
1. General
Reprint: FlinkSQL metadata validation
Flink1. After 9, the CatalogManager was introduced to manage the Catalog and CatalogBaseTable. When executing DDL statements, the table information was encapsulated as CatalogBaseTable and stored in the CatalogManager. At the same time, the Schema interface of calculate is extended, so that calculate can read the table information in the Catalog manager in the Validate phase.
2.CatalogTable writing
By executing DDL statements, check how BlinkPlanner parses DDL statements and stores them in CatalogManamer. Focus on how to parse the calculated columns of protocol as procedure().
CREATE TABLE user_address (
userId BIGINT,
addressInfo VARCHAR,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = 'localhost:9092',
'topic' = 'tp02',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
)
Execute createCatalogTable to call the link.
org.apache.flink.table.api.internal.TableEnvironmentImpl#executeSql
org.apache.flink.table.planner.delegation.ParserImpl#parse
org.apache.flink.table.planner.operations.SqlToOperationConverter#convert
org.apache.flink.table.planner.operations.SqlCreateTableConverter#convertCreateTable
// Resolve CatalogTable from SqlCreateTable statement
org.apache.flink.table.planner.operations.SqlCreateTableConverter#createCatalogTable
Extract TableSchema, table partition, primary key, annotation and other information from SqlCreateTable to build CatalogTableImpl.
private CatalogTable createCatalogTable(SqlCreateTable sqlCreateTable) {
final TableSchema sourceTableSchema;
final List<String> sourcePartitionKeys;
final List<SqlTableLike.SqlTableLikeOption> likeOptions;
final Map<String, String> sourceProperties;
// Processing create table like
if (sqlCreateTable.getTableLike().isPresent()) {
SqlTableLike sqlTableLike = sqlCreateTable.getTableLike().get();
CatalogTable table = lookupLikeSourceTable(sqlTableLike);
sourceTableSchema = table.getSchema();
sourcePartitionKeys = table.getPartitionKeys();
likeOptions = sqlTableLike.getOptions();
sourceProperties = table.getProperties();
} else {
sourceTableSchema = TableSchema.builder().build();
sourcePartitionKeys = Collections.emptyList();
likeOptions = Collections.emptyList();
sourceProperties = Collections.emptyMap();
}
// Handle options in SqlTableLike, INCLUDING ALL, OVERWRITING OPTIONS, EXCLUDING PARTITIONS, etc
Map<SqlTableLike.FeatureOption, SqlTableLike.MergingStrategy> mergingStrategies =
mergeTableLikeUtil.computeMergingStrategies(likeOptions);
Map<String, String> mergedOptions = mergeOptions(sqlCreateTable, sourceProperties, mergingStrategies);
// Extract primary key
Optional<SqlTableConstraint> primaryKey = sqlCreateTable.getFullConstraints()
.stream()
.filter(SqlTableConstraint::isPrimaryKey)
.findAny();
// Get TableSchema
TableSchema mergedSchema = mergeTableLikeUtil.mergeTables(
mergingStrategies,
sourceTableSchema, // Non create table like statement, sourceTableSchema is null.
sqlCreateTable.getColumnList().getList(),
sqlCreateTable.getWatermark().map(Collections::singletonList).orElseGet(Collections::emptyList),
primaryKey.orElse(null)
);
// Table partition
List<String> partitionKeys = mergePartitions(
sourcePartitionKeys,
sqlCreateTable.getPartitionKeyList(),
mergingStrategies
);
verifyPartitioningColumnsExist(mergedSchema, partitionKeys);
// notes
String tableComment = sqlCreateTable.getComment()
.map(comment -> comment.getNlsString().getValue())
.orElse(null);
return new CatalogTableImpl(mergedSchema,
partitionKeys,
mergedOptions,
tableComment);
}
When extracting the TableSchema, the column type in calculate will be converted to the data type inside Flink. If a calculated column is included, such as procime(), the expression will be validated. The FlinkSqlOperatorTable class contains all the built-in functions of FlinkSQL.
/**
* Function used to access a processing time attribute.
*/
public static final SqlFunction PROCTIME =
new CalciteSqlFunction(
"PROCTIME",
SqlKind.OTHER_FUNCTION,
PROCTIME_TYPE_INFERENCE,
null,
OperandTypes.NILADIC,
SqlFunctionCategory.TIMEDATE,
false
);
TableColumn generation process:
- Type convert non computed columns and store them in the physicalFieldNamesToTypes collection.
- Verify the existence of the calculated column generated by the expression, and return the RelDataType corresponding to the function.
- Convert the RelDataType of the field to LogicalType, then to DataType, and build it into TableColumn. You need to check the differences between different types of systems.
private void appendDerivedColumns(
Map<FeatureOption, MergingStrategy> mergingStrategies,
List<SqlNode> derivedColumns) {
// Data conversion is performed for non calculated columns and stored in physicalFieldNamesToTypes
collectPhysicalFieldsTypes(derivedColumns);
for (SqlNode derivedColumn : derivedColumns) {
final SqlTableColumn tableColumn = (SqlTableColumn) derivedColumn;
final TableColumn column;
if (tableColumn.isGenerated()) {
String fieldName = tableColumn.getName().toString();
//Verify whether the expression, such as the procime() function, is registered in FlinkSqlOperatorTable
SqlNode validatedExpr = sqlValidator.validateParameterizedExpression(
tableColumn.getExpr().get(),
physicalFieldNamesToTypes);
// Verification return type: the RelDataType corresponding to procime() is the TimeIndicatorRelDataType of Flink extension
final RelDataType validatedType = sqlValidator.getValidatedNodeType(validatedExpr);
column = TableColumn.of(
fieldName,
// RelDataType--->LogicalType--->DataType
fromLogicalToDataType(toLogicalType(validatedType)),
escapeExpressions.apply(validatedExpr));
computedFieldNamesToTypes.put(fieldName, validatedType);
} else {
// Non computed columns are converted to data types inside Flink
String name = tableColumn.getName().getSimple();
// RelDataType --> LogicalType --> DataType
LogicalType logicalType = FlinkTypeFactory.toLogicalType(physicalFieldNamesToTypes.get(name));
column = TableColumn.of(name, TypeConversions.fromLogicalToDataType(logicalType));
}
columns.put(column.getName(), column);
}
}
To calculate the procime information of the column, you need to see the binding type when defining the procime function.
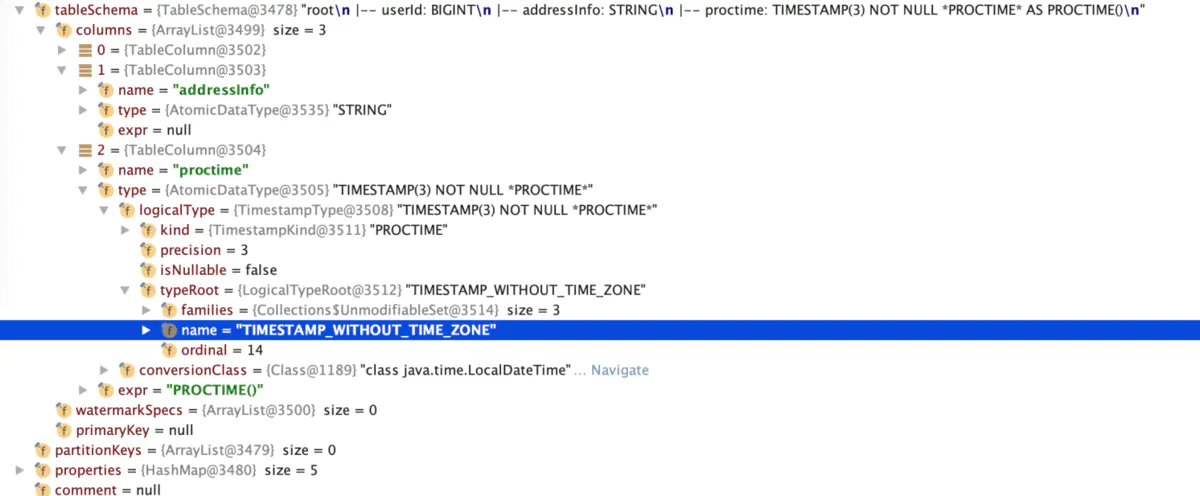
3.Validate reading metadata
FlinkSchema includes three subclasses: CatalogManagerCalciteSchema, CatalogCalciteSchema and DatabaseCalciteSchema. When calculate validates, call the rewritten getSubSchema method to obtain the Catalog and Database information in turn, and finally obtain the corresponding Table information from the catalogManager.
By creating a custom Schema, view calculate to obtain the Schema information of the table. test case
// Currently, Scheam contains two tables of USERS and JOBS,
public class CatalogManagerCalciteSchema implements Schema {
static Map<String, Table> TABLES = Maps.newHashMap();
static {
TABLES.put("USERS", new AbstractTable() { //note: add a table
@Override
public RelDataType getRowType(final RelDataTypeFactory typeFactory) {
RelDataTypeFactory.Builder builder = typeFactory.builder();
builder.add("ID", new BasicSqlType(new RelDataTypeSystemImpl() {
}, SqlTypeName.INTEGER));
builder.add("NAME", new BasicSqlType(new RelDataTypeSystemImpl() {
}, SqlTypeName.CHAR));
builder.add("AGE", new BasicSqlType(new RelDataTypeSystemImpl() {
}, SqlTypeName.INTEGER));
return builder.build();
}
});
TABLES.put("JOBS", new AbstractTable() {
@Override
public RelDataType getRowType(final RelDataTypeFactory typeFactory) {
RelDataTypeFactory.Builder builder = typeFactory.builder();
builder.add("ID", new BasicSqlType(new RelDataTypeSystemImpl() {
}, SqlTypeName.INTEGER));
builder.add("NAME", new BasicSqlType(new RelDataTypeSystemImpl() {
}, SqlTypeName.CHAR));
builder.add("COMPANY", new BasicSqlType(new RelDataTypeSystemImpl() {
}, SqlTypeName.CHAR));
return builder.build();
}
});
}
@Override
public Table getTable(String name) {
return TABLES.get(name);
}
@Override
public Set<String> getTableNames() {
return null;
}
@Override
public RelProtoDataType getType(String name) {
return null;
}
@Override
public Set<String> getTypeNames() {
return null;
}
@Override
public Collection<Function> getFunctions(String name) {
return null;
}
@Override
public Set<String> getFunctionNames() {
return Collections.emptySet();
}
@Override
public Schema getSubSchema(String name) {
return null;
}
@Override
public Set<String> getSubSchemaNames() {
return null;
}
@Override
public Expression getExpression(SchemaPlus parentSchema, String name) {
return null;
}
@Override
public boolean isMutable() {
return false;
}
@Override
public Schema snapshot(SchemaVersion version) {
return this;
}
}
case
public static void main(String[] args) throws SqlParseException {
// CatalogManagerCalciteSchema is customized and not internal to Flink
CalciteSchema rootSchema =
CalciteSchemaBuilder.asRootSchema(new CatalogManagerCalciteSchema());
SchemaPlus schemaPlus = rootSchema.plus();
SqlTypeFactoryImpl factory = new SqlTypeFactoryImpl(RelDataTypeSystem.DEFAULT);
// Create a CalciteCatalogReader to read metadata from SimpleCalciteSchema during rel phase
CalciteCatalogReader calciteCatalogReader = new CalciteCatalogReader(
CalciteSchema.from(schemaPlus),
CalciteSchema.from(schemaPlus).path(null),
factory,
new CalciteConnectionConfigImpl(new Properties()));
String sql = "select u.id as user_id, u.name as user_name, j.company as user_company, u.age as user_age \n"
+ "from users u join jobs j on u.name=j.name";
SqlParser parser = SqlParser.create(sql, SqlParser.Config.DEFAULT);
SqlNode sqlNode = parser.parseStmt();
SqlValidator
validator = SqlValidatorUtil.newValidator(SqlStdOperatorTable.instance(), calciteCatalogReader, factory,
SqlConformanceEnum.DEFAULT);
SqlNode validateSqlNode = validator.validate(sqlNode);
System.out.println(validateSqlNode);
}
Calculate accesses the call link of CatalogManagerCalciteSchema through Validate. When getSubSchema is null, it means there is no Schema information of children, and then the Table information is read from the current Schema.
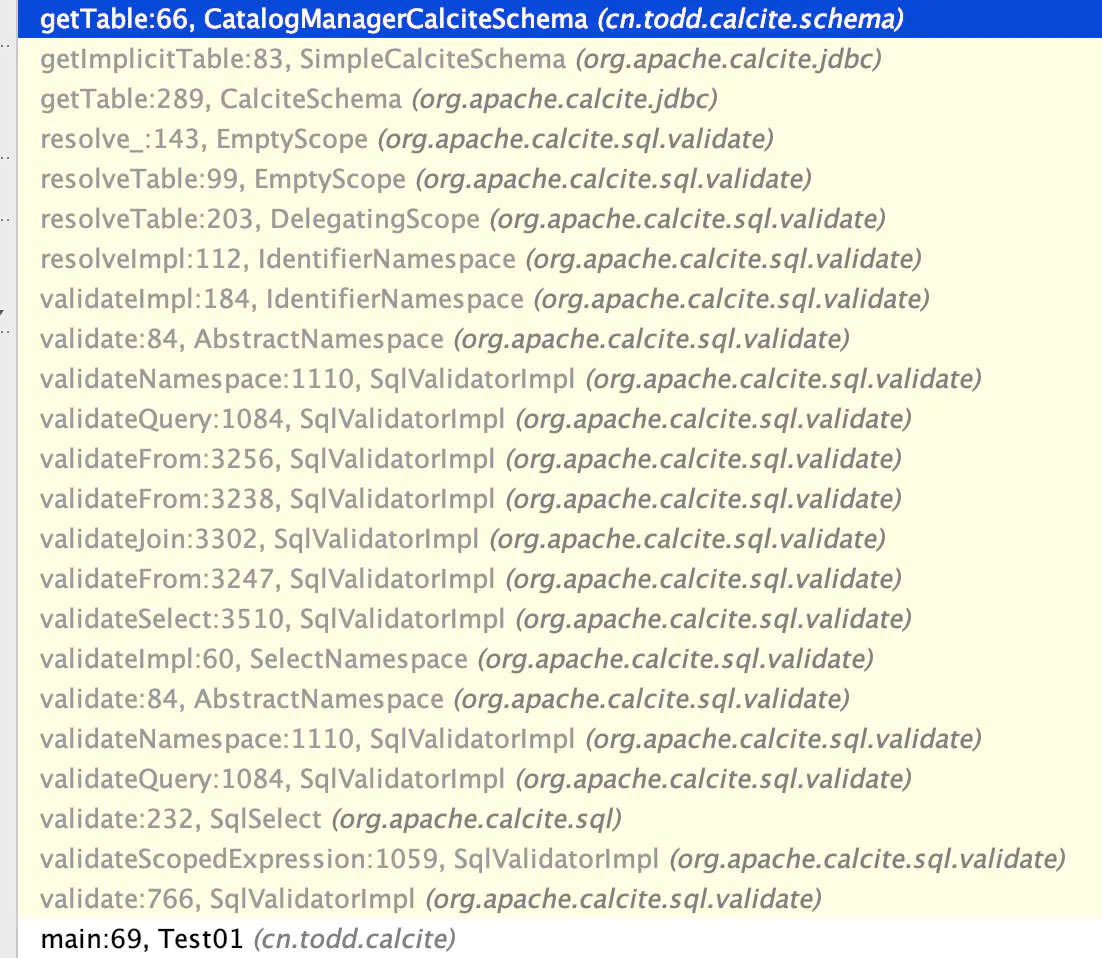
Flink defines a three-level Schema and reads the Catalog, Database and Table from the CatalogManager by calling getSubSchema. For specific calls, please refer to: org apache. calcite. sql. validate. EmptyScope#resolve_.
CatalogManagerCalciteSchema#getSubSchemaNames: obtain the CatalogSchema from the catalogManager through the catalog information in the table name.
@Override
public Schema getSubSchema(String name) {
if (catalogManager.schemaExists(name)) {
return new CatalogCalciteSchema(name, catalogManager, isStreamingMode);
} else {
return null;
}
}
CatalogCalciteSchema#getSubSchemaNames: obtain the DatabaseSchema from the catalogManager through the database information in the table name.
/**
* Look up a sub-schema (database) by the given sub-schema name.
*
* @param schemaName name of sub-schema to look up
* @return the sub-schema with a given database name, or null
*/
@Override
public Schema getSubSchema(String schemaName) {
if (catalogManager.schemaExists(catalogName, schemaName)) {
return new DatabaseCalciteSchema(schemaName, catalogName, catalogManager, isStreamingMode);
} else {
return null;
}
}
If there is no subschema in the DatabaseSchema, get the Table information from the current Schema.
public Table getTable(String tableName) {
ObjectIdentifier identifier = ObjectIdentifier.of(catalogName, databaseName, tableName);
return catalogManager.getTable(identifier)
.map(result -> {
CatalogBaseTable table = result.getTable();
FlinkStatistic statistic = getStatistic(result.isTemporary(), table, identifier);
return new CatalogSchemaTable(
identifier,
result,
statistic,
catalogManager.getCatalog(catalogName).orElseThrow(IllegalStateException::new),
isStreamingMode);
})
.orElse(null);
}
4. ProTime field verification
When reading the Table schema in validate, flysql will convert the rowtime and procime types of the calculation columns to the RelDataType types recognized by invoke. First, list the codes for calculating column type conversion.
## CatalogManager
public Optional<TableLookupResult> getTable(ObjectIdentifier objectIdentifier) {
CatalogBaseTable temporaryTable = temporaryTables.get(objectIdentifier);
if (temporaryTable != null) {
TableSchema resolvedSchema = resolveTableSchema(temporaryTable);
return Optional.of(TableLookupResult.temporary(temporaryTable, resolvedSchema));
} else {
return getPermanentTable(objectIdentifier);
}
}
## org.apache.flink.table.api.internal.CatalogTableSchemaResolver#resolve
/**
* Resolve the computed column's type for the given schema.
*
* @param tableSchema Table schema to derive table field names and data types
* @return the resolved TableSchema
*/
public TableSchema resolve(TableSchema tableSchema) {
final String rowtime;
String[] fieldNames = tableSchema.getFieldNames();
DataType[] fieldTypes = tableSchema.getFieldDataTypes();
TableSchema.Builder builder = TableSchema.builder();
for (int i = 0; i < tableSchema.getFieldCount(); ++i) {
TableColumn tableColumn = tableSchema.getTableColumns().get(i);
DataType fieldType = fieldTypes[i];
if (tableColumn.isGenerated()) {
// Extract the corresponding DataType by obtaining the expression of the calculated column
fieldType = resolveExpressionDataType(tableColumn.getExpr().get(), tableSchema);
if (isProctime(fieldType)) {
if (fieldNames[i].equals(rowtime)) {
throw new TableException("Watermark can not be defined for a processing time attribute column.");
}
}
}
......
if (tableColumn.isGenerated()) {
builder.field(fieldNames[i], fieldType, tableColumn.getExpr().get());
} else {
builder.field(fieldNames[i], fieldType);
}
}
tableSchema.getWatermarkSpecs().forEach(builder::watermark);
tableSchema.getPrimaryKey().ifPresent(
pk -> builder.primaryKey(pk.getName(), pk.getColumns().toArray(new String[0])));
return builder.build();
}
# org.apache.flink.table.api.internal.CatalogTableSchemaResolver#resolveExpressionDataType
private DataType resolveExpressionDataType(String expr, TableSchema tableSchema) {
ResolvedExpression resolvedExpr = parser.parseSqlExpression(expr, tableSchema);
if (resolvedExpr == null) {
throw new ValidationException("Could not resolve field expression: " + expr);
}
return resolvedExpr.getOutputDataType();
}
# org.apache.flink.table.planner.delegation.ParserImpl#parseSqlExpression
public ResolvedExpression parseSqlExpression(String sqlExpression, TableSchema inputSchema) {
SqlExprToRexConverter sqlExprToRexConverter = sqlExprToRexConverterCreator.apply(inputSchema);
RexNode rexNode = sqlExprToRexConverter.convertToRexNode(sqlExpression);
// [[RelDataType]] ----> [[LogicalType]]
LogicalType logicalType = FlinkTypeFactory.toLogicalType(rexNode.getType());
return new RexNodeExpression(rexNode, TypeConversions.fromLogicalToDataType(logicalType));
}
# org.apache.flink.table.planner.calcite.SqlExprToRexConverterImpl#convertToRexNodes
public RexNode[] convertToRexNodes(String[] exprs) {
// Obtain RexNode by constructing a temporary table query
String query = String.format(QUERY_FORMAT, String.join(",", exprs));
SqlNode parsed = planner.parser().parse(query);
SqlNode validated = planner.validate(parsed);
// Convert to relNode
RelNode rel = planner.rel(validated).rel;
// The plan should in the following tree
// LogicalProject
// +- TableScan
if (rel instanceof LogicalProject
&& rel.getInput(0) != null
&& rel.getInput(0) instanceof TableScan) {
return ((LogicalProject) rel).getProjects().toArray(new RexNode[0]);
} else {
throw new IllegalStateException("The root RelNode should be LogicalProject, but is " + rel.toString());
}
}
Procime() type extraction process:
- If the calculation column is included, the TableSchema in the table creation statement will be registered as a table temp_table.
- According to the expression of the calculated column in the table, such as procime(), build a temporary query statement select procime() from temp_ Table, procime() is Flink's built-in function.
- validate the query statement, convert the RelNode, and extract the row expression RexNode from the RelNode.
- Extract the RelDataType corresponding to procime() from RexNode and finally convert it to DataType.
[FLINK-18378] previous processing flow of calculation column. It is distinguished separately according to procime and rowtime.
Question: in the DDL statement, the procime has been converted to DataType. In the validate Table schema, you can get the fieldType directly. Why do you need to do a parsing.
for (int i = 0; i < tableSchema.getFieldCount(); ++i) {
TableColumn tableColumn = tableSchema.getTableColumns().get(i);
DataType fieldType = fieldTypes[i];
if (tableColumn.isGenerated() && isProctimeType(tableColumn.getExpr().get(), tableSchema)) {
if (fieldNames[i].equals(rowtime)) {
throw new TableException("Watermark can not be defined for a processing time attribute column.");
}
TimestampType originalType = (TimestampType) fieldType.getLogicalType();
LogicalType proctimeType = new TimestampType(
originalType.isNullable(),
TimestampKind.PROCTIME,
originalType.getPrecision());
fieldType = TypeConversions.fromLogicalToDataType(proctimeType);
} else if (isStreamingMode && fieldNames[i].equals(rowtime)) {
TimestampType originalType = (TimestampType) fieldType.getLogicalType();
LogicalType rowtimeType = new TimestampType(
originalType.isNullable(),
TimestampKind.ROWTIME,
originalType.getPrecision());
fieldType = TypeConversions.fromLogicalToDataType(rowtimeType);
}
if (tableColumn.isGenerated()) {
builder.field(fieldNames[i], fieldType, tableColumn.getExpr().get());
} else {
builder.field(fieldNames[i], fieldType);
}
}