
1. General
Reprint and supplement: Flink controls task scheduling: job chain and processing slot sharing group
In order to realize parallel execution, Flink application will divide the operator into different tasks, and then assign these tasks to different processes in the cluster for execution. Like many other distributed systems, the performance of Flink applications largely depends on the scheduling mode of tasks. The work process to which the task is assigned, the coexistence between tasks and the number of tasks in the work process will have a significant impact on the performance of the application. In this section, we will discuss how to improve application performance by adjusting the default behavior and controlling job chain and job allocation (processing slot sharing group).
In fact, these two concepts can be regarded as: resource sharing chain and resource sharing group. When we finish writing a Flink program and start executing from the Client - > jobmanager - > taskmanager - > slot, we will optimize the execution plan submitted by us. Two important optimization processes are: Task chain and processing slot sharing group. The former is to optimize execution efficiency and the latter is to optimize memory resources.
2. Implementation process
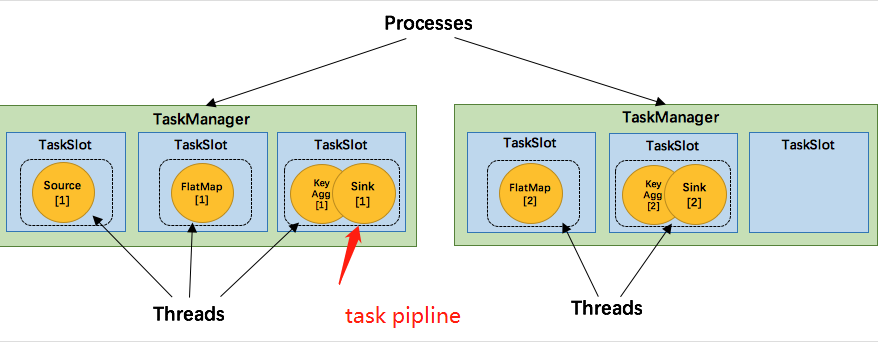
Chain: Flink will try to link multiple operator s together to form a task pipeline. Each task pipline is executed in one thread
Advantages: it can reduce the switching between threads, reduce the serialization / deserialization of messages, reduce the exchange of data in the buffer (i.e. reduce the cost of local data exchange), reduce the delay and improve the overall throughput.
For this, please refer to: [Flink] the collector is very slow. An embarrassing troubleshooting is the difference between the wrong direction chain and not chain
Overview: in the process of converting StreamGraph to JobGraph, the key is to optimize multiple streamnodes into one JobVertex, and the corresponding StreamEdge is converted into JobEdge, and a connection relationship between producers and consumers is formed between JobVertex and JobEdge through IntermediateDataSet (intermediate dataset). Each JobVertex is a Task scheduling unit (Task) of JobManger. In order to avoid the efficiency problems caused by Task execution (data exchange (network transmission) and thread context switching) by placing several highly correlated streamnodes (operators) into different jobvertices (tasks) in this process, Flink will merge the operators that can be optimized into an operator chain (that is, form a Task) in the process of converting StreamGraph to JobGraph. In this way, the operators in this chain can be put into one thread for execution, which improves the efficiency of Task execution.
It can be seen that in the process of converting a StreamGraph to a JobGraph, the characteristics of each streambedge and the two streamnodes connected at both ends of the streambedge are actually reviewed one by one to determine whether the streamnodes at both ends of the streambedge can be combined to form an operator chain. In this judgment process, flick gives clear rules. Let's take a look at isChainable() method in StreamingJobGraphGenerator:
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
/** Gets the source and target StreamNode of StreamEdge */
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
/** Gets the StreamOperator in the source and target StreamNode */
StreamOperatorFactory<?> headOperator = upStreamVertex.getOperatorFactory();
StreamOperatorFactory<?> outOperator = downStreamVertex.getOperatorFactory();
/**
* 1,The downstream node has only one input
* 2,The operator of the downstream node is not null
* 3,The operator of the upstream node is not null
* 4,Upstream and downstream nodes are in a slot sharing group
* 5,The connection strategy of downstream nodes is ALWAYS
* 6,The connection strategy of the upstream node is HEAD or ALWAYS
* 7,edge The partition function of is an instance of ForwardPartitioner
* 8,The parallelism of upstream and downstream nodes is equal
* 9,You can connect nodes
*/
//If the number of incoming edges of downstream flow nodes of an edge is 1 (that is, it is a single input operator)
return downStreamVertex.getInEdges().size() == 1
//The operator corresponding to the downstream node of the edge is not null
&& outOperator != null
//The operator corresponding to the upstream node of the edge is not null
&& headOperator != null
//The nodes at both ends of the edge have the same slot sharing group name
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
//The link strategy of the edge downstream operator is ALWAYS
&& outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
&& (headOperator.getChainingStrategy() == ChainingStrategy.HEAD ||
//The link strategy of the upstream operator is HEAD or ALWAYS
headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS)
//The partition type of the edge is ForwardPartitioner
&& (edge.getPartitioner() instanceof ForwardPartitioner)
&& edge.getShuffleMode() != ShuffleMode.BATCH
//The parallelism of upstream and downstream nodes is equal
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
//The current streamGraph allows linked
&& streamGraph.isChainingEnabled();
}
3. Processing tank sharing group
Processing slot sharing group (multiple tasks are placed in the same slot for a certain purpose)
3.1 Task Slot
TaskManager is a JVM process and executes a task as a separate thread. In order to control how many tasks a task manager can accept, Flink puts forward the concept of Task Slot, which defines the computing resources in Flink. Solt allocates the TaskManager memory evenly. Each solt memory is the same, and the sum is equal to the available memory of TaskManager, but only the memory is isolated, not the cpu. Slotting resources means that tasks from different job s will not compete for memory, but each task has a certain amount of memory reserves.
By adjusting the number of task slot s, users can define how tasks are isolated from each other. Each task manager has a slot, which means that each task runs in a separate JVM. If each task manager has multiple slots, that is, multiple tasks run in the same JVM. Tasks in the same JVM process can share TCP connections (based on Multiplexing) and heartbeat messages, which can reduce the network transmission of data. It can also share some data structures, which reduces the consumption of each task to a certain extent.
3.2 shared slot
Question:
There is at least one slot in A Task manager. Each slot shares memory and is memory isolated, but shares CPU. Operators can be divided into resource intensive and non resource intensive operators according to the computational complexity (it can be considered that some operators have large memory requirements and some operators have small memory requirements). There is such A situation: there are both resource intensive Tasks (A) and non resource intensive Tasks (B) in the Tasks under A Job. They are divided into different slots, which will cause problems:
- Some slots have a high memory utilization rate, while others have a low memory utilization rate, which is very unfair. A slot resource is not fully utilized;
- For the case of limited slot resources, the degree of task parallelism is not high.
Solution
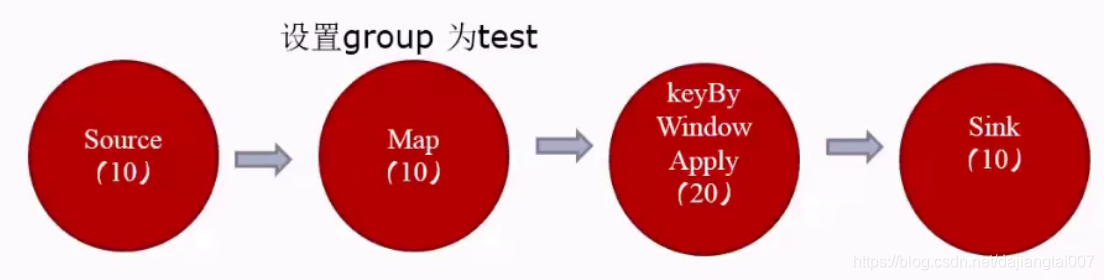
By default, Flink allows subtasks to share slots, provided that they all come from subtasks of different tasks in the same job. As a result, a slot may hold the entire pipeline of the job. Allowing slot sharing has the following two benefits:
-
For the scenario with limited slots, we can increase the parallelism of each task. For example, if SlotSharingGroup is not set and all tasks are in the same shared group by default (all slots can be shared), the task slot required by Flink cluster is exactly the same as the maximum parallelism used in jobs. However, as shown in the above figure, if we forcibly specify the slot sharing group of the map as test, then the map and the downstream group of the map are test, and the sharing group of the upstream source of the map is default. At this time, the maximum parallelism in the default group is 10 and the maximum parallelism in the test group is 20, then the required Slot=10+20=30;
-
Make better use of resources: without slot sharing, those map/source/flatmap subtasks with small resource requirements will occupy the same resources as window/sink with greater resource requirements, and the slot resources are not fully utilized (memory is not fully utilized).
3.2.1 implementation of specific sharing mechanism
Flink determines which tasks need to share slots and which tasks must be placed in a specific slot. Although tasks share slots to improve resource utilization, if there are too many tasks in a slot, it will lead to low resources (for example, in extreme cases, all tasks are distributed in one slot). Therefore, tasks in Flink need to share slots according to certain rules, which are mainly defined by SlotSharingGroup and colocation group:
-
CoLocationGroup: forcing subtask to be placed in the same slot is a hard constraint:
- Ensure that the nth running instance of JobVertices and the nth instance of JobVertices in other same groups operate in the same slot (all subTasks with the same parallelism operate in the same slot);
- It is mainly used for iterative flow (training machine learning model) to ensure that the ith subtask at the beginning and end of the iteration can be scheduled to the same TaskManager.
-
SlotSharingGroup: it is a class used to realize slot sharing in Flink. Different JobVertices are allowed to be deployed in the same slot as far as possible, but this is a wide constraint, which can not be fully guaranteed as far as possible.
- The default group of the operator is default, and all tasks can share the same slot;
- To determine whether the group of an operator without SlotSharingGroup setting is correct, it can be determined jointly according to the group of the upstream operator and whether it sets a group (that is, if the downstream operator does not set a group, it inherits the group of the upstream operator);
- In order to prevent unreasonable sharing, users can forcibly specify the sharing group of the operator through the provided API. Unreasonable sharing of slot resources (for example, all tasks share all slots by default) will lead to an increase in the number of threads running in each slot and increase the machine load. Therefore, proper settings can reduce the number of threads running in each slot, so as to reduce the load of the machine as a whole. For example: somestream filter(...). The slot sharing group ("group1") forces the slot sharing group of the specified filter to be group1.
3.2.2 cases
@Test
public void slotSharingGroupTest() throws Exception {
Configuration configuration = new Configuration();
configuration.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER,true);
configuration.setInteger(ConfigConstants.JOB_MANAGER_WEB_PORT_KEY,7088);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(1,configuration);
env.getConfig().enableObjectReuse();
DataStream<String> text = env.socketTextStream("localhost", 9992, "\n");
SingleOutputStreamOperator<String> map = text.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value;
}
});
SingleOutputStreamOperator<String> filter = map.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return true;
}
}).slotSharingGroup("group_03");
SingleOutputStreamOperator<String> bb = filter.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value;
}
});
SingleOutputStreamOperator<String> cc = bb.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return true;
}
}).slotSharingGroup("group_04");
SingleOutputStreamOperator<String> dd = cc.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value;
}
});
dd.print();
env.execute("xxx");
}
You can see the running results as follows
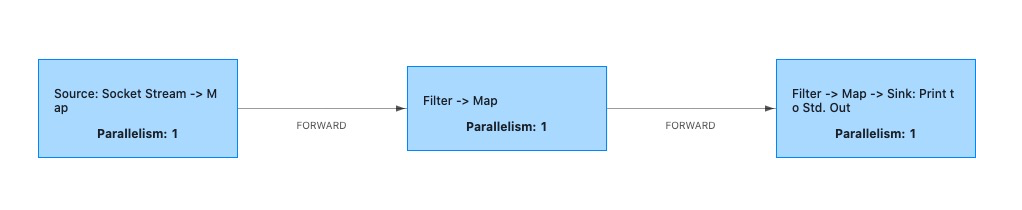
Each slotSharingGroup cannot be chained to each other, and the operators within each slotSharingGroup can be chained together.
But there are some questions:
-
Is it good to do it separately?
-
We are generally default and correct. All chain s are together. Is it more efficient?