1. Agent Components
Components in Agent include Source, Channel, Sink.
1.1 Source
The Source component can handle various types and formats of log data.
Common source s in Flume:
- avro
- exec
- netcat
- spooling directory
- taildir
| Common Categories | describe |
|---|---|
| avro | Listen for Avro ports and receive Event s from external Avro client streams |
| exec | Exec source runs a given Unix command at startup, tail-F file |
| netcat | Listens for a given port and converts each line of text to an Event |
| soopling directpry | Monitor the entire directory, read all files in the directory, do not support recursion, do not support breakpoint continuation |
| taildir | You can monitor changes to multiple files or folders and support logging progress |
1.3 Channel
Channel is a buffer between Source and Ink that stores Event s.
Channel is thread-safe and can handle several Source write operations and several Sink read operations simultaneously.
Channel commonly used in Flume:
- Memary Channel
- File Channel
- Kafka Channel
| Common Categories | describe |
|---|---|
| Memary | Queues Stored in Memory for Event s |
| File | Event s are stored in files without worrying about data loss |
| KafKa | Event s are stored in a Kafka cluster. Kafka provides high availability |
1.3 Sink
Sink writes Event s from Channel in bulk to a storage or indexing system or is sent to another Flume Agent.
Common sink s in Flume:
- logger
- hdfs
- avro
- HBase
| Common Categories | describe |
|---|---|
| logger | Console output, log level INFO. Usually used for testing/debugging |
| hdfs | Event events written to HDFS |
| avro | Flume Event s sent to Sink are converted to Avro events and sent to the configured host name/port |
| HBase | Event events written to HBase |
2. Agent Component Matching
Agent components can be customized to match, using different Source s, Sink s, Channel s.
Here are a few simple combinations.
exec2logger stands for exec to logger, and 2 stands for to, which translates two into to. Common ones are p2p, log4j, etc., which are analogues as numbers.
You can start the Hadoop cluster first: start-dfs.sh.
Complex Flume startup commands are:
flume-ng agent --conf <Flume Configuration Path> --conf-file <agent Absolute path to configuration file> --name <agent Name> -Dflume.root.logger=INFO,console
The above commands can be abbreviated as:
flume-ng agent -c <Flume Configuration Path> -f <agent Absolute path to configuration file> -n <agent Name> -Dflume.root.logger=INFO,console
2.1 Source
2.1.1 exec2logger
| Common Configuration Items | Default value | describe |
|---|---|---|
| type | - | Configure type to exec |
| command | - | Configure commands to execute, such as tail-F file |
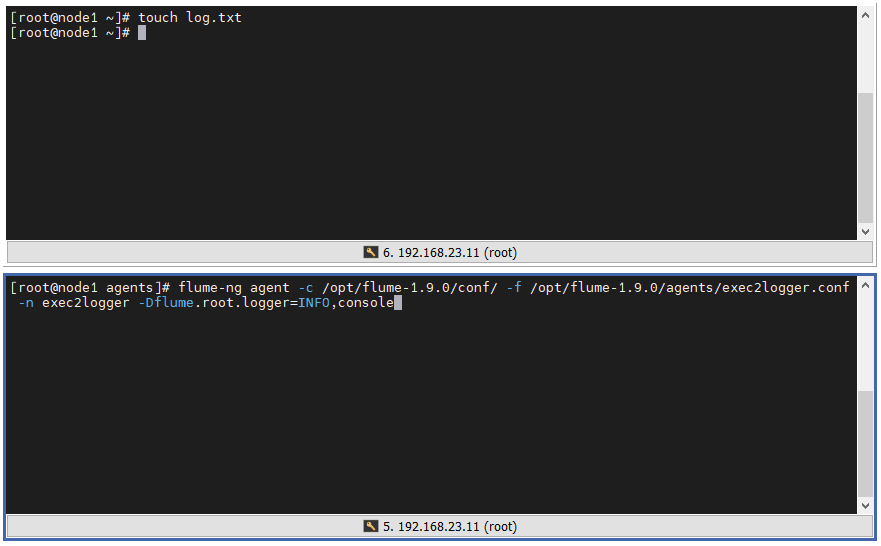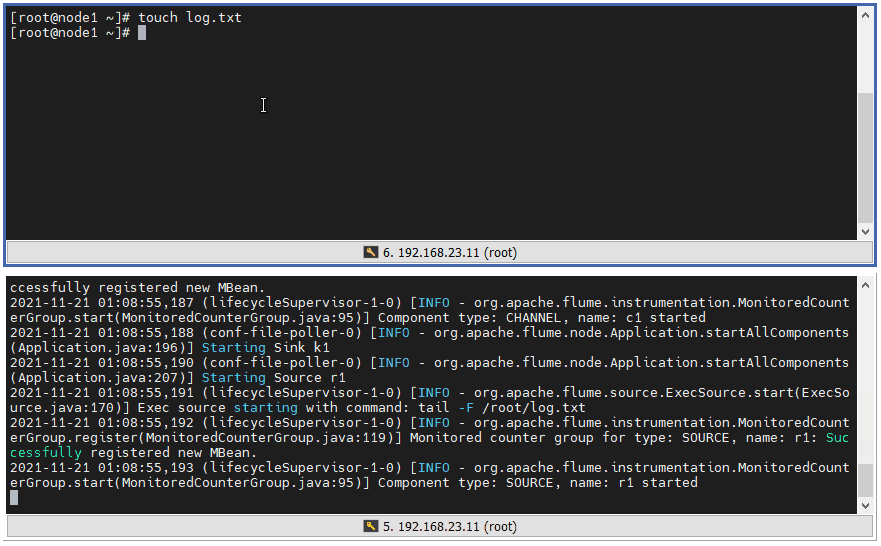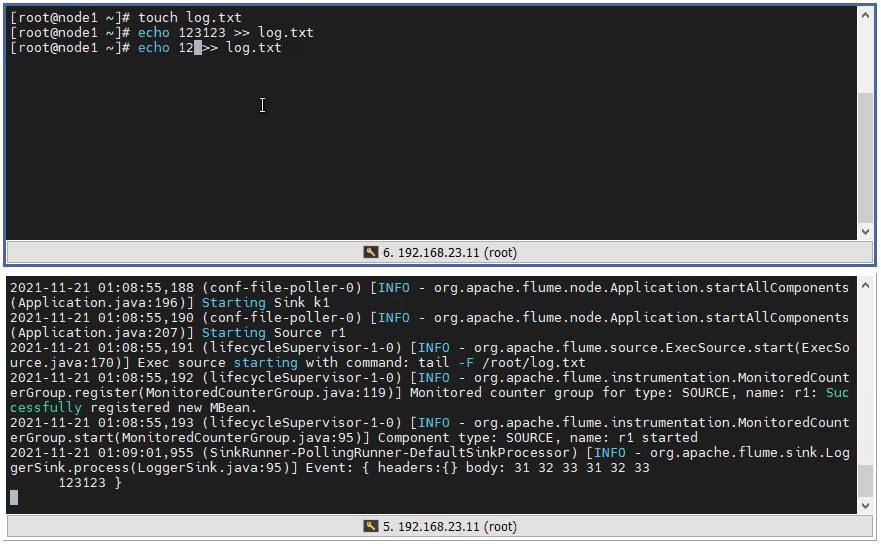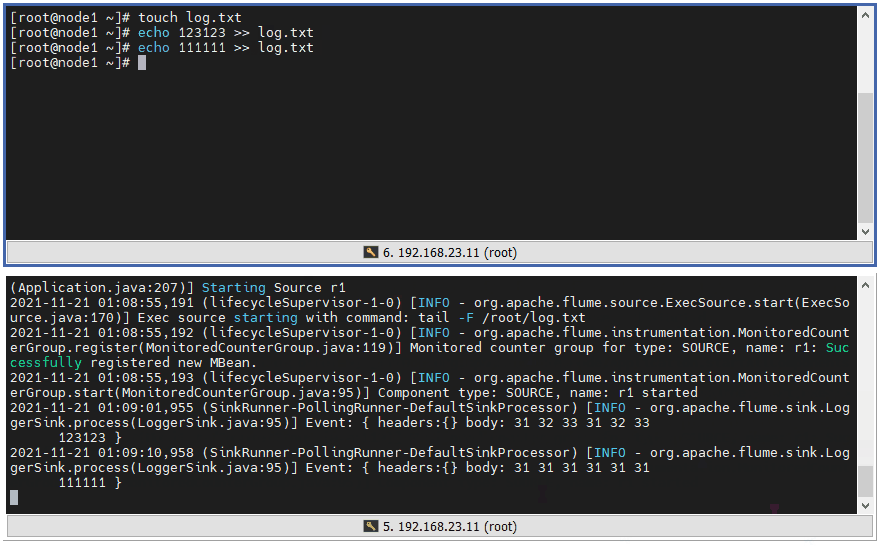
1 ️⃣ Step1: Customize a directory in the flume directory (mine is the agents directory) and add the configuration file exec2logger.conf
vim exec2logger.conf
# exec reads log files and sends data to logger sink # Name the components on this agent exec2logger.sources = r1 exec2logger.sinks = k1 exec2logger.channels = c1 # Describe/configure the source exec2logger.sources.r1.type = exec exec2logger.sources.r1.command = tail -F /root/log.txt # Describe the sink exec2logger.sinks.k1.type = logger # Use a channel which buffers events in memory exec2logger.channels.c1.type = memory exec2logger.channels.c1.capacity = 1000 exec2logger.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel exec2logger.sources.r1.channels = c1 exec2logger.sinks.k1.channel = c1
2 ️⃣ Step2: Start Flume exec2logger
flume-ng agent -c /opt/flume-1.9.0/conf/ -f /opt/flume-1.9.0/agents/exec2logger.conf -n exec2logger -Dflume.root.logger=INFO,console
3 ️⃣ Step3: Test and view the console output (instead of touch ing to create the file, > is a flow redirection, and if the file does not exist, create it directly)
2.1.2 spoolDir2logger
| Common Configuration Items | Default value | describe |
|---|---|---|
| type | - | Configure the type as spooldir |
| spoolDir | - | Configure to file to read (absolute path) |
1 ️⃣ Step1: Add configuration file spooldir2logger.conf
# spooldir reads multiple log files in the same directory and sends data to logger sink # Name the components on this agent spooldir2logger.sources = r1 spooldir2logger.sinks = k1 spooldir2logger.channels = c1 # Describe/configure the source spooldir2logger.sources.r1.type = spooldir spooldir2logger.sources.r1.spoolDir = /root/log # Describe the sink spooldir2logger.sinks.k1.type = logger # Use a channel which buffers events in memory spooldir2logger.channels.c1.type = memory spooldir2logger.channels.c1.capacity = 1000 spooldir2logger.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel spooldir2logger.sources.r1.channels = c1 spooldir2logger.sinks.k1.channel = c1
2 ️⃣ Step2: Start Flume spooldir2logger
flume-ng agent -c /opt/flume-1.9.0/conf/ -f /opt/flume-1.9.0/agents/spooldir2logger.conf -n spooldir2logger -Dflume.root.logger=INFO,console
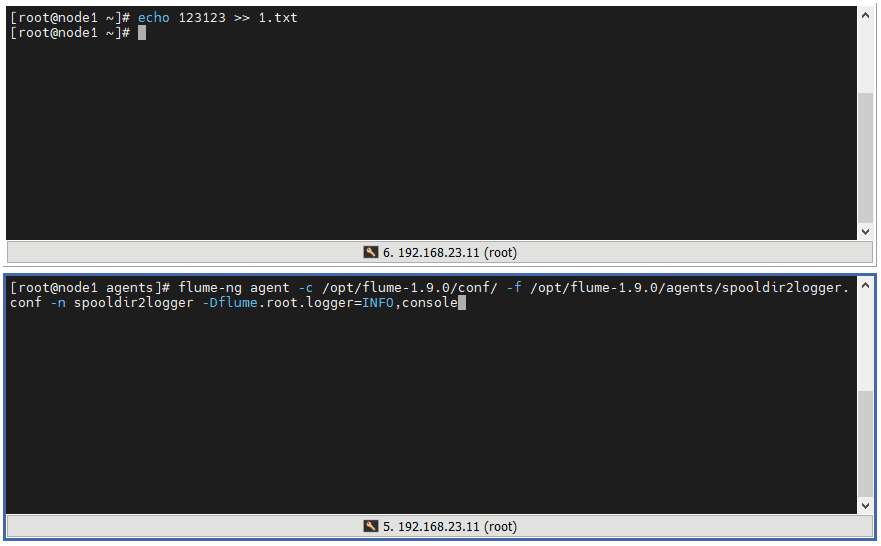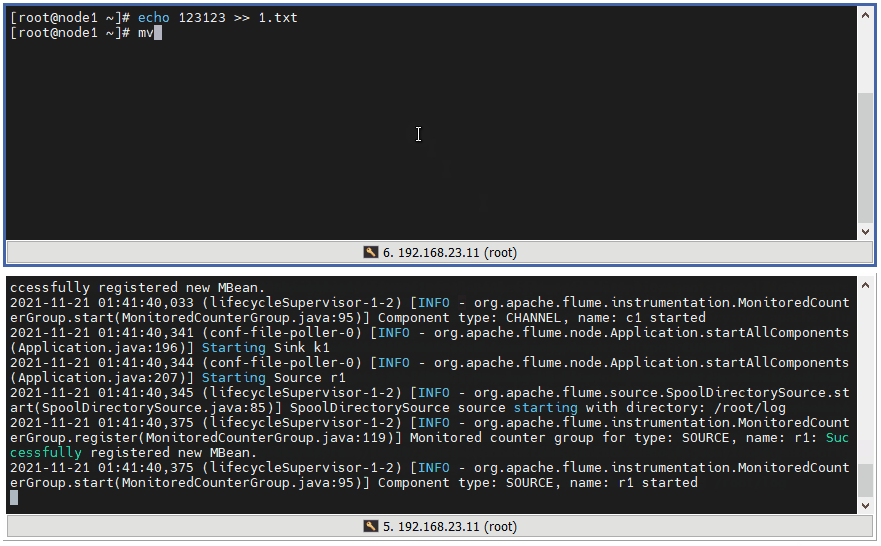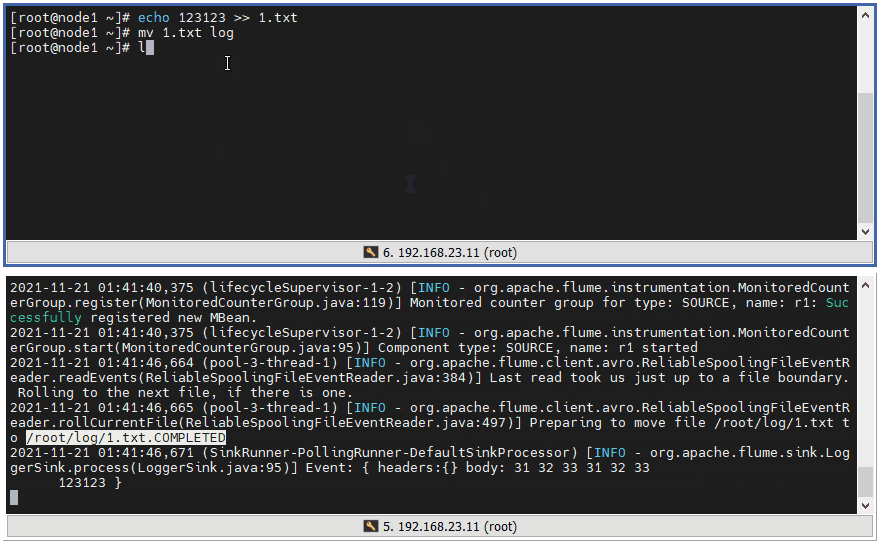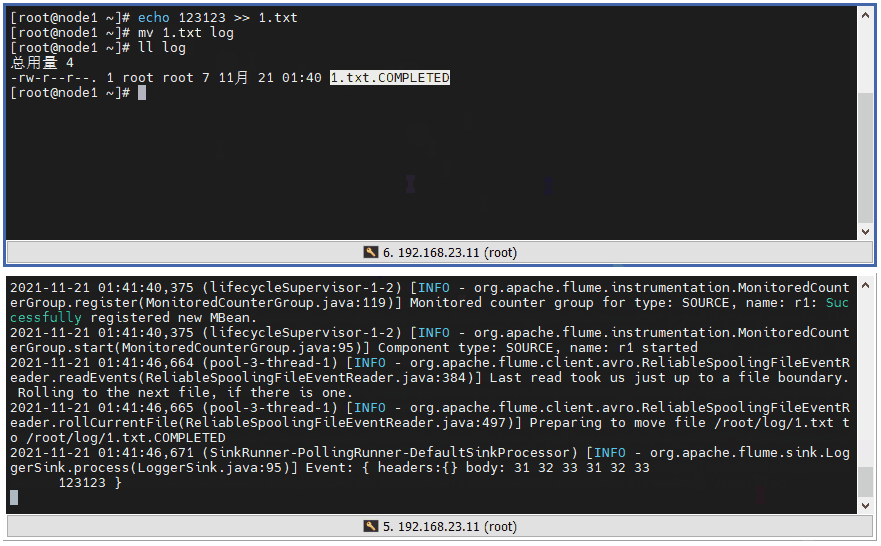
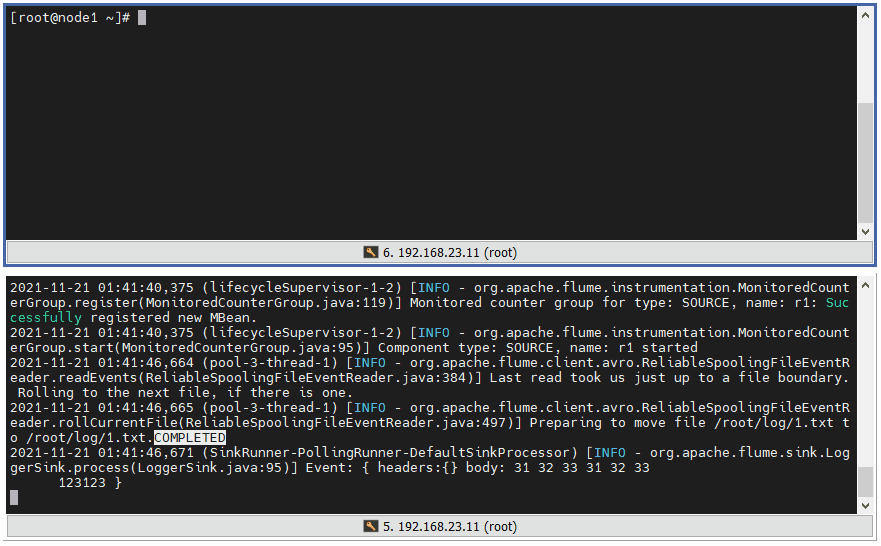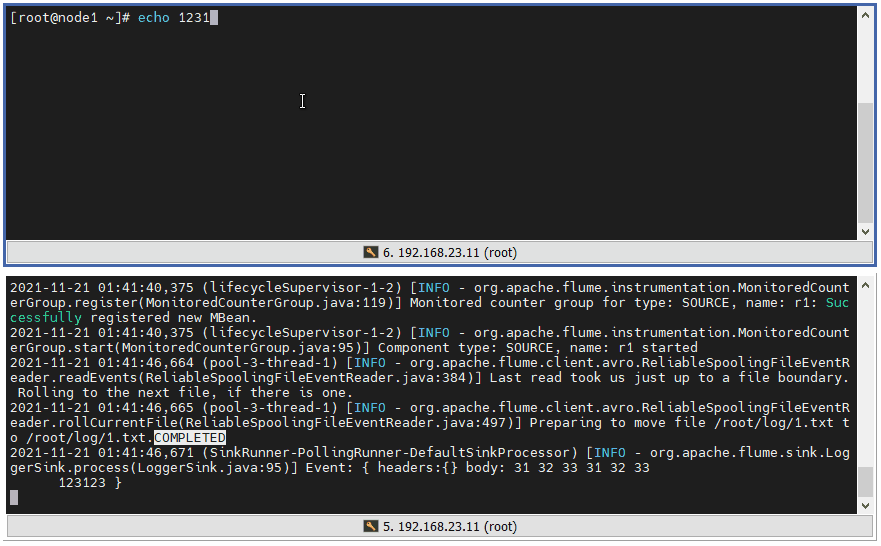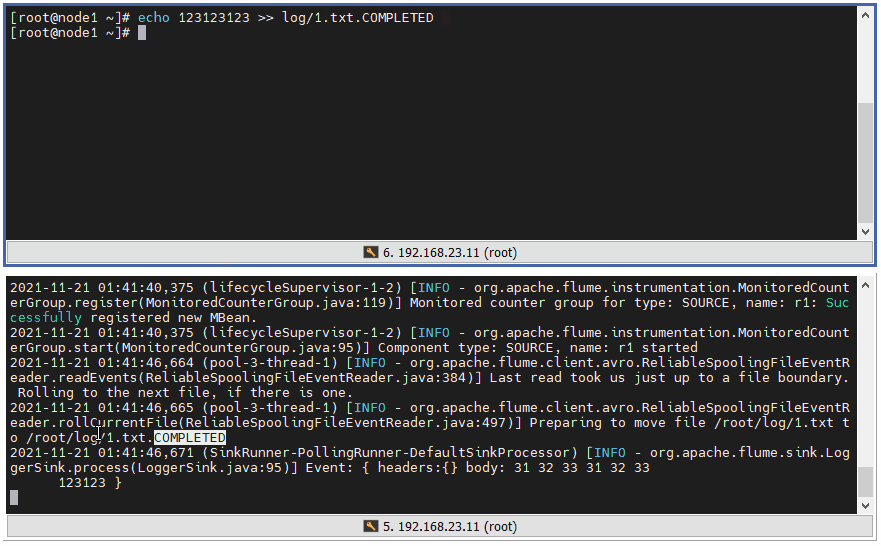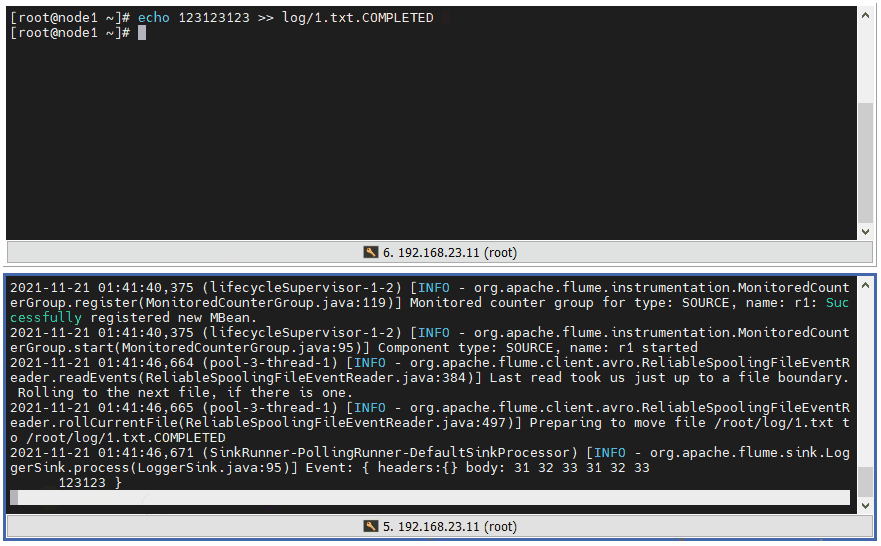
3 ️⃣ Step3: Test that when the output of content within a file is complete, the file suffix will be marked COMPLETED to indicate the completed file.
4 ️⃣ Step4: If we enter content into the finished file, we will no longer be able to get the file changes.
2.1.3 tailDir2logger
| Common Configuration Items | Default value | describe |
|---|---|---|
| type | - | Configure type to TAILDIR |
| filegroups | - | Profile Group |
| filegroups.<filegroupName> | - | Configure the corresponding file or directory for the filegroup |
| positionFile | ~/.flume/taildir_position.json | The absolute path to the tailDir record file file |
1 ️⃣ Step1: Add configuration file taildir2logger.conf
# tailDir reads multiple log files in the same directory and sends data to logger sink # Name the components on this agent taildir2logger.sources = r1 taildir2logger.sinks = k1 taildir2logger.channels = c1 # Describe/configure the source taildir2logger.sources.r1.type = TAILDIR taildir2logger.sources.r1.filegroups = g1 g2 taildir2logger.sources.r1.filegroups.g1 = /root/log.txt taildir2logger.sources.r1.filegroups.g2 = /root/log/.*.txt # Describe the sink taildir2logger.sinks.k1.type = logger # Use a channel which buffers events in memory taildir2logger.channels.c1.type = memory taildir2logger.channels.c1.capacity = 1000 taildir2logger.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel taildir2logger.sources.r1.channels = c1 taildir2logger.sinks.k1.channel = c1
2 ️⃣ Step2: Start Flume taildir2logger
flume-ng agent -c /opt/flume-1.9.0/conf/ -f /opt/flume-1.9.0/agents/taildir2logger.conf -n taildir2logger -Dflume.root.logger=INFO,console
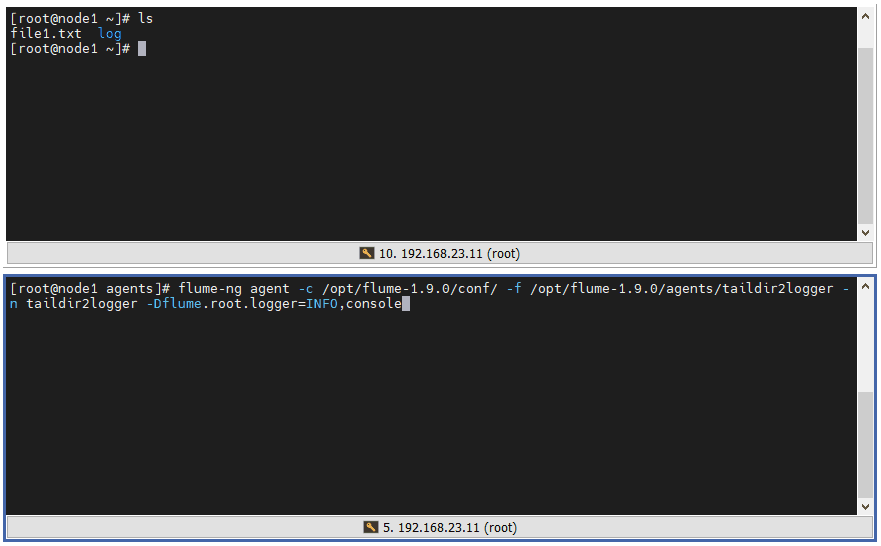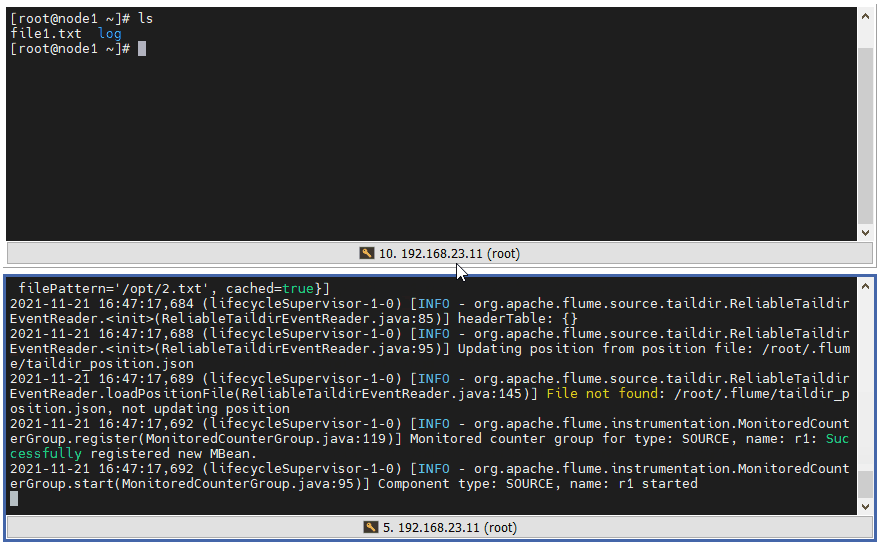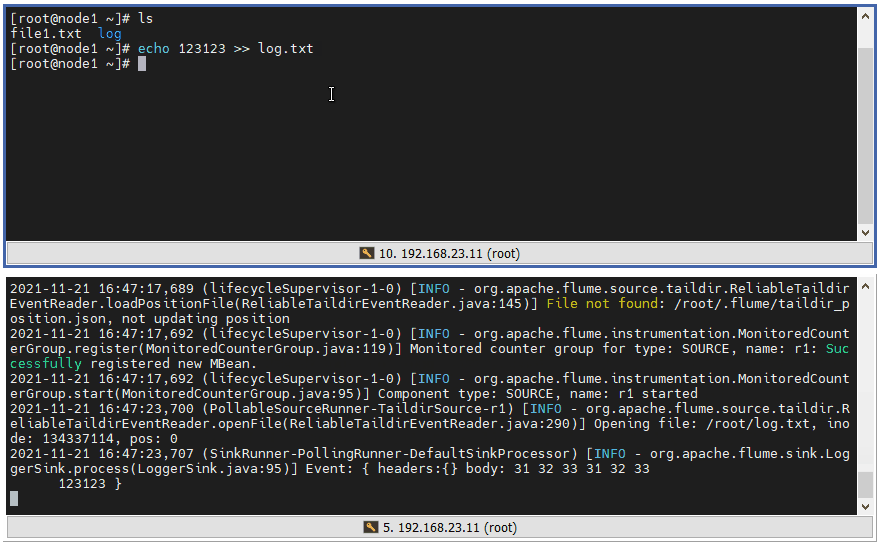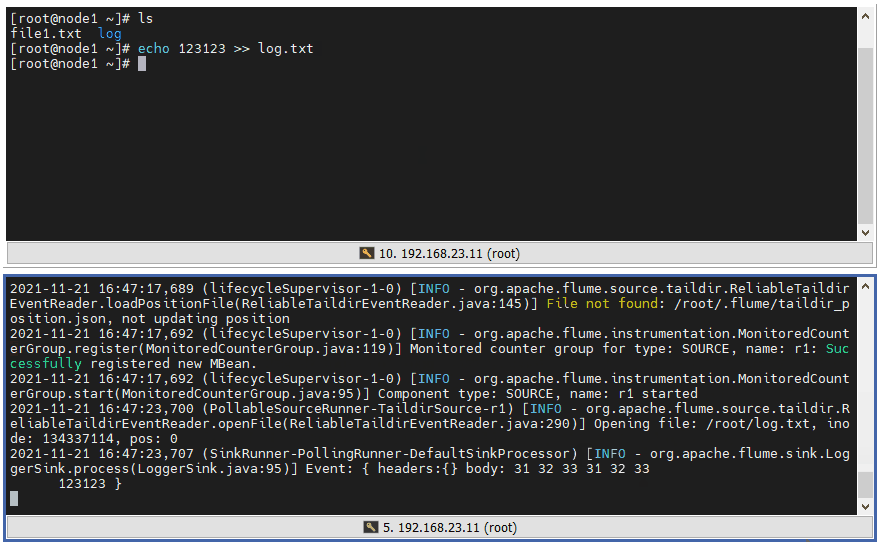
3 ️⃣ Step3: Test 1, detect file changes when appending content to a file
4 ️⃣ Step4: Test 2, detect changes in.txt files in folders
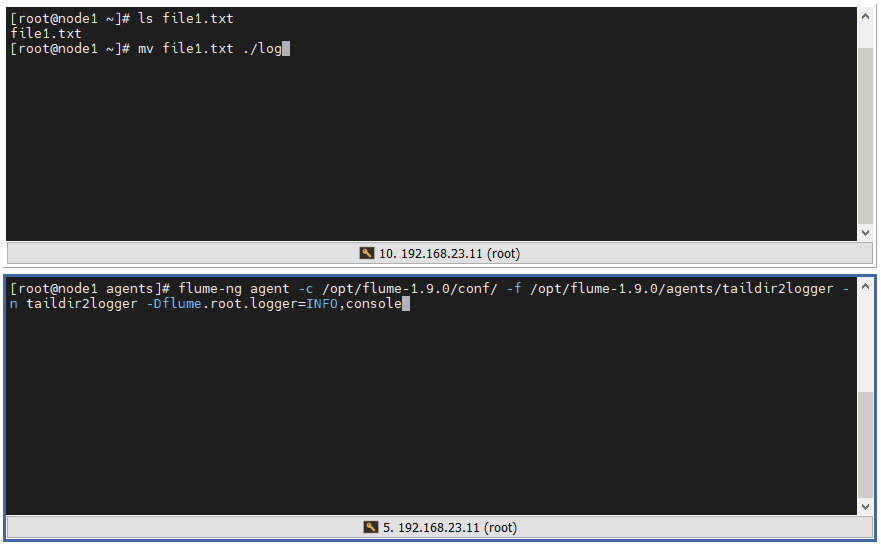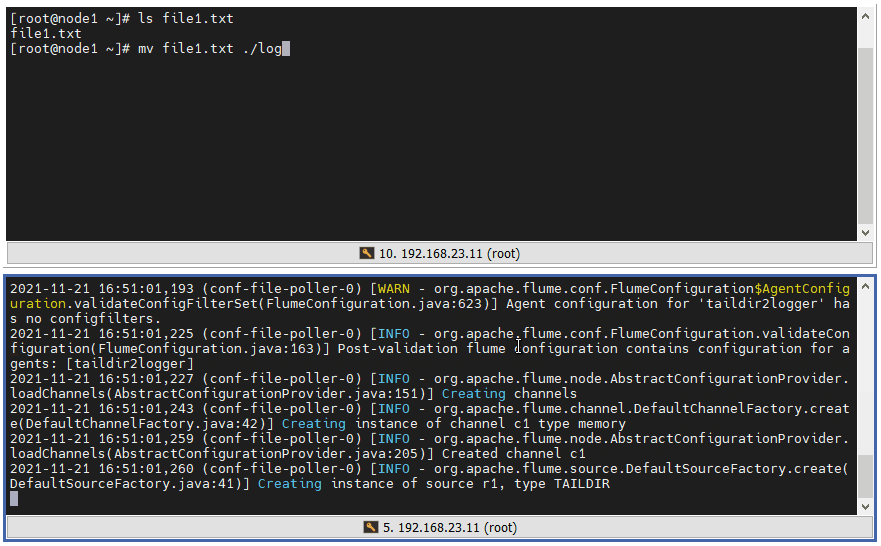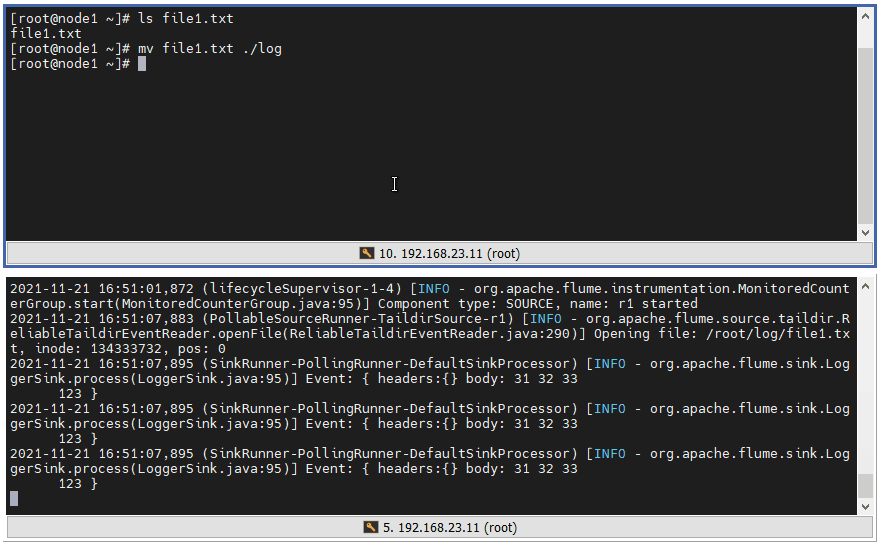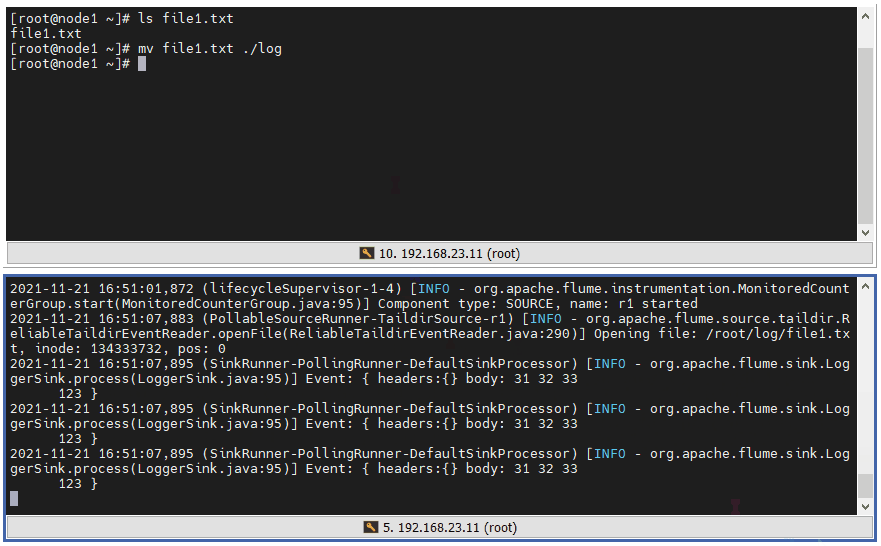
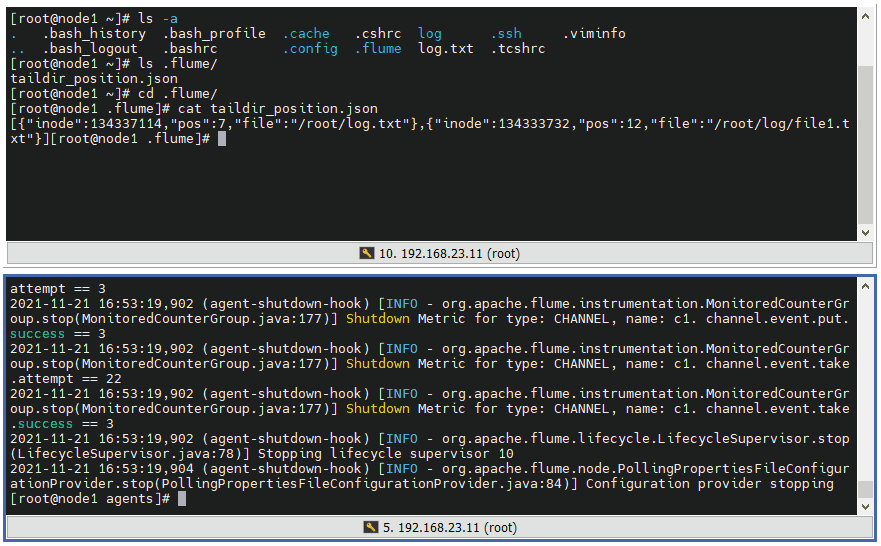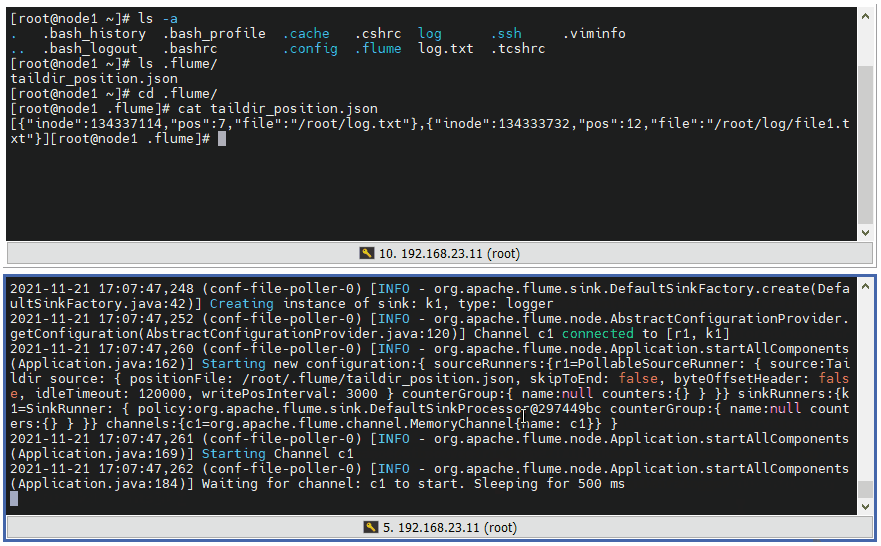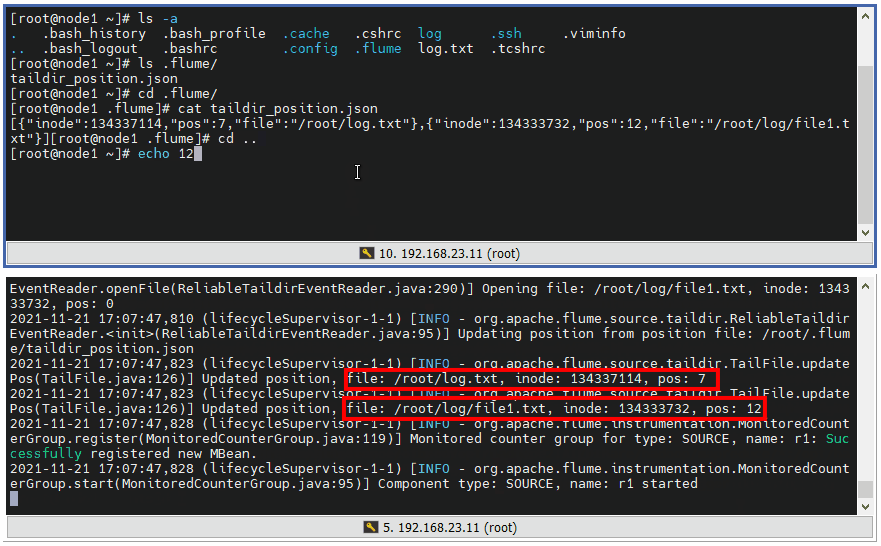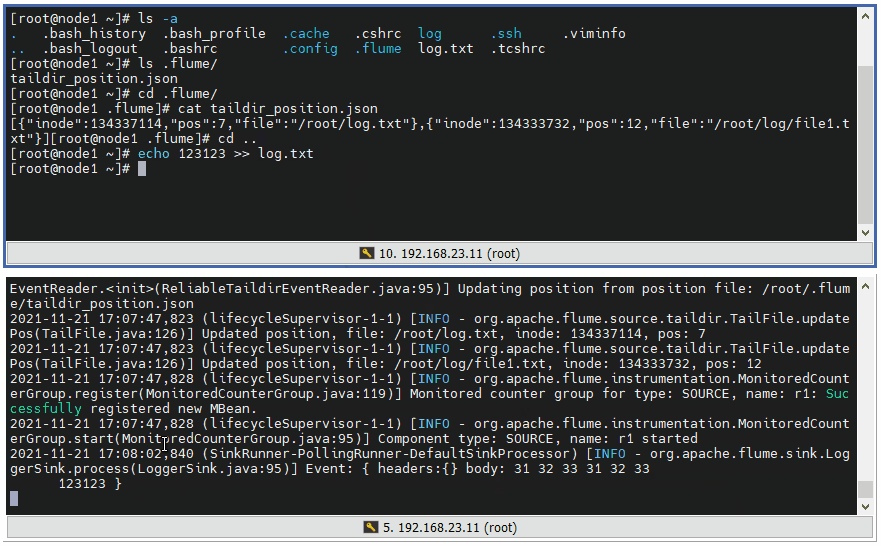
5 ️⃣ Step5:taildir Logging File does not add COMPLETED to the file suffix, but places the record in a json file
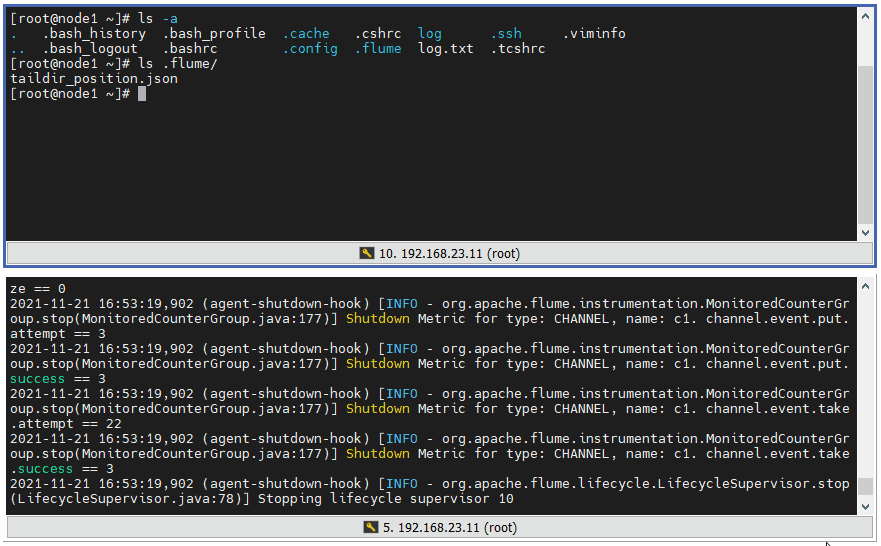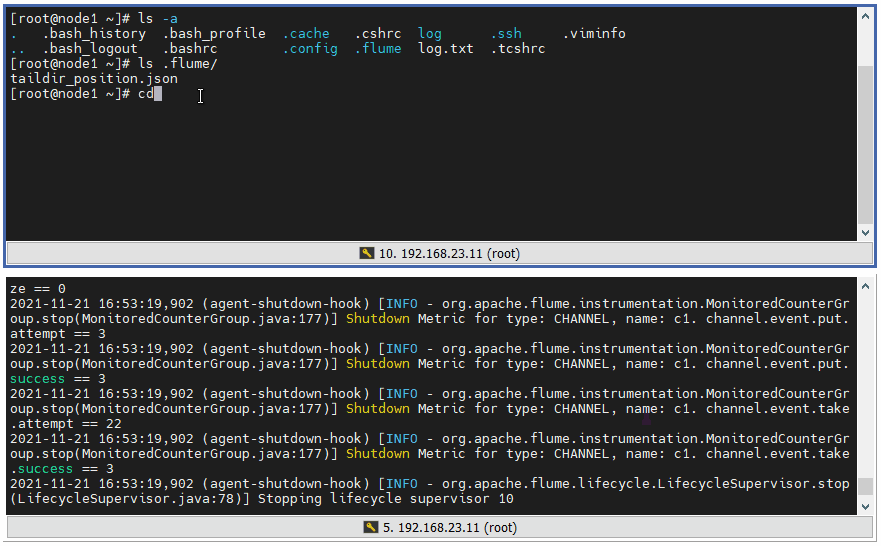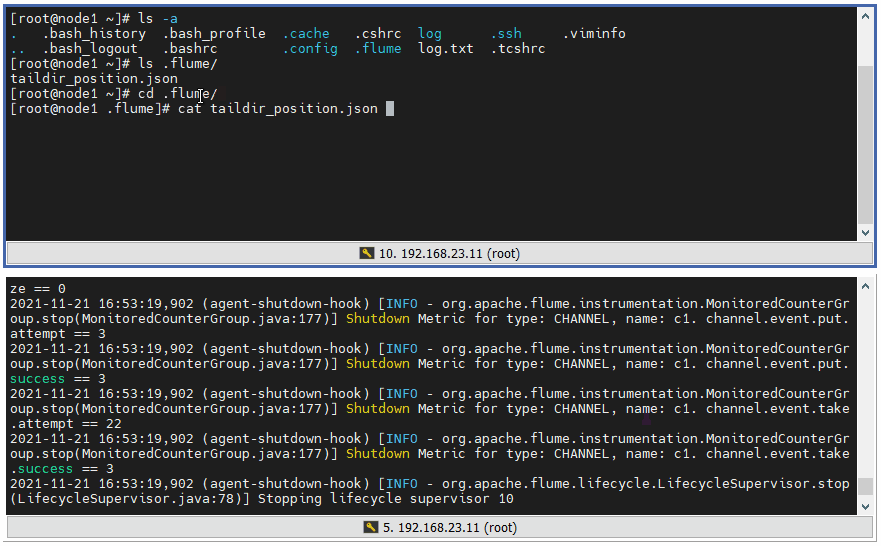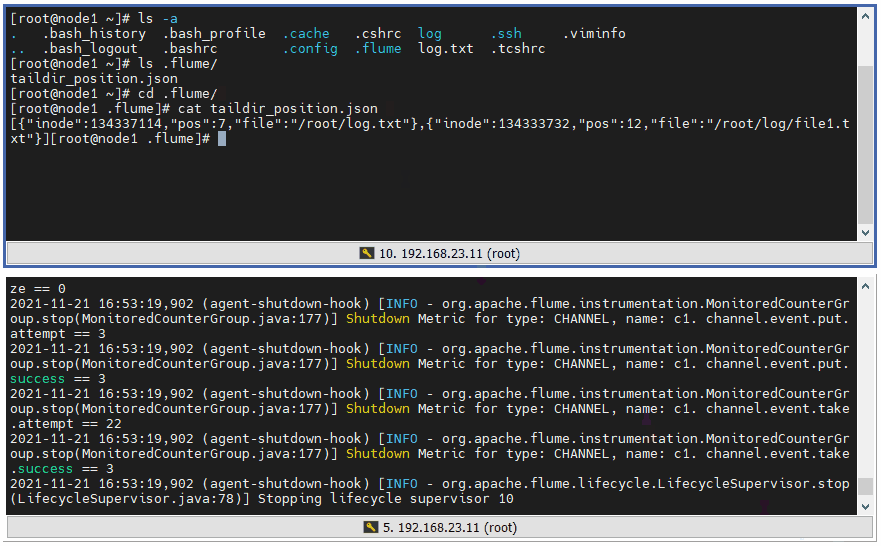
6 ️⃣ Step6: Format the json file and find that an array stores data in json format, and each json stores an absolute path file that uniquely identifies the inode, the pos where it was read, and the file
[
{
"inode":134337114,
"pos":7,
"file":"/root/log.txt"
},
{
"inode":134333732,
"pos":12,
"file":"/root/log/file1.txt"
}
]
7 ️⃣ Step7: Append content to / root/log.txt and start Flume again. Flume loads the read location once, then reads it, and records the new read location in json
Interview Question: Which Source is commonly used for log collection?
Answer: We usually use tailDir type Source, before we tried exec, spoolDir, later there should be more directories in the middle of the application scenario, and tailDir was chosen for each read to follow the last read. The main reason for using tailDir is that tailDir will record the location in the json file and read the file. If the agent hangs up later, Simply restart and continue reading as you progressed from your last reading
2.2 Channel
2.2.1 memary channel
| Common Configuration Items | Default value | describe |
|---|---|---|
| type | - | Configuring the type as memory |
| capacity | 100 | Maximum number of Event s in channel |
| transactionCapacity | 100 | Maximum number of Event s per channel sent to sink |
capacity is estimated based on estimating the amount of data channel may cache (typically 2w-20w) and the Jvm memory available to the agent (typically 20MB).
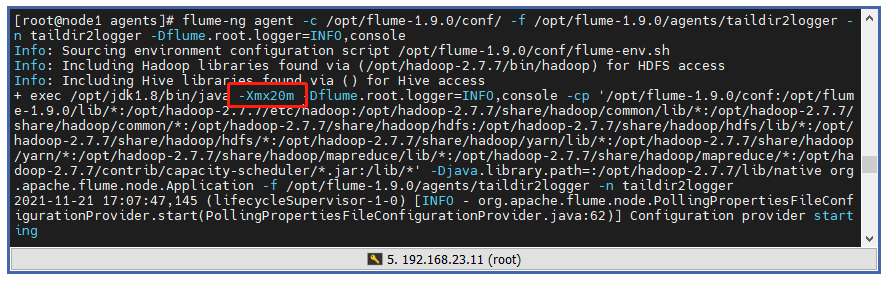
The default maximum memory is 20MB. If a log is 512B long, it can hold more than 4w of data (20x1024x2=40960), but capacity is usually not set too full, which can easily overflow memory.
❓ How can I increase the Jvm memory capacity since the default value is small?
⭐ Expansion can be achieved by modifying the Flume boot configuration, vim/flume-1.9.0/bin/flume-ng can view the Flume boot script and modify JAVA_OPTS item:
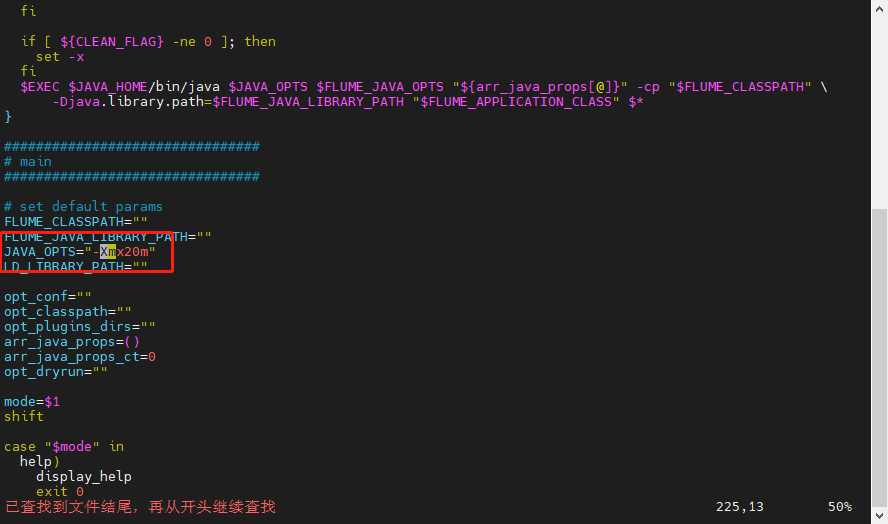
2.2.2 File channel
Channel s of File type are used when data security is high to avoid data loss due to program crashes.
| Common Configuration Items | Default value | describe |
|---|---|---|
| type | - | Configuring types as file s |
| checkpointDir | ~/.flume/file-channel/checkpoint | Absolute path to checkpoint file |
When the program crashes before it starts, it reads the checkpointDir configuration file from which Sink will continue reading the last unread Event.
2.3 Sink
2.3.1 logger sink
Log events at the INFO level, usually for testing/debugging purposes. Usually, when configuring Fume, you use logger to output the Event to the console to test if the Source has a problem, and then modify the Sink type.
| Common Configuration Items | Default value | describe |
|---|---|---|
| type | - | Configure type as logger |
2.3.2 tailDir2hdfs
| Common Configuration Items | Default value | describe |
|---|---|---|
| type | - | Configuring types as file s |
| hdfs.path | - | Path to HDFS log |
| hdfs.fileType | SequenceFile | Configuration file type, which can be configured as DataStream or CompressedStream |
| hdfs.writeFormat | Writable | Formatting type, configurable as Text |
| hdfs.useLocalTimeStamp | false | Configure whether to use local timestamps |
| hdfs.rollInterva | 30 | Configure scroll cycle, units s |
| hdfs.rollSize | 1024 | Specified size of profile arrival |
| hdfs.rollCount | 10 | Configure how many pieces of data are written to the file, and configure 0 to indicate no dependency on that item |
1 ️⃣ Step1: Add configuration file taildir2hdfs.conf
# taildir reads multiple log files in the same directory and sends data to logger sink # Name the components on this agent taildir2hdfs.sources = r1 taildir2hdfs.sinks = k1 taildir2hdfs.channels = c1 # Describe/configure the source taildir2hdfs.sources.r1.type = TAILDIR taildir2hdfs.sources.r1.filegroups = g1 g2 taildir2hdfs.sources.r1.filegroups.g1 = /root/log.txt taildir2hdfs.sources.r1.filegroups.g2 = /root/log/.*.txt # Describe the sink taildir2hdfs.sinks.k1.type = hdfs taildir2hdfs.sinks.k1.hdfs.path = hdfs://node1:8020/flume/%y-%m-%d-%H-%M # Change hdfs output file type to data stream taildir2hdfs.sinks.k1.hdfs.fileType = DataStream # Change output formatting to text formatting taildir2hdfs.sinks.k1.hdfs.writeFormat = Text taildir2hdfs.sinks.k1.hdfs.useLocalTimeStamp = true # Use a channel which buffers events in memory taildir2hdfs.channels.c1.type = memory taildir2hdfs.channels.c1.capacity = 30000 taildir2hdfs.channels.c1.transactionCapacity = 3000 # Bind the source and sink to the channel taildir2hdfs.sources.r1.channels = c1 taildir2hdfs.sinks.k1.channel = c1
2 ️⃣ Step2: Writing data one by one is too cumbersome, so write a dead-loop script to enter data into the file, stop after a while, and check the size of the file
[root@node1 ~]# vim printer.sh
[root@node1 ~]# chmod a+x printer.sh
[root@node1 ~]# cat printer.sh
#!/bin/bash
while true
do
echo '123123123123123123123123123123123123123123123123123123123123' >> log.txt
done
[root@node1 ~]# ll -h Total usage 17 M drwxr-xr-x. 3 root root 65 11 21/16:51 log -rw-r--r--. 1 root root 14M 11 February 21 23:29 log.txt -rwxr-xr-x. 1 root root 134 11 February 21 23:22 printer.sh
3 ️⃣ Step3: Start HDFS start-dfs.sh, start Flume taildir 2hdfs, you can see and are already sending logs frantically
flume-ng agent -c /opt/flume-1.9.0/conf/ -f /opt/flume-1.9.0/agents/taildir2hdfs.conf -n taildir2hdfs -Dflume.root.logger=INFO,console
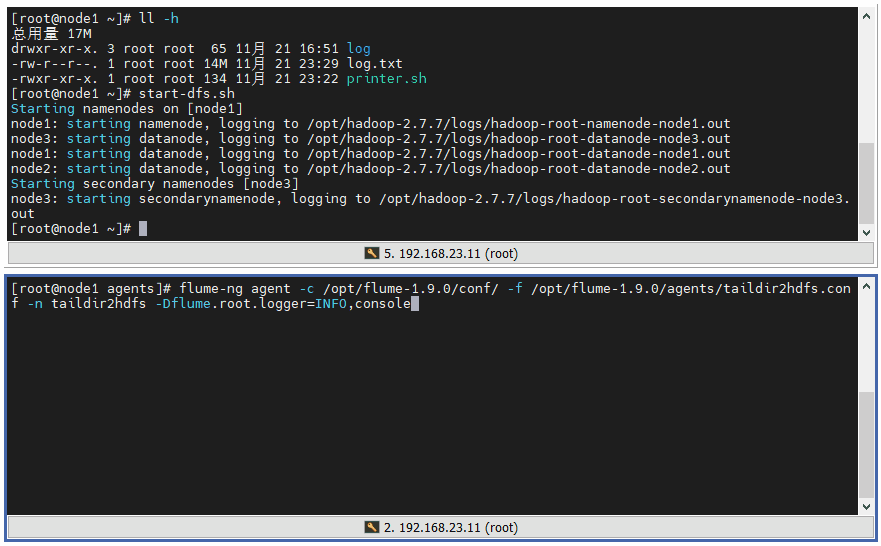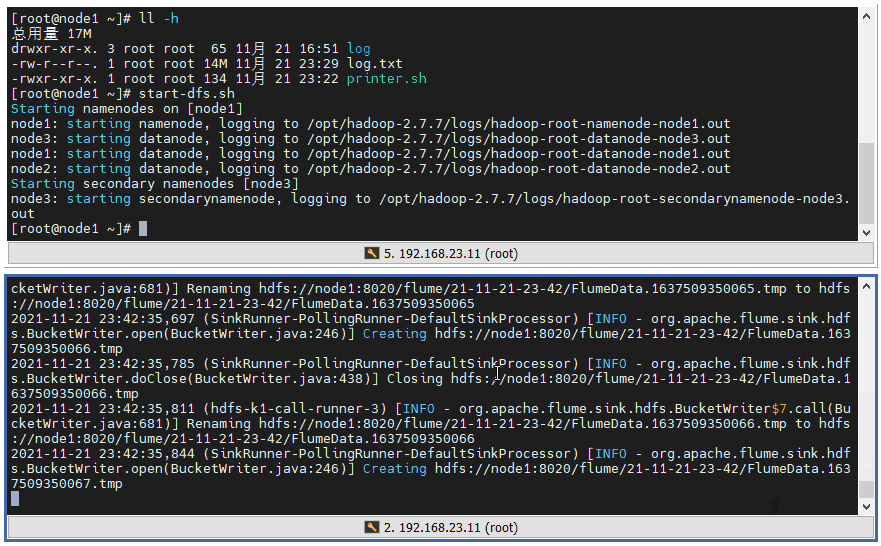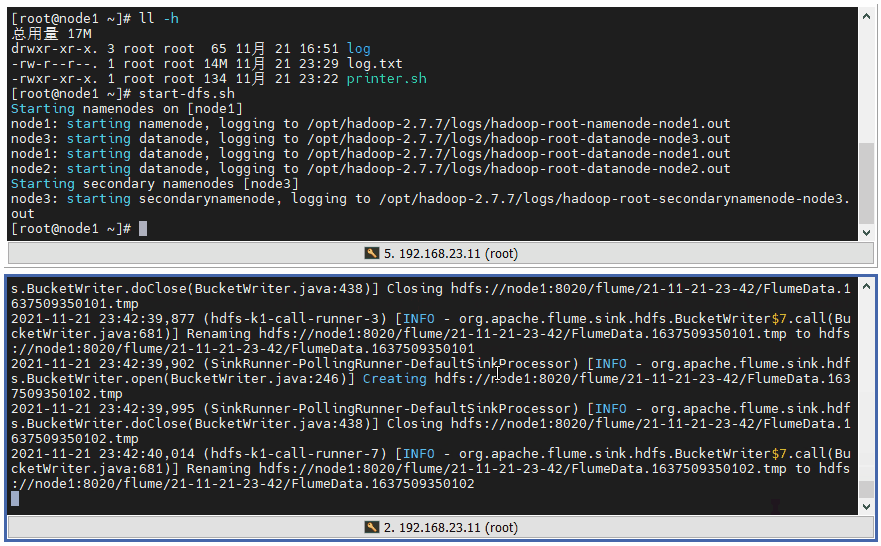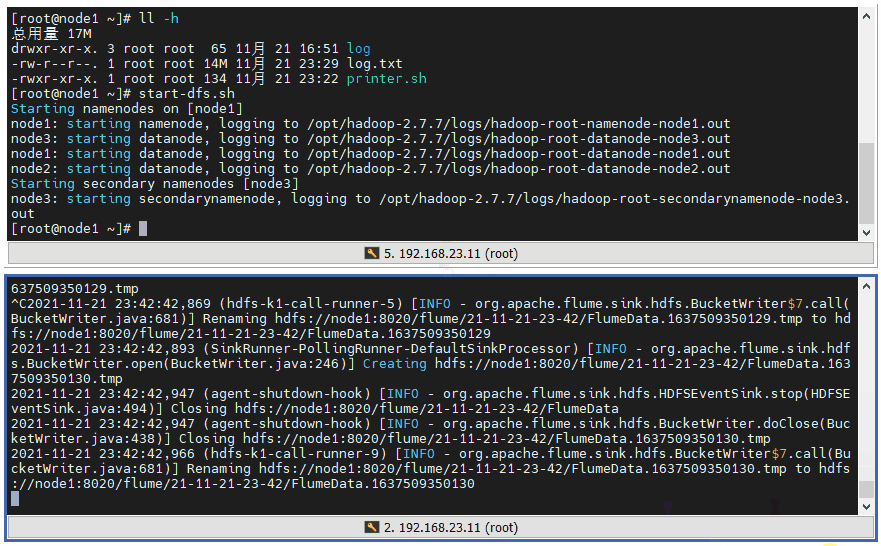
4 ️⃣ Step4: Look at the web page and find / flume / has a file named by the current time, go in and find it's all small files
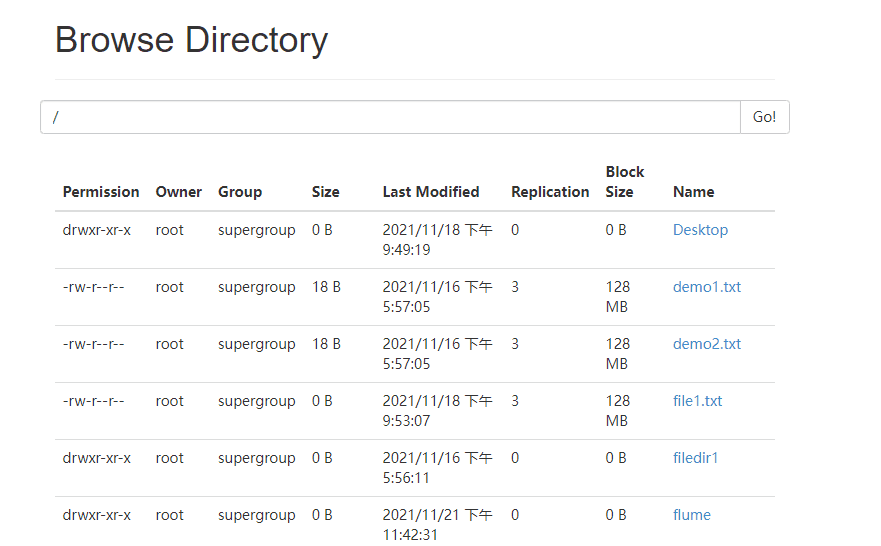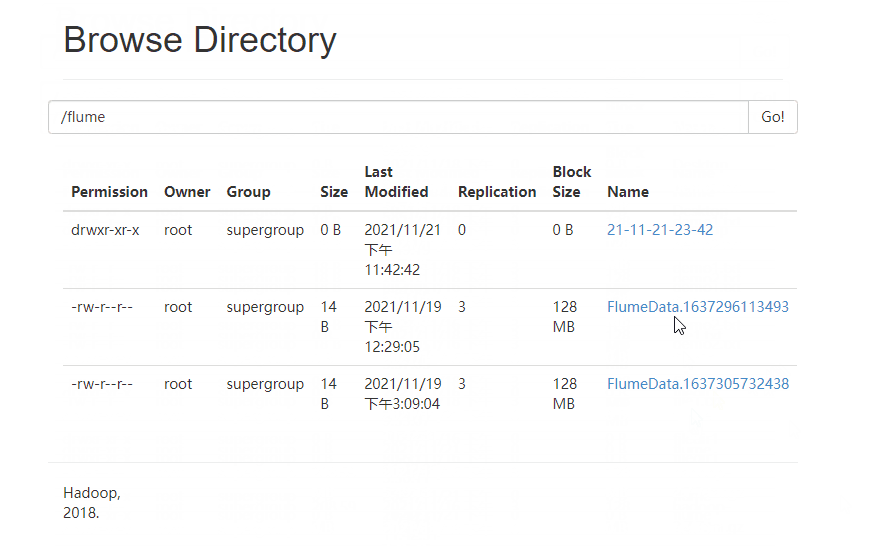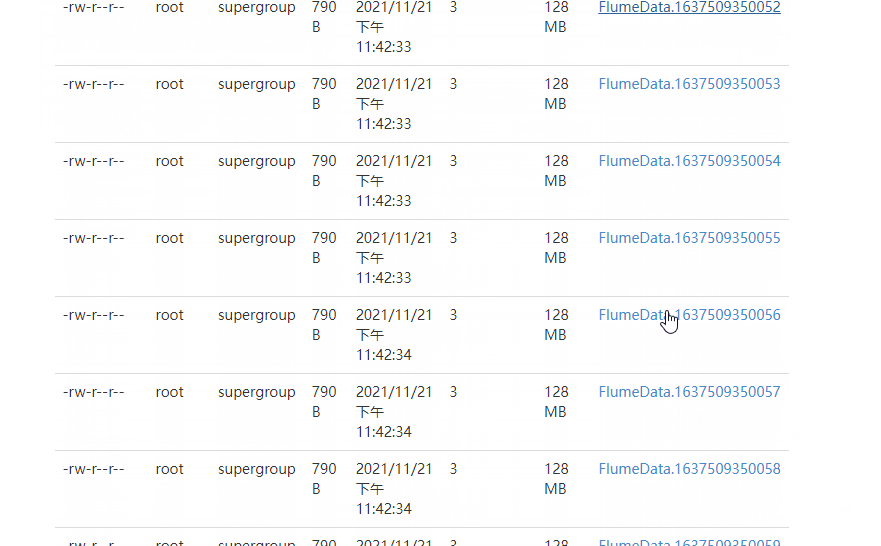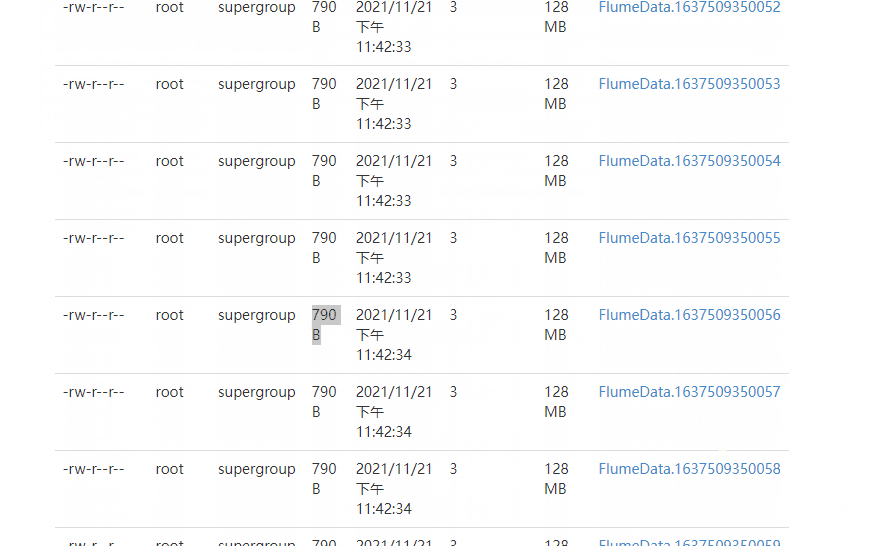
5 ️⃣ Step5:flume has a fast size of 128MB, and configuration information needs to be added to make the most of space.
# Set the scrolling condition of the file------------------------------- # Set scroll cycle units s taildir2hdfs.sinks.k1.hdfs.rollInterval = 300 # The settings file reaches the specified size, 128MB is 134,217,728B, but will not normally be full taildir2hdfs.sinks.k1.hdfs.rollSize = 130000000 # Set how many records are written to the file taildir2hdfs.sinks.k1.hdfs.rollCount = 0
6 ️⃣ Step6: Rerun Flume after modification and view changes on the web side
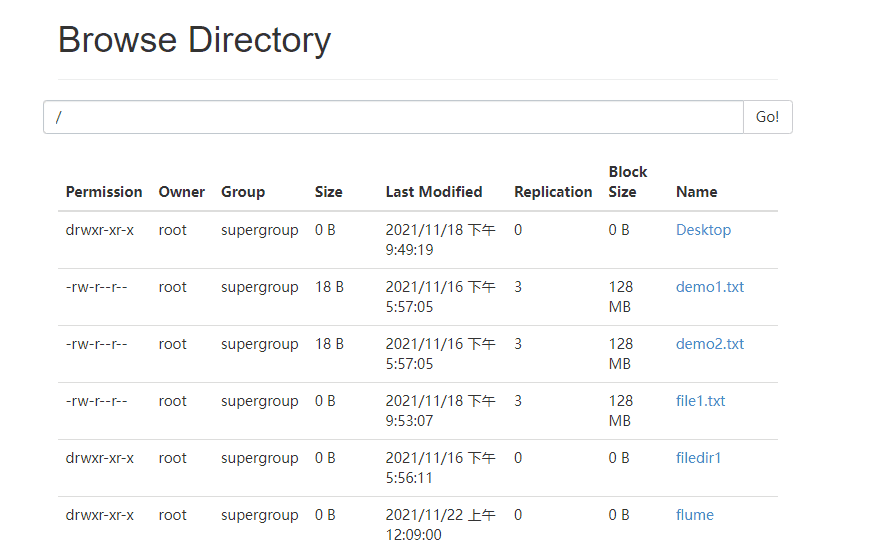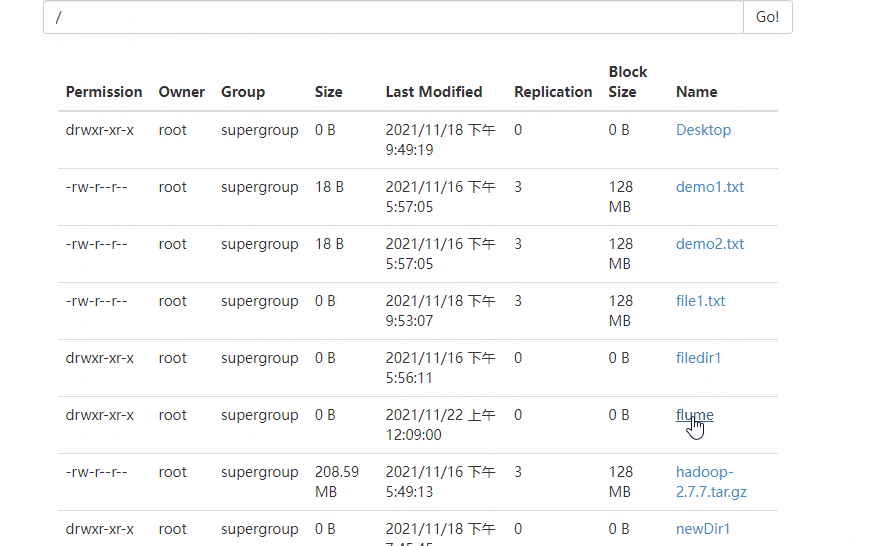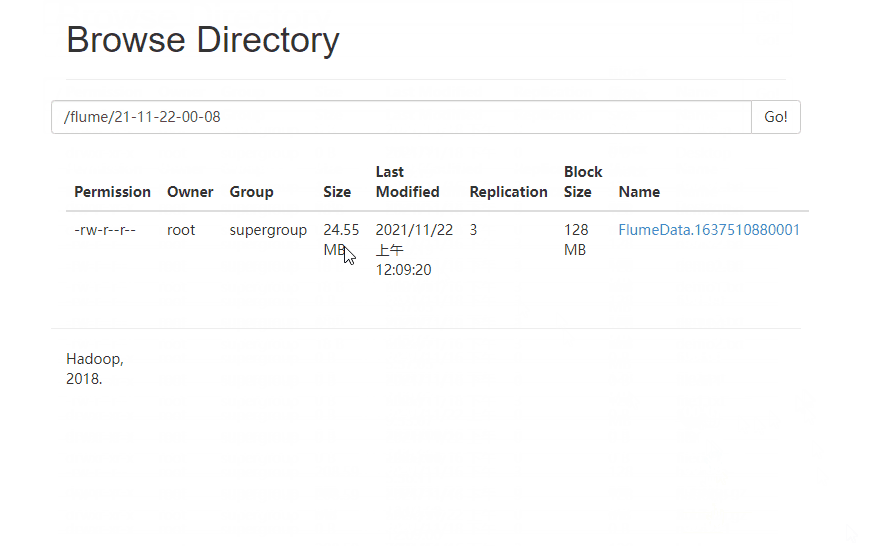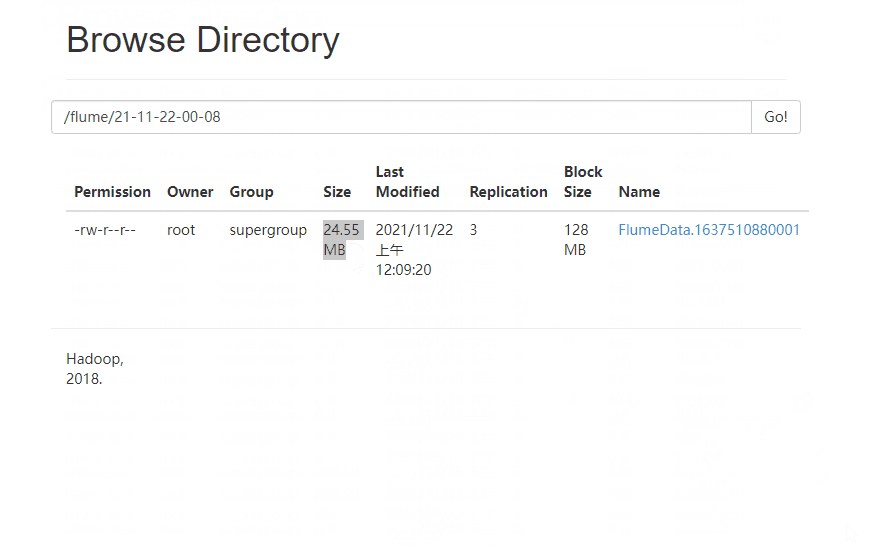
2.3.3 tailDir2avro-avro2hdfs
Two servers are currently required, and if only one is configured with Flume, you can send files to other servers via scp-rq <file> <hostname>: <path>.
scp -rq /opt/flume-1.9.0/ node2:/opt/
Implement the following topology:

| avro sink common configuration items | Default value | describe |
|---|---|---|
| type | - | Configuring types as avro |
| hostname | - | Configure type as host name or IP address |
| port | - | Configure port number |
| avro source common configuration items | Default value | describe |
|---|---|---|
| type | - | Configuring types as avro |
| bind | - | Configure the type as a host name or IP address to listen on |
| port | - | Configure Listening Port Number |
1 ️⃣ Step1:node1 host, add configuration file tailDir2avro.conf
# taildir reads multiple log files in the same directory and sends data to avro sink # Name the components on this agent taildir2avro.sources = r1 taildir2avro.sinks = k1 taildir2avro.channels = c1 # Describe/configure the source taildir2avro.sources.r1.type = TAILDIR taildir2avro.sources.r1.filegroups = g1 g2 taildir2avro.sources.r1.filegroups.g1 = /root/log.txt taildir2avro.sources.r1.filegroups.g2 = /root/log/.*.txt # Describe the sink taildir2avro.sinks.k1.type = avro taildir2avro.sinks.k1.hostname = node2 taildir2avro.sinks.k1.port = 12345 # Use a channel which buffers events in memory taildir2avro.channels.c1.type = memory taildir2avro.channels.c1.capacity = 30000 taildir2avro.channels.c1.transactionCapacity = 3000 # Bind the source and sink to the channel taildir2avro.sources.r1.channels = c1 taildir2avro.sinks.k1.channel = c1
2 ️⃣ Step2:node2 host, add configuration file avro2hdfs.conf
# spooldir reads multiple log files in the same directory and sends data to logger sink # Name the components on this agent avro2hdfs.sources = r1 avro2hdfs.sinks = k1 avro2hdfs.channels = c1 # Describe/configure the source avro2hdfs.sources.r1.type = avro avro2hdfs.sources.r1.bind = node2 avro2hdfs.sources.r1.port = 12345 # Describe the sink avro2hdfs.sinks.k1.type = hdfs avro2hdfs.sinks.k1.hdfs.path = hdfs://node1:8020/flume/%y-%m-%d-%H-%M avro2hdfs.sinks.k1.hdfs.fileType = DataStream avro2hdfs.sinks.k1.hdfs.writeFormat = Text avro2hdfs.sinks.k1.hdfs.useLocalTimeStamp = true avro2hdfs.sinks.k1.hdfs.rollInterval = 300 avro2hdfs.sinks.k1.hdfs.rollSize = 130000000 avro2hdfs.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory avro2hdfs.channels.c1.type = memory avro2hdfs.channels.c1.capacity = 30000 avro2hdfs.channels.c1.transactionCapacity = 3000 # Bind the source and sink to the channel avro2hdfs.sources.r1.channels = c1 avro2hdfs.sinks.k1.channel = c1
3 ️⃣ Step3: Start Flume on node2
flume-ng agent -c /opt/flume-1.9.0/conf/ -f /opt/flume-1.9.0/agents/avro2hdfs.conf -n avro2hdfs -Dflume.root.logger=INFO,console
4 ️⃣ Step4: Check if port 12345 of node2 is being listened on and make sure it is already listening on

5 ️⃣ Step5: Run the printer.sh script for node1 for a while and start the Flume for node1
flume-ng agent -c /opt/flume-1.9.0/conf/ -f /opt/flume-1.9.0/agents/taildir2avro.conf -n taildir2avro -Dflume.root.logger=INFO,console
6 ️⃣ Step6: View the node2 console output, node1 successfully sent data to port 12345 of node2
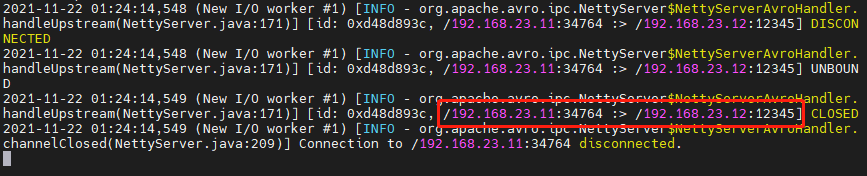
7 ️⃣ Step7: See if there is data submission on the web side
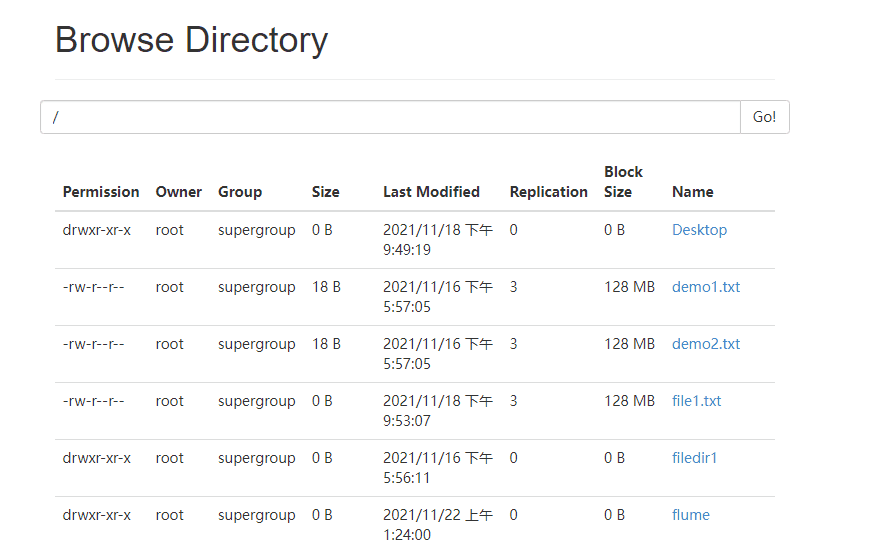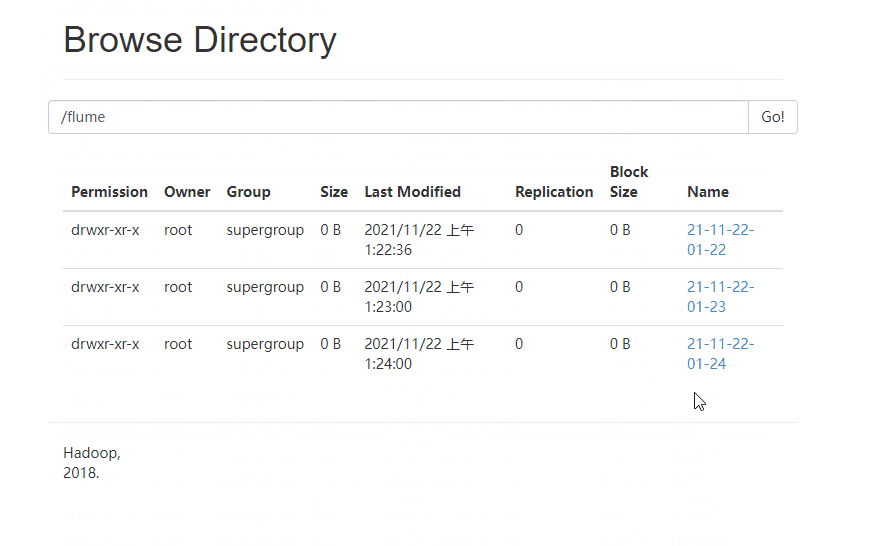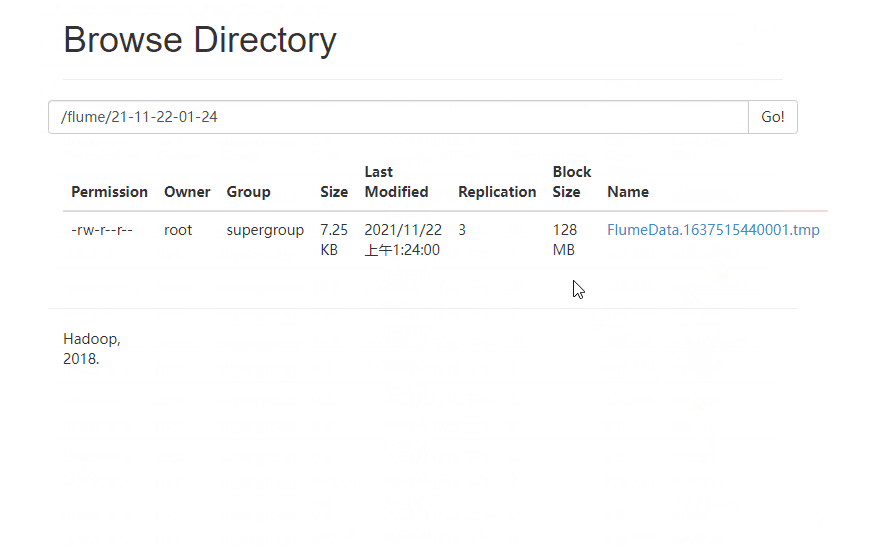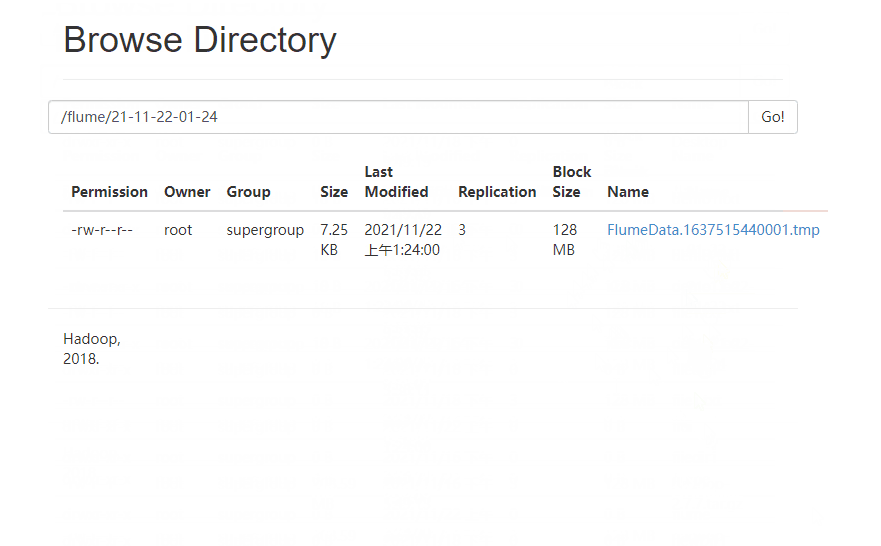
Already running!
3. Write at the end
When starting a program, sometimes the terminal is occupied, closing the terminal will close the program, so sometimes we need to mention submitting the program to the background for execution, then we need to add a &symbol after the command.
If there is content in the program that is output to the console and you don't want to be output to the console all the time, you can add a nohup command before the command and input the output to a file to make the program silent.