01 introduction
In the previous blog, we have a certain understanding of the use of Flink batch streaming API. Interested students can refer to the following:
- Flink tutorial (01) - Flink knowledge map
- Flink tutorial (02) - getting started with Flink
- Flink tutorial (03) - Flink environment construction
- Flink tutorial (04) - getting started with Flink
- Flink tutorial (05) - simple analysis of Flink principle
- Flink tutorial (06) - Flink batch streaming API (Source example)
- Flink tutorial (07) - Flink batch streaming API (Transformation example)
- Flink tutorial (08) - Flink batch streaming API (Sink example)
- Flink tutorial (09) - Flink batch streaming API (Connectors example)
- Flink tutorial (10) - Flink batch streaming API (others)
- Flink tutorial (11) - Flink advanced API (Window)
- Flink tutorial (12) - Flink advanced API (Time and Watermaker)
In the previous tutorial, we have learned the Time in Flink's four cornerstones. As shown in the figure below, this article explains the State:

02 stateful computing in Flink
The API for stateful computing has been encapsulated in Flink, and the underlying state has been maintained!
You don't need to write updateStateByKey yourself like SparkStreaming. That is to say, the State we learn today only needs to master the principle. In actual development, we generally use the State maintained by the underlying layer of Flink or the State maintained by a third party (for example, Flink integrates Kafka's offset to maintain the underlying layer, which is the State used, but others have written it)
/**
* Stateful calculation
*
* @author : YangLinWei
* @createTime: 2022/3/7 11:31 afternoon
*/
public class SourceDemo031 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2.source
DataStream<String> linesDS = env.socketTextStream("node1", 9999);
//3. Data processing - transformation
//3.1 each line of data is divided into words according to the space to form a set
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//value is row by row data
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);//Collect and return the cut words one by one
}
}
});
//3.2 mark each word in the set as 1
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//value is the word that comes in one by one
return Tuple2.of(value, 1);
}
});
//3.3 group the data according to the word (key)
//KeyedStream<Tuple2<String, Integer>, Tuple> groupedDS = wordAndOnesDS.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0);
//3.4 aggregate the data in each group according to the quantity (value), that is, sum
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
//4. Output result - sink
result.print();
//5. Trigger execute
env.execute();
}
}
Execute netcat, and then enter hello world at the terminal. What will the execution program output?
- The answer is obvious, (hello, 1) and (word,1)
So the question is, if you input hello world on the terminal again, what will the program input?
- The answer is also obvious, (hello, 2) and (world, 2).
Because Flink knows that hello world has been processed once before, that is, state plays a role. Here is called keyed state, which stores the data that needs to be counted before, so Flink knows that hello and world have appeared once respectively.
03 stateful and stateless calculation
3.1 stateless calculation
3.1.1 stateless calculation characteristics
Features of stateless calculation:
- Historical data need not be considered
- Getting the same output from the same input is stateless computing, such as map/flatMap/filter
3.1.2 stateless calculation example (consumption delay calculation)

The above figure is an example of stateless calculation, consumption delay calculation: suppose there is a message queue, a producer in the message queue continues to write messages to the consumption queue, and multiple consumers read messages from the message queue respectively.
As can be seen from the figure, the producer has written 16 messages, and the Offset stays at 15; There are three consumers. Some consume fast while others consume slowly. Those who consume fast have consumed 13 pieces of data, while those who consume slow have consumed 7 or 8 pieces of data.
How to count how many pieces of data each consumer lags behind in real time, as shown in the figure, an example of input and output is given. We can know that the input time point has a timestamp, the producer writes the message to the location of a certain time point, and what location each consumer reads at the same time point. Just now, it was mentioned that the producer wrote 15 entries and the consumer read 10, 7 and 12 entries respectively. So the question is, how to convert the progress of producers and consumers into the schematic information on the right?
consumer 0 lags behind by 5, consumer 1 lags behind by 8, and consumer 2 lags behind by 3. According to the principle of Flink, map operation is required here. Map first reads in the messages and then subtracts them respectively to know how many items each consumer is behind. If you send the map all the way down, you will get the final result.
You will find that in the calculation of this mode, no matter how many times this input comes in, the output result is the same, because a single input already contains all the required information. Consumption lag equals producers minus consumers. The consumption of producers can be obtained in a single piece of data, and the data of consumers can also be obtained in a single piece of data, so the same input can get the same output, which is a stateless calculation.
3.2 stateful calculation
3.2.1 features of stateful calculation
characteristic:
- Historical data needs to be considered
- If the same input gets different outputs / not necessarily the same output, it is stateful calculation, such as sum/reduce
3.2.2 stateful calculation example (traffic statistics)

Take the example of access log statistics. For example, you currently get an Nginx access log. A log represents a request. It records where the request comes from and which address is accessed. You need to count how many times each address is accessed in real time, that is, how many times each API is called.
You can see the following simplified input and output. The first input is to request GET / api/a at a certain point in time; The second log records Post /api/b at a certain time point; The third is to GET a / api/a at a certain point in time. There are three Nginx logs in total.
From these three Nginx logs, it can be seen that the first incoming output / api/a is accessed once, the second incoming output / api/b is accessed once, and then another incoming access api/a, so api/a is accessed twice.
The difference is that the incoming data of the two / api/a Nginx logs are the same, but the output results may be different. The first output count=1 and the second output count=2, indicating that the same input may get different outputs.
The output result depends on how many times the API address of the current request has been accessed before. The cumulative number of visits from the first one is 0, and count = 1. The second one has been accessed once, so the cumulative number of visits from / api/a is count=2. In fact, a single piece of data only contains the information of the current visit, not all the information.
To get this result, you also need to rely on the cumulative access volume of the API, that is, the status.
This calculation mode is to input data into the operator for various complex calculations and output data. In this process, the operator will access the state previously stored in it. On the other hand, it will also update the impact of the current data on the state in real time. If 200 pieces of data are input, the final output is 200 results.
3.2.3 scenario of stateful calculation

Stateful calculation uses the following four scenarios:
- De duplication: for example, the data of the upstream system may be duplicated. When it falls to the downstream system, we want to remove all the duplicate data. De duplication needs to know which data has come and which data has not come. That is, record all primary keys. When a piece of data arrives, you can see whether there is a primary key.
- Window calculation: for example, count how many times the Nginx log API is accessed per minute. The window is calculated once a minute. Before the window is triggered, such as the window from 08:00 to 08:01, the data in the first 59 seconds needs to be put into memory, that is, the data in the window needs to be retained first, and then the triggered data in the whole window will be output one minute after 8:01. Non triggered window data is also a state.
- Machine learning / deep learning: for example, the trained model and the parameters of the current model are also a state. Machine learning may use a data set every time. It is necessary to learn on the data set and give a feedback to the model.
- Accessing historical data: for example, comparing with yesterday's data, you need to access some historical data. If you read from the outside every time, the consumption of resources may be relatively large, so you also want to put these historical data into the state for comparison.
04 classification of status
4.1 Managed State & Raw State
From the perspective of whether Flink takes over or not, it can be divided into:
- Managedstate (managed state)
- Raw state
| type | Managed State | Raw State |
|---|---|---|
| Status management mode | Flink Runtime management (automatic storage, automatic recovery, memory management optimization) | User management (serialization required) |
| State data structure | Known data structures (value, list, map...) | Byte array (byte []) |
| Recommended scenario | It can be used in most cases | Available when customizing the Operator |
The differences between the two are as follows:
- In terms of State management mode, Managed State is managed by Flink Runtime, which is automatically stored and restored, and optimized in memory management; The Raw State needs to be managed and serialized by the user. Flink doesn't know what structure the data stored in the State is. Only the user knows it and needs to be finally serialized into a storable data structure.
- In terms of state data structure, Managed State supports known data structures, such as Value, List, Map, etc. Raw State only supports byte arrays, and all States must be converted to binary byte arrays.
- In terms of recommended usage scenarios, Managed State can be used in most cases, while Raw State is used only when Managed State is not enough, such as when the Operator needs to be customized.
In actual production, only ManagedState is recommended.
4.2 Keyed State & Operator State
Managed states are divided into two types: Keyed State and Operator State (Raw State is both Operator State)
| type | Keyed State | Operator State |
|---|---|---|
| operator | Can only be used in operators on KeyedStream | Can be used for all operators (commonly used for source, such as FlinkKafakaConsumer) |
| Corresponding State | Each key corresponds to a State (one Operator instance processes multiple keys and accesses multiple states) | An Operator instance corresponds to a State |
| Concurrent change | Concurrent changes, and the State migrates between instances with the Key | In case of concurrent change, multiple reallocation methods can be selected (uniform distribution and full amount of each after merging) |
| Access mode | Access through RuntimeContext (Rich Function) | Implement the checkpoint edfunction or listcheckpoint interface |
| Support structure | Supported data structures (ValueState, ListState, ReducingState, AggregatingState, MapState) | Supported data structures (ListState) |
4.2.1 Keyed State
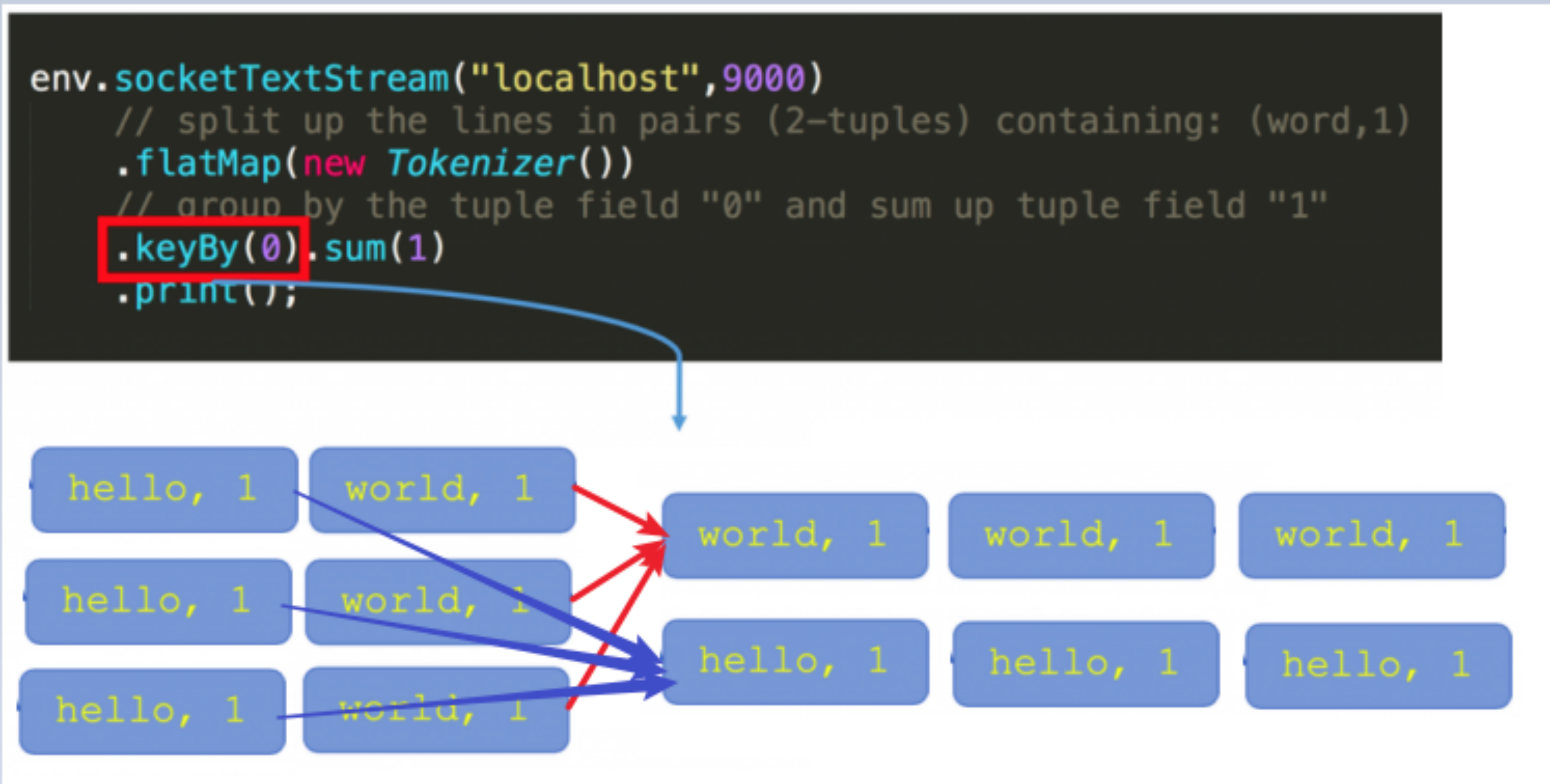
In Flink Stream model, Datastream can be changed into KeyedStream after keyBy operation.
Keyed State is based on the state on KeyedStream. This state is bound to a specific key. Each key on the KeyedStream stream corresponds to a state, such as stream keyBy(…)
The State after KeyBy can be understood as a partitioned State. Each key of each instance of each parallel keyed Operator has a Keyed State, that is, < parallel operator instance, key > is a unique State. Since each key belongs to a parallel instance of a keyed Operator, we simply understand it as < operator, key >.
4.2.2 Operator State
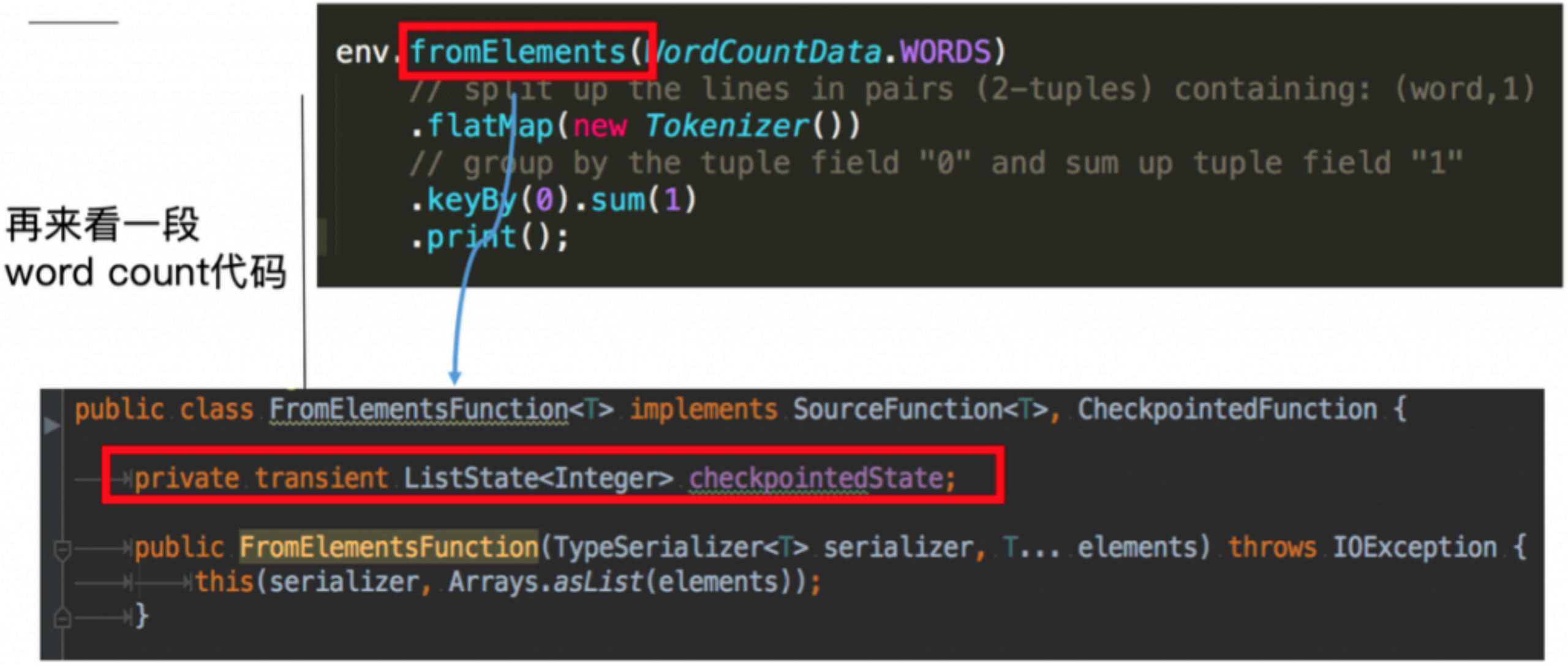
fromElements here will call the class of FromElementsFunction, in which operator state of type list state is used
Each instance of the Key State operator is independent of the State operator.
Operator State can be used for all operators, but it is generally used for Source.
05 State storage structure
As mentioned earlier, stateful computing actually needs to consider historical data, and historical data needs to be stored in a place. Flink provides the following API / data structure to store states in order to facilitate the storage and management of different categories of State s!
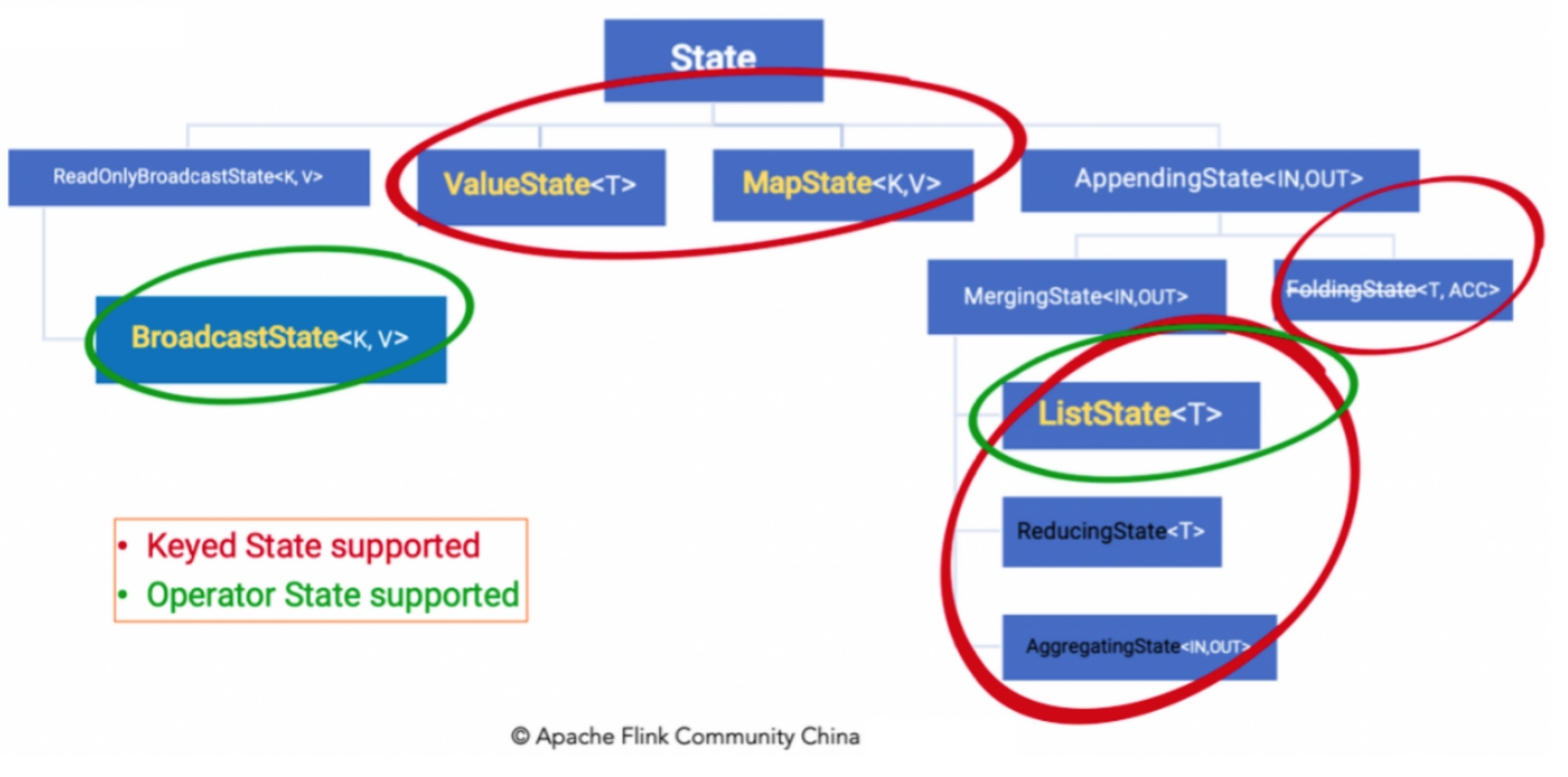
5.1 State API
The Keyed State is accessed through the RuntimeContext, which requires the Operator to be a rich function.
Save the data structure of Keyed state:
- Valuestate < T >: a single value state of type T. This state is bound to the corresponding key, which is the simplest state. It can update the status value through the update method and obtain the status value through the value() method. For example, calculate the total transaction amount of users by user id
- Liststate < T >: that is, the state value on the key is a list. You can add value to the list through the add method; You can also use the get() method to return an iteratable < T > to traverse the status value. For example, you can count the Ip frequently logged in by user id
- Reducingstate < T >: this state passes through the reduceFunction passed in by the user. Each time the add method is called to add a value, reduceFunction will be called, and finally merged into a single state value
- Mapstate < UK, UV >: that is, the state value is a map. The user adds elements through the put or putAll methods
It should be noted that the State object described above is only used to interact with the State (update, delete, empty, etc.), and the real State value may exist in memory, disk, or other distributed storage systems. It means that we just hold the handle of this State - Operator state: you need to implement the checkpoint edfunction or listcheckpoint interface yourself. Save the data structure of operator state: (liststate < T >, broadcaststate < K, V >)
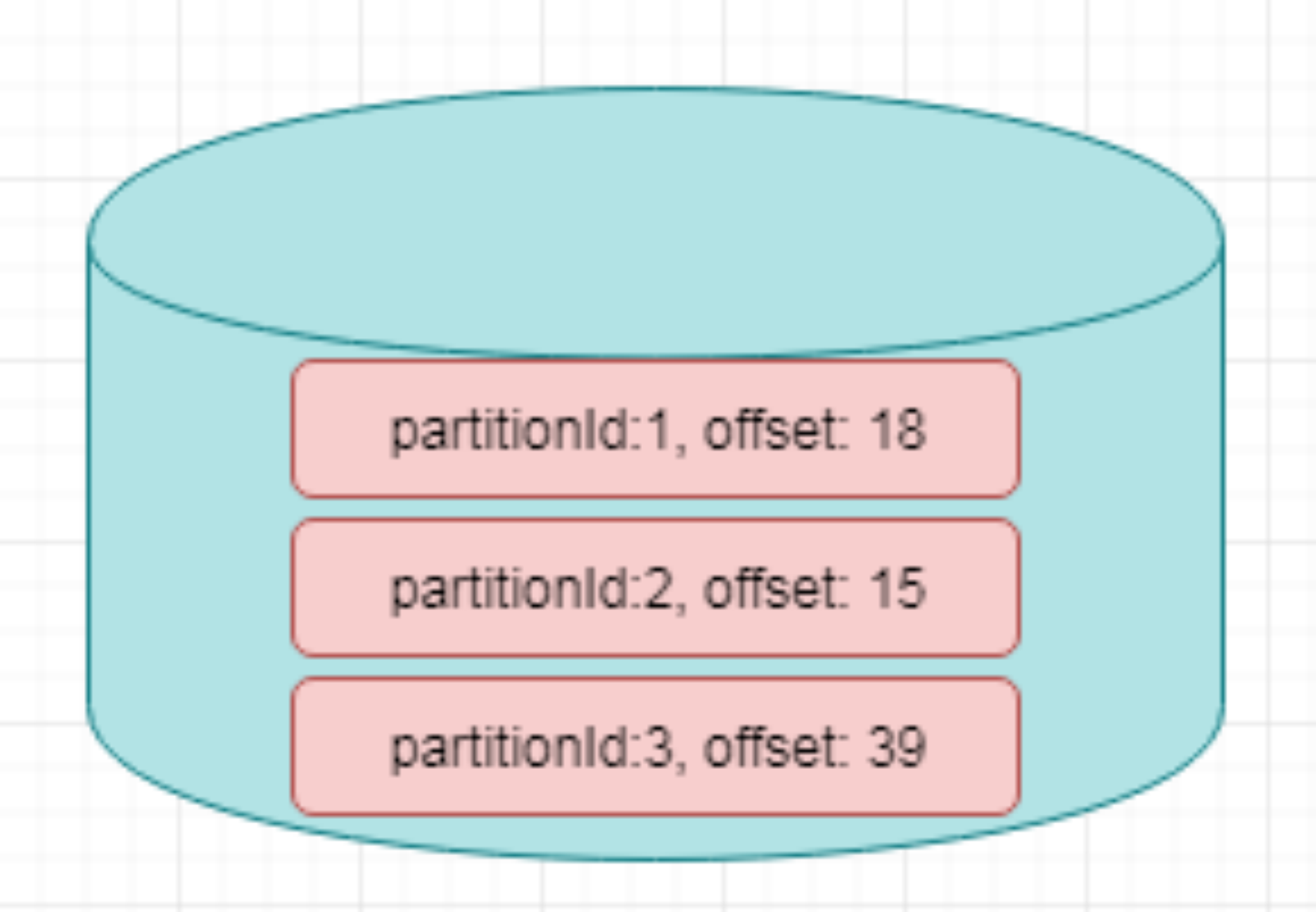
For example, the FlinkKafkaConsumer in Flink uses operator state, which saves all (partition, offset) mappings of the consumed topic in each connector instance.
06 State case
6.1 Keyed State case
reference resources: https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/state/state.html#using-managed-keyed-state
The following figure illustrates how to use keyed state in the code by taking the StreamGroupedReduce class used by sum of word count as an example:
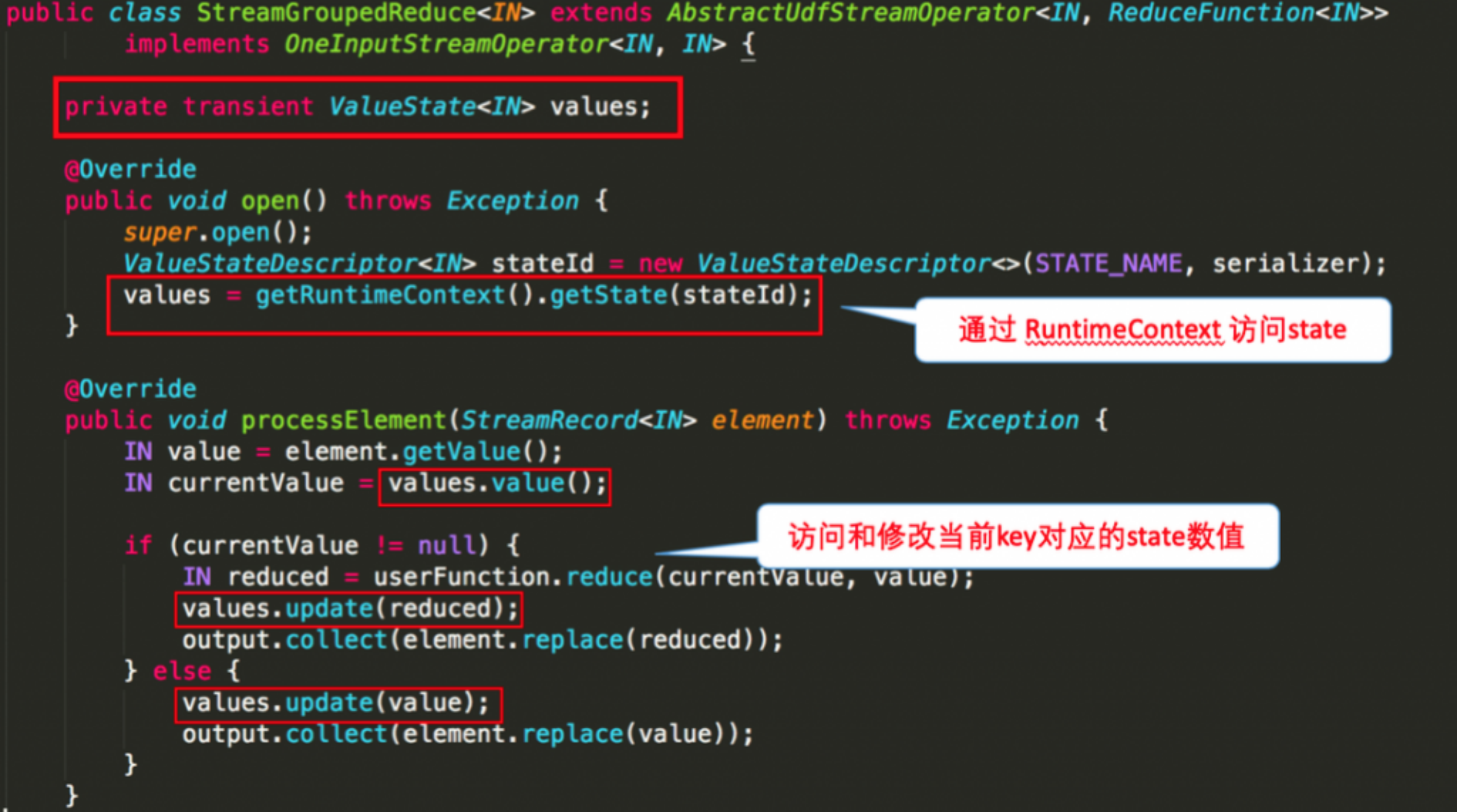
Requirement: use the ValueState in the KeyState to obtain the maximum value in the data (in practice, you can directly use maxBy)
Coding steps:
//-1. Define a status to store the maximum value
private transient ValueState<Long> maxValueState;
//-2. Create a state descriptor object
ValueStateDescriptor descriptor = new ValueStateDescriptor("maxValueState", Long.class);
//-3. Get the State according to the State descriptor
maxValueState = getRuntimeContext().getState(maxValueStateDescriptor);
//-4. Use State
Long historyValue = maxValueState.value();
//Judge the current value and historical value
if (historyValue == null || currentValue > historyValue)
//-5. Update status
maxValueState.update(currentValue);
Example code:
/**
* Use the ValueState in the KeyState to obtain the maximum value in the stream data (in practice, maxBy can be used directly)
*
* @author : YangLinWei
* @createTime: 2022/3/8 12:13 morning
*/
public class KeyedState {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//Convenient observation
//2.Source
DataStreamSource<Tuple2<String, Long>> tupleDS = env.fromElements(
Tuple2.of("Beijing", 1L),
Tuple2.of("Shanghai", 2L),
Tuple2.of("Beijing", 6L),
Tuple2.of("Shanghai", 8L),
Tuple2.of("Beijing", 3L),
Tuple2.of("Shanghai", 4L)
);
//3.Transformation
//Use the ValueState in the KeyState to obtain the maximum value in the stream data (in practice, maxBy can be used directly)
//Implementation method 1: directly use maxBy -- this method can be used in development
//min will find the smallest field, regardless of the other fields
//minBy will find the smallest field and the corresponding other fields
//max will only find the largest field, regardless of other fields
//maxBy will find the largest field and the corresponding other fields
SingleOutputStreamOperator<Tuple2<String, Long>> result = tupleDS.keyBy(t -> t.f0)
.maxBy(1);
//Implementation method 2: use the ValueState in KeyState - used in learning and testing, or use this method only when you encounter complex logic that Flink does not implement in subsequent projects / actual development!
SingleOutputStreamOperator<Tuple3<String, Long, Long>> result2 = tupleDS.keyBy(t -> t.f0)
.map(new RichMapFunction<Tuple2<String, Long>, Tuple3<String, Long, Long>>() {
//-1. Define the status to store the maximum value
private ValueState<Long> maxValueState = null;
@Override
public void open(Configuration parameters) throws Exception {
//-2. Define state descriptor: describe the name of the state and the data type in it
ValueStateDescriptor descriptor = new ValueStateDescriptor("maxValueState", Long.class);
//-3. Initialize the status according to the status descriptor
maxValueState = getRuntimeContext().getState(descriptor);
}
@Override
public Tuple3<String, Long, Long> map(Tuple2<String, Long> value) throws Exception {
//-Get the maximum value of State in history, 4. Use the maximum value of State in history
Long historyMaxValue = maxValueState.value();
Long currentValue = value.f1;
if (historyMaxValue == null || currentValue > historyMaxValue) {
//5 - update the status and save the current as the new maximum value in the status
maxValueState.update(currentValue);
return Tuple3.of(value.f0, currentValue, currentValue);
} else {
return Tuple3.of(value.f0, currentValue, historyMaxValue);
}
}
});
//4.Sink
//result.print();
result2.print();
//5.execute
env.execute();
}
}
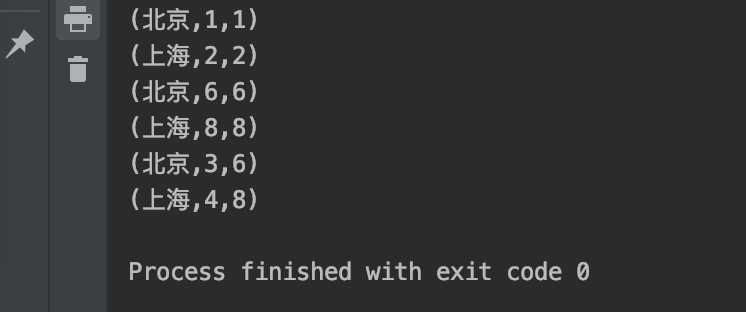
Operation results:
6.2 Operator State case
reference resources: https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/state/state.html#using-managed-operator-state
The following figure explains the FromElementsFunction class in the word count example in detail and shares how to use operator state in the code:
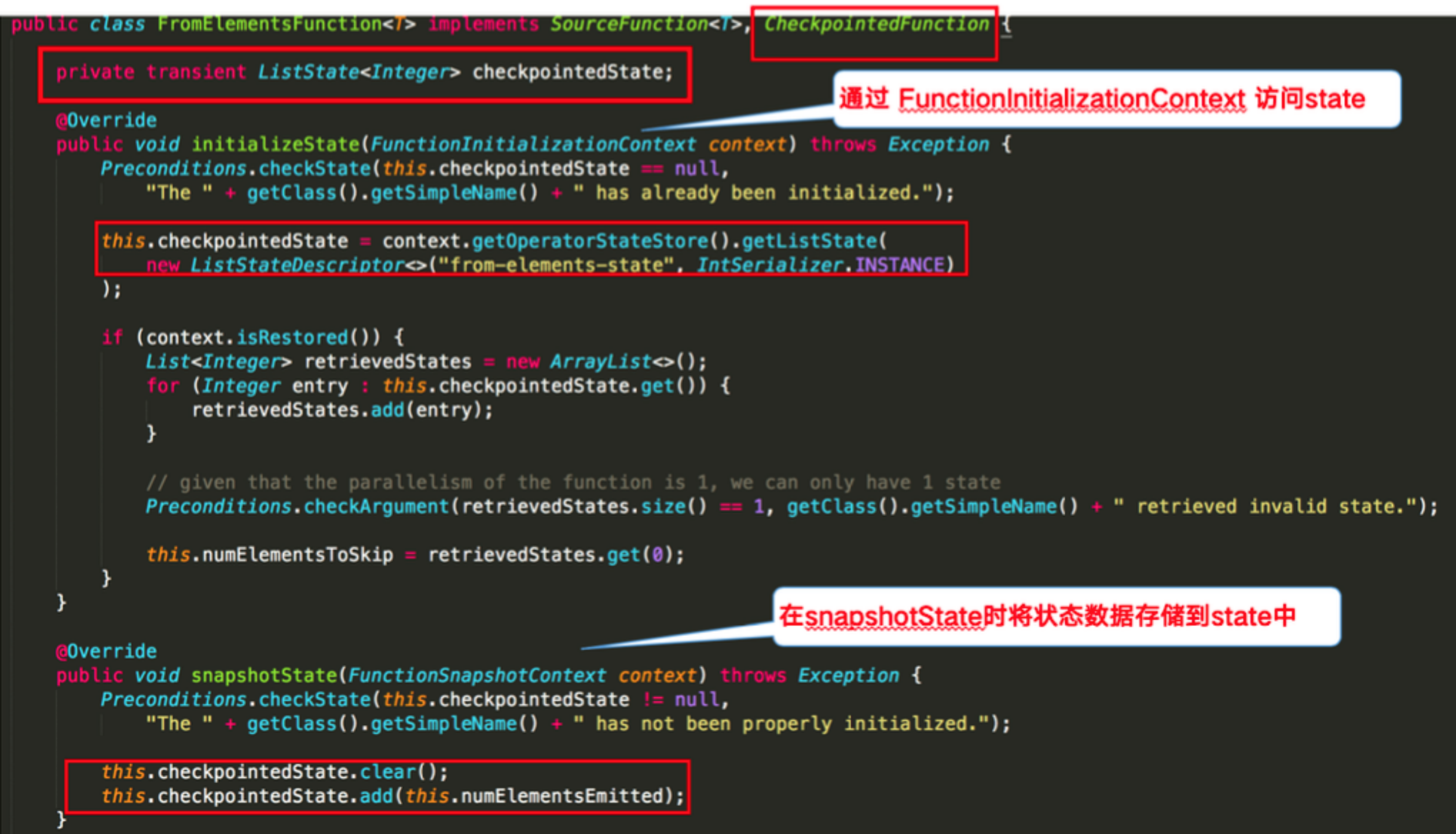
Requirement: use ListState to store offset to simulate Kafka's offset maintenance
Coding steps:
//-1. Declare an OperatorState to record offset
private ListState<Long> offsetState = null;
private Long offset = 0L;
//-2. Create a status descriptor
ListStateDescriptor<Long> descriptor = new ListStateDescriptor<Long>("offsetState", Long.class);
//-3. Get the State according to the State descriptor
offsetState = context.getOperatorStateStore().getListState(descriptor);
//-4. Get the value in State
Iterator<Long> iterator = offsetState.get().iterator();
if (iterator.hasNext()) {//Value in iterator
offset = iterator.next();//The extracted value is offset
}
offset += 1L;
ctx.collect("subTaskId:" + getRuntimeContext().getIndexOfThisSubtask() + ",Current offset by:" + offset);
if (offset % 5 == 0) {//Simulate an exception every 5 messages
//-5. Save State to Checkpoint
offsetState.clear();//Clear the offset stored in memory into Checkpoint
//-6. Store offset in State
offsetState.add(offset);
Example code:
/**
* OperatorState
*
* @author : YangLinWei
* @createTime: 2022/3/8 12:17 morning
*/
public class OperatorState {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//First, directly use the following code to set the Checkpoint interval and disk path, as well as the restart strategy after the code encounters an exception, which will be learned in the afternoon
env.enableCheckpointing(1000);//Execute Checkpoint every 1s
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//Fixed delay restart strategy: when the program is abnormal, restart twice with a delay of 3 seconds each time. If more than twice, the program exits
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 3000));
//2.Source
DataStreamSource<String> sourceData = env.addSource(new MyKafkaSource());
//3.Transformation
//4.Sink
sourceData.print();
//5.execute
env.execute();
}
/**
* MyKafkaSource It is the simulated FlinkKafkaConsumer and maintains offset
*/
public static class MyKafkaSource extends RichParallelSourceFunction<String> implements CheckpointedFunction {
//-1. Declare an OperatorState to record offset
private ListState<Long> offsetState = null;
private Long offset = 0L;
private boolean flag = true;
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
//-2. Create a status descriptor
ListStateDescriptor descriptor = new ListStateDescriptor("offsetState", Long.class);
//-3. Initialize the state according to the state descriptor
offsetState = context.getOperatorStateStore().getListState(descriptor);
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
//-4. Get and use the value in the State
Iterator<Long> iterator = offsetState.get().iterator();
if (iterator.hasNext()) {
offset = iterator.next();
}
while (flag) {
offset += 1;
int id = getRuntimeContext().getIndexOfThisSubtask();
ctx.collect("partition:" + id + "Consumed offset Location is:" + offset);//1 2 3 4 5 6
//Thread.sleep(1000);
TimeUnit.SECONDS.sleep(2);
if (offset % 5 == 0) {
System.out.println("The program encountered an exception.....");
throw new Exception("The program encountered an exception.....");
}
}
}
@Override
public void cancel() {
flag = false;
}
/**
* The following snapshotState method will store the State information in the Checkpoint / disk at a fixed time interval, that is, take a snapshot on the disk!
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
//-5. Save State to Checkpoint
offsetState.clear();//Clear the offset stored in memory into Checkpoint
//-6. Store offset in State
offsetState.add(offset);
}
}
}
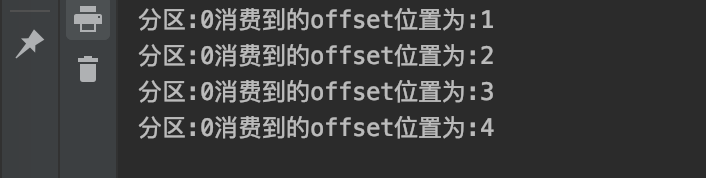
Operation results:
07 end of text
This article mainly explains the state management in Flink advanced API. Thank you for reading. The end of this article!