DataStream common operators
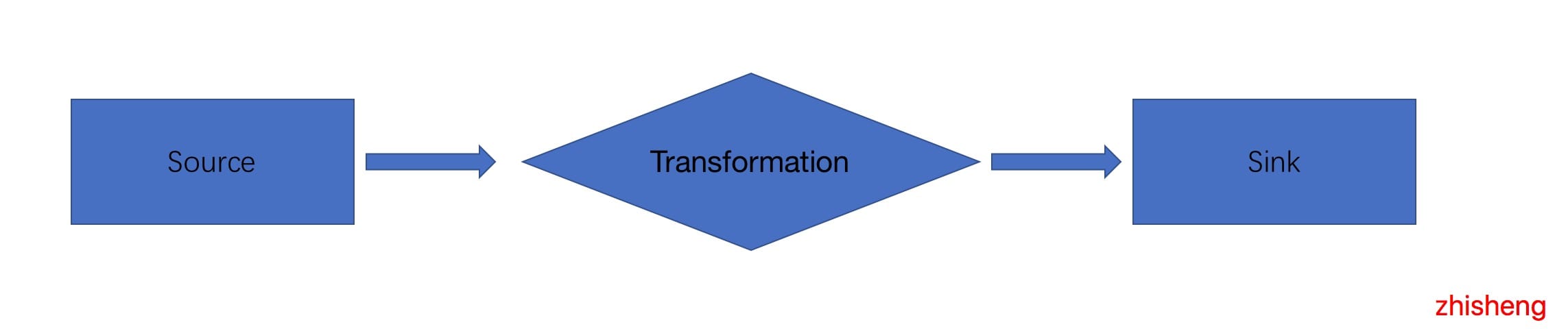
In the Flink application, whether your application is a batch program or a stream program, it is the model shown in the figure above. There are data sources and data sink s. The applications we write mostly do a series of operations on the data from the data source, which are summarized as follows.
-
Source: data source. Flink's sources for stream processing and batch processing can be divided into four categories: source based on local collection, source based on file, source based on network socket and custom source. Common custom sources include Apache kafka, Amazon Kinesis Streams, RabbitMQ, Twitter Streaming API, Apache NiFi, etc. of course, you can also define your own source.
-
Transformation: various operations of data conversion, including map / flatmap / filter / keyby / reduce / fold / aggregates / window / windowall / Union / window join / split / select / project, etc. there are many operations, which can convert and calculate the data into the data you want.
-
Sink: receiver. Sink refers to the place where Flink sends the converted data. You may need to store it. The common sink types of Flink are as follows: write to file, print out, write to Socket, and custom sink. Common custom sinks include Apache kafka, RabbitMQ, MySQL, ElasticSearch, Apache Cassandra, Hadoop file system, etc. similarly, you can also define your own sink.
Then this article will introduce the operators commonly used in batch and stream programs in Flink.
DataStream Operator
Let's first look at the operators commonly used in stream programs.
1,Map
The input stream of the Map operator is DataStream. The data format returned after the Map operator is SingleOutputStreamOperator type. Obtain an element and generate an element, for example:
SingleOutputStreamOperator<Employee> map = employeeStream.map(new MapFunction<Employee, Employee>() {
@Override
public Employee map(Employee employee) throws Exception {
employee.salary = employee.salary + 5000;
return employee;
}
});
map.print();
The salary of each employee will be increased by 5000 in the new year.
2,FlatMap
The input stream of the FlatMap operator is DataStream. The data format returned after the FlatMap operator is SingleOutputStreamOperator type. Obtain an element and generate zero, one or more elements, for example:
SingleOutputStreamOperator<Employee> flatMap = employeeStream.flatMap(new FlatMapFunction<Employee, Employee>() {
@Override
public void flatMap(Employee employee, Collector<Employee> out) throws Exception {
if (employee.salary >= 40000) {
out.collect(employee);
}
}
});
flatMap.print();
Find out those whose salary is more than 40000.
3,Filter
SingleOutputStreamOperator filter = ds.filter(new FilterFunction<Employee>() {
@Override
public boolean filter(Employee employee) throws Exception {
if (employee.salary >= 40000) {
return true;
}
return false;
}
});
filter.print();
Judge each element and return the element that is true. If it is false, discard the data. In fact, you can also use Filter to find employees whose salary is greater than 40000:
4,KeyBy
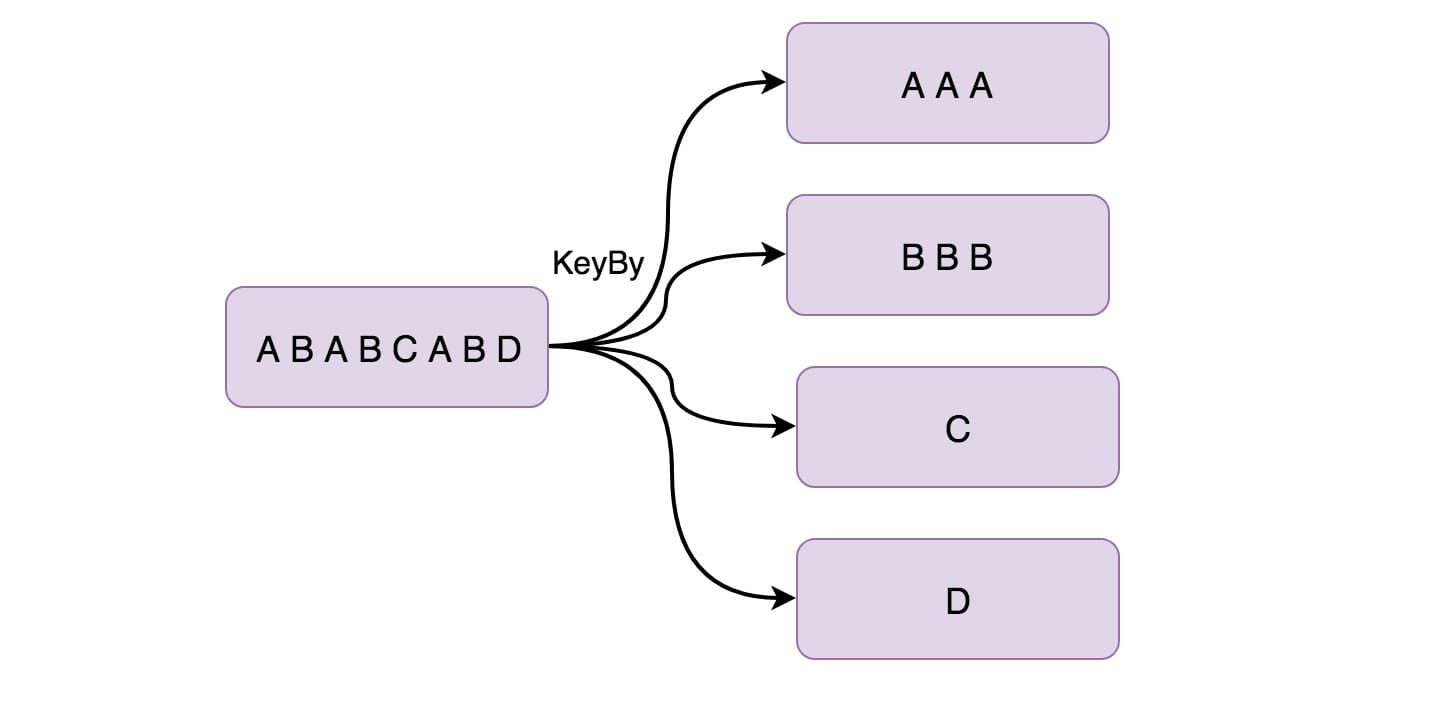
KeyBy is logically partitioned based on key convection, and the same key will be divided into a partition (here, partition refers to one of multiple parallel nodes of downstream operators). Internally, it uses hash functions to partition streams. It returns the KeyedDataStream data stream. for instance:
KeyedStream<ProductEvent, Integer> keyBy = productStream.keyBy(new KeySelector<ProductEvent, Integer>() {
@Override
public Integer getKey(ProductEvent product) throws Exception {
return product.shopId;
}
});
keyBy.print();
Partition according to the store id of the goods.
5,Reduce
Reduce returns a single result value, and a new value is always created for each element processed by the reduce operation. The commonly used methods include average, sum, min, max and count, which can be realized by using the reduce method.
SingleOutputStreamOperator<Employee> reduce = employeeStream.keyBy(new KeySelector<Employee, Integer>() {
@Override
public Integer getKey(Employee employee) throws Exception {
return employee.shopId;
}
}).reduce(new ReduceFunction<Employee>() {
@Override
public Employee reduce(Employee employee1, Employee employee2) throws Exception {
employee1.salary = (employee1.salary + employee2.salary) / 2;
return employee1;
}
});
reduce.print();
Firstly, the data stream is keyed, because the Reduce operation can only be KeyedStream, and then the employee's salary is averaged.
6,Aggregations
The DataStream API supports various Aggregations, such as min, max, sum, and so on. These functions can be applied to KeyedStream to obtain aggregates.
KeyedStream.sum(0)
KeyedStream.sum("key")
KeyedStream.min(0)
KeyedStream.min("key")
KeyedStream.max(0)
KeyedStream.max("key")
KeyedStream.minBy(0)
KeyedStream.minBy("key")
KeyedStream.maxBy(0)
KeyedStream.maxBy("key")
The difference between max and maxBy is that max returns the maximum value in the stream, but maxBy returns the key with the maximum value. min and minBy are the same.
7,Window
The Window function allows you to group existing keyedstreams by time or other criteria. The following is the aggregation in a 10 second time Window:
inputStream.keyBy(0).window(Time.seconds(10));
Sometimes, the business demand scenario requires that the data of one minute and one hour be aggregated for statistical reports.
8,WindowAll
WindowAll gathers elements according to certain characteristics. This function does not support parallel operation. The default parallelism is 1. Therefore, if you use this operator, you need to pay attention to performance problems. The following is an example:
inputStream.keyBy(0).windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)));
9,Union
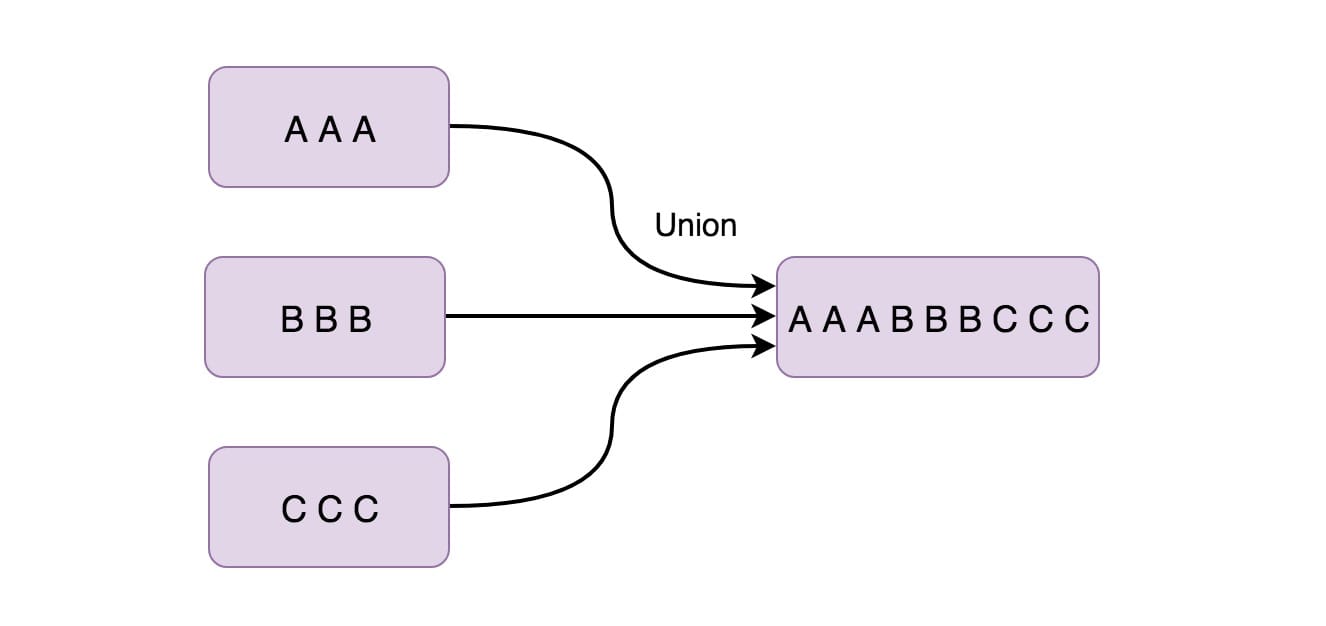
The Union function combines two or more data streams. In this way, only one data stream needs to be used later. If we combine a stream with itself, the combined data stream will have two copies of the same data.
inputStream.union(inputStream1, inputStream2, ...);
10,Window Join
We can join two data streams in the same window through some key s.
inputStream.join(inputStream1) .where(0).equalTo(1) .window(Time.seconds(5)) .apply (new JoinFunction () {...});
The above example is to connect two streams in a 5-second window, in which the connection condition of the first attribute of the first stream is equal to the second attribute of the other stream.
11,Split
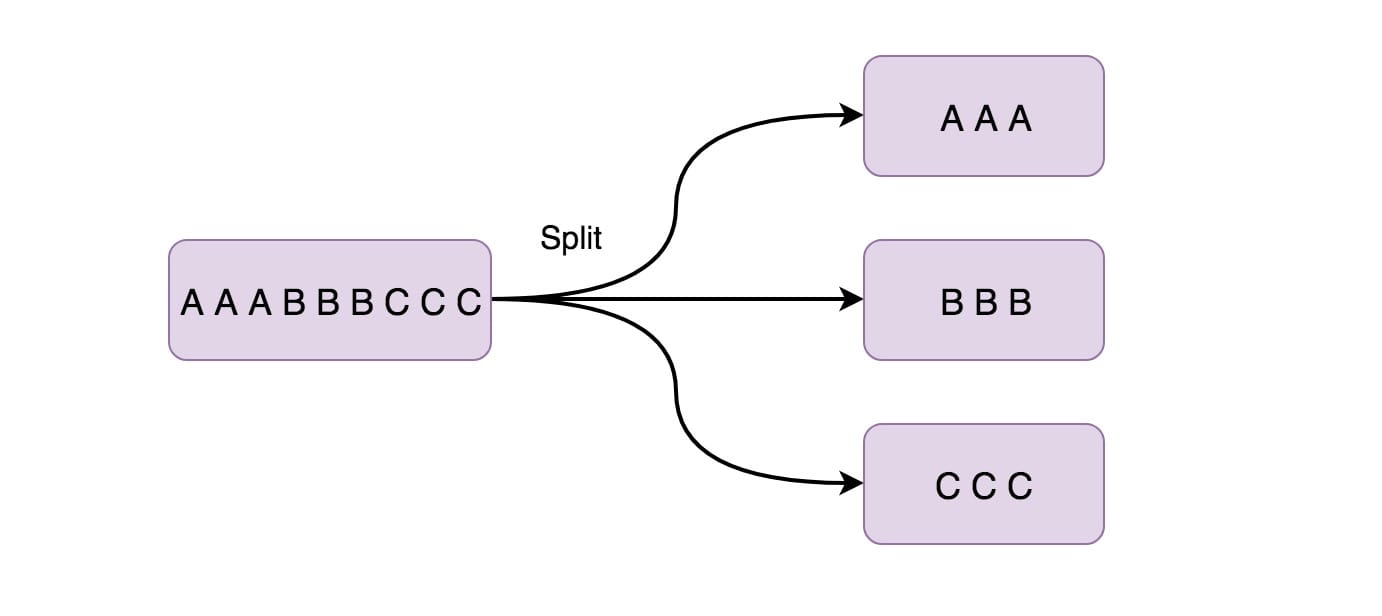
This function splits a flow into two or more flows based on conditions. You can use this method when you get mixed streams and then you may want to process each data stream separately.
SplitStream<Integer> split = inputStream.split(new OutputSelector<Integer>() { @Override public Iterable<String> select(Integer value) { List<String> output = new ArrayList<String>(); if (value % 2 == 0) { output.add("even"); } else { output.add("odd"); } return output; }});
The above is to put the even data stream in even and the odd data stream in odd.
12,Select
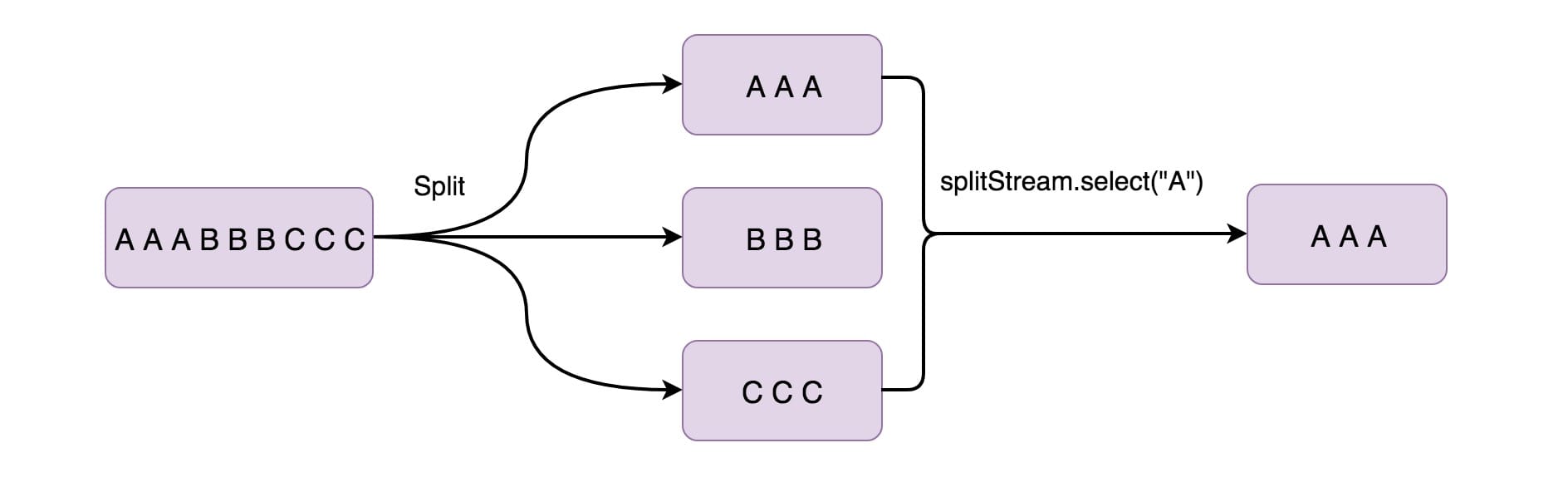
The Split operator is used to Split the data stream into two data streams (odd and even). Next, you may want to Select a specific stream from the Split streams, so you have to use the Select operator (generally, the two are used together),
SplitStream<Integer> split;DataStream<Integer> even = split.select("even"); DataStream<Integer> odd = split.select("odd"); DataStream<Integer> all = split.select("even","odd");