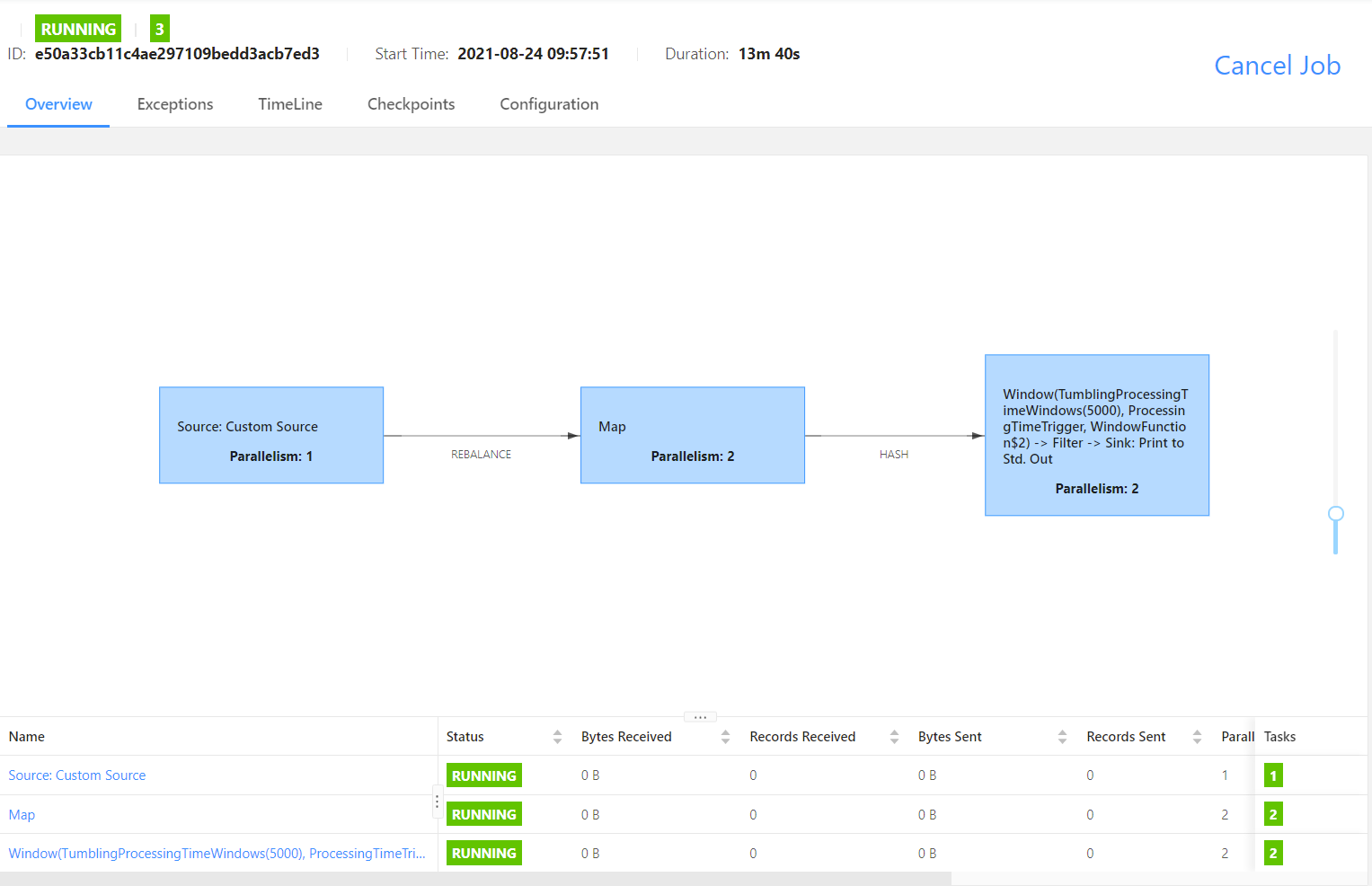
For distributed execution, Flink links the subtasks of operators together to form tasks, and the operators in each subtask are connected into a chain, that is, the Operator chain. Compared with each task executed by one thread, linking operators into tasks is a useful optimization: it reduces the overhead of inter thread switching and buffering, and increases the overall throughput while reducing latency.
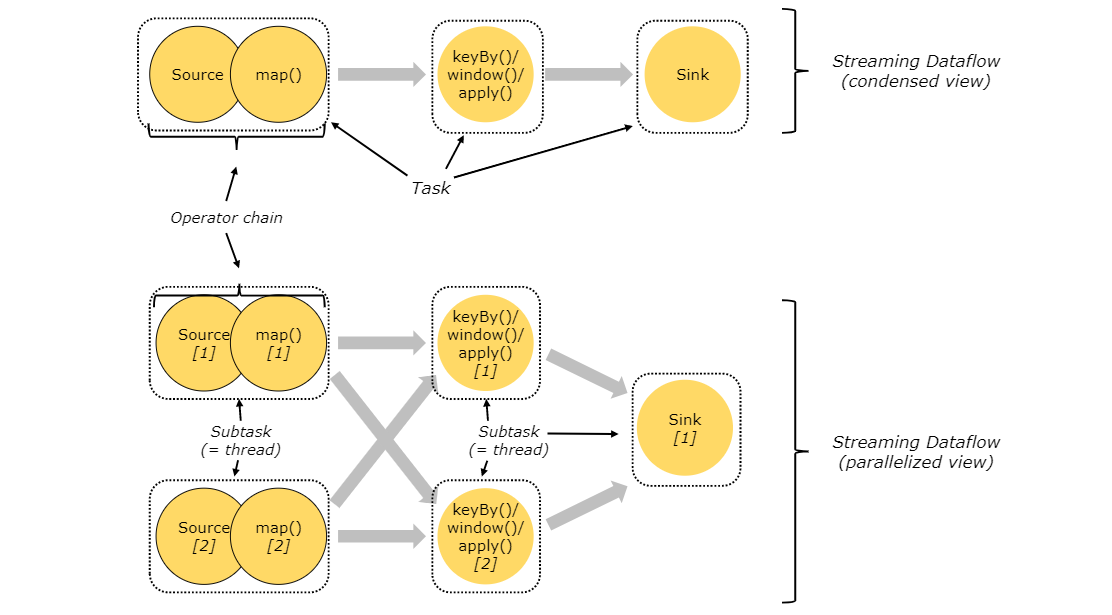
Each worker (Task Manager) is a JVM process that can execute one or more subtask s in a separate thread. In order to control how many tasks a task manager accepts, there are so-called task slots (at least one).
Each task slot represents a fixed subset of resources in task manager. For example, a TaskManager with three slots will use 1 / 3 of its managed memory for each slot. Allocating resources means that subtasks do not compete for managed memory with subtasks of other jobs, but have a certain amount of reserved managed memory. Note that there is no CPU isolation here; Currently, slot only separates the managed memory of task.
By adjusting the number of task slot s, users can define how subtasks are isolated from each other. Each task manager has a slot, This means that each task group runs in a separate JVM (for example, it can be started in a separate container). Having multiple slots means that more subtasks share the same JVM. Tasks in the same JVM share TCP connections (through multiplexing) and heartbeat information. They can also share data sets and data structures, reducing the overhead of each task.
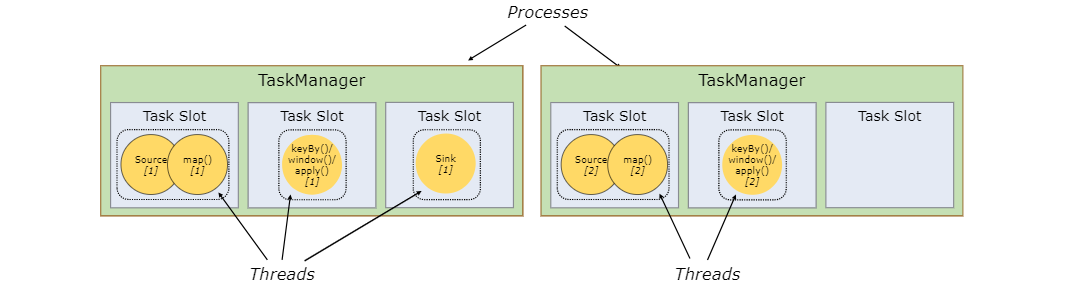
By default, Flink allows subtasks to share slots, even if they are subtasks of different tasks, as long as they come from the same job. The result is that a slot can hold the entire job pipeline. Allowing slot sharing has two main advantages:
-
The task slot required by the Flink cluster is exactly the same as the maximum parallelism used in the job. There is no need to calculate how many tasks the program contains in total (with different parallelism).
-
Easy access to better resource utilization. Without slot sharing, non intensive subtasks (source/map()) will block as many resources as intensive subtasks (Windows). Through slot sharing, the basic parallelism in our example increases from 2 to 6, which can make full use of the allocated resources and ensure that heavy subtasks are fairly distributed among taskmanagers.
You can experience how Flink divides subtasks according to the following sample program.
- When data is redirected, such as KeyBy operation.
- When the parallelism of program operators changes.
- Manually segment Operator by Operator
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port",8082);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(2);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("auto.offset.reset", "earliest");
properties.setProperty("group.id", "g1");
properties.setProperty("enable.auto.commit", "true");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"mytest",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> source = env.addSource(kafkaConsumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = source.map(new RichMapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(" ");
return Tuple2.of(split[0], Integer.parseInt(split[1]));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> applyStream = mapStream.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple2<String, Integer>> out) throws Exception {
for (Tuple2<String, Integer> tuple2 : input) {
out.collect(tuple2);
}
}
});
applyStream.print().setParallelism(1);
env.execute("");
}
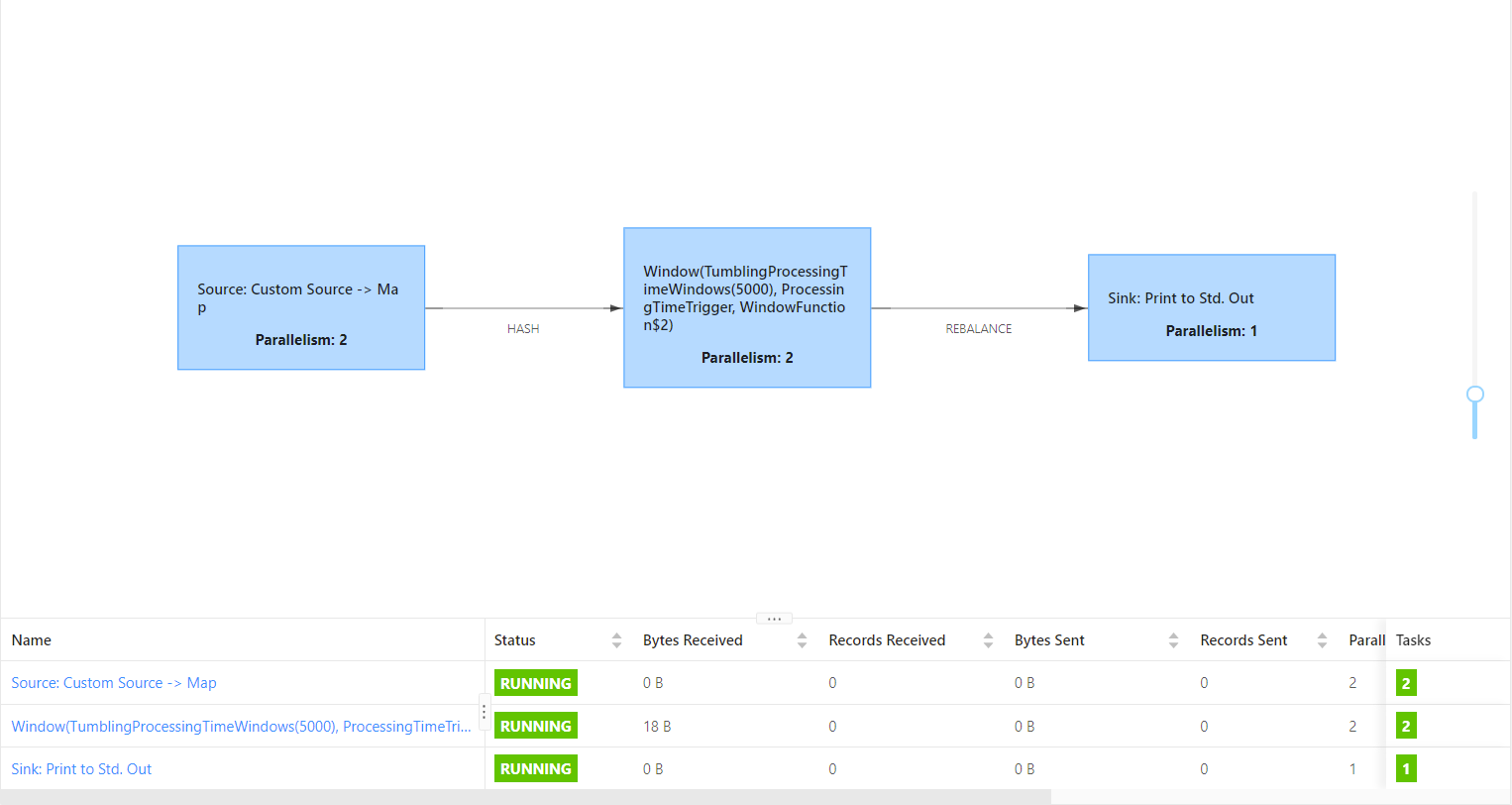
1. disableOperatorChaining
The Flink program opens the Operator chain by default. We can use it in the program
env.disableOperatorChaining(); To close.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port",8082);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(2);
env.disableOperatorChaining();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "59.111.211.35:9092,59.111.211.36:9092,59.111.211.37:9092");
properties.setProperty("auto.offset.reset", "earliest");
properties.setProperty("group.id", "g1");
properties.setProperty("enable.auto.commit", "true");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"mytest",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> source = env.addSource(kafkaConsumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = source.map(new RichMapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(" ");
return Tuple2.of(split[0], Integer.parseInt(split[1]));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> applyStream = mapStream.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple2<String, Integer>> out) throws Exception {
for (Tuple2<String, Integer> tuple2 : input) {
out.collect(tuple2);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> filterStream = applyStream.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> integerTuple2) throws Exception {
return integerTuple2.f0.startsWith("a");
}
});
filterStream.print().setParallelism(1);
env.execute("");
}
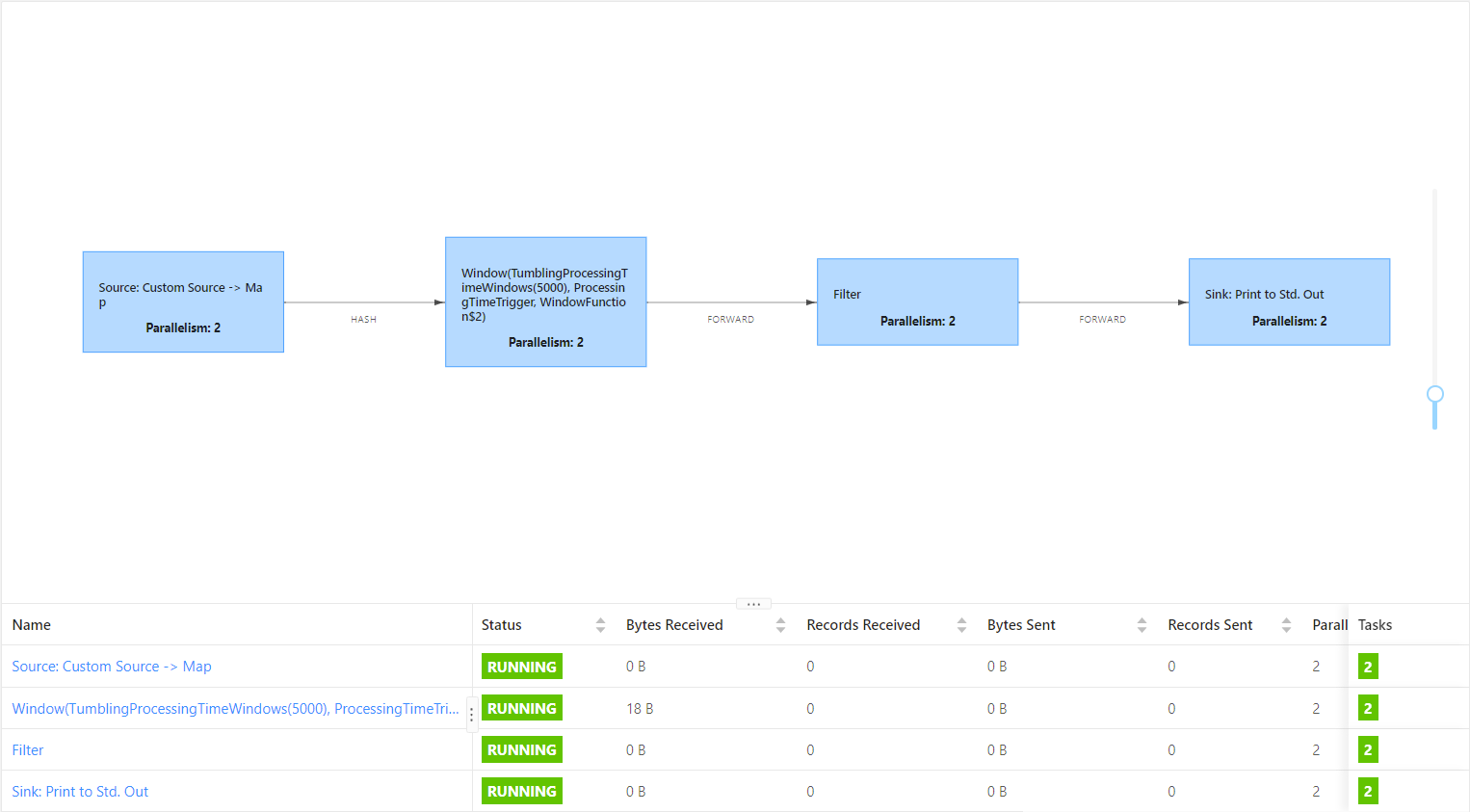
In this case, each Operator will be divided into a Task.
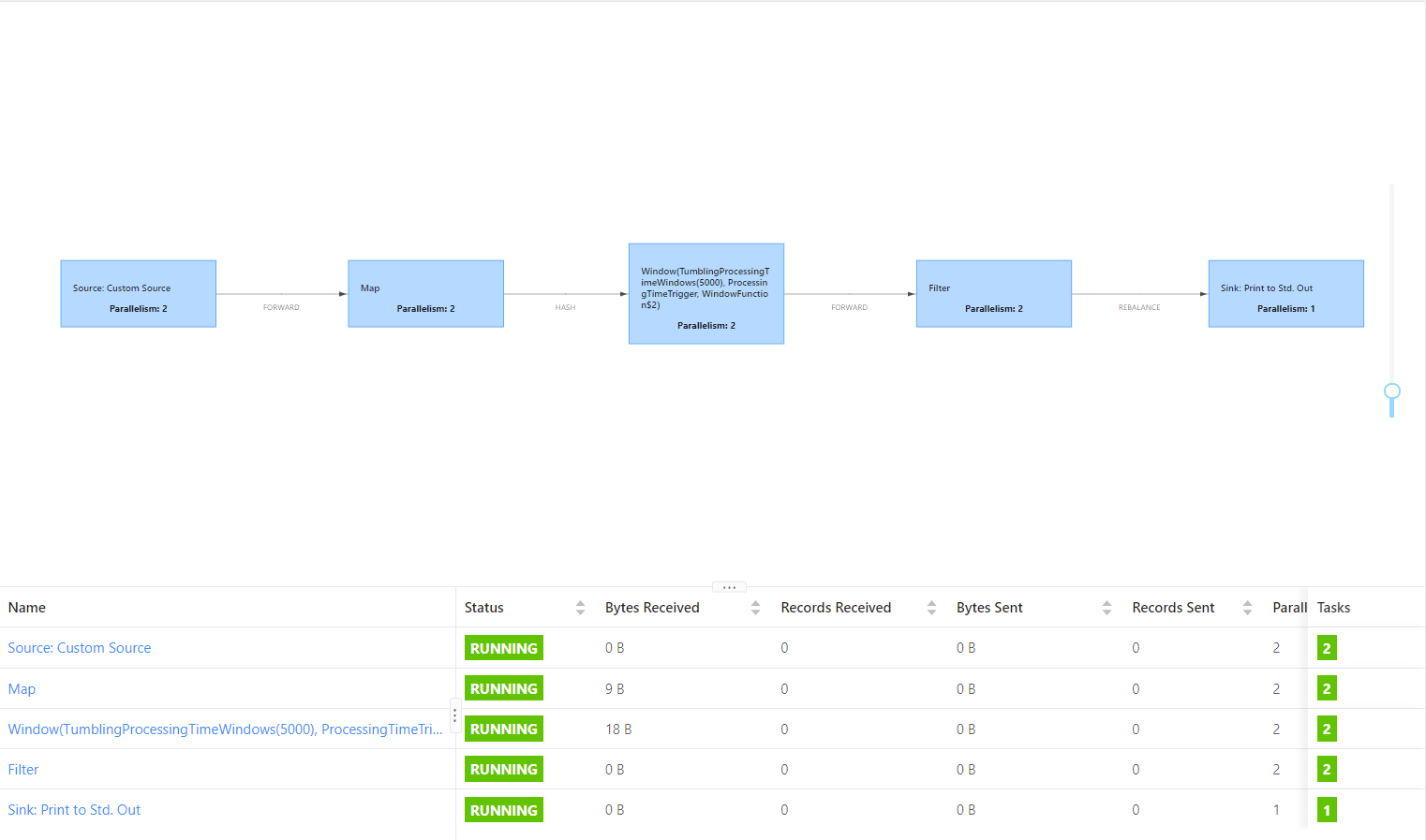
2. startNewChain
A new Operator chain is divided before the current operator, which can be divided separately in combination with the shared resource slot.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port",8082);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(2);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "59.111.211.35:9092,59.111.211.36:9092,59.111.211.37:9092");
properties.setProperty("auto.offset.reset", "earliest");
properties.setProperty("group.id", "g1");
properties.setProperty("enable.auto.commit", "true");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"mytest",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> source = env.addSource(kafkaConsumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = source.map(new RichMapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(" ");
return Tuple2.of(split[0], Integer.parseInt(split[1]));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> applyStream = mapStream.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple2<String, Integer>> out) throws Exception {
for (Tuple2<String, Integer> tuple2 : input) {
out.collect(tuple2);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> filterStream = applyStream.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> integerTuple2) throws Exception {
return integerTuple2.f0.startsWith("a");
}
}).startNewChain();
filterStream.print();
env.execute("");
}
Before opening:
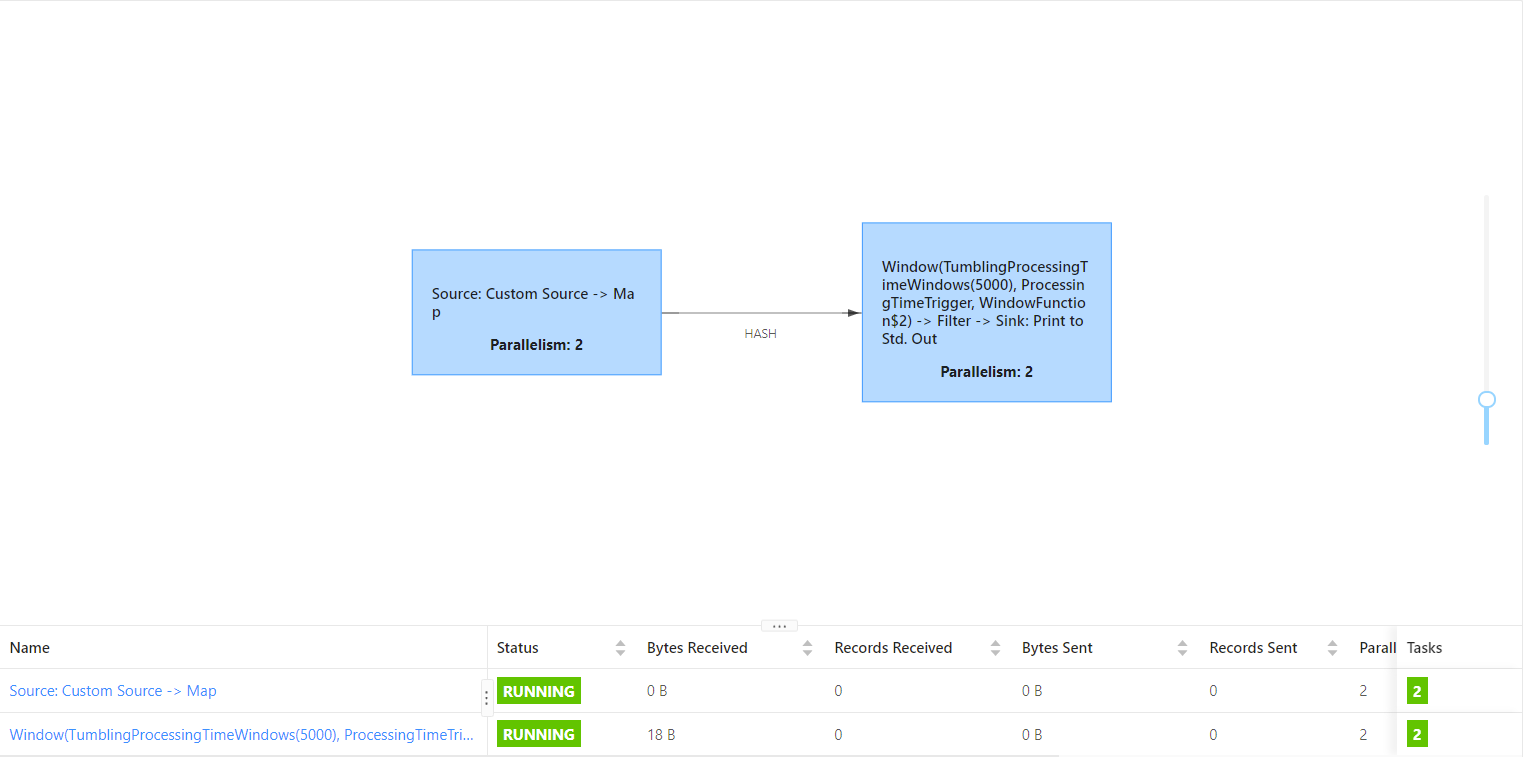
After opening:
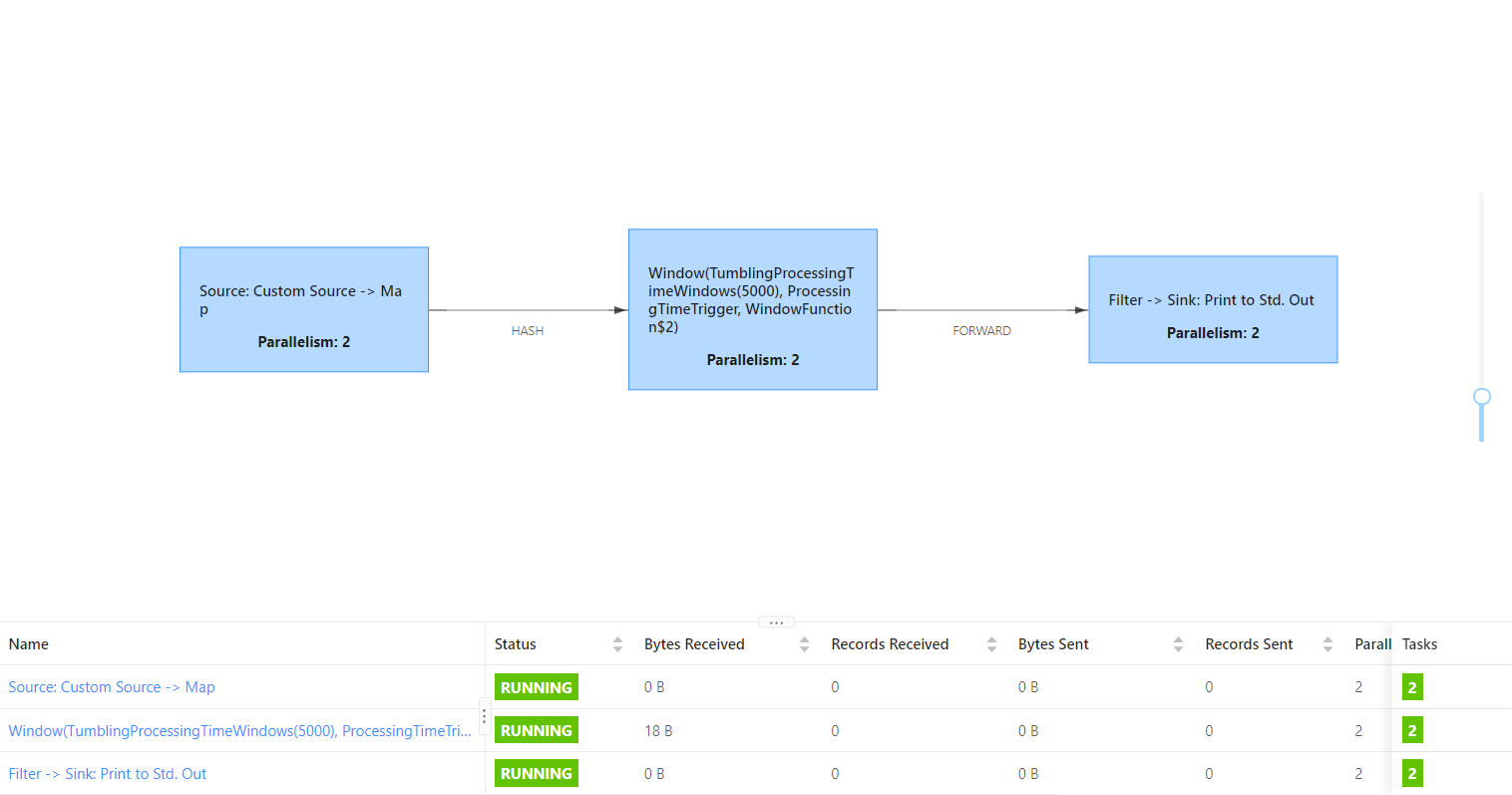
3. disableChaining
For an operator operation, disconnect the Operator chain before and after the operator to make the operator a separate Task.
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port",8082);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(2);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "59.111.211.35:9092,59.111.211.36:9092,59.111.211.37:9092");
properties.setProperty("auto.offset.reset", "earliest");
properties.setProperty("group.id", "g1");
properties.setProperty("enable.auto.commit", "true");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"mytest",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> source = env.addSource(kafkaConsumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = source.map(new RichMapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(" ");
return Tuple2.of(split[0], Integer.parseInt(split[1]));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> applyStream = mapStream.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple2<String, Integer>> out) throws Exception {
for (Tuple2<String, Integer> tuple2 : input) {
out.collect(tuple2);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> filterStream = applyStream.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> integerTuple2) throws Exception {
return integerTuple2.f0.startsWith("a");
}
}).disableChaining();
filterStream.print();
env.execute("");
}
Before opening:
After opening:
4. Shared resource slot
Configure the resource group of the operator. Flink will execute operators with the same resource group in the same slot, and assign operators of different resource groups to different slots. So as to realize slot isolation. The resource group will inherit from the input operator (proximity principle) if all input operations are in the same resource group. Flink's default resource group name is "default", and the operator is added to this resource group by explicitly calling slotSharingGroup("default").
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "59.111.211.35:9092,59.111.211.36:9092,59.111.211.37:9092");
properties.setProperty("auto.offset.reset", "earliest");
properties.setProperty("group.id", "g1");
properties.setProperty("enable.auto.commit", "true");
FlinkKafkaConsumer010<String> kafkaConsumer = new FlinkKafkaConsumer010<>(
"mytest",
new SimpleStringSchema(),
properties
);
DataStreamSource<String> source = env.addSource(kafkaConsumer).setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = source.map(new RichMapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] split = s.split(" ");
return Tuple2.of(split[0], Integer.parseInt(split[1]));
}
}).disableChaining().slotSharingGroup("map");
SingleOutputStreamOperator<Tuple2<String, Integer>> applyStream = mapStream.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple2<String, Integer>> out) throws Exception {
for (Tuple2<String, Integer> tuple2 : input) {
out.collect(tuple2);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> filterStream = applyStream.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> integerTuple2) throws Exception {
return integerTuple2.f0.startsWith("a");
}
});
filterStream.print();
env.execute("");
}
When the cluster starts, three slots are specified. You can see that the source occupies one slot, and the operators starting from the Map share the other two slots.