
Thank you for your little love (attention + praise + look again). Your affirmation of the blogger will urge the blogger to continuously output more high-quality practical content!!!
1. Preface - structure of this paper

Big data sheep said
Using data to improve the probability of good things~
32 original content
official account
This article mainly introduces the relationship between flex SQL and invoke. The parsing of flink sql mainly depends on call.
Through this article, bloggers can help you understand how flink sql relies on call in parsing, as well as the process of flink sql parsing and sql parser. I hope it will help you.
This article is introduced in the following sections. Those interested in a chapter can be directly divided into the corresponding chapter.
- Background - an execution process of flink sql
-
Use your imagination
-
Look at the implementation of flink
- Introduction - the role of calcite
-
What is calcite?
-
Why does flink sql choose call?
- Case - calite's ability and case
-
Call first
-
Relational algebra
-
Basic model of calcite
-
Process flow of invoke (take flink sql as an example)
-
How can calcite be so universal?
- Principle analysis - calcite shows its skill in flink sql
-
FlinkSqlParserImpl
-
Generation of FlinkSqlParserImpl
- Summary and Prospect
2. Background - an execution process of flink sql
This section first gives you a general description of the execution process of a flick SQL. It doesn't matter if you don't understand the details. You mainly understand the whole process first. After you have a global perspective, you will detail the details later.
Before introducing the execution process of a flink sql, let's take a look at the execution process of the flink datastream task, which is very helpful to understand the execution process of a flink sql.
-
Datastream: various UDFs to be provided in the flink datastream api when datastream is used (as like as two peas, flatmap, keyedprocessfunction, etc.), the custom processing logic is implemented in the specific logic of business execution, and then compiled in jvm, which is exactly the same process as a common main function. Because the code execution logic is written by itself, this part is relatively well understood. The logic of java is very simple.
-
sql: the java compiler cannot recognize and compile an sql for execution. How does an sql execute?
2.1. Use your imagination first
Let's think in reverse. If we want a flick SQL to execute in the jvm as we expect, what processes are needed.
-
Overall: referring to datastream, if the jvm can execute the class file compiled by datastream java code, it can add an sql parsing layer, which can parse the sql logic into various operators of datastream, and then compile and execute it.
-
sql parser: first, there must be an sql parser. First, you must be able to recognize sql syntax and convert sql syntax into AST and specific relational algebra.
-
Mapping from relational algebra to datastream operator: if sql logic is parsed into datastream, there needs to be a parsed mapping logic. sql is based on relational algebra. It can maintain the mapping relationship between each relational algebra in sql and the specific datastream interface. With these mapping relationships, we can map sql into an executable datastream code. For example, it can:
-
sql select xxx is parsed into a map similar to that in datastream
-
where xxx resolves to filter
-
group by resolves to keyby
-
sum (xx), count (xxx) can be resolved to aggregate function in datastream
-
etc...
-
Code generation: with sql AST and the mapping relationship between sql and datasretam operator, specific code generation is required. For example, to parse which fields in sql ast are used as where logic and which fields are used as group by, you need to generate the corresponding specific datastream code.
-
Run: after the above process, you can translate an sql into a datastream job and execute happy.
As shown in the figure below, the above logic is depicted:

12
So what are the similarities and differences between this and the actual implementation of flink?
flink generally does this. Although there are other processes in the middle of flink itself, and later versions are not based on datastream, the overall processing logic is consistent with the above.
Therefore, students who do not understand the overall process can first understand it according to the above process.
According to the blogger's brain hole, the mission of sql is: sql - > ast - > CodeGen (Java code) - > let's run, okay
2.2. Look at the implementation of flink
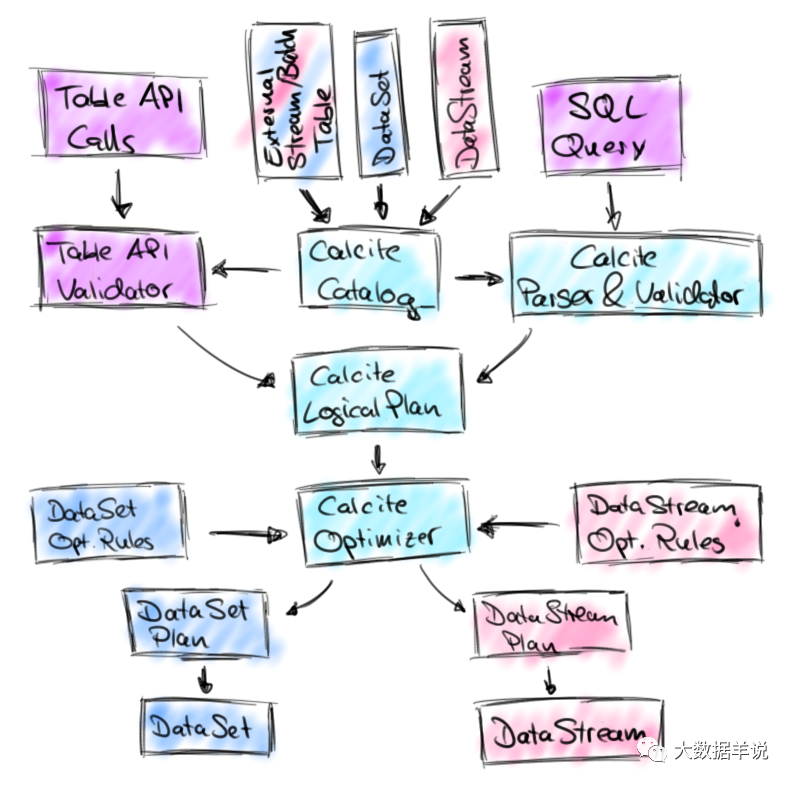
26
The hand drawing on the top may not be clear, but the picture below is more clear.
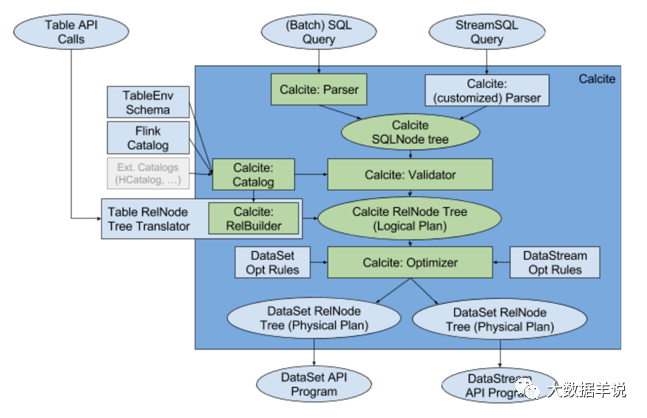
28
The process of running a standard flink sql is as follows:
Notes: at the beginning, the concept of SqlNode and RelNode may be vague. First understand the whole process, and then introduce these concepts in detail.
-
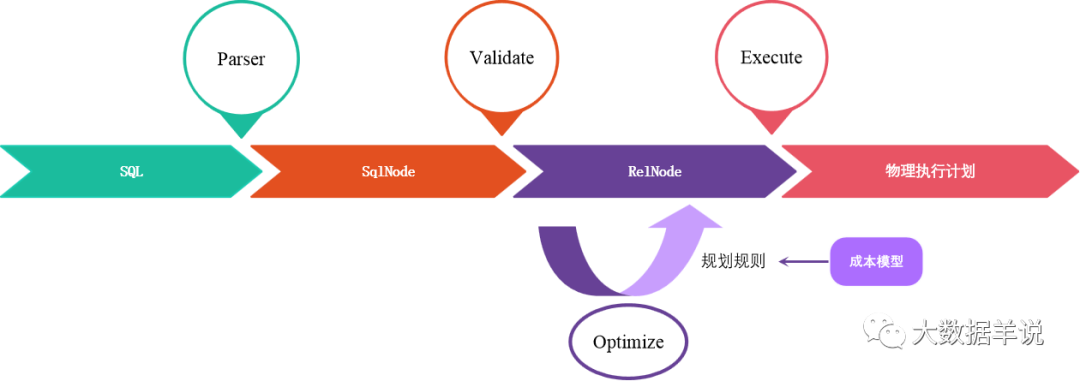
sql parsing stage: invoke parser parsing (sql - > AST, which is SqlNode Tree)
-
SqlNode verification phase: calibrate validator verification (SqlNode - > SqlNode, syntax, expression and table information)
-
Semantic analysis stage: SqlNode is converted to RelNode, which is Logical Plan (SqlNode - > RelNode)
-
Optimization stage: invoke optimizer optimization (relnode - > relnode, pruning, predicate push down, etc.)
-
Physical Plan generation stage: convert Logical Plan to Physical Plan (equivalent to converting RelNode to DataSet\DataStream API)
-
The subsequent operation logic is consistent with datastream
It can be found that the implementation of flink is consistent with the overall main framework of the blogger's brain hole. The extra parts are mainly SqlNode verification phase and optimization phase.
3. Introduction - the role of call in flink sql
After we have a general understanding of the running process of flink sql, let's take a look at what the call does in flink.
According to the above summary, calcite plays the role of sql parsing, validation and Optimization in flink sql.

30
Watching calcite do so many things, what is calcite and what is its positioning?
3.1. What is calcite?
Call is a dynamic data management framework, which can be used to build different parsing modules of database system, but it does not include data storage, data processing and other functions.
The goal of calcite is to provide a solution that can adapt to all demand scenarios. It hopes to provide a unified sql parsing engine for different computing platforms and data sources, but it only provides a query engine without really storing these data.

61
The following figure shows other components that currently use the calcite capability. You can also see the official website https://calcite.apache.org/docs/powered_by.html .
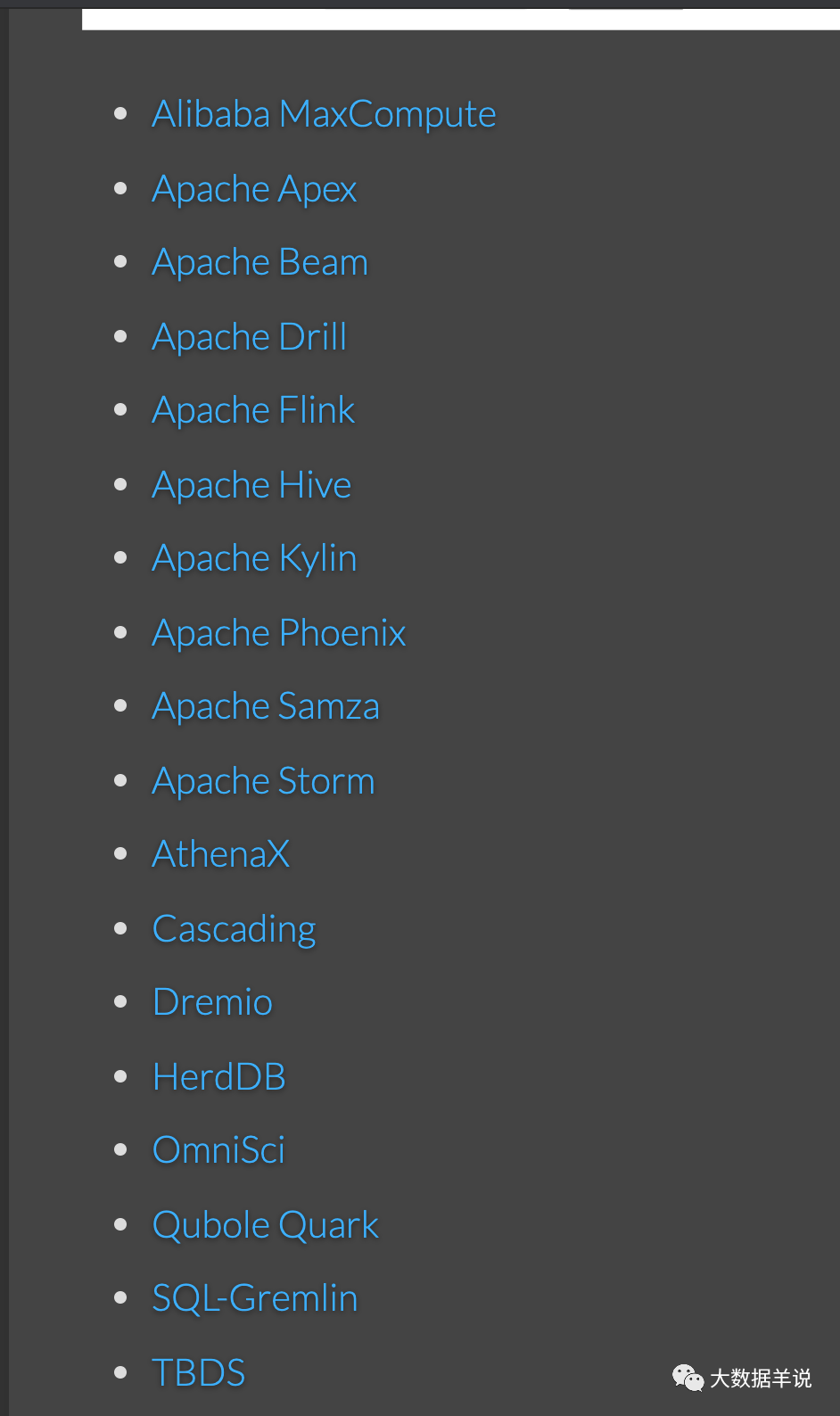
4
In short, it can be understood that calcite has these functions (of course, there are other awesome functions. If you are interested, you can check the official website).
-
Custom sql parser: for example, we have invented a new engine, and then we want to create a set of sql based interfaces on this engine, so we can use direct invoke instead of writing a special sql parser and execution and optimization engine, which are owned by calcite people.
-
sql parser (extensions sqlabstractparserimpl): parses various relational algebras of sql into specific asts, which can correspond to specific java model s. In the java world, objects are very important. With these objects (SqlSelect, SqlNode), you can do specific logical processing according to these objects. For example, as shown in the following figure, a simple select c,d from source where a = '6' sql can be obtained after the parse of call. You can see SqlSelect, SqlIdentifier, SqlIdentifier and SqlCharStringLiteral.
-
sql validator (extensions sqlvalidatorimpl): checks the correctness of SqlNode according to syntax, expression and table information.
-
sql optimizer: pruning, predicate push down and other optimizations
The overall composition of the above capabilities is shown in the figure below:
29
Actually use calculate to parse an sql, run and have a look.
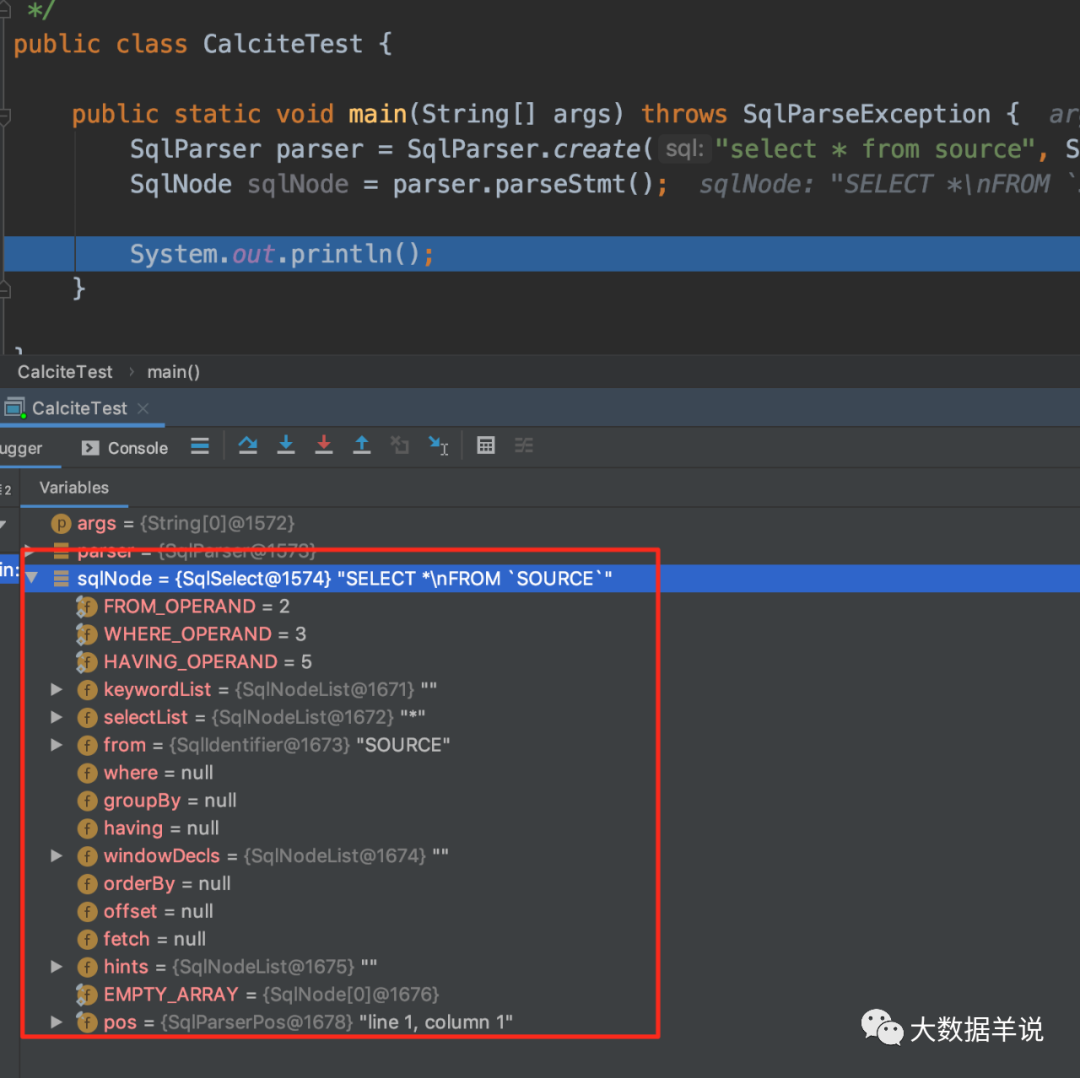
2
3.2. Why does Flink SQL choose invoke?
-
You don't have to build wheels again. Limited energy should be focused on valuable things.
-
Calcite has a solution for stream tables. Specific visible https://calcite.apache.org/docs/stream.html .
4. Case - calite's ability and case
4.1. Call first
The most important thing is to run first before understanding the principle, which will help us understand it step by step.
There is already a csv case on the official website. Interested can go directly to https://calcite.apache.org/docs/tutorial.html .
After running a csv demo, you need to understand sql, the pillar of calcite: relational algebra, before understanding calcite in detail.
4.2. Relational algebra
sql is a query language based on relational algebra. It is a good implementation scheme of relational algebra in engineering. In engineering, relational algebra is difficult to express, but sql is easy to understand. The relationship between relational algebra and sql is as follows.
-
An sql can be parsed into a combination of relational algebraic expressions. All operations in sql can be transformed into expressions of relational algebra.
-
The execution optimization of sql (the premise of all optimization is that the final execution results before and after optimization are the same, that is, equivalent exchange) is based on relational algebra.
4.2. 1. Common relational algebra
To summarize, what are the common relational Algebras:

50
4.2. 2. Relational algebraic equivalent transformation of SQL optimization pillar
The equivalent transformation of relational algebra is the basic theory of call optimizer.
Here are some examples of equivalent transformations.
1. Connection (⋈), Cartesian product( ×) Commutative law of
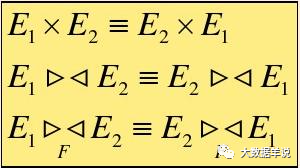
51
2. Connection (⋈), Cartesian product( ×) Combination law of
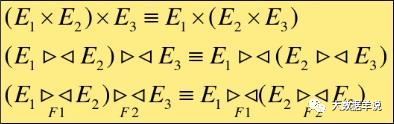
3. Projection( Π) Series connection law of

4. Selection( σ) Series connection law of
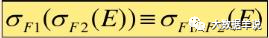
5. Selection( σ) And projection( Π) Exchange of
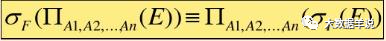
6. Selection( σ) Cartesian product( ×) Exchange of

7. Selection( σ) Exchange with Union (∪)
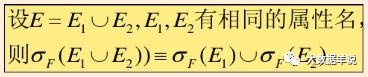
8. Selection( σ) Exchange with difference (-)

9. Projection( Π) Cartesian product( ×) Exchange of

10. Projection( Π) Exchange with Union (∪)

Then take a look at an actual sql case based on relational algebra Optimization:
There are three relations a (a1,a2,a3,...), B (b1,b2,b3,...), C (a1,b1,c1,c2,...)
There is a query request as follows:
SELECT A.a1 FROM A,B,C WHERE A.a1 = C.a1 AND B.b1 = C.b1 AND f(c1)
1. First, turn sql into a syntax tree of relational algebra.
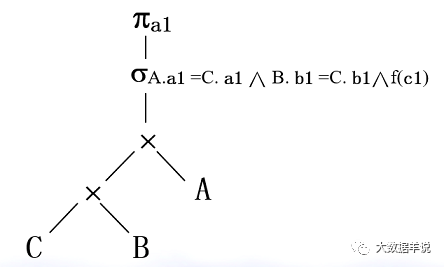
36
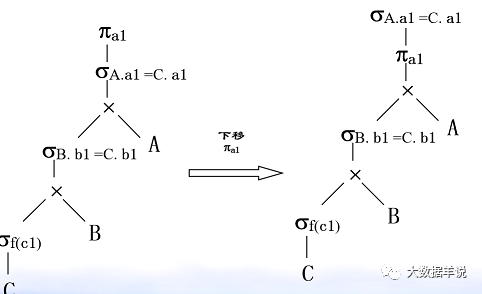
2. Optimization: selection( σ) Series connection law.
47

37
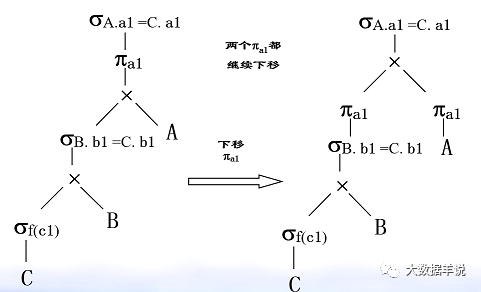
3. Optimization: selection( σ) Cartesian product( ×) Exchange of.
48
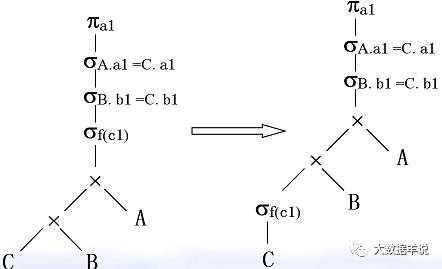
38
4. Optimization: projection (π) and Cartesian product( ×) Exchange of.
49
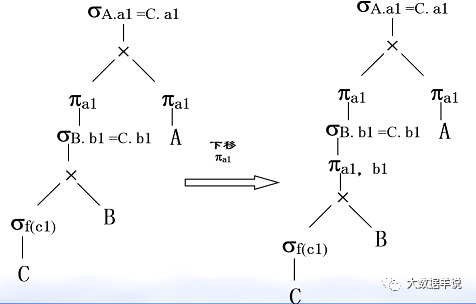
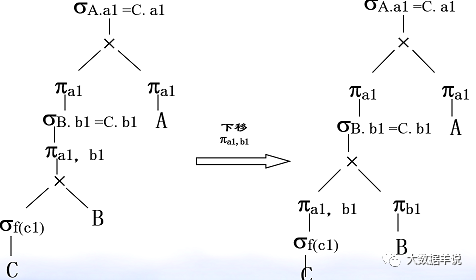


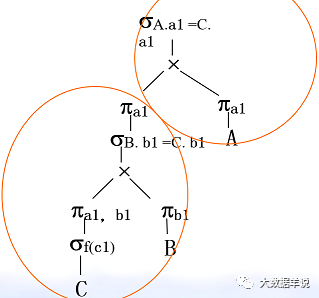
We have a general understanding of relational algebra.
In addition, for a deeper understanding of flex SQL, we also need to know what important model s are in the calcite code system.
4.3. Basic model of calcite
There are two most basic and important model s in calcite, which we need to know when we understand the flash SQL parsing process.
-
SqlNode: it is transformed from sql and can be understood as a model that visually expresses the sql hierarchy
-
RelNode: transformed from SqlNode, which can be understood as transforming SqlNode into relational algebra and expressing the hierarchical structure of relational algebra
As an example, the following flink sql, the parsed SqlNode and RelNode are shown in the following figure:
SELECT sum(part_pv) as pv, window_start FROM ( SELECT count(1) as part_pv, cast(tumble_start(rowtime, INTERVAL '60' SECOND) as bigint) * 1000 as window_start FROM source_db.source_table GROUP BY tumble(rowtime, INTERVAL '60' SECOND) , mod(id, 1024) ) GROUP BY window_start
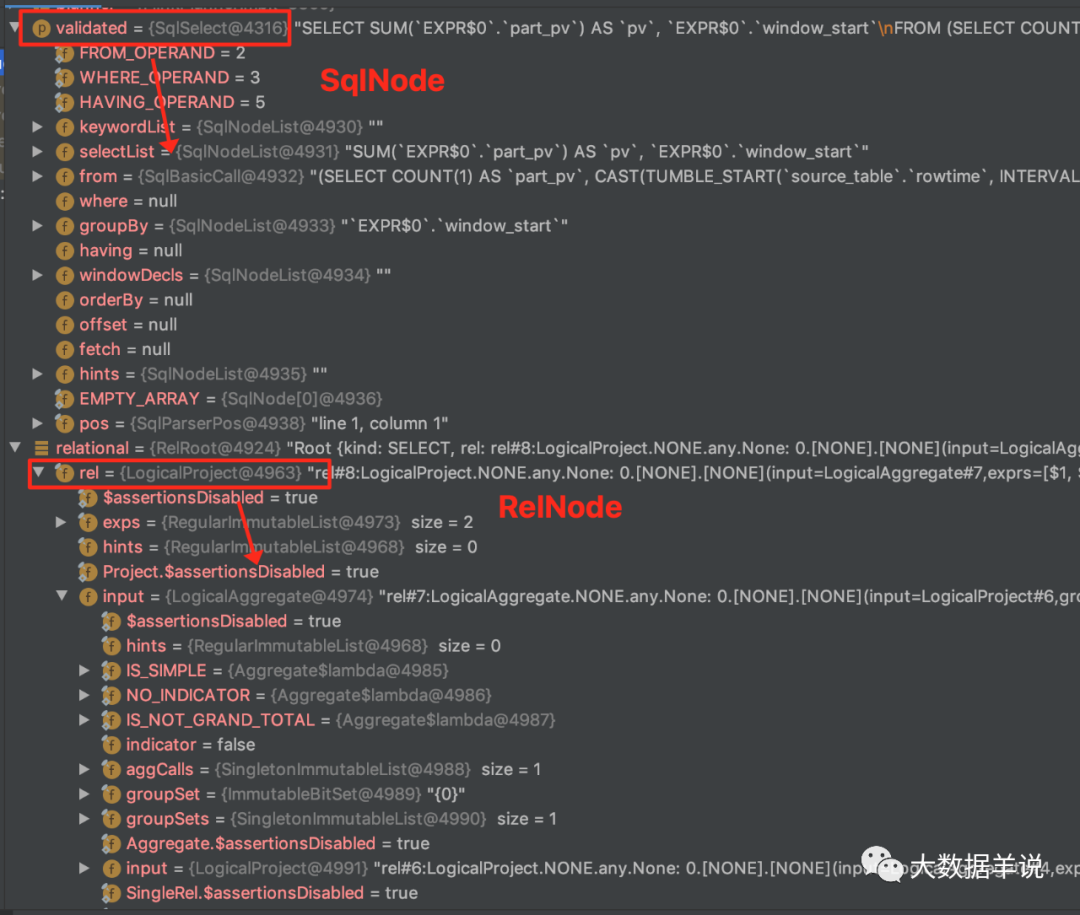
62
You can see that the SqlNode contains the hierarchical structure of sql, including selectList, from, where, group by, etc.
RelNode contains the hierarchical structure of relational algebra, and each layer has an input to undertake. Combined with the above optimization case, the tree structure is the same.

63
4.4. Process flow of invoke (take flink sql as an example)
29
As shown in the figure above, let's go through the processing flow here in combination with the model of calcite and the implementation of flink sql introduced in the previous section:
-
sql parsing phase (sql – > sqlnode)
-
SqlNode validation (SqlNode – > SqlNode)
-
Semantic analysis (SqlNode – > relnode)
-
Optimization phase (RelNode – > RelNode)
4.4.1.flink sql demo
SELECT sum(part_pv) as pv, window_start FROM ( SELECT count(1) as part_pv, cast(tumble_start(rowtime, INTERVAL '60' SECOND) as bigint) * 1000 as window_start FROM source_db.source_table GROUP BY tumble(rowtime, INTERVAL '60' SECOND) , mod(id, 1024) ) GROUP BY window_start
The first three steps of parsing and transformation are all performed by executing TableEnvironment#sqlQuery.
The last step of optimization is performed when the sink operation is executed, that is, in this example, tenv toRetractStream(result, Row.class).
The source official account is back to flink sql to know its reason why (six) flink sql date calcite gets.
4.4.2.sql parsing phase (sql – > sqlnode)
In the sql parsing phase, Sql Parser is used to parse sql into SqlNode. This step is performed after executing TableEnvironment#sqlQuery.
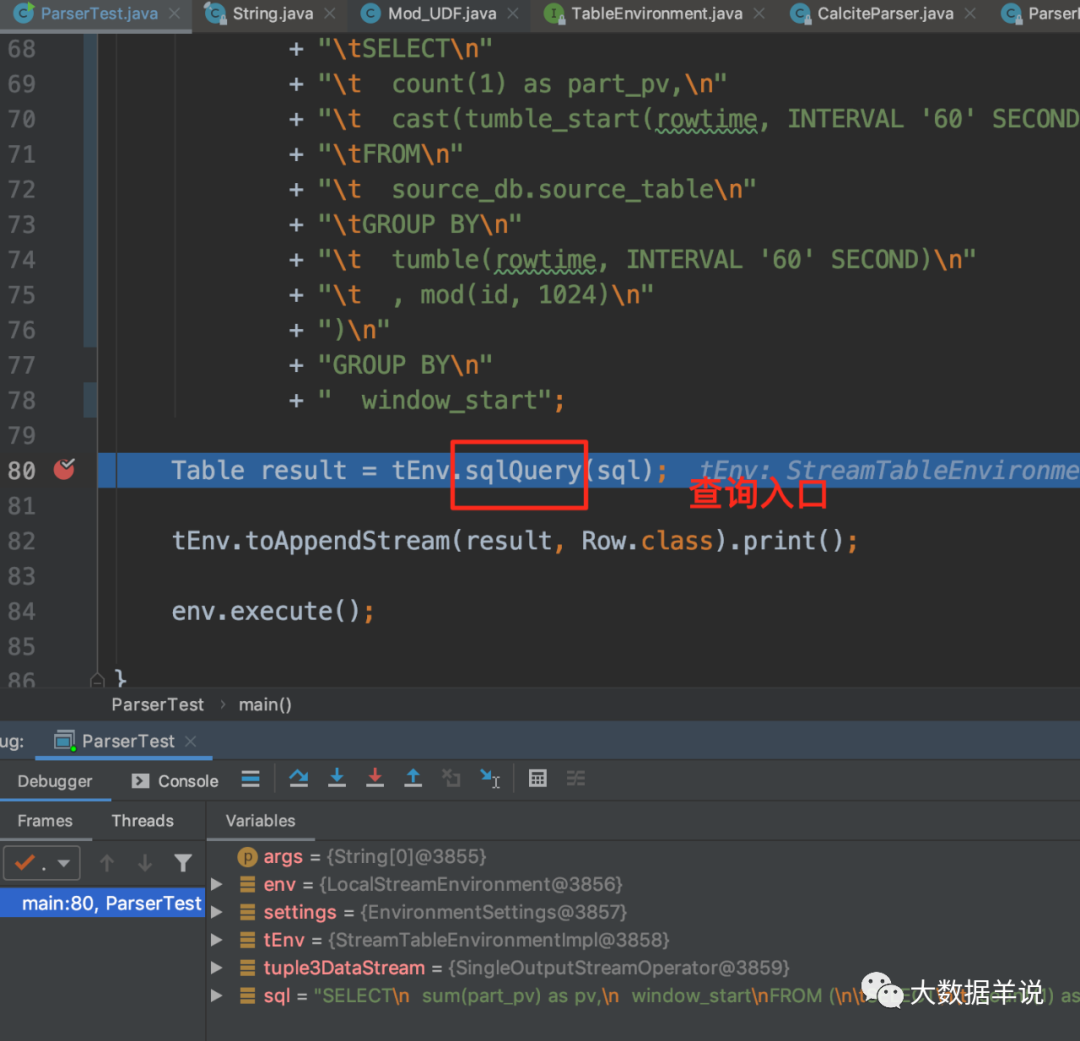
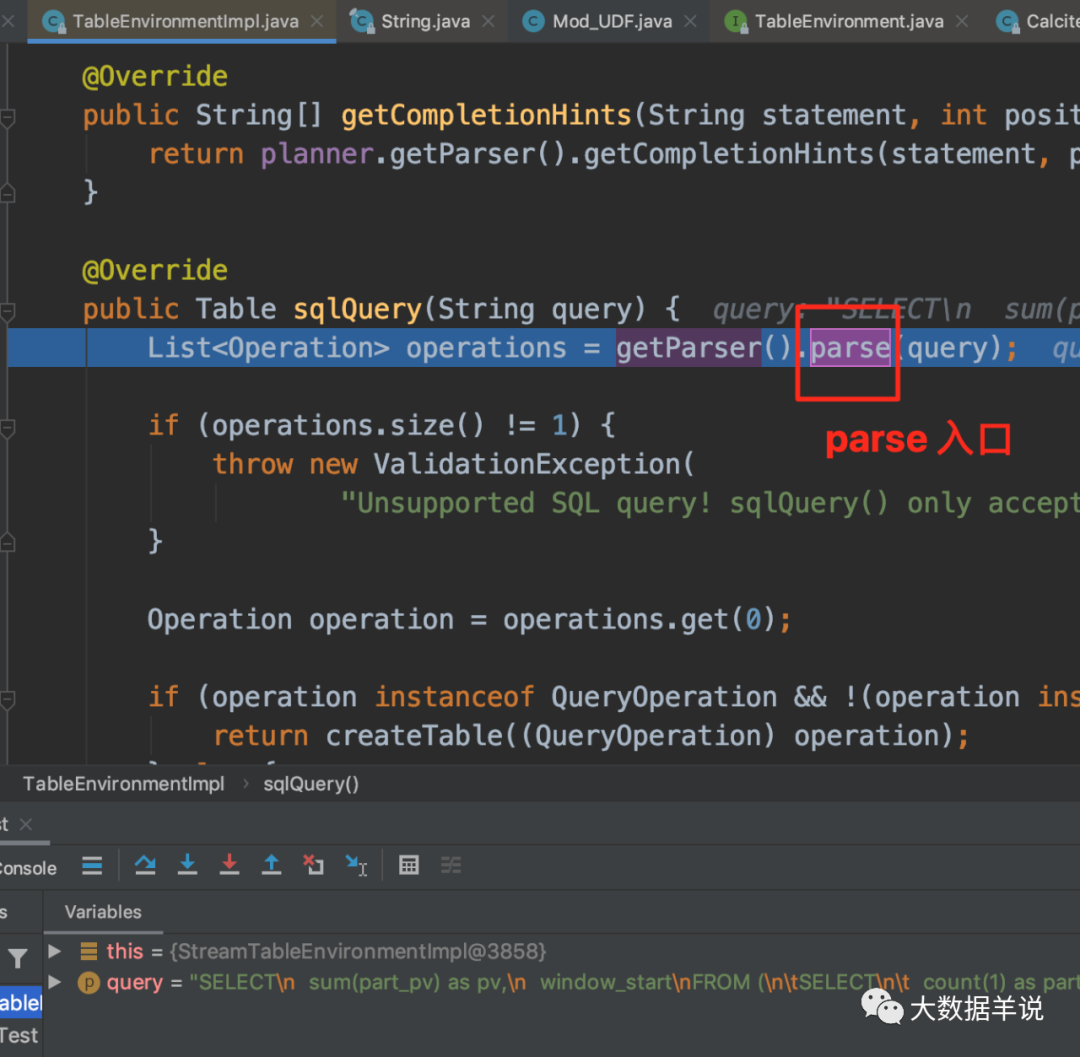
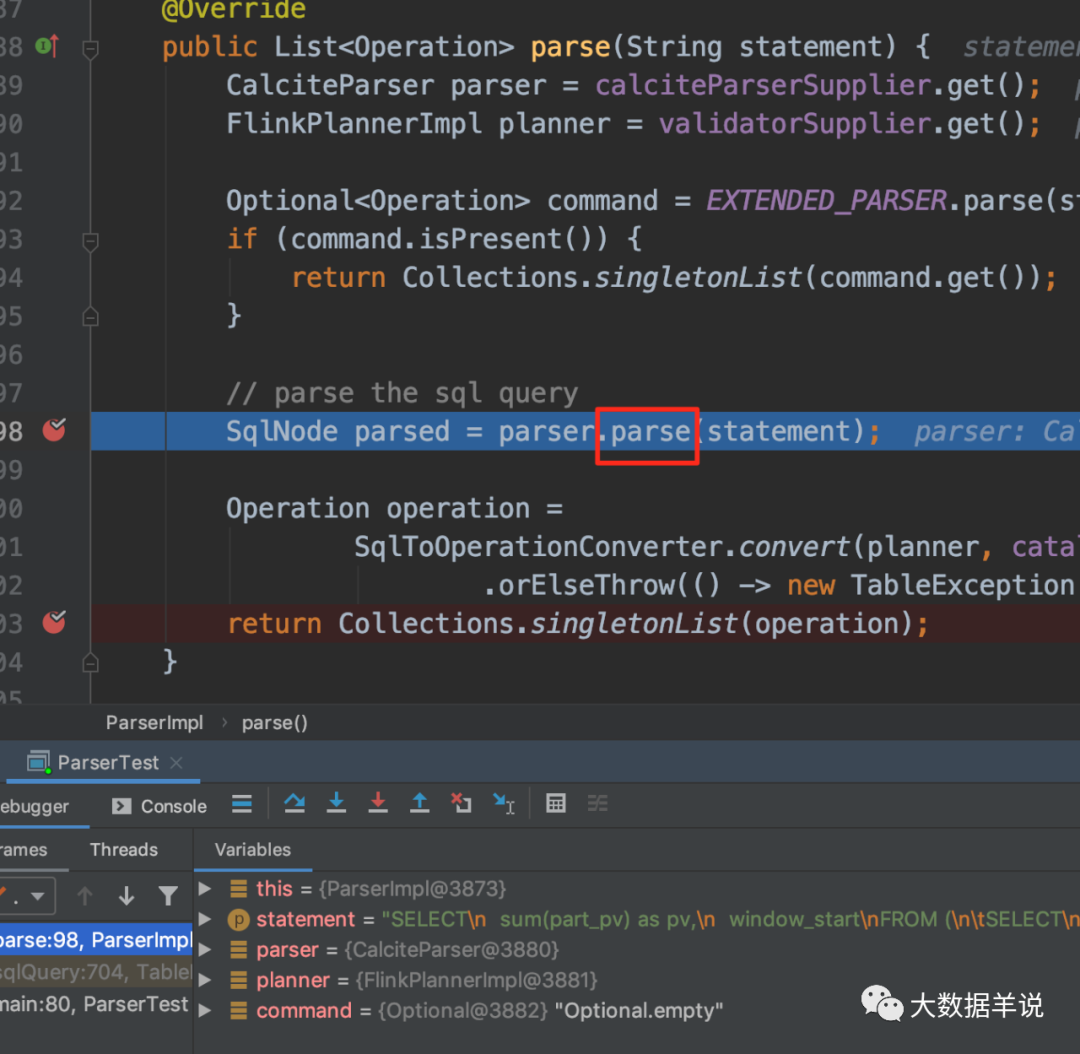
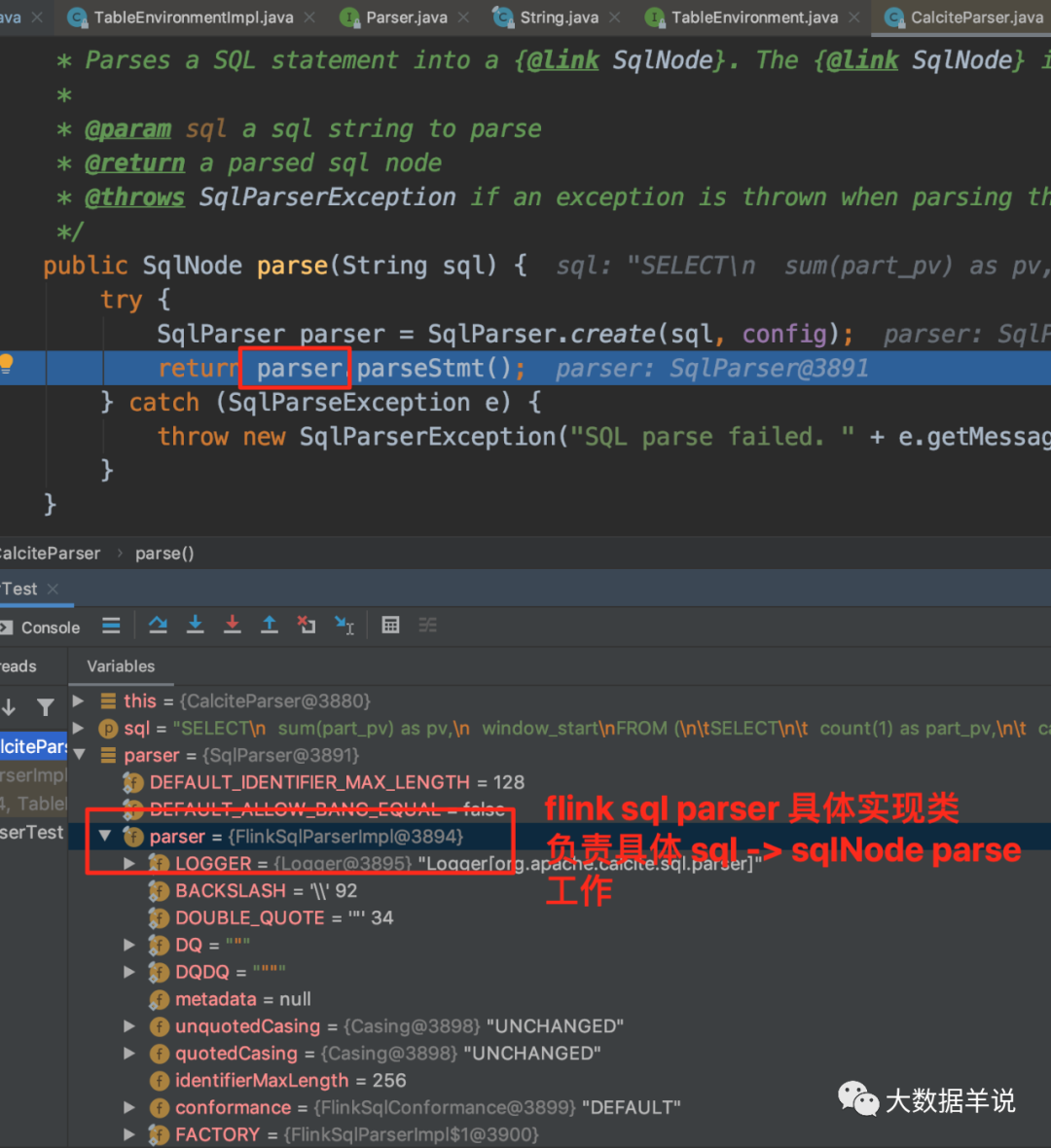
You can see from the above figure that the specific implementation class of FlinkSqlParserImpl is flinksql.
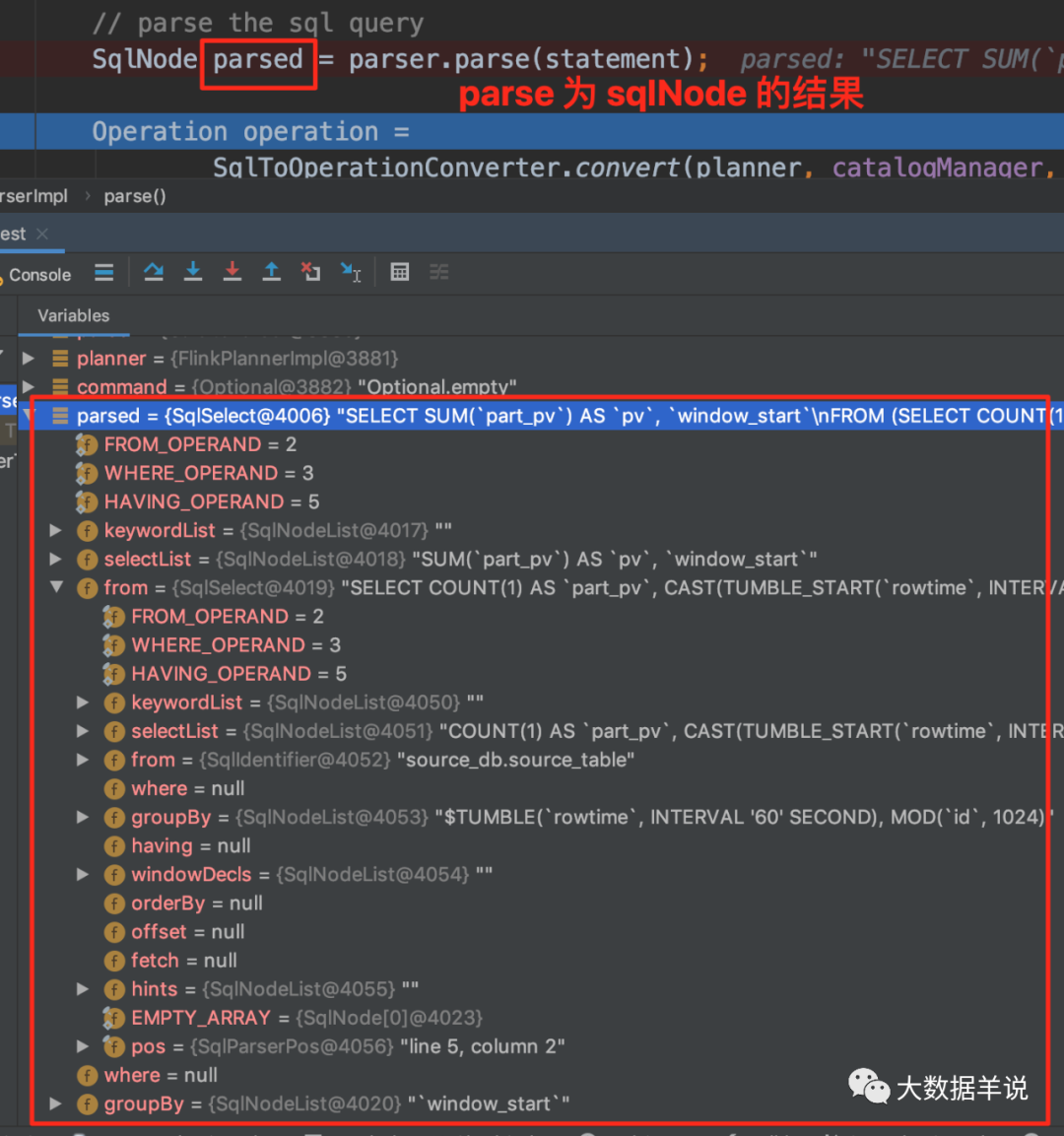
68
The SqlNode obtained by parse is shown in the figure above.
4.4.3.SqlNode verification (SqlNode – > SqlNode)
The SqlNode object produced in the first step above is unauthenticated. This step is the syntax check stage. Before syntax check, you need to know the metadata information. This check will include the check of table name, field name, function name and data type. The implementation of syntax check is as follows:
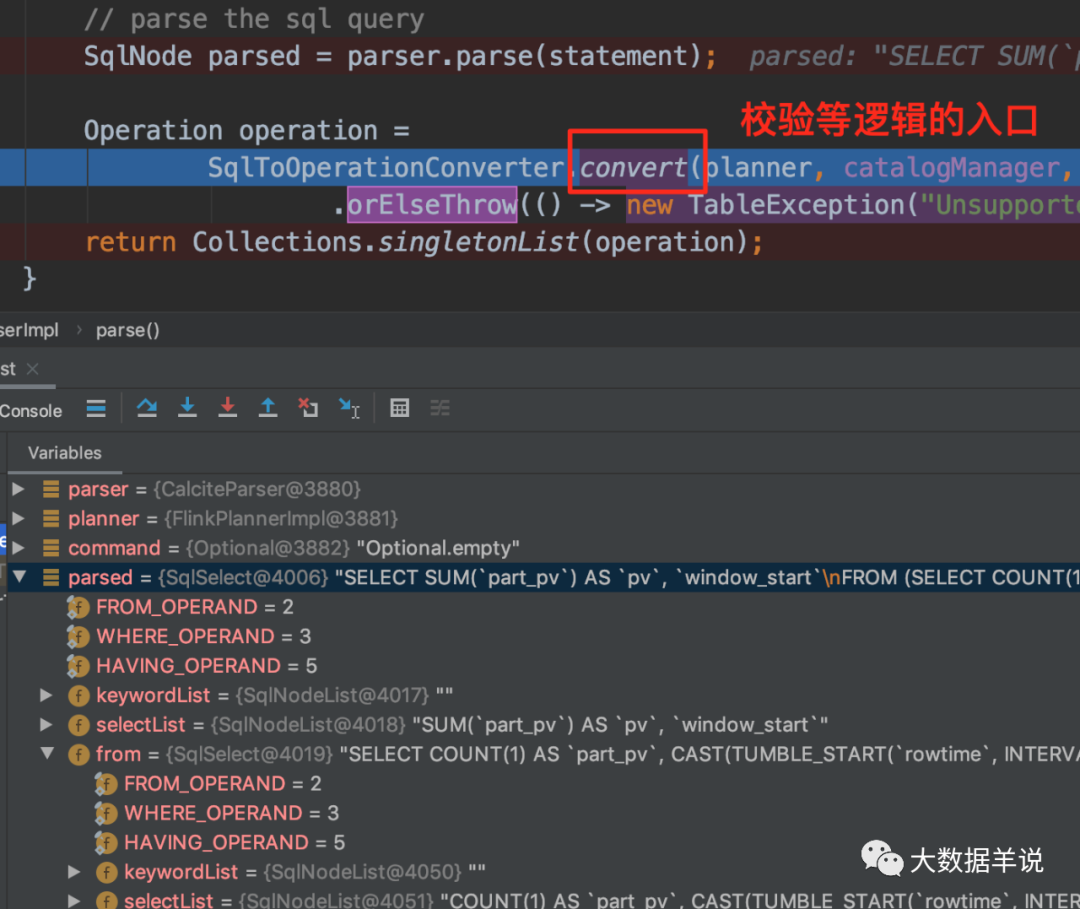
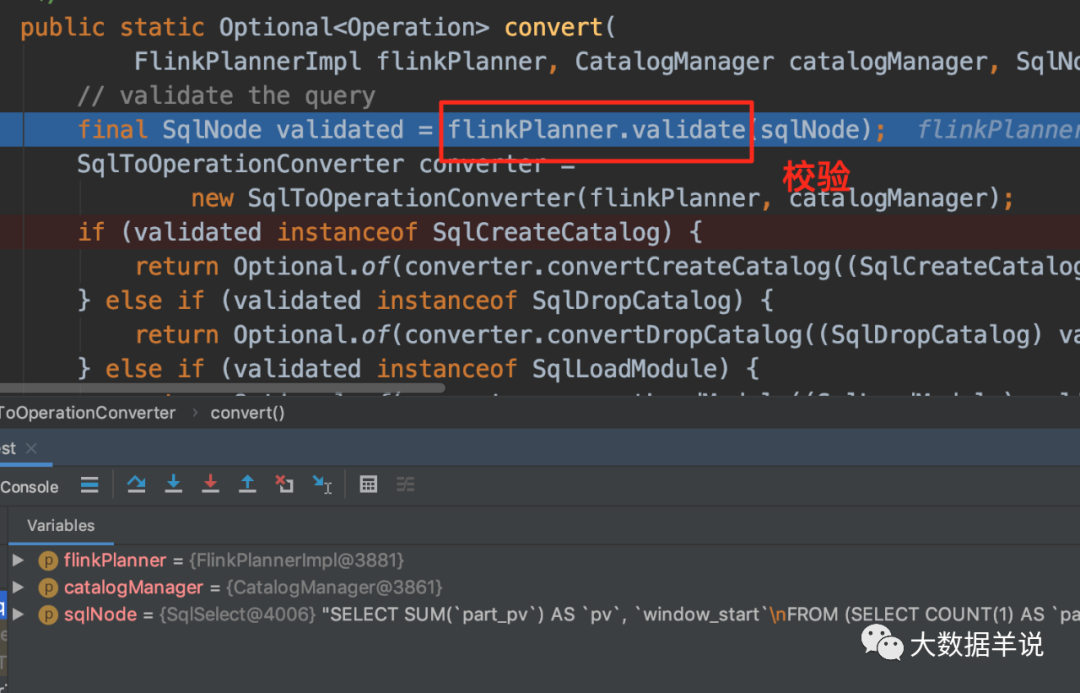
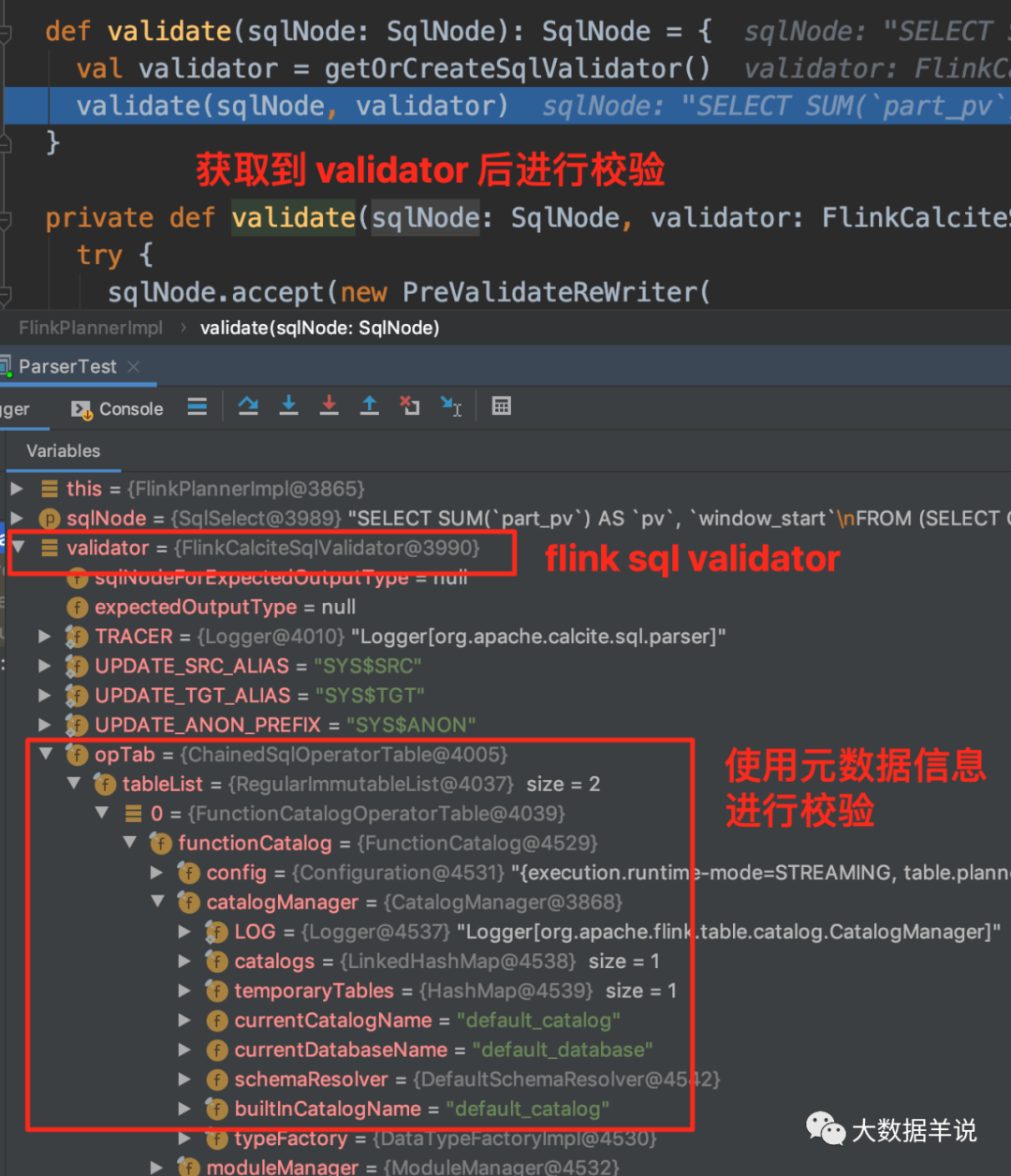
As can be seen from the above figure, the specific implementation class of the flink sql validator is FlinkCalciteSqlValidator, which contains metadata information, so you can check the metadata information.
4.4. 4. Semantic analysis (SqlNode – > relnode)
This step is to convert SqlNode into RelNode, that is, generate corresponding logic at the relational algebra level (generally called Logical Plan here).
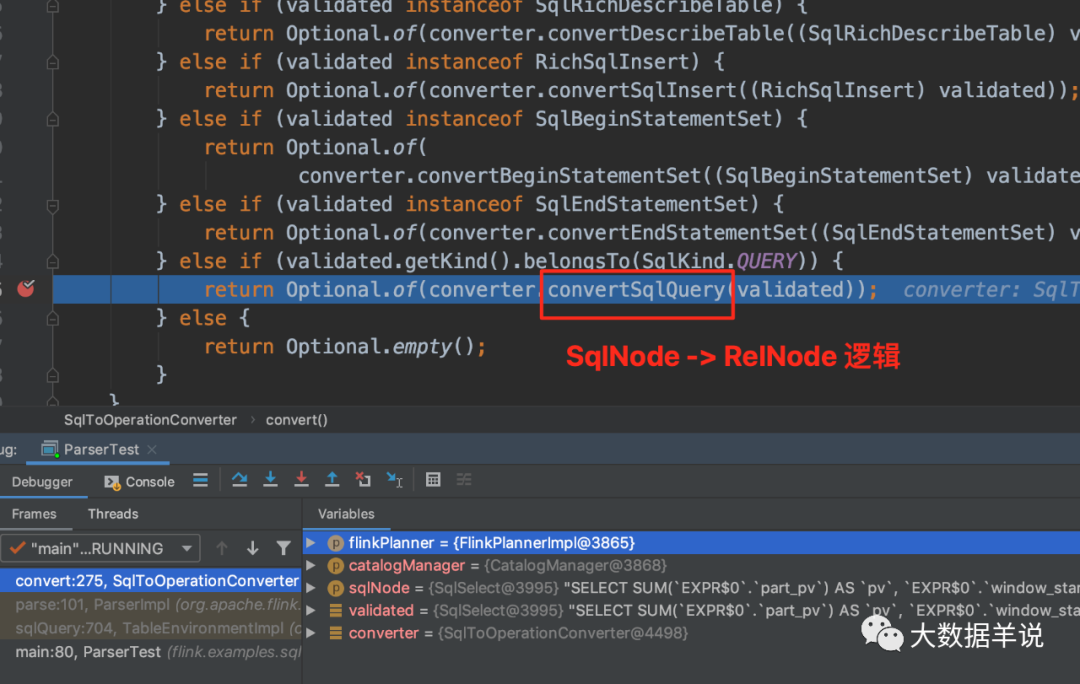
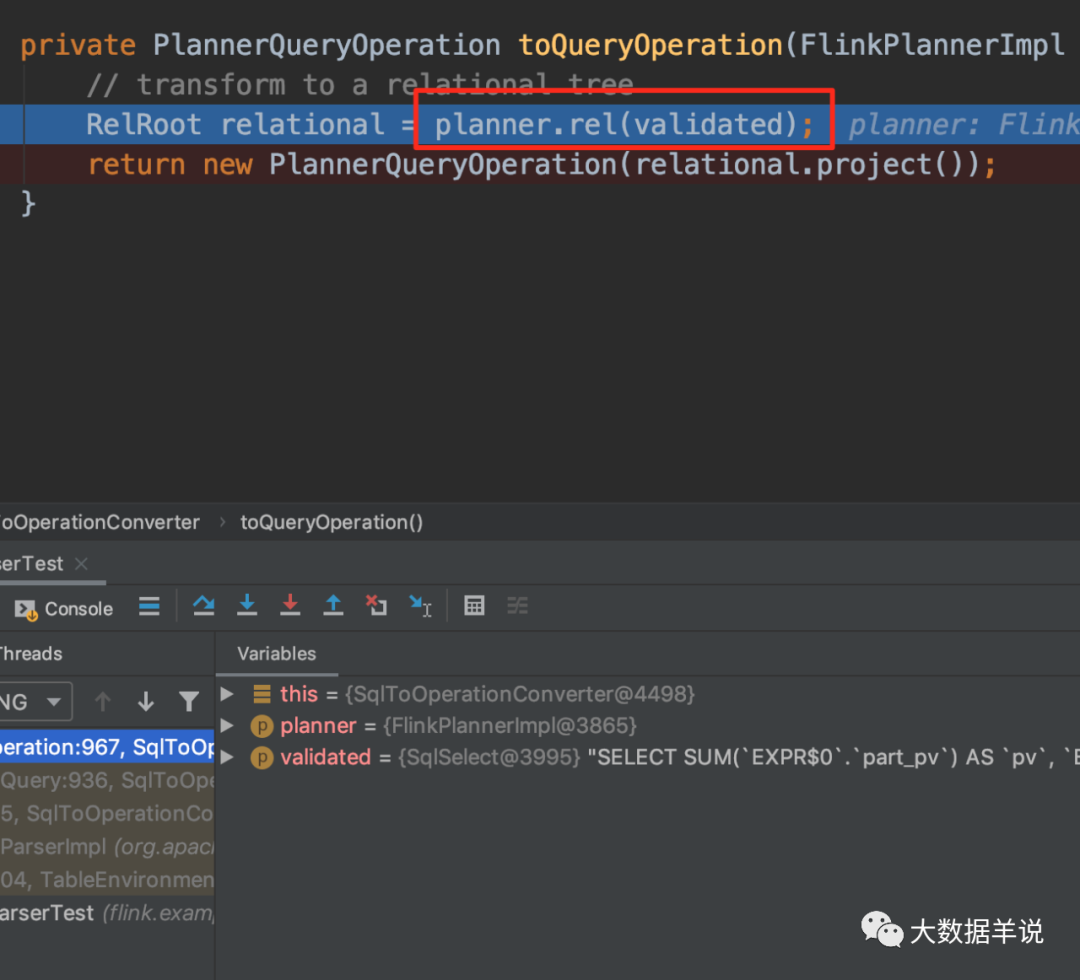
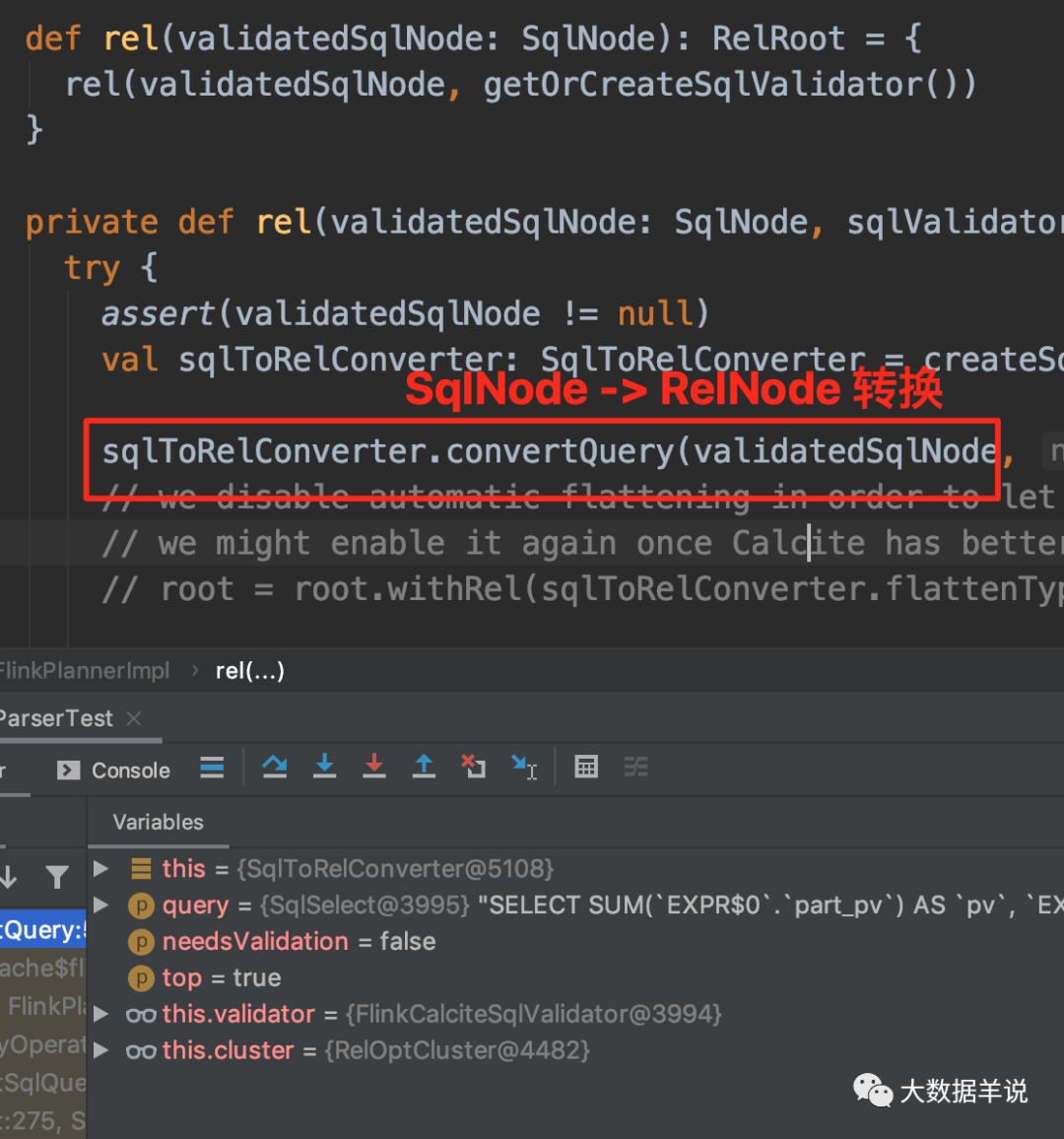
4.4. 5. Optimization stage (RelNode – > RelNode)
This step is the optimization stage. You can view the details in your own debug code, which will not be repeated here.
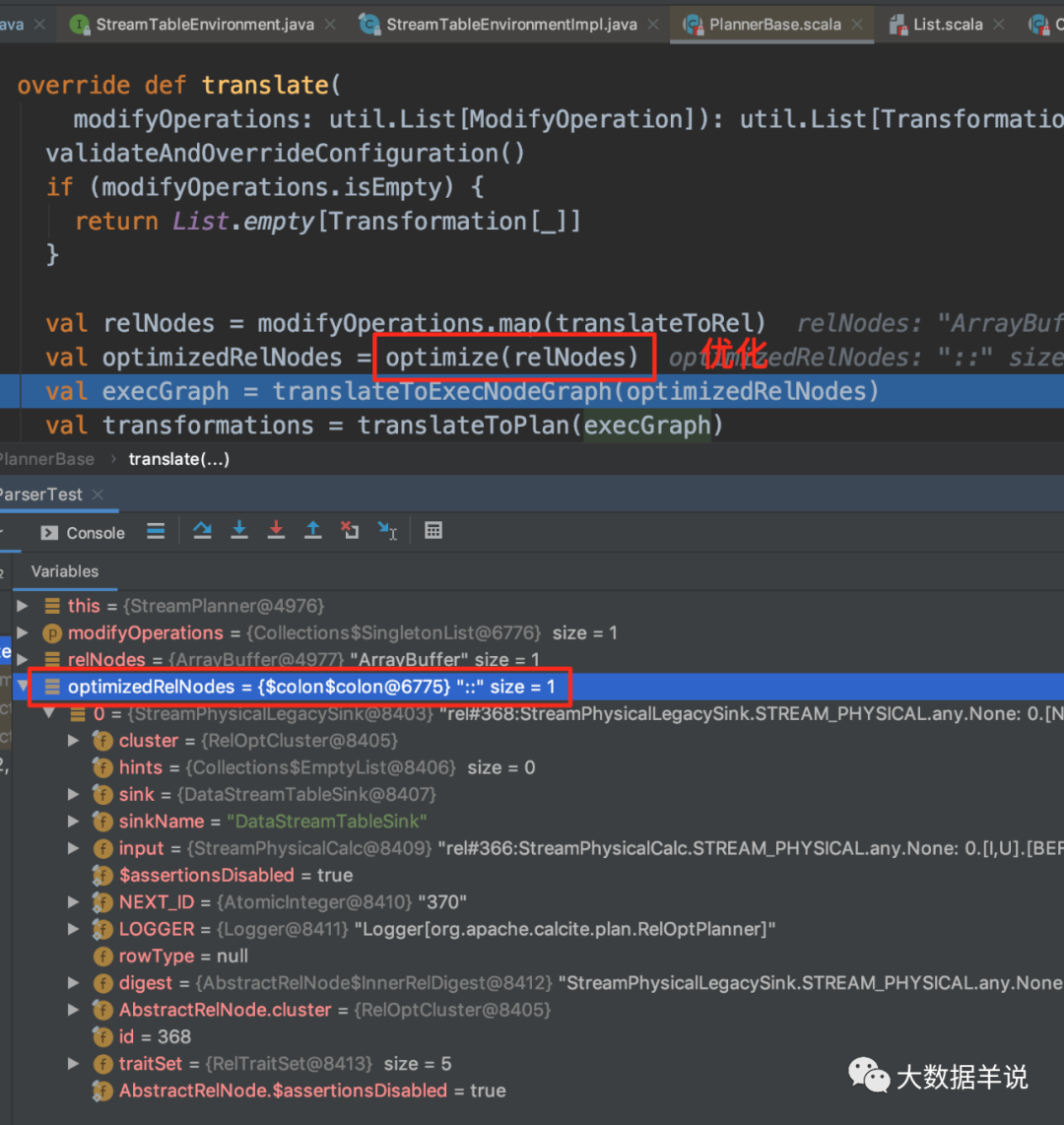

4.5. How can calcite be so universal?
Here, we use the invoke parser as an example to illustrate why its modules are common? Other modules are similar.
Let's start with the conclusion: because the invoke parser module provides an interface, the specific parse logic and rules can be configured according to user customization. You can see the figure below. The blogger drew a picture for details.
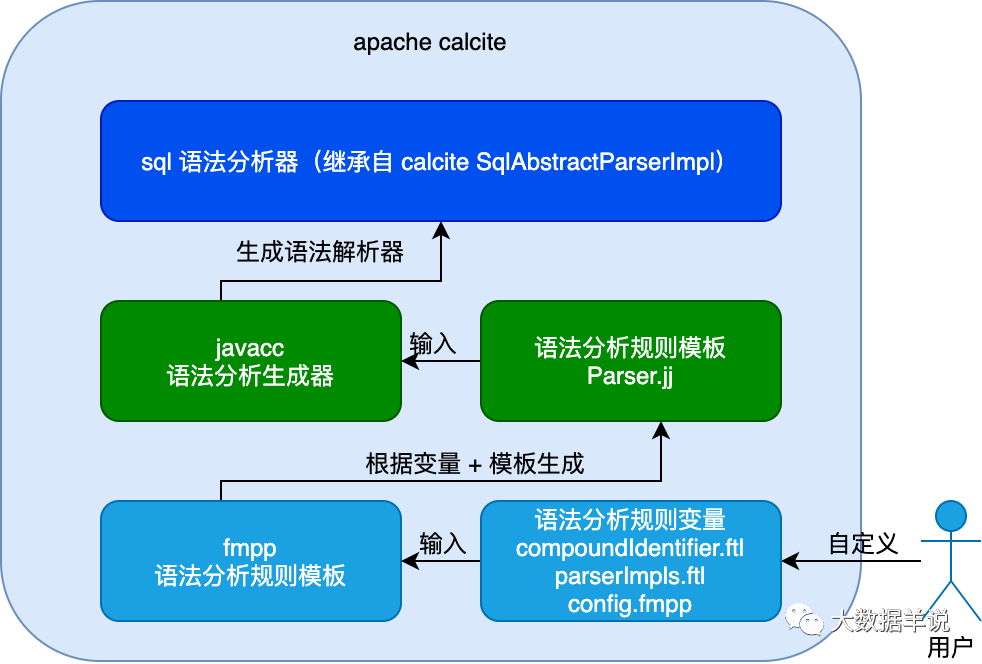
5
As shown in the figure above, there is an input to the generation of engine sql parser, which is the variable of user-defined parsing rules. In fact, the sql parser of a specific engine is also generated according to the user-defined parsing rules. The dynamic generation of its parser depends on components such as javacc. calcite provides a unified sql AST model and optimization model interface, and the specific parsing implementation is left to the user to decide.
javacc will use the parser defined in call JJ file to generate specific sql parser code (as shown in the figure above). The capability of this sql parser is to convert sql into AST (SqlNode). For more details about the invoke capability, see https://matt33.com/2019/03/07/apache-calcite-process-flow/ .
The files involved in the figure above can be downloaded from the cacite source code https://github.com/apache/calcite.git After that, switch to the core module and view it.
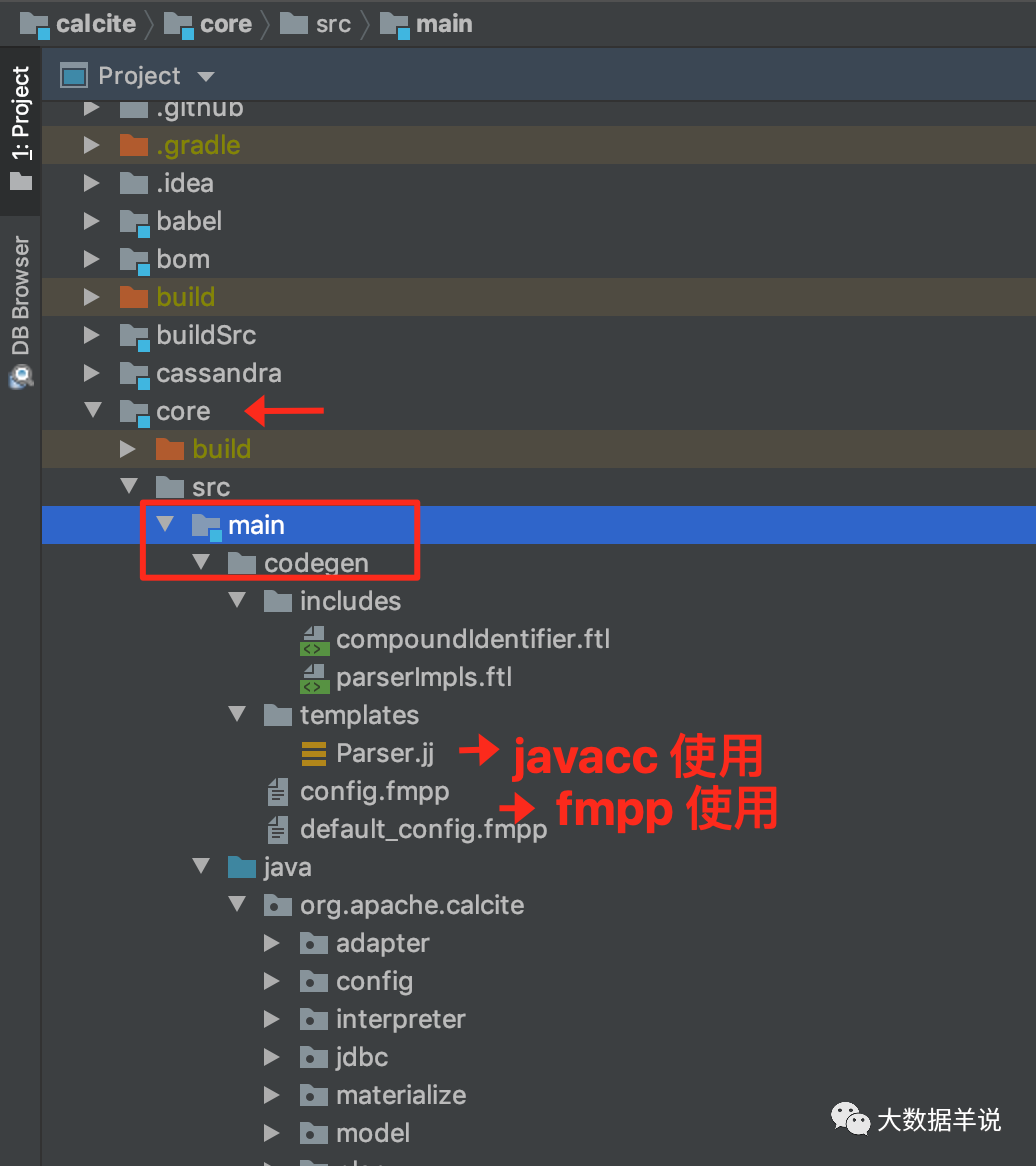
31
4.5. 1. What is JavaCC?
javacc is the most popular parser generator developed in Java. The parser tool can read context free and meaningful syntax and convert it into a java program that can recognize and match the syntax. It is 100% pure java code and can run on a variety of platforms.
Simply explain that javacc is a general syntax analysis producer. Users can use javacc to define a set of DSL and parser arbitrarily.
For example, if one day you think sql is not concise and general enough, you can use javacc to define a more concise set of user define QL. Then use javacc as your user-define-ql parser. Is it very popular? You can get your own compiler.
4.5. 2. Run javacc
The specific JavaCC syntax will not be introduced here. Simply use simple1. 0 on the official website JJ is a case. For detailed syntax and functions, please refer to the official website( https://javacc.github.io/javacc/ )Or blog.
-
https://www.cnblogs.com/Gavin_Liu/archive/2009/03/07/1405029.html
-
https://www.yangguo.info/2014/12/13/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86-Javacc%E4%BD%BF%E7%94%A8/
-
https://www.engr.mun.ca/~theo/JavaCC-Tutorial/javacc-tutorial.pdf
Simple1.jj is used to identify a series of {the same number of curly braces}, followed by 0 or more line terminators.

7
The following is an example of a legal string:
{},{{{{{}}}}},etc.
The following is an example of an illegal string:
{{{{,{}{},{}},{{}{}},etc.
Next, let's actually put simple1 JJ compilation generates specific rule code.
Add javacc build plug-in to pom:
<plugin>
<!-- This must be run AFTER the fmpp-maven-plugin -->
<groupId>org.codehaus.mojo</groupId>
<artifactId>javacc-maven-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<phase>generate-sources</phase>
<id>javacc</id>
<goals>
<goal>javacc</goal>
</goals>
<configuration>
<sourceDirectory>${project.build.directory}/generated-sources/</sourceDirectory>
<includes>
<include>**/Simple1.jj</include>
</includes>
<!-- This must be kept synced with Apache Calcite. -->
<lookAhead>1</lookAhead>
<isStatic>false</isStatic>
<outputDirectory>${project.build.directory}/generated-sources/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
After compiling, code will be generated under generated sources:
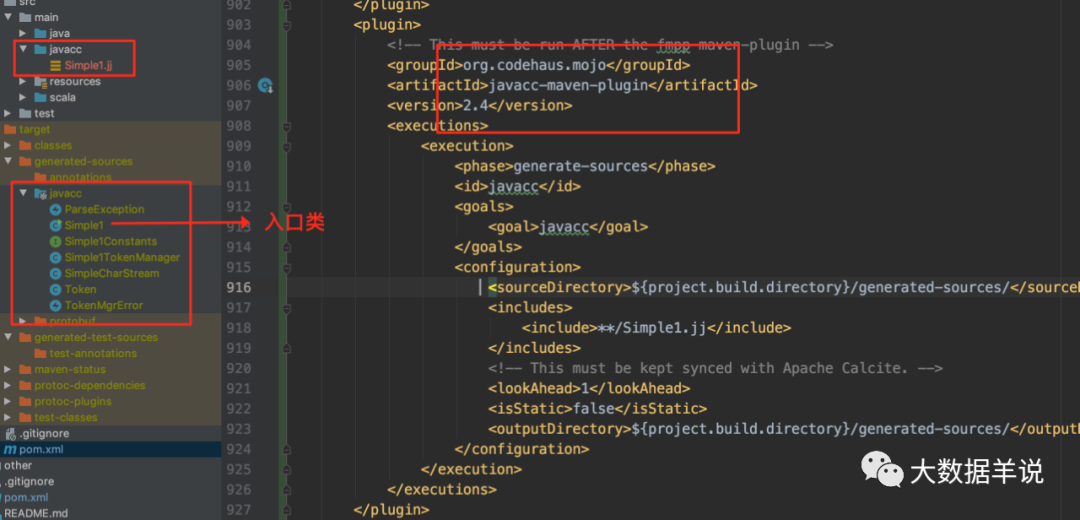
8
Then copy the code to the Sources path:

33
After executing the code, you can see that {} and {}} can pass the verification. Once {} input does not meet the rules, an exception will be thrown.
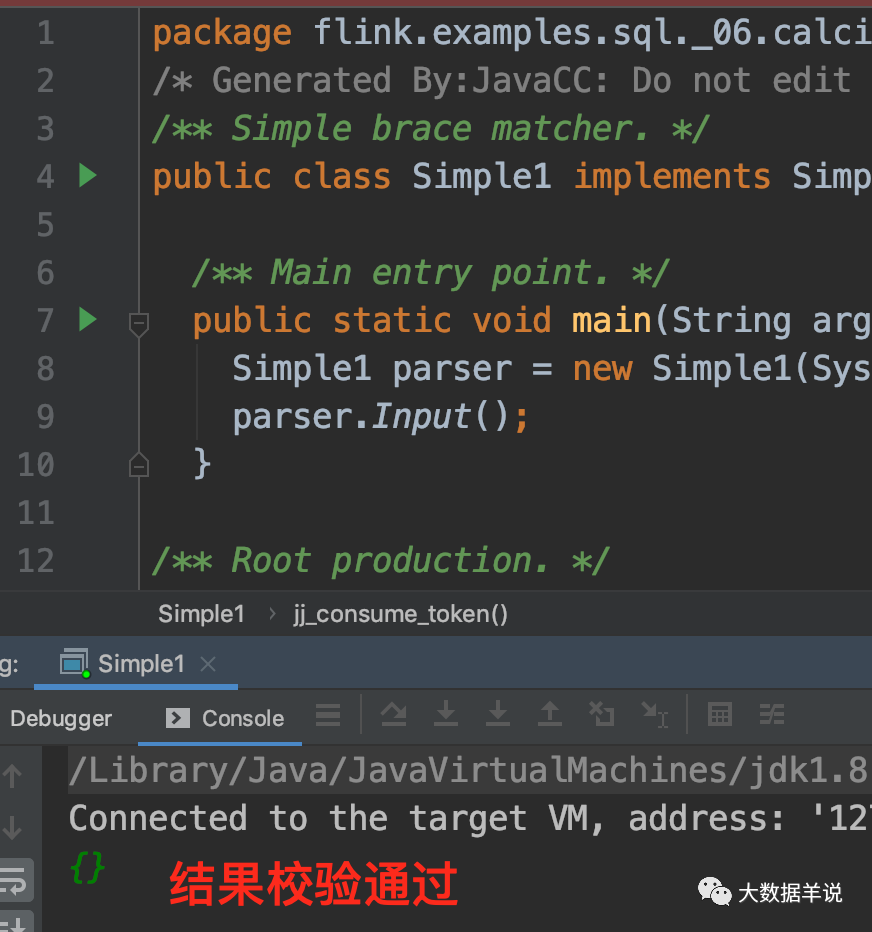


I basically know about javacc.
If you are interested, you can try to customize a compiler.
4.5. 3. What is FMPP?
5
fmpp is a template producer based on freemaker. Users can manage their own variables uniformly, and then generate the corresponding final file with ftl template + variables. Use fmpp as the unified manager of variable + template in calcite. Then generate the corresponding parser based on fmpp JJ file.
5. Principle analysis - calcite shows its skill in flink sql
The blogger drew a diagram containing the dependencies between important components.
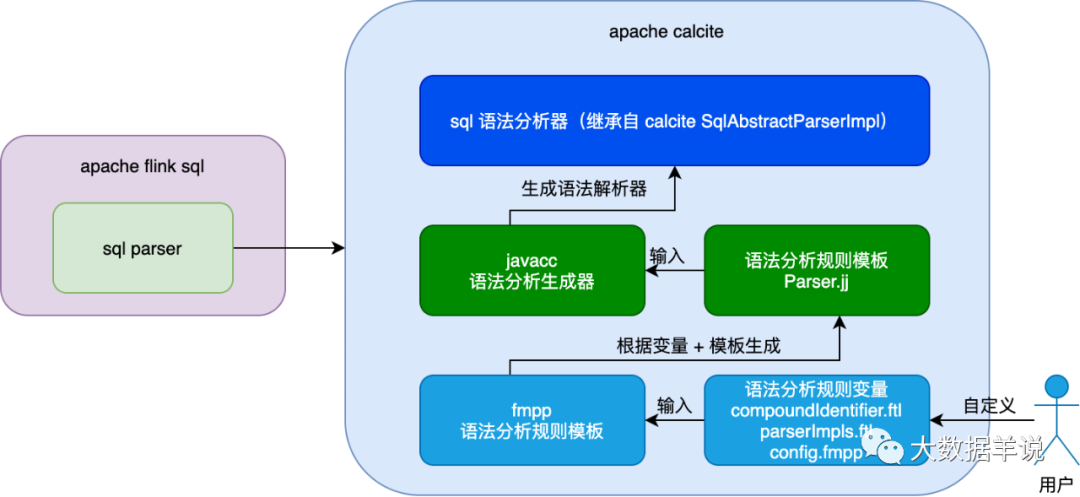
3
You guessed right. It's still the above processes, fmpp (Parser.jj template generation) - > JavaCC (Parser generation) - > invoke.
Before introducing the Parser generation process, let's take a look at the Parser finally generated by flink: FlinkSqlParserImpl (the Blink Planner is used here).
5.1.FlinkSqlParserImpl
Start with the following case (the code is based on Flink version 1.13.1):
public class ParserTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(10);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
DataStream<Tuple3<String, Long, Long>> tuple3DataStream =
env.fromCollection(Arrays.asList(
Tuple3.of("2", 1L, 1627254000000L),
Tuple3.of("2", 1L, 1627218000000L + 5000L),
Tuple3.of("2", 101L, 1627218000000L + 6000L),
Tuple3.of("2", 201L, 1627218000000L + 7000L),
Tuple3.of("2", 301L, 1627218000000L + 7000L),
Tuple3.of("2", 301L, 1627218000000L + 7000L),
Tuple3.of("2", 301L, 1627218000000L + 7000L),
Tuple3.of("2", 301L, 1627218000000L + 7000L),
Tuple3.of("2", 301L, 1627218000000L + 7000L),
Tuple3.of("2", 301L, 1627218000000L + 86400000 + 7000L)))
.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<Tuple3<String, Long, Long>>(Time.seconds(0L)) {
@Override
public long extractTimestamp(Tuple3<String, Long, Long> element) {
return element.f2;
}
});
tEnv.registerFunction("mod", new Mod_UDF());
tEnv.registerFunction("status_mapper", new StatusMapper_UDF());
tEnv.createTemporaryView("source_db.source_table", tuple3DataStream,
"status, id, timestamp, rowtime.rowtime");
String sql = "SELECT\n"
+ " count(1),\n"
+ " cast(tumble_start(rowtime, INTERVAL '1' DAY) as string)\n"
+ "FROM\n"
+ " source_db.source_table\n"
+ "GROUP BY\n"
+ " tumble(rowtime, INTERVAL '1' DAY)";
Table result = tEnv.sqlQuery(sql);
tEnv.toAppendStream(result, Row.class).print();
env.execute();
}
}
The debug process is as shown in the previous SQL - > sqlnode analysis process, as shown in the following figure. Directly locate SqlParser:
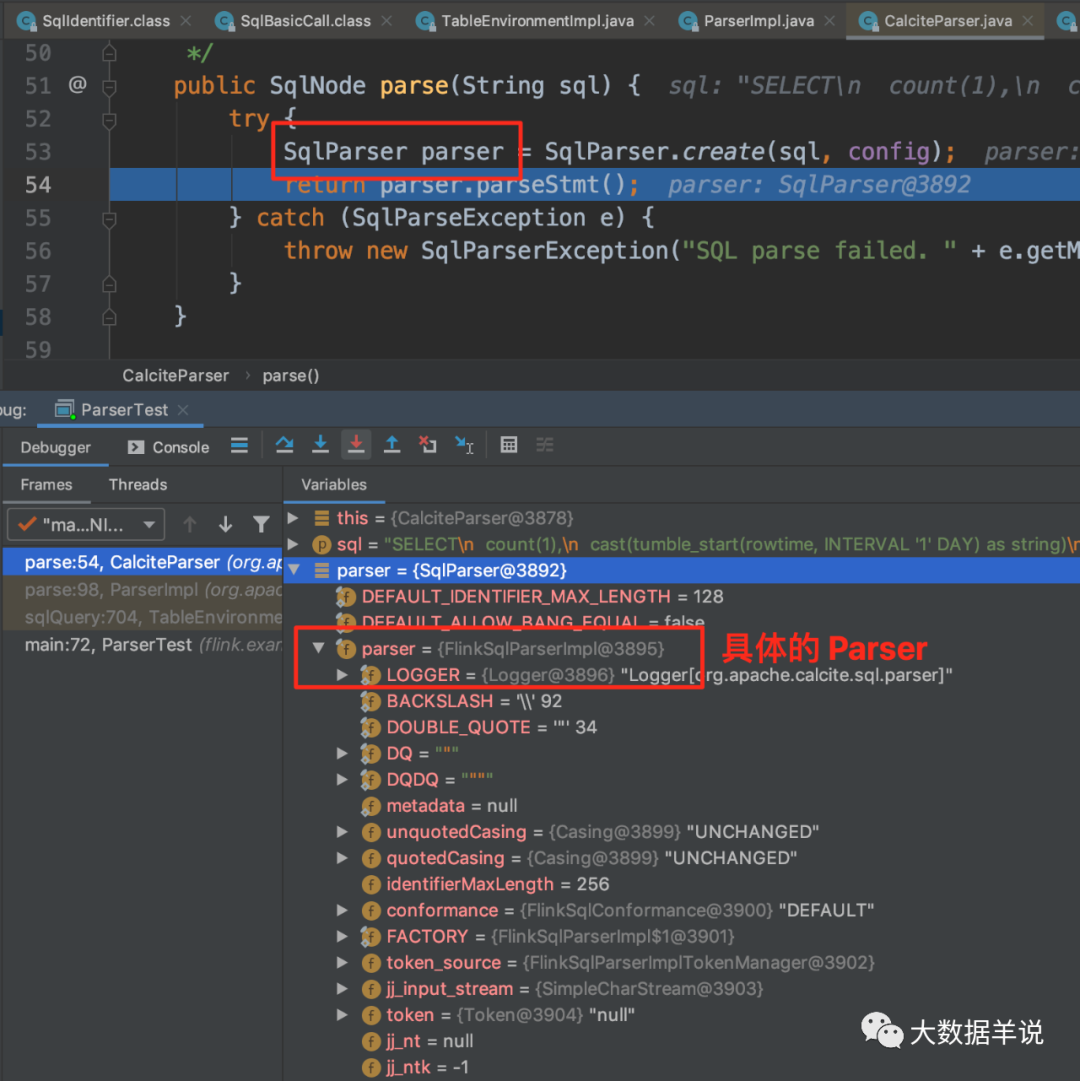
21
As shown in the figure above, the specific Parser is FlinkSqlParserImpl.
Locate the specific code as shown in the following figure (flink-table-palnner-blink-2.11-1.13.1.jar).
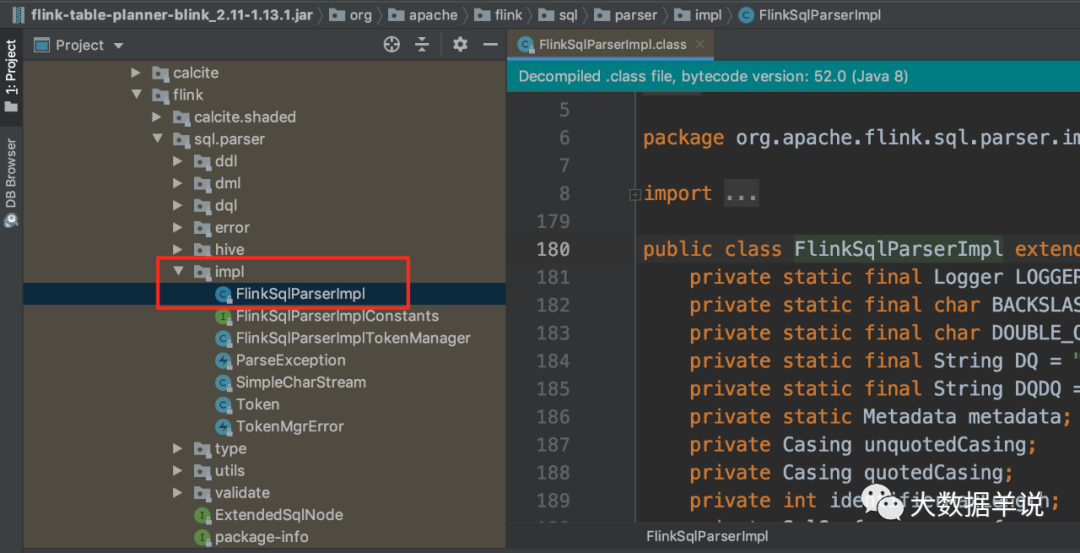
34
The final parse result SqlNode is shown in the figure below.
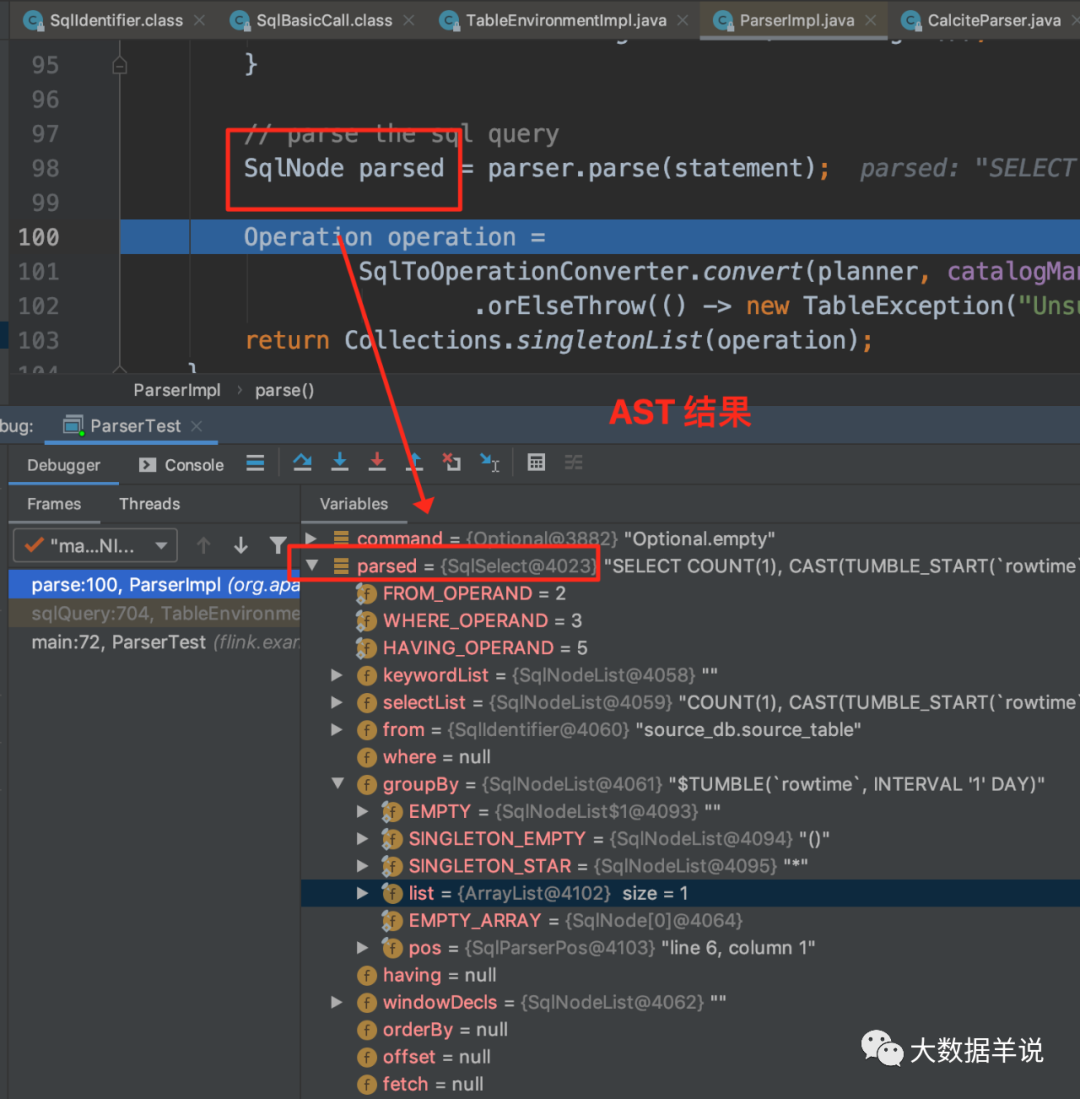
22
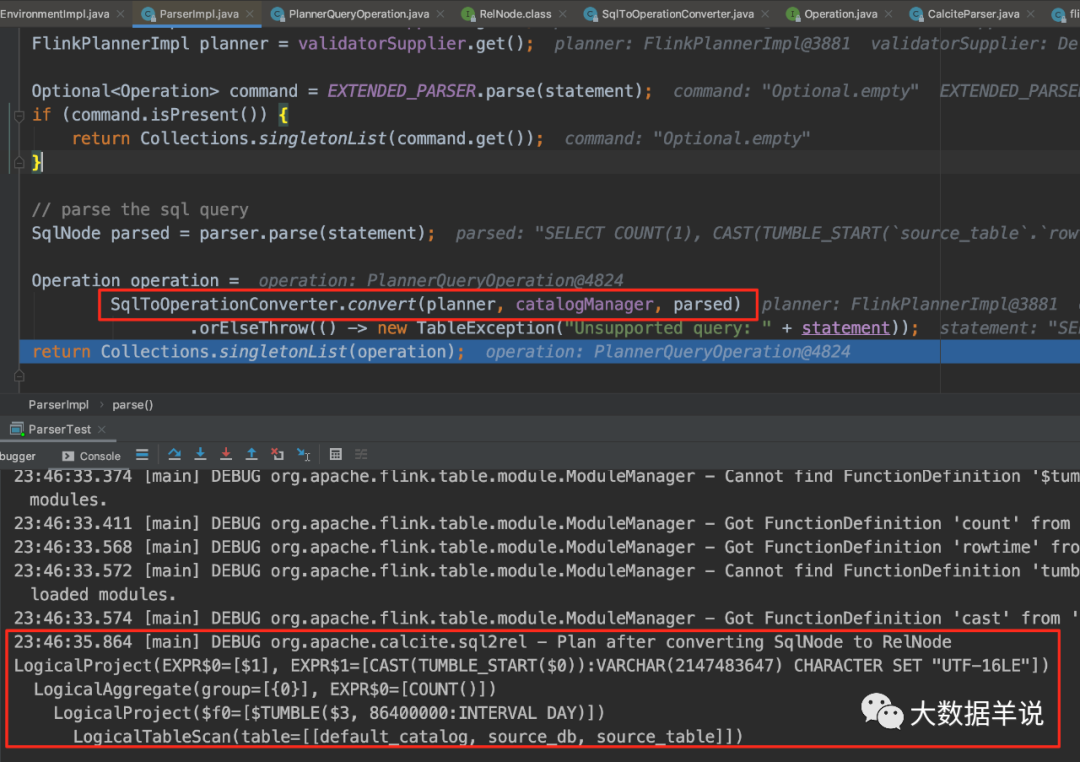
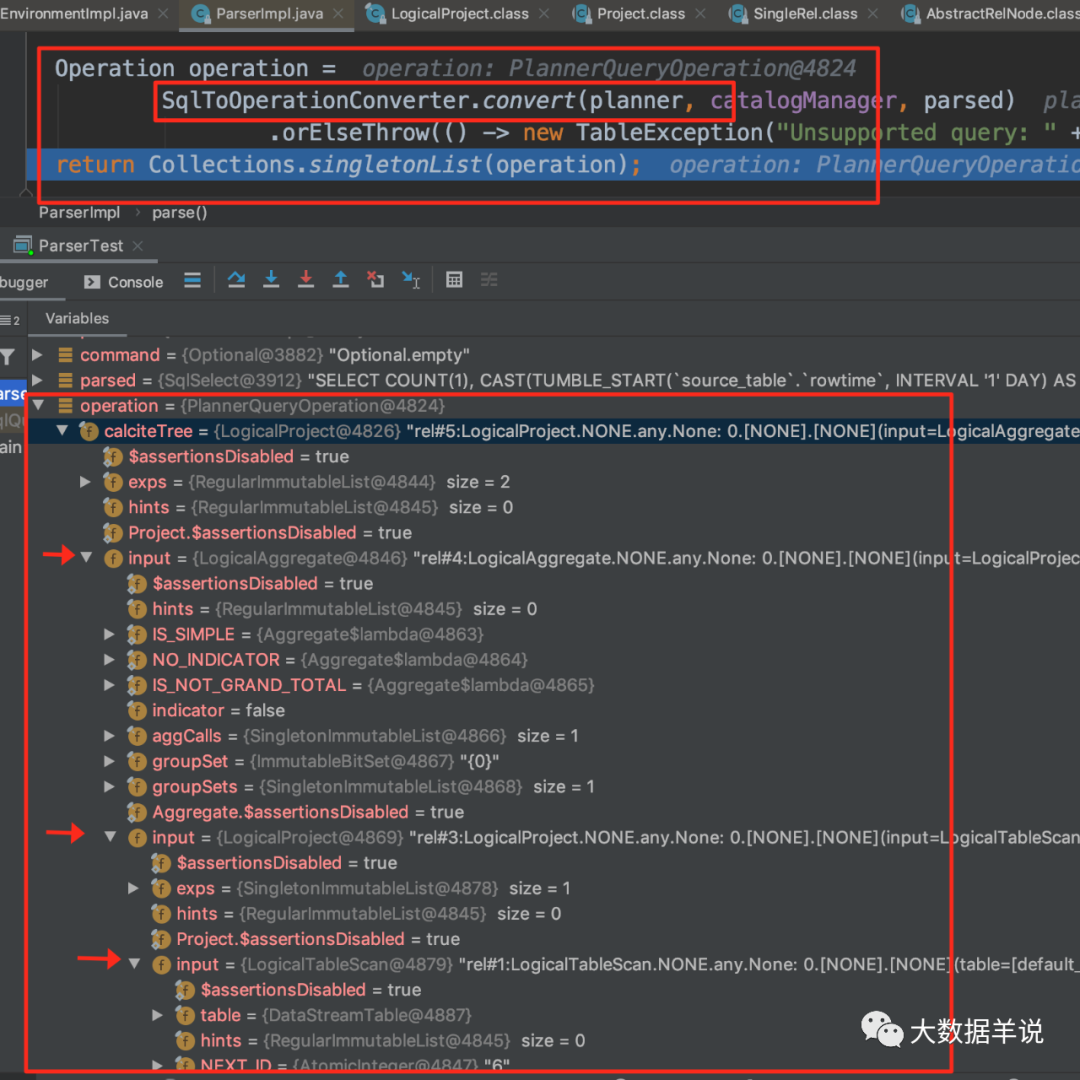
Let's take a look at how FlinkSqlParserImpl is generated using invoke.
Specific to the implementation in flink, it is located in the flink table in the source code flink SQL parser module (the source code is based on flink 1.13.1).
flink is the above overall process implemented by maven plug-in.
5.2. Generation of flinksqlparserimpl

14
Next, let's look at the whole Parser generation process.
5.2.1.flink introduces calcite
Use Maven dependency plugin to unzip the call to the build directory of the flink project.
<plugin>
<!-- Extract parser grammar template from calcite-core.jar and put
it under ${project.build.directory} where all freemarker templates are. -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>unpack-parser-template</id>
<phase>initialize</phase>
<goals>
<goal>unpack</goal>
</goals>
<configuration>
<artifactItems>
<artifactItem>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<type>jar</type>
<overWrite>true</overWrite>
<outputDirectory>${project.build.directory}/</outputDirectory>
<includes>**/Parser.jj</includes>
</artifactItem>
</artifactItems>
</configuration>
</execution>
</executions>
</plugin>

15
5.2.2.fmpp generate parser jj
Use Maven resources plugin to add parser JJ code generation.
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<id>copy-fmpp-resources</id>
<phase>initialize</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/codegen</outputDirectory>
<resources>
<resource>
<directory>src/main/codegen</directory>
<filtering>false</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>com.googlecode.fmpp-maven-plugin</groupId>
<artifactId>fmpp-maven-plugin</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.28</version>
</dependency>
</dependencies>
<executions>
<execution>
<id>generate-fmpp-sources</id>
<phase>generate-sources</phase>
<goals>
<goal>generate</goal>
</goals>
<configuration>
<cfgFile>${project.build.directory}/codegen/config.fmpp</cfgFile>
<outputDirectory>target/generated-sources</outputDirectory>
<templateDirectory>${project.build.directory}/codegen/templates</templateDirectory>
</configuration>
</execution>
</executions>
</plugin>

16
5.2. 3. Generate parser from JavaCC
Using javacc will be based on Parser Generate Parser from JJ file.
<plugin>
<!-- This must be run AFTER the fmpp-maven-plugin -->
<groupId>org.codehaus.mojo</groupId>
<artifactId>javacc-maven-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<phase>generate-sources</phase>
<id>javacc</id>
<goals>
<goal>javacc</goal>
</goals>
<configuration>
<sourceDirectory>${project.build.directory}/generated-sources/</sourceDirectory>
<includes>
<include>**/Parser.jj</include>
</includes>
<!-- This must be kept synced with Apache Calcite. -->
<lookAhead>1</lookAhead>
<isStatic>false</isStatic>
<outputDirectory>${project.build.directory}/generated-sources/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>

17
5.2. 4. Look at the Parser
The resulting Parser is FlinkSqlParserImpl.
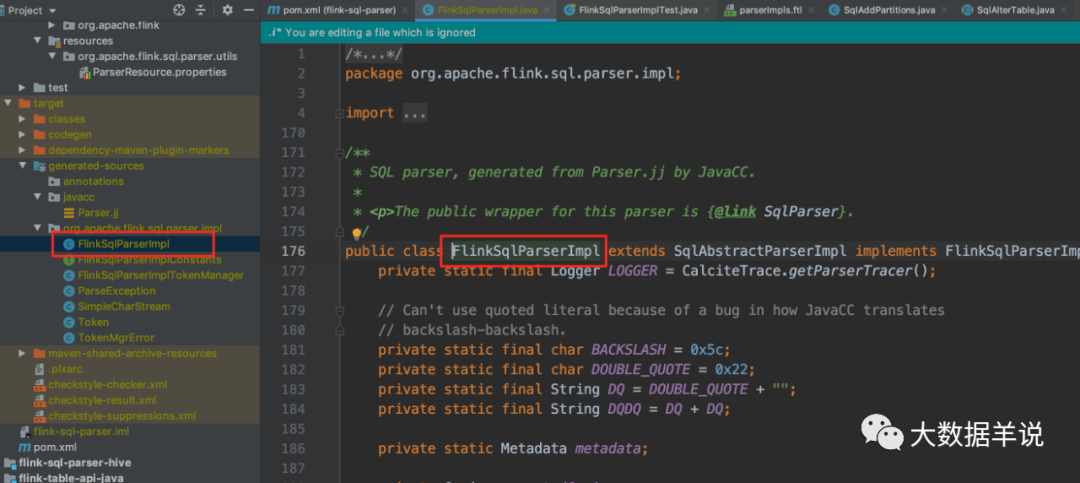
18
5.2. 5. The blink planner introduces the blink SQL parser
The blink planner (blink table planner blink) packages the blink SQL parser and the blink SQL parser hive.
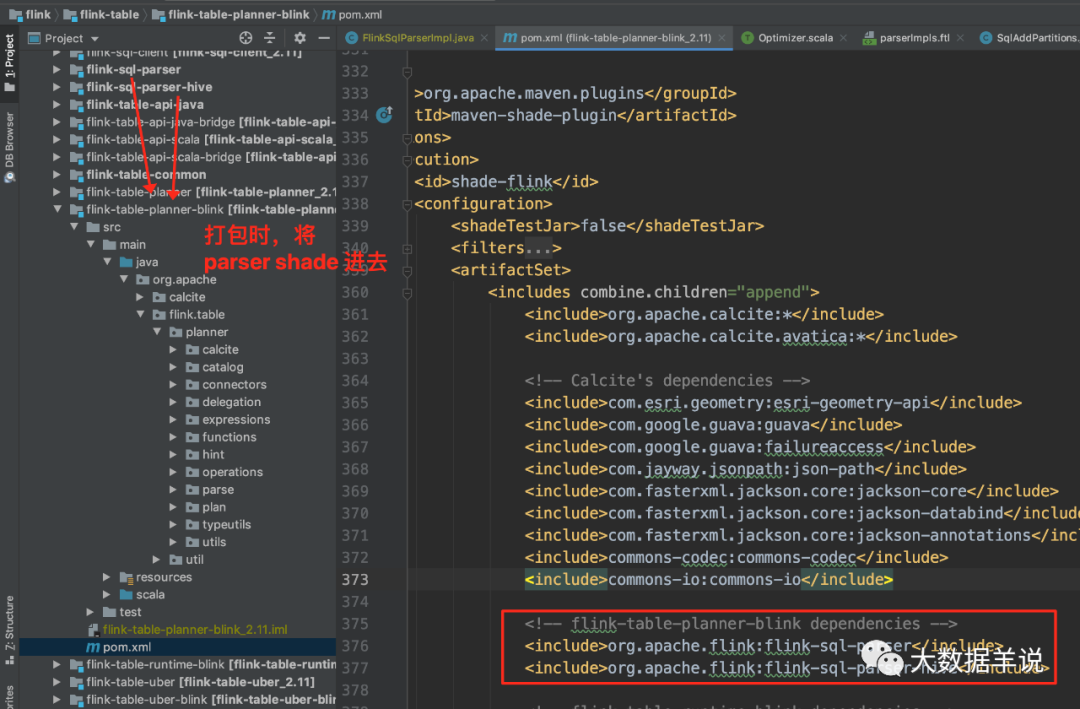
35
6. Summary and Prospect
This paper mainly introduces the dependency between flex SQL and invoke, and the generation process of flex SQL parser. If you think it's helpful for you to understand the flex SQL parsing, please give me a little love (attention + praise + look again) for three consecutive times.
7. References
https://www.slideshare.net/JordanHalterman/introduction-to-apache-calcite
https://arxiv.org/pdf/1802.10233.pdf
https://changbo.tech/blog/7dec2e4.html
http://www.liaojiayi.com/calcite/
https://www.zhihu.com/column/c_1110245426124554240
https://blog.csdn.net/QuinnNorris/article/details/70739094
https://www.pianshen.com/article/72171186489/
https://matt33.com/2019/03/07/apache-calcite-process-flow/
https://www.jianshu.com/p/edf503a2a1e7
https://blog.csdn.net/u013007900/article/details/78978271
https://blog.csdn.net/u013007900/article/details/78993101
http://www.ptbird.cn/optimization-of-relational-algebraic-expression.html
https://book.51cto.com/art/201306/400084.htm
https://book.51cto.com/art/201306/400085.htm
https://miaowenting.site/2019/11/10/Flink-SQL-with-Calcite/
Big data sheep said
Using data to improve the probability of good things~
32 original content
official account
Previous recommendation
[
Flex SQL knows why (V) | custom protobuf format
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488994&idx=1&sn=20236350b1c8cfc4ec5055687b35603d&chksm=c154991af623100c46c0ed224a8264be08235ab30c9f191df7400e69a8ee873a3b74859fb0b7&scene=21#wechat_redirect)
[
flink sql knows why (4) | sql api type system
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488788&idx=1&sn=0127fd4037788762a0401313b43b0ea5&chksm=c15499ecf62310fa747c530f722e631570a1b0469af2a693e9f48d3a660aa2c15e610653fe8c&scene=21#wechat_redirect)
[
flink sql knows why (3) | custom redis data summary table (with source code)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488720&idx=1&sn=5695e3691b55a7e40814d0e455dbe92a&chksm=c1549828f623113e9959a382f98dc9033997dd4bdcb127f9fb2fbea046545b527233d4c3510e&scene=21#wechat_redirect)
[
flink sql knows why (2) | custom redis data dimension table (with source code)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488635&idx=1&sn=41817a078ef456fb036e94072b2383ff&chksm=c1549883f623119559c47047c6d2a9540531e0e6f0b58b155ef9da17e37e32a9c486fe50f8e3&scene=21#wechat_redirect)
[
flink sql knows why (I) | source\sink principle
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488486&idx=1&sn=b9bdb56e44631145c8cc6354a093e7c0&chksm=c1549f1ef623160834e3c5661c155ec421699fc18c57f2c63ba14d33bab1d37c5930fdce016b&scene=21#wechat_redirect)
More blog posts and videos related to flink real-time big data analysis. The background replies to "flink" or "flink sql" to obtain.
Like it+Yes, thank you for your affirmation 👇