFunction. Therefore, access to the org.apache.flink.api.common.functions.RuntimeContext is always available and setup and teardown methods can be implemented. See org.apache.flink.api.common.functions.RichFunction.open(org.apache.flink.configuration.Configuration) and org.apache.flink.api.common.functions.RichFunction.close().
(1) ProcessFunction is a function used to process elements in a stream
(2) The processElement() method is used to process each element and can output 0 to multiple outputs
(3) Through processfunction Context. Get alarm clock and set alarm clock
(4) When the alarm clock rings, the OnTimer() method will execute. In this method, 0 to n outputs can be output, and the alarm clock can be set again
matters needing attention:
(1) The function of the alarm clock is only valid for KeyedStream
(2) Processfunctions are also rich functions in nature, so you can also use state programming and lifecycle methods
1.2 type structure view

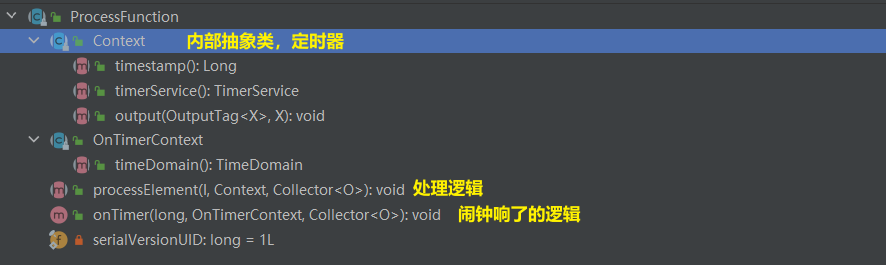
1.3 application scenario of processfunction
Since ProcessFunction is an abstract subclass of AbstractRichFunction, ProcessFunction can be used in any scenario where RichFunction can be used
Usage scenario of richFunction:
- Third party write library
- Get the context environment for state programming
Unique usage scenarios of ProcessFunction:
- timer
- Side output stream
processFunction can only be used for data processing and cannot be used to define transmission and window opening (keyBy and window cannot)
Additional note: Flink SQL is implemented using Process Function.
1.4 8 processfunctions
Flink provides 8 process functions, each of which is used for different streams.
All processfunctions are parameters of the Stream's process operator
- ProcessFunction (common to DataStream)
- KeyedProcessFunction ( KeyedStream)
- CoProcessFunction (ConnectStream)
- ProcessJoinFunction (JoinStream)
- BroadcastProcessFunction (broadcast stream)
- KeyedBroadcastProcessFunction
- ProcessWindowFunction (windowfunction of windowStream after KeyBy)
- Processallwindowfunction (windowfunction of datastream)
2. Function display of processfunction
package No08_process;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
public class _01_ProcessFunction Function display {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("hadoop102", 9999);
}
public static class MyProcessFunc extends ProcessFunction<String,String> {
@Override
public void open(Configuration parameters) throws Exception {
//TODO function 1 gets the runtime context for state programming (this method inherits from RichFunction)
RuntimeContext runtimeContext = getRuntimeContext();
// Can get status
//runtimeContext.getState();
}
@Override
public void close() throws Exception {
super.close();
}
@Override
//TODO calls this method for each Element in the DataStream. The return value is void. You can decide whether there is output
// If you want to output, use collector to output
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
// todo function 3-out to mainstream output
out.collect(" ");
//todo function 2-ctx obtains the processing time, registers the processing time timer, and deletes the processing time timer
ctx.timerService().currentProcessingTime();
ctx.timerService().registerProcessingTimeTimer(1L);
ctx.timerService().deleteProcessingTimeTimer(1L);
//todo function 2 obtains the event time, registers the event time timer, and deletes the event time timer
ctx.timerService().currentWatermark();
ctx.timerService().registerEventTimeTimer(1L);
ctx.timerService().deleteEventTimeTimer(1L);
//todo function 4-ctx: write CTX to the side output stream output
//ctx.output(new OutputTag<String>("outPutTag"){},value);
}
@Override
//todo function 5: specify the task execution when the timer is triggered
// ctx can also set the alarm clock again
//out to mainstream output
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
super.onTimer(timestamp, ctx, out);
}
}
}
1. Timer
The TimerService objects held by Context and OnTimerContext have the following methods:
- currentProcessingTime(): Long returns the current processing time
- currentWatermark(): Long returns the timestamp of the current watermark
- Registerprocessingtimer (timestamp: long): unit will register the timer of the processing time of the current key. When the processing time reaches the timing time, the timer is triggered.
- Registereventtimer (timestamp: long): unit will register the event time timer of the current key. When the water level is greater than or equal to the time registered by the timer, the timer is triggered to execute the callback function.
- Deleteprocessingtimer (timestamp: long): unit deletes the previously registered processing time timer. If there is no timer with this timestamp, it will not be executed.
- Deleteeventtimer (timestamp: long): unit deletes the previously registered event time timer. If there is no timer with this timestamp, it will not be executed.
When the timer timer is triggered, the callback function onTimer() is executed. Note that the timer timer can only be used on keyed streams.
package No08_process;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class _03_timer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("hadoop102", 9999);
SingleOutputStreamOperator<String> res = source.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String s) throws Exception {
return s;
}
}).process(new MyOnTimerProcessFunc());
//The timer function can only be used with KeyedStream
res.print();
env.execute();
}
//todo implements the output of a piece of data two seconds after processing the current data
public static class MyOnTimerProcessFunc extends KeyedProcessFunction<String,String,String>{
@Override
public void processElement(String value,Context ctx, Collector<String> out) throws Exception {
out.collect(value);
//Register the alarm clock in two seconds
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + 2000L);
}
//The alarm clock rings and the task is timed
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println("The timer is triggered");
}
}
}
2. Side output flow
The output of most operators of DataStream API is a single output, that is, a stream of some data type. In addition to the split operator, a stream can be divided into multiple streams with the same data types. The side outputs function of process function can generate multiple streams, and the data types of these streams can be different. A side output can be defined as an OutputTag[X] object. X is the data type of the output stream. Process function can send an event to one or more side outputs through the Context object.
package No08_process;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class _04_Side output stream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("hadoop102", 9999);
KeyedStream<String, String> keyedStream = source.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String s) throws Exception {
return s;
}
});
//todo outputs the output with temperature less than 30 degrees to the side output stream, and the mainstream of the output with temperature greater than 30 degrees
SingleOutputStreamOperator<String> result = keyedStream.process(new mySplit());
result.print("high");
result.getSideOutput(new OutputTag<Tuple2<String,Double>>("<30"){}).print("sideOut");
env.execute();
}
public static class mySplit extends KeyedProcessFunction<String,String,String> {
@Override
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
//todo get temperature
String[] fields = value.split(",");
double temp = Double.parseDouble(fields[2]);
if(temp >= 30){
out.collect(value);
}else{
//The data type of the measured output stream is not limited and is defined when outputting
ctx.output(new OutputTag<Tuple2<String,Double>>("<30"){},new Tuple2<String,Double>(fields[0],temp));
}
//todo Description: the reason why the official recommends this method of streaming split is that the side output stream can be different from the mainstream data type
}
}
}