1, What is the status?
1.1 stateful and stateless:
- Flink is going to stream. When a data stream comes, the first data will be executed by the operator in the Flink, and an execution result will be generated after the execution is completed
- The result of this execution, for example, is output. The subsequent data, such as the calculation of the second data, has nothing to do with the calculation of the first data, which is stateless
- This is a demerit recording after execution. For example, a summation calculation needs to be performed. For subsequent data, for example, the calculation of the second data needs to depend on the result of the first calculation, which is a stateful calculation
1.2. Stateful flow computation in Flink
1.2. 1. Its stateful calculation is mainly used in Flink
We use Flink technology mainly to complete our stateful computing functions and tasks. In the process of stream processing, the execution results of some previous data need to be used as dependencies for subsequent calculations in many scenarios
1.2. 2. Some specific scenarios
- Filter the data stream from the data source to see if it is in the format we want. If so, save it. If not, filter it out
- Aggregate and analyze the information transmitted from the data source over a period of time, for example, count the data greater than 80 and less than 90 in the data transmitted within 10 minutes
- Record the data line input from the data source, and then perform operations such as de duplication
There is a feature in the above examples, that is, save the previously entered data, and then update the subsequent data, which is the stateful calculation in flink
1.3 status update process in Flink
The update of status is simply the update of the calculation results of the previous data, which can be understood by referring to the following figure:
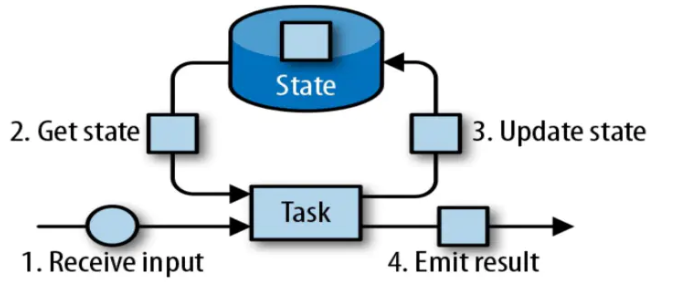
- Step 1: input data from the data source: receive input
- After you get the input data, you need to calculate it in the Task
- Then it comes to the second step. get state obtains the status, that is, the result after the last calculation. If it is the first time, it is also empty
- Then save the result, that is, update the calculation result to state, which is the third step: update state
- Then the subsequent data will come again. It is also calculated in the Task first. At this time, the second item and subsequent data will depend on the results of the previous calculation. At this time, the second step can get the state from the, that is, the results of the last calculation, and then perform the Task calculation. After the calculation is completed, the calculation results will be updated to the state, That is the third step on the way: update state
2, What are the statuses?
2.1 two classification methods:
- According to the class, it can be divided into Operator State operator state and Keyed State keying state
- Storage can be divided into Managed State and Raw State
2.2 further understanding of Operator State and Keyed State
1. First talk about these two states
Each state (the data of calculation results) are all completed by the current task and naturally associated with the current operator. Flink needs to manage these states. First of all, you need to know what types these states define, so you have to register the corresponding states at the beginning, that is, the Operator State operator state and the Keyed State keying state
2. The difference between them: the main difference is that the scope of action is different
- The scope of the operator state is limited to the operator task (that is, when the current partition is executed, all data can access the state when it comes)
- In keying status, not all data in the current partition can access all statuses. Instead, it is divided according to the key after keyby. The current key can only access its own status
2.3 further understanding of Managed State and Raw State
Both Keyed State and Operator State are stored in two ways: managed and raw.
Managed state refers to the data structure of state controlled by Flink, such as using internal hash table, RocksDB, etc. Based on this, Flink can better perform memory optimization and fault recovery based on managed state.
Raw state means that Flink only knows that state is an array of bytes and nothing else. You need to serialize and deserialize the state yourself. Therefore, Flink cannot perform memory optimization and fault recovery based on raw state. Therefore, in enterprise practice, raw state is rarely used
The difference between the two:
- Managed State is managed by Flink, which helps with storage, recovery and optimization,
- Raw State is managed by developers themselves and needs to be serialized by themselves.
Specific differences:
- In terms of state management, the Managed State is hosted by Flink Runtime. The state is automatically stored and restored. Flink has made some optimization in storage management and persistence. When scaling horizontally, or modifying the parallelism of Flink applications, the state can also be automatically redistributed to multiple parallel instances. Raw State is a user-defined state.
- In terms of state data structure, Managed State supports a series of common data structures, such as ValueState, ListState, MapState, etc. Raw State only supports bytes, and any upper data structure needs to be serialized into a byte array. When using, the user needs to serialize it and store it in the form of a very low-level byte array. Flink doesn't know what kind of data structure it stores.
- In terms of specific usage scenarios, most operators can use Managed State by inheriting Rich function classes or other interface classes provided. Raw State is used when the existing operator and Managed State are not enough and the operator is user-defined.
To customize the operator of Flink, you can override the Rich Function interface class, such as RichFlatMapFunction. When using Keyed State, create and access the state by overriding the Rich Function interface class. For Operator State, the checkpoint edfunction interface needs to be further implemented.
3, Learn more about Keyed State
3.1 introduction
- Keying, keying, keying state must be managed, maintained and accessed relative to keys
- Keyed State can only be used after KeyedStream. Keyed State is very similar to a distributed key value map data structure and can only be used for KeyedStream (after keyBy operator processing).
- Keying state is managed based on each key. Generally, after HashCode repartition, keyby will save an independent storage state for each different key based on its own exclusive memory space. Next, a new data can only access its own state. If other keys cannot be accessed, Flink will maintain a state for each key.
- clear() is a clear operation in each state.
- During state programming, StateDescriptor needs to be registered through RuntimeContext.
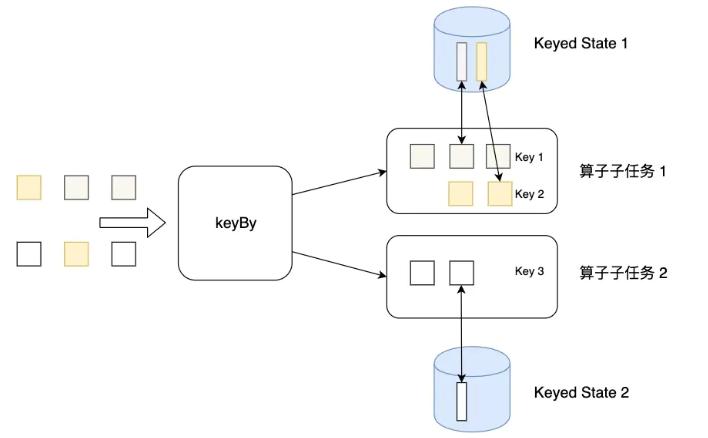
As shown in the figure: when a pile of data comes, it will first be grouped according to the key, and the operator will be executed wherever it is assigned. For example, a piece of data comes from operator task 2. If it is assigned to operator task 2, you will stay here. The state you can access (previously calculated result data) can only be that of your operator task. If you want to access the state in operator task 1, sorry, you can't
3.2 Flink provides the following data formats to manage and store keyed states:
- ValueState: stores the state of a single value type. You can use update(T) to update and retrieve through T value().
- ListState: stores the state of a list type. You can use add(T) or addAll(List) to add elements; And get the whole list through get().
- ReducingState: used to store the results calculated by ReduceFunction. add(T) is used to add elements.
- AggregatingState: used to store the results calculated by AggregatingState. add(IN) is used to add elements.
- MapState: maintain the state of Map type.
The summary is shown in the figure below:

3.3 next is how to use these things in Flink
The general steps are as follows:
- Through datastream Keyby() gets a keyedStream
- keyedStream. Map (self written method)
- Define this self written method: complete data processing based on status
3.4 then the main content is how to write this custom class according to different requirements
General steps:
- Write a class that inherits the RichMapFunction class
- Override the open method in RichMapFunction. In the open method, get the XxxState object through the getXxxState(XxxStateDescriptor) method of the RuntimeContext object
- Implement the map method in RichMapFunction. In the map method, specific functions are implemented according to business needs through the xxstate object
- Use a custom MapFunction on the KeyedStream in your code
3.4. 1. Requirement: wordcount. Practice ValueState
import org.apache.flink.api.common.functions.{RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
/**
* See the application of ValueState through the wordcount function
*/
object ValueStateJob {
def main(args: Array[String]): Unit = {
//1. Define the environment
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2. Set data source
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
//3. keyedStream is obtained by keyBy
val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(0)
//4. Realize the specific operation of status through user-defined methods to complete data processing
val result: DataStream[String] = keyedStream.map(new MyMapFunction)
//5. Printout
result.print()
//6. Implementation
environment.execute("ValueStateJob")
}
}
//Two type parameters represent input type and output type respectively
//Input type: the data type in the keyedStream using this function
//Output type: it is a type set according to business needs
class MyMapFunction extends RichMapFunction[(String, Int),String]{
//valueState stores the number of words
var valueState:ValueState[Int]=_
//The open method is used for initialization: it is executed only once
//Create the required state object in this method
override def open(parameters: Configuration): Unit = {
//To create a state object, you only need to create the object through the RuntimeContext object and the provided method
val runtimeContext: RuntimeContext = getRuntimeContext//A RuntimeContext object can be obtained through the method getRuntimeContext provided in RichMapFunction
//valueStateDescriptor: it is a descriptor of valuestate, which declares the type of data stored in valuestate
//The two parameters respectively represent the unique tag and the type information of the data to be stored in the status
var valueStateDescriptor:ValueStateDescriptor[Int]=new ValueStateDescriptor[Int]("valueState",createTypeInformation[Int])
valueState=runtimeContext.getState(valueStateDescriptor)//A ValueState object can be obtained through the getState method provided by runtimeContext
}
//value: is the input (stream) data; this method will be executed once for each incoming element
override def map(value: (String, Int)): String = {
//In this method, the calculation of word count is completed
//Idea: first get the count corresponding to word from the status, and then add 1. After adding, store the latest results in the status
//1. Obtain the data stored in the state through the value method of valueState
val oldCount: Int = valueState.value()
//Add 1 to the original data
val newCount: Int = oldCount + value._2//You can also write: oldCount+1
//2. Store the newly calculated results into the state through the update method of valueState
valueState.update(newCount)
value._1+"==The number of is==>"+newCount
}
}
3.4. 2 requirements: enable users to browse commodity category statistics. Practice ListState
import java.lang
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
/**
* Categories accessed by users
* The log information sent by the business system is in the following format: user number, user name, access class alias
* Complete statistical processing by status
* Statistics should be made according to users (keyby); A user may access many categories: you should use ListState to store the categories that the user has accessed
*/
object ListStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//Simulate and collect log information of business system; In the next test, you should enter the data in this format: user number, user name, access category
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[(String, String, String), Tuple] = dataStream
.map(_.split("\\s+"))
.map(array => (array(0), array(1), array(2)))
.keyBy(0)
val result: DataStream[(String, String)] = keyedStream.map(new MyListStateMapFunction)
result.print()
environment.execute("ListStateJob")
}
}
class MyListStateMapFunction extends RichMapFunction[(String, String, String),(String,String)]{
var listState:ListState[String]=_
override def open(parameters: Configuration): Unit = {
listState=getRuntimeContext.getListState(new ListStateDescriptor[String]("lsd",createTypeInformation[String]))
}
override def map(value: (String, String, String)): (String, String) = {
/*//According to business needs, obtain data from the state, then process the data, and then save the data in the state
listState.add(value._3)//add The method is to add a data to the state
//Build return value
//get Method to obtain the data stored in the state
val iter: lang.Iterable[String] = listState.get()
val scalaIterable: Iterable[String] = iter.asScala//Convert java's Iterable to scala's Iterable
val str: String = scalaIterable.mkString(",")//The elements in the iterable object are connected by commas through the mkString method*/
//Consider de duplication: the stored data is the data that has been de duplicated
//1. Get the data from the status, add the new data, and then remove the duplicate; Then it is stored in the status
val oldIterable: lang.Iterable[String] = listState.get()
val scalaList: List[String] = oldIterable.asScala.toList
// println(scalaList)
val list: List[String] = scalaList :+ value._3//Add:
// println(scalaList+"=========================")
val distinctList: List[String] = list.distinct//duplicate removal
listState.update(distinctList.asJava)//Update the data in the status; The upate method requires a util list; So it should be converted through asJava
(value._1+":"+value._2,distinctList.mkString(" | "))
}
}
3.4. 3 demand: count the number of times users browse the commodity category and the category. Practice MapState
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
/**
* Use MapState to record the category browsed by the user and the number of browses corresponding to the category
*/
object MapStateJob {
def main(args: Array[String]): Unit = {
/**
* 1.2.3.4.5
*/
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//Data = = = "user No. category accessed by user name
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
//To process, you should group according to the user = = = "keyby according to the user
val keyedStream: KeyedStream[(String, String), Tuple] = dataStream.map(_.split("\\s+"))
.map(words => (words(0) + ":" + words(1), words(2)))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyMapMapFunction)
result.print()
environment.execute("MapStateJob")
}
}
class MyMapMapFunction extends RichMapFunction[(String,String),String]{
//Store the categories accessed by users through MapState
//key in mapState is the category, and value is the number of accesses corresponding to the category
var mapState:MapState[String,Int]=_
override def open(parameters: Configuration): Unit = {
mapState=getRuntimeContext.getMapState(new MapStateDescriptor[String,Int]("MapStateDescriptor",createTypeInformation[String],createTypeInformation[Int]))
}
override def map(value: (String, String)): String = {
var category:String = value._2
//If the category has been visited, the number of visits will be increased by 1; If it has not been accessed, it is marked as 1
var count:Int=0
if(mapState.contains(category)){
count=mapState.get(category)
}
//Put the category and the corresponding number of accesses into the state
mapState.put(category,count+1)
//Build return value
val list: List[String] = mapState.entries().asScala.map(entry => entry.getKey + ":" + entry.getValue).toList
val str: String = list.mkString(" | ")
value._1+"--->"+str
}
}
3.4. 4 requirements: realize automatic statistics of wordCount. Practice ReducingState
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
/**
* Realize wordcount automatic statistics through ReducingState
*/
object ReducingStateJob {
def main(args: Array[String]): Unit = {
/**
* 1.execution environment
* 2.Data source: socket
* 3.Data processing:
* 3.1 flatmap
* 3.2 map--->(word,1)
* 3.3 keyby ===>dataStream Converted to keyedStream
* 3.4 map(new MyMapFunction)
* 4.sink:print
* 5.executeJob
*/
/**
* class MyMapFunction extends RichMapFunction
* Complete the statistical processing of data through valueState
* 1.Create a valueState object in the open method
* a.A RuntimeContext object is required
*
* b.RuntimeContext There are methods provided in the object that can get ValueState
* 2.Use the valueState object in the map method
*/
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyReducingMapFunction)
result.print()
environment.execute("ReducingStateJob")
}
}
/**
* In: Type of input data; It depends on the type of data stream that uses this function
* Out: Type of output data; The return value type of the map method. Determined according to business needs
*/
/*class MyMapFunction extends RichMapFunction[IN,Out]*/
class MyReducingMapFunction extends RichMapFunction[(String,Int),String]{
//Complete the automatic statistics of wordcount through ReducingState
var reducingState:ReducingState[Int]=_
override def open(parameters: Configuration): Unit = {
val context: RuntimeContext = getRuntimeContext
val name:String="ReducingStateDescriptor"
val typeInfo:TypeInformation[Int]=createTypeInformation[Int]
val reduceFunction: ReduceFunction[Int] = new ReduceFunction[Int] {
override def reduce(value1: Int, value2: Int): Int = {
// print(value1+"****"+value2)
value1+value2
}
}
var reducingStateDescriptor:ReducingStateDescriptor[Int]=new ReducingStateDescriptor[Int](name,reduceFunction,typeInfo)
reducingState=context.getReducingState(reducingStateDescriptor)
}
override def map(value: (String, Int)): String = {
reducingState.add(value._2)//Add the data to be calculated to the reducingState
value._1+":"+reducingState.get()
}
}
3.4. 5 demand: realize the average amount of user orders. Practice AggeragetingState
import org.apache.flink.api.common.functions.{AggregateFunction, RichMapFunction}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object AggregatingStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//Data required: user number user name order amount
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[(String, Double), Tuple] = dataStream.map(_.split("\\s+"))
.map(words => (words(0) + ":" + words(1), words(2).toDouble))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyAggregateMapFunction)
result.print()
environment.execute("AggregatingStateJob")
}
}
//Calculate the average amount of orders through aggregatingState
class MyAggregateMapFunction extends RichMapFunction[(String,Double),String]{
//The first Double indicates the order amount; The second Double indicates the average order amount of the user
var aggregatingState:AggregatingState[Double,Double]=_
override def open(parameters: Configuration): Unit = {
//The first Double: the input type is the order amount
//The second type (Double,Int): intermediate type. It refers to the type in the calculation process. It indicates (total order amount, number of orders)
//The third type, Double: output type, is the average order amount
var name:String="aggregatingStateDescriptor"
var aggFunction:AggregateFunction[Double,(Double,Int),Double]=new AggregateFunction[Double,(Double,Int),Double] {
override def createAccumulator(): (Double, Int) = (0,0)//Initial value
/**
* Intermediate calculation process
* @param value Input data, order amount
* @param accumulator Intermediate calculation results (total order amount, number of orders)
* @return
*/
override def add(value: Double, accumulator: (Double, Int)): (Double, Int) = (accumulator._1+value,accumulator._2+1)
//Calculation results
override def getResult(accumulator: (Double, Int)): Double = accumulator._1/accumulator._2
override def merge(a: (Double, Int), b: (Double, Int)): (Double, Int) = (a._1+b._1,a._2+b._2)
}
var accType:TypeInformation[(Double,Int)]=createTypeInformation[(Double,Int)]
var aggregatingStateDescriptor:AggregatingStateDescriptor[Double,(Double,Int),Double]= new AggregatingStateDescriptor[Double,(Double,Int),Double](name,aggFunction,accType)
aggregatingState=getRuntimeContext.getAggregatingState[Double,(Double,Int),Double](aggregatingStateDescriptor)
override def map(value: (String, Double)): String = {
aggregatingState.add(value._2)//Put in the amount of this order
val avg: Double = aggregatingState.get()//Get the average order amount after calculation in status
value._1+"Average order amount:"+avg
}
}