01 introduction
In the previous blog, we learned the advanced features of Flink. Interested students can refer to the following:
- Flink tutorial (01) - Flink knowledge map
- Flink tutorial (02) - getting started with Flink
- Flink tutorial (03) - Flink environment construction
- Flink tutorial (04) - getting started with Flink
- Flink tutorial (05) - simple analysis of Flink principle
- Flink tutorial (06) - Flink batch streaming API (Source example)
- Flink tutorial (07) - Flink batch streaming API (Transformation example)
- Flink tutorial (08) - Flink batch streaming API (Sink example)
- Flink tutorial (09) - Flink batch streaming API (Connectors example)
- Flink tutorial (10) - Flink batch streaming API (others)
- Flink tutorial (11) - Flink advanced API (Window)
- Flink tutorial (12) - Flink advanced API (Time and Watermaker)
- Flink tutorial (13) - Flink advanced API (state management)
- Flink tutorial (14) - Flink advanced API (fault tolerance mechanism)
- Flink tutorial (15) - Flink advanced API (parallelism)
- Flink tutorial (16) - Flink Table and SQL
- Flink tutorial (17) - Flink Table and SQL (cases and SQL operators)
- Flink tutorial (18) - Flink phase summary
- Flink tutorial (19) - Flink advanced features (BroadcastState)
- Flink tutorial (20) - Flink advanced features (dual stream Join)
- Flink tutorial (21) - end to end exactly once
- Flink tutorial (22) - Flink advanced features (asynchronous IO)
- Flink tutorial (23) - Streaming File Sink
- Flink tutorial (24) - Flink advanced features (File Sink)
- Flink tutorial (25) - Flink advanced features (FlinkSQL integration Hive)
This article mainly explains Flink multilingual development.
reference resources: https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/scala_api_extensions.html
02 Scala-Flink
2.1 requirements
Use Flink to receive the e-commerce click stream log data from Kafka and process it in real time:
- Data preprocessing: broaden the data, that is, turn the data into a wide table for subsequent analysis
- Analyze real-time channel hotspots
- Analyze real-time channel PV/UV
2.2 preparation
kafka:
View theme: /export/servers/kafka/bin/kafka-topics.sh --list --zookeeper node01:2181 create themes: /export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 3 --topic pyg Review the topic again: /export/servers/kafka/bin/kafka-topics.sh --list --zookeeper node01:2181 Launch console consumer /export/servers/kafka/bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --from-beginning --topic pyg Delete theme--No execution required /export/servers/kafka/bin/kafka-topics.sh --delete --zookeeper node01:2181 --topic pyg
Prepare skeleton code for import:
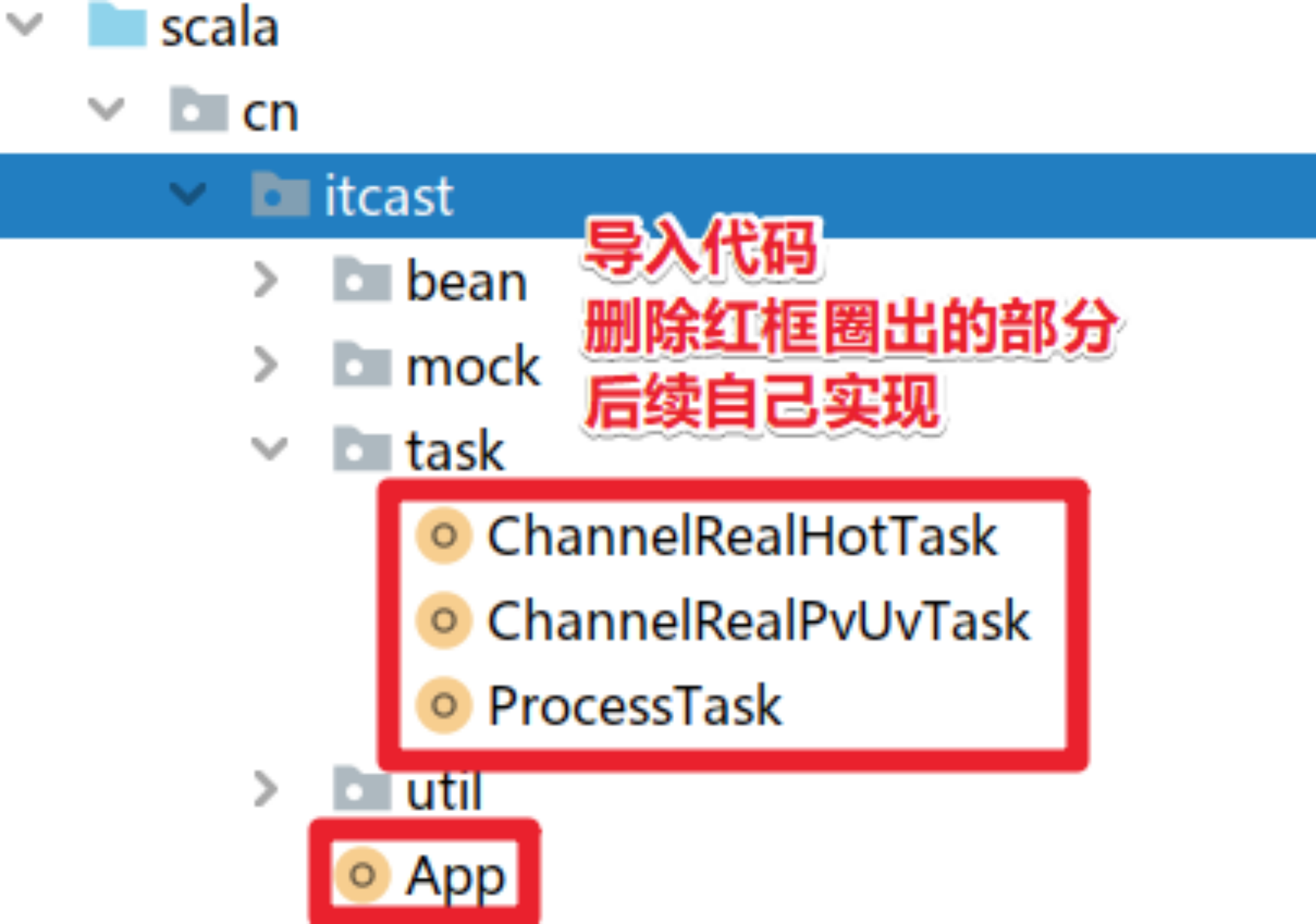
2.3 code implementation
2.3.1 entry class - Data Analysis
object App {
def main(args: Array[String]): Unit = {
//Note: TODO indicates that this step has not been completed during development and needs to be completed later
//Here is just to use different colors to distinguish the steps
//TODO 1. Preparing the StreamExecutionEnvironment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//TODO 2. Set environment parameters (Checkpoint / restart policy / whether to use event time...)
//=================Recommended must be set===================
//Set the state backend of checkpoint state to FsStateBackend, use local path for local test, and use the path of incoming HDFS for cluster test
if(args.length<1){
env.setStateBackend(new FsStateBackend("file:///D:/ckp"))
}else{
env.setStateBackend(new FsStateBackend(args(0)))//Incoming during subsequent cluster tests hdfs://node01:8020/flink-checkpoint/checkpoint
}
//Set the Checkpoint interval to 1000ms, which means that the interval between two checkpoints is 1000ms. The more frequently Checkpoint is used, the easier it is to recover data. At the same time, Checkpoint will consume some IO accordingly.
env.enableCheckpointing(1000)//(by default, if the time is not set, checkpoint is not enabled)
//Set the minimum waiting time between two checkpoints. For example, set the minimum waiting time between checkpoints to be 500ms (in order to avoid that the previous time is too slow and the latter time overlaps when doing Checkpoint every 1000ms)
//For example, on the expressway, one vehicle is released at the gate every 1s, but the minimum distance between two vehicles is 500m
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)//The default is 0
//Set whether to fail the overall task if an error occurs in the process of Checkpoint: true is false, not true
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)//The default is true
//Set whether to clear checkpoints, indicating whether to keep the current Checkpoint when canceling. The default Checkpoint will be deleted when the job is cancelled
//ExternalizedCheckpointCleanup. DELETE_ ON_ Cancelation: true. When the job is cancelled, the external checkpoint is deleted (the default value)
//ExternalizedCheckpointCleanup. RETAIN_ ON_ Cancel: false. When the job is cancelled, the external checkpoint will be reserved
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//=================Recommended must be set===================
//=================Just use the default===============
//Set the execution mode of checkpoint to actual_ Once (default), note: external support is required, such as Source and Sink support
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//Set the timeout time of the Checkpoint. If the Checkpoint has not been completed within 60s, it means that the Checkpoint fails, it will be discarded.
env.getCheckpointConfig.setCheckpointTimeout(60000)//Default 10 minutes
//Set how many checkpoint s can be executed at the same time
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)//The default is 1
//=================Just use the default===============
//======================Configure restart policy==============
//1. If Checkpoint is configured without a restart policy, the program will restart indefinitely when a non fatal error occurs in the code
//2. Configure no restart policy
//env.setRestartStrategy(RestartStrategies.noRestart())
//3. Fixed delay restart strategy -- used in development
//As follows: in case of abnormality, restart once every 10s, up to 3 times
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // Up to 3 restarts
org.apache.flink.api.common.time.Time.of(10, TimeUnit.SECONDS) // Restart interval
))
//4. Failure rate restart strategy - occasionally used by developers
//As follows: restart up to 3 times within 5 minutes, with an interval of 10 minutes
/*env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // Maximum number of failures per measurement interval
Time.of(5, TimeUnit.MINUTES), //Time interval for failure rate measurement
Time.of(10, TimeUnit.SECONDS) // Time interval between two consecutive restarts
))*/
//======================Configure restart policy==============
//TODO 3.Source-Kafka
val topic: String = "pyg"
val schema = new SimpleStringSchema()
val props:Properties = new Properties()
props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG,"node1:9092")
props.setProperty("group.id","flink")
props.setProperty("auto.offset.reset","latest")//If there is a recorded offset, it will be consumed from the recorded position. If not, it will be consumed from the latest data
props.setProperty("flink.partition-discovery.interval-millis","5000")//Dynamic partition detection: start a background thread to check the partition status of Kafka every 5s
val kafkaSource: FlinkKafkaConsumer[String] = new FlinkKafkaConsumer[String](topic,schema,props)
kafkaSource.setCommitOffsetsOnCheckpoints(true)//When the Checkpoint is executed, the offset will be submitted (one in the Checkpoint and one in the default topic)
val jsonStrDS: DataStream[String] = env.addSource(kafkaSource)
//jsonStrDS.print()
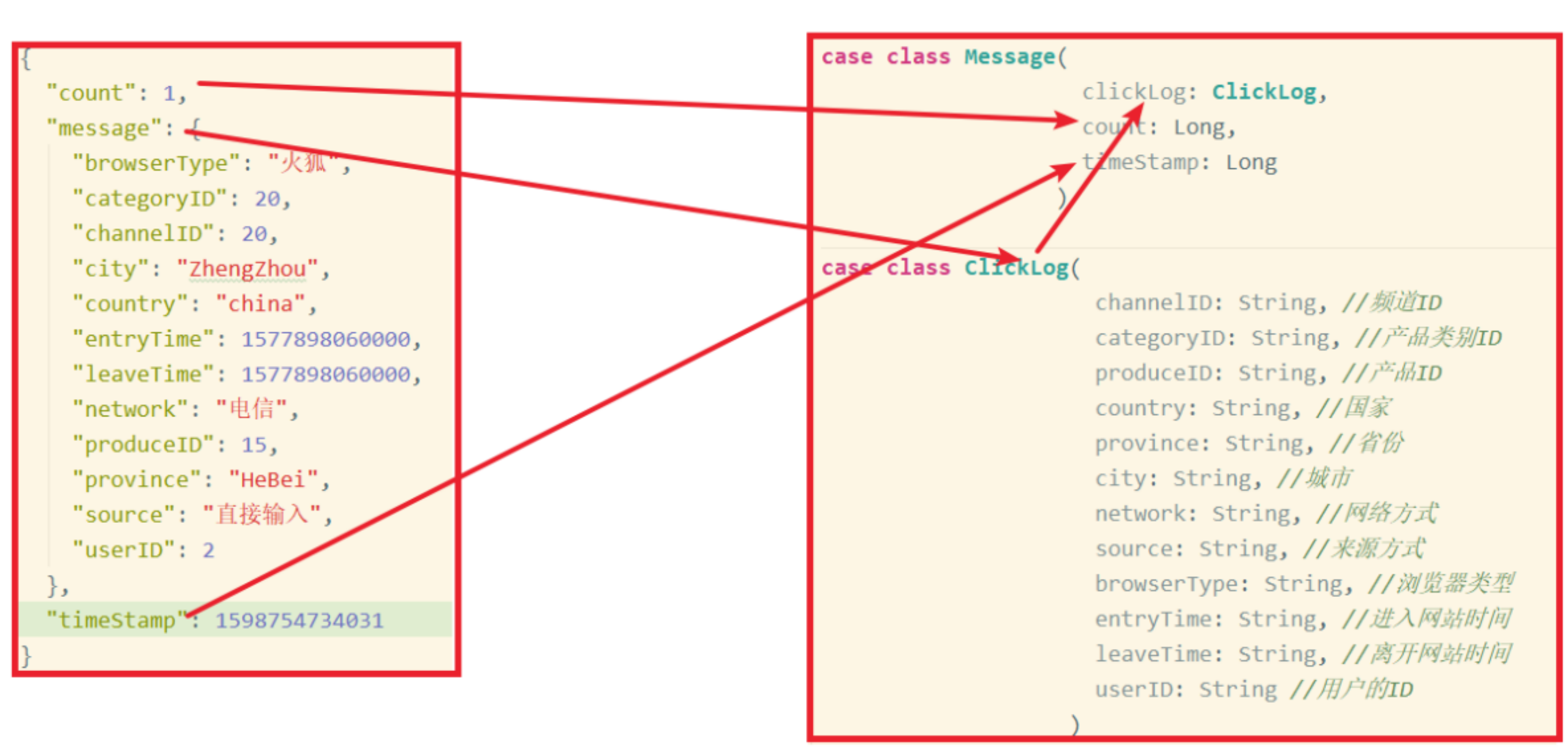
// {"count":1,"message":"{\"browserType \ ": \" Firefox \ ", \" categoryID\":20,\"channelID\":20,\"city\":\"ZhengZhou\",\"country\":\"china\",\"entryTime\":1577898060000,\"leaveTime\":1577898060000,\"network \ ": \" Telecom \ ", \" produceID\":15,\"province\":\"HeBei\",\"source \ ": \" direct input \ ", \" userid \ ": 2}, timestamp: 1598754734031}
//TODO 4. Parse jsonStr data into sample class Message
val messageDS: DataStream[Message] = jsonStrDS.map(jsonStr => {
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
val count: lang.Long = jsonObj.getLong("count")
val timeStamp: lang.Long = jsonObj.getLong("timeStamp")
val clickLogStr: String = jsonObj.getString("message")
val clickLog: ClickLog = JSON.parseObject(clickLogStr, classOf[ClickLog])
Message(clickLog, count, timeStamp)
//You can't use the following lazy methods
//val message: Message = JSON.parseObject(jsonStr,classOf[Message])
})
//messageDS.print()
//Message(ClickLog(10,10,3,china,HeBei,ZhengZhou, telecom, 360 search jump, Google browser, 15778776460000157789806000,15), 11598754740100)
//TODO 5. Add watermaker to the data (or put it in step 6)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(200)
val watermakerDS: DataStream[Message] = messageDS.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[Message](org.apache.flink.streaming.api.windowing.time.Time.seconds(5)) {
override def extractTimestamp(element: Message): Long = element.timeStamp
}
)
//TODO 6. Data preprocessing
//In order to facilitate subsequent indicator statistics, you can preprocess the log Message parsed above, such as broadening the field
//The preprocessing code can be written here, or a method can be extracted separately, or an object can be extracted separately Method to complete
//Expand [datastream] to [datastream]
val clickLogWideDS: DataStream[ClickLogWide] = ProcessTask.process(watermakerDS)
clickLogWideDS.print()
//Clicklogwide (18,9,10, China, Henan, Luyang, mobile, baidu jump, Google browser, 1577887260001, 577898060000,15,11598758614216, China Henan Luyang, 20200820200830202020083081011,0,0,0,0,0)
//TODO 7. Real time index statistical analysis - direct sink results to HBase
//Statistical analysis of real-time indicators - hot spots of real-time channels
ChannelRealHotTask.process(clickLogWideDS)
//Statistical analysis of real-time indicators - real-time channel time division PV/UV
ChannelRealPvUvTask.process(clickLogWideDS)
//TODO 8.execute
env.execute()
}
}
2.3.2 data preprocessing
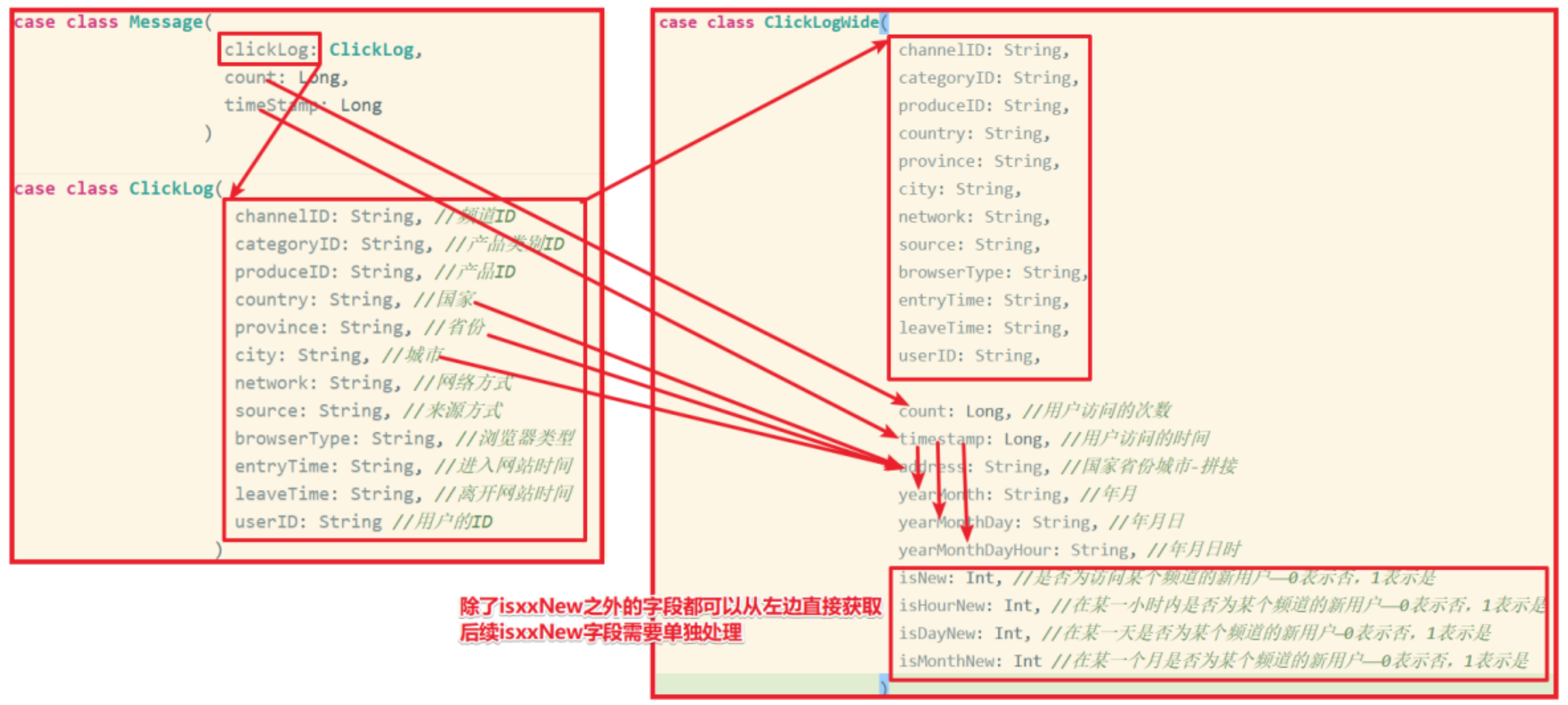
In order to facilitate subsequent analysis, we need to use Flink to preprocess the click stream log in real time. Add some fields on the basis of the original click stream log to facilitate the statistical development of subsequent business functions.
The following are the original click stream log fields obtained from consumption in Kafka:
Field name Description
channelID channel ID
categoryID product category ID
produceID product ID
Country country
province
city City
network mode
Source source method
browserType browser type
entryTime time of entering the website
leaveTime time to leave the website
userID ID of the user
We need to add the following fields on the basis of the original click stream log fields:
Field name Description
count number of user visits
timestamp user access time
address country, province and city (splicing)
yearMonth
yearMonthDay
yearMonthDayHour
Is isNew a new user accessing a channel
Is isHourNew a new user of a channel within an hour
Is isDayNew a new user of a channel on a certain day
Is isMonthNew a new user of a channel in a certain month
We cannot directly calculate the values of the last four fields from the click stream log. Instead, you need to have a history table in hbase to save the user's historical access status before you can calculate it.
The structure of the user_history table is as follows:
Example of column name Description
rowkey user ID: channel ID 10:220
userid user ID 10
channelid 220
lastVisitedTime last access time (timestamp) 1553653555
/**
* Author itcast
* Desc Business tasks of data preprocessing module
*/
object ProcessTask {
//Convert the original user behavior log data with watermark into wide table ClickLogWide and return it as required
//Convert DataStream[Message] to DataStream[ClickLogWide]
def process(watermakerDS: DataStream[Message]): DataStream[ClickLogWide] = {
import org.apache.flink.api.scala._
val clickLogWideDS: DataStream[ClickLogWide] = watermakerDS.map(message => {
val address: String = message.clickLog.country + message.clickLog.province + message.clickLog.city
val yearMonth: String = TimeUtil.parseTime(message.timeStamp, "yyyyMM")
val yearMonthDay: String = TimeUtil.parseTime(message.timeStamp, "yyyyMMdd")
val yearMonthDayHour: String = TimeUtil.parseTime(message.timeStamp, "yyyyMMddHH")
val (isNew, isHourNew, isDayNew, isMonthNew) = getIsNew(message)
val clickLogWide = ClickLogWide(
message.clickLog.channelID,
message.clickLog.categoryID,
message.clickLog.produceID,
message.clickLog.country,
message.clickLog.province,
message.clickLog.city,
message.clickLog.network,
message.clickLog.source,
message.clickLog.browserType,
message.clickLog.entryTime,
message.clickLog.leaveTime,
message.clickLog.userID,
message.count, //Number of user visits
message.timeStamp, //User access time
address, //Country, province and city - splicing
yearMonth, //years
yearMonthDay, //specific date
yearMonthDayHour, //Mm / DD / yyyy
isNew, //Is it a new user accessing a channel - 0 means no, 1 means yes
isHourNew, //Whether you are a new user of a channel within a certain hour - 0 means no, 1 means yes
isDayNew, //Whether you are a new user of a channel on a certain day - 0 means no, 1 means yes
isMonthNew //Whether you are a new user of a channel in a certain month - 0 means no, 1 means yes
)
clickLogWide
})
clickLogWideDS
}
/*For example, a user accesses this channel for the first time on August 30, 2020
So this log
isNew=1
isHourNew=1
isDayNew=1
isMonthNew=1
The user will visit again on August 30, 2020
Then this log:
isNew=0
isHourNew=0
isDayNew=0
isMonthNew=0
The user will visit again on August 30, 2020
isNew=0
isHourNew=1
isDayNew=0
isMonthNew=0
The user will visit again on August 31, 2020
isNew=0
isHourNew=1
isDayNew=1
isMonthNew=0*/
def getIsNew(msg: Message):(Int,Int,Int,Int) = {
var isNew: Int = 0 //Is it a new user accessing a channel - 0 means no, 1 means yes
var isHourNew: Int = 0 //Whether you are a new user of a channel within a certain hour - 0 means no, 1 means yes
var isDayNew: Int = 0 //Whether you are a new user of a channel on a certain day - 0 means no, 1 means yes
var isMonthNew: Int = 0//Whether you are a new user of a channel in a certain month - 0 means no, 1 means yes
//How to judge whether the user is each isxxNew of the channel?
//The access time of the last time the user accessed the channel can be recorded in an external medium, such as HBase
//Enter a log and go to HBase to check the lastVisitTime of the user and the channel
//No results -- isxxNew is all 1
//There are results -- compare the visit time with lastVisitTime
//1. Define some HBase constants, such as table name, column family name and field name
val tableName = "user_history"
val columnFamily = "info"
val rowkey = msg.clickLog.userID + ":" + msg.clickLog.channelID
val queryColumn = "lastVisitTime"
//2. Check lastVisitTime according to the channel of the user
//Note: remember to modify resources / HBase site The host name in XML and HBase have to be started
val lastVisitTime: String = HBaseUtil.getData(tableName,rowkey,columnFamily,queryColumn)
//3. Judge whether lastVisitTime has a value
if(StringUtils.isBlank(lastVisitTime)){
//If lastVisitTime is empty, it means that the user has not accessed the channel before, and all can be set to 1
isNew = 1
isHourNew = 1
isDayNew = 1
isMonthNew = 1
}else{
//If lastVisitTime is not empty, it indicates that the user has accessed the channel before, and isxxNew assigns values to the user according to the situation
//For example, if lastVisitTime is 2020-08-30-11 and the current visit time is 2020-08-30-12, isHourNew=1 and others are 0
//For example, if lastVisitTime is 2020-08-30 and the current access time is 2020-08-31, isDayNew=1 and others are 0
//For example, if lastVisitTime is 2020-08 and the current access time is 2020-09, isMonthNew=1 and others are 0
isNew = 0
isHourNew = TimeUtil.compareDate(msg.timeStamp,lastVisitTime.toLong,"yyyyMMddHH")
isDayNew = TimeUtil.compareDate(msg.timeStamp,lastVisitTime.toLong,"yyyyMMdd")
isMonthNew = TimeUtil.compareDate(msg.timeStamp,lastVisitTime.toLong,"yyyyMM")
}
//Don't forget to save this visit time into HBase as lastVisitTime
HBaseUtil.putData(tableName,rowkey,columnFamily,queryColumn,msg.timeStamp.toString)
(isNew,isHourNew,isDayNew,isMonthNew)
//be careful:
/*
Start hbase before testing
/export/servers/hbase/bin/start-hbase.sh
Then log in to hbase shell
./hbase shell
View hbase table
list
After running, the table will be generated, and then the table data will be viewed
scan "user_history",{LIMIT=>10}
*/
}
}
2.3.3 real time channel hotspot
Channel hotspot is to count the number of channels accessed (clicked).
The following data are obtained from the analysis:

The historical click data needs to be accumulated
object ChannelRealHotTask {
//Define a sample class to encapsulate the channel id and access times
case class ChannelRealHot(channelId: String, visited: Long)
//According to the incoming user behavior log width table, statistical analysis of channel access times is carried out, and the results are saved to HBase
def process(clickLogWideDS: DataStream[ClickLogWide]) = {
import org.apache.flink.api.scala._
//1. Take out the fields channelID and count we need and encapsulate them into sample classes
val result: DataStream[ChannelRealHot] = clickLogWideDS
.map(clickLogWide => {
ChannelRealHot(clickLogWide.channelID, clickLogWide.count)
})
//2. Grouping
.keyBy(_.channelId)
//3. Window
//ize: Time, slide: Time
//Demand: count the access times of each channel every 10s
.timeWindow(Time.seconds(10))
//4. Polymerization
.reduce((c1, c2) => {
ChannelRealHot(c2.channelId, c1.visited + c2.visited)
})
//5. The results are stored in HBase
result.addSink(new SinkFunction[ChannelRealHot] {
override def invoke(value: ChannelRealHot, context: SinkFunction.Context): Unit = {
//Call HBaseUtil here to save each result (the number of accesses per channel) to HBase
//-1. Check the last access times of HBase channel first
val tableName = "channel_realhot"
val columnFamily = "info"
val queryColumn = "visited"
val rowkey = value.channelId
val historyValueStr: String = HBaseUtil.getData(tableName, rowkey, columnFamily, queryColumn)
var currentFinalResult = 0L
//-2. Judge and combine the results
if (StringUtils.isBlank(historyValueStr)) {
//If historyValueStr is empty, directly let the number of times this time be the final result of this time and save it
currentFinalResult = value.visited
} else {
//If historyValueStr is not empty, the number of times + historical value of this time will be taken as the final result of this time and saved
currentFinalResult = value.visited + historyValueStr.toLong
}
//-3. Save the final results
HBaseUtil.putData(tableName, rowkey, columnFamily, queryColumn, currentFinalResult.toString)
}
})
}
}
2.3.4 real time channel PV/UV
PV (traffic volume) is Page View, and page refresh is calculated once.
UV (Unique Visitor), that is, the same client is calculated only once within the specified time
The data obtained after statistical analysis are as follows:

object ChannelRealPvUvTask {
case class ChannelRealPvUv(channelId: String, monthDayHour: String, pv: Long, uv: Long)
def process(clickLogWideDS: DataStream[ClickLogWide]) = {
import org.apache.flink.api.scala._
//be careful:
// Each wide table log has three fields: Yearmonth, yearmonthday and yearmonthdayhour,
// According to the demand, we need to convert one log into three pieces of data according to these three fields, so as to facilitate the later statistics of PV/UV in different periods
// That is to say, every piece of data should be changed into 3 pieces of data now!
//Using flatMap
//Zhang San, Changping, Beijing, China
// -->
//China, Zhang San
//Zhang San, Beijing, China
//Zhang San, Changping, Beijing, China
//1. Data conversion
val result: DataStream[ChannelRealPvUv] = clickLogWideDS.flatMap(clickLogWide => {
List(
ChannelRealPvUv(clickLogWide.channelID, clickLogWide.yearMonth, clickLogWide.count, clickLogWide.isMonthNew),
ChannelRealPvUv(clickLogWide.channelID, clickLogWide.yearMonthDay, clickLogWide.count, clickLogWide.isDayNew),
ChannelRealPvUv(clickLogWide.channelID, clickLogWide.yearMonthDayHour, clickLogWide.count, clickLogWide.isHourNew)
)
})
//2. Grouping
.keyBy("channelId", "monthDayHour")
//3. Window
.timeWindow(Time.seconds(10))
//4. Polymerization
.reduce((c1, c2) => {
ChannelRealPvUv(c2.channelId, c2.monthDayHour, c1.pv + c2.pv, c1.uv + c2.uv)
})
//5. Save the results to HBase
//Note: if the performance of HBase can't keep up during the test after class, you can print directly and see the results. Just read the sink below!
//result.print()
result.addSink(new SinkFunction[ChannelRealPvUv] {
override def invoke(value: ChannelRealPvUv, context: SinkFunction.Context): Unit = {
//-1. Check
val tableName = "channel_pvuv"
val columnFamily = "info"
val queryColumn1 = "pv"
val queryColumn2 = "uv"
val rowkey = value.channelId + ":" + value.monthDayHour
val map: Map[String, String] = HBaseUtil.getMapData(tableName,rowkey,columnFamily,List(queryColumn1,queryColumn2))
/* val pvhistoryValueStr: String = map.getOrElse(queryColumn1,null)
val uvhistoryValueStr: String = map.getOrElse(queryColumn2,null)
//-2.close
var currentFinalPv = 0L
var currentFinalUv = 0L
if(StringUtils.isBlank(pvhistoryValueStr)){
//If the value of this channel is null, the value of this channel will be taken as the final value of this channel
currentFinalPv = value.pv
}else{
//If pvhistoryValueStr is not empty, pv + pvhistoryValueStr of this time period of this channel will be taken as the final result of this time period of this channel
currentFinalPv = value.pv + pvhistoryValueStr.toLong
}
if(StringUtils.isBlank(uvhistoryValueStr)){
//If uvhistoryValueStr is empty, the uv of this channel in this period will be directly taken as the final result of this channel in this period
currentFinalUv = value.uv
}else{
//If uvhistoryValueStr is not empty, take the uv + uvhistoryValueStr of this channel in this period as the final result of this channel in this period
currentFinalUv = value.uv + uvhistoryValueStr.toLong
}*/
val pvhistoryValueStr: String = map.getOrElse(queryColumn1,"0")
val uvhistoryValueStr: String = map.getOrElse(queryColumn2,"0")
val currentFinalPv = value.pv + pvhistoryValueStr.toLong
val currentFinalUv = value.uv + uvhistoryValueStr.toLong
//-3. Deposit
HBaseUtil.putMapData(tableName,rowkey,columnFamily,
Map(
(queryColumn1,currentFinalPv),
(queryColumn2,currentFinalUv)
)
)
}
})
}
}
03 Py-Flink
Environment preparation
pip install apache-flink
It needs to be installed under the condition of good network environment, which is estimated to take about 2 hours, because it needs to download many other dependencies
3.2 official documents
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/python/datastream_tutorial.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/python/table_api_tutorial.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/api/python/
3.3 example code
from pyflink.common.serialization import SimpleStringEncoder
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import StreamingFileSink
def tutorial():
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
ds = env.from_collection(
collection=["hadoop spark flink","hadoop spark","hadoop"],
type_info=Types.STRING()
)
ds.print()
result = ds.flat_map(lambda line: line.split(" "), result_type=Types.STRING())\
.map(lambda word: (word, 1),output_type=Types.ROW([Types.STRING(), Types.INT()]))\
.key_by(lambda x: x[0],key_type_info=Types.STRING())\
.reduce(lambda a, b: a + b)
result.print()
result.add_sink(StreamingFileSink
.for_row_format('data/output/result1', SimpleStringEncoder())
.build())
env.execute("tutorial_job")
if __name__ == '__main__':
tutorial()
from pyflink.dataset import ExecutionEnvironment
from pyflink.table import TableConfig, DataTypes, BatchTableEnvironment
from pyflink.table.descriptors import Schema, OldCsv, FileSystem
from pyflink.table.expressions import lit
exec_env = ExecutionEnvironment.get_execution_environment()
exec_env.set_parallelism(1)
t_config = TableConfig()
t_env = BatchTableEnvironment.create(exec_env, t_config)
t_env.connect(FileSystem().path('data/input')) \
.with_format(OldCsv()
.field('word', DataTypes.STRING())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())) \
.create_temporary_table('mySource')
t_env.connect(FileSystem().path('/tmp/output')) \
.with_format(OldCsv()
.field_delimiter('\t')
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.with_schema(Schema()
.field('word', DataTypes.STRING())
.field('count', DataTypes.BIGINT())) \
.create_temporary_table('mySink')
tab = t_env.from_path('mySource')
tab.group_by(tab.word) \
.select(tab.word, lit(1).count) \
.execute_insert('mySink').wait()
04 end
This article mainly explains a simple example of Flink's multilingual development. Thank you for reading. The end of this article!