1 Environment
1.1 getExecutionEnvironment
Create an execution environment that represents the context of the current executing program. If the program is called independently, this method returns to the local execution environment; If the program is called from the command-line client to submit to the cluster, this method returns the execution environment of the cluster, that is, getExecutionEnvironment will determine the returned operation environment according to the query operation mode, which is the most commonly used way to create the execution environment.
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // Streaming data execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
If the parallelism is not set, the configuration in flink-conf.yaml will prevail, and the default is 1.
1.2 Source
- Read data from collection
// Source: get data from Collection
DataStream<SensorReading> dataStream = env.fromCollection(
Arrays.asList(
new SensorReading("sensor_1", 1547718199L, 35.8),
new SensorReading("sensor_6", 1547718201L, 15.4),
new SensorReading("sensor_7", 1547718202L, 6.7),
new SensorReading("sensor_10", 1547718205L, 38.1)
)
);
- Read data from file
// Get data output from file
DataStream<String> dataStream = env.readTextFile("/src/main/resources/sensor.txt");
- Read data from Kafka
1 pom dependency
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>Flink_Tutorial</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.12.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
2 start zookeeper
$ bin/zookeeper-server-start.sh config/zookeeper.properties
3 start kafka service
$ bin/kafka-server-start.sh config/server.properties
4 start kafka producer
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic sensor
5 write java code
public class SourceTest3_Kafka {
public static void main(String[] args) throws Exception {
// Create execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Set parallelism 1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
// The following secondary parameters
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
// flink add external data source
DataStream<String> dataStream = env.addSource(new FlinkKafkaConsumer<String>("sensor", new SimpleStringSchema(),properties));
// Printout
dataStream.print();
env.execute();
}
}
6 run the java code and enter it in the Kafka producer console
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic sensor >sensor_1,1547718199,35.8 >sensor_6,1547718201,15.4 >
- Custom Source
addSource function
DataStream<SensorReading> dataStream = env.addSource(new MySensorSource());
// Implement custom SourceFunction
public static class MySensorSource implements SourceFunction<SensorReading> {
// Flag bit, control data generation
private volatile boolean running = true;
@Override
public void run(SourceContext<SensorReading> ctx) throws Exception {
//Define a random number generator
Random random = new Random();
// Set the initial temperature of 10 sensors
HashMap<String, Double> sensorTempMap = new HashMap<>();
for (int i = 0; i < 10; ++i) {
sensorTempMap.put("sensor_" + (i + 1), 60 + random.nextGaussian() * 20);
}
while (running) {
for (String sensorId : sensorTempMap.keySet()) {
// Random fluctuation based on current temperature
Double newTemp = sensorTempMap.get(sensorId) + random.nextGaussian();
sensorTempMap.put(sensorId, newTemp);
ctx.collect(new SensorReading(sensorId,System.currentTimeMillis(),newTemp));
}
// Control output rating
Thread.sleep(2000L);
}
}
@Override
public void cancel() {
this.running = false;
}
}
1.3 Transform
- Basic conversion operator (map/flatMap/filter)
// 1. Map, string = > string length INT
DataStream<Integer> mapStream = dataStream.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
return value.length();
}
});
// 2. flatMap, separating strings by commas
DataStream<String> flatMapStream = dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] fields = value.split(",");
for(String field:fields){
out.collect(field);
}
}
});
// 3. filter to filter the data starting with "sensor_1"
DataStream<String> filterStream = dataStream.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("sensor_1");
}
});
- Aggregation operator
There are no aggregation methods such as reduce and sum in DataStream, because in Flink design, all data must be grouped before aggregation.
First keyBy gets KeyedStream, then calls reduce, sum and so on. (group first and then aggregate)
Common aggregation operators include:
keyBy
Rolling Aggregation
reduce
KeyBy
1. KeyBy will repartition;
2. Different key s may be grouped together because they are implemented through the hash principle;
Rolling Aggregation
These operators can aggregate each tributary of KeyedStream.
sum()
min()
max()
minBy()
maxBy()
// Group first and then aggregate
// grouping
KeyedStream<SensorReading, String> keyedStream = sensorStream.keyBy(SensorReading::getId);
// For rolling aggregation, the difference between Max and maxBy is that except for the fields used for max comparison, other fields of maxBy will also be updated to the latest, while Max only updates the compared fields, and other fields remain unchanged
DataStream<SensorReading> resultStream = keyedStream.maxBy("temperature");
reduce
Reduce is applicable to more general aggregation operation scenarios. The ReduceFunction functional interface needs to be implemented in java.
For example: modify the requirements on the premise of Rolling Aggregation. Obtain the sensor information with the highest historical temperature in the same group, and update its timestamp information in real time.
// Group first and then aggregate
// grouping
KeyedStream<SensorReading, String> keyedStream = sensorStream.keyBy(SensorReading::getId);
// reduce, user-defined protocol function, except for obtaining the sensor information of max temperature, the timestamp is required to be updated to the latest
DataStream<SensorReading> resultStream = keyedStream.reduce(
(curSensor,newSensor)->new SensorReading(curSensor.getId(),newSensor.getTimestamp(), Math.max(curSensor.getTemperature(), newSensor.getTemperature()))
);
3 multi stream conversion operator
Multi stream conversion operators generally include:
Split and Select (new version removed)
Connect and CoMap
Union
Split and Select: separate
Note: Split and Select API s no longer exist in the new version of Flink (at least not in Flink 1.12.1!) getSideOutput is required
Split & select: split a DataStream into multiple datastreams
This function is implemented using getSideOutput
First, define the class to be divided
// Defines the classification of getSideOutput
private static final org.apache.flink.util.OutputTag<SensorReading> high = new org.apache.flink.util.OutputTag<SensorReading>("high"){
};
private static final org.apache.flink.util.OutputTag<SensorReading> low = new org.apache.flink.util.OutputTag<SensorReading>("low"){
};
// Spilt shunt
SingleOutputStreamOperator<SensorReading> SplitSensorReading = DataSensorReadingmap.process(new ProcessFunction<SensorReading, SensorReading>() {
@Override
public void processElement(SensorReading sensorReading, Context context, Collector<SensorReading> collector) throws Exception {
// Grade according to temperature
if (sensorReading.getTemperature()>30) {
context.output(high, sensorReading);
}else if(sensorReading.getTemperature()<=30){
context.output(low,sensorReading);
}else{
collector.collect(sensorReading);
}
}
});
SplitSensorReading.getSideOutput(high).print("high");
SplitSensorReading.getSideOutput(low).print("low");
Connect and CoMap: Connect
Connect:
DataStream,DataStream -> ConnectedStreams:
Connect two data streams that maintain their types. After the two data streams are connected, they are only placed in one stream. Their internal data and form remain unchanged, and the two streams are independent of each other.
CoMap:
ConnectedStreams -> DataStream:
Acting on ConnectedStreams, the function is the same as that of map and flatMap. Map and flatMap operations are performed on each Stream in ConnectedStreams respectively;
// connect converts the high-temperature flow into a binary type, and outputs status information after connecting and merging with the low-temperature flow
SingleOutputStreamOperator<Tuple2<String,Double>> HighTemperatureWarning = SplitSensorReading.getSideOutput(high).map(new MapFunction<SensorReading, Tuple2<String,Double>>() {
@Override
public Tuple2<String, Double> map(SensorReading sensorReading) throws Exception {
return new Tuple2<>(sensorReading.getId(),sensorReading.getTemperature());
}
});
// Merge high temperature flow conversion binary type and low temperature flow SensorReading type
ConnectedStreams<Tuple2<String, Double>, SensorReading> sensorReadingConnectedStreams = HighTemperatureWarning.connect(SplitSensorReading.getSideOutput(low));
// CoMap performs map and flatMap operations on each Stream
SingleOutputStreamOperator<Object> ResultStream = sensorReadingConnectedStreams.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() {
@Override
public Object map1(Tuple2<String, Double> stringDoubleTuple2) throws Exception {
return new Tuple3<>(stringDoubleTuple2.f0, stringDoubleTuple2.f1, "high temp warning");
}
@Override
public Object map2(SensorReading sensorReading) throws Exception {
return new Tuple2<>(sensorReading.getId(), sensorReading.getTemperature());
}
});
ResultStream.print();
Union: Union (multiple)
DataStream ->DataStream:
Union two or more datastreams to generate a new DataStream containing multiple DataStream elements.
Union And Connect Differences between: 1Connect Data types can be different, Connect Only two streams can be merged; 2Union Multiple streams can be merged, Union The data structure must be the same;
// union Union multiple
DataStream<SensorReading> UnionSensorReadingDataStream = SplitSensorReading.getSideOutput(high).union(SplitSensorReading.getSideOutput(low));
UnionSensorReadingDataStream.print("Union");
1.4 summary
Transformation operator is to convert one or more datastreams into new datastreams
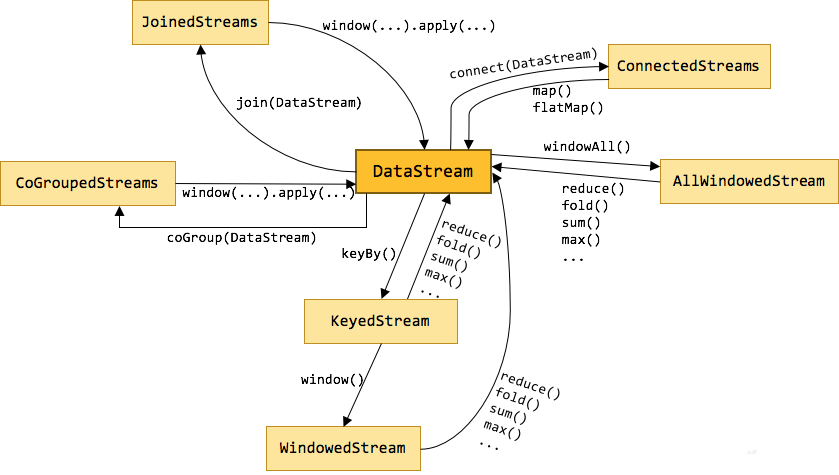
As shown in the figure above, DataStream will be transformed, filtered and aggregated into other different streams by different Transformation operations, so as to meet our business requirements.