catalogue
The new architecture is integrated with the lake warehouse
2, Compile and package Hudi version 0.10.0
1. Use git to clone the latest master on github
1. Main contents of POM document
4.hudi code (refer to the official website for specific parameters)
5. Capture mysql changes and write them to hudi
2. View the contents of the hdfs partition after inserting data
2. Log in to hive client connection tool
The new architecture is integrated with the lake warehouse
Through the integration of Lake warehouse and flow batch, we can achieve: Data homology, the same computing engine, the same storage and the same computing caliber in the quasi real-time scenario. The timeliness of data can reach the minute level, which can well meet the needs of business quasi real-time data warehouse. The following is the architecture diagram:
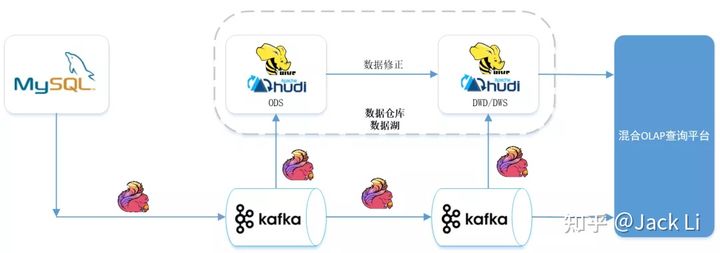
MySQL data enters Kafka through Flink CDC. The reason why the data enters Kafka first rather than directly into Hudi is to reuse the data from MySQL for multiple real-time tasks, so as to avoid the impact on the performance of MySQL database caused by multiple tasks connecting MySQL tables and Binlog through Flink CDC.
In addition to the ODS layer of the offline data warehouse, the data entered into Kafka through CDC will be transferred from ODS - > DWD - > DWS - > OLAP database according to the link of the real-time data warehouse, and finally used for data services such as reports. The result data of each layer of the real-time data warehouse will be sent to the offline data warehouse in quasi real time. In this way, the program is developed once, the index caliber is unified, and the data is unified.
From the architecture diagram, we can see that there is a step of data correction (rerunning historical data). The reason for this step is that there may be rerunning historical data due to caliber adjustment or error in the calculation result of the real-time task of the previous day.
The data stored in Kafka has expiration time and will not store historical data for too long. The historical data that runs for a long time cannot obtain historical source data from Kafka. Moreover, if a large amount of historical data is pushed to Kafka again and the historical data is corrected through the link of real-time calculation, the real-time operation of the day may be affected. Therefore, the rerun history data will be processed through data correction.
Generally speaking, this architecture is a hybrid architecture of Lambda and Kappa. Each data link of the stream batch integrated data warehouse has a data quality verification process. The next day, the data of the previous day is reconciled. If the data calculated in real time the previous day is normal, there is no need to correct the data. The Kappa architecture is sufficient.
(this section is quoted from the practice of 37 mobile games based on Flink CDC + Hudi Lake warehouse integration scheme)
1, Version Description
flink 1.13.1
flinkcdc 2.0.2
hudi 0.10.0
hive 3.1.2
mysql 5.7+
Code environment idea
2, Compile and package Hudi version 0.10.0
1. Use git to clone the latest master on github
Enter the folder and right-click git bash here to enter git command line mode
Clone Hudi source code git clone https://github.com/apache/hudi.git
Switch to the 0.10.0 branch git checkout release-0.10.0
2. Compilation and packaging
First at $Hudi_ Execute the command mvn clean install -DskipTests in the home directory
Then enter the packaging / Hudi flex bundle directory and type bundle jar as follows
mvn install -DskipTests -Drat.skip=true -Pflink-bundle-shade-hive3
# If it's hive2 profile -Pflink-bundle-shade-hive2 is required # If it is hive1, you need to use profile -Pflink-bundle-shade-hive1 #Note 1: hive1.x can only synchronize metadata to hive, but can't use hive query. If you need to query, you can use spark to query hive appearance. #Note 2: using - pflink bundle shade hive x, you need to modify the hive version in the profile to the corresponding version of the cluster (you only need to modify the hive version in the profile). Modify the corresponding profile section at the bottom of packaging / hudi-flex-bundle / pom.xml. After finding it, modify the hive version in the profile to the corresponding version.
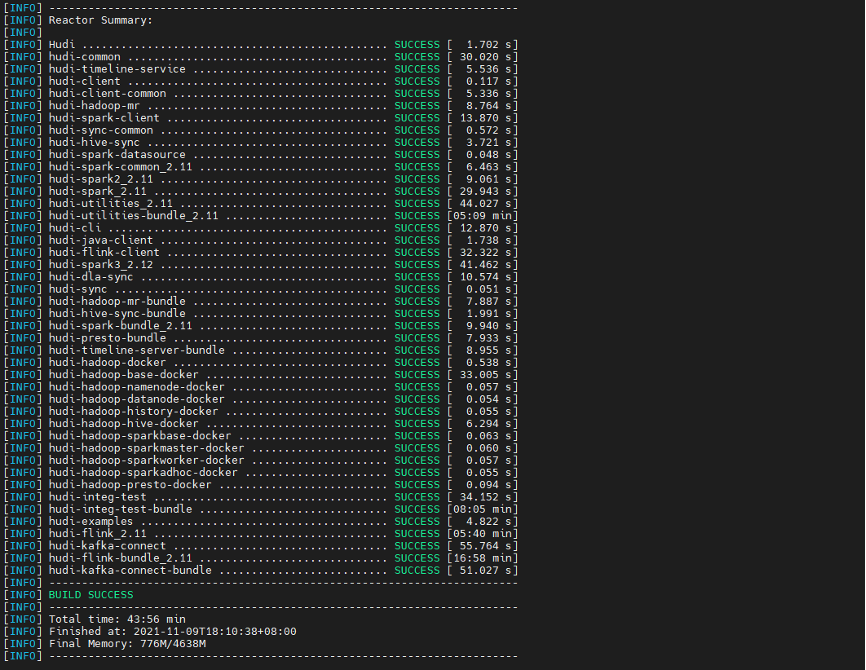
(if Hudi Intel test or Hudi Intel test bundle fails to compile, you can enter the pom file under the root directory and note out these two module s.)
3, Create a flick project
1. Main contents of POM document
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<encoding>UTF-8</encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<scala.version>2.12</scala.version>
<flink.version>1.13.1</flink.version>
<mysql-connector.version>5.1.44</mysql-connector.version>
</properties>
<dependencies>
<!-- hudi Correlation dependency -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-bundle_2.12</artifactId>
<version>0.10.0-rc2</version>
</dependency>
<!-- cdc Correlation dependency -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.2</version>
</dependency>
<!-- flink Correlation dependency -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.12</artifactId>
<version>1.10.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- hdfs Correlation dependency -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<!-- mysql Correlation dependency -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector.version}</version>
</dependency>
</dependencies>2.checkpoint
//1.1 turn on CK and specify the status as FS
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://hadoop1:8020/flink/checkpoints/hudi-flink"));
env.enableCheckpointing(60000L); //Head and head
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(30000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000L); //Tail and head
3.flinkcdc code
String source_table = "CREATE TABLE mysql_users (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
" ) WITH (\n" +
" 'connector'= 'mysql-cdc',\n" +
" 'hostname'= '*.*.*.*',\n" +
" 'port'= '3306',\n" +
" 'username'= 'root',\n" +
" 'password'='123456',\n" +
" 'server-time-zone'= 'Asia/Shanghai',\n" +
" 'debezium.snapshot.mode'='initial',\n" +
" 'database-name'= 'test',\n" +
" 'table-name'= 'users_cdc'\n" +
")";4.hudi code (refer to the official website for specific parameters)
String sink_table = "CREATE TABLE hudi_users (\n" +
" id BIGINT,\n" +
" name VARCHAR(20),\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20),\n" +
" primary key(id) not enforced --Must specify uuid Primary key \n" +
")\n" +
"PARTITIONED BY (`partition`)\n" +
"with(\n" +
" 'connector'='hudi',\n" +
" 'path' = 'hdfs://hadoop1:8020/hudi/hudi_users',\n" +
" 'hoodie.datasource.write.recordkey.field'= 'id', -- Primary key\n" +
" 'write.precombine.field'= 'ts', -- automatic precombine Field of\n" +
" 'write.tasks'= '1',\n" +
" 'compaction.tasks'= '1',\n" +
" 'write.rate.limit'= '2000', -- Speed limit\n" +
" 'table.type'= 'MERGE_ON_READ', -- default COPY_ON_WRITE,Optional MERGE_ON_READ\n" +
" 'compaction.async.enabled'= 'true', -- Enable asynchronous compression\n" +
" 'compaction.trigger.strategy'= 'num_commits', -- Compress by number of times\n" +
" 'compaction.delta_commits'= '1', -- The default is 5\n" +
" 'changelog.enabled'= 'true', -- open changelog change\n" +
" 'read.streaming.enabled'= 'true', -- Enable streaming reading\n" +
" 'read.streaming.check-interval'= '3', -- Check interval, default 60 s\n" +
" 'hive_sync.enable'='true', -- required,open hive Synchronization function\n" +
" 'hive_sync.mode' = 'hms', -- required, take hive sync mode Set to hms, default jdbc\n" +
" 'hive_sync.metastore.uris' = 'thrift://Hadoop 1:9083 ', -- port of Metastore \ n "+
" 'hive_sync.table' = 'hudi_users', -- hive New table name\n" +
" 'hive_sync.db' = 'hudi', -- hive New database name\n" +
" 'hive_sync.support_timestamp' = 'true' -- compatible hive timestamp type\n" +
")";5. Capture mysql changes and write them to hudi
String transform_sql = "insert into hudi_users select *, DATE_FORMAT(birthday, 'yyyyMMdd') from mysql_users";
6. Execute statement
tableEnv.executeSql(source_table); tableEnv.executeSql(sink_table); tableEnv.executeSql(transform_sql);
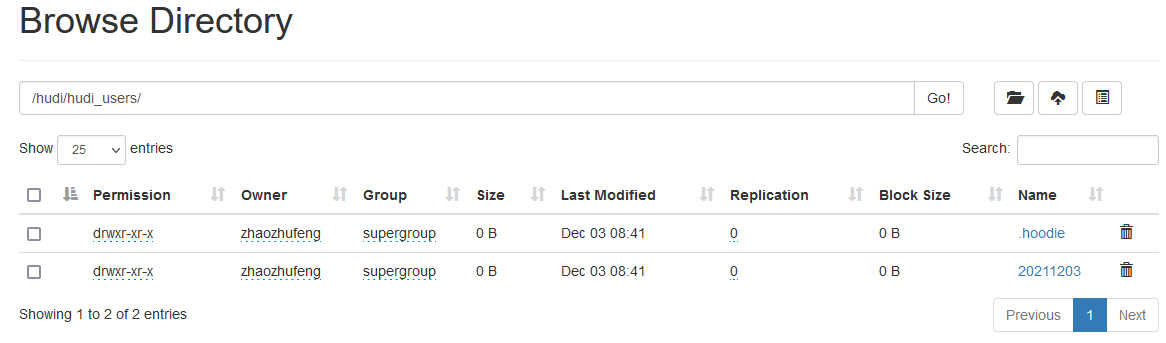
4, View hudi file directory
1.mysql does not insert data
When the task starts, no data is inserted into mysql, and the directory / hudi/hudi_users is automatically created on hdfs/
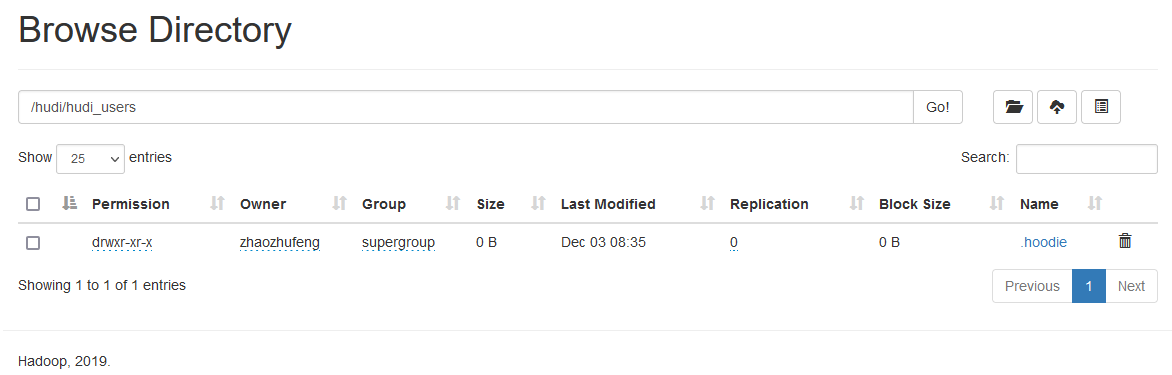
Click. hoodie
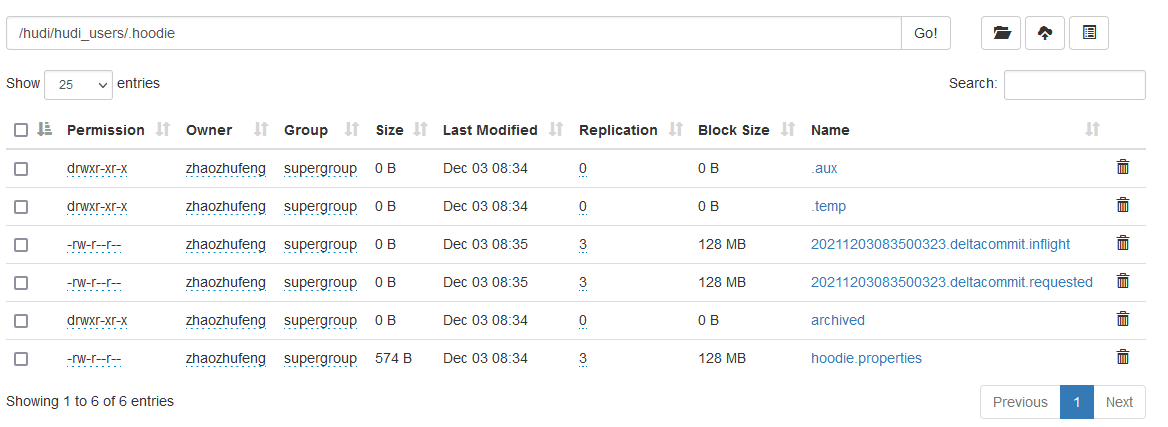
Hudi status file description:
(1) requested: indicates that an action has been scheduled but has not been started
(2) inflight: indicates that the operation is currently being performed
(3) Completed: indicates that the operation has been completed on the timeline
2. View the contents of the hdfs partition after inserting data
Observe the change of hdfs and add a partition directory
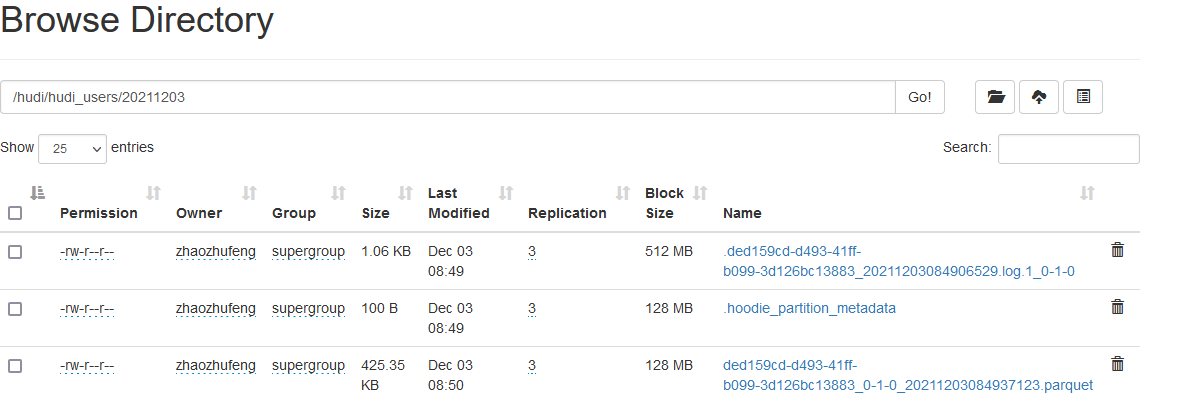
Note: hudi partition files and. log and. parquet files have been generated
Differences between the two files: Hudi will organize into directory structure under the basepath basic path on the DFS distributed file system. Each corresponding table will be divided into multiple partitions. These partitions are the folders containing the data files of the partition, which is very similar to the directory structure of hive. Within each partition, the files are organized into file groups, and the file id is the unique id. each file group contains multiple partitions Each slice contains the basic column file (parquet file) generated at a certain commit / compression instant time, and a set of log files (*. Log) for the insertion / update of the basic file since the generation of the basic file Hudi adopts MVCC design, in which the compression operation will merge logs and basic files into new file slices, and the cleaning operation will delete unused / older file slices to reclaim space on DFS.
5, hive query hudi data
1.hive preparation
1) Import Hudi package on Hive server
Create the auxlib / folder in the root directory of Hive, and put the hudi-hadoop-mr-bundle-0.10.0-SNAPSHOT.jar in the packaging / Hudi hadoop-mr-bundle / target directory after hudi install into it. Otherwise, an error will be reported
FAILED: SemanticException Cannot find class 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
2) Put hudi-hadoop-mr-bundle-0.9.0xxx.jar and hudi-hive-sync-bundle-0.9.0xx.jar in the lib directory of the hiveserver node;
Modify hive-site.xml, find hive.default.aux.jars.path and hive.aux.jars.path, and configure the full path of jar package in the first step;
<property>
<name>hive.default.aux.jars.path</name>
<value>file:///opt/hive-3.1.2/lib/hudi-hadoop-mr-bundle-0.9.0xxx.jar,file:///opt/hive-3.1.2/lib/hudi-hive-sync-bundle-0.9.0xx.jar</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>file:///opt/hive-3.1.2/lib/hudi-hadoop-mr-bundle-0.9.0xxx.jar,file:///opt/hive-3.1.2/lib/hudi-hive-sync-bundle-0.9.0xx.jar</value>
</property>3) Restart the hive metastore service and the hiveserver2 service;
4) set hive.input.format= org.apache.hadoop.hive.ql.io.HiveInputFormat;
2. Log in to hive client connection tool
Use the DBeaver tool to connect to the hive client
It is found that the Hudi library and Hudi are automatically added_ user_ ro,hudi_user_rt two tables
Difference between ro table and rt table:
The full name of ro table is read optimized table, which is used for the synchronization of MOR table_ ro table, only the compressed parquet is exposed. The query method is similar to the COW table. After setting the hiveInputFormat, you can query like the normal Hive table;
rt represents the incremental view, mainly for the rt table of incremental query;
ro table can only query parquet file data, while rt table can query both parquet file data and log file data;
3.select * query
Query hudi_user_ro table

Query hudi_user_rt table

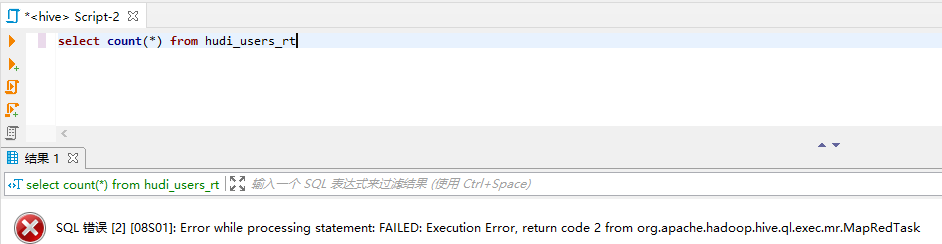
4.select count(*) query
Query hudi_user_ro table
Query hudi_user_rt table. It is found that there are exceptions. After consulting the data, the hudi community will repair it in a later version